ElasticSearch 实现分词全文检索 - 概述
需求
做一个类似百度的全文搜索功能

所用的技术如下:
- ElasticSearch
- Kibana 管理界面
- IK Analysis 分词器
- SpringBoot
ElasticSearch 简介
ES 是一个使用Java语言并且基于Lucene编写的搜索引擎框架,他提供了分布式的全文搜索功能,提供了一个统一的基于Restful风格的WEB接口,官方客户端也对多种语言都提供了相应的API。
Lucene:Lucene本身就是一个搜索引擎的底层
分布式:ES主要是为了突出他的横向扩展能力。
全文检索:将一段词语进行分词,并且将分出来的单个词语统一放到一个分词库中,在搜索时,根据关键字去分词库中检查,找到匹配的内容。(倒排索引)
Restful 风格的WEB接口:操作ES很简单,只需要发送一个HTTP请求,并且根据请求方式的不同,携带参数,执行相应的功能。
应用广泛:Github, wiki, gold man 用ES每天维护将近10TB的数据。
ES 结构

索引
ES的服务中,可以创建多个索引,每个索引默认被分成5个分片存储(提高查询效率、存储容量),每个分片至少有一个备份分片
备份分片默认不会分担查询效率,当ES检索压力特别大的时候,备份分片才会帮助检索数据
备份的分片必须放在不同的服务器中(集群)

类型
索引可以分多个分版 ,每个分片中有多个type,ES版本不同,类型的创建也不同
7.x 默认不再支持自定投索引类型(默认类型为_doc)

文档
一个type又可以分多个 document 文档 (一个个文档,相当于RDB中的一行行数据),每个文档中有多个field属性
一个MySQL有多个数据库,一个库中有多个表,一张表中存放着多行数据,每行数据中分多个列

列
一个文档包括多个属性,相当于RDB中的字段

ES和Slor
Slor 在查询死数据时(不能改变的数据,不增加、不减少),速度相对ES更快一些。但是数据如果是实时改变时,Solr的查询速度会降低很多,ES的查询效率基本没有变化。
Solr搭建集群时,需要依赖Zookeeper来帮助管理。ES本身就支持集群的搭建,不需要第三方的介入
Solr针对国内的中文文档不多,ES社区火爆,文档健全
ES 对现在云计算和大数据支持特别好
倒排索引
将存放的数据,以一定的方式进行分词,并且将分词的内容存放到一个单独的分词库中。
当用户去查询数据时,会将用户的查询关键字进行分词
然后去分词库中匹配内容,最终得到数据的ID标识
根据ID标识去存放数据的位置拉取到指定的数据
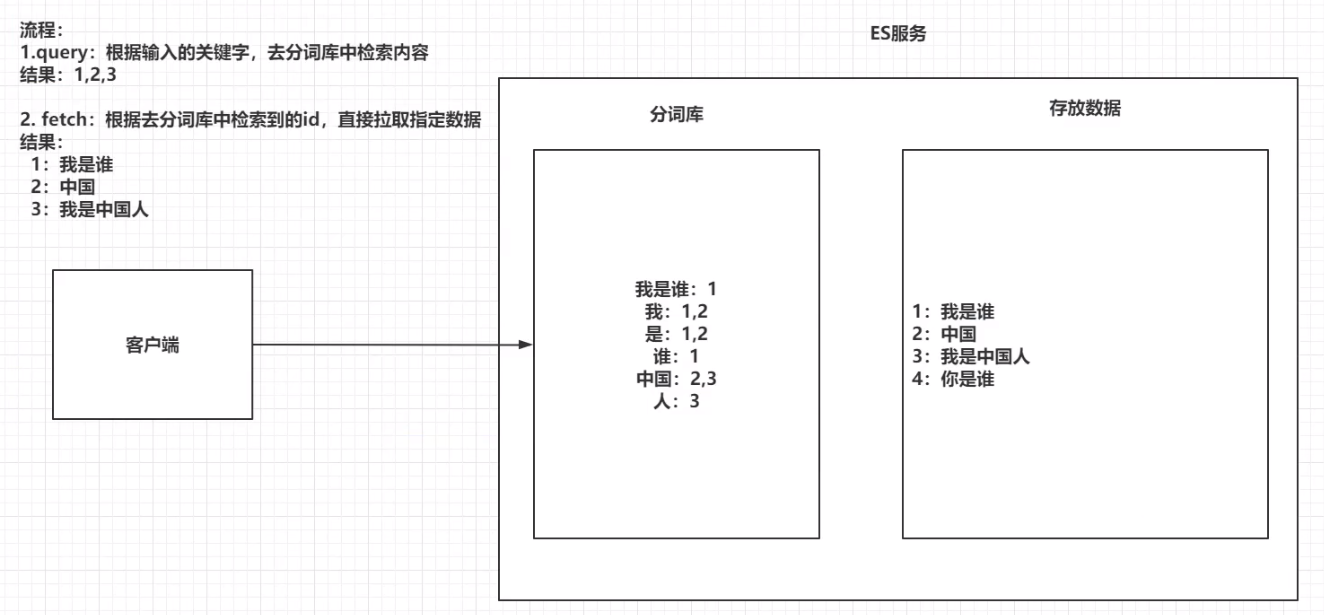
全文检索流程

- 创建ES索引、设置需要分词查询的 field
- 可以通过 canal 对 MySQL binlog 进行数据同步,或者 flink 或者 SpringBoot 直接往ES里添加数据
- 根据业务需求,通过 SpringBoot 进行查询
ElasticSearch 实现分词全文检索 - 概述的更多相关文章
- PHP+mysql数据库开发搜索功能:中英文分词+全文检索(MySQL全文检索+中文分词(SCWS))
PHP+mysql数据库开发类似百度的搜索功能:中英文分词+全文检索 中文分词: a) robbe PHP中文分词扩展: http://www.boyunjian.com/v/softd/robb ...
- ElasticSearch中文分词(IK)
ElasticSearch常用的很受欢迎的是IK,这里稍微介绍下安装过程及测试过程. 1.ElasticSearch官方分词 自带的中文分词器很弱,可以体检下: [zsz@VS-zsz ~]$ c ...
- 实战ELK(8) 安装ElasticSearch中文分词器
安装 方法1 - download pre-build package from here: https://github.com/medcl/elasticsearch-analysis-ik/re ...
- Elasticsearch 中文分词(elasticsearch-analysis-ik) 安装
由于elasticsearch基于lucene,所以天然地就多了许多lucene上的中文分词的支持,比如 IK, Paoding, MMSEG4J等lucene中文分词原理上都能在elasticsea ...
- Elasticsearch之分词器的作用
前提 什么是倒排索引? Analyzer(分词器)的作用是把一段文本中的词按一定规则进行切分.对应的是Analyzer类,这是一个抽象类,切分词的具体规则是由子类实现的,所以对于不同的语言,要用不同的 ...
- Elasticsearch之分词器的工作流程
前提 什么是倒排索引? Elasticsearch之分词器的作用 Elasticsearch的分词器的一般工作流程: 1.切分关键词 2.去除停用词 3.对于英文单词,把所有字母转为小写(搜索时不区分 ...
- elasticsearch 拼音+ik分词,spring data elasticsearch 拼音分词
elasticsearch 自定义分词器 安装拼音分词器.ik分词器 拼音分词器: https://github.com/medcl/elasticsearch-analysis-pinyin/rel ...
- elasticsearch 中文分词(elasticsearch-analysis-ik)安装
elasticsearch 中文分词(elasticsearch-analysis-ik)安装 下载最新的发布版本 https://github.com/medcl/elasticsearch-ana ...
- elasticsearch kibana + 分词器安装详细步骤
elasticsearch kibana + 分词器安装详细步骤 一.准备环境 系统:Centos7 JDK安装包:jdk-8u191-linux-x64.tar.gz ES安装包:elasticse ...
- Elasticsearch修改分词器以及自定义分词器
Elasticsearch修改分词器以及自定义分词器 参考博客:https://blog.csdn.net/shuimofengyang/article/details/88973597
随机推荐
- http转成https工具类
工具类代码如下: 点击查看代码 package com.astronaut.auction.modules.oss.utils; import org.apache.commons.collectio ...
- 编译安装nmon
nmon 是什么? nmon(Nigel's performance Monitor for Linux)是一种Linux性能监视工具,当前它支持 Power/x86/x86_64/Mainframe ...
- 一文详解RocketMQ的存储模型
摘要:RocketMQ 优异的性能表现,必然绕不开其优秀的存储模型. 本文分享自华为云社区<终于弄明白了 RocketMQ 的存储模型>,作者:勇哥java实战分享. RocketMQ 优 ...
- 防微杜渐,未雨绸缪,百度网盘(百度云盘)接口API自动化备份上传以及开源发布,基于Golang1.18
奉行长期主义的开发者都有一个共识:对于服务器来说,数据备份非常重要,因为服务器上的数据通常是无价的,如果丢失了这些数据,可能会导致严重的后果,伴随云时代的发展,备份技术也让千行百业看到了其" ...
- MQ系列11:如何保证消息可靠性传输(除夕奉上)
MQ系列1:消息中间件执行原理 MQ系列2:消息中间件的技术选型 MQ系列3:RocketMQ 架构分析 MQ系列4:NameServer 原理解析 MQ系列5:RocketMQ消息的发送模式 MQ系 ...
- 【Redis场景3】缓存穿透、击穿问题
场景问题及原因 缓存穿透: 原因:客户端请求的数据在缓存和数据库中不存在,这样缓存永远不会生效,请求全部打入数据库,造成数据库连接异常. 解决思路: 缓存空对象 对于不存在的数据也在Redis建立缓存 ...
- MyBatis的使用三(在sql语句中传值)
本文主要介绍在mybatis中如何在sql语句中传递参数 一. #{ } 和 ${ } 1. #{ } 和 ${ }的区别 #{ }是预编译处理 ==> PreparedStatement ${ ...
- 定时任务,LocalDateTime,在代码中调用其他项目的接口url
1.定时任务 1.在类上添加注解 @Component @Configuration @EnableScheduling 2.在类中方法上添加注解 @Scheduled(cron = "0 ...
- 阿里云服务器中MySQL数据库被攻击
前几天刚领了一个月的阿里云服务器玩,在里面装了MySQL,然后这几天找了个小项目练习着玩呢,就将表建在里面了. 刚访问添加员工还好好的,刚给员工分页查询呢 ,啪一下 ,很突然昂 ,就访问不了了 ,看控 ...
- vue学习笔记(八)---- vue中的实例属性(wacth和computed的使用)
一.watch属性的使用 1.传统方式实现双向数据改变监听事件(姓名拼接案例) <div id="app"> 姓: <input type="text& ...