【达人专栏】还不会用Apache Dolphinscheduler吗,大佬用时一个月写出的最全入门教学【二】

02 Master启动流程
2.1 MasterServer的启动
在正式开始前,笔者想先鼓励一下大家。我们知道启动Master其实就是启动MasterServer,本质上与其他SpringBoot项目相似,即启动里面的main函数。但想要开始实操前,肯定有不少的人,尤其是初学者会突然发现这里面有十多个由bean注入的autowired。
被多个bean的注入搞到一头雾水,甚至感觉一脸懵逼的不是少数。但笔者就想说是,这些其实都是吓唬你们的,不用害怕,接下来将带领你们把这些bean分别解剖并归类,那么我们就正式开始。
第一类:MasterConfig、MasterRegistryClient、MasterSchedulerService、Scheduler这些bean。从字面意思来说,MasterConfig就是跟Master配置相关的,MasterRegistryClient就是负责注册相关的内容,MasterSchedulerService肯定跟Master调度有关的,说白了就是Master内部的东西。
第二类:是那些后缀名为一堆Processor的,例如taskExecuteRunningProcessor等。相同后缀一定处理同样的task,在以后肯定被某个东西一起加载的。
第三类:是EventExecuteService以及FailoverExecuteThread,这些根据名字可以大胆猜一下是与事件执行相关以及灾备转换相关的东西,这些肯定也是Master内部的东西,理论上应该归到第一类。
第四类:至于LoggerRequestProcessor就是与打印日志相关的了,至于这类具体干的内容,后面会有详细的介绍。
main方法执行完成后,基于spring特性,执行run方法。在run方法中,创建nettyRemotingServer对象(这个对象不是spring管理的,而是直接new创建的)。然后将第二类的一堆Processor放到netty的Processor里面去。从这里就可以推断,Master和Worker的通信一定是通过netty的。
我们可以看看下面的代码,其实就是将第一类的那些bean执行init以及start方法。
总结其实Master这就像一个总司令,这个总司令就调用这里面的bean的start方法,这些bean开始执行自己的功能,至于这些bean里面执行啥样的功能,MasterServer是懒得管,也没必要管了。
本节总结:
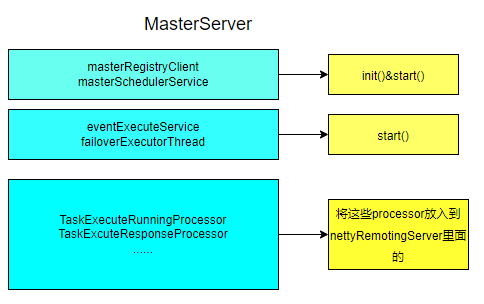
至此MasterServer就运行完了,下一节我们将逐个分析各个bean的用途以及功能的了。
2.2 MasterConfig的信息以及MasterRegistry Client的注册
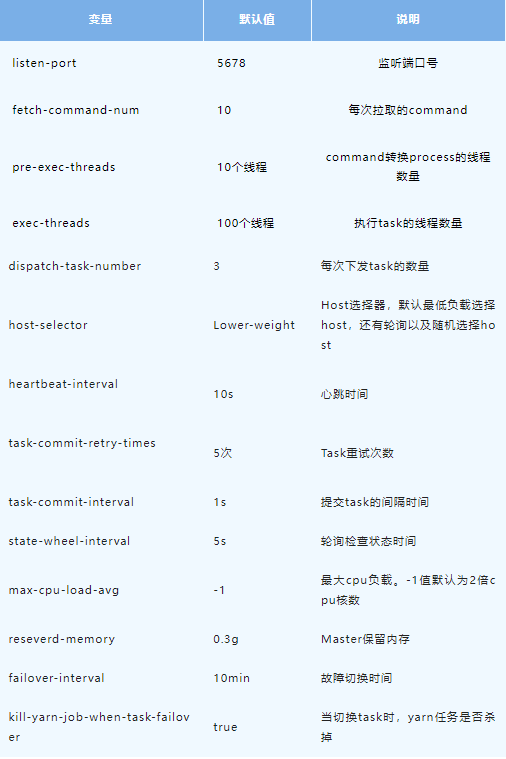
MasterConfig从application.yml中获取配置信息加载到MasterConfig类中,获取到的具体配置信息如下。
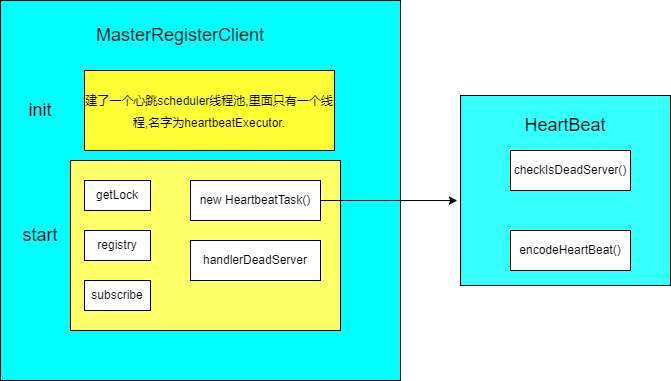
在MasterServer里,MasterRegisterConfig会执行init()以及start()方法。
init()方法新建了一个心跳线程池。注意,此时只是建了一个线程池,里面还没有心跳任务。
start()方法从zk获取了锁(getLock),注册信息(registry)以及监听注册的信息(subscribe)。
注册信息做了两件事情:
第一:构建心跳信息,并丢到线程池中运行心跳任务的。
第二:在zk临时注册该Master信息,并移除没用的Master信息。
心跳任务就是检查是否有死亡节点以及每隔10s(heartbeatInterval)将最新的机器信息,包括机器CPU,内存,PID等等信息注册到zk上去的。
监听订阅的信息,只要注册的信息有变化,就会立马感知,如果是增加了机器,则会打印日志。减少了机器,移除并同时打印日志。本节如下图所示:
2.3 ServerNodeManger的运行
前面两节是从MasterServer启动过程以及MasterRegisterConfig的注册过程的。注册完成之后Master,Worker如何管理呢,如何同步保存到数据库的呢。ServerNodeManager的作用就是负责这一部分的内容。
ServerNodeManager实现了InitializingBean接口的。基于spring的特性,构建此对象后,会执行AfterPropertiesSet()方法。做了三件事情:
- load()。从zk加载节点信息通过UpdateMasterNodes()到MasterPriorityQueue。
- 新建线程每十秒钟将zk的节点信息同步数据到数据库中。
- 监听zk节点,实时把最新数据通过UpdateMasterNodes()方法更新到MasterPriorityQueue队列中去。
几乎所有的更新操作都是通过重入锁来实现的,这样就能确保多线程下系统是安全的。此外,还有一个细节是如果是移除节点会发送警告信息。
MasterProrityQueue里面有个HashMap,每台机器对应一个index,以这样的方式构建了槽位。后面去找Master信息的时候就是通过这index去找的。
至于MasterBlockingQueue队列的内容,如何同步到数据库的,如何将数据放到队列和队列中移除数据等,这些都是纯crud的内容,读者可以自行阅读的。
2.4 MasterSchedulerService的启动
2.1到2.3讲述都是由zk管理的节点信息的事情。为什么我们要在Master启动之后会先讲节点信息的?
理由其实很简单,因为不管是Master还是Worker归根结底都是机器。如果这些机器崩了或者增加了,DS不知道的话,那这机器岂不是浪费了。只有机器运行正常,配置正常,都管理好了,那DS运行才能够顺畅地运行。同样,其他大数据组件也是类似的道理。
前面MasterServer里MasterRegisterClient执行完init()以及start()方法之后,紧接着MasterSchedulerService执行了init()和start()方法。从这里开始就真正的进入了Master干活的阶段了。
init()方法是创建了一个Master-Pre-Exec-Thread线程池以及netty客户端的。
Pre-exec-Thread线程池里面有固定的10个线程(在2.1中对应的是MasterConfig配置里面的pre-exec-threads)。这些线程处理就是从command里构建ProcessInstance(流程实例)过程的。
start方法就是启动了状态轮询执行(StateWheelExecutorThread)的线程,这线程专门就干的是检查task,process,workflow超时以及task状态的过程,符合条件的都被移除了。
其中,MasterSchedulerService本身继承了thread类,在start方法过后,就立马执行了run方法。在run方法中确保机器有了足够的CPU和内存之后,就会执行ScheduleProcess方法。至于ScheduleProcess做的事情,将在2.5说明。
2.5 MasterSchedulerService的执行
ScheduleProcess方法
ScheduleProcess是在MasterSchedulerService中的while死循环里面的,所以它会依次循环执行下面4个方法。
- FindCommands方法。从t_ds_command表中每次取出10条数据,并且这10条数据都是根据slot查找出来的,查找完成后,可以在MasterConfig.FetchCommandNum中进行配置。
- CommandProcessInstance将这些command表中转换成ProcessInstance。这里用到了CountdownLatch,目的是全部转换完成才执行以后的方法。
- 将转换好的processInstance一个一个的构建成workFlowExecuteThread对象,将这些对象通过workFlowExecuteThreadPool线程池中的线程一个一个执行的,并且将任务实例和工作流在processInstanceExecCacheManager缓存起来。
- 在这个线程池中运行StartWorkFlow方法后,执行WorkFlowExecuteThread的StartProcess方法的,StartProcess做了哪些事情将在2.6说明的。
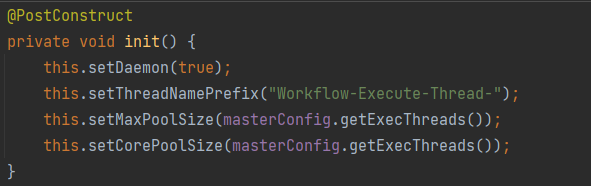
这个线程池交给了spring管理,而且属于后台线程。它的最大数量以及核心数量的线程池都是100个(MasterConfig.getExecThreads)。详细如下图:
这里有两个细节要说明一下,
第一:WorkflowExecuteThread它并不是继承了Thread类,而是一个普通类。只是类名字后面有个Thread,所以阅读的时候不要在此类找start或者run方法了。
第二:SchedulerProcess方法里面如果找到的ProcessInstance是超时的话,
就会交给2.4说的状态轮询线程(stateWheelExecuteThread)去执行的,将这个ProcessInstance进行移除。
2.6 WorkflowExecutorThread里执行StartProcess方法
StartProcess这个方法就直接先看图的了。
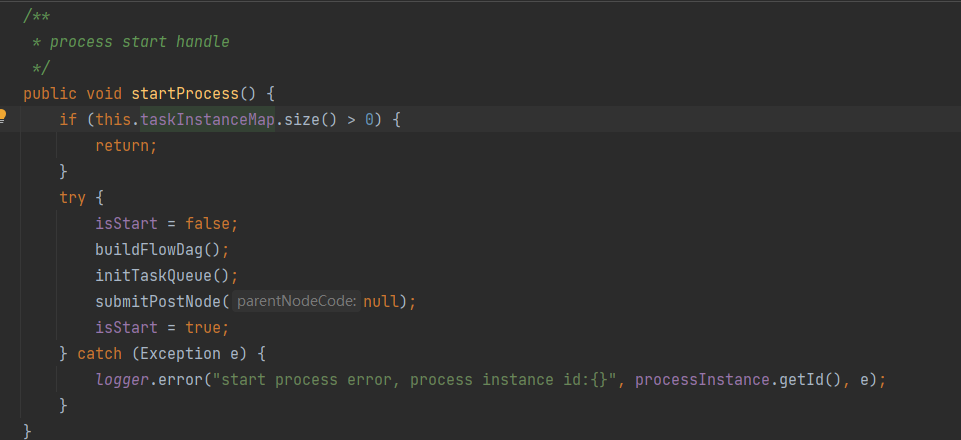
StartProcess就干了三件事请,buildFlowDag()构建了DAG,initTaskQueue()初始化task队列以及submitPostNode()提交节点的。
构建DAG如何干的,初始化队列中又干了什么事情,提交节点后又干了什么事情的,将在2.7到2.9章节说明。
2.7 WorkflowExecutorThread里执行buildFlowDag方法
根据buildFlowDag里面的代码,梳理了一下执行过程,分别为下面9步:
- FindProcessDefinition获取流程定义,就是要构建哪个流程的DAG的。
- GetStartTaskInstanceList获取流程下有哪些任务实例,一般情况下,一个流程肯定有不止一个任务。
- FindRelationByCode获取任务关系表(ProcessTaskRelation)中的数据。
- GetTaskDefineLogListByRelation通过第3步获取的任务关系数据确定任务定义日志(TaskDefinitionLog)的数据的。
- TransformTask就是通过第3步和第4步获取到Relation和Log转换成任务节点TaskNode。
- GetRecoveryNodeCodeList获取到的是task里的nodeCode。
- ParseStartNodeName获取到的是命令的参数。
- 根据第5、第6、第7获取到数据,构建了流程的DAG(ProcessDag)。
- 将构建好的ProcessDag数据转换成DAG数据。
基本逻辑就是上面的步骤的。当然,每一步都会有些更多的逻辑,但这些本质上都是数据结构变来变去的。如果读者写过业务方面的代码,这点肯定不陌生的。所以就不详细的说明了。
可能有读者对于DAG是什么,下面是DAG的简介链接,阅读之后理解起来应该并不难。
https://dolphinscheduler.apache.org/zh-cn/blog/DAG.html
这个链接是在理论上介绍DAG,如果对DAG想要在实践上更深入的认识,在dao模块的test文件夹下搜索DagHelperTest类,这里面有5个test的操作的,大家可以都运行一下(Debug形式),就会对DAG有着更深入的认识的。
还有两个链接跟本节有关的。这两个链接是关于dag中任务关系的改造的。就是1.3版本以前保存任务之间的关系只是以字段的形式进行保存,后来发现数据量很大不可行之后,就把这个字段拆成多个表了。读者可以阅读一下的。
https://dolphinscheduler.apache.org/zh-cn/blog/dolphinscheduler_json.html
https://dolphinscheduler.apache.org/zh-cn/blog/json_split.html
这构建DAG(有向无环图)目的就是在前端拖拉拽的任务告诉Master任务的执行顺序,也就是告诉Master哪些任务先执行,哪些任务后执行。
2.8 WorkflowExexutorThread里执行InitTaskQueue方法
InitTaskQueue里面干了3件重要事情:
- 初始化4个map,分别是ValidTaskMap,ErrorTaskMap,ActiveTaskProcessorMaps,CompleteTaskMap。就是将找到的task和process按valid(有效),complete(完成),error(失败),active(运行)为根据,保存到不同的map中(这些map都是以taskCode作为key),这些map将在后面的方法中用到的。
- 如果task是可以重试的,就是通过addTaskToStandByList将其放到readyToSubmitTaskQueue队列中。
- 如果开启了补数状态的话,那就设置具体的补数时间以及全局参数,将其更新到流程实例中。
(笔者觉得这个InitTaskQueue方法名字并不是很好,可能觉得InitTask或者InitTaskMap会更好的。因为Queue的话很容易误认为是队列的,这个方法只是构建了4个map的。而且队列也只是放了可以重试的任务的,这个队列在下面章节中还有更大的用处的。)
2.9 WorkFlowExecutorThread里执行SubmitPostNode方法
SubmitPostNode干了6件事情:
- DagHelper.ParsePostNodes(dag)把2.8最后生成的DAG解析出来TaskNodeList。
- 根据TaskNodeList生成TaskInstance集合。
- 如果只有一个任务运行的话,将TaskInstance参数配置传递给ProcessInstance。
- 将TaskInstance通过AddTaskToStandByList方法放到ReadyToSubmitTaskQueue队列去。
- SubmitStandByTask提交这些task。
- UpdateProcessInstanceState是更新流程实例状态的。
最重要的就是最后两件事情,就是将TaskInstance放到队列里和更新流程实例。更新流程实例纯属数据结构的变化的,这点并不难的。放到队列中的task如何处理,接下来将怎么做,
也就是SubmitStandByTask干了哪些事情将在后续章节中说明。
【达人专栏】还不会用Apache Dolphinscheduler吗,大佬用时一个月写出的最全入门教学【二】的更多相关文章
- 达人专栏 | 还不会用 Apache Dolphinscheduler?大佬用时一个月写出的最全入门教程【三】
作者 | 欧阳涛 招联金融大数据开发工程师 02 Master启动流程 2.10 WorkFlowExecutorThread 里执行 Submit StandByTask 方法 SubmitStan ...
- Apache DolphinScheduler 3.0.0 正式版发布!
点亮 ️ Star · 照亮开源之路 GitHub:https://github.com/apache/dolphinscheduler 版本发布 2022/8/10 2022 年 8 ...
- Apache DolphinScheduler&TiDB联合Meetup | 聚焦开源生态发展下的应用开发能力
在软件开发领域有一个流行的原则:Don't Repeat Yourself(DRY),翻译过来就是:不要重复造轮子.而开源项目最基本的目的,其实就是为了不让大家重复造轮子. 尤其是在大数据这样一个高速 ...
- 杭州思科对 Apache DolphinScheduler Alert 模块的改造
杭州思科已经将 Apache DolphinScheduler 引入公司自建的大数据平台.目前,杭州思科大数据工程师 李庆旺 负责 Alert 模块的改造已基本完成,以更完善的 Alert 模块适应实 ...
- 数据平台调度升级改造 | 从Azkaban 平滑过度到 Apache DolphinScheduler 的操作实践
Fordeal的数据平台调度系统之前是基于Azkaban进行二次开发的,但是在用户层面.技术层面都存在一些痛点问题难以被解决.比如在用户层面缺少任务可视化编辑界面.补数等必要功能,导致用户上手难体验差 ...
- 倒计时2日!基于 Apache DolphinScheduler&TiDB 的交叉开发实践,从编写到调度让你大幅提升效率
当大数据挖掘成为企业赖以生存.发展乃至转型的生命,如何找到一款好软件帮助企业满足需求,成为了许多大数据工程师困扰的问题.但在当下高速发展的大数据领域,光是一款好软件似乎都不足以满足所有场景业务需求,许 ...
- Apache DolphinScheduler 1.2.1 发布说明
Apache DolphinScheduler 于2020年2月24日正式发布 1.2.1 版,发布内容如下: 新特性: [#1497] 通过 API 创建的工作流在前端展示时自动调整布局. [#74 ...
- Apache DolphinScheduler 需要的sudo,还可以这么玩,长见识了!
Apache DolphinScheduler(incubator)需要的sudo,还可以这么玩,长见识了! 在新一代大数据任务调度 - Apache DolphinScheduler(以下简称dol ...
- Apache DolphinScheduler新一代分布式工作流任务调度平台实战-上
概述 定义 dolphinscheduler 官网地址 https://dolphinscheduler.apache.org/ dolphinscheduler GitHub地址 https://g ...
随机推荐
- Java基础(1)——ThreadLocal
1. Java基础(1)--ThreadLocal 1.1. ThreadLocal ThreadLocal是一个泛型类,当我们在一个类中声明一个字段:private ThreadLocal<F ...
- 深入浅出Nginx实战与架构
本文主要内容如下(让读者朋友们深入浅出地理解Nginx,有代码有示例有图): 1.Nginx是什么? 2.Nginx具有哪些功能? 3.Nginx的应用场景有哪些? 4.Nginx的衍生生态有哪些? ...
- C++:小包包的玩具
小包包的玩具 时间限制 : 1.000 sec 内存限制 : 128 MB 题目描述: 小包包最讨厌的是整理他自己的玩具,为此,他制造了一个伟大的发明:玩具传送门!利用这个传送门,他可以 ...
- redis+lua实现脚本一键查询
场景 经常需要查redis某个key的值,需要执行三条命令才能查到 redis-cli,启动redis select num,选择db get key,查询语句 需要执行三条命令才能实现某个key的查 ...
- k8s中label和label selector的基本概念及使用方法
1.概述 在k8s中,有一个非常核心的概念,就是label(标签),以及对label的使用,label selector. 本文档中,我们就来看看:1.什么是标签,2.如何定义标签,3.什么是标签选择 ...
- AtCoder ABC 250 总结
AtCoder ABC 250 总结 总体 连续若干次一样的结果:30min 切前 4 题,剩下卡在 T5 这几次卡在 T5 都是一次比一次接近, 什么 dp 前缀和打挂,精度被卡,能水过的题连水法都 ...
- junit 5 - Display Name 展示名称
本文地址:https://www.cnblogs.com/hchengmx/p/14883563.html @DisplayName可以给 测试类 或者 测试方法来自定义显示的名称.可以支持 空格.特 ...
- Acwing 1927 自动补全(知识点:hash,二分,排序)
读完题目第一想法是trie树 ,不过好像没怎么做过trie树的题,看y总给的知识点是二分排序,所以就有了如下思路: 但是但是,看完其他题解之后才坚定了我的想法,原来真的是这样排序,暴力啊! 具体步骤 ...
- ExtJS直接加载HTML页面
ExtJS直接加载HTML页面 说明 ExtJS组件很不错,但再完美也有需要其他组件的时候,比如有时候就需要引入已经写好的HTML页面.主要的方法如下. 测试环境:ExtJS 7.4 使用html配置 ...
- pytorch初学
(pytorch_gpu) D:\pytorch-text>pythonPython 3.7.9 (default, Aug 31 2020, 17:10:11) [MSC v.1916 64 ...