Hadoop 三剑客之 —— 分布式计算框架 MapReduce
一、MapReduce概述
Hadoop MapReduce是一个分布式计算框架,用于编写批处理应用程序。编写好的程序可以提交到Hadoop集群上用于并行处理大规模的数据集。
MapReduce作业通过将输入的数据集拆分为独立的块,这些块由map以并行的方式处理,框架对map的输出进行排序,然后输入到reduce中。MapReduce框架专门用于<key,value>键值对处理,它将作业的输入视为一组<key,value>对,并生成一组<key,value>对作为输出。输出和输出的key和value都必须实现Writable 接口。
(input) <k1, v1> -> map -> <k2, v2> -> combine -> <k2, v2> -> reduce -> <k3, v3> (output)二、MapReduce编程模型简述
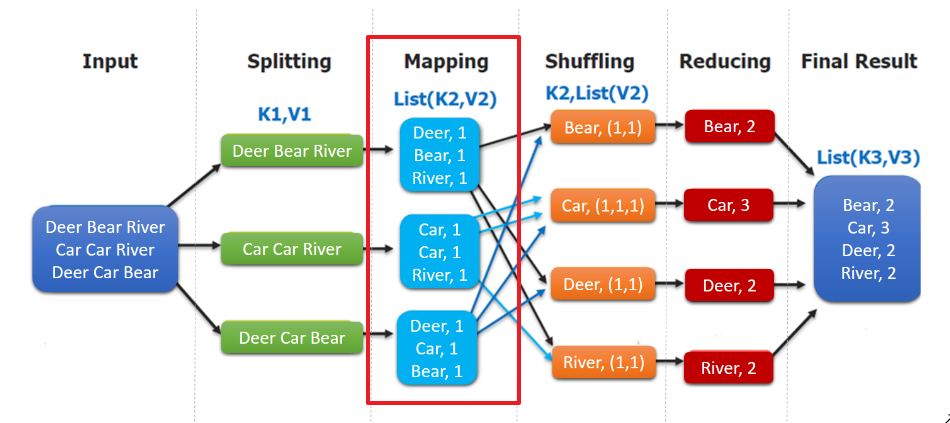
这里以词频统计为例进行说明,MapReduce处理的流程如下:
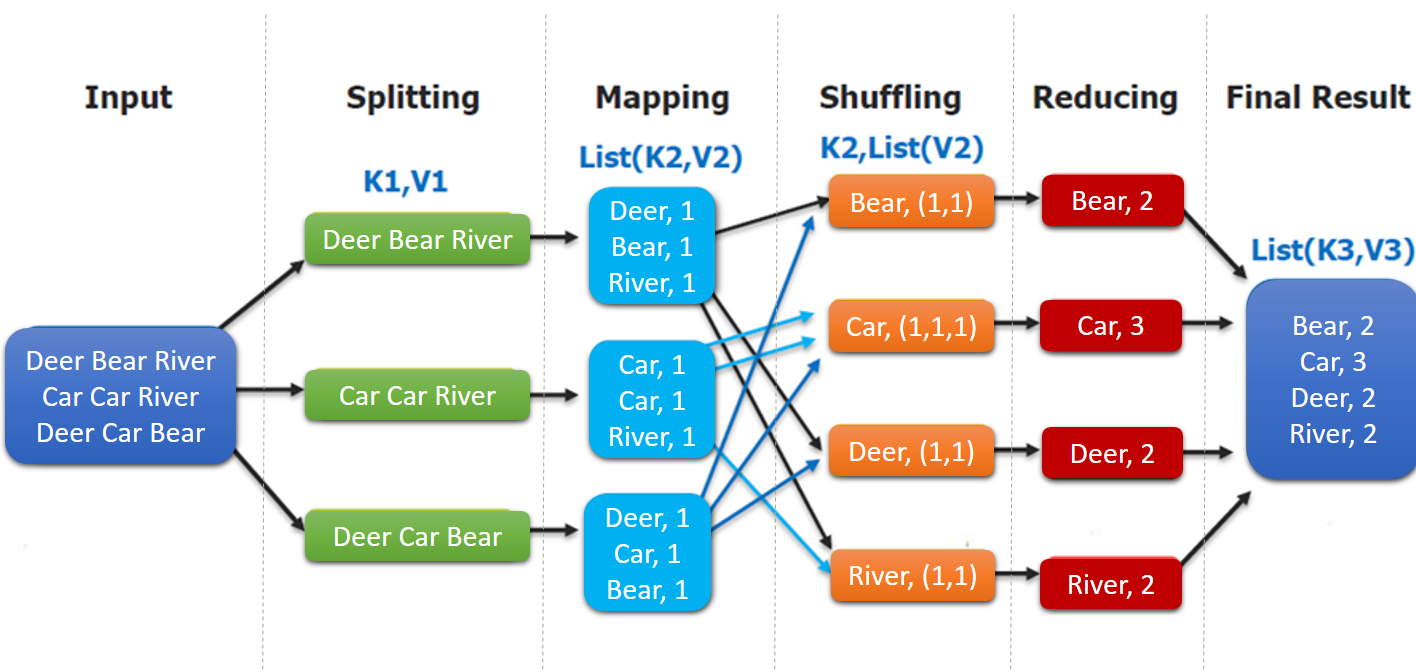
- input : 读取文本文件;
- splitting : 将文件按照行进行拆分,此时得到的
K1行数,V1表示对应行的文本内容; - mapping : 并行将每一行按照空格进行拆分,拆分得到的
List(K2,V2),其中K2代表每一个单词,由于是做词频统计,所以V2的值为1,代表出现1次; - shuffling:由于
Mapping操作可能是在不同的机器上并行处理的,所以需要通过shuffling将相同key值的数据分发到同一个节点上去合并,这样才能统计出最终的结果,此时得到K2为每一个单词,List(V2)为可迭代集合,V2就是Mapping中的V2; - Reducing : 这里的案例是统计单词出现的总次数,所以
Reducing对List(V2)进行归约求和操作,最终输出。
MapReduce编程模型中splitting 和shuffing操作都是由框架实现的,需要我们自己编程实现的只有mapping和reducing,这也就是MapReduce这个称呼的来源。
三、combiner & partitioner
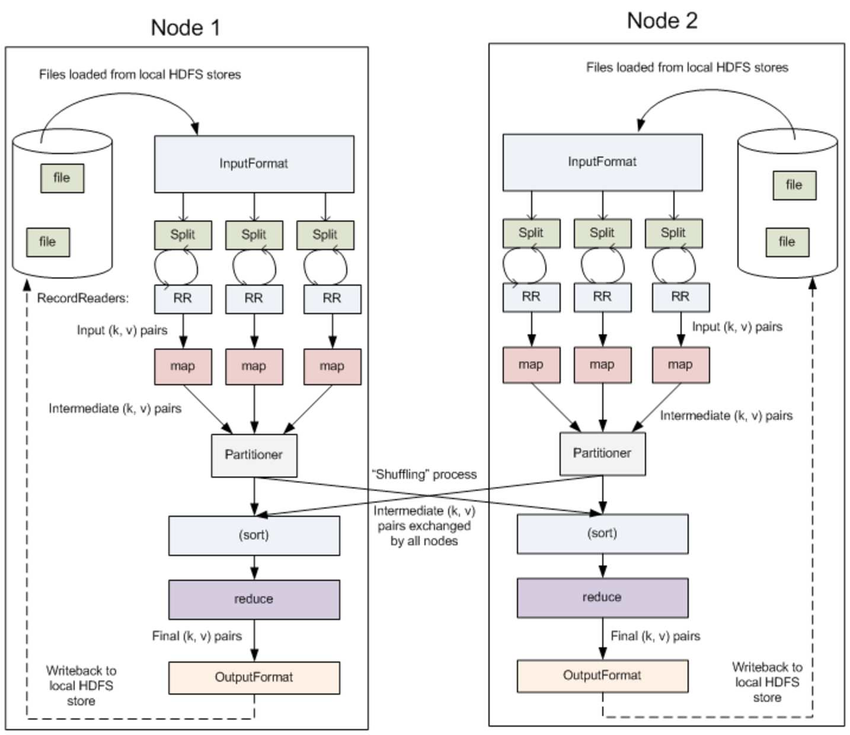
3.1 InputFormat & RecordReaders
InputFormat将输出文件拆分为多个InputSplit,并由RecordReaders将InputSplit转换为标准的<key,value>键值对,作为map的输出。这一步的意义在于只有先进行逻辑拆分并转为标准的键值对格式后,才能为多个map提供输入,以便进行并行处理。
3.2 Combiner
combiner是map运算后的可选操作,它实际上是一个本地化的reduce操作,它主要是在map计算出中间文件后做一个简单的合并重复key值的操作。这里以词频统计为例:
map在遇到一个hadoop的单词时就会记录为1,但是这篇文章里hadoop可能会出现n多次,那么map输出文件冗余就会很多,因此在reduce计算前对相同的key做一个合并操作,那么需要传输的数据量就会减少,传输效率就可以得到提升。
但并非所有场景都适合使用combiner,使用它的原则是combiner的输出不会影响到reduce计算的最终输入,例如:求总数,最大值,最小值时都可以使用combiner,但是做平均值计算则不能使用combiner。
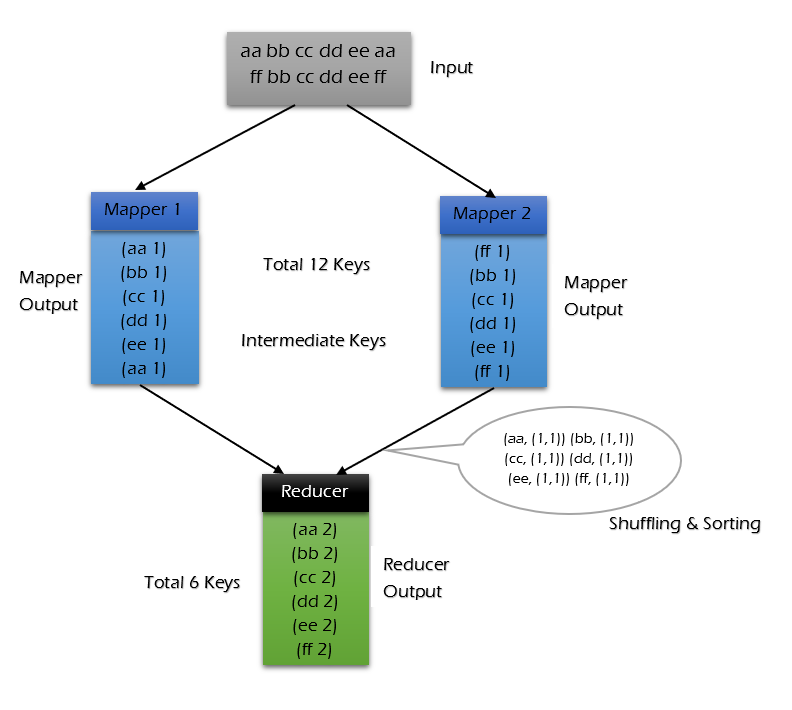
不使用combiner的情况:
使用combiner的情况:
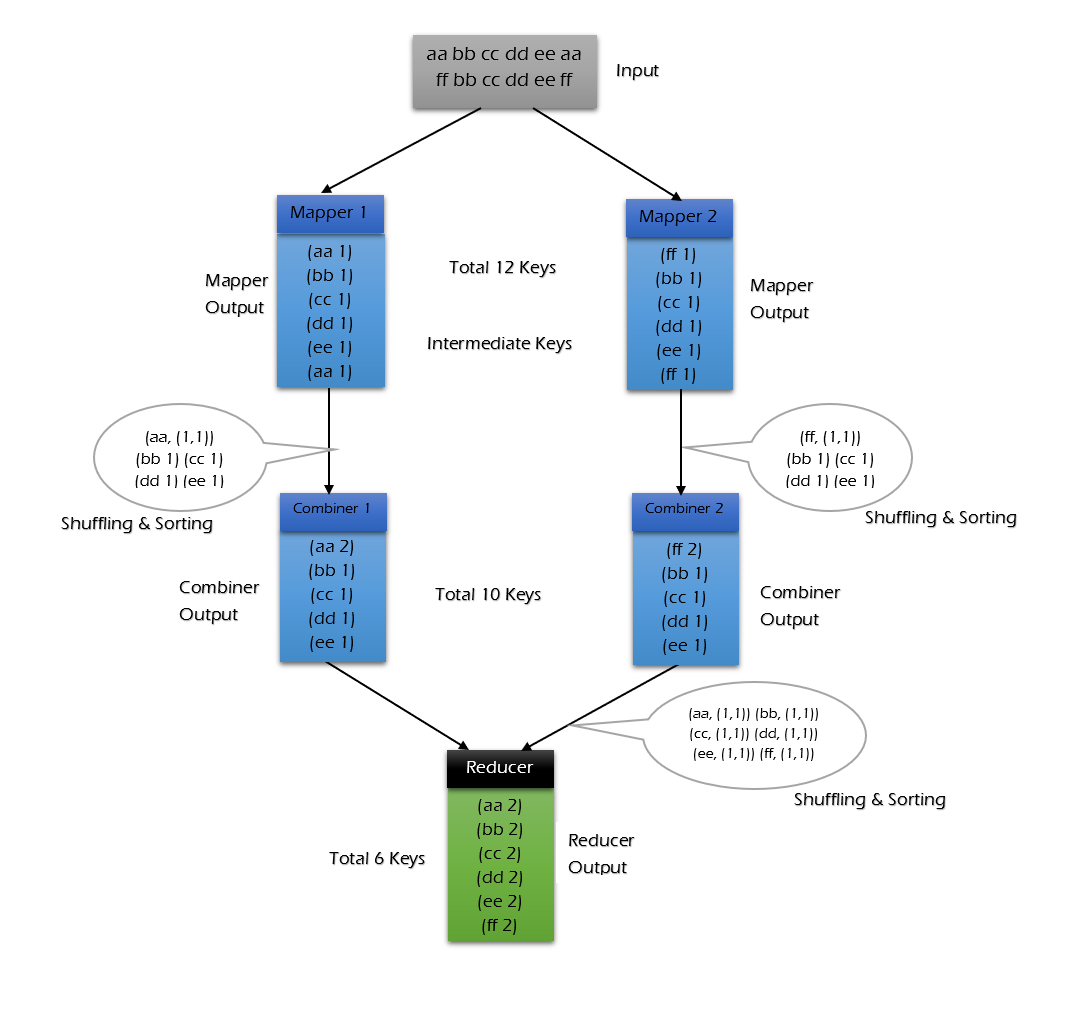
可以看到使用combiner的时候,需要传输到reducer中的数据由12keys,降低到10keys。降低的幅度取决于你keys的重复率,下文词频统计案例会演示用combiner降低数百倍的传输量。
3.3 Partitioner
partitioner可以理解成分类器,将map的输出按照key值的不同分别分给对应的reducer,支持自定义实现,下文案例会给出演示。
四、MapReduce词频统计案例
4.1 项目简介
这里给出一个经典的词频统计的案例:统计如下样本数据中每个单词出现的次数。
Spark HBase
Hive Flink Storm Hadoop HBase Spark
Flink
HBase Storm
HBase Hadoop Hive Flink
HBase Flink Hive Storm
Hive Flink Hadoop
HBase Hive
Hadoop Spark HBase Storm
HBase Hadoop Hive Flink
HBase Flink Hive Storm
Hive Flink Hadoop
HBase Hive为方便大家开发,我在项目源码中放置了一个工具类WordCountDataUtils,用于模拟产生词频统计的样本,生成的文件支持输出到本地或者直接写到HDFS上。
项目完整源码下载地址:hadoop-word-count
4.2 项目依赖
想要进行MapReduce编程,需要导入hadoop-client依赖:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>4.3 WordCountMapper
将每行数据按照指定分隔符进行拆分。这里需要注意在MapReduce中必须使用Hadoop定义的类型,因为Hadoop预定义的类型都是可序列化,可比较的,所有类型均实现了WritableComparable接口。
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException,
InterruptedException {
String[] words = value.toString().split("\t");
for (String word : words) {
context.write(new Text(word), new IntWritable(1));
}
}
}WordCountMapper对应下图的Mapping操作:
WordCountMapper继承自Mappe类,这是一个泛型类,定义如下:
WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>
public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
......
}- KEYIN :
mapping输入key的类型,即每行的偏移量(每行第一个字符在整个文本中的位置),Long类型,对应Hadoop中的LongWritable类型; - VALUEIN :
mapping输入value的类型,即每行数据;String类型,对应Hadoop中Text类型; - KEYOUT :
mapping输出的key的类型,即每个单词;String类型,对应Hadoop中Text类型; - VALUEOUT:
mapping输出value的类型,即每个单词出现的次数;这里用int类型,对应IntWritable类型。
4.4 WordCountReducer
在Reduce中进行单词出现次数的统计:
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException,
InterruptedException {
int count = 0;
for (IntWritable value : values) {
count += value.get();
}
context.write(key, new IntWritable(count));
}
}如下图,shuffling的输出是reduce的输入。这里的key是每个单词,values是一个可迭代的数据类型,类似(1,1,1,...)。
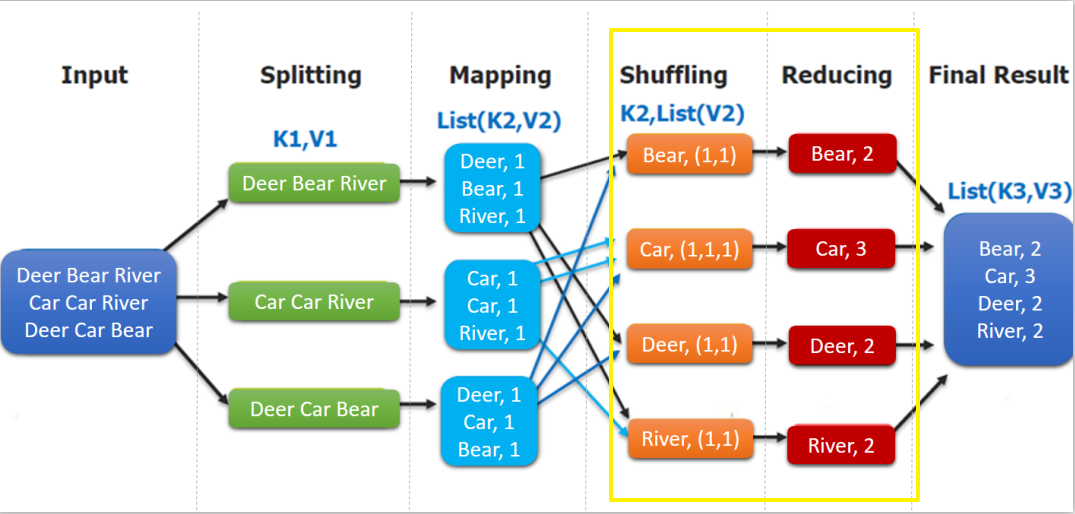
4.4 WordCountApp
组装MapReduce作业,并提交到服务器运行,代码如下:
/**
* 组装作业 并提交到集群运行
*/
public class WordCountApp {
// 这里为了直观显示参数 使用了硬编码,实际开发中可以通过外部传参
private static final String HDFS_URL = "hdfs://192.168.0.107:8020";
private static final String HADOOP_USER_NAME = "root";
public static void main(String[] args) throws Exception {
// 文件输入路径和输出路径由外部传参指定
if (args.length < 2) {
System.out.println("Input and output paths are necessary!");
return;
}
// 需要指明hadoop用户名,否则在HDFS上创建目录时可能会抛出权限不足的异常
System.setProperty("HADOOP_USER_NAME", HADOOP_USER_NAME);
Configuration configuration = new Configuration();
// 指明HDFS的地址
configuration.set("fs.defaultFS", HDFS_URL);
// 创建一个Job
Job job = Job.getInstance(configuration);
// 设置运行的主类
job.setJarByClass(WordCountApp.class);
// 设置Mapper和Reducer
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 设置Mapper输出key和value的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 设置Reducer输出key和value的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 如果输出目录已经存在,则必须先删除,否则重复运行程序时会抛出异常
FileSystem fileSystem = FileSystem.get(new URI(HDFS_URL), configuration, HADOOP_USER_NAME);
Path outputPath = new Path(args[1]);
if (fileSystem.exists(outputPath)) {
fileSystem.delete(outputPath, true);
}
// 设置作业输入文件和输出文件的路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, outputPath);
// 将作业提交到群集并等待它完成,参数设置为true代表打印显示对应的进度
boolean result = job.waitForCompletion(true);
// 关闭之前创建的fileSystem
fileSystem.close();
// 根据作业结果,终止当前运行的Java虚拟机,退出程序
System.exit(result ? 0 : -1);
}
}需要注意的是:如果不设置Mapper操作的输出类型,则程序默认它和Reducer操作输出的类型相同。
4.5 提交到服务器运行
在实际开发中,可以在本机配置hadoop开发环境,直接在IDE中启动进行测试。这里主要介绍一下打包提交到服务器运行。由于本项目没有使用除Hadoop外的第三方依赖,直接打包即可:
# mvn clean package使用以下命令提交作业:
hadoop jar /usr/appjar/hadoop-word-count-1.0.jar \
com.heibaiying.WordCountApp \
/wordcount/input.txt /wordcount/output/WordCountApp作业完成后查看HDFS上生成目录:
# 查看目录
hadoop fs -ls /wordcount/output/WordCountApp
# 查看统计结果
hadoop fs -cat /wordcount/output/WordCountApp/part-r-00000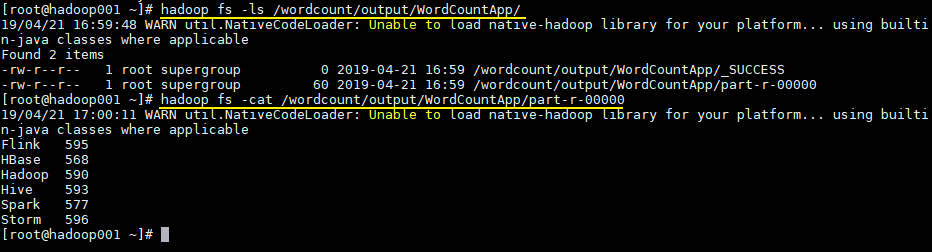
五、词频统计案例进阶之Combiner
5.1 代码实现
想要使用combiner功能只要在组装作业时,添加下面一行代码即可:
// 设置Combiner
job.setCombinerClass(WordCountReducer.class);5.2 执行结果
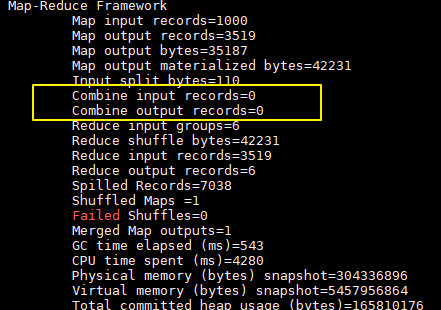
加入combiner后统计结果是不会有变化的,但是可以从打印的日志看出combiner的效果:
没有加入combiner的打印日志:
加入combiner后的打印日志如下:
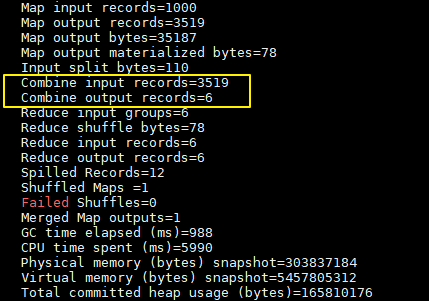
这里我们只有一个输入文件并且小于128M,所以只有一个Map进行处理。可以看到经过combiner后,records由3519降低为6(样本中单词种类就只有6种),在这个用例中combiner就能极大地降低需要传输的数据量。
六、词频统计案例进阶之Partitioner
6.1 默认的Partitioner
这里假设有个需求:将不同单词的统计结果输出到不同文件。这种需求实际上比较常见,比如统计产品的销量时,需要将结果按照产品种类进行拆分。要实现这个功能,就需要用到自定义Partitioner。
这里先介绍下MapReduce默认的分类规则:在构建job时候,如果不指定,默认的使用的是HashPartitioner:对key值进行哈希散列并对numReduceTasks取余。其实现如下:
public class HashPartitioner<K, V> extends Partitioner<K, V> {
public int getPartition(K key, V value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}6.2 自定义Partitioner
这里我们继承Partitioner自定义分类规则,这里按照单词进行分类:
public class CustomPartitioner extends Partitioner<Text, IntWritable> {
public int getPartition(Text text, IntWritable intWritable, int numPartitions) {
return WordCountDataUtils.WORD_LIST.indexOf(text.toString());
}
}在构建job时候指定使用我们自己的分类规则,并设置reduce的个数:
// 设置自定义分区规则
job.setPartitionerClass(CustomPartitioner.class);
// 设置reduce个数
job.setNumReduceTasks(WordCountDataUtils.WORD_LIST.size());6.3 执行结果
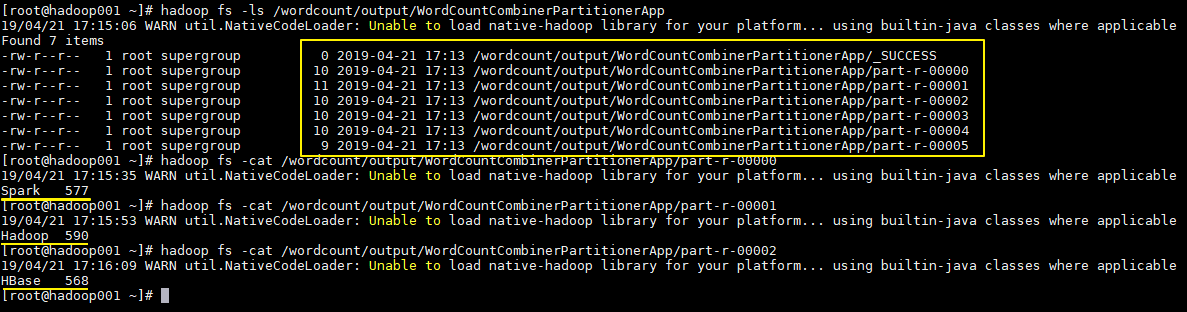
执行结果如下,分别生成6个文件,每个文件中为对应单词的统计结果:
参考资料
更多大数据系列文章可以参见个人 GitHub 开源项目: 大数据入门指南
Hadoop 三剑客之 —— 分布式计算框架 MapReduce的更多相关文章
- Hadoop 学习之路(三)—— 分布式计算框架 MapReduce
一.MapReduce概述 Hadoop MapReduce是一个分布式计算框架,用于编写批处理应用程序.编写好的程序可以提交到Hadoop集群上用于并行处理大规模的数据集. MapReduce作业通 ...
- Hadoop 系列(三)—— 分布式计算框架 MapReduce
一.MapReduce概述 Hadoop MapReduce 是一个分布式计算框架,用于编写批处理应用程序.编写好的程序可以提交到 Hadoop 集群上用于并行处理大规模的数据集. MapReduce ...
- Hadoop介绍-2.分布式计算框架Hadoop原理及架构全解
Hadoop是Apache软件基金会所开发的并行计算框架与分布式文件系统.最核心的模块包括Hadoop Common.HDFS与MapReduce. HDFS HDFS是Hadoop分布式文件系统(H ...
- 分布式计算框架-MapReduce 基本原理(MP用于分布式计算)
hadoop最主要的2个基本的内容要了解.上次了解了一下HDFS,本章节主要是了解了MapReduce的一些基本原理. MapReduce文件系统:它是一种编程模型,用于大规模数据集(大于1TB)的并 ...
- Hadoop整理四(Hadoop分布式计算框架MapReduce)
Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提 ...
- Hadoop整理三(Hadoop分布式计算框架MapReduce)
一.概念 MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算.概念"Map(映射)"和"Reduce(归约)",是它们的主要思想.它极大 ...
- 2_分布式计算框架MapReduce
一.mr介绍 1.MapReduce设计理念是移动计算而不是移动数据,就是把分析计算的程序,分别拷贝一份到不同的机器上,而不是移动数据. 2.计算框架有很多,不是谁替换谁的问题,是谁更适合的问题.mr ...
- 大数据时代之hadoop(五):hadoop 分布式计算框架(MapReduce)
大数据时代之hadoop(一):hadoop安装 大数据时代之hadoop(二):hadoop脚本解析 大数据时代之hadoop(三):hadoop数据流(生命周期) 大数据时代之hadoop(四): ...
- 分布式计算框架学习笔记--hadoop工作原理
(hadoop安装方法:http://blog.csdn.net/wangjia55/article/details/53160679这里不再累述) hadoop是针对大数据设计的一个计算架构.如果你 ...
随机推荐
- 函数模板“偏特化” (C++)
模板是C++中很重要的一个特性,利用模板可以编写出类型无关的通用代码,极大的减少了代码量,提升工作效率.C++中包含类模板.函数模板,对于需要特殊处理的类型,可以通过特化的方式来实现特定类型 ...
- Bit error testing and training in double data rate (ddr) memory system
DDR PHY interface bit error testing and training is provided for Double Data Rate memory systems. An ...
- 从Client应用场景介绍IdentityServer4(一)
原文:从Client应用场景介绍IdentityServer4(一) 一.背景 IdentityServer4的介绍将不再叙述,百度下可以找到,且官网的快速入门例子也有翻译的版本.这里主要从Clien ...
- yii联查
$count = Acticle::find()->select("acticle_type.act_type,acticle.act_id,acticle.act_title,act ...
- android点击屏幕隐藏小键盘
原文:android点击屏幕隐藏小键盘 fragment 下隐藏点击空白处隐藏小键盘 view.setOnTouchListener(new OnTouchListener() { @Overri ...
- hdu 1087 Super Jumping! Jumping! Jumping!(dp 最长上升子序列和)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1087 ------------------------------------------------ ...
- USER_AGENT 知识
USER-AGENT 是 Http 协议中的一部分,属于头域的组成部分,User Agent也简称 UA,意为用户代理,当用户通过浏览器发送 http 请求时,USER_AGENT 起到表明自己身份的 ...
- Microsoft IoT Starter Kit
Microsoft IoT Starter Kit 开发初体验 1. 引子 今年6月底,在上海举办的中国国际物联网大会上,微软中国面向中国物联网社区推出了Microsoft IoT Starter K ...
- 零元学Expression Design 4 - Chapter 5 教你如何用自制笔刷在5分钟内做出设计感效果
原文:零元学Expression Design 4 - Chapter 5 教你如何用自制笔刷在5分钟内做出设计感效果 本章将教你如何运用笔刷与简单线条,只要5分钟,就能做出设计感效果 ? 本章将教你 ...
- Codeforces 458A Golden System
经过计算两个字符串的大小对比 主要q^2=q+1 明明是斐波那契数 100000位肯定超LL 我在每一位仅仅取到两个以内 竟然ac了 #include<bits/stdc++.h> usi ...