03、如何理解Kafka和Zookeeper的关系
001、Kafka简介
Apache Kafka最早是由Linkedin公司开发,后来捐献给了Apack基金会。
Kafka被官方定义为分布式流式处理平台,因为具备高吞吐、可持久化、可水平扩展等特性而被广泛使用。目前Kafka具体如下功能:
消息队列,Kafka具有系统解耦、流量削峰、缓冲、异步通信等消息队列的功能。
分布式存储系统,Kafka可以把消息持久化,同时用多副本来实现故障转移,可以作为数据存储系统来使用。
实时数据处理,Kafka提供了一些和数据处理相关的组件,比如Kafka Streams、Kafka Connect,具备了实时数据的处理功能。
Kafka的消息模型:[2]
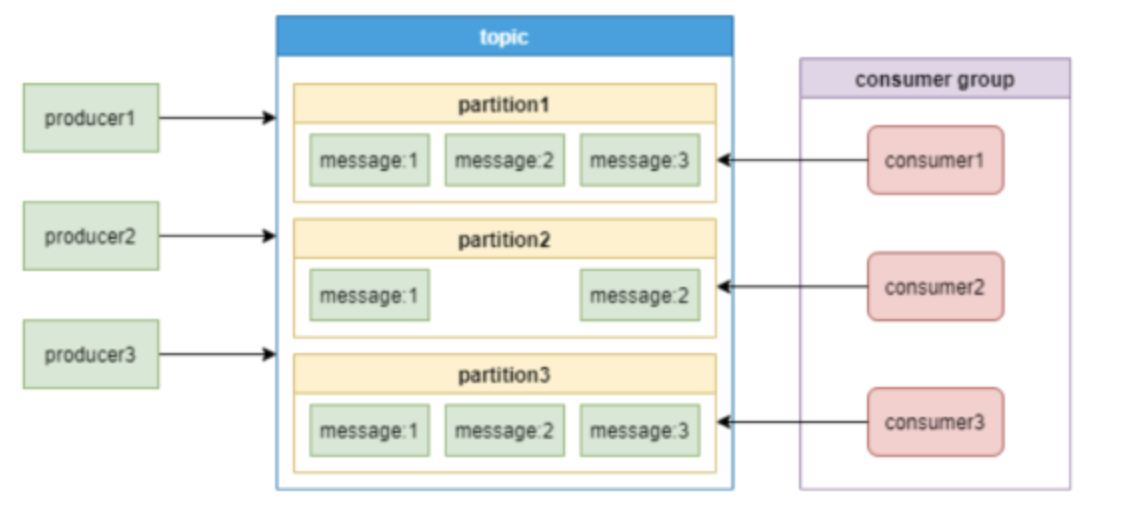
通过上面这张图,介绍一下Kafka中的几个主要概念:
producer和consumer: 消息队列中的生产者和消费者,生产者将消息推送到队列,消费者从队列中拉取消息。
consumer group:消费者集合,这些消费者可以并行消费同一个topic下不同partition中的消息。
broker:Kafka集群中的服务器。
topic:消息的分类。
partition:topic物理上的分组,一个topic可以有partition,每个partition中的消息会被分配一个有序的id作为offset。每个consumer group只能有一个消费者来消费一个partition。
002、Kafka和Zookeeper关系
Kafka架构如下图:图片从图中可以看到,Kafka的工作需要Zookeeper的配合。那他们到底是怎么配合工作呢?
看下面这张图:
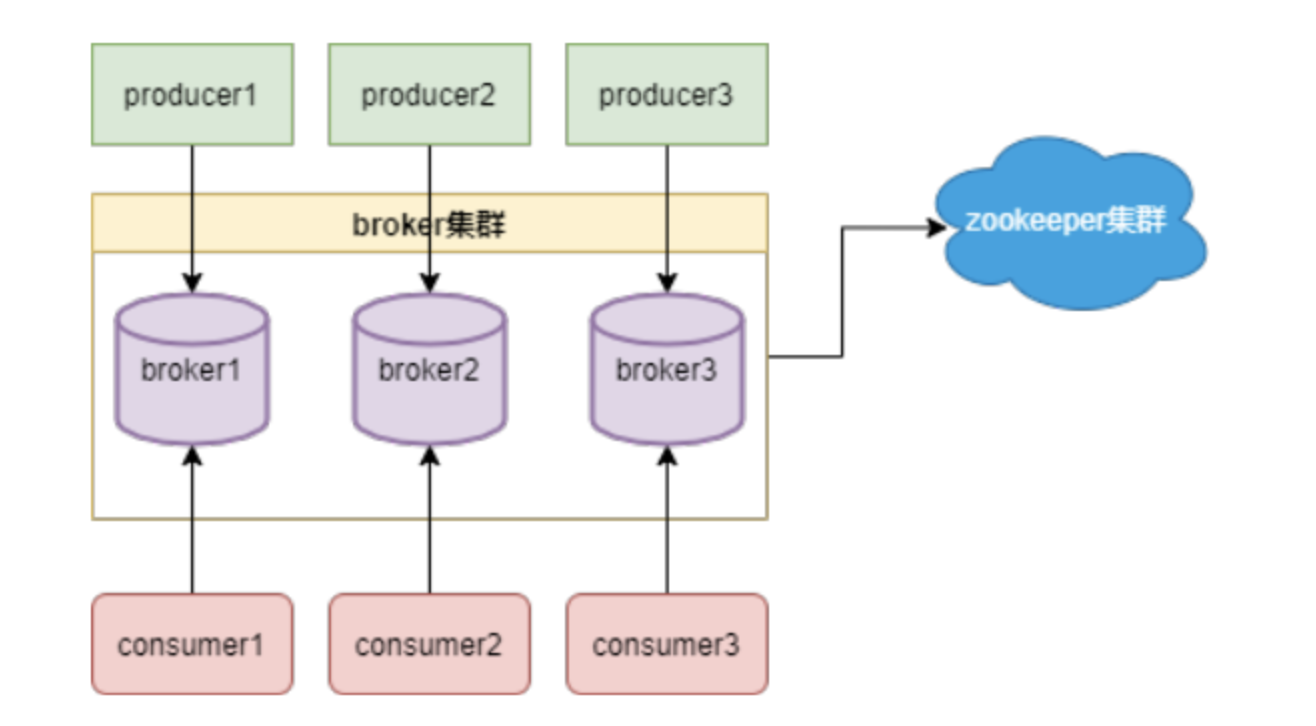
从图中可以看到,Kafka的工作需要Zookeeper的配合。那他们到底是怎么配合工作呢?
看下面这张图:
021、broker注册
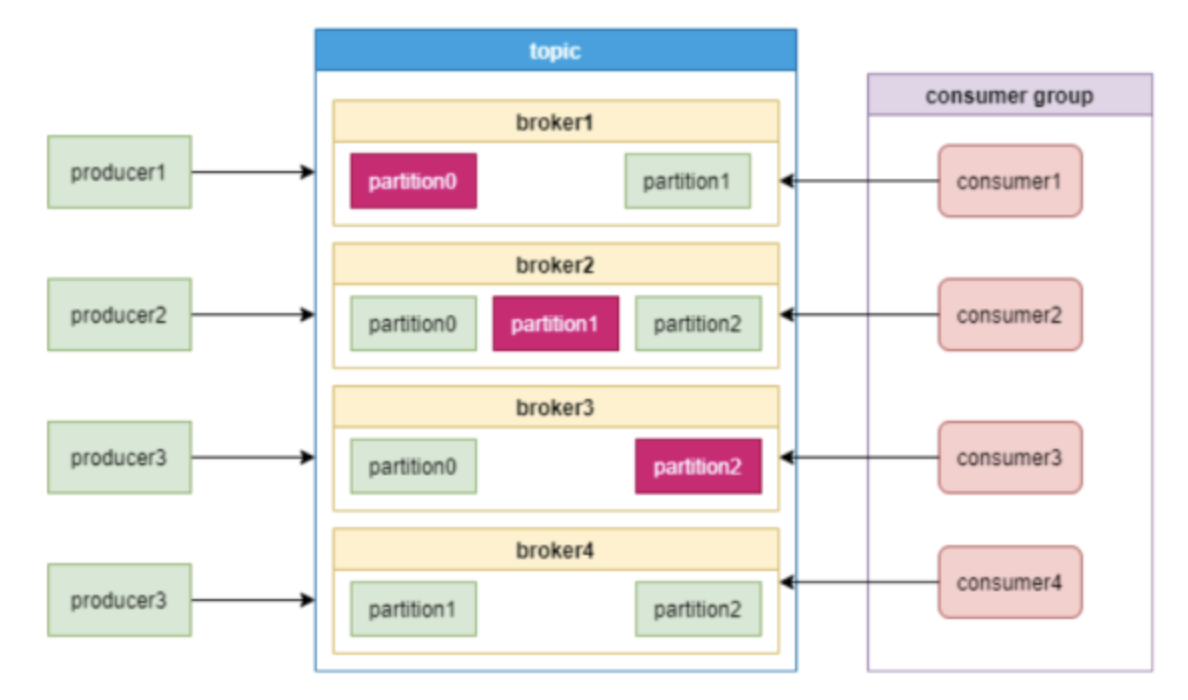
从上面的图中可以看到,broker分布式部署,就需要一个注册中心来进行统一管理。Zookeeper用一个专门节点保存Broker服务列表,也就是 /brokers/ids。
broker在启动时,向Zookeeper发送注册请求,Zookeeper会在/brokers/ids下创建这个broker节点,如/brokers/ids/[0...N],并保存broker的IP地址和端口。
这个节点临时节点,一旦broker宕机,这个临时节点会被自动删除。
022、topic注册
Zookeeper也会为topic分配一个单独节点,每个topic都会以/brokers/topics/[topic_name]的形式记录在Zookeeper。
一个topic的消息会被保存到多个partition,这些partition跟broker的对应关系也需要保存到Zookeeper。
partition是多副本保存的,上图中红色partition是leader副本。当leader副本所在的broker发生故障时,partition需要重新选举leader,这个需要由Zookeeper主导完成。
broker启动后,会把自己的Broker ID注册到到对应topic节点的分区列表中。
查看一个topic是xxx,分区编号是1的信息,命令如下:
[root@master] get /brokers/topics/xxx/partitions/1/state {"controller_epoch":15,"leader":11,"version":1,"leader_epoch":2,"isr":[11,12,13]}
023、consumer注册
消费者组也会向Zookeeper进行注册,Zookeeper会为其分配节点来保存相关数据,节点路径为/consumers/{group_id},有3个子节点,如下图:

这样Zookeeper可以记录分区跟消费者的关系,以及分区的offset。
024、负载均衡
broker向Zookeeper进行注册后,生产者根据broker节点来感知broker服务列表变化,这样可以实现动态负载均衡。
consumer group中的消费者,可以根据topic节点信息来拉取特定分区的消息,实现负载均衡。
实际上,Kafka在Zookeeper中保存的元数据非常多,看下面这张图:

随着broker、topic和partition增多,保存的数据量会越来越大。
003、kafka和zookeeper的交互(Controller)
Kafka离开Zookeeper是没有办法独立运行的。那Kafka是怎么跟Zookeeper进行交互的呢?
Kafka集群中会有一个broker被选举为Controller负责跟Zookeeper进行交互,它负责管理整个Kafka集群中所有分区和副本的状态。其他broker监听Controller节点的数据变化。
Controller的选举工作依赖于Zookeeper,选举成功后,Zookeeper会创建一个/controller临时节点。
Controller具体职责如下:
监听分区变化:比如当某个分区的leader出现故障时,Controller会为该分区选举新的leader。当检测到分区的ISR集合发生变化时,Controller会通知所有broker更新元数据。当某个topic增加分区时,Controller会负责重新分配分区。
监听topic相关的变化
监听broker相关的变化
集群元数据管理
下面这张图展示了Controller、Zookeeper和broker的交互细节:

Controller选举成功后,会从Zookeeper集群中拉取一份完整的元数据初始化ControllerContext,这些元数据缓存在Controller节点。当集群发生变化时,比如增加topic分区,Controller不仅需要变更本地的缓存数据,还需要将这些变更信息同步到其他Broker。
Controller监听到Zookeeper事件、定时任务事件和其他事件后,将这些事件按照先后顺序暂存到LinkedBlockingQueue中,由事件处理线程按顺序处理,这些处理多数需要跟Zookeeper交互,Controller则需要更新自己的元数据。
004、Zookeeper带来的问题
Kafka本身就是一个分布式系统,但是需要另一个分布式系统来管理,复杂性无疑增加了。
041、运维复杂度
使用了Zookeeper,部署Kafka的时候必须要部署两套系统,Kafka的运维人员必须要具备Zookeeper的运维能力。
042、Controller故障处理
Kafaka依赖一个单一Controller节点跟Zookeeper进行交互,如果这个Controller节点发生了故障,就需要从broker中选择新的Controller。如下图,新的Controller变成了broker3。

新的Controller选举成功后,会重新从Zookeeper拉取元数据进行初始化,并且需要通知其他所有的broker更新ActiveControllerId。老的Controller需要关闭监听、事件处理线程和定时任务。分区数非常多时,这个过程非常耗时,而且这个过程中Kafka集群是不能工作的。
043、分区瓶颈
当分区数增加时,Zookeeper保存的元数据变多,Zookeeper集群压力变大,达到一定级别后,监听延迟增加,给Kafaka的工作带来了影响。
所以,Kafka单集群承载的分区数量是一个瓶颈。而这又恰恰是一些业务场景需要的。
005、升级
升级前后的架构图对比如下:

KIP-500用Quorum Controller代替之前的Controller,Quorum中每个Controller节点都会保存所有元数据,通过KRaft协议保证副本的一致性。这样即使Quorum Controller节点出故障了,新的Controller迁移也会非常快。
官方介绍,升级之后,Kafka可以轻松支持百万级别的分区。
Kafak团队把通过Raft协议同步数据的方式Kafka Raft Metadata mode,简称KRaft
Kafka的用户体量非常大,在不停服的情况下升级是必要的。
目前去除Zookeeper的Kafka代码KIP-500已经提交到trunk分支,并且计划在未来的2.8版本发布。
Kafaka计划在3.0版本会兼容Zookeeper Controller和Quorum Controller,这样用户可以进行灰度测试
03、如何理解Kafka和Zookeeper的关系的更多相关文章
- 深入浅出理解基于 Kafka 和 ZooKeeper 的分布式消息队列
消息队列中间件是分布式系统中重要的组件,主要解决应用耦合,异步消息,流量削锋等问题.实现高性能,高可用,可伸缩和最终一致性架构,是大型分布式系统不可缺少的中间件. 本场 Chat 主要内容: Kafk ...
- Kafka在zookeeper中存储结构和查看方式
Zookeeper 主要用来跟踪Kafka 集群中的节点状态, 以及Kafka Topic, message 等等其他信息. 同时, Kafka 依赖于Zookeeper, 没有Zookeeper 是 ...
- Kafka 和 ZooKeeper 的分布式消息队列分析
1. Kafka 总体架构 基于 Kafka-ZooKeeper 的分布式消息队列系统总体架构如下: 如上图所示,一个典型的 Kafka 体系架构包括若干 Producer(消息生产者),若干 bro ...
- 深入理解Kafka核心设计及原理(三):消费者
转载请注明出处:https://www.cnblogs.com/zjdxr-up/p/16114877.html 深入理解Kafka核心设计及原理(一):初识Kafka 深入理解Kafka核心设计及原 ...
- 深入理解Kafka核心设计及原理(四):主题管理
转载请注明出处:https://www.cnblogs.com/zjdxr-up/p/16124354.html 目录: 4.1创建主题 4.2 优先副本的选举 4.3 分区重分配 4.4 如何选择合 ...
- 【转】快速理解Kafka分布式消息队列框架
from:http://blog.csdn.net/colorant/article/details/12081909 快速理解Kafka分布式消息队列框架 标签: kafkamessage que ...
- kafka与zookeeper
kafka简介 kafka (官网地址:http://kafka.apache.org)是一款分布式消息发布和订阅的系统,具有高性能和高吞吐率. 下载地址:http://kafka.apache.or ...
- 深入理解Kafka核心设计及原理(五):消息存储
转载请注明出处:https://www.cnblogs.com/zjdxr-up/p/16127749.html 目录: 5.1文件目录布局 5.2消息压缩 5.3日志索引 5.4日志文件及索引文件分 ...
- kafka及zookeeper安装
kafka_2.9.2-0.8.1.tgzzookeeper-3.4.8.tar.gz 安装 zookeeper1 export PATH=$PATH:/usr/local/zookeeper/bin ...
- java企业架构 spring mvc +mybatis + KafKa+Flume+Zookeeper
声明:该框架面向企业,是大型互联网分布式企业架构,后期会介绍linux上部署高可用集群项目. 项目基础功能截图(自提供了最小部分) 平台简介 Jeesz是一个分布式的框架,提供 ...
随机推荐
- 肖sir____Apsara Clouder云计算专项技能认证题目收集
Apsara Clouder云计算专项技能认证: Apsara Clouder云计算专项技能认证:云服务器ECS入门[认证考试真题分享](答案仅供参考) 单选13道题 1.下列哪一个不是重置ECS密码 ...
- windows搭建syncthing中继服务器和发现服务器
软件准备 1.stdiscosrv:发现服务器,下载地址 https://github.com/syncthing/discosrv/releases 2.strelaysrv:中继服务器,下载地址 ...
- Software--C#--grammer_Delegate--Event
2018-05-01 10:49:47 委托是一种类型,而事件是一个类或结构的成员,如同字段,属性.必须在类或结构中声明. 引申 - Observe 观察者模式 Publish/Subscribe ...
- supervisor(进程管理)
1.安装程序 yum -y install supervisor 2.路径文件 /etc/supervisord.d /etc/supervisord.conf 3.生成配置. echo_superv ...
- jmeter组件
1.进程:一个正在执行的程序就对应一个进程 线程:进程中的执行线索(一个进程有多个执行线索) 线程组:按照线程性质对线程进行分组 2.并发执行:多个线程同时执行 特点:执行结束的顺序和线程的启动顺序不 ...
- 当win7遭遇蓝屏代码0x0000006b
转载请注明来源:https://www.cnblogs.com/Sherlock-L/p/15069877.html 关键词:win7.蓝屏.0x0000006b 事发 话说在某个周末,当我打开电脑, ...
- clion+mx+stm32
- PowerShell Regex
PowerShell默认按每一行遍历去匹配模式 比如"aaa`nbbb"用"a.*b"是匹配不到的 需要用"(?s)a.*b"来匹配 1. ...
- ctfshow web入门 命令执行 web58-71
都是 POST传递参数 执行 eval() 函数 web58 if(isset($_POST['c'])){ $c= $_POST['c']; eval($c); }else{ highlight_f ...
- PostgreSQL-14 安装配置-wsl_v1_ubuntu22.04
环境准备 pgAdmin: Cisco2022 postgrep数据库: postgres: Postgres_2023 install https://learn.microsoft.com/en- ...