Python 爬虫练习: 爬取百度贴吧中的图片
背景:最近开始看一些Python爬虫相关的知识,就在网上找了一些简单已与练习的一些爬虫脚本
实现功能:1,读取用户想要爬取的贴吧
2,读取用户先要爬取某个贴吧的页数范围
3,爬取每个贴吧中用户输入的页数范围内的每个帖子的链接
4,爬取每个帖子中的图片,并下载到本地。
开发环境:Python 3.7 , lxml, urllib
思路分析:
1,指定贴吧URL的获取
比如我们进入“秦时明月汉时关”吧
http://tieba.baidu.com/f?kw=%E7%A7%A6%E6%97%B6%E6%98%8E%E6%9C%88
?后面为查询字符串,“%E7%A7%A6%E6%97%B6%E6%98%8E%E6%9C%88“是贴吧名称“秦时明月”的url编码。
这样我们就可以通过构造请求进入每一个贴吧了,代码实现如下:
import urllib.parse
# 贴吧url前半部分
url = "http://tieba.baidu.com/f?"
value = input("请输入要爬取的贴吧名称:")
# 将查询字符串转换为url编码形式
key = urllib.parse.urlencode({"kw":value}) # 组合完整的贴吧url url = url + key # 查看完整url
print url
运行程序,这里输入“天行九歌”作为演示,可以得到天行九歌吧的完整链接如下:
http://tieba.baidu.com/f?kw=%CC%EC%D0%D0%BE%C5%B8%E8
这样就可以获取任意贴吧的链接了。
二、获取贴吧指定页数的链接:
我们进入天行九歌吧,取出该贴吧第2页到底4页的url,如下:
http://tieba.baidu.com/f?kw=%E7%A7%A6%E6%97%B6%E6%98%8E%E6%9C%88&pn=50
http://tieba.baidu.com/f?kw=%E7%A7%A6%E6%97%B6%E6%98%8E%E6%9C%88&pn=100
http://tieba.baidu.com/f?kw=%E7%A7%A6%E6%97%B6%E6%98%8E%E6%9C%88&pn=150
我们发现,每一页的url变化的是pn的值,依次增加50,结合上面贴吧完整的url,要想获得每一页的链接可以如下
import urllib.parse
url = "http://tieba.baidu.com/f?"
value = input("请输入要爬取的贴吧名称:")
key = urllib.parse.urlencode({"kw":value})
# 贴吧完整url
url = url + key
begin_page = int(input("请输入起始页:"))
end_page = int(input("请输入终止页:"))
for page in range(begin_page, end_page+1):
pn = (page-1)*50
# 组合出贴吧每一页的url
full_url = url + "&pn=" + str(pn)
print (full_url)
运行程序,输入贴吧名称:“天行九歌”,再输入起始页1,终止页5,可得到如下结果:

这样我们就可以拿到贴吧每一页的链接了。
三、获取贴吧每一页中帖子的链接:
选择一个帖子,首先查看该帖子的元素得到:
<a href="/p/5344262338" title="端木蓉为何一直不苏醒" target="_blank" class="j_th_tit ">端木蓉为何一直不苏醒</a>
然后进入这个帖子取得它的完整链接:
http://tieba.baidu.com/p/5344262338
分析可得:完整链接可由两部分组成,http://tieba.baidu.com和/p/5344262338,后面的部分可以从页面源码中提取,使用xpath规则提取如下:
xpath提取规则://a[@class="j_th_tit"]/@href(先在浏览器中使用插件匹配,规则很多,找到合适的就行)
下面选择第二页帖子链接做如下演示
# -*- coding: utf-8 -*-
import urllib.request
from lxml import etree
# 贴吧第二页url
url = "http://tieba.baidu.com/f?kw=%E5%A4%A9%E8%A1%8C%E4%B9%9D%E6%AD%8C&pn=50"
request = urllib.request.Request(url)
html = urllib.request.urlopen(request).read()
content = etree.HTML(html)
# 匹配这一页中所以帖子链接的后半部分
link_list = content.xpath('//div[@class="t_con cleafix"]/div/div/div/a/@href')
for link in link_list:
# 组合为完整帖子链接
fulllink = "http://tieba.baidu.com" + link
print(fulllink)
运行程序,则可取该页中帖子的链接(展示部分)
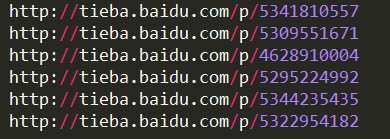
这样就拿到了每个帖子的链接了。
四、获取每一个帖子中图片的链接:
进入一个帖子,找到发布的图片查看元素:
<img class="BDE_Image" src="https://imgsa.baidu.com/forum/w%3D580/sign=c1cc6b66b819ebc4c0787691b227cf79/3577812397dda14415c938b1b9b7d0a20df48615.jpg" pic_ext="jpeg" size="39874" height="600" width="450">
使用xpath规则提取图片链接:
xpath提取规则://img[@class="BDE_Image"]/@src
取上面第一个帖子做演示:
# -*- coding: utf-8 -*-
import urllib.request
from lxml import etree
# 第一个帖子的url
url = "http://tieba.baidu.com/p/5341810557"
headers = {"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
request = urllib.request.Request(url, headers = headers)
html = urllib.request.urlopen(request).read()
content = etree.HTML(html)
# 匹配出帖子中的图片链接
link_list = content.xpath('//img[@class="BDE_Image"]/@src')
for link in link_list:
print (link)
运行程序,取得帖子中图片链接(展示部分)

到现在为止,我们已经可以进入任意一个贴吧,获取每个贴吧指定页数的响应,并且可以拿到每个帖子中的图片链接,接下来要做的就是以图片链接发送请求获取响应文件保存下来即可。
五、保存图片到本地:
import urllib.request
# 取得的图片链接
url = "http://imgsa.baidu.com/forum/w%3D580/sign=b42c88339945d688a302b2ac94c37dab/541d5d510fb30f243576ad03c395d143ac4b0352.jpg"
headers = {"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
request = urllib.request.Request(url, headers = headers)
image = urllib.request.urlopen(request).read()
# 将图片链接后10位作为图片文件名称
filename = url[-10:]
# 保存图片到本地
with open(filename, "wb") as f:
f.write(image)
六、完整程序
整个过程就是这样了,根据上面的分析,写出的完整程序如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @File : tiebaSpider.py
# @Author: bpan
# @Date : 2018/11/15 0015
# @Desc : from lxml import etree
import urllib.request, urllib.parse def loadPage(url):
"""
作用:根据url发送请求,获取服务器响应文件,获取一个贴吧中所有帖子的url
url: 需要爬取的url地址
""" headers = {"User-Agent" : "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;"} request = urllib.request.Request(url,headers=headers) html = urllib.request.urlopen(request).read() content = etree.HTML(html) #匹配每个帖子的URL的后半部分
link_list = content.xpath('//div[@class="t_con cleafix"]/div/div/div/a/@href')
for link in link_list:
#组合为每个帖子的完整链接
fulllink = "http://tieba.baidu.com" + link print("tiezi URL: ---------------------- "+fulllink) loadImage(fulllink) def loadImage(link):
"""
作用:取出每个帖子里的每个图片连接
link:每个帖子的链接
"""
headers = {"User-Agent": "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;"} request = urllib.request.Request(link,headers=headers) html = urllib.request.urlopen(request).read() content= etree.HTML(html) # 匹配帖子里发送的图片链接
link_list = content.xpath('//img[@class="BDE_Image"]/@src')
# 取出每个图片的连接
for link in link_list:
print("Image Link: -------------------- "+link) writeImage(link) def writeImage(link):
"""
作用:将图片保存到本地
link:图片连接
"""
headers = {"User-Agent": "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;"} request = urllib.request.Request(link,headers=headers) image = urllib.request.urlopen(request).read()
filename = link[-10:]
with open(filename, "wb") as f:
f.write(image)
print("已经成功下载 "+ filename) def tiebaSpider(url, beginPage, endPage):
"""
作用:负责组合处理贴吧每个页面的url
url : 贴吧url的前部分
beginPage : 起始页
endPage : 结束页
"""
for page in range(beginPage,endPage+1):
pn = (page - 1) * 50
fullurl = url + "&pn=" + str(pn) print("页面: ----------------- "+fullurl) loadPage(fullurl)
print("谢谢使用") if __name__ == '__main__':
kw = input("请输入需要爬取的贴吧名:")
beginPage = int(input("请输入起始页:"))
endPage = int(input("请输入结束页:"))
url = "http://tieba.baidu.com/f?"
key = urllib.parse.urlencode({"kw": kw})
fullurl = url + key print("fullurl: --------------- "+fullurl) tiebaSpider(fullurl, beginPage, endPage)
运行程序,输入你要爬取的贴吧名称和要爬取的页数,图片就可以下载到你的工作目录下了。
参考链接:
https://www.cnblogs.com/xinyangsdut/p/7616053.html
https://blog.csdn.net/moll_77/article/details/78581817 这是python 2 和Python3中url类库的区别
Python 爬虫练习: 爬取百度贴吧中的图片的更多相关文章
- python爬虫之爬取百度图片
##author:wuhao##爬取指定页码的图片,如果需要爬取某一类的所有图片,整体框架不变,但需要另作分析#import urllib.requestimport urllib.parseimpo ...
- Python学习 —— 爬虫入门 - 爬取Pixiv每日排行中的图片
更新于 2019-01-30 16:30:55 我另外写了一个面向 pixiv 的库:pixiver 支持通过作品 ID 获取相关信息.下载等,支持通过日期浏览各种排行榜(包括R-18),支持通过 p ...
- Python爬虫之爬取慕课网课程评分
BS是什么? BeautifulSoup是一个基于标签的文本解析工具.可以根据标签提取想要的内容,很适合处理html和xml这类语言文本.如果你希望了解更多关于BS的介绍和用法,请看Beautiful ...
- [Python爬虫] Selenium爬取新浪微博客户端用户信息、热点话题及评论 (上)
转载自:http://blog.csdn.net/eastmount/article/details/51231852 一. 文章介绍 源码下载地址:http://download.csdn.net/ ...
- from appium import webdriver 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium) - 北平吴彦祖 - 博客园 https://www.cnblogs.com/stevenshushu/p ...
- 第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息 crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多 ...
- Python爬虫之爬取站内所有图片
title date tags layut Python爬虫之爬取站内所有图片 2018-10-07 Python post 目标是 http://www.5442.com/meinv/ 如需在非li ...
- python爬虫实战---爬取大众点评评论
python爬虫实战—爬取大众点评评论(加密字体) 1.首先打开一个店铺找到评论 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经 ...
- Python爬虫之爬取淘女郎照片示例详解
这篇文章主要介绍了Python爬虫之爬取淘女郎照片示例详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧 本篇目标 抓取淘宝MM ...
随机推荐
- awk的总结
入门总结 Awk简介 awk不仅仅时linux系统中的一个命令,而且是一种编程语言,可以用来处理数据和生成报告.处理的数据可以是一个或多个文件,可以是来自标准输入,也可以通过管道获取标准输入,awk可 ...
- PHP面向对象(一)
1 面向对象介绍 1.1 介绍 面向对象是一个编思想. 编程思想有面向过程和面向对象. 面向过程: 编程思路集中的是过程上 面向对象: 编程思路集中在参与的对象 1.2 好处 多人合作方便 ...
- Git学习总结(4)——我的Git忽略文件
*.bak *.txt *.vm .gitignore #svn .svn/ # built application files *.apk *.ap_ # files for the dex VM ...
- servletConfig和ServletContext 以及servletContextListener介绍
<servlet> <servlet-name>BeerParamTests</servlet-name> <servlet-class> ...
- SharePoint 创建网站地图树视图及格式枚举截图
SharePoint 创建网站地图树视图及格式枚举截图 SharePoint首页隐藏掉左側导航以后,假设要以树视图呈现站点地图也非常easy. 仅仅须要复制v4.mas ...
- Android 利用TimerTask实现ImageView图片播放效果
在项目开发中,往往 要用到图片播放的效果.今天就用TimerTask和ImageView是实现简单的图片播放效果. 当中,TimerTask和Timer结合一起使用.主要是利用TimerTask的迭代 ...
- [SCOI 2008] 奖励关
[题目链接] https://www.lydsy.com/JudgeOnline/problem.php?id=1076 [算法] f[i][S]表示当前第i次抛出宝物,目前集合为S,所能获得的最高分 ...
- 【POJ 1082】 Calendar Game
[题目链接] http://poj.org/problem?id=1082 [算法] 对于每种状态,要么必胜,要么必败 记忆化搜索即可 [代码] #include <algorithm> ...
- maven的pom.xml配置标签
转自:https://blog.csdn.net/wf787283810/article/details/76188595 <project xmlns="http://maven.a ...
- 【刷题笔记】LeetCode 606. Construct String from Binary Tree
题意 给一棵二叉树,把它转化为字符串返回.转化字符串的要求如下: 1. null 直接转化为 () ;(这个要求其实有点误导人~) 2. 子节点用 () 包裹起来:(这是我自己根据例子添加的要求) ...