使用jmh框架进行benchmark测试
性能问题
最近在跑flink社区1.15版本使用json_value函数时,发现其性能很差,通过jstack查看堆栈经常在执行以下堆栈
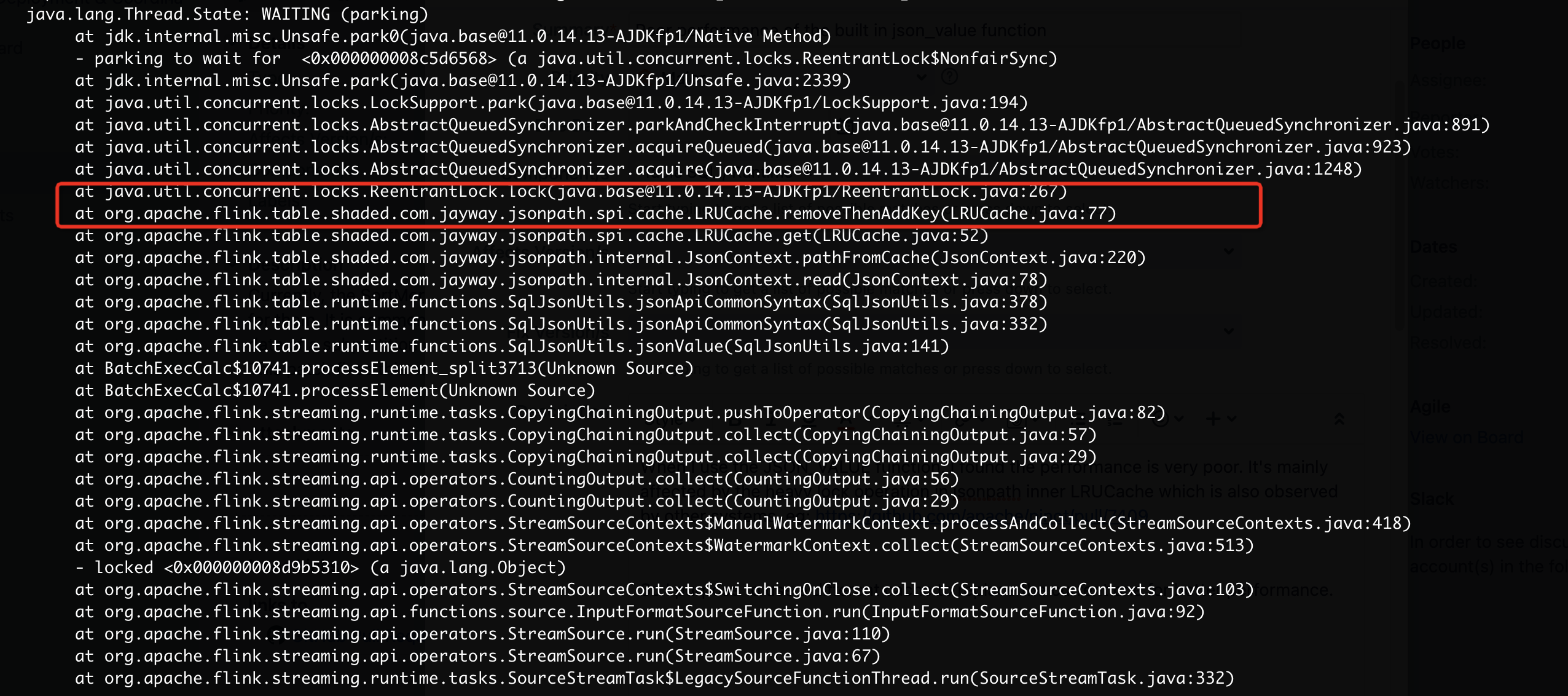
可以看到这里的逻辑是在等锁,查看jsonpath的LRUCache
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by FernFlower decompiler)
//
package org.apache.flink.table.shaded.com.jayway.jsonpath.spi.cache;
import java.util.Deque;
import java.util.LinkedList;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.locks.ReentrantLock;
import org.apache.flink.table.shaded.com.jayway.jsonpath.JsonPath;
public class LRUCache implements Cache {
private final ReentrantLock lock = new ReentrantLock();
private final Map<String, JsonPath> map = new ConcurrentHashMap();
private final Deque<String> queue = new LinkedList();
private final int limit;
public LRUCache(int limit) {
this.limit = limit;
}
public void put(String key, JsonPath value) {
JsonPath oldValue = (JsonPath)this.map.put(key, value);
if (oldValue != null) {
this.removeThenAddKey(key);
} else {
this.addKey(key);
}
if (this.map.size() > this.limit) {
this.map.remove(this.removeLast());
}
}
public JsonPath get(String key) {
JsonPath jsonPath = (JsonPath)this.map.get(key);
if (jsonPath != null) {
this.removeThenAddKey(key);
}
return jsonPath;
}
private void addKey(String key) {
this.lock.lock();
try {
this.queue.addFirst(key);
} finally {
this.lock.unlock();
}
}
private String removeLast() {
this.lock.lock();
String var2;
try {
String removedKey = (String)this.queue.removeLast();
var2 = removedKey;
} finally {
this.lock.unlock();
}
return var2;
}
private void removeThenAddKey(String key) {
this.lock.lock();
try {
this.queue.removeFirstOccurrence(key);
this.queue.addFirst(key);
} finally {
this.lock.unlock();
}
}
private void removeFirstOccurrence(String key) {
this.lock.lock();
try {
this.queue.removeFirstOccurrence(key);
} finally {
this.lock.unlock();
}
}
...
}
可以看到get操作时,如果获取到的是有值的,那么会更新相应key的数据从双端队列移到首位,借此来实现LRU的功能,但是这样每次get和put操作都是需要加锁的,因此并发情况下吞吐就会比较低,也会导致cpu使用效率较低。
从jsonpath社区查看相应的问题,也有相关的反馈
https://github.com/json-path/JsonPath/issues/740
https://github.com/apache/pinot/pull/7409
比较方便的是,jsonpath 提供了spi的方式可以自定义的设置Cache的实现类,可以通过以下方式来设置新的cache实现。
static {
CacheProvider.setCache(new JsonPathCache());
}
从pinot的实现中,我们看到他是用了guava的cache来替换了默认的LRUCache实现,那么这样实现性能优化有多少呢,这里我们是用java的性能测试框架jmh来测试下性能提升的情况
性能测试
这里为了方便,直接在flink-benchmark工程里添加了两个benchmark的测试类.
GuavaCache
LRUCache
这里面需要注意,因为cache是进程级别共享的,所以我们需要将设置@State(Benchmark)级别,这样我们构建的cache就是进程级别共享,而不是线程级别共享的。
写的测试是4个线程运行,缓存大小均为400
为了避免在本机运行时受本机的其他程序影响,最好是build jar之后放到服务器上跑
java -jar target/benchmarks.jar -rf csv org.apache.flink.benchmark.GuavaCacheBenchmark
得到一个测试结果
Benchmark Mode Cnt Score Error Units
GuavaCacheBenchmark.get thrpt 30 4480.563 ± 203.311 ops/ms
GuavaCacheBenchmark.put thrpt 30 1774.769 ± 119.198 ops/ms
LRUCacheBenchmark.get thrpt 30 441.239 ± 2.812 ops/ms
LRUCacheBenchmark.put thrpt 30 350.549 ± 12.285 ops/ms
可以看到使用guava的cache后,get性能提升8倍左右,put性能提升5倍左右。
这块性能提升的主要来源是cache的实现机制上,和caffeine 的作者在github上也简单了解了下相关的推荐实现
后面会写一篇文章来专门分析下caffeine cache的优化实现。
参考
https://github.com/ben-manes/caffeine/wiki/Benchmarks#read-100-1 caffeine benchmark
https://github.com/ben-manes/caffeine/blob/master/caffeine/src/jmh/java/com/github/benmanes/caffeine/cache/GetPutBenchmark.java caffeine benchmark
https://www.jianshu.com/p/ad34c4c8a2a3 jmh 框架常见参数
http://hg.openjdk.java.net/code-tools/jmh/file/tip/jmh-samples/src/main/java/org/openjdk/jmh/samples/ jmh 常见用例
使用jmh框架进行benchmark测试的更多相关文章
- IOS(SystemConfiguration)框架中关于测试连接网络状态相关方法
1. 在SystemConfiguration.famework中提供和联网相关的function, 可用来检查网络连接状态. 2. SC(SystemConfiguration)框架中关于测试连接网 ...
- Spring框架下Junit测试
Spring框架下Junit测试 一.设置 1.1 目录 设置源码目录和测试目录,这样在设置产生测试方法时,会统一放到一个目录,如果没有设置测试目录,则不会产生测试代码. 1.2 增加配置文件 Res ...
- [转帖]TPC-C解析系列01_TPC-C benchmark测试介绍
TPC-C解析系列01_TPC-C benchmark测试介绍 http://www.itpub.net/2019/10/08/3334/ 学习一下. 自从蚂蚁金服自研数据库OceanBase获得TP ...
- <自动化测试>之<使用unittest Python测试框架进行参数化测试>
最近在看视频时,虫师简单提到了简化自动化测试脚本用例中的代码量,而python中本身的参数化方法用来测试很糟糕,他在实际操作中使用了parameterized参数化... 有兴趣就查了下使用的方法,来 ...
- Java8 Stream代码详解+BenchMark测试
Java8 Stream基础.深入.测试 1.基本介绍 1.创建方式 1.Array的Stream创建 1.直接创建 // main Stream stream = Stream.of("a ...
- python实例编写(6)--引入unittest测试框架,构造测试集批量测试(以微信统一管理平台为例)
---恢复内容开始--- 一.python单元测试实例介绍 unittest框架又叫PyUnit框架,是python的单元测试框架. 先介绍一个普通的单元测试(不用unittest框架)的实例: 首先 ...
- 修改testtools框架,将测试结果显示用例注释名字
在之前介绍的测试框架testtool中,发现测试结果中显示的都是测试用例的函数名,并没有将注释显示出来 这很不符合国人使用阿,没办法,自己动手来改改吧 首先,testtools是继承unittest的 ...
- 框架重构:测试中的DateTime.Now
存在的问题 DateTime.Now是C#语言中获取计算机的当前时间的代码: 但是,在对使用了DateTime.Now的方法进行测试时,由于计算机时间的实时性,期望值一直在变化.如:计算年龄. pub ...
- YCSB benchmark测试mongodb性能——和web服务器测试性能结果类似
转自:http://blog.sina.com.cn/s/blog_48c95a190102v9kg.html YCSB(Yahoo! Cloud Serving Benchmark) ...
随机推荐
- 安装Zabbix到Ubuntu(APT)
运行环境 系统版本:Ubuntu 16.04.2 LTS 软件版本:Zabbix-4.0.2 硬件要求:无 安装过程 1.安装APT-Zabbix存储库 APT-Zabbix存储库由Zabbix官网提 ...
- 新建Vue项目记得几个配置
1.在APP.vue文件夹中进行CSS初始化 2.下载vuex,vue-router,并配置 3.关闭语法检查vue.config.js 4.按需引入组件库
- 怎样生成分布式的流水ID
流水编号 日常在我们开发的过程中可能会用到编号的功能,如销售订单号,采购订单号,日志编号,凭证号...等等,为了保证唯一有些表的主键要么用自增长,要么用GUID值,或通过雪花ID算法生成.这此方式基本 ...
- Linux版本的项目环境搭建
项目环境docker及docker-compose文档 1.Linux环境介绍 centos7.6 16G以上内存空间(至少8G) 2.静态IP设置 1.找到配置文件 cd /etc/sysconfi ...
- vue-property-decorator
vue-property-decorator使我们能在vue组件中写TypeScript语法,依赖于vue-class-component 装饰器:@Component.@Prop.@PropSync ...
- 2021.05.04【NOIP提高B组】模拟 总结
T1 题目大意, \(S_{i,j}=\sum_{k=i}^j a_k\) ,求 \(ans=\min\{ S_{i,j}\mod P|S_{i,j}\mod P\ge K \}\) 其中 \(i\l ...
- Chrome自带功能实现网页截图
更新记录 本文迁移自Panda666原博客,原发布时间:2021年6月28日. 很简单,按下Ctrl+Shift+P,打开命令行窗口,如下图所示. 输入命令. Capture full size sc ...
- Java-调用R语言和调用Python(前后端展示)
1. 背景 R语言和Python用于数据分析和数据处理,并生成相应的直方图和散点图 需要实现一个展示平台,后端使用Java,分别调用R语言和调用Python,并返回数据和图给前端显示 这个平台主要实现 ...
- 【SpringBoot】YAML 配置文件
博客主页:准Java全栈开发工程师 00年出生,即将进入职场闯荡,目标赚钱,可能会有人觉得我格局小.觉得俗,但不得不承认这个世界已经不再是以一条线来分割的平面,而是围绕财富旋转的球面,成为有钱人不是为 ...
- Leetcode----<Re-Space LCCI>
题解如下: /** * 动态规划解法: * dp[i] 表示 0-i的最小不能被识别的字母个数 * 求 dp[k] 如果第K个字母 不能和前面的字母[0-{k-1}]合在一起被识别 那么dp[k] = ...