大数据面试——HDFS
一、Hadoop1.0 与 Hadoop2.0的区别

![]()
二、写一个 WordCount 案例
【1】我在安装目录执行 hadoop jar "jar包" wordcount "统计文件目录" "输出目录(一定不要存在,会自动创建)",重点就是 wordcount ,在Linux 中也常常使用 wc 来统计行数,字符个数等。
[root@localhost hadoop-2.7.2]# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount data/zzx data/output![]()
【2】进入输出目录,查看统计结果
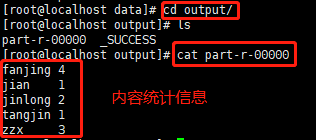
![]()
三、从多个文件 Grep 制定数据
【1】我在安装目录执行 hadoop jar "jar包" grep "统计文件目录" "输出目录(一定不要存在,会自动创建)" "'抓取文件时的规则'"
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar grep input output 'dfs[a-z.]+'![]()
【2】进入输出目录,查看统计结果。统计的是input 文件下所有文件,符合正则的单词的数量。
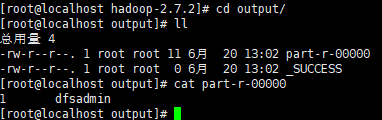
![]()
四、为什么不能一直格式化NameNode,格式化NameNode,要注意什么?
[zzx@hadoop101 hadoop-2.7.2]$ cd data/tmp/dfs/name/current/
[zzx@hadoop101 current]$ cat VERSION
clusterID=CID-f0330a58-36fa-4a2a-a65f-2688269b5837
[zzx@hadoop101 hadoop-2.7.2]$ cd data/tmp/dfs/data/current/
clusterID=CID-f0330a58-36fa-4a2a-a65f-2688269b5837![]()
如上图,DataNode 与 NameNode 的集群ID是相同的。如果格式化NameNode,会产生新的集群id,导致 NameNode和 DataNode的 集群id不同,集群找不到已往数据。就会出现启动了 NameNode 时,DataNode会挂掉。启动了DataNode时,NameNode会挂掉的问题。所以,格式NameNode时,一定要先删除 data数据和 log日志,然后再格式化NameNode。
五、HDFS 文件块大小
HDFS 中的文件在物理上是分块存储(Block),块的大小可以通过配置参数(dfs.blocksize)来规定,默认在 Hadoop2.x版本中是 128M,老版本是 64M。
![]()
HDFS 块大小设置:为什么块的大小不能设置太小,也不能设置太大
【1】HDFS 块设置太小,会增加寻址时间,程序一直在找块的位置;
【2】如果块设置的太大,从磁盘传输数据的时间会明显大于块定位的时间。导致程序在处理块数据时,会非常慢。
总结:HDFS 块的大小设置取决于磁盘传输速率
六、setrep 设置副本数
如果设置了10个副本,但是目前只有三台服务器,如果后续增加了服务器,会怎样?
hadoop fs -setrep 10 /sanguo/shuguo/kongming.txt![]()

![]() 这里设置的副本数只是记录在NameNode的元数据中,是否真的会有这么多副本,还得看DataNode的数量。因为目前只有3台设备,最多也就3个副本,只有节点数的增加到10台时,副本数才能达到10。
这里设置的副本数只是记录在NameNode的元数据中,是否真的会有这么多副本,还得看DataNode的数量。因为目前只有3台设备,最多也就3个副本,只有节点数的增加到10台时,副本数才能达到10。
七、HDFS 读数据流程
HDFS的读数据流程,如下图所示:
![]()
【1】客户端通过 Distributed FileSystem向 NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址进行返回。
【2】挑选一台 DataNode(就近原则,然后随机)服务器,请求读取数据。当第一次读取完成之后,才进行第二次块的读取。
【3】DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以 Packet为单位来做校验)。
【4】客户端以 Packet为单位接收,先在本地缓存,然后写入目标文件。
八、HDFS 写数据流程
HDFS 文件写入流程图如下:三个模块(客户端、NameNode、DataNode)
![]()
【1】校验:客户端通过 DistributedFileSystem 模块向 NameNode 请求上传文件,NameNode 会检查目标文件是否已经存在,父目录是否存在。
【2】响应:NameNode 返回是否可以上传的信号。
【3】请求 NameNode:客户端对上传的数据根据块进行切片,并请求第一块 Block 上传到哪几个 DataNode 服务器上。
【4】响应 DataNode节点信息:NameNode 根据副本数等信息返回可上传的DataNode节点,例如这里的 dn1,dn2,dn3。
【5】建立通道:客户端通过 FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
【6】DataNode 响应 Client:dn1、dn2、dn3逐级应答客户端。
【7】上传数据到DataNode:客户端开始往 dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以 Packet为单位,dn1收到一个 Packet就会传给 dn2,dn2传给 dn3;dn1每传一个 packet会放入一个应答队列等待应答。
【8】通知 NameNode上传完成:当一个 Block传输完成之后,客户端再次请求 NameNode上传第二个 Block的服务器。
【9】关闭输入输出流。
大数据面试——HDFS的更多相关文章
- 面试系列二:精选大数据面试真题JVM专项-附答案详细解析
公众号(五分钟学大数据)已推出大数据面试系列文章-五分钟小面试,此系列文章将会深入研究各大厂笔面试真题,并根据笔面试题扩展相关的知识点,助力大家都能够成功入职大厂! 大数据笔面试系列文章分为两种类型: ...
- 我要进大厂之大数据Hadoop HDFS知识点(1)
01 我们一起学大数据 老刘今天开始了大数据Hadoop知识点的复习,Hadoop包含三个模块,这次先分享出Hadoop中的HDFS模块的基础知识点,也算是对今天复习的内容进行一次总结,希望能够给想学 ...
- 老李分享:大数据测试之HDFS文件系统
poptest是国内唯一一家培养测试开发工程师的培训机构,以学员能胜任自动化测试,性能测试,测试工具开发等工作为目标.如果对课程感兴趣,请大家咨询qq:908821478,咨询电话010-845052 ...
- 大数据(1)---大数据及HDFS简述
一.大数据简述 在互联技术飞速发展过程中,越来越多的人融入互联网.也就意味着各个平台的用户所产生的数据也越来越多,可以说是爆炸式的增长,以前传统的数据处理的技术已经无法胜任了.比如淘宝,每天的活跃用户 ...
- FusionInsight大数据开发---HDFS应用开发
HDFS应用开发 HDFS(Dadoop Distributed File System) HDFS概述 高容错性 高吞吐量 大文件存储 HDFS架构包含三部分 Name Node DataNode ...
- 我要进大厂之大数据Hadoop HDFS知识点(2)
01 我们一起学大数据 老刘继续分享出Hadoop中的HDFS模块的一些高级知识点,也算是对今天复习的HDFS内容进行一次总结,希望能够给想学大数据的同学一点帮助,也希望能够得到大佬们的批评和指点! ...
- 【大数据面试】【框架】Hadoop-入门、HDFS
一.入门 1.常用端口号 2.x 50070:查看HDFS Web-UI 8088:查看MapReduce运行情况 19888:历史服务器 9000:hdfs客户端访问集群 50090:Seconda ...
- 【大数据面试】sqoop:空值、数据一致性、列式存储导出、数据量、数据倾斜
一.有没有遇到过问题,怎么进行解决的 1.空值问题 本质:hive底层存储空数据使用\n<==>MySQL存储空数据使用null 解决:双向导入均分别使用两个参数☆,之前讲过 2.数据一致 ...
- Hadoop大数据面试--Hadoop篇
本篇大部分内容參考网上,当中性能部分參考:http://blog.cloudera.com/blog/2009/12/7-tips-for-improving-mapreduce-performanc ...
- Java+大数据开发——HDFS详解
1. HDFS 介绍 • 什么是HDFS 首先,它是一个文件系统,用于存储文件,通过统一的命名空间--目录树来定位文件. 其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角 ...
随机推荐
- ssh-add
ssh-add -l https://www.jianshu.com/p/0c6719f33fb9 添加秘钥,而不是公钥
- 解决通过Eclipse启动Tomcat-Run On Server无法选择Tomcat v7.0的问题
在eclipse中配置Tomcat并启动右键项目 -> Run As -> Run on Server可能会出现无法选择Tomcat v7.0的现象如下图,不慌菜鸟小编带你解决!1.定位到 ...
- HDFS 内部工作机制
HDFS 内部工作机制 HDFS集群分为两大角色:NameNode.DataNode (Secondary Namenode) NameNode 负责管理整个文件系统的元数据 DataNode 负责管 ...
- dos命令初学
DOS命令 打开DOS命令方式 开始+系统+命令提示符 WIN键盘+R 输入CMD 打开控制台(推荐使用) 在任意文件夹下面,按住shift键加鼠标右键点击,在此处打开命令行窗口 自愿管理器的地址栏前 ...
- 一键搭建dns
#!/bin/bash DOMAIN=wang.orgHOST=wwwHOST_IP=10.0.0.100LOCALHOST=`hostname -I | awk '{print $1}'` . /e ...
- Array of products
refer to: https://www.algoexpert.io/questions/Array%20Of%20Products Problem Statement Sample input A ...
- 用shell开火车哈哈
用shell开火车!(σ゚∀゚)σ⁶⁶⁶⁶⁶⁶⁶⁶⁶⁶ while true; do sl -aFile; done 这个效果更佳
- Linux 格式化 挂载 Gdisk
对磁盘进行格式化mkfs 创建文件系统 xfs ext4/2/3 mkfs -b 设定数据区块(block)占用空间大小,目前支持1024.2048.4096 bytes每个块.默认4K mkfs - ...
- 07.异常、多线程、Lambda 表达式
一.异常 指的是程序在执行过程中,出现的非正常的情况,最终会导致JVM的非正常停止. 异常体系 根类 java.lang.Throwable 两个直接子类 java.lang.Error 严重错误Er ...
- 复制文件到U盘提示“一个意外错误使您无法复制该文件”处理办法
运行cmd 运行 chkdsk H(U盘所在盘符):/f 即可