mysql索引的使用及优化方法
数据库高级管理及优化
MySQL性能优化
优化MySQL数据库是数据库管理员和数据库开发人员的必备技能。优化MySQL,一方面是找出系统的瓶颈,提高MySQL数据库整体的性能;另一方面是合理设计结构和调整参数,以提高用户操作响应的速度。同时还要尽可能节省系统资源,以便系统可以提供更大负荷的服务。
MySQL数据库优化是多方面的,原则是减少系统的瓶颈,减少资源的占用,提高系统的反应速度。例如,通过优化文件系统,提高磁盘的读写速度;通过优化操作系统调度策略,提高MySQL在高负荷情况下的负载能力;通过优化表结构、索引、查询语句等,使查询响应更快。我们这里只讲第三点
在MySQL中可以使用show status语句查询MySQL数据库的一些性能参数。其语法如下:
Show status like ‘value’;
其中value是要查询的参数值,常用的一些性能参数如下:
Connections :连接MySQL服务器的时间
Uptime : MySQL服务器的上线时间
Slow_ queries :慢查询的次数
Com_select : 查询操作的次数
Com_insert :插入操作的次数
Com_update:更新操作的次数
Com_delete :删除操作的次数
对数据库的优化有俩个方面:优化查询(使用索引、使用连接查询代替子查询)和优化数据库表结构
优化查询
使用MySQL自带的关键字explain或describe(desc)可以对查询语句进行分析
如下:
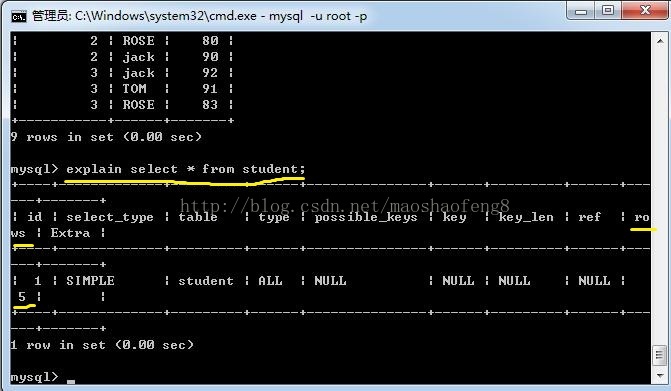
其中比较关键的是rows该参数十分重要代表了本次查询遍历了多少行数据。
使用索引进行查询:
前面已经介绍过了索引的用法这里不再赘述,只是比较一下使用索引与不使用索引查询的区别:
不用索引查询成绩表中成绩为90的所有信息
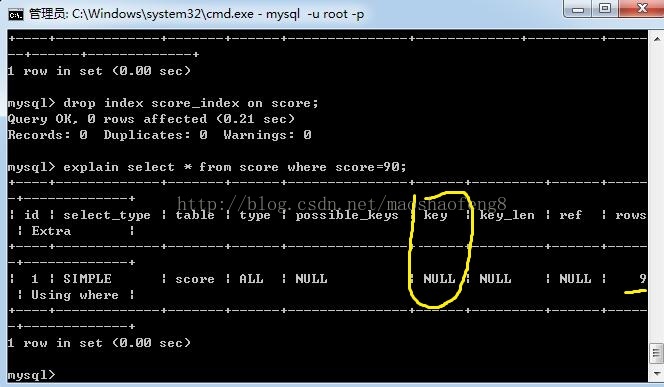
Key代表的是使用索引的名字,这里为null表示没有使用索引,rows为9表示本次查询遍历了9行数据。
使用索引查询成绩表中成绩为90的所有信息
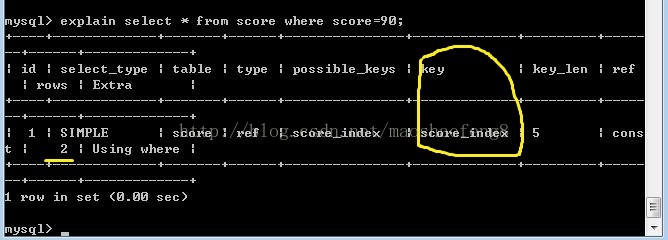
Key代表使用的索引名,rows为2表示本次查询只遍历了2行(要知道我的成绩表中总的数据量只有9条)与不用索引对比简直天壤之别。
索引可以提高查询速度,但并不是使用带有索引的字段查询时索引都会起作用,一下几种情况索引不会起作用:
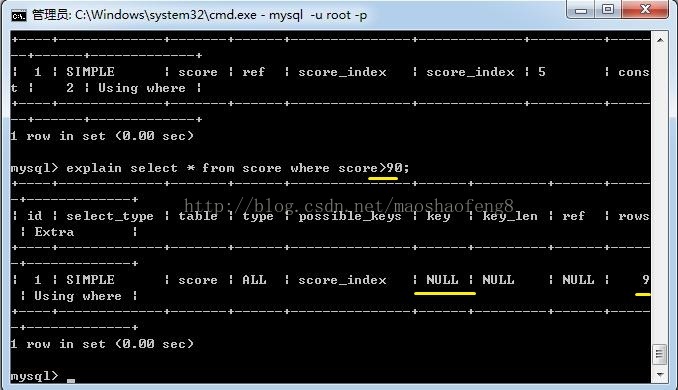
1、如果在成绩表中给score字段设置索引,但查询时where条件使用的是一个范围而不是一个确切的值时,索引无效,如:
2、在子查询中,主句连接的索引无效,子句连接的索引有效
如:select * from student where id in (select studentid from score where score>90);
即此处id的索引无效,studentid的索引有效,如图
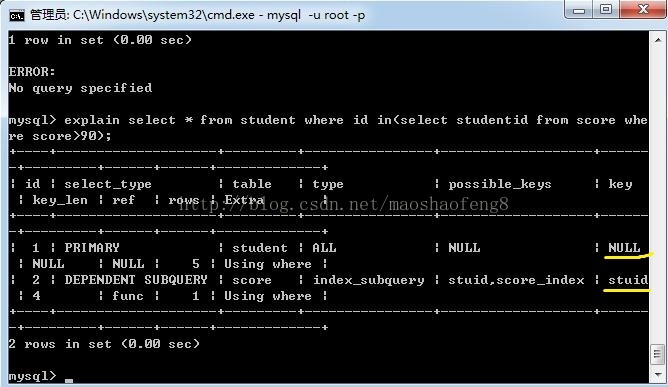
主句的key为null,子句的key为stuid索引。
3、使用like关键字进行查询时,如果匹配字符串的第一个字符为“%”,索引不会起作用,
“%”不在第一个位置索引才会起作用
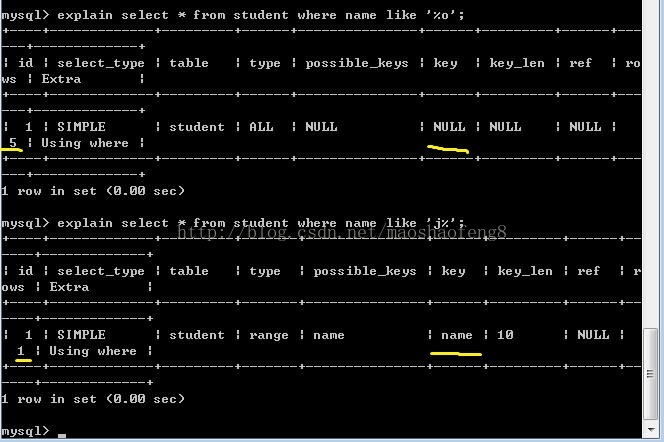
4、使用多列索引查询语句
对于多列索引,只有在查询条件中使用了这些字段中的第一个字段时,索引才会被使用。
5、使用or关键字的查询语句
查询语句的条件中只有OR时,并且OR前后的俩个条件中的列都是索引时,查询中才使用索引,否则不使用索引。
优化子查询
使用连接查询(join)代替子查询可以提高查询效率。
MySQL从4.1版开始支持子查询(一个查询的结果作为另一个select子句的条件),子查询虽然灵活但执行效率不高,因为使用子查询时,MySQL需要为内层查询语句的查询结果建立一个临时表,然后外层查询语句从临时表中查询记录,查询完毕后
再撤销这些临时表,因此子查询的速度会相应的受到影响。而连接查询不需要建立临时表其查询速度快于子查询!
优化数据库表结构
1、将字段较多的表分解成多个表
对于字段较多的表,如果有些字段的使用频率很低,可以将这些字段分离出来形成新表。因为当一个表的数据量很大时,会由于存在使用频率低的字段而使查询速度变慢。
2、增加中间表
对于经常需要联合查询的表,可以建立中间表以提高查询效率。通过建立中间表,把需要经常联合查询的数据插入中间表,然后将原来的联合查询改为对中间表的查询,以此来提高查询效率。
3、增加冗余字段
设计数据库表时应尽量遵循范式理论的规约,尽可能减少冗余字段,让数据库表的设计看起来精致、优雅。但是,合理地加入冗余字段可以提高查询速度。如:员工信息存储在staff表中,部门信息存储在department表中。通过staff表中的department_id字段与department表建立关系,如果要查询一个员工所在的部门的名称,必须从staff表中找到员工所在部门的编号(department_id),然后根据这个编号在department表中查找部门名称,如果经常需要这个操作,连接查询便会浪费很多时间。可以在staff表中增加一个冗余字段department_name,该字段用于存储员工所在部门的名称,这样就不用每次都进行连接查询操作了。
4、优化插入记录的速度
innoDB引擎的表常见的优化方法
(1)、禁用唯一性检查
插入数据时,MySQL会对插入的记录进行唯一性校验。这种唯一性校验会降低插入记录的速度。为了降低这种情况对查询速度的影响可以在插入记录之前禁用唯一性检查,等到记录插入完毕后再开启。
Set unique_check=0; 开启唯一性检查的语句如下:set unique_checks=1;
(2)、禁用外键检查
插入数据之前禁止对外键的检查,数据插入完成之后再恢复对外键的检查。
Set foreign_key_checks=0; 恢复外键检查:set foreign_key_checks=1;
(3)、禁止自动提交
插入数据之前禁止事务的自动提交,数据导入之后,执行恢复自动提交操作。
禁止自动提交的语句 set autocommit=0;恢复自动提交:set autocommit=1;
Myisam引擎表常见的优化方法
(1)、禁用索引 alter table table_name disable keys
开启索引 alter table table_name enable keys
(2)禁用唯一性检查
(3)使用批量插入
(4)当需要批量导入数据时,使用load data infile
5、分析、检查和优化表
MySQL提供了分析。检查和优化表的语句。分析表主要是分析关键字的分布,检查表主要是检查表是否存在错误,优化表主要是消除删除或者更新造成的空间浪费。
(1)分析表:
对innoDB、myisam、BDB类型的表有效
Analyze table talbename;分析期间数据库系统会为表加一个只读锁。
(2)检查表
Check对innoDB、myisam类型的表有效
Check table tablename option={quick | fast | medium | extended | changed}
Quick:不扫描行,不检查错误的连接
Fast:只检查没有被正确关闭的表
Changed:只检查上次检查后被更改的表和没有被正确关闭的表
Medium:扫描行,以验证被删除的连接是有效的,也可以计算各行的关键字校验和,并使用计算出的校验和验证这一点。
Extended:对每行的所有关键字进行全面的关键字查找,这可以确保表是100%一致的,但是用时较长。
(3)优化表
对innoDB、myisam类型的表有效
Optimize table tablename 可以删除和更新造成的文件碎片。
6、优化MySQL的参数
通过优化MySQL的参数可以提高资源利用率,从而达到提高MySQL服务器性能的目的。MySQL服务的配置参数都在my.cnf或者my.ini文件的【MySQL】组中,下面介绍对性能影响比较大的几个参数:
Key_buffer_size : 表示索引缓冲区的大小。索引缓冲区所有的线程共享。增加索引缓冲区可以得到更好处理的索引。当然该值也不是越大越好,它的大小取决于内存的大小(如果该值太大,导致操作系统频繁换页,也会降低系统的性能)
Table_cache:表示同时打开的表的个数。这个值越大,能够同时打开的表就越多,但同时打开的表越多会影响操作系统的性能。
Query_cache_size:表示查询缓冲区的大小,该参数需要和query_cache_type配合使用。当query_cache_type的值是0时,所有的查询都不使用查询缓冲区。但是query_cache_type=0并不会导致MySQL释放query_cache_size所配置的缓冲区的内存。当query_cache_type=1时,所有的查询都将使用查询缓冲区。除非在查询语句中加select
sql_no_cache * from tablename 。query_cache_type=2时,除非在查询中使用sql_cache 关键字,否则查询不会使用缓冲区。使用查询缓冲区可以提高查询的速度,这种方式只适用修改操作少并且经常执行相同的查询操作的情况。
Sort_buffer_size:表示排序缓冲区的大小,这个值越大进行排序的速度越快。
Read_buffer_size:表示每个线程连续扫描时为扫描的每个表分配的缓冲区的大小。当线程从表中连续读取数据时会用到该缓冲区。
Read_rnd_buffer_size:表示为每个线程保留的缓存区的大小,与Read_buffer_size相似。但主要用于存储按特定顺序读取出来的记录。
Innodb_buffer_pool_size:表示InnoDB类型的表和索引的最大缓存。这个值越大,查询的速度就会越快,但这个值太大会影响操作系统的性能。
Max_connections:表示数据库的最大连接数。这个数据不是越大越好,因为这些链接会浪费内存资源,过多的连接可能会导致MySQL服务器僵死。
Innodb_flush_log_at_trx_commit:表示何时将缓冲区的数据写入日志文件,并且将日志文件写入磁盘。该参数对于innoDB引擎非常重要。该参数有3个值,分别为0、1、2.值为0时表示每隔一秒将数据写入日志文件并将日志写入磁盘;值为1时表示每次提交事务时将数据写入日志文件并将日志文件写入磁盘;值为2时表示每次提交事务时将数据写入磁盘,每隔一秒将日志文件写入磁盘。该参数的默认值为1,值为1时安全性最高,但是每次事务提交或事务外的指令都需要把日志写入硬盘,是比较费时的;值为0时更快一些,但安全方面比较差;值为2时日志仍然会每秒都写入硬盘,所以即使出现故障,一般也不会丢失超过1~2秒的更新。
Back_log:表示在MySQL暂时停止回答新请求之前的短时间内,多少个请求可以被存在堆栈中。换句话说,该值表示到来的TCP/IP连接的侦听队列的大小。
Interactive_timeout:表示服务器在关闭连接前等待行动的秒数。
Sort_buffer_size:表示每个需要进行排序的线程分配的缓冲区的大小,增加这个参数可以提高order by或group by操作的速度。
Thread_cache_size:表示可以复用的线程的数量。
Wait_timeout:表示服务器在关闭一个连接时等待行动的秒数。
数据库备份
1、使用mysqldump命令备份
Mysqldump是MySQL提供的一个非常有用的数据备份工具,执行MySQLdump命令时,可以将数据备份成一个文本文件。
对整个数据库备份语法为:mysqldump -u username -p dbname >filename.sql
例如:mysqldump -u root -p feng_test > d:feng.sql
对某张表备份语法为:mysqldump -u username -p dbname tablename > filename.sql
备份多个数据库:mysqldump -u username -p --databases booksdb test > filename.sql(备份booksdb和test数据库)
另外--all-databases参数可以备份系统中所有的数据库
还原备份:mysql -u username -p dbname < filename.sql
如果已经登录了就可以使用:source filaname.sql
2、直接复制数据文件
3、Mysqlhotcopy快速备份与恢复
该方法是备份数据库或单个表的最快途径,但只能备份MYISAM类型的表!
如 将test数据库备份到/user/backup目录下:
Mysqlhotcopy -u root -p test /user/backup
恢复数据:
如 cp -r /usr/backup/test usr/local/mysql/data
数据库日志
MySQL有四类日志
错误日志:记录启动、运行或停止MySQL服务时出现的问题
查询日志:记录建立的客户端连接和执行的语句
二进制日志:记录所有更改数据的语句,可用于数据复制
慢查询日志:记录执行时间超过long_query_time的所有查询或不使用索引的查询。
1、二进制日志:
二进制日志主要记录MySQL数据库的变化。二进制日志以一种有效的格式,并且是事务安全的方式包含更新日志中可用的所有信息。二进制日志包含所有更新了数据或者已经潜在更新了数据的语句。语句以“事件”的形式保存,描述数据更改。
启动和设置二进制日志
默认情况下,二进制日志是关闭的,可以通过修改MySQL的配置文件来启动和设置二进制日志。My.ini文件中[mysqld]组下面有如下几个设置是关于二进制日志的:
Log-bin [=path/ [filename] ]
Expire_logs_days = 10
Max_binlog_size = 100M
Log-bin定义开启二进制日志,path表明日志文件所在的目录路径;filename指定了日志文件的名称。
Expire_logs_days 定义了MySQL清除过期日志的时间,即二进制日志存活的日期
Max_binlog_size :定义了单个文件的大小,如果二进制日志写入的内容大小超过给定值,日志就会发生滚动(关闭当前文件,重新打开一个新的日志文件)
在my.ini配置文件中的[mysqld]组下,添加上述几个参数与参数值,关闭并重启MySQL服务进程,即可打开二进制日志。
使用show variables like ‘log_%’;语句查询日志设置
使用show binary logs命令查看二进制日志文件的个数及文件名
如:show binary logs
使用MySQLbinlog查看二进制日志
如:Mysqlbinlog d:/mysql/log/binlog.000001
2、错误日志
在my.ini(或者my.cnf)文件下的【mysqld】下配置log-error,则可以启动错误日志。
Show variables like ‘log_error’;
3、通用查询日志
通用查询日志记录MySQL所有用户操作,包括启动和关闭服务、执行查询、更新语句等 。通过配置my.ini的【mysqld】组下加入log选项
4、慢查询日志
慢查询日志是记录查询时长超过指定时间的日志
启动:a)配置my.ini或者my.cnf中的log-slow-queries选项打开,
b) MySQL服务启动时使用-log-slow-queries[=file_name]启动慢查询日志
但都需要在配置文件中配置 long_query_time选项指定记录阈值
Show variables like ‘slow_query_log%’;
Set global slow_query_log=1;开启日志
Set global long_query_time=4 设置阈值
select *from mysql.slow_log;
MySQL查询缓存
MySQL服务器有一个重要的特征是查询缓存,缓存机制简单的说就是缓存SQL语句和查询的结果,如果运行相同的SQL语句,服务器会直接从缓存中取到结果,而不再需要再去解析和执行SQL语句。查询缓存会存储最新数据,而不会返回过期数据,当数据被修改后,在查询缓存中的的任何相关数据均被清除。
如何使用:
1、设置query_cache_type 为ON
Set session query_cache_type=on ;
2、查看查询缓存是否开启
Select @@query_cache_type;
3、查看系统变量have_query_cache是否为YES,该参数表示MYSQL的查询缓存是否可用
Show variables like ‘have_query_cache’;
4、查看系统变量query_cache_size 的大小,该参数表示数据库分配给查询缓存的内存大小,如果该参数的值设置为0,那么查询缓存将不起作用。
Select @@global.query_cache_size;
5、设置系统变量query_cache_size的大小
Set @@global.query_cache_size = 1000000;
6、如果查询结果很大导致缓存不了,那就得设置query_cache_limit参数的值,
Set @@global.query_cache_limit = 2000000;
7、以如上方法设置缓存大小和缓存的最大值只对该次有用,如要永久设定则需修改 my.cnf配置文件:
[mysqld]
Port = 3306
Query_cache_size =1000000
Query_cache_limit = 2000000
还有俩条使用的命令:show variables like ‘%query_cache%’;查看缓存的相关参数
Show status like ‘qcache_hits’; 查看缓存命中的次数
SQL命令还是需要自己多敲多总结才能掌握!
mysql索引的使用及优化方法的更多相关文章
- MySQL的性能指标计算和优化方法
MySQL的性能指标计算和优化方法1 QPS计算(每秒查询数) 针对MyISAM引擎为主的DB mysql> show global status like 'questions';+----- ...
- php面试专题---Mysql索引原理及SQL优化
php面试专题---Mysql索引原理及SQL优化 一.总结 一句话总结: 注意:只写精品 1.为表设置索引要付出代价 是什么? 存储空间:一是增加了数据库的存储空间 修改插入变动索引时间:二是在插入 ...
- mysql索引的使用和优化
参考: http://blog.csdn.net/xluren/article/details/32746183 http://www.cnblogs.com/hustcat/archive/2009 ...
- mysql索引使用策略及优化
原文地址:http://blog.codinglabs.org/articles/theory-of-mysql-index.html 索引使用策略及优化 MySQL的优化主要分为结构优化(Schem ...
- Mysql索引详解及优化(key和index区别)
MySQL索引的概念 索引是一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的引用指针.更通俗的说,数据库索引好比是一本书前面的目录,能加快数据库 ...
- mysql 索引使用策略及优化
索引使用策略及优化 MySQL的优化主要分为结构优化(Scheme optimization)和查询优化(Query optimization).本章讨论的高性能索引策略主要属于结构优化范畴.本章的内 ...
- MySQL索引的维护与优化——查找重复及冗余索引
方法一:通过MySQL的information_schema数据库 查找重复与冗余索引 SELECT a.table_schema AS '数据库', a.table_name AS '表名', a. ...
- MySQL索引原理及SQL优化
目录 索引(Index) 索引的原理 b+树 MySQL如何使用索引 如何优化 索引虽好,不可滥用 如何验证索引使用情况? SQL优化 explain查询执行计划 id select_type tab ...
- Phoenix表和索引分区优化方法
Phoenix表和索引分区,基本优化方法 优化方法 1. SALT_BUCKETS RowKey SALT_BUCKETS 分区 2. Pre-split RowKey分区 3. 分列族 4. 使用压 ...
随机推荐
- cron 和anacron 、日志转储的周期任务
一.cron是开机自动启动的 [root@localhost ~]# chkconfig --list | grep "cron" crond 0:off 1:off 2:on 3 ...
- PHP动态函数处理
public class Student{ public function speek($name){ echo 'my name is '.$name; } } $method='speek'; $ ...
- 小白神器 - 两篇博客读懂JavaScript (一基础篇)
JavaScript是一门编程语言,浏览器内置了JavaScript语言的解释器,所以在浏览器上按照JavaScript语言的规则编写相应代码之,浏览器可以解释并做出相应的处理. 一. 编写格式 1, ...
- [luogu] P4105 [HEOI2014]南园满地堆轻絮 (贪心)
P4105 [HEOI2014]南园满地堆轻絮 题目描述 小 Z 是 ZRP(Zombies' Republic of Poetry,僵尸诗歌共和国)的一名诗歌爱好者,最近 他研究起了诗词音律的问题. ...
- Vue轮播图插件---Vue-Awesome-Swiper
轮播图插件 Vue-Awesome-Swiper 地址:https://github.com/surmon-china/vue-awesome-swiper 安装:npm install vue-aw ...
- java中的instanceof用法
Java 中的instanceof 运算符是用来在运行时指出对象是否是特定类的一个实例.instanceof通过返回一个布尔值来指出,这个对象是否是这个特定类或者是它的子类的一个实例. 用法: ...
- 【Codeforces Round #483 (Div. 2) C】Finite or not?
[链接] 我是链接,点我呀:) [题意] 在这里输入题意 [题解] 有个性质. 如果p/q是分数的最简形式. 那么p/q能化成有限小数. 当且仅当q的质因数分解形式中只有质因子2和5 (且不能出现其他 ...
- java字符文件的读写
1.java文件读写,首先我们需要导入相应的包:java.io.*; 2.代码如下: package Demo1; import java.io.*; public class FileWirteTe ...
- DQL命令(查询)
select *或字段1,字段2... from 表名 [where 条件] 提示:*符号表示取表中所有列:没有where语句表示 查询表中所有记录:有wh ...
- fork同一时候创建多个子进程的方法
Fork同一时候创建多个子进程方法 第一种方法:验证通过 特点:同一时候创建多个子进程.每一个子进程能够运行不同的任务,程序 可读性较好,便于分析,易扩展为多个子进程 int main(void) { ...