vivo 实时计算平台建设实践
作者:vivo 互联网实时计算团队- Chen Tao
本文根据“2022 vivo开发者大会"现场演讲内容整理而成。
vivo 实时计算平台是 vivo 实时团队基于 Apache Flink 计算引擎自研的覆盖实时流数据接入、开发、部署、运维和运营全流程的一站式数据建设与治理平台。
一、vivo 实时计算业务现状
2022年,vivo互联网在网用户总数达到2.8亿,多款互联网应用的日活超过了千万甚至突破了1亿,为了向用户提供优质的内容和服务,我们需要对如此大规模的用户所产生的海量数据进行实时处理,帮助我们进行运营决策、精准推荐、提升终端用户体验,同时通过提升我们的商业化能力为广告主提供更加优质的广告服务。
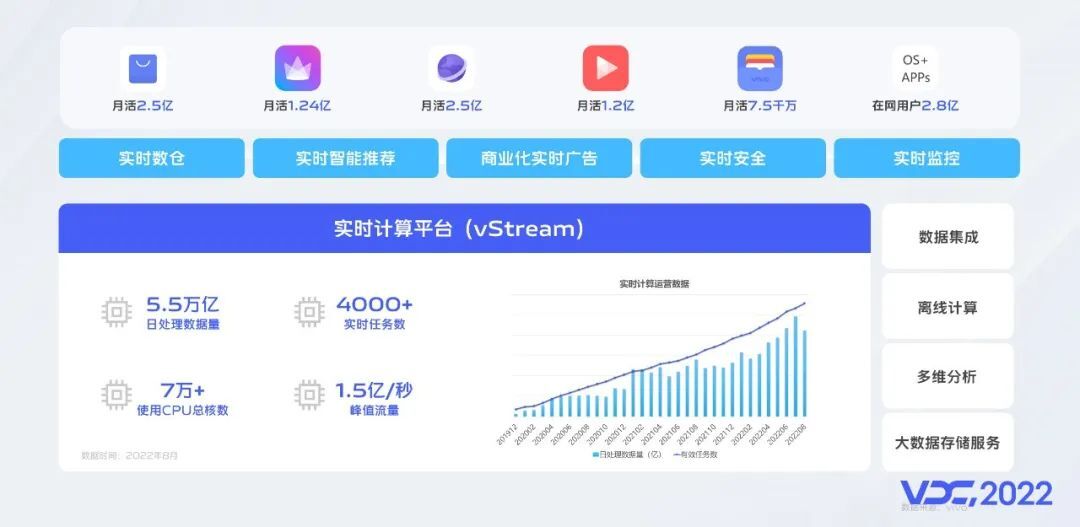
近几年,大数据实时计算技术和公司的实时数据业务都在飞速发展,截止到今年8月,vivo实时计算每日处理数据量达到5PB,有效任务数超过4000,目前已接入98个项目,从趋势上来看,每年都有超过100%的规模增长,如此大的业务规模和业务增速给我们实时计算团队带来的非常大的挑战。首先,我们要确保业务的稳定,高速增长的数据、复杂的业务场景和系统架构需要我们自底向上的全方位的稳定性建设;为了帮助用户快速落地业务,我们需要降低开发门槛,提供良好的易用性和覆盖各种场景的功能特性,业务的高效接入和运维能带来长期的降本收益。同时,大规模的数据和计算我们也希望能够以尽可能低的成本去运行,这就需要我们提供高效的存储、计算能力,并且对于许多关键业务,实时计算时效性保障的要求也非常高。在复杂的数据环境中要保障数据安全需要有非常良好的且具有前瞻性的设计,优秀的安全能力需要能够提前防范可能的风险。
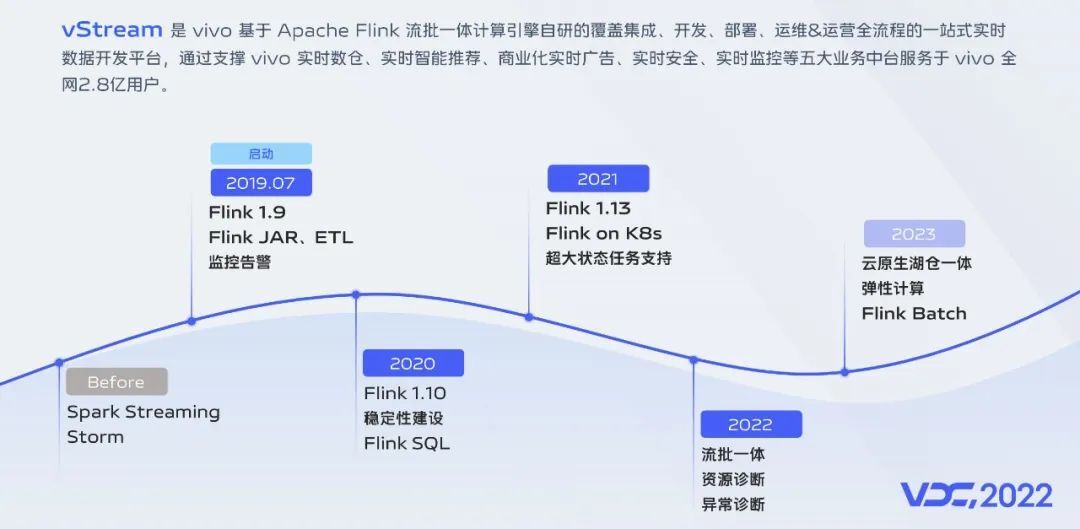
我们从2019年下半年启动了实时计算平台的建设,2020年关注在稳定性建设,初步上线了SQL能力,2021年引入了Flink 1.13版本并启动了容器化建设,2022年主要关注在效率提升,包括流批一体、任务诊断等,到目前为止,我们平台已初步具备了一些能力,所以今天我代表我们团队简单给大家介绍一下我们的平台建设实践。
二、实时计算平台建设实践
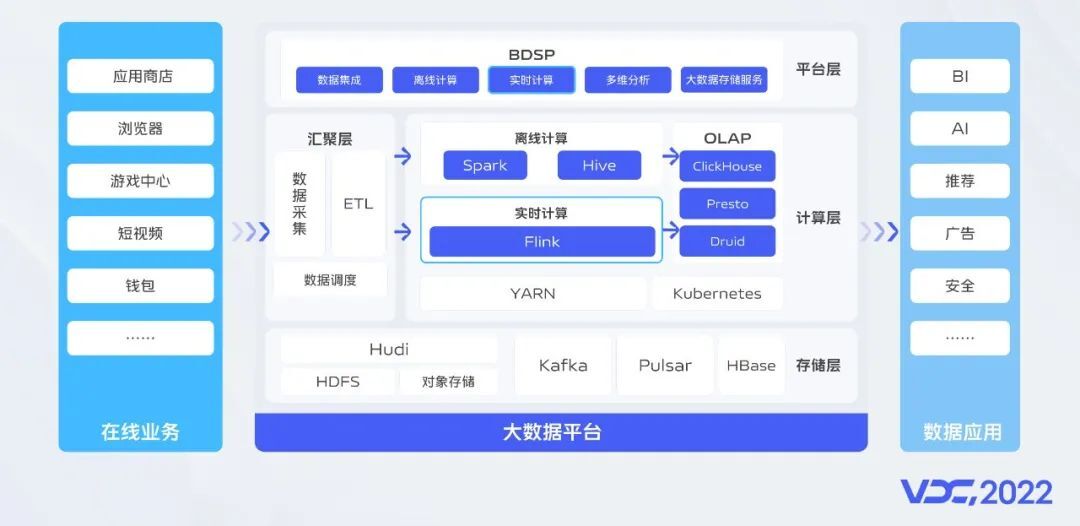
从我们大数据平台的体系架构上来看,我们通过汇聚层能力收集整个vivo互联网的埋点、服务器日志,通过计算、存储、分析等能力从海量数据中挖掘出业务价值。实时计算作为平台的核心能力之一,它同时满足了大规模数据计算和高时效计算的需求,我们通过实时计算平台来承载和向业务提供这方面的能力。
vivo实时计算平台是基于Apache Flink计算引擎自研的覆盖实时流数据接入、开发、部署、运维和运营全流程的一站式数据建设与治理平台。接下来我会从基础服务建设、稳定性建设、易用性建设、效率提升和安全能力建设五个方面来介绍我们团队的建设思路和实践过程。
2.1 基础服务建设
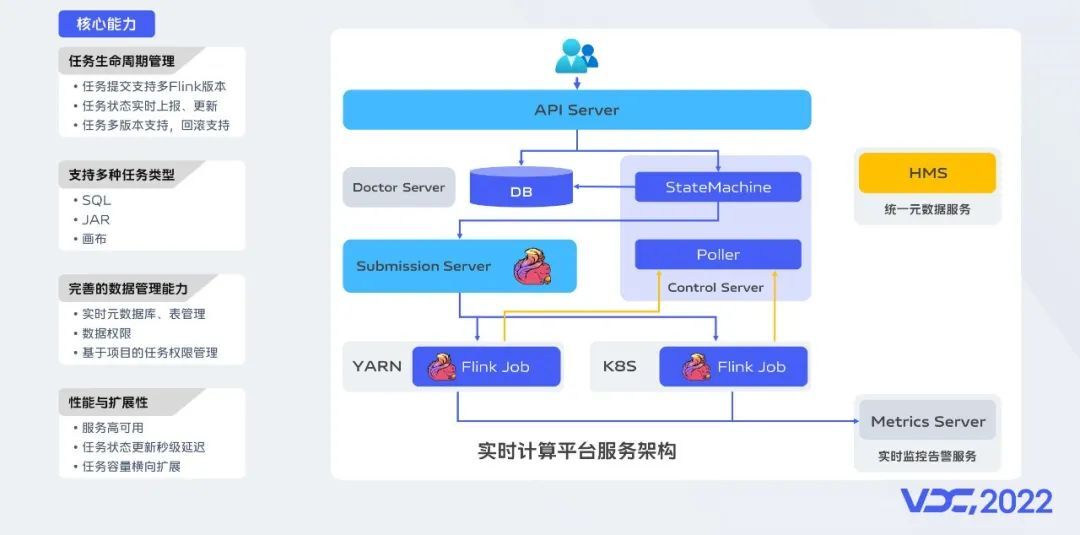
我们自研的实时平台后端架构包括两个核心服务:
SubmissionServer:负责作业的提交,以及跟资源管理系统的交互,具备高可用、高可扩展能力,支持多版本Flink和多种任务类型。
ControlServer:负责任务运行状态的维护,我们定义了9种任务状态,通过一个内置状态机进行实时的状态维护,状态的更新延迟在秒级。
基础服务还包括统一的元数据服务和实时的监控告警服务。这两个部分做一下简单介绍。
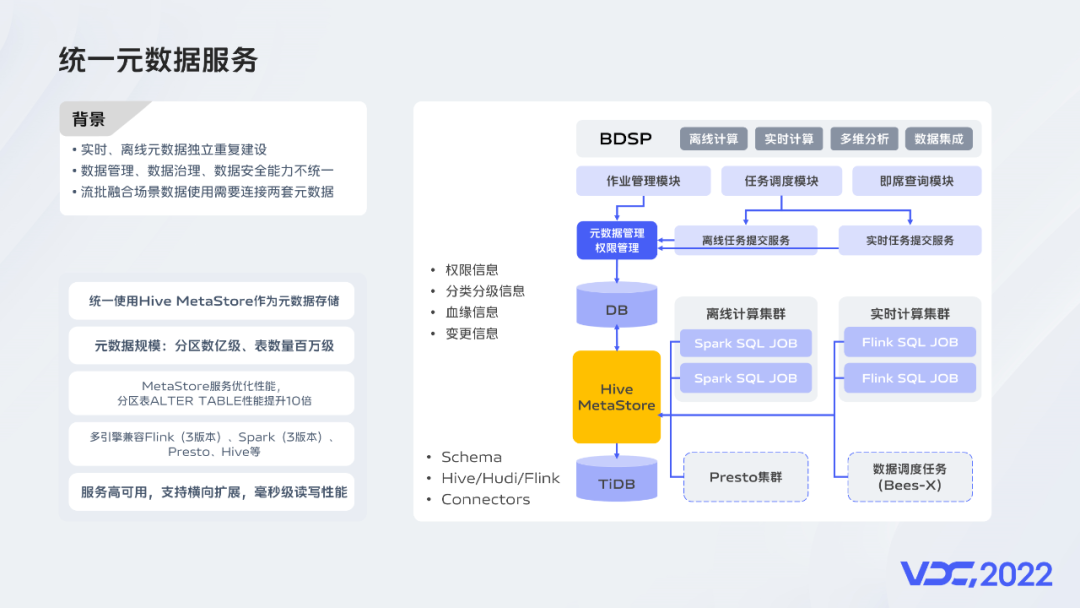
我们使用HiveMetaStore作为元数据基础服务,基于TIDB的扩展能力,当前元数据实体规模已达到亿级,通过对MetaStore服务的优化,大分区表操作性能提升了10倍,目前已接入Spark、Hive、Flink、Presto等引擎,同时,统一的权限控制、数据分类分级、数据血缘、元数据变更记录等能力也为数据治理提供了良好的基础。
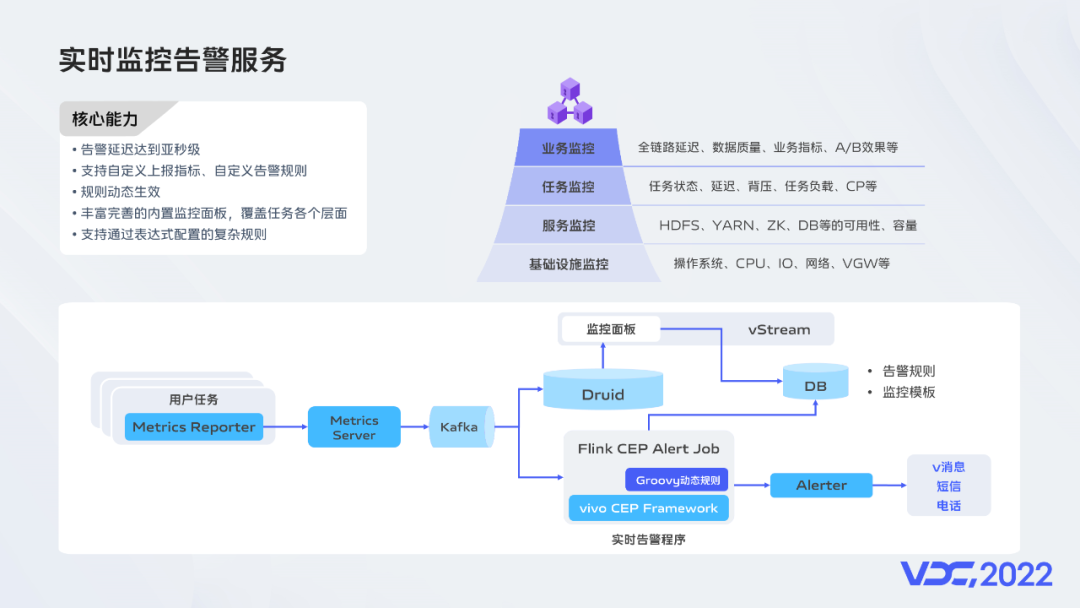
我们基于Flink的CEP能力构建了一套秒级延迟、支持动态规则配置的监控告警系统,同时从基础设施、基础服务、实时任务和业务多个维度构建了全方位的监控体系。以上这三个方面构成了我们的基础服务。基础服务都具备高可用特性,但是要保障业务稳定,还需要关注整个系统以及在系统上运行的业务数据链路,这里最重要的有两个方面:大数据组件服务的稳定性和任务本身的稳定性。
2.2 稳定性建设
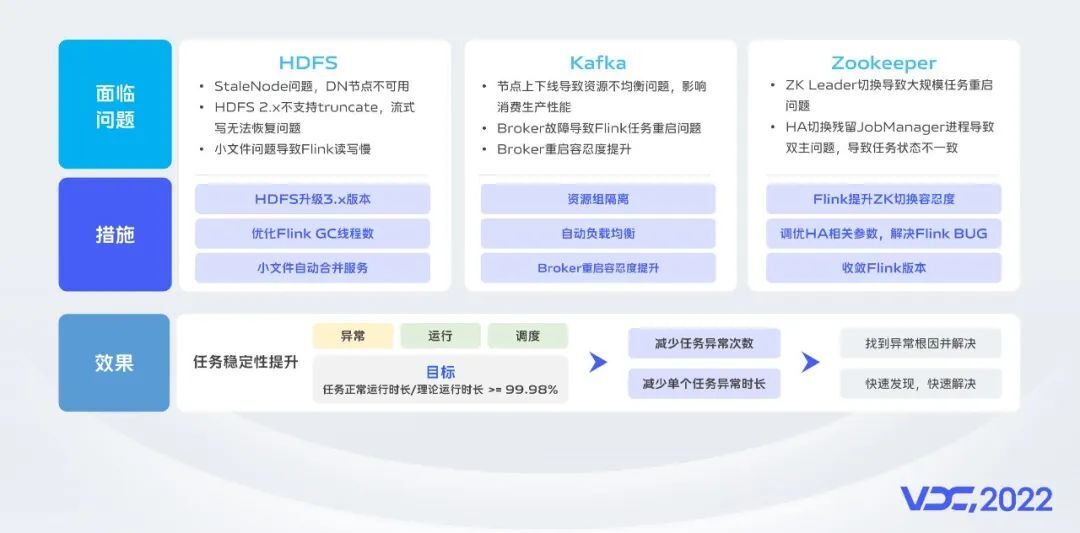
我们使用HDFS作为状态的持久存储和业务数据落地的存储,随着存储规模和读写量的增长,我们遇到了DataNode的StaleNode问题、低版本HDFS流式写无法恢复问题和越来越严重的小文件问题,为此我们通过平滑升级HDFS到3版本、优化Flink Sink性能和基于Spark3建设小文件合并服务来解决这些问题。
Kafka是主要的流存储组件,但是在集群运维上存在一些痛点,比如扩缩容和节点硬件故障会导致资源不均衡和消费生产的异常,Kafka团队建设了流量均衡和动态限流能力,显著提升了Kafka服务的稳定性,同时我们也提升了Flink对Kafka Broker重启的容忍度,能够有效减少Broker故障对运行任务带来的影响。
另外,Flink任务的高可用依赖于Zookeeper,为了避免ZK leader切换对实时作业的影响,我们对1.10和1.13版本的Flink进行了容忍度增强,对更低版本的任务做了版本升级,也根据社区经验优化了Flink HA部分的功能,以及加强了对ZK的全面监控和治理,保障了ZK的稳定性。
通过这些对相关组件的优化措施减少了任务异常时间和次数,有效的提升了任务稳定性。接下来介绍一下我们针对某种特定场景的Flink任务稳定性优化实践。
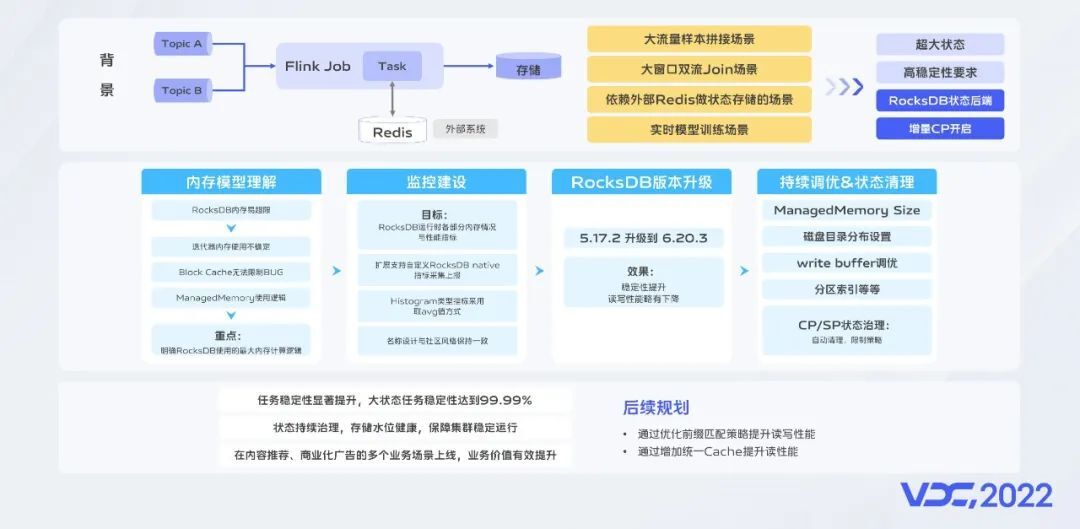
在内容实时推荐场景,产生自在线预估服务的用户特征快照需要与用户实时数据进行拼接,由于数据量巨大在做Join时需要一个大缓存,相比于原来采用Redis作为缓存的方案,Flink的RocksDB状态后端是一个更合适的方案,但是在状态大小达到TB级别时,任务稳定性很难保障。我们基于对RocksDB内存模型的深刻理解,扩展原生监控指标,升级RocksDB版本,建设了状态治理相关能力,把任务稳定性提升到了生产可用级别。在多个业务场景上线后,样本和模型的时效性和稳定性得到保障,推荐效果得到很大提升。
后续我们规划通过增加读缓存和优化前缀匹配策略进一步提升RocksDB状态后端的性能。
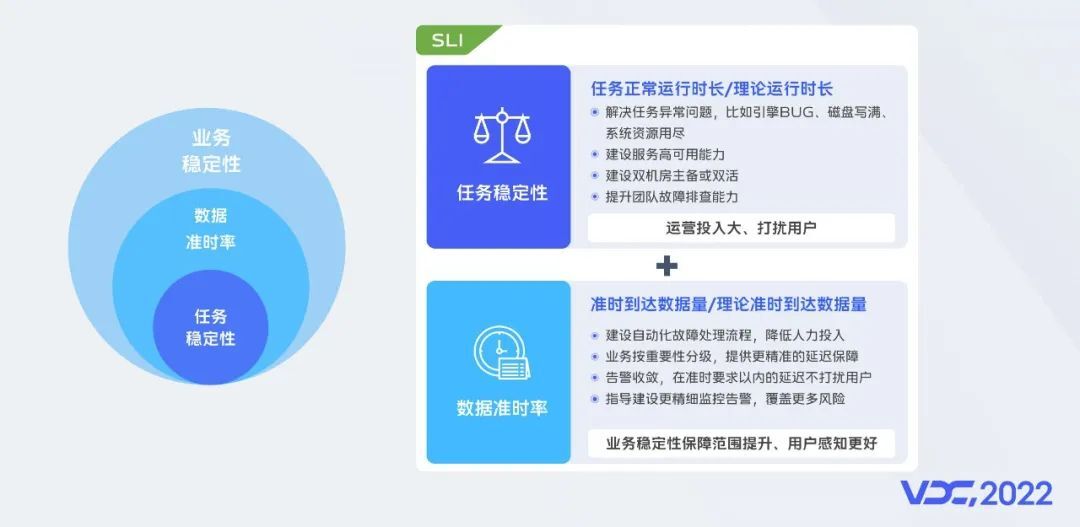
我们一直在思考如何进一步提升业务的稳定性,相对于任务的稳定性我们的用户更加关心他们所需要的数据是否准时、数据质量是否符合预期,而任务的稳定不完全等同于时效和质量。在时效这个维度我们定义了数据准时率的SLI指标,这对我们有两方面的指引:更自动化和精细化的故障分级保障和流计算的弹性能力的建设。其中前者正在建设中,后者也在我们的规划之中。
2.3 易用性建设
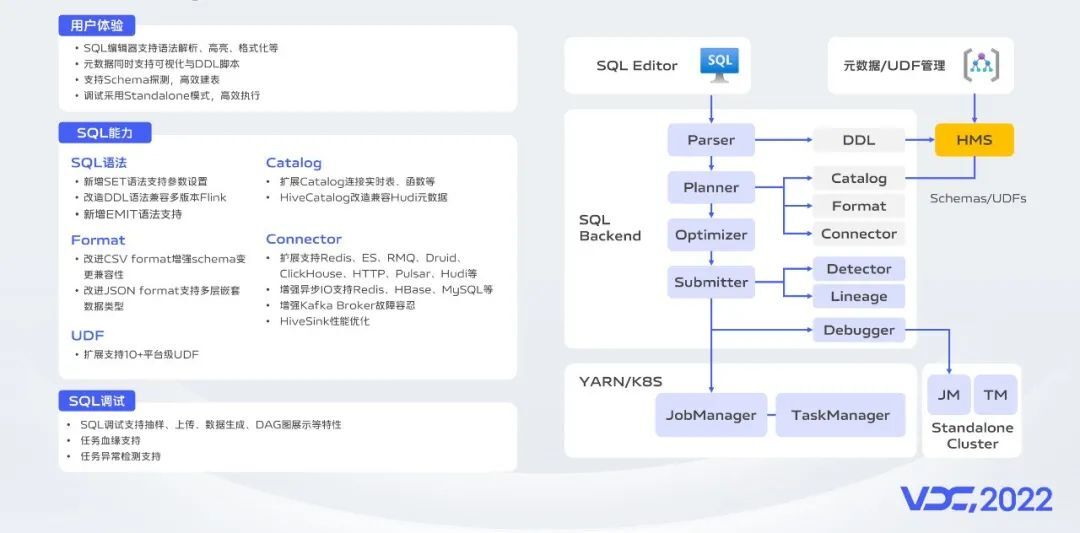
从实时作业开发角度,
我们提供了功能完善、体验良好的FlinkSQL开发环境。相比于社区版本Flink,我们对SQL能力进行了扩展,比如更加可控的窗口计算触发功能,兼容性更强的DDL功能,更加方便的流表创建功能,我们对Format、Connector、UDF都做了一些扩展和优化,适用于更多业务场景,提升了性能;同时我们建设了运行于Standalone集群的SQL调试能力,具备数据抽样、上传、DAG图展示、调试结果实时展示等功能。经过一年的建设,新增SQL运行任务占比从5%提升到了60%。
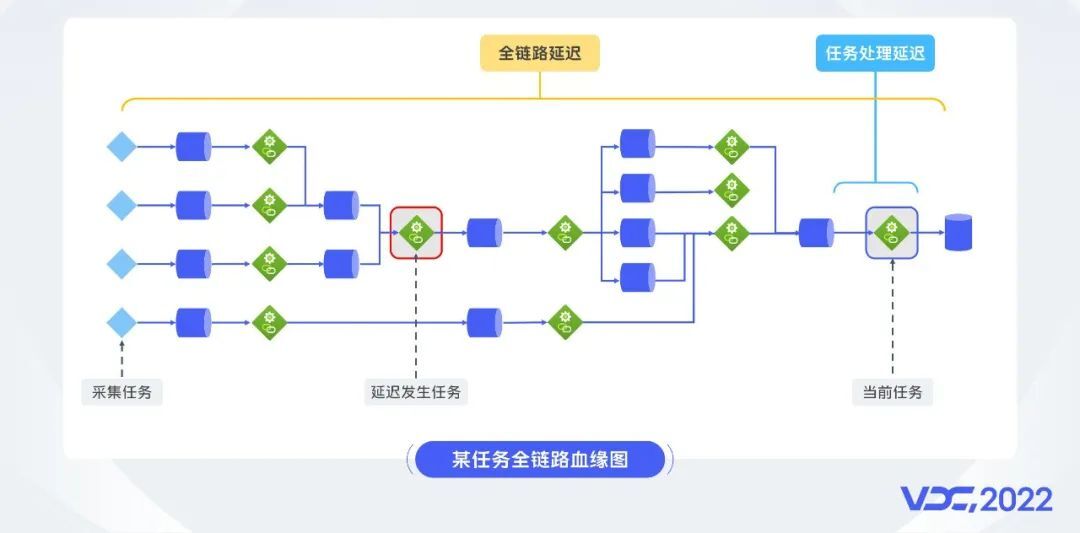
从实时作业运维角度,
我们提供了实时全链路的血缘与延迟监控功能。为了实现数据业务,实时计算链路往往是很长的,而一个团队一般只负责其中一段,为了解决链路中出现的问题,可能需要上下游多个团队配合,效率很低。我们作为平台团队为用户提供了一个全局的视角,这样可以迅速定位到异常任务节点,非常高效。血缘数据可以实时生成,并且不需要任务的重启,因此不存在血缘不全的问题。同时,我们也可以输出端到端全链路延迟数据和任务处理延迟数据,帮助我们的用户做质量监控。
2.4 效率提升
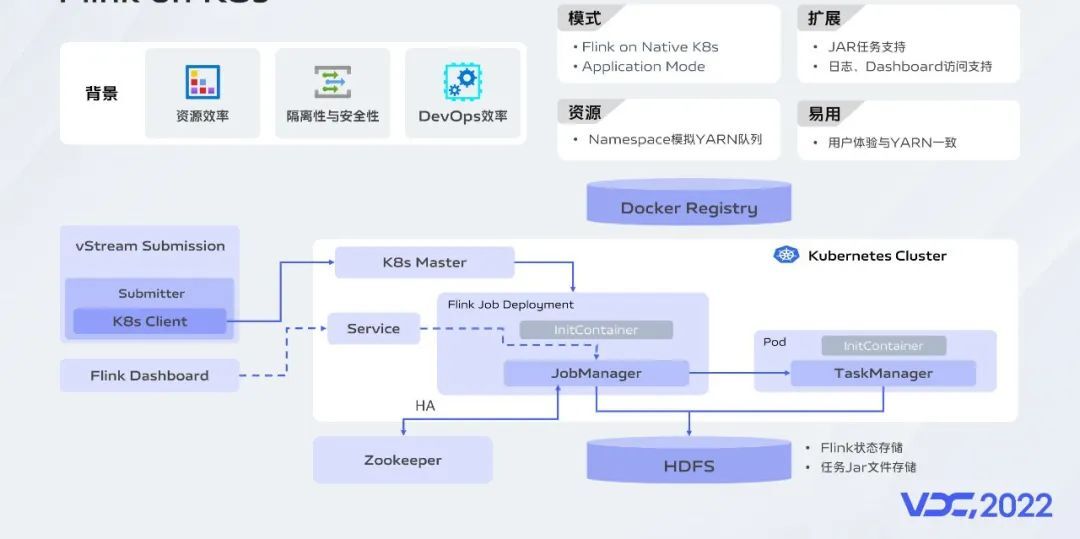
今年,降本提效是我们的重点工作方向,我们从计算、存储和资源治理三个方面做了一些工作,取得初步效果。YARN资源管理的粒度较大,而K8s更精细的资源粒度从整体上来看可以有效提升资源利用效率。YARN虽然开启了cgroups,但是对系统资源的隔离能力仍然较弱,个别异常任务耗尽机器资源可能影响正常运行的任务。因此平台支持了K8s的资源管理能力,借助于Flink社区提供的Native K8s特性以及平台良好的可扩展性,我们当前支持JAR任务的容器化部署,并且通过在开发、运维、资源交付等方面的建设确保了用户体验与YARN是一致的。借助于容器化,我们可以确保开发、测试、线上等环境的一致性,研发效率也得到提升。目前已接入3个业务,明年会比较大规模的应用。
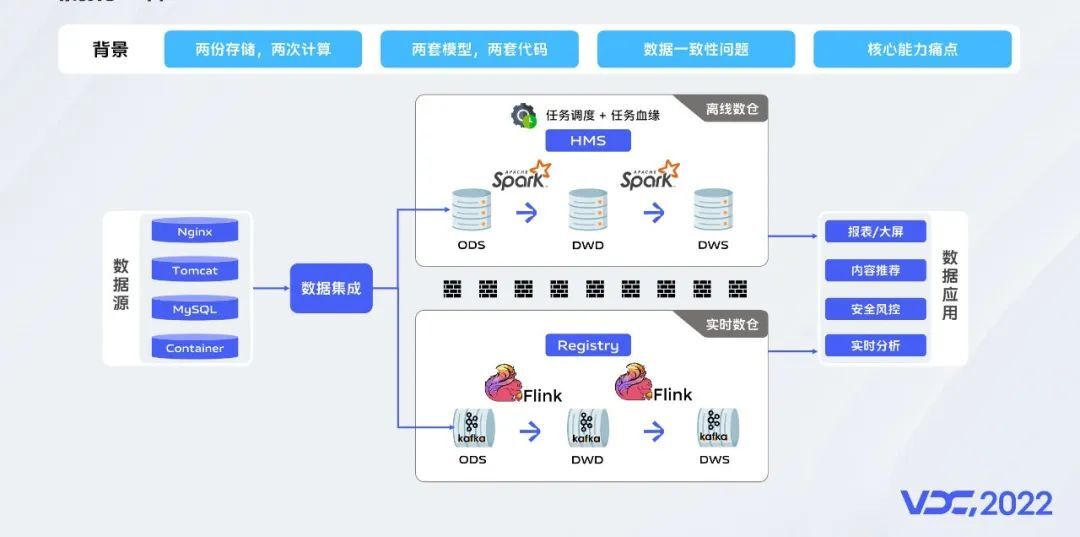
多年以来,大数据领域在发展过程中形成了批和流两套架构并存的现状,很多时候,业务在落地过程中不得不同时考虑和投入建设两套链路。比如离线数仓和实时数仓独立建设,数据口径和计算结果的一致性保障需要付出额外的努力,Hive表不支持数据更新、探查较慢,Kafka数据回溯和查询困难等问题也一直困扰着数据开发人员。
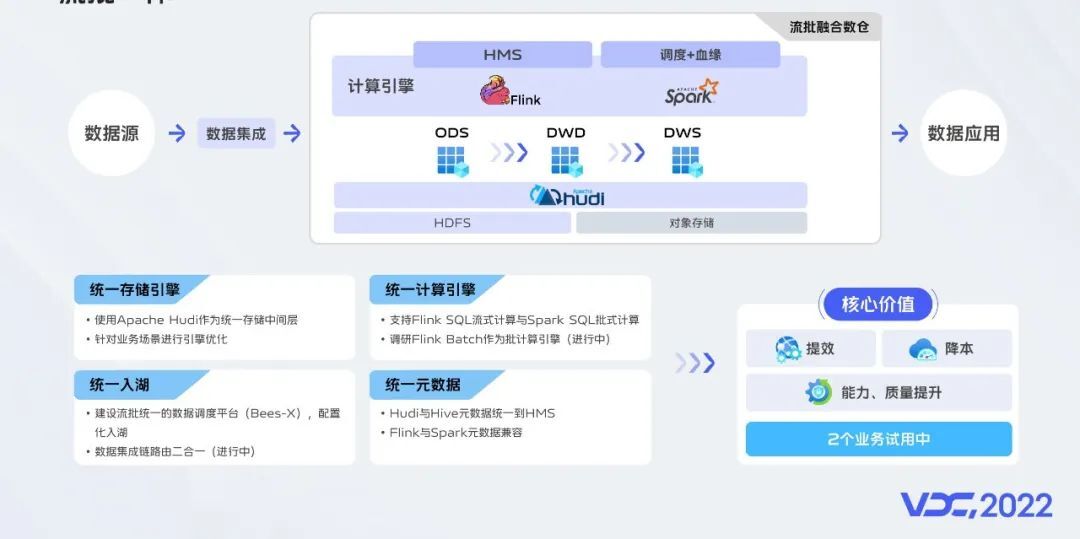
幸运的是,业界已经探索出来基于数据湖组件在分布式存储之上构建流批统一存储的技术,我们根据vivo的业务特点选择并设计了我们的流批一体方案,目前已经完成基于Hudi的统一存储引擎、基于Flink的统一入湖、基于HMS的统一元数据建设,目前业务已经完成试用并开始接入。今年我们主要接入实时业务,明年会有离线业务的接入。这也是我们大数据平台构建湖仓一体很重要的一步。
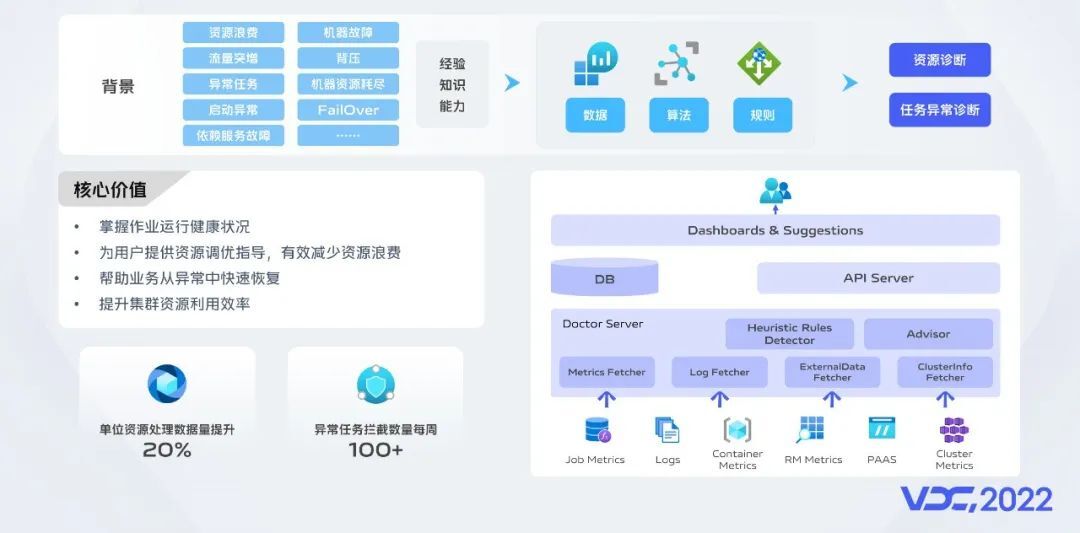
在长期的实时作业运维过程中,我们积累的大量作业调优和问题解决经验,随着运维压力的增加,我们在思考如何提升运维效率。我们也发现用户资源队列用满的同时,机器的CPU利用率却处于较低水平,因此我们思考如何减少资源浪费,提升集群的资源利用效率。资源诊断和异常诊断这两类问题都是作业优化问题,要优化作业,首先需要掌握作业及其运行环境的信息,包括运行指标、运行日志、GC日志、依赖组件运行状况、操作系统进程级别信息,以及作业配置、环境配置等等,然后需要将运维经验和思路转化为启发式算法的规则和数据,运用这些数据、算法和规则去找到优化的方法。基于这个思路,我们建设了一个诊断服务,具备灵活的信息收集、规则配置、数据调优功能,能够在作业启动或运行时,诊断作业的健康程度,提供一些作业的优化建议给我们的用户。目前资源诊断能力已经在运行,异常诊断还在建设中。
2.5 安全能力建设
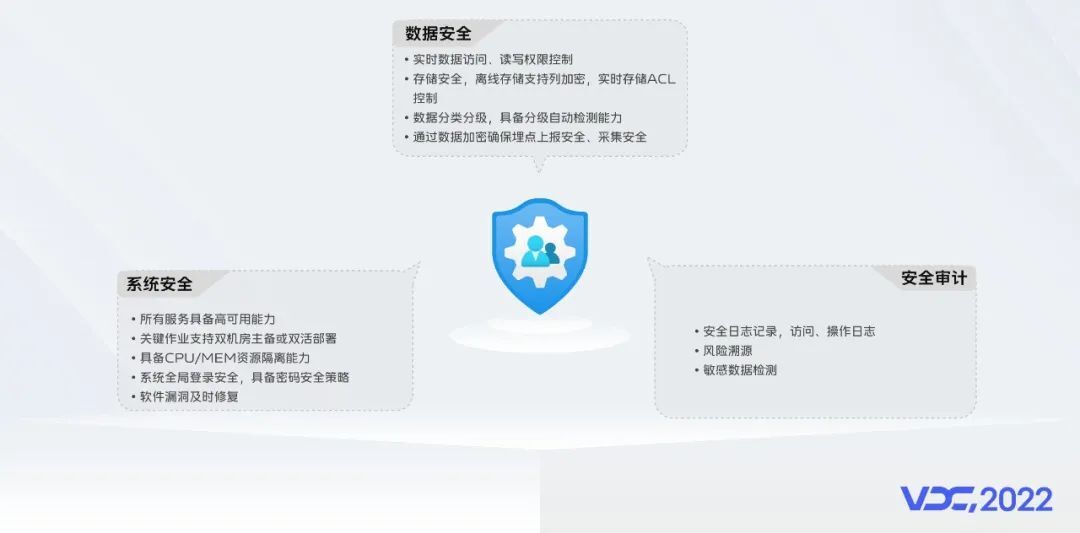
作为一个基础的大数据服务,安全在我们看来是一个非常重要的命题,因此我们在系统设计之初就考虑了实时数据访问、离线数据读写、各个系统与服务之间的安全隔离能力等方面的设计,在实时数仓具备一定规模后,我们又建设了数据分类分级、日志审计等能力。去年,根据最新的合规要求,离线存储支持了列级别透明加密,实时数据支持了敏感字段自动检测等能力。安全无止境,我们也在对DSMM进行研究解读,以持续提升大数据的安全能力。
以上是我们平台建设的一些实践,总结来看,我们基于Flink建设了功能比较完善的实时计算开发和运维能力,业务复杂度越来越高,我们的挑战还有很多,比如Flink引擎的优化与难点问题的解决、计算效率的进一步提升、流批一体、容器化的大规模应用等,都是我们后续的重点方向。
前面有提到,基于实时计算平台,公司的多个中台团队建设了五大中台能力,覆盖了各种各样的实时场景,这里就跟大家简单分享下其中两个典型场景。
三、应用场景简介
3.1 实时数仓

vivo大数据团队基于vStream平台建设的实时数仓服务覆盖了应用分发、内容分发、产品平台、商业化等多个业务线的报表、营销、推荐、决策、广告等多种应用场景。实时数仓沿用了离线数仓的逻辑分层理论,从数据源经过采集和ETL进入到ODS层,然后经过维度扩展、过滤、转换等操作进入到DWD明细层,然后是轻度聚合层DWS,最后按照主题或业务需求计算出结果指标存入ClickHouse等OLAP引擎成为ADS层,为业务提供数据报表、接口或者数据服务。与离线有所不同的是,实时数据受限于数据达到时间或业务对数据的要求,可能会有层次的裁剪,因此实时数仓也提供了中间层开放的能力。
实时数仓的一部分维度表与离线是共用的,并且为了与离线链路保证一致的数据口径需要将Kafka流表落地到Hive表进行数据的比对,离线与实时的互操作不是很方便,因此,数仓团队已经开始基于流批一体能力建设准实时的数据链路。然后我们看一下,实时计算是如何应用在内容推荐场景的。
3.2 短视频实时内容推荐
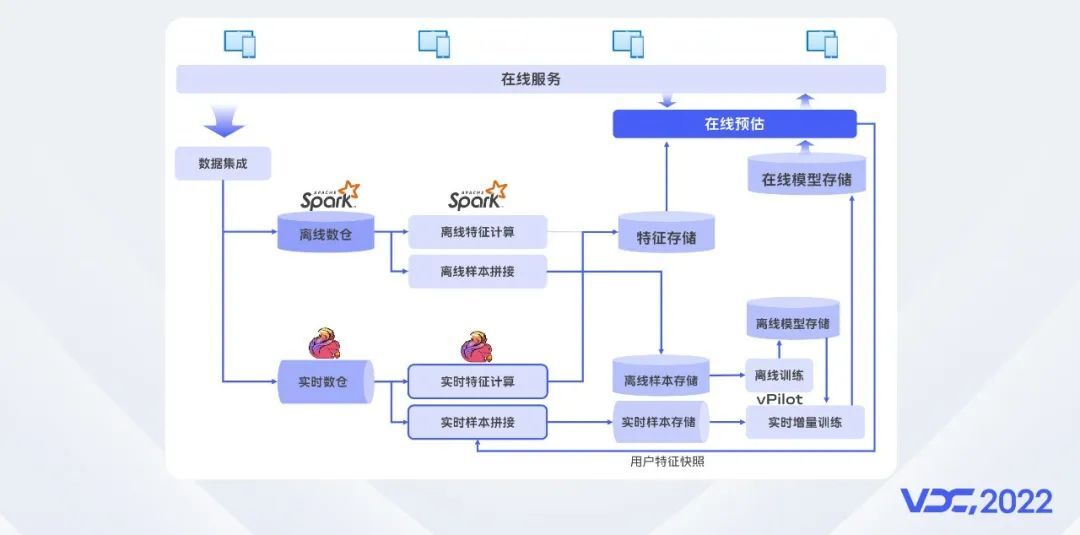
vivo短视频是一个很火的应用,为了给到用户高质量的视频内容推荐,特别依赖于推荐模型的时效性以及用户特征计算的时效性,为了做到实时的模型训练,需要有实时的样本数据。因此实时特征计算和样本拼接在内容推荐里面扮演了很重要的角色,vStream平台提供的TB级别超大状态任务能力支撑了短视频以及许多其他应用的实时样本拼接任务。同时我们也可以看到,在这个方案里,特征和样本都同时存在离线和实时两条链路,这是因为Flink的批计算能力目前还没有Spark成熟,基于Kafka的实时计算难以做到数据回溯,站在我们大数据平台的角度,一方面我们希望能够减少重复的计算和存储,另一方面也希望平台的用户能够不需要重复开发计算和回溯的代码。在业界广泛讨论的湖仓一体架构,很重要的一个方面就是为了解决这些问题。在后面的部分,我们会再聊一聊湖仓一体。
实时计算的应用场景有很多,但本质上来说它的目的跟离线计算是一样的,就是为业务提供数据支持。从前面的介绍可以看到,当前基于Hadoop的大数据平台组件繁多、架构复杂、流批重复、资源效率较低,那么我们有没有办法或者说有没有希望改变这种现状呢?我认为是有的,最后分享一下我们对未来的一些探索和展望。
四、探索与展望

我们知道,业务是弹性的,比如在一天之内总有用户访问的高峰和低谷,一段时间内总有业务的增长或下降。但是当前,不管是我们的数据计算任务还是YARN集群的资源分配策略,都不具备弹性,首先,任务分配的资源是固定的,并且,为了尽可能避免计算受到业务波动的影响,离线、实时和在线三种不同类型的计算分别运行在不同的物理集群。
因此我们需要如下两种维度的弹性能力:
任务级别的弹性能力,我们打算紧跟Flink社区,探索其AutoScaling特性的应用。
集群级别的弹性能力,我们会采用vivo容器团队提供的在离线混部能力来实现。
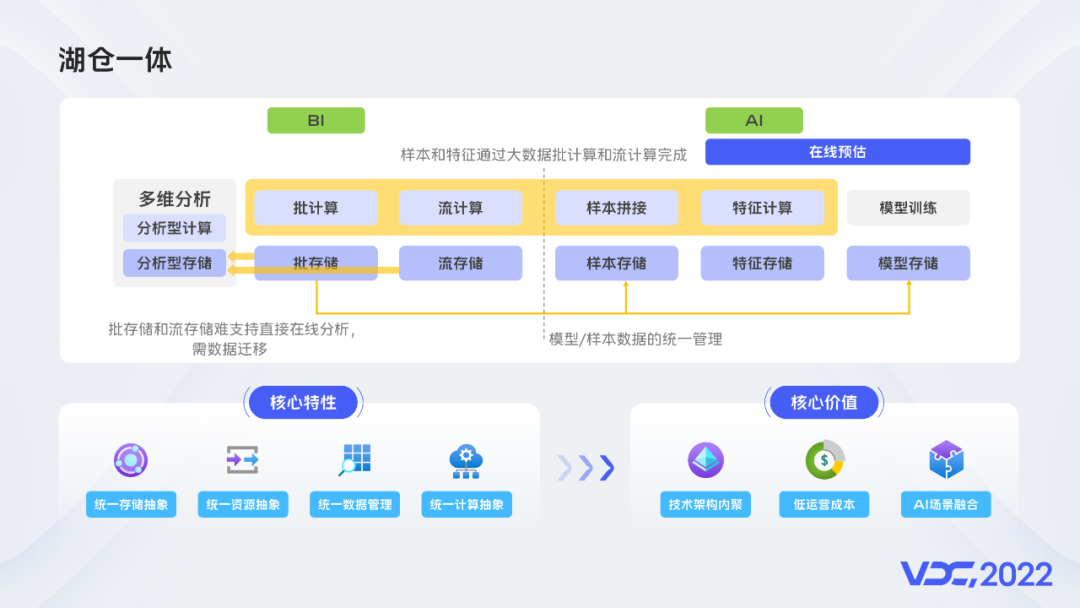
刚刚我们提到了湖仓一体,为什么需要湖仓一体呢?可以拿BI和AI两个大数据应用领域放在一起来看,流计算、批计算、分析型计算和AI计算及其对应的存储系统分别解决各自的问题,并且由于发展阶段差异,围绕这四种计算形式建设了大量的平台系统和业务系统,运营这个复杂庞大的系统资源成本和人力成本都是非常高的。因此大家期望通过统一的存储抽象、统一的计算抽象、统一的资源抽象和统一的数据管理来建设一个架构内聚、低成本、易于使用的大数据系统。大家的期望促进了云原生、数据湖、新一代计算引擎等技术的发展,这些发展也使得大家的期望更明确更一致。
vivo 实时计算平台建设实践的更多相关文章
- 携程实时计算平台架构与实践丨DataPipeline
文 | 潘国庆 携程大数据平台实时计算平台负责人 本文主要从携程大数据平台概况.架构设计及实现.在实现当中踩坑及填坑的过程.实时计算领域详细的应用场景,以及未来规划五个方面阐述携程实时计算平台架构与实 ...
- TOP100summit:【分享实录】Twitter 新一代实时计算平台Heron
本篇文章内容来自2016年TOP100summit Twitter technical lead for Heron Maosong Fu 的案例分享. 编辑:Cynthia Maosong Fu:T ...
- SLA 99.99%以上!饿了么实时计算平台3年演进历程
作者介绍 倪增光,饿了么BDI-大数据平台研发高级技术经理,曾先后就职于PPTV.唯品会.15年加入饿了么,组建数据架构team,整体负责离线平台.实时平台.平台工具的开发和运维,先后经历了唯品会.饿 ...
- 克拉克拉(KilaKila):大规模实时计算平台架构实战
克拉克拉(KilaKila):大规模实时计算平台架构实战 一.产品背景:克拉克拉(KilaKila)是国内专注二次元.主打年轻用户的娱乐互动内容社区软件.KilaKila推出互动语音直播.短视频配音. ...
- 阿里PB级Kubernetes日志平台建设实践
干货分享 | 阿里PB级Kubernetes日志平台建设实践https://www.infoq.cn/article/HiIxh-8o0Lm4b3DWKvph 日志最主要的采集工具是 Agent,在 ...
- [平台建设] HBase平台建设实践
背景 由于公司业务场景的需要,我们需要开发HBase平台,主要需要以下功能: 建表管理 授权管理 SDK实现 与公司内部系统打通 我们使用的HBase 版本: HBase 1.2.0-cdh5.16. ...
- TOP100summit 2017:【案例分享】魅族持续交付平台建设实践
本篇文章内容来自第10期魅族开放日魅族运维架构师林钟洪的现场分享.编辑:Cynthia 一.自动化建设历程1.1 魅族互联网发展的时间线 2003-2008年被称之为“互联网1.0时代”.2003年, ...
- Kubernetes容器云平台建设实践
[51CTO.com原创稿件]Kubernetes是Google开源的一个容器编排引擎,它支持自动化部署.大规模可伸缩.应用容器化管理.伴随着云原生技术的迅速崛起,如今Kubernetes 事实上已经 ...
- 趣头条基于 Flink 的实时平台建设实践
本文由趣头条实时平台负责人席建刚分享趣头条实时平台的建设,整理者叶里君.文章将从平台的架构.Flink 现状,Flink 应用以及未来计划四部分分享. 一.平台架构 1.Flink 应用时间线 首先是 ...
- 美团点评基于 Flink 的实时数仓建设实践
https://mp.weixin.qq.com/s?__biz=MjM5NjQ5MTI5OA==&mid=2651749037&idx=1&sn=4a448647b3dae5 ...
随机推荐
- Failed to convert from type [java.lang.String] to type [java.util.Date] for value '2020-02-06'; nested exception is java.lang.IllegalArgumentException]解决
今天做springbook项目前端输入日期传到数据库保存报了一下错误 Whitelabel Error Page This application has no explicit mapping fo ...
- 知识图谱顶会论文(ACL-2022) PKGC:预训练模型是否有利于KGC?可靠的评估和合理的方法
PKGC:预训练模型是否有利于KGC?可靠的评估和合理的方法 论文地址:Do Pre-trained Models Benefit Knowledge Graph Completion? A Reli ...
- vue中push()和splice()的使用方法
vue中push()和splice()的使用方法 push()使用 push() 方法可向数组的末尾添加一个或多个元素,并返回新的长度.注意:1. 新元素将添加在数组的末尾. 2.此方法改变数组的长度 ...
- 【神经网络】softmax回归
前言 softmax回归为一种分类模型. 基本原理 由于softmax回归也是一种线性叠加算法,且需要输出离散值. 很自然地想到,可以取值最大的输出为置信输出.更进一步想到,如果有三个人A.B.C分别 ...
- 一、什么是Kubernetes
一.什么是Kubernetes 它是一个全新的基于容器技术的分布式架构领先方案,确切地说,Kubernetes是谷歌严格保密十几年的秘密武器Borg的一个开源版本.Borg是谷歌内部使用的大规模集群 ...
- Bob 的生存概率问题
Bob 的生存概率问题 作者:Grey 原文地址: 博客园:Bob 的生存概率问题 CSDN:Bob 的生存概率问题 题目描述 给定五个参数 n , m , i , j , k,表示在一个 n*m 的 ...
- Mysql之PXC高可用
PXC高可用 1.环境准备 pxc1: centos7 10.0.0.7 pxc2: centos7 10.0.0.17 pxc3: centos7 10.0.0.27 pxc4: centos7 1 ...
- ES6 学习笔记(十)Map的基本用法
1 基本用法 Map类型是键值对的有序列表,而键和值都可以是任意类型.可以看做Python中的字典(Dictionary)类型. 1.1 创建方法 Map本身是一个构造函数,用来生成Map实例,如: ...
- js高级之对象高级部分
基于尚硅谷的尚硅谷JavaScript高级教程提供笔记撰写,加入一些个人理解 github源码 博客下载 对象的创建模式 Object构造函数模式 套路: 先创建空Object对象, 再动态添加属性/ ...
- K8S节点选择器案例
#给节点打上标签 [root@lecode-k8s-master deployment]# kubectl label no lecode-dev-001 hostname=lecode-dev-00 ...