thrift源码分析
1 前言
学习thrift源码主要为了弄清楚几个问题
- thrift客户端和服务端的通信流程是如何的
- thrift的IDL中给属性加上编号的作用是什么
- thrift中require、optional和默认字段到底是怎么处理的
- thrift的默认值是怎么处理的
这里我们只分析生成的java代码,使用thrift使用和源码分析中的demo
2 生成java代码
生成java代码可以有多种方式,假设IDL文件名是mythrift.thrift
- thrift --gen java mythrift.thrift
- thrift --gen java:beans mythrift.thrift
那么这两种有什么区别呢? 可以在命令行中直接输入thrift回车,就可以看到相关解释

可以看到除了beans的方式外,还有其他多种生成java的方式:
- 使用beans的方式后,属性会是private的,并且setter方法将返回void;
- 另外还有一种方式是private-members同样生成的属性是private的,但是setter方法返回的是this。
- 那么只使用java呢,则生成的属性是public的
这点我们可以从生成的源码去看下,是显而易见的
3 通信流程
3.1 客户端
DemoClient.java
public class DemoClient {
public static void main(String[] args) throws Exception{
// 创建Transport
TTransport transport = new TSocket("localhost", 9090, 5000);
//创建protocol
TProtocol protocol = new TBinaryProtocol(transport);
//创建客户端
MyService.Client client = new MyService.Client(protocol);
transport.open();
Stu stu = new Stu();
stu.setAge(23);
Teacher teacher = new Teacher("jack", "32");
client.printStu(stu, teacher);
transport.close();
}
}
3.1.1 TSocket
TSocket封装了Socket连接, 其继承关系如下
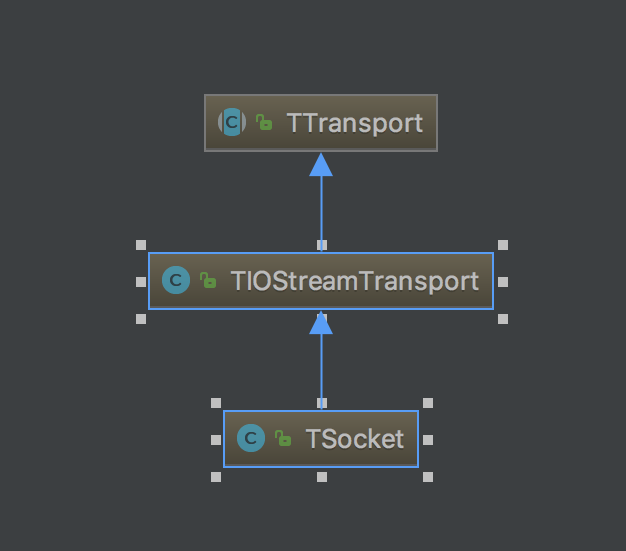
TSocket中包括java的socket,TIOStreamTransport中包括InputStream和OutputStream,其InputStream和OutputStream是由TSocket中的socket创建的。总结来说,TSocket封装了底层网络IO的方法
3.1.2 TProtocol
TProtocol是一个抽象类,而TBinaryProtocol是TProtocol的一种实现之一,用于二进制形式的序列化。TProtocol的实现类包括如下
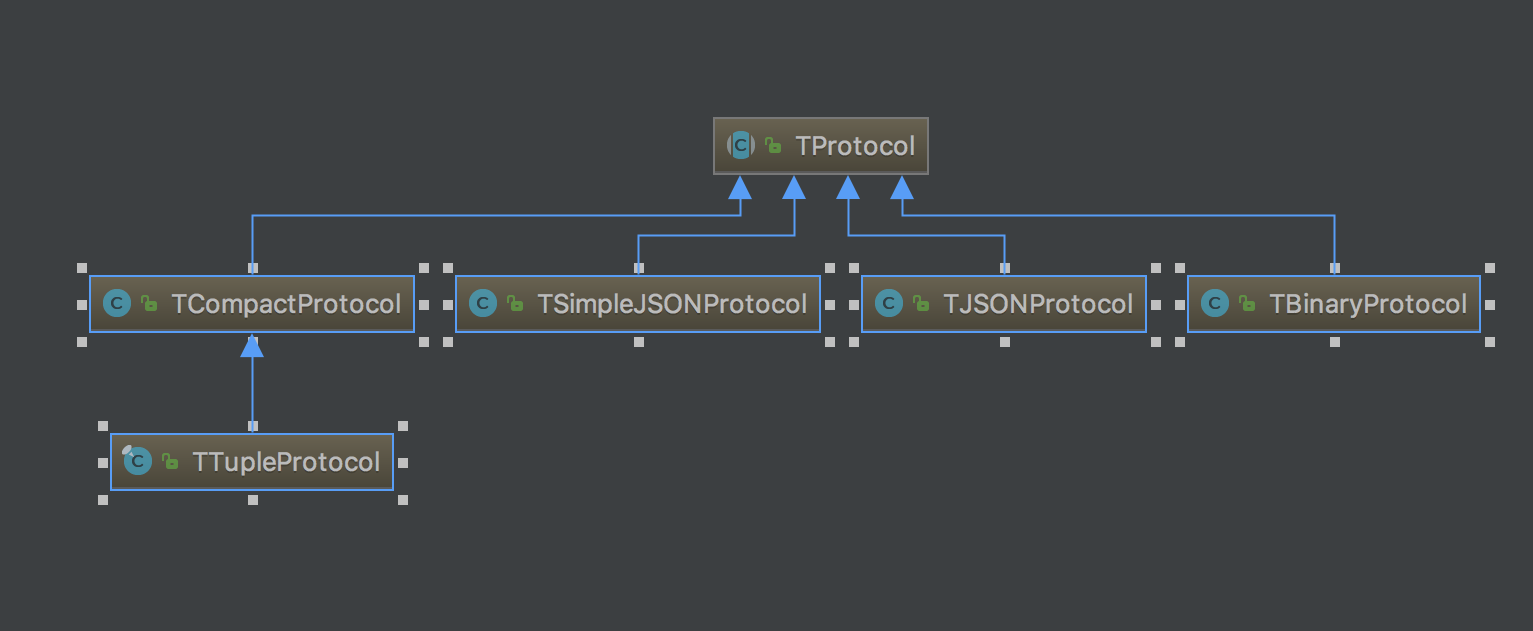
TProtocol中包含一个TSocket,使用TSocket来将数据经过编码后写入和读出到网络中。
TSocket和TProtocol都是我们引入的thrift依赖中引入的类
3.1.3 MyService
和TProtocol与TSocket不同,MyService是我们在IDL中定义的Server,然后使用thrift命令生成的java代码
MyService中包含了很多的内部类
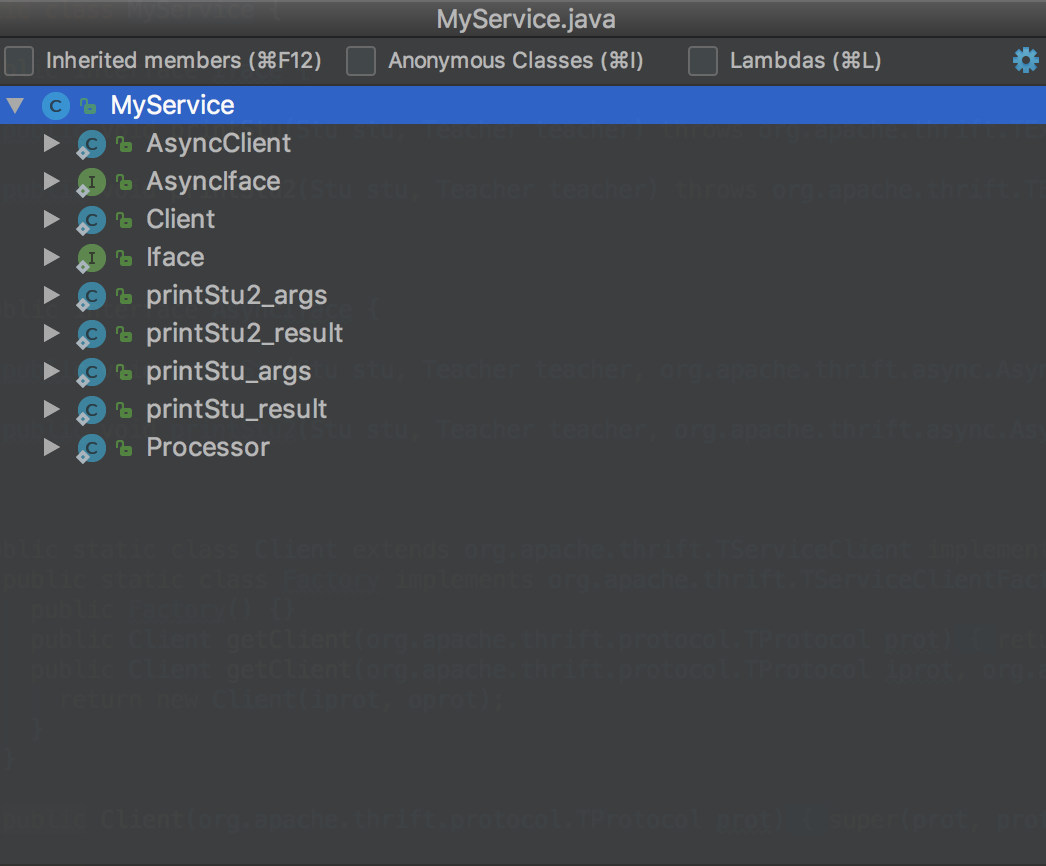
客户端使用的是MyService.Client。Client中有我们在IDL中定义的方法,当需要调用远程方法的时候,就可以直接调用,例如client.printStu。以客户端调用printStu为例介绍下客户端是如何序列化参数然后写到网络中的:
当客户端调用printStu的时候会调用send_printStu方法
public void send_printStu(Stu stu, Teacher teacher) throws org.apache.thrift.TException
{
printStu_args args = new printStu_args(); // 代表printStu的参数,重点关注
args.setStu(stu);
args.setTeacher(teacher);
sendBase("printStu", args); // 发送到网络
}
protected void sendBase(String methodName, TBase args) throws TException {
oprot_.writeMessageBegin(new TMessage(methodName, TMessageType.CALL, ++seqid_)); // seqid_从0开始
args.write(oprot_); // printStu_args的write方法来写方法的参数
oprot_.writeMessageEnd(); // TProtocol的方法
oprot_.getTransport().flush();
}
public void writeMessageBegin(TMessage message) throws TException {
if (strictWrite_) { // 将方法的名字、类型和id通过网络写到socket中,既然后id序列号了,为甚还要写名字?
int version = VERSION_1 | message.type;
writeI32(version);
writeString(message.name); //可见方法名字短点也能提高RPC性能
writeI32(message.seqid);
} else {
writeString(message.name);
writeByte(message.type);
writeI32(message.seqid);
}
}
使用writeMessageBegins将方法名字写到网络后,会使用MyService.printStu_args##write,将方法的参数写到网络中
3.1.4 MyService.printStu_args
printStu是我们在定义在IDL中的方法,生成的代码中会用printStu_args来表示该方法的参数,
printStu_args中定义了write和read方法用于将参数写到socket中
public void write(org.apache.thrift.protocol.TProtocol oprot) throws org.apache.thrift.TException {
schemes.get(oprot.getScheme()).getScheme().write(oprot, this);
}
其write方法又调用了printStu_argsStandardScheme#write,printStu_argsStandardScheme是定义在printStu_args中的内部类,用来真正的读写参数
3.1.5 printStu_argsStandardScheme
前面说了 printStu_argsStandardScheme是MyService.printStu_args的内部类,它只有两个方法:read和write,用于真正的读写printStu的参数,我们这里看下参数是怎么被写到网络中的
贴下部分IDL,方便比较
service MyService {
void printStu(1:Stu stu, 2:Teacher teacher) // 主要看这个
void printStu2(1:Stu stu, 2:Teacher teacher)
}
public void write(org.apache.thrift.protocol.TProtocol oprot, printStu_args struct) throws org.apache.thrift.TException {
struct.validate(); // printStu_args#validate进行校验,会校验参数是带require的,如果为null则抛出异常
oprot.writeStructBegin(STRUCT_DESC);
if (struct.stu != null) { // 不为null才发送
oprot.writeFieldBegin(STU_FIELD_DESC); // 写参数开头
struct.stu.write(oprot); // 参数的具体值
oprot.writeFieldEnd();
}
if (struct.teacher != null) {
oprot.writeFieldBegin(TEACHER_FIELD_DESC);
struct.teacher.write(oprot);
oprot.writeFieldEnd();
}
oprot.writeFieldStop();
oprot.writeStructEnd();
}
// oprot.writeFieldBegin 也就是TBinaryProtocol#writeFieldBegin
public void writeFieldBegin(TField field) throws TException {
writeByte(field.type); //只写了类型和id,没有写参数的名字
writeI16(field.id);
}
从writeFieldBegin我们可以看到,在序列化写方法参数的时候并没有用到参数的名字,而是只用了id,这也就是为什么IDL中参数要写上序号的原因。至此我们解决了开头的第2个问题
3.1.6 Stu#write 原生类型的写入
写完参数的类型和id后,会继续写参数的值,以Stu为例
struct Stu {
1:i32 name = 13
2:required i32 age
3:optional i32 height = 23
}
和printStu_args类似,Stu真正写的时候同样是调用了Stu的内部类StuStandardScheme进行写。StuStandardScheme也只有read和write方法
public void write(org.apache.thrift.protocol.TProtocol oprot, Stu struct) throws org.apache.thrift.TException {
struct.validate(); // 重点关注
oprot.writeStructBegin(STRUCT_DESC);
oprot.writeFieldBegin(NAME_FIELD_DESC); // 同样只写了id和类型
oprot.writeI32(struct.name);
oprot.writeFieldEnd();
oprot.writeFieldBegin(AGE_FIELD_DESC);
oprot.writeI32(struct.age);
oprot.writeFieldEnd();
if (struct.isSetHeight()) { // height是 optional,只有set了才能序列化
oprot.writeFieldBegin(HEIGHT_FIELD_DESC);
oprot.writeI32(struct.height);
oprot.writeFieldEnd();
}
oprot.writeFieldStop();
oprot.writeStructEnd();
}
// Stu#validate
public void validate() throws org.apache.thrift.TException {
// check for required fields
if (!isSetAge()) { // age是require,会进行校验,没有set就抛异常
throw new org.apache.thrift.protocol.TProtocolException("Required field 'age' is unset! Struct:" + toString());
}
}
//
public boolean isSetAge() { // 用一个BitSet来标记属性是否被set
return __isset_bit_vector.get(__AGE_ISSET_ID);
}
public void setAge(int age) {
this.age = age;
setAgeIsSet(true); // 只有在调用setter的方法的的时候才会将set标记
}
看下有默认值的是怎么回事,也就是开头的第4个问题
public Stu() {
this.name = 13; // default
this.height = 23; // optional, 并没有调用setter,因此即使写了默认值也不会被序列化
}
// 构造函数只有default和require类型
public Stu(
int name, // default
int age) // require
{
this();
this.name = name;
setNameIsSet(true);
this.age = age;
setAgeIsSet(true);
}
由以上我们可以总结下:
- 对于原生类型,因为其不会为null,所以对于require和默认类型,总会序列化,但是optional只有调用了setter方法才会对齐序列化
- validate只会检查require类型有没有调用setter,其他的不管
- optional的默认值并不会被序列化,而是读的时候只从默认值读
- 带参数的构造函数只有defalut和require类型
- 对应optional原生类型,如果没有调用setter是不会写入的,例如stu.height = 5,由于没有调用setter,传到另一端的还是0,所以我们生成代码的时候最好用beans模式,将属性置位private
3.1.7 Teacher#write 引用类型的写入
引用类型的写和原生类型存在差异
struct Teacher {
1:string name = "13"
2:required string age = "14"
3:optional string height = "15"
}
public void write(org.apache.thrift.protocol.TProtocol oprot, Teacher struct) throws org.apache.thrift.TException {
struct.validate(); // 检查参数
oprot.writeStructBegin(STRUCT_DESC);
if (struct.name != null) { // 只要不是null就写入,因为有校验,所以require肯定不会为null
oprot.writeFieldBegin(NAME_FIELD_DESC);
oprot.writeString(struct.name);
oprot.writeFieldEnd();
}
if (struct.age != null) { // 和原生类型不同,default不一定会被序列化
oprot.writeFieldBegin(AGE_FIELD_DESC);
oprot.writeString(struct.age);
oprot.writeFieldEnd();
}
if (struct.height != null) {
if (struct.isSetHeight()) {
oprot.writeFieldBegin(HEIGHT_FIELD_DESC);
oprot.writeString(struct.height);
oprot.writeFieldEnd();
}
}
oprot.writeFieldStop();
oprot.writeStructEnd();
}
}
public void validate() throws org.apache.thrift.TException {
// check for required fields
if (!isSetAge()) { // 只校验require参数,这点和原生类型相同
throw new org.apache.thrift.protocol.TProtocolException("Required field 'age' is unset! Struct:" + toString());
}
}
// 和原生类型不同,判断是否set只是根据参数是否为null
public boolean isSetAge() {
return this.age != null;
}
由以上我们可以总结下:
- 对于引用类型, 为null就不会序列化,但是由于require类型为null会在validate抛出异常,所以肯定是会被序列化的。
- 对于引用类型,无论是直接对属性赋值还是调用setter方法,都会对其序列化
3.2 服务端
服务端和客户端其实类似,主要注意以下一点
3.2.1 MyService.Processor
MyService.Processor接收一个继承自Iface的参数,也就是我们的实现类MyServiceImpl。在MyService.Processor中有个方法,会将每个方法对应的处理方法存在在一个map中:
private static <I extends Iface> Map<String, org.apache.thrift.ProcessFunction<I, ? extends org.apache.thrift.TBase>> getProcessMap(Map<String, org.apache.thrift.ProcessFunction<I, ? extends org.apache.thrift.TBase>> processMap) {
processMap.put("printStu", new printStu());
processMap.put("printStu2", new printStu2());
return processMap;
}
4 总结
- require、optional和default的序列化方式是和原生类型还是引用类型有关系的
- 无论原生类型还是引用类型,require的参数必须设置,但是原先类型是检查isXXSet,引用类型只检查是否为null
- 有参数的构造函数的参数只有require和defalut类型,没有optional类型
- 原生类型设置了默认值,但是没有setXXIsSet,是不会被序列化的,但是因为读的时候也是读默认值,所以不会出错
- 原生类型直接对public属性设值,是不会被序列化的,最好是调用setter,所以生成代码的时候最好也是用java:beans的方式
- require是一定会被序列化的,因为有检查,不设置会抛异常
- defalut没有检查,原生类型一定被序列化,引用类型不一定会被序列化(null的时候不序列化)
- optional没有检查,不设置一定不会被序列化,但是设置了也不一定会序列化,比如直接对public属性复制stu.height = 10,没有调用setter是不会被序列化的
- thrift这块还是比较乱的~~
thrift源码分析的更多相关文章
- golang thrift 源码分析,服务器和客户端究竟是如何工作的
首先编写thrift文件(rpcserver.thrift),运行thrift --gen go rpcserver.thrift,生成代码 namespace go rpc service RpcS ...
- Thrift源码分析(一)-- 基本概念
我所在的公司使用Thrift作为基础通信组件,相当一部分的RPC服务基于Thrift框架.公司的日UV在千万级别,Thrift很好地支持了高并发访问,并且Thrift相对简单地编程模型也提高了服务地开 ...
- Thrift源码分析(二)-- 协议和编解码
协议和编解码是一个网络应用程序的核心问题之一,客户端和服务器通过约定的协议来传输消息(数据),通过特定的格式来编解码字节流,并转化成业务消息,提供给上层框架调用. Thrift的协议比较简单,它把协议 ...
- worker启动executor源码分析-executor.clj
在"supervisor启动worker源码分析-worker.clj"一文中,我们详细讲解了worker是如何初始化的.主要通过调用mk-worker函数实现的.在启动worke ...
- dubbo源码分析一:整体分析
本文作为dubbo源码分析的第一章,先从总体上来分析一下dubbo的代码架构.功能及优缺点,注意,本文只分析说明开源版本提供的代码及功能. 1.dubbo的代码架构: spring适配层:常规的sp ...
- Nimbus<二>storm启动nimbus源码分析-nimbus.clj
nimbus是storm集群的"控制器",是storm集群的重要组成部分.我们可以通用执行bin/storm nimbus >/dev/null 2>&1 &a ...
- JStorm与Storm源码分析(一)--nimbus-data
Nimbus里定义了一些共享数据结构,比如nimbus-data. nimbus-data结构里定义了很多公用的数据,请看下面代码: (defn nimbus-data [conf inimbus] ...
- SparkThriftServer 源码分析
目录 版本 起点 客户端--Beeline 服务端 Hive-jdbc TCLIService.Iface客户端请求 流程 SparkThrift 主函数HiveThriftServer2 Thrif ...
- Thrift源码学习二——Server层
Thrift 提供了如图五种模式:TSimpleServer.TNonblockingServer.THsHaServer.TThreadPoolServer.TThreadSelectorServe ...
随机推荐
- jmeter非gui之shell脚本
非gui运行脚本,如果目录非空,会报不能写的错 可以通过shell脚本来处理: #!/bin/bash filename=`date +'%Y%m%d%H%M%S'` if [ -d /root/te ...
- 渗透利器burp suite新版本v2020.9.1及v2020.8汉化版下载
Burp suite是一款抓包渗透必备软件.burp Suite是响当当的web应用程序渗透测试集成平台.从应用程序攻击表面的最初映射和分析,到寻找和利用安全漏洞等过程,所有工具为支持整体测试程序而无 ...
- ASPack壳脱壳实验
实验目的 1.学会使用相关软件工具,手动脱ASPack壳. 2.不要用PEiD查入口,单步跟踪,提高手动找入口能力. 实验内容 手动对文件"ASPack 2.12 - Alexey Solo ...
- BI报表系统该如何集成到其他系统呢?
近期小麦我经常收到很多用户的反馈,想知道Smartbi的报表能不能从微信/钉钉之类的直接跳转到已做好的报表页面?他们都希望通过这种方式尽可能地避免由于各个管理软件账号密码不同而造成的不便,能够在日常工 ...
- 谁说EXCEL不能处理大数据?那是你用错了工具
我是一名数据分析师,每天需要和各种各样的数据和表格打交道,是一名名副其实的"表哥",不仅需要制作和更新公司里的日报.周报和月报,有时候也要为公司的会议准备各种数据材料.由于公司的业 ...
- 安装好的pycharm修改代码存储路径
安装好pycharm的时候,第一次点开pycharm没有配置好,导致代码存放的路径是默认的.但是现在想把路径改成自己的路径怎么办? 首先,pycharm->file->settings-& ...
- 1.分类维护-通过Java8 Stream API 获取商品三级分类数据
实体类 @Data @TableName("pms_category") public class CategoryEntity implements Serializable { ...
- omnet++:官方文档翻译总结(四)
学习翻译自:Adding Statistics Collection - OMNeT++ Technical Articles Part 5 - Adding Statistics Collectio ...
- Linux CentOS7.X- 添加用户
1.创建用户 useradd username 其中,username是要创建用户的用户名(root使用): 2.设置密码 passwd username 其中,username是指定要修改密码的用户 ...
- IntelliJ IDEA 中打包时报aspose-cells错误缺失
异常情况 在本地执行word转换为pdf是没有问题,但是在maven中提示错误: 解决方案 将com\aspose\aspose-cells\9.0.0下除了[aspose-cells-9.0.0.j ...