选择Key-Value Store
【IT168 专稿】在之前的文章中,给大家介绍了《Redis快速入门:Key-Value存储系统简介》,今天进一步给大家介绍为什么选择Key-Value Store。Key-Value Store是当下比较流行的话题,尤其在构建诸如搜索引擎、IM、P2P、游戏服务器、SNS等大型互联网应用以及提供云计算服务的时候,怎样保证系统在海量数据环境下的高性能、高可靠性、高扩展性、高可用性、低成本成为所有系统架构们挖苦心思考虑的重点,而怎样解决数据库服务器的性能瓶颈是最大的挑战。
大量的互联网用户选择Key-Value Store的原因具体是什么呢? 主要分为下面的2个主要原因:
1、大规模的互联网应用
对于google,ebay这样的互联网企业,每时每刻都有无数的用户在使用它们提供的互联网服务,这些服务带来的就是大量的数据吞吐量,在同一时间,会并发的有成千上万的连接对数据库进行操作。在这种情况下,单台服务器或者几台服务器远远不能满足这些数据处理的需求,简单的升级服务器性能这样的scale up的方式也不行,所以唯一可以采用的办法就是scale out了。scale out的方法有很多种,但大致分为两类:一类仍然采用RDBMS,然后通过对数据库的垂直和水平切割将整个数据库部署到一个集群上,这种方法的优点在于可以采用RDBMS这种熟悉的技术,但缺点在于它是针对特定应用的,就是说,由于应用的不同,切割的方法是不一样的。
还有一类就是google所采用的方法,抛弃RDBMS,采用key-value形式的存储,这样可 以极大的增强系统的可扩展性(scalability),如果要处理的数据持续增大,多加机器就 可以了。事实上,key-value的存储就是由于BigTable等相关论文的发表慢慢进入人们的 视野的。
2、云存储
如果说上一个问题还有可以替代的解决方案(切割数据库)的话,那么对于云存储来说,也许key-value的store就是唯一的解决方案了。云存储简单点说就是构建一个大型的存储平台给别人用,这也就意味着在这上面运行的应用其实是不可控的。如果其中某个客户的应用随着用户的增长而不断增长时,云存储供应商是没有办法通过数据库的切割来达到scale的,因为这个数据是客户的,供应商不了解这个数据自然就没法作出切割。在这种情况下,key-value的store就是唯一的选择了,因为这种条件下的scalability必须是自动完成的,不能有人工干预。这也是为什么几乎所有的现有的云存储都是key-value形式的,例如Amazon的smipleDB,底层实现就是key-value,还有google的 GoogleAppEngine,采用的是BigTable的存储形式。也许唯一可能例外的是MS的解决方案,我在Qcon大会上听说MS的Azure平台的下一个版本中就会推出基于RDBMS的云存储,尽管我本人仍然对此保持怀疑。
Key-Value Store最大的特点就是它的可扩展性,这也就是它最大的优势。所谓的可扩展性,在我看来这里包括了两方面内容。一方面,是指Key-Value Store可以支持极大的数据的存储,它的分布式的架构决定了只要有更多的机器,就能够保证存储更多的数据。另一方面,是指它可以支持数量很多的并发的查询。对于RDBMS,一般几百个并发的查询就可以让它很吃力了,而一个Key-Value Store,可以很轻松的支持上千的并发查询。下面而简单的罗列了一些特点:
●Key-value store:一个 key-value 数据存储系统,只支持一些基本操作,如:SET(key, value) 和 GET(key) 等;
●分布式:多台机器(nodes)同时存储数据和状态,彼此交换消息来保持数据一致,可视为一个完整的存储系统。
●数据一致:所有机器上的数据都是同步更新的、不用担心得到不一致的结果;
●冗余:所有机器(nodes)保存相同的数据,整个系统的存储能力取决于单台机器(node)的能力;
●容错:如果有少数 nodes 出错,比如重启、当机、断网、网络丢包等各种 fault/fail 都不影响整个系统的运行;
●高可靠性:容错、冗余等保证了数据库系统的可靠性。
3、Redis实际应用案例
目前全球最大的Redis用户是新浪微博,在新浪有200多台物理机,400多个端口正在运行着Redis, 有+4G的数据跑在Redis上来为微博用户提供服务。
在新浪微博Redis的部署场景很多,大概分为如下的2种:
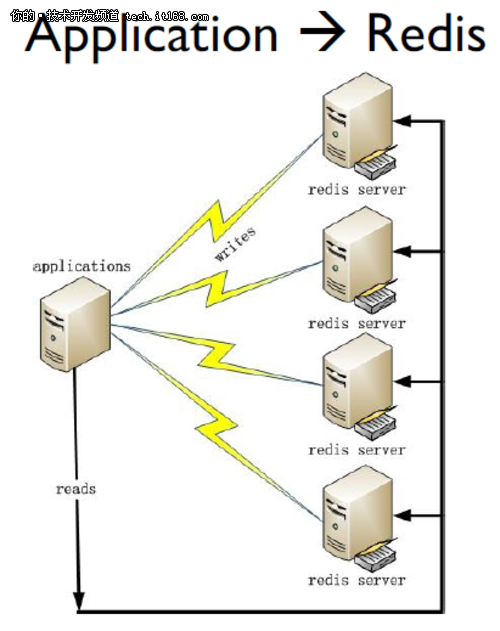
第一种是应用程序直接访问Redis数据库:
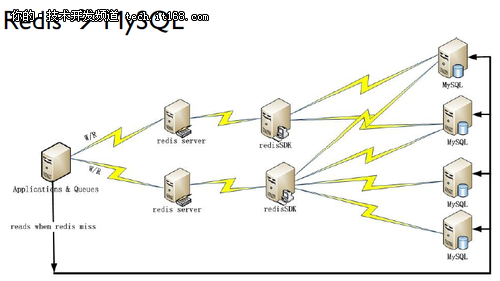
第二种是应用程序直接访问Redis,只有当Redis访问失败时才访问MySQL:
同时,Digg的一项新功能,添加了对文章浏览数的显示,这一功能的一大卖点是其实时性。而支持此实时浏览量计数的,正是Redis。
选择Key-Value Store的更多相关文章
- etcd -> Highly-avaliable key value store for shared configuration and service discovery
The name "etcd" originated from two ideas, the unix "/etc" folder and "d&qu ...
- External Configuration Store Pattern 外部配置存储模式
Move configuration information out of the application deployment package to a centralized location. ...
- iPhone应用提交流程:如何将App程序发布到App Store?
对于刚加入iOS应用开发行列的开发者来说,终于经过艰苦的Coding后完成了第一个应用后最重要的历史时刻就是将应用程序提交到iTunes App Store.Xcode 4.2开发工具已经把App提交 ...
- iPhone应用提交流程:如何将App程序发布到App Store
http://www.techolics.com/apple/20120401_197.html 对于刚加入iOS应用开发行列的开发者来说,终于经过艰苦的Coding后完成了第一个应用后最重要的历史时 ...
- 将App程序发布到苹果App Store
发布iOS应用程序到App Store - 前期工作 要发布iOS应用程序到App Store首先需要一个iOS developer帐号,账号是收费的,$99美元/年.即便是免费应用也需要一个开发者账 ...
- IIS部署SSL,.crt .key 的证书,怎么部署到IIS,记录一下,以免忘记。
SSL连接作用不说,百度很多.因为最近想考虑重构一些功能,在登录这块有打算弄成HTTPS的,然后百度了,弄成了,就记录一下,以便以后万一部署的时候忘记掉. 做实验的时候,拿的我个人申请的已经备案的域名 ...
- 对于AP中为什么有4个WEP KEY的分析
这篇文章简要分析一下为什么有4个WEP KEY,及其中的一些原因. SPEC 用过AP的都知道,AP中有4个WEP KEY,但是为什么要设置4个呢,这个是WEP帧的格式决定的: 图中的keyid是2个 ...
- store / cache 系列
### golang go-cache An in-memory key:value store/cache (similar to Memcached) library for Go, suitab ...
- mac 上如何安装非app store上的下载的软件-------打开未知来源
打开了 Terminal 终端后 ,在命令提示后输入 sudo spctl --master-disable 并按下回车执行,如下图所示. 随后再输入当前 Mac 用户的密码,如下图所示. 如 ...
- 内部排序->选择排序->简单选择排序
文字描述 简单排序的基本思想是:每一趟在n-i+1(i=1,2,…,n)个记录中选取关键字最小的记录作为有序列表中的第i个记录. 示意图 略 算法分析 简单排序算法中,所需进行记录移动的操作次数较少, ...
随机推荐
- 4、架构--NFS实践、搭建web服务、文件共享
笔记 1.晨考 1.数据备份的方式有哪些 全量和增量 2.数据备份的命令有哪些,都有哪些优点缺点 cp : 本地,全量复制 scp :远程,全量复制 rsync :远程,增量复制 3.rsync的参数 ...
- 7、Linux基础--权限、查看用户信息
笔记 1.晨考 1.Linux系统中的文件"身份证号"是什么 index node 号码 2.什么是硬链接,什么是软连接 硬链接是文件的入口,软连接是快捷方式. 3.硬链接中保存的 ...
- .NET 固定时间窗口算法实现(无锁线程安全)
一.前言 最近有一个生成 APM TraceId 的需求,公司的APM系统的 TraceId 的格式为:APM AgentId+毫秒级时间戳+自增数字,根据此规则生成的 Id 可以保证全局唯一(有 N ...
- Blob检测
一 Laplace 算子 使用一阶微分算子可以检测图像边缘.对于剧烈变化的图像边缘,一阶微分效果比较理想.但对于缓慢变化的图像边缘,通过对二阶微分并寻找过零点可以很精确的定位边缘中心.二阶微分即为 L ...
- 搭建 NFS 服务 & 实时同步
今日内容 NFS简介 实现 NFS 文件同步功能 NFS 配置详解 统一用户 搭建 web 服务 NFS 实现文件共享 内容详细 1.NFS 简介 1.1 介绍 实现多台 web 服务器可以共享数据资 ...
- Solution -「CF 1132G」Greedy Subsequences
\(\mathcal{Description}\) Link. 定义 \(\{a\}\) 最长贪心严格上升子序列(LGIS) \(\{b\}\) 为满足以下两点的最长序列: \(\{b\}\) ...
- MyBatis功能点一:二级缓存cache
对于Mybatis缓存分作用域等维度区别一.二级缓存特点如下图: 分析缓存源码首先得找到缓存操作的入口:前面已经分析,sqlsesion.close()仅对一级缓存有影响,而update等对一/二级缓 ...
- 为什么使用Mybatis对JDBC进行包装探究
一.原生JDBC在实际生产中使用存在的影响性能的问题 首先分析使用JDBC的代码: Connection connection = null; PreparedStatement preparedSt ...
- Numpy的各种下标操作
技术背景 本文所使用的Numpy版本为:Version: 1.20.3.基于Python和C++开发的Numpy一般被认为是Python中最好的Matlab替代品,其中最常见的就是各种Numpy矩阵类 ...
- WeifenLuo.WinFormsUI.Docking 简单入门
WinForm布局,开源且好用的貌似不多,WeifenLuo.WinFormsUI.Docking 这个是其中之一,这个唯一的不好地方,就是没有文档,只能通过读源码,不过它源码里面也提供了一个例子 ...