第2-3-8章 分片上传和分片合并的接口开发-文件存储服务系统-nginx/fastDFS/minio/阿里云oss/七牛云oss
5.10 接口开发-分片上传
第2-1-2章 传统方式安装FastDFS-附FastDFS常用命令
第2-1-3章 docker-compose安装FastDFS,实现文件存储服务
第2-1-5章 docker安装MinIO实现文件存储服务-springboot整合minio-minio全网最全的资料
5.10.1 分片上传介绍
前面我们已经实现了普通的附件服务和网盘服务,如果上传的文件比较小,可以直接使用这两个服务即可。如果上传的文件比较大,例如要上传一个500M或者1G的视频文件(或者更大),这就需要分片上传了。那么什么是分片上传呢?
分片上传就是把一个大文件进行分片,一片一片的上传到服务端,最后由服务端进行分片的合并。
要实现分片上传需要前端和后端配合来完成。在进行分片上传时,一般是由前端对要上传的大文件进行分片,然后分多次将这些分片上传到服务端,所有分片都上传到服务端后,在服务端将分片合并为原始的大文件。采用大文件分片并发上传,可以极大的提高文件的上传效率。
5.10.2 前端分片上传插件webuploader
WebUploader是由Baidu WebFE(FEX)团队开发的一个简单的以HTML5为主,FLASH为辅的现代文件上传组件。在现代的浏览器里面能充分发挥HTML5的优势,同时又不摒弃主流IE浏览器,沿用原来的FLASH运行时,兼容IE6+,iOS 6+, android 4+。
官网地址:http://fex.baidu.com/webuploader/
分片与并发结合,将一个大文件分割成多块,并发上传,极大地提高大文件的上传速度。
当网络问题导致传输错误时,只需要重传出错分片,而不是整个文件。另外分片传输能够更加实时的跟踪上传进度。
由于本文展示的主要为后端服务开发,所以前端部分不再开发,直接从资料中获得使用即可。
资料位置:文件服务\资料\分片上传\前端
直接打开index.html页面,选择要上传的大文件,可以看到发送了多次请求,每次请求会上传此大文件的一个分片:
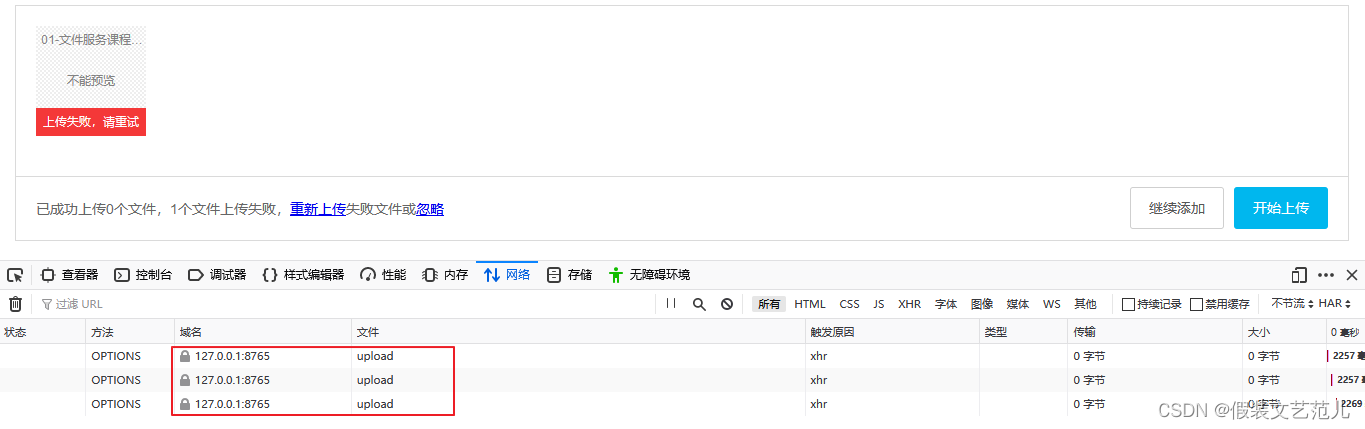
注:由于目前后端服务还没有开发,所以上传会失败。
5.10.3 后端代码实现
5.10.3.1 接口文档
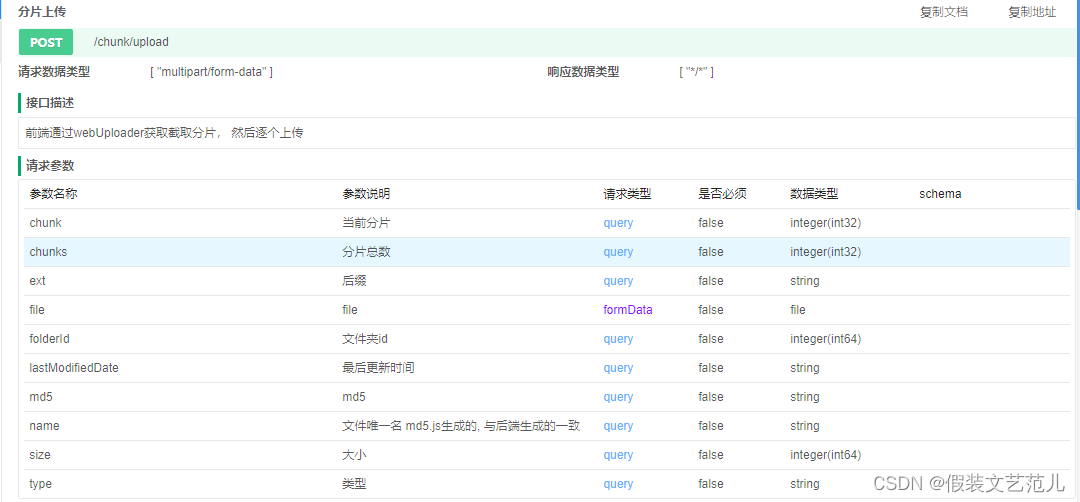

5.10.3.2 代码开发
第一步:创建FileChunkController并提供分片上传方法uploadFile
package com.itheima.pinda.file.controller;
import com.itheima.pinda.base.BaseController;
import com.itheima.pinda.base.R;
import com.itheima.pinda.dozer.DozerUtils;
import com.itheima.pinda.file.domain.FileAttrDO;
import com.itheima.pinda.file.dto.chunk.FileChunksMergeDTO;
import com.itheima.pinda.file.dto.chunk.FileUploadDTO;
import com.itheima.pinda.file.entity.File;
import com.itheima.pinda.file.manager.WebUploader;
import com.itheima.pinda.file.properties.FileServerProperties;
import com.itheima.pinda.file.service.FileService;
import com.itheima.pinda.file.strategy.FileChunkStrategy;
import com.itheima.pinda.file.strategy.FileStrategy;
import com.itheima.pinda.file.utils.FileDataTypeUtil;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.multipart.MultipartFile;
/**
* 分片上传
*/
@RestController
@Slf4j
@RequestMapping("/chunk")
@CrossOrigin
@Api(value = "分片上传", tags = "分片上传,需要webuploder.js插件进行配合使用")
public class FileChunkController extends BaseController {
@Autowired
private FileServerProperties fileProperties;
@Autowired
private FileService fileService;
@Autowired
private FileStrategy fileStrategy;
@Autowired
private WebUploader webUploader;
@Autowired
private DozerUtils dozerUtils;
/**
* 分片上传
* @param fileUploadDTO
* @param multipartFile
* @return
*/
@ApiOperation(value = "分片上传", notes = "分片上传")
@PostMapping(value = "/upload")
public R<FileChunksMergeDTO> uploadFile(FileUploadDTO fileUploadDTO,
@RequestParam(value = "file", required = false) MultipartFile multipartFile) throws Exception {
if (multipartFile == null || multipartFile.isEmpty()) {
log.error("分片上传分片为空");
return fail("分片上传分片为空");
}
// 存放分片文件的服务器绝对路径 ,例如 D:\\uploadfiles\\2020\\04
String uploadFolder = FileDataTypeUtil.getUploadPathPrefix(fileProperties.getStoragePath());
if (fileUploadDTO.getChunks() == null || fileUploadDTO.getChunks() <= 0) {
//没有分片,按照普通文件上传处理
File file = fileStrategy.upload(multipartFile);
file.setFileMd5(fileUploadDTO.getMd5());
fileService.save(file);
return success(null);
} else {
//为上传的文件准备好对应的位置
java.io.File targetFile = webUploader.getReadySpace(fileUploadDTO, uploadFolder);
if (targetFile == null) {
return fail("分片上传失败");
}
//保存上传文件
multipartFile.transferTo(targetFile);
//封装信息给前端,用于分片合并
FileChunksMergeDTO mergeDTO = new FileChunksMergeDTO();
mergeDTO.setSubmittedFileName(multipartFile.getOriginalFilename());
dozerUtils.map(fileUploadDTO,mergeDTO);
return success(mergeDTO);
}
}
}
第二步:在配置属性类中添加storagePath属性和对于的get、set方法
public String getStoragePath() {
return storagePath;
}
public void setStoragePath(String storagePath) {
this.storagePath = storagePath;
}
//指定分片上传时临时存放目录
private String storagePath ;
第三步:创建WebUploader分片上传工具类
package com.itheima.pinda.file.manager;
import com.itheima.pinda.file.dto.chunk.FileUploadDTO;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Service;
import java.io.IOException;
/**
* 分片上传工具类
*/
@Service
@Slf4j
public class WebUploader2 {
/**
* 为上传的文件创建对应的保存位置,若上传的是分片,则会创建对应的文件夹结构和tmp文件
*
* @param fileUploadDTO 上传文件的相关信息
* @param path 文件保存根路径
* @return
*/
public java.io.File getReadySpace(FileUploadDTO fileUploadDTO, String path) {
//创建上传文件所需的文件夹
if (!this.createFileFolder(path, false)) {
return null;
}
//将上传的分片保存在此目录中
String fileFolder = fileUploadDTO.getName();
if (fileFolder == null) {
return null;
}
//文件上传路径更新为指定文件信息签名后的临时文件夹,用于后期合并
path += "/" + fileFolder;
if (!this.createFileFolder(path, true)) {
return null;
}
//分片上传,指定当前分片文件的文件名
String newFileName = String.valueOf(fileUploadDTO.getChunk());
return new java.io.File(path, newFileName);
}
/**
* 创建存放分片上传的文件的文件夹
*
* @param file 文件夹路径
* @param hasTmp 是否有临时文件
* @return
*/
private boolean createFileFolder(String file, boolean hasTmp) {
//创建存放分片文件的临时文件夹
java.io.File tmpFile = new java.io.File(file);
if (!tmpFile.exists()) {
try {
tmpFile.mkdirs();
} catch (SecurityException ex) {
log.error("无法创建文件夹", ex);
return false;
}
}
if (hasTmp) {
//创建临时文件,用来记录上传分片文件的修改时间,用于清理长期未完成的垃圾分片
tmpFile = new java.io.File(file + ".tmp");
if (tmpFile.exists()) {
return tmpFile.setLastModified(System.currentTimeMillis());
} else {
try {
tmpFile.createNewFile();
} catch (IOException ex) {
log.error("无法创建tmp文件", ex);
return false;
}
}
}
return true;
}
}
第四步:修改Nacos配置中心的pd-file-server.yml文件,加入storagePath配置项
5.10.3.3 接口测试
第一步:启动Nacos配置中心
第二步:启动Nginx服务
第三步:启动文件服务
第四步:访问分片上传页面,进行大文件上传
可以看到,上传完成后,对应的分片上传所需目录、临时文件、分片文件都已经创建成功了:


5.11 接口开发-分片合并
前面我们已经完成了分片上传的接口,本小节需要完成的是将这些分片文件合并为原始文件并按照配置文件配置的存储策略保存到相应位置。由于不同的存储方式对应的分片合并方式也不同,所以我们需要提供不同的分片合并处理策略。具体接口设计如下:
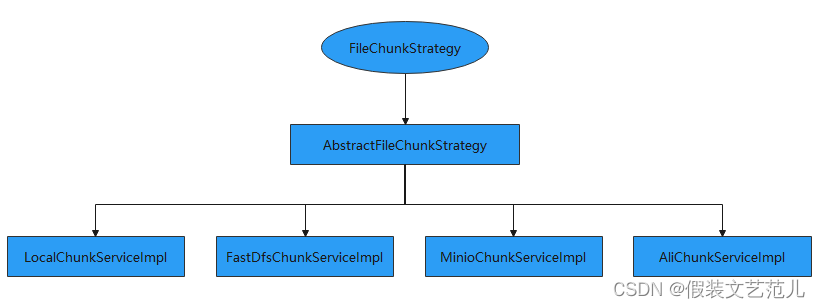
5.11.1 FileChunkStrategy
FileChunkStrategy是分片文件处理策略顶层接口,是对分片文件处理的顶层抽象,具体代码如下:
package com.itheima.pinda.file.strategy;
import com.itheima.pinda.base.R;
import com.itheima.pinda.file.dto.chunk.FileChunksMergeDTO;
import com.itheima.pinda.file.entity.File;
/**
* 文件分片处理策略接口
*/
public interface FileChunkStrategy {
/**
* 分片合并
*
* @param merge
* @return
*/
R<File> chunksMerge(FileChunksMergeDTO merge);
}
5.11.2 AbstractFileChunkStrategy
AbstractFileChunkStrategy是抽象分片策略处理类,实现了FileChunkStrategy接口。AbstractFileChunkStrategy实现主要的分片合并处理流程,例如:分片临时存储路径获取、分片数量的检查、合并后临时分片文件清理、合并后将文件信息保存到数据库等,但是真正分片合并的处理过程需要其子类来完成,因为不同的存储方案处理方式是不同的。
由于在进行分片合并处理过程中需要锁,在资料中(文件服务\资料\分片上传\后端)已经提供了工具类,直接导入项目使用即可。
AbstractFileChunkStrategy代码如下:
package com.itheima.pinda.file.strategy.impl;
import com.itheima.pinda.base.R;
import com.itheima.pinda.file.dto.chunk.FileChunksMergeDTO;
import com.itheima.pinda.file.entity.File;
import com.itheima.pinda.file.enumeration.IconType;
import com.itheima.pinda.file.properties.FileServerProperties;
import com.itheima.pinda.file.service.FileService;
import com.itheima.pinda.file.strategy.FileChunkStrategy;
import com.itheima.pinda.file.utils.FileLock;
import com.itheima.pinda.file.utils.FileDataTypeUtil;
import com.itheima.pinda.utils.DateUtils;
import com.itheima.pinda.utils.NumberHelper;
import com.itheima.pinda.utils.StrPool;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.io.FileUtils;
import org.springframework.beans.factory.annotation.Autowired;
import java.io.IOException;
import java.nio.file.Paths;
import java.time.LocalDateTime;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.locks.Lock;
/**
* 文件分片处理 抽象策略类
*/
@Slf4j
public abstract class AbstractFileChunkStrategy implements FileChunkStrategy {
@Autowired
protected FileService fileService;
@Autowired
protected FileServerProperties fileProperties;
protected FileServerProperties.Properties properties;
/**
* 分片合并
* @param info
* @return
*/
@Override
public R<File> chunksMerge(FileChunksMergeDTO info) {
// 570de89d476e6a5ba371f5fdd8d7920b.avi
String filename = new StringBuilder(info.getName()).append(StrPool.DOT).append(info.getExt()).toString();
//分片合并
R<File> result = chunksMerge(info, filename);
if (result.getIsSuccess() && result.getData() != null) {
//文件名
File filePo = result.getData();
LocalDateTime now = LocalDateTime.now();
filePo.setDataType(FileDataTypeUtil.getDataType(info.getContextType()))
.setCreateMonth(DateUtils.formatAsYearMonthEn(now))
.setCreateWeek(DateUtils.formatAsYearWeekEn(now))
.setCreateDay(DateUtils.formatAsDateEn(now))
.setSubmittedFileName(info.getSubmittedFileName())
.setIsDelete(false)
.setSize(info.getSize())
.setFileMd5(info.getMd5())
.setContextType(info.getContextType())
.setFilename(filename)
.setExt(info.getExt())
.setIcon(IconType.getIcon(info.getExt()).getIcon());
//将上传的文件信息保存到数据库
fileService.save(filePo);
return R.success(filePo);
}
return result;
}
/**
* 分片合并
* @param info
* @param fileName
* @return
*/
private R<File> chunksMerge(FileChunksMergeDTO info, String fileName) {
//获得分片文件存储的路径 D:\\chunks\\2020\\05
String path = FileDataTypeUtil.getUploadPathPrefix(fileProperties.getStoragePath());
int chunks = info.getChunks();
String folder = info.getName();
String md5 = info.getMd5();
int chunksNum = this.getChunksNum(Paths.get(path, folder).toString());
//检查是否满足合并条件:分片数量是否足够
if (chunks == chunksNum) {
//同步指定合并的对象
Lock lock = FileLock.getLock(folder);
try {
lock.lock();
//检查是否满足合并条件:分片数量是否足够
List<java.io.File> files = new ArrayList<>(Arrays.asList(this.getChunks(Paths.get(path, folder).toString())));
if (chunks == files.size()) {
//按照名称排序文件,这里分片都是按照数字命名的
//这里存放的文件名一定是数字
files.sort((f1, f2) -> NumberHelper.intValueOf0(f1.getName()) - NumberHelper.intValueOf0(f2.getName()));
R<File> result = merge(files, fileName, info);
//清理:文件夹,tmp文件
this.cleanSpace(folder, path);
return result;
}
} catch (Exception ex) {
log.error("数据分片合并失败", ex);
return R.fail("数据分片合并失败");
} finally {
//解锁
lock.unlock();
//清理锁对象
FileLock.removeLock(folder);
}
}
log.error("文件[签名:" + md5 + "]数据不完整,可能该文件正在合并中");
return R.fail("数据不完整,可能该文件正在合并中, 也有可能是上传过程中某些分片丢失");
}
/**
* 子类实现具体的合并操作
*
* @param files 分片文件
* @param fileName 唯一名 含后缀
* @param info 分片信息
* @return
* @throws IOException
*/
protected abstract R<File> merge(List<java.io.File> files, String fileName, FileChunksMergeDTO info) throws IOException;
/**
* 清理分片上传的相关数据
* 文件夹,tmp文件
*
* @param folder 文件夹名称
* @param path 上传文件根路径
* @return
*/
protected boolean cleanSpace(String folder, String path) {
//删除分片文件夹
java.io.File garbage = new java.io.File(Paths.get(path, folder).toString());
if (!FileUtils.deleteQuietly(garbage)) {
return false;
}
//删除tmp文件
garbage = new java.io.File(Paths.get(path, folder + ".tmp").toString());
if (!FileUtils.deleteQuietly(garbage)) {
return false;
}
return true;
}
/**
* 获取指定文件的分片数量
*
* @param folder 文件夹路径
* @return
*/
private int getChunksNum(String folder) {
java.io.File[] filesList = this.getChunks(folder);
return filesList.length;
}
/**
* 获取指定文件的所有分片
*
* @param folder 文件夹路径
* @return
*/
private java.io.File[] getChunks(String folder) {
java.io.File targetFolder = new java.io.File(folder);
return targetFolder.listFiles((file) -> {
if (file.isDirectory()) {
return false;
}
return true;
});
}
}
5.11.3 LocalChunkServiceImpl
LocalChunkServiceImpl是AbstractFileChunkStrategy的子类,负责处理存储策略为本地时的分片文件合并操作。为了使程序能够动态选择具体的策略处理类,故将LocalChunkServiceImpl定义在LocalAutoConfigure配置类中,具体代码如下:
/**
* 本地分片文件处理策略类
*/
@Service
public class LocalChunkServiceImpl extends AbstractFileChunkStrategy {
/**
*分片合并
* @param files 分片文件
* @param fileName 唯一名 含后缀
* @param info 分片信息
* @return
* @throws IOException
*/
@Override
protected R<File> merge(List<java.io.File> files, String fileName, FileChunksMergeDTO info) throws IOException {
properties = fileProperties.getLocal();
//日期目录
String relativePath = Paths.get(LocalDate.now().format(DateTimeFormatter.ofPattern(DateUtils.DEFAULT_MONTH_FORMAT_SLASH))).toString();
//合并后文件的存储路径 例如:D:\\uploadFiles\\oss-file-service\\2020\\05
String path = Paths.get(properties.getEndpoint(), properties.getBucketName(), relativePath).toString();
//上传文件存放目录,如果不存在则创建
java.io.File uploadFolder = new java.io.File(path);
if(!uploadFolder.exists()){
uploadFolder.mkdirs();
}
//创建合并后的文件
java.io.File outputFile = new java.io.File(Paths.get(path, fileName).toString());
if (!outputFile.exists()) {
boolean newFile = outputFile.createNewFile();
if (!newFile) {
return R.fail("创建文件失败");
}
try (FileChannel outChannel = new FileOutputStream(outputFile).getChannel()) {
//同步nio 方式对分片进行合并, 有效的避免文件过大导致内存溢出
for (java.io.File file : files) {
try (FileChannel inChannel = new FileInputStream(file).getChannel()) {
inChannel.transferTo(0, inChannel.size(), outChannel);
} catch (FileNotFoundException ex) {
log.error("文件转换失败", ex);
return R.fail("文件转换失败");
}
//删除分片
if (!file.delete()) {
log.error("分片[" + info.getName() + "=>" + file.getName() + "]删除失败");
}
}
} catch (FileNotFoundException e) {
log.error("文件输出失败", e);
return R.fail("文件输出失败");
}
} else {
log.warn("文件[{}], fileName={}已经存在", info.getName(), fileName);
}
String url = new StringBuilder(properties.getUriPrefix()).
append(bucketName).append(StrPool.SLASH).
append(relativePath).append(StrPool.SLASH).
append(fileName).toString();
File filePo = File.builder()
.relativePath(relativePath)
.url(StringUtils.replace(url, "\\", StrPool.SLASH))
.build();
return R.success(filePo);
}
}
5.11.4 FastDfsChunkServiceImpl
FastDfsChunkServiceImpl是AbstractFileChunkStrategy的子类,负责处理存储策略为FastDFS时的分片文件合并操作。为了使程序能够动态选择具体的策略处理类,故将FastDfsChunkServiceImpl定义在FastDfsAutoConfigure配置类中,具体代码如下:
/**
* FastDfs分片文件处理策略类
*/
@Service
public class FastDfsChunkServiceImpl extends AbstractFileChunkStrategy {
@Autowired
protected AppendFileStorageClient storageClient;
/**
* 分片合并
* @param files 分片文件
* @param fileName 唯一名 含后缀
* @param info 分片信息
* @return
* @throws IOException
*/
@Override
protected R<File> merge(List<java.io.File> files, String fileName, FileChunksMergeDTO info) throws IOException {
StorePath storePath = null;
for (int i = 0; i < files.size(); i++) {
java.io.File file = files.get(i);
FileInputStream in = FileUtils.openInputStream(file);
if (i == 0) {
storePath = storageClient.uploadAppenderFile(null, in,
file.length(), info.getExt());
} else {
storageClient.appendFile(storePath.getGroup(), storePath.getPath(),
in, file.length());
}
}
if (storePath == null) {
return R.fail("上传失败");
}
String url = new StringBuilder(fileProperties.getUriPrefix())
.append(storePath.getFullPath())
.toString();
File filePo = File.builder()
.url(url)
.group(storePath.getGroup())
.path(storePath.getPath())
.build();
return R.success(filePo);
}
}
5.11.5 AliChunkServiceImpl
AliChunkServiceImpl是AbstractFileChunkStrategy的子类,负责处理存储策略为阿里云OSS时的分片文件合并操作。为了使程序能够动态选择具体的策略处理类,故将AliChunkServiceImpl定义在AliOssAutoConfigure配置类中,具体代码如下:
/**
* 阿里云OSS分片文件处理策略类
*/
@Service
public class AliChunkServiceImpl extends AbstractFileChunkStrategy {
private OSS buildClient() {
properties = fileProperties.getAli();
return new OSSClientBuilder().build(properties.getEndpoint(), properties.getAccessKeyId(),
properties.getAccessKeySecret());
}
/**
* 分片合并
* @param files 分片文件
* @param fileName 唯一名 含后缀
* @param info 分片信息
* @return
* @throws IOException
*/
@Override
protected R<File> merge(List<java.io.File> files, String fileName, FileChunksMergeDTO info) throws IOException {
OSS client = buildClient();
String bucketName = properties.getBucketName();
//日期文件夹
String relativePath = LocalDate.now().format(DateTimeFormatter.ofPattern(DEFAULT_MONTH_FORMAT_SLASH));
// web服务器存放的相对路径
String relativeFileName = relativePath + StrPool.SLASH + fileName;
ObjectMetadata metadata = new ObjectMetadata();
metadata.setContentDisposition("attachment;fileName=" + info.getSubmittedFileName());
metadata.setContentType(info.getContextType());
//步骤1:初始化一个分片上传事件。
InitiateMultipartUploadRequest request = new InitiateMultipartUploadRequest(bucketName, relativeFileName, metadata);
InitiateMultipartUploadResult result = client.initiateMultipartUpload(request);
// 返回uploadId,它是分片上传事件的唯一标识,您可以根据这个ID来发起相关的操作,如取消分片上传、查询分片上传等。
String uploadId = result.getUploadId();
// partETags是PartETag的集合。PartETag由分片的ETag和分片号组成。
List<PartETag> partETags = new ArrayList<PartETag>();
for (int i = 0; i < files.size(); i++) {
java.io.File file = files.get(i);
FileInputStream in = FileUtils.openInputStream(file);
UploadPartRequest uploadPartRequest = new UploadPartRequest();
uploadPartRequest.setBucketName(bucketName);
uploadPartRequest.setKey(relativeFileName);
uploadPartRequest.setUploadId(uploadId);
uploadPartRequest.setInputStream(in);
// 设置分片大小。除了最后一个分片没有大小限制,其他的分片最小为100KB。
uploadPartRequest.setPartSize(file.length());
// 设置分片号。每一个上传的分片都有一个分片号,取值范围是1~10000,如果超出这个范围,OSS将返回InvalidArgument的错误码。
uploadPartRequest.setPartNumber(i + 1);
// 每个分片不需要按顺序上传,甚至可以在不同客户端上传,OSS会按照分片号排序组成完整的文件。
UploadPartResult uploadPartResult = client.uploadPart(uploadPartRequest);
// 每次上传分片之后,OSS的返回结果会包含一个PartETag。PartETag将被保存到partETags中。
partETags.add(uploadPartResult.getPartETag());
}
/* 步骤3:完成分片上传。 */
// 排序。partETags必须按分片号升序排列。
partETags.sort(Comparator.comparingInt(PartETag::getPartNumber));
// 在执行该操作时,需要提供所有有效的partETags。OSS收到提交的partETags后,会逐一验证每个分片的有效性。当所有的数据分片验证通过后,OSS将把这些分片组合成一个完整的文件。
CompleteMultipartUploadRequest completeMultipartUploadRequest =
new CompleteMultipartUploadRequest(bucketName, relativeFileName, uploadId, partETags);
CompleteMultipartUploadResult uploadResult = client.completeMultipartUpload(completeMultipartUploadRequest);
String url = new StringBuilder(properties.getUriPrefix())
.append(relativePath)
.append(StrPool.SLASH)
.append(fileName)
.toString();
File filePo = File.builder()
.relativePath(relativePath)
.group(uploadResult.getETag())
.path(uploadResult.getRequestId())
.url(StringUtils.replace(url, "\\", StrPool.SLASH))
.build();
// 关闭OSSClient。
client.shutdown();
return R.success(filePo);
}
}
5.11.6 MinioChunkServiceImpl
MinioChunkServiceImpl是AbstractFileChunkStrategy的子类,负责处理存储策略为MINIO时的分片文件合并操作。为了使程序能够动态选择具体的策略处理类,故将MinioChunkServiceImpll定义在MinioAutoConfigure配置类中,具体代码如下:
/**
* 分片文件策略处理类
*/
@Service
public class MinioChunkServiceImpl extends AbstractFileChunkStrategy {
/**
* 分片合并抽象方法,需要子类实现
*
* @param files
* @param fileName
* @param fileChunksMergeDTO
* @return
*/
@Override
protected R<File> merge(List<java.io.File> files, String fileName, FileChunksMergeDTO fileChunksMergeDTO) throws Exception {
MinioAutoConfigure.this.buildClient(fileServerProperties);
Vector<InputStream> streams = new Vector<>();
//分片合并成功,需要封装File对象相关属性
File fileResult = new File();
for (java.io.File file : files) {//file对应的就是分片文件
streams.add(new FileInputStream(file));
new FileInputStream(file).available();
//删除当前分片
file.delete();
}
//生成满足要求的objectName和url
String objectName = doReName(fileName, fileResult);
//sequenceInputStream直接使用只能获取第一个分片的数据,故先全部转成输出流再转成输入流
//存在问题:
//1.本身这个实现就不优雅
//2.OutOfMemoryError: Java heap space,测试同时传三个几百M的文件会发生内存溢出
//目前是分片文件上传到服务器,再程序里合并后再上传到minio,下面提供了很多minio的工具类,可以改成分片文件上传到minio,利用minioClient合并文件,目前未实现
try (SequenceInputStream sequenceInputStream = new SequenceInputStream(streams.elements());
ByteArrayOutputStream outputStream = new ByteArrayOutputStream()) {
byte[] bytes = new byte[sequenceInputStream.available()];
int len;
while ((len = sequenceInputStream.read(bytes)) != -1) {
outputStream.write(bytes, 0, len);
}
byte[] outBytes = outputStream.toByteArray();
ByteBuffer buffer = ByteBuffer.wrap(outBytes);
try (ByteArrayInputStream inputStream = new ByteArrayInputStream(buffer.array())) {
// 使用putObject上传一个文件到存储桶中
PutObjectArgs putObjectArgs = PutObjectArgs.builder()
.bucket(bucketName)
.object(objectName)
.contentType(fileChunksMergeDTO.getContextType())
.stream(inputStream, inputStream.available(), ObjectWriteArgs.MIN_MULTIPART_SIZE).build();
minioClient.putObject(putObjectArgs);
} catch (Exception ex) {
log.error("分片文件合并失败");
return R.fail("分片文件合并失败");
}
} catch (Exception ex) {
log.error("分片文件合并失败");
return R.fail("分片文件合并失败");
}
return R.success(fileResult);
}
}
5.11.7 分片合并接口
接口文档:
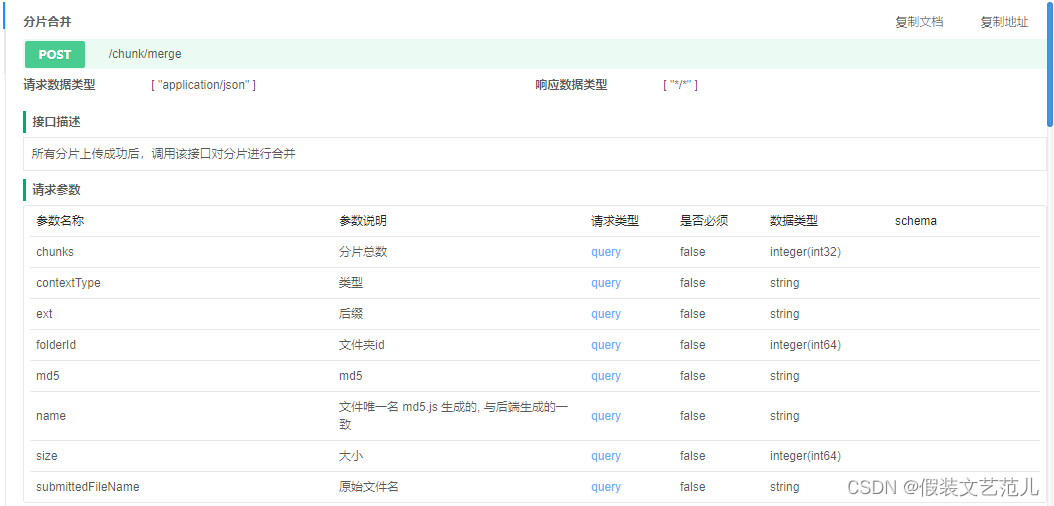
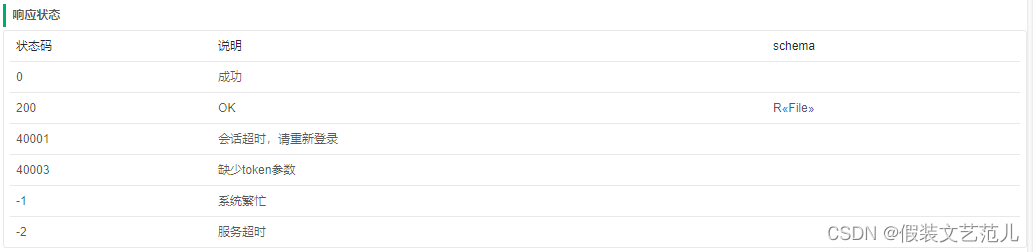
在FileChunkController中提供分片合并方法,直接调用分片处理策略类完成分片合并操作:
@Autowired
private FileChunkStrategy fileChunkStrategy;//分片文件处理策略
/**
* 分片合并
* @param info
* @return
*/
@ApiOperation(value = "分片合并", notes = "所有分片上传成功后,调用该接口对分片进行合并")
@PostMapping(value = "/merge")
public R<File> saveChunksMerge(FileChunksMergeDTO info) {
log.info("info={}", info);
return fileChunkStrategy.chunksMerge(info);
}
第2-1-2章 传统方式安装FastDFS-附FastDFS常用命令
第2-1-3章 docker-compose安装FastDFS,实现文件存储服务
第2-1-5章 docker安装MinIO实现文件存储服务-springboot整合minio-minio全网最全的资料
第2-3-8章 分片上传和分片合并的接口开发-文件存储服务系统-nginx/fastDFS/minio/阿里云oss/七牛云oss的更多相关文章
- 第2-3-1章 文件存储服务系统-nginx/fastDFS/minio/阿里云oss/七牛云oss
目录 文件存储服务 1. 需求背景 2. 核心功能 3. 存储策略 3.1 本地存储 3.2 FastDFS存储 3.3 云存储 3.4 minio 4. 技术设计 文件存储服务 全套代码及资料全部完 ...
- 视频分片上传+C#后端合并
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Vue2.0结合webuploader实现文件分片上传
Vue项目中遇到了大文件分片上传的问题,之前用过webuploader,索性就把Vue2.0与webuploader结合起来使用,封装了一个vue的上传组件,使用起来也比较舒爽. 上传就上传吧,为什么 ...
- ASP.NET CORE使用WebUploader对大文件分片上传,并通过ASP.NET CORE SignalR实时反馈后台处理进度给前端展示
本次,我们来实现一个单个大文件上传,并且把后台对上传文件的处理进度通过ASP.NET CORE SignalR反馈给前端展示,比如上传一个大的zip压缩包文件,后台进行解压缩,并且对压缩包中的文件进行 ...
- 用百度webuploader分片上传大文件
一般在做文件上传的时候,都是通过客户端把要上传的文件上传到服务器,此时上传的文件都在服务器内存,如果上传的是视频等大文件,那么服务器内存就很紧张,而且一般我们都是用flash或者html5做异步上传, ...
- iOS大文件分片上传和断点续传
总结一下大文件分片上传和断点续传的问题.因为文件过大(比如1G以上),必须要考虑上传过程网络中断的情况.http的网络请求中本身就已经具备了分片上传功能,当传输的文件比较大时,http协议自动会将文件 ...
- Node + js实现大文件分片上传基本原理及实践(一)
_ 阅读目录 一:什么是分片上传? 二:理解Blob对象中的slice方法对文件进行分割及其他知识点 三. 使用 spark-md5 生成 md5文件 四. 使用koa+js实现大文件分片上传实践 回 ...
- net core WebApi——文件分片上传与跨域请求处理
目录 前言 开始 测试 跨域 小结 @ 前言 在之前整理完一套简单的后台基础工程后,因为业务需要鼓捣了文件上传跟下载,整理完后就迫不及待的想分享出来,希望有用到文件相关操作的朋友可以得到些帮助. 开始 ...
- thinkphp+webuploader实现大文件分片上传
大文件分片上传,简单来说就是把大文件切分为小文件,然后再一个一个的上传,到最后由这些小文件再合并成原来的文件 webuploader下载地址及其文档:http://fex.baidu.com/webu ...
- js+php大文件分片上传
1 背景 用户本地有一份txt或者csv文件,无论是从业务数据库导出.还是其他途径获取,当需要使用蚂蚁的大数据分析工具进行数据加工.挖掘和共创应用的时候,首先要将本地文件上传至ODPS,普通的小文件通 ...
随机推荐
- 第一篇博客:HTML:background的使用
开篇 我是一名程序员小白,这是我写的第一篇博客,在学习的路上难免会遇到难以解决的问题,我将会在这里写下我遇到的问题并附上解决方法 希望可以对各位有所帮助!! 我们在html中经常会遇到这样的问题 例如 ...
- 《吐血整理》高级系列教程-吃透Fiddler抓包教程(21)-如何使用Fiddler生成Jmeter脚本-上篇
1.简介 通过跟随宏哥的脚步学习宏哥的Jmeter系列文章,.我们知道Jmeter本身可以录制脚本,也可以通过BadBoy,BlazeMeter等工具进行录制,其实Fiddler也可以录制Jmter脚 ...
- vscode常用快捷键及插件
macOS 全局 Command + Shift + P / F1 显示命令面板 Command + P 快速打开 Command + Shift + N 打开新窗口 Command + W 关闭窗口 ...
- 使用Metricbeat监控zookeeper遇到的问题
1.metricbeat中启动自动加载模块 metricbeat.config.modules: path: ${path.config}/modules.d/*.yml reload.enabled ...
- Logstash: 如何创建可维护和可重用的Logstash管道
- Beats:为 Beats => Logstash => Elasticsearch 架构创建 template 及 Dashboard
文章转载自:https://elasticstack.blog.csdn.net/article/details/115341977 前一段时间有一个开发者私信我说自己的 Beats 连接到 Logs ...
- 使用DBeaver Enterprise连接redis集群的一些操作记录
要点总结: 使用DBeaver Enterprise连接redis集群可以通过SQL语句查看key对应的value,但是没法查看key. 使用RedisDesktopManager连接redis集群可 ...
- 220722 T4 求和 /P4587 [FJOI2016]神秘数 (主席树)
好久没打主席树了,都忘了怎么用了...... 假设我们选了一些数能构成[0,x]范围内的所有值,下一个要加的数是k(k<=x+1),那么可以取到[0,x+k]内的所有取值,所以有一种做法: 对于 ...
- POJ3041 小行星 (二分图匹配模板)
学了这么久连模板都没有写过,我来补个坑...... 将行看成集合X,列看成Y,障碍看成是X到Y的一条边. 消除次数最少,等价于最小点覆盖问题,最小点覆盖=最大匹配数,跑一遍匈牙利就行了 #includ ...
- zabbix企业监控
第一节.系统初始化 1.前期环境 主机名 IP地址 操作系统 备注 zabbix-10 192.168.2.10 CentOS Linux release 7.4 zabbix服务端 agent-15 ...