docker搭建Elasticsearch、Kibana、Logstash 同步mysql数据到ES
一、前言
在数据量大的企业级实践中,Elasticsearch显得非常常见,特别是数据表超过千万级后,无论怎么优化,还是有点力不从心!使用中,最首先的问题就是怎么把千万级数据同步到Elasticsearch中,在一些开源框架中知道了,有专门进行同步的!那就是Logstash 。在思考,同步完怎么查看呢,这时Kibana映入眼帘,可视化的界面,让使用更加的得心应手哈!!这就是三剑客ELK。不过大多时候都是进行日志采集的,小编没有用,只是用来解决一个表的数据量大,查询慢的!后面小编在专门搭建日志采集的ELK。
二、三者介绍
1. Elasticsearch
Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。作为 Elastic Stack 的核心,Elasticsearch 会集中存储您的数据,让您飞快完成搜索,微调相关性,进行强大的分析,并轻松缩放规模。
2. Kibana
Kibana 是一个免费且开放的用户界面,能够让您对 Elasticsearch 数据进行可视化,并让您在 Elastic Stack 中进行导航。您可以进行各种操作,从跟踪查询负载,到理解请求如何流经您的整个应用,都能轻松完成。
3. Logstash
Logstash 是免费且开放的服务器端数据处理管道,能够从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的“存储库”中。
三、版本选择
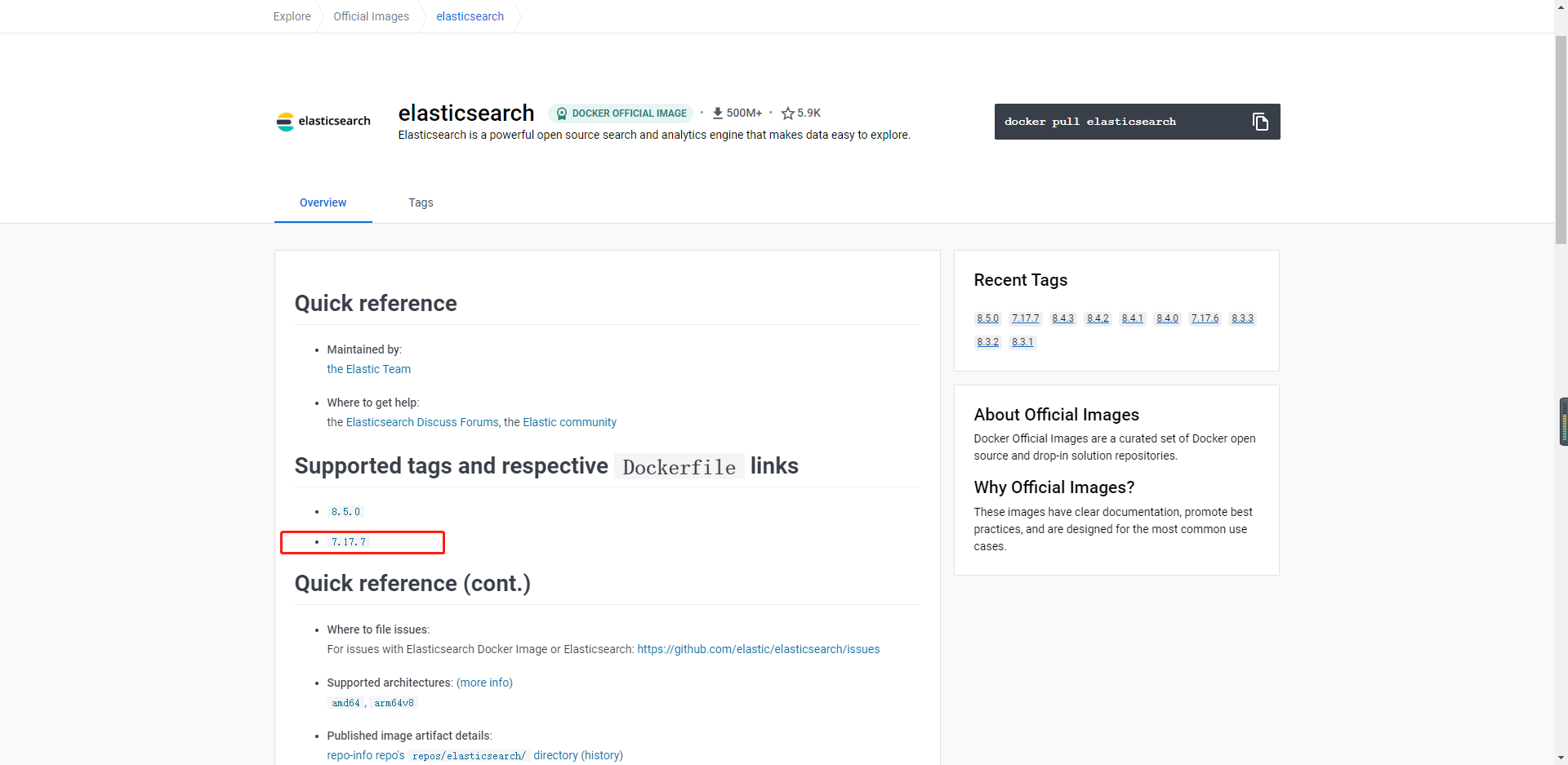
现在最新版就是8.5,最新的教程少和问题未知,小编选择7版本的,求一手稳定哈!
于是去hub.docker查看了一下,经常用的版本,最终确定为:7.17.7
官方规定:
安装 Elastic Stack 时,您必须在整个堆栈中使用相同的版本。例如,如果您使用的是 Elasticsearch 7.17.7,则安装 Beats 7.17.7、APM Server 7.17.7、Elasticsearch Hadoop 7.17.7、Kibana 7.17.7 和 Logstash 7.17.7
四、搭建mysql
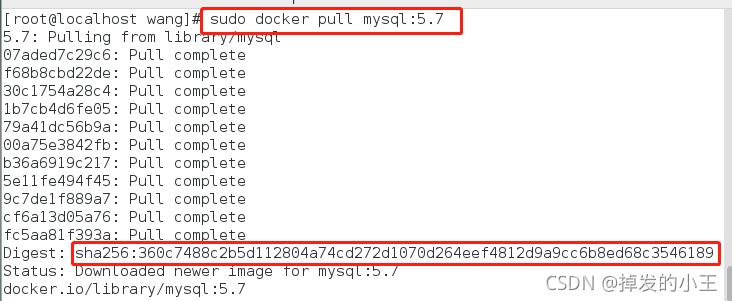
1. 拉去MySQL镜像
sudo docker pull mysql:5.7
)
2. Docker启动MySQL
sudo docker run -p 3306:3306 --name mysql \
-v /mydata/mysql/log:/var/log/mysql \
-v /mydata/mysql/data:/var/lib/mysql \
-v /mydata/mysql/conf:/etc/mysql \
-e MYSQL_ROOT_PASSWORD=root \
-d mysql:5.7
####这里往下是解释,不需要粘贴到linux上#############
--name 指定容器名字
-v 将对应文件挂载到linux主机上
-e 初始化密码
-p 容器端口映射到主机的端口(把容器的3306映射到linux中3306,这样windows上就可以访问这个数据库)
-d 后台运行

3. Docker配置MySQL
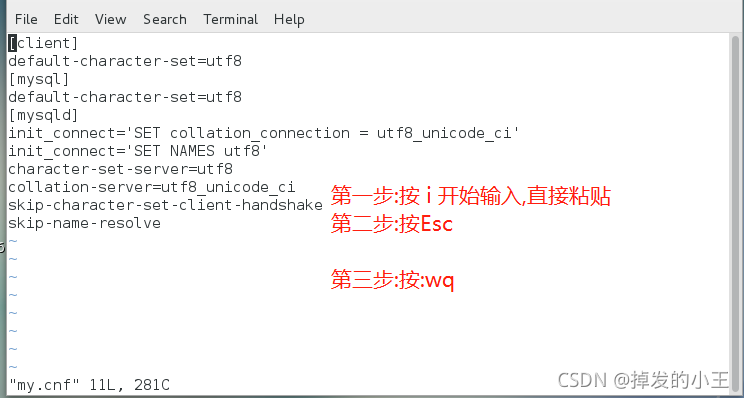
vim /mydata/mysql/conf/my.cnf # 创建并进入编辑
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
[mysqld]
init_connect='SET collation_connection = utf8_unicode_ci'
init_connect='SET NAMES utf8'
character-set-server=utf8
collation-server=utf8_unicode_ci
skip-character-set-client-handshake
skip-name-resolve
4. Docker重启MySQL使配置生效
docker restart mysql
5. 新增数据库

6. 新建测试表
DROP TABLE IF EXISTS `sys_log`;
CREATE TABLE `sys_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '日志主键',
`title` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT '' COMMENT '模块标题',
`business_type` int(2) NULL DEFAULT 0 COMMENT '业务类型(0其它 1新增 2修改 3删除)',
`method` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT '' COMMENT '方法名称',
`request_method` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT '' COMMENT '请求方式',
`oper_name` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT '' COMMENT '操作人员',
`oper_url` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT '' COMMENT '请求URL',
`oper_ip` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT '' COMMENT '主机地址',
`oper_time` datetime(0) NULL DEFAULT NULL COMMENT '操作时间',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1585197503834284034 CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '操作日志记录' ROW_FORMAT = Dynamic;
SET FOREIGN_KEY_CHECKS = 1;
五、ELK搭建准备
1. 创建挂载的文件
es挂载:
mkdir -p /mydata/elk/elasticsearch/{config,plugins,data,logs}
kibana挂载:
mkdir -p /mydata/elk/kibana/config
logstash挂载:
mkdir -p /mydata/elk/logstash/config
2. ES挂载具体配置
vim /mydata/elk/elasticsearch/config/elasticsearch.yml
输入下面命令:
http.host: 0.0.0.0
xpack.security.enabled: false
http.host:任何地址都可以访问。
xpack.security.enabled:关闭密码认证
3. Kibana挂载具体配置
vim /mydata/elk/kibana/config/kibana.yml
内容:
server.host: 0.0.0.0
elasticsearch.hosts: [ "http://192.168.239.131:9200" ]
elasticsearch.hosts:指向es地址
4. Logstash挂载具体配置
vim /mydata/elk/logstash/config/logstash.yml
内容:
http.host: 0.0.0.0
xpack.monitoring.elasticsearch.hosts: [ "http://192.168.239.131:9200" ]
记录存放:
touch log
chmod 777 log
vim /mydata/elk/logstash/config/logstash.conf
内容:
jdbc_driver_library:指定必须要自己下载mysql-connector-java-8.0.28.jar,版本自己决定,下载地址;
statement:如果sql长,可以指定sql文件,直接指定文件所在位置,这里的位置都为容器内部的地址;
last_run_metadata_path:上次记录存放文件对应上方的log。
input {
stdin {
}
jdbc {
jdbc_connection_string => "jdbc:mysql://192.168.239.131:3306/test?useUnicode=true&characterEncoding=utf8&serverTimezone=UTC"
jdbc_user => "root"
jdbc_password => "root"
jdbc_driver_library => "/usr/share/logstash/config/mysql-connector-java-8.0.28.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_paging_enabled => "true"
jdbc_page_size => "300000"
statement => "SELECT id, title, business_type, method, request_method, oper_name, oper_url, oper_ip, oper_time FROM sys_log"
schedule => "*/1 * * * *"
use_column_value => false
tracking_column_type => "timestamp"
tracking_column => "oper_time"
record_last_run => true
jdbc_default_timezone => "Asia/Shanghai"
last_run_metadata_path => "/usr/share/logstash/config/log"
}
}
output {
elasticsearch {
hosts => ["192.168.239.131:9200"]
index => "sys_log"
document_id => "%{id}"
}
stdout {
codec => json_lines
}
}
流水线指定上面的配置文件:
vim /mydata/elk/logstash/config/pipelines.yml
内容:
- pipeline.id: sys_log
path.config: "/usr/share/logstash/config/logstash.conf"
最终/mydata/elk/logstash/config/下的文件

防止保存没有修改权限,可以把上面建的文件夹和文件赋予修改权限:
chmod 777 文件名称
五、运行容器
0. docker compose一键搭建
在elk目录创建:
vim docker-compose.yml
内容如下:
version: '3'
services:
elasticsearch:
image: elasticsearch:7.17.7
container_name: elasticsearch
ports:
- "9200:9200"
- "9300:9300"
environment:
- cluster.name=elasticsearch
- discovery.type=single-node
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
- /mydata/elk/elasticsearch/plugins:/usr/share/elasticsearch/plugins
- /mydata/elk/elasticsearch/data:/usr/share/elasticsearch/data
- /mydata/elk/elasticsearch/logs:/usr/share/elasticsearch/logs
kibana:
image: kibana:7.17.7
container_name: kibana
ports:
- "5601:5601"
depends_on:
- elasticsearch
environment:
I18N_LOCALE: zh-CN
volumes:
- /mydata/elk/kibana/config/kibana.yml:/usr/share/kibana/config/kibana.yml
logstash:
image: logstash:7.17.7
container_name: logstash
ports:
- "5044:5044"
volumes:
- /mydata/elk/logstash/config:/usr/share/logstash/config
depends_on:
- elasticsearch
一定要在docker-compose.yml所在目录执行命令!!
运行:
docker compose up -d
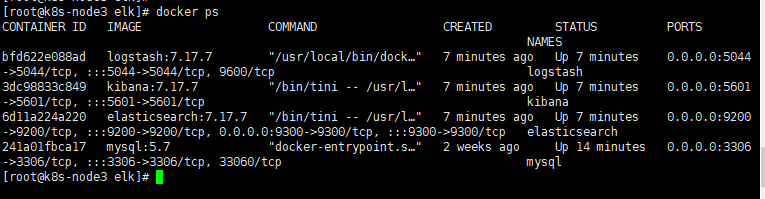
完成后可以跳到5进行查看kibana!!
1. 运行ES
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -e ES_JAVA_OPTS="-Xms64m -Xmx512m" -v /mydata/elk/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml -v /mydata/elk/elasticsearch/data:/usr/share/elasticsearch/data -v /mydata/elk/elasticsearch/plugins:/usr/share/elasticsearch/plugins -d elasticsearch:7.17.7

2. 运行Kibana
docker run --name kibana -e ELASTICSEARCH_HOSTS=http://192.168.239.131:9200 -p 5601:5601 -d kibana:7.17.7

3. 运行Logstash
docker run -d -p 5044:5044 -v /mydata/elk/logstash/config:/usr/share/logstash/config --name logstash logstash:7.17.7

4. 容器完结图
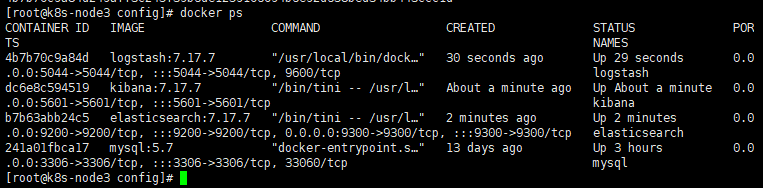
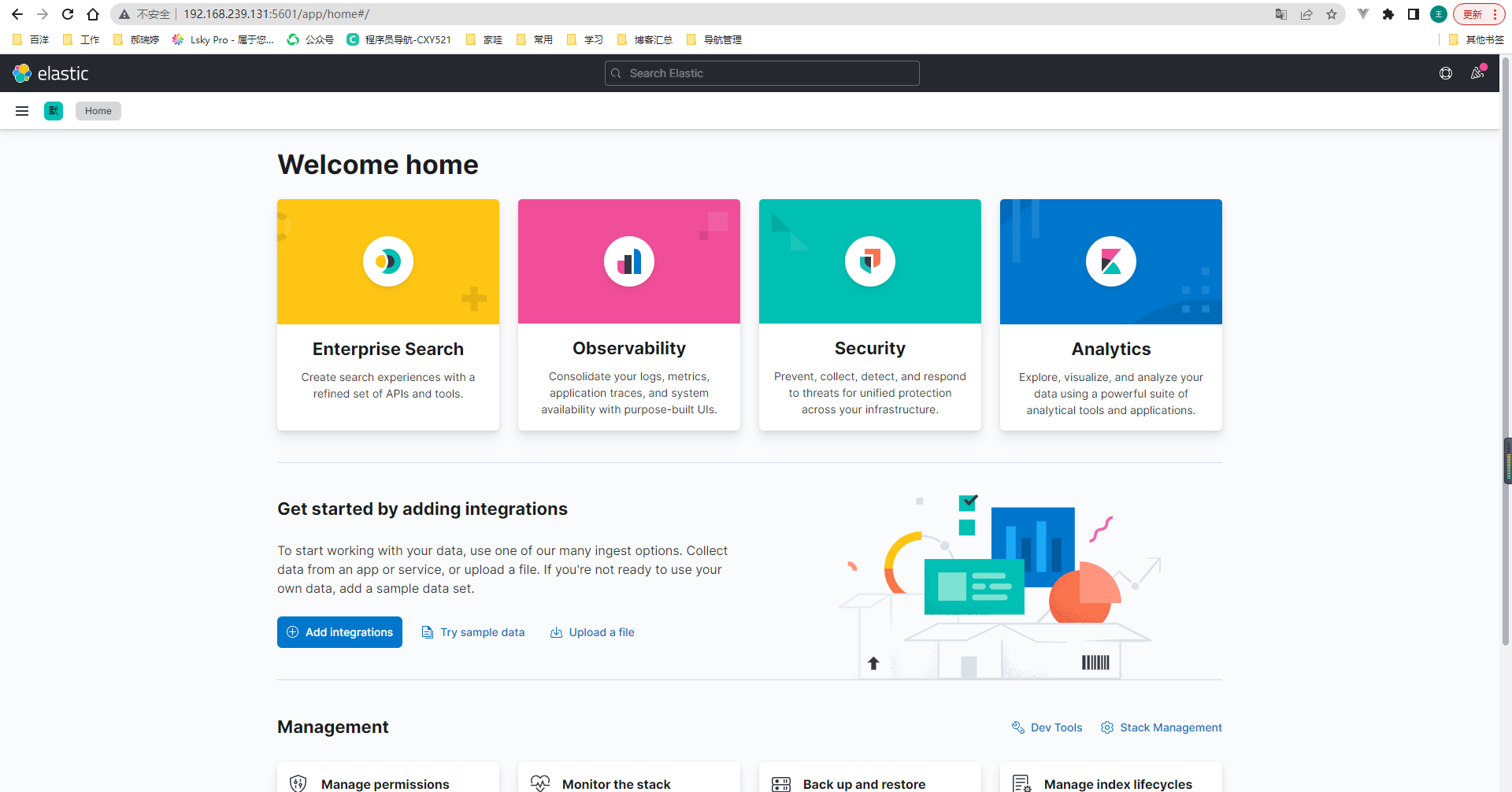
5. 访问Kibana
http://192.168.239.131:5601/app/home#/
六、新建索引
PUT /sys_log
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0,
"index": {
"max_result_window": 100000000
}
},
"mappings": {
"dynamic": "strict",
"properties": {
"@timestamp": {
"type": "date"
},
"@version": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"business_type": {
"type": "integer"
},
"title": {
"type": "text"
},
"method": {
"type": "text"
},
"request_method": {
"type": "text"
},
"oper_name": {
"type": "text"
},
"oper_url": {
"type": "text"
},
"oper_ip": {
"type": "text"
},
"oper_time": {
"type": "date"
},
"id": {
"type": "long"
}
}
}
}
七、测试
新增几条记录,然后查看Logstash日志
docker logs -f logstash
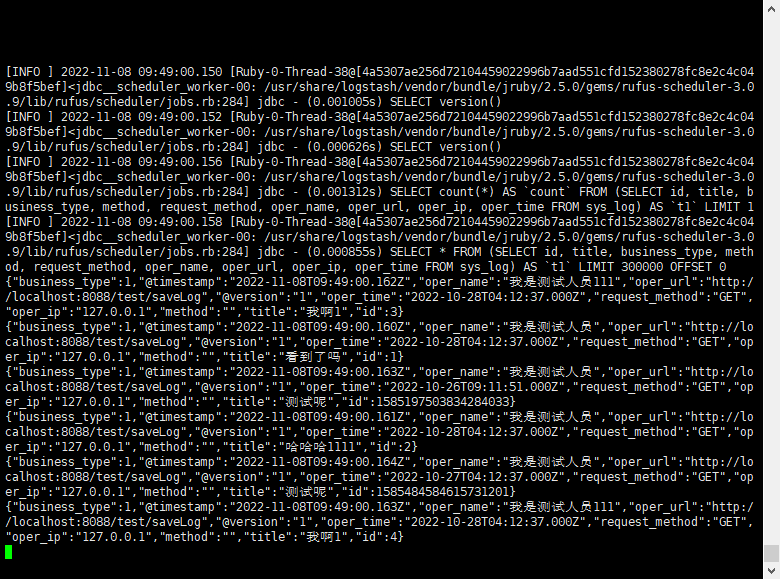
我们去kibana看一下是否已存在:
输入命令:
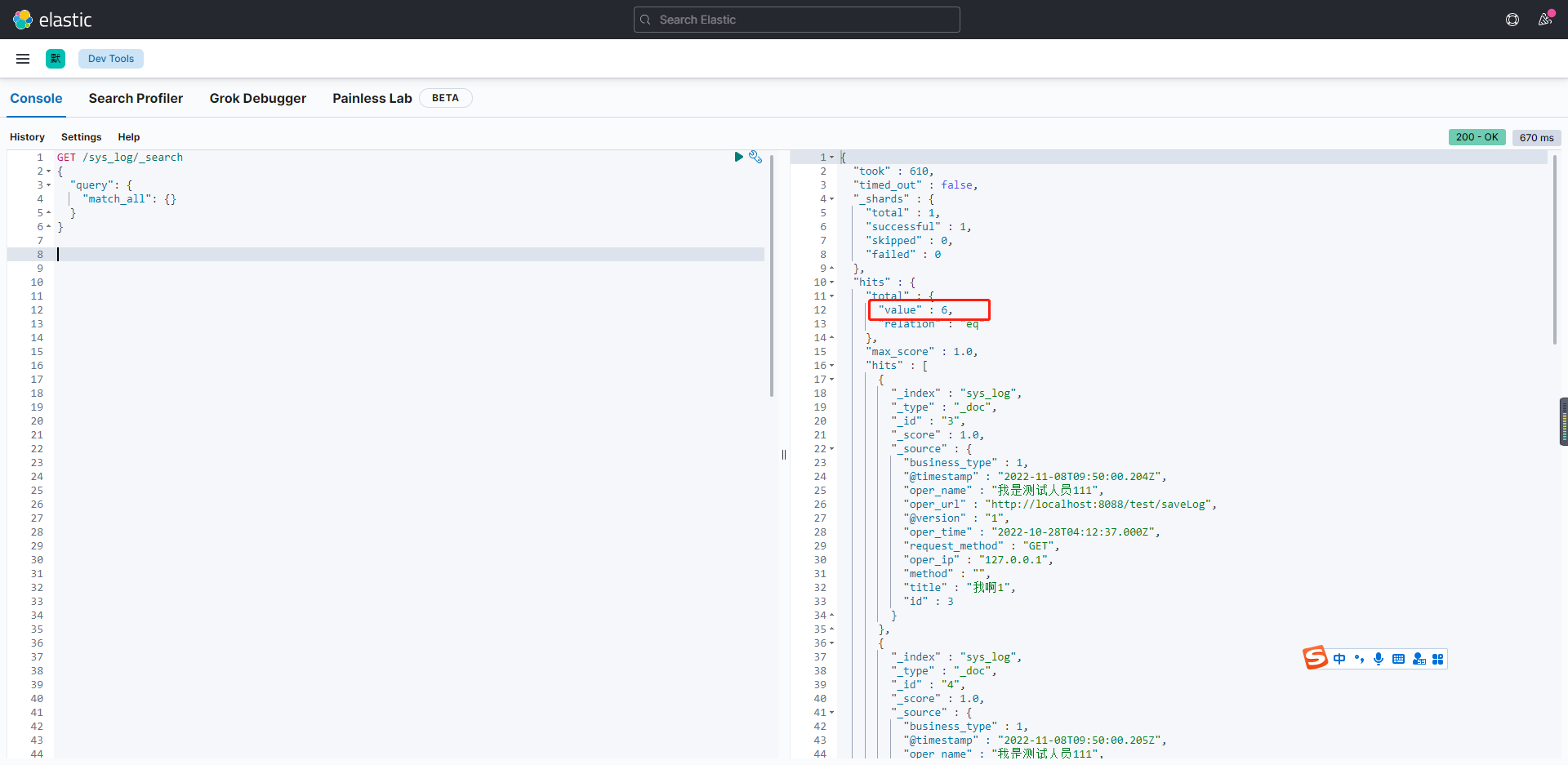
GET /sys_log/_search
{
"query": {
"match_all": {}
}
}
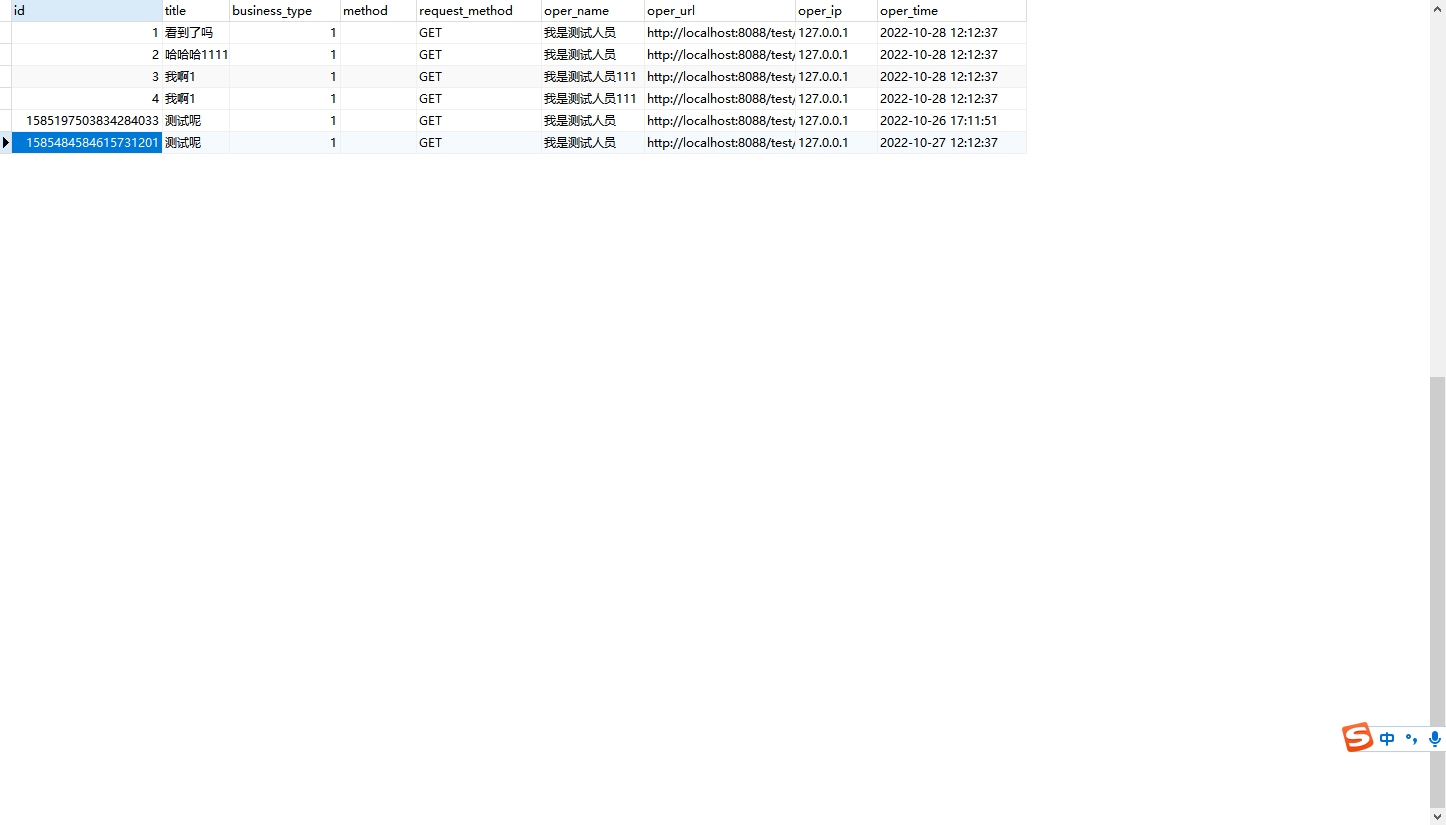
我们看到存在6条,和mysql一致!!
八、总结
话费了一天时间,终于搭建完成了,太不容易了!下篇文章搭建ELK日志,欢迎点个关注,等待更新哈!!
如果对你有帮助,还请不要吝啬您的发财小手,一键三连是我写作的动力,谢谢大家哈!!
可以看下一小编的微信公众号文章首发看,欢迎关注,一起交流哈!!

docker搭建Elasticsearch、Kibana、Logstash 同步mysql数据到ES的更多相关文章
- 使用logstash同步MySQL数据到ES
使用logstash同步MySQL数据到ES 版权声明:[分享也是一种提高]个人转载请在正文开头明显位置注明出处,未经作者同意禁止企业/组织转载,禁止私自更改原文,禁止用于商业目的. https:// ...
- centos7配置Logstash同步Mysql数据到Elasticsearch
Logstash 是开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的“存储库”中.个人认为这款插件是比较稳定,容易配置的使用Logstash之前,我们得明确 ...
- 使用Logstash来实时同步MySQL数据到ES
上篇讲到了ES和Head插件的环境搭建和配置,也简单模拟了数据作测试 本篇我们来实战从MYSQL里直接同步数据 一.首先下载和你的ES对应的logstash版本,本篇我们使用的都是6.1.1 下载后使 ...
- Centos8 部署 ElasticSearch 集群并搭建 ELK,基于Logstash同步MySQL数据到ElasticSearch
Centos8安装Docker 1.更新一下yum [root@VM-24-9-centos ~]# yum -y update 2.安装containerd.io # centos8默认使用podm ...
- 实战ELK(6)使用logstash同步mysql数据到ElasticSearch
一.准备 1.mysql 我这里准备了个数据库mysqlEs,表User 结构如下 添加几条记录 2.创建elasticsearch索引 curl -XPUT 'localhost:9200/user ...
- 【记录】ELK之logstash同步mysql数据到Elasticsearch ,配置文件详解
本文出处:https://my.oschina.net/xiaowangqiongyou/blog/1812708#comments 截取部分内容以便学习 input { jdbc { # mysql ...
- Docker搭建ElasticSearch+Redis+Logstash+Filebeat日志分析系统
一.系统的基本架构 在以前的博客中有介绍过在物理机上搭建ELK日志分析系统,有兴趣的朋友可以看一看-------------->>链接戳我<<.这篇博客将介绍如何使用Docke ...
- logstash同步mysql数据失败
问题描述 前提: 项目采用Elasticsearch提供搜索服务,Mysql提供存储服务,通过Logstash将Mysql中数据同步到Elasticsearch. 问题: 使用logstash-j ...
- elasticsearch使用river同步mysql数据
====== mysql的river介绍====== - 什么是river?river代表es的一个数据源,也是其它存储方式(如:数据库)同步数据到es的一个方法.它是以插件方式存在的一个e ...
- logstash同步mysql数据到mysql(问题一)
问题 通过logstash同步数据时 字段类型为tinyint时 通过过去 0变成了false 1变为了true 时间类型 变为 2018-10-16T14:58:02.871Z 分析 开始尝试通过 ...
随机推荐
- 一个C#开发者学习SpringCloud搭建微服务的心路历程
前言 Spring Cloud很火,很多文章都有介绍如何使用,但对于我这种初学者,我需要从创建项目开始学起,所以这些文章对于我的启蒙,帮助不大,所以只好自己写一篇文章,用于备忘. SpringClou ...
- Springboot 之 Filter 实现超大响应 JSON 数据压缩
简介 项目中,请求时发送超大 json 数据外:响应时也有可能返回超大 json数据.上一篇实现了请求数据的 gzip 压缩.本篇通过 filter 实现对响应 json 数据的压缩. 先了解一下以下 ...
- Node.js躬行记(24)——低代码
低代码开发平台(LCDP)是无需编码(0代码)或通过少量代码就可以快速生成应用程序的开发平台.让具有不同经验水平的开发人员可以通过图形化的用户界面,通过拖拽组件和模型驱动的逻辑来创建网页和移动应用程序 ...
- react.js 实现音乐播放、下一曲、以及删除歌曲(仅播放列表)
import React, { Component } from 'react'; export default class Music extends Component { construct ...
- 解决在vue中设置的height: 100%没有效果
在新的页面设置height无效果的时候.需要改动App这个文件的heigth 解决办法.给app这个盒子设置高度.默认情况下为0 设置高度100%时,div的高度会等同于其父元素的高度.而上面中id为 ...
- 题解 P3395 路障
前言 没想到这是\(\sf {tgD1T1}\)难度-- 题目大意 有一个\(n\times n\) 的棋盘,有\(2n-2\) 个路障,在第\(i\) 秒会在\((x_i,y_i)\) 放置路障.求 ...
- Codeforces Round #805 (Div. 3)E.Split Into Two Sets
题目链接:https://codeforces.ml/contest/1702/problem/E 题目大意: 每张牌上面有两个数字,现在有n张牌(n为偶数),问能否将这n张牌分成两堆,使得每堆牌中的 ...
- EXCEL_BASIC
公式类 比较大小 A1单元格的值大于B1单元格时为"A",小于时为"a",等于时为"e" =IF(A1>B1,"A" ...
- Java使用lamda表达式简化代码
代码,自然写的越简洁越好啦,写的人舒服,看的人也舒服,一切为了高效. 要把有限的时间花到其它有意思的事情上去. 目的 学习简化代码的思路,使用jdk8新特性lamada表达式. 使用 某接口,只有一个 ...
- 基于SqlSugar的开发框架循序渐进介绍(21)-- 在工作流列表页面中增加一些转义信息的输出,在后端进行内容转换
有时候,为了给前端页面输出内容,有时候我们需要准备和数据库不一样的实体信息,因为数据库可能记录的是一些引用的ID或者特殊字符,那么我们为了避免前端单独的进行转义处理,我们可以在后端进行统一的格式化后再 ...