GPS地图生成04之数据预处理
1. 引言¶
下载的轨迹数据来源真实,并非特意模拟的轨迹数据,所以质量问题十分严重,进行预处理就显得尤为重要
2. 裁剪¶
我们将下载的岳麓山轨迹数据加载入QGIS,并使用OSM作为底图:
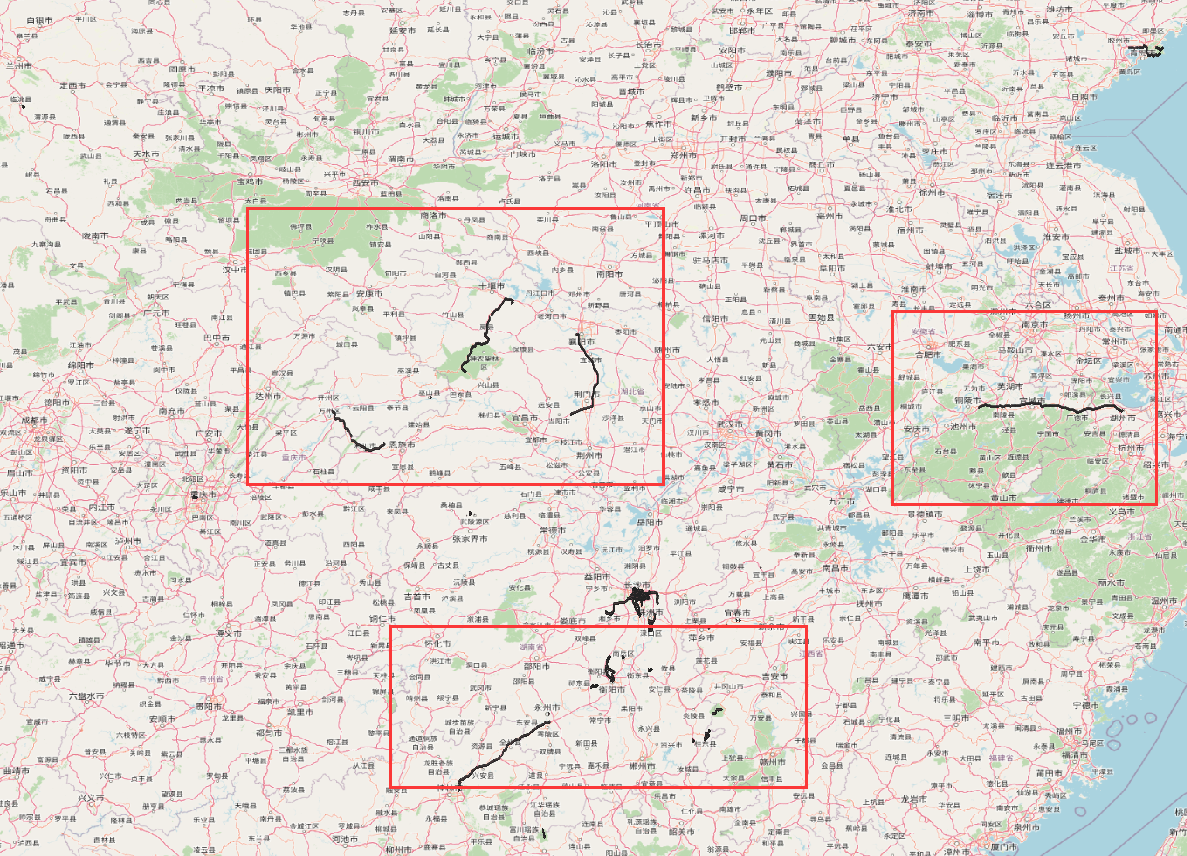
可以看到,存在着远超出长沙市范围的数据,这个是显然的必须要去除的
结合实际情况,第一次裁剪范围设置为岳麓山及周边的橘子洲、桃花岭、梅溪湖等,如图:
对应的分界点坐标为:
- 112.96715,28.14384 (右下)
- 112.85616,28.21707 (左上)
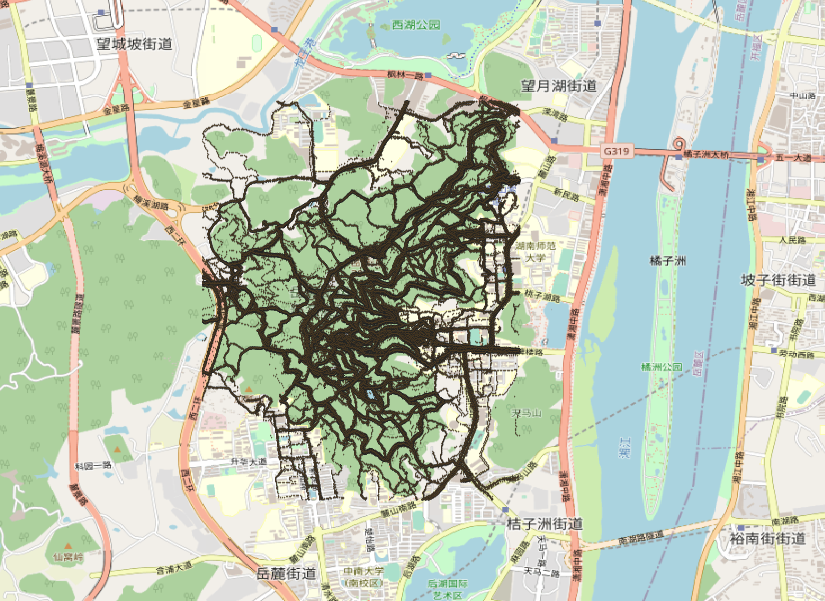
由于我们此次的本意(轨迹数据关键词)是岳麓山景区,第二次划分则以岳麓山景区边界为划分依据,如图所示:
对应的分界点坐标为:
- 112.943637,28.170235 (右下)
- 112.917099,28.203567 (左上)
class MBR:
def __init__(self, min_lat, min_lng, max_lat, max_lng):
self.min_lat = min_lat
self.min_lng = min_lng
self.max_lat = max_lat
self.max_lng = max_lng
def contains(self, lat, lng):
return self.min_lat <= lat < self.max_lat and self.min_lng <= lng < self.max_lng定义MBR
big_MBR = MBR(28.14384, 112.85616, 28.21707, 112.96715)
small_MBR = MBR(28.170235, 112.917099, 28.203567, 112.943637)遍历文件夹中的所有文件
import os
file = os.listdir('./trackdata')
trip_files = []
for trip_file in file:
if trip_file.startswith('trip_'):
trip_files.append(trip_file)
trip_files.__len__()1158对每个文件中的轨迹点进行遍历,包含在MBR中就另存为
dir = './trackdata/'
for trip_file in trip_files:
with open(dir+trip_file) as tf:
# print(trip_file)
tmp = []
for trip_line in tf:
point = trip_line.split(' ')
if big_MBR.contains(float(point[0]),float(point[1])):
tmp.append(trip_line)
# print(len(tmp))
if(len(tmp) > 1):
with open(dir+'clip/'+trip_file,'w') as cf:
cf.writelines(tmp)
with open(dir+'clip/all.csv','a') as af:
af.writelines(tmp)
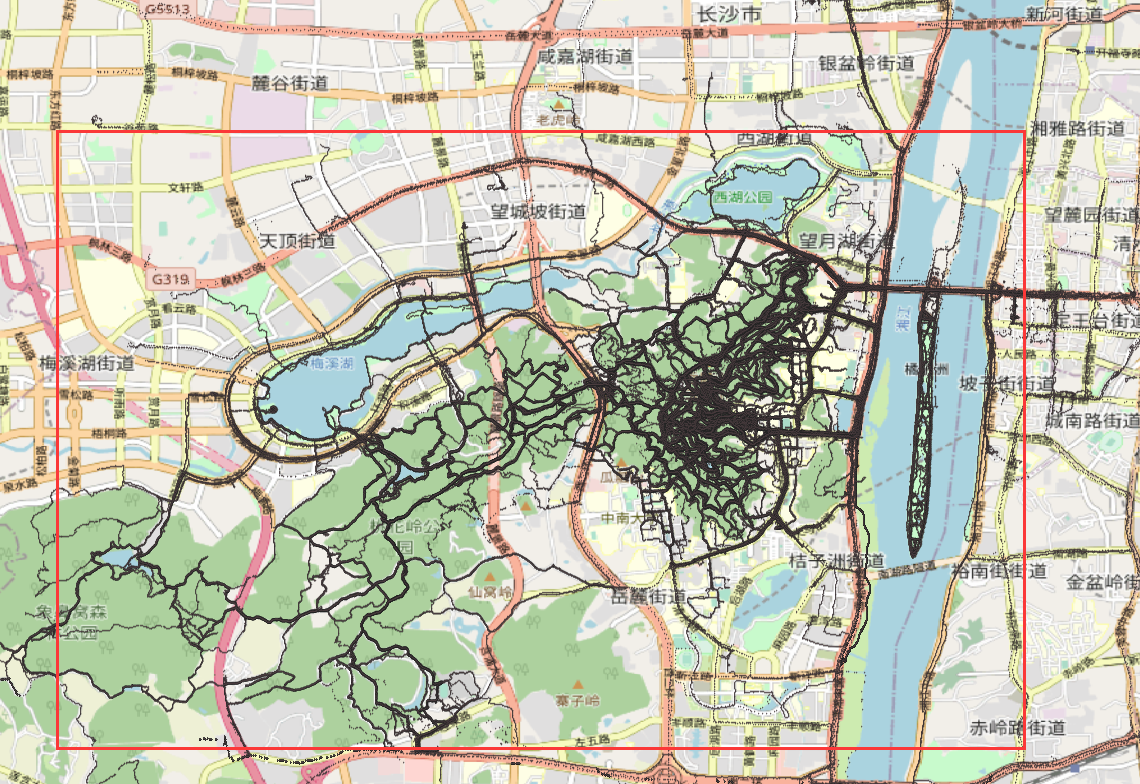
# print(trip_file)以上是对大的范围剪裁,裁减结果如图:
dir = './trackdata/'
for trip_file in trip_files:
with open(dir+trip_file) as tf:
# print(trip_file)
tmp = []
for trip_line in tf:
point = trip_line.split(' ')
if small_MBR.contains(float(point[0]),float(point[1])):
tmp.append(trip_line)
# print(len(tmp))
if(len(tmp) > 1):
with open(dir+'clip_yuelushan/'+trip_file,'w') as cf:
cf.writelines(tmp)
with open(dir+'clip_yulushan/all.csv','a') as af:
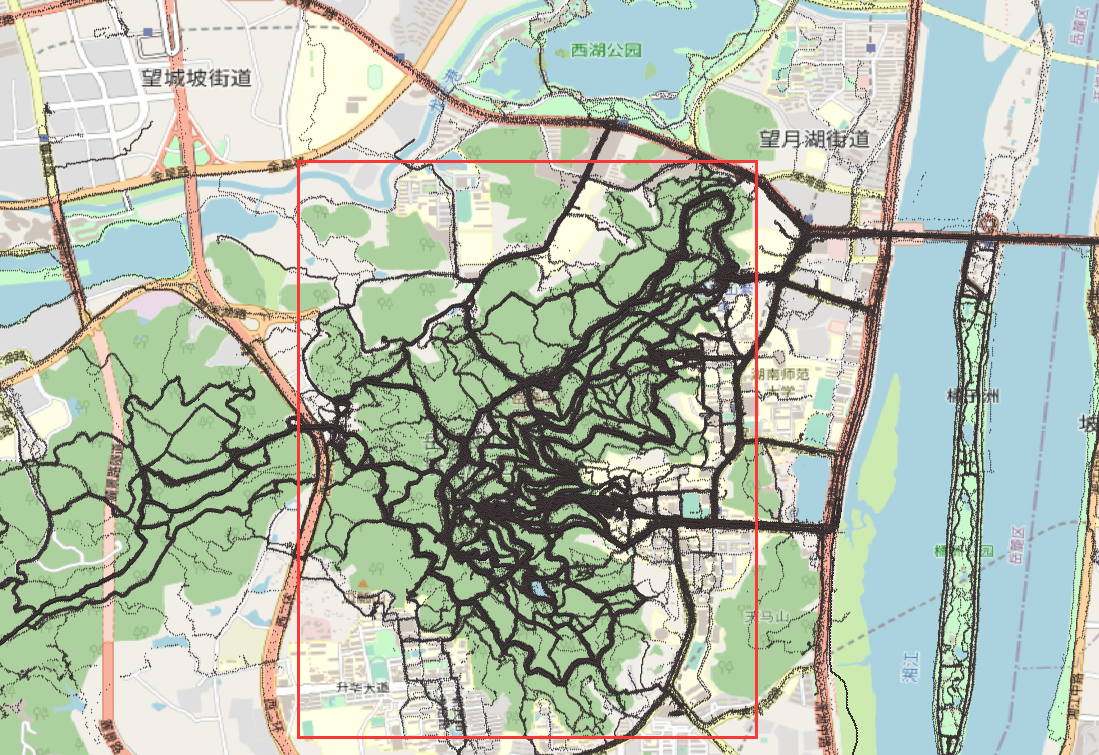
af.writelines(tmp)以上是对岳麓山进行裁减,结果如图:
不妨将裁减的轨迹放入KDE程序中运行,得到KDE图像:
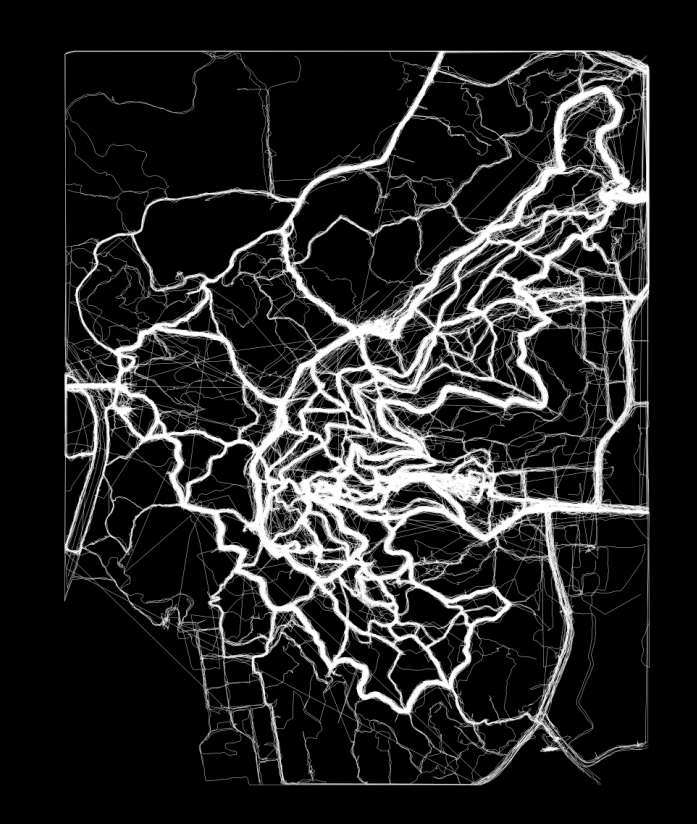
看到跳来跳去的线,显然下一步的工作是跳跃点去除
3. 跳跃点去除¶
前后点之间距离过大视为跳跃点,将这两点切断,该轨迹后面的点设为新的轨迹
定义包含距离计算的实体类:
import math
EARTH_MEAN_RADIUS_METER = 6371008.7714
class SPoint:
def __init__(self, lat, lng):
self.lat = lat
self.lng = lng
def __str__(self):
return '({},{})'.format(self.lat, self.lng)
def __eq__(self, other):
return self.lat == other.lat and self.lng == other.lng
# returns the distance in meters between two points specified in degrees (Haversine formula).
def distance(a, b):
return haversine_distance(a, b)
def haversine_distance(a, b):
if a.__eq__(b):
return 0.0
delta_lat = math.radians(b.lat - a.lat)
delta_lng = math.radians(b.lng - a.lng)
h = math.sin(delta_lat / 2.0) * math.sin(delta_lat / 2.0) + math.cos(math.radians(a.lat)) * math.cos(
math.radians(b.lat)) * math.sin(delta_lng / 2.0) * math.sin(delta_lng / 2.0)
c = 2.0 * math.atan2(math.sqrt(h), math.sqrt(1 - h))
d = EARTH_MEAN_RADIUS_METER * c
return ddistance(SPoint(28.00100,118.00001),SPoint(28.00002,118.00000))108.97560082918801读取文件:
import os
file = os.listdir('./trackdata/clip_yuelushan/')
trip_files = []
for trip_file in file:
if trip_file.startswith('trip_'):
trip_files.append(trip_file)
trip_files.__len__()995跳跃点去除:
dir = './trackdata/clip_yuelushan/'
MAX_SAPN = 20
for trip_file in trip_files:
with open(dir+trip_file) as tf:
# print(trip_file)
tmp = []
num = 0
tag = ''
lines = tf.readlines()
for i in range(len(lines)-1):
point1 = lines[i].split(' ')
point2 = lines[i+1].split(' ')
if distance(SPoint(float(point1[0]),float(point1[1])),SPoint(float(point2[0]),float(point2[1]))) < MAX_SAPN:
tmp.append(lines[i])
else:
if(len(tmp) > 1):
if num > 0:
tag = '_' + str(num)
with open('./trackdata/'+'jumpfilter_yueluhsan/'+trip_file[:-4]+tag+'.txt','w') as cf:
cf.writelines(tmp)
with open('./trackdata/'+'jumpfilter_yueluhsan/all.csv','a') as af:
af.writelines(tmp)
num = num + 1
tmp.clear()
if(len(tmp) > 1):
tmp.append(lines[len(lines)-1])
if num > 0:
tag = '_' + str(num)
with open('./trackdata/'+'jumpfilter_yueluhsan/'+trip_file[:-4]+tag+'.txt','w') as cf:
cf.writelines(tmp)
with open('./trackdata/'+'jumpfilter_yueluhsan/all.csv','a') as af:
af.writelines(tmp)再运行KDE程序得到图像:
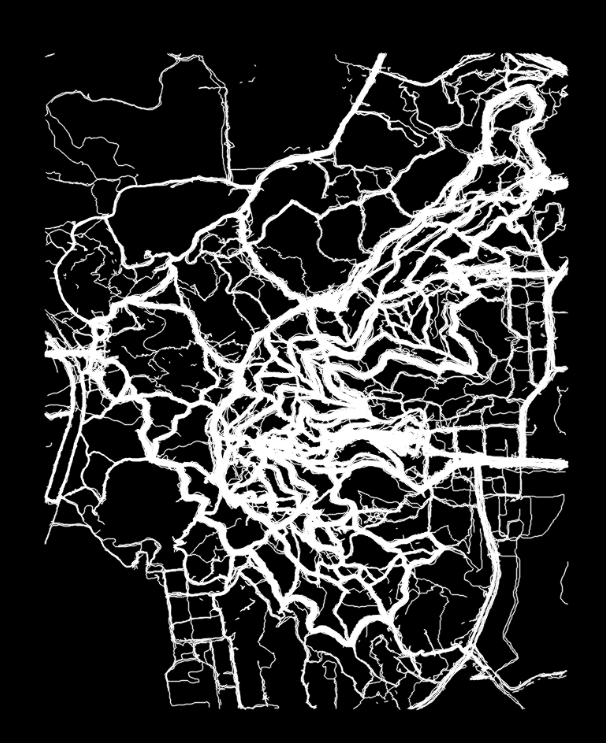
看起来似乎好多了
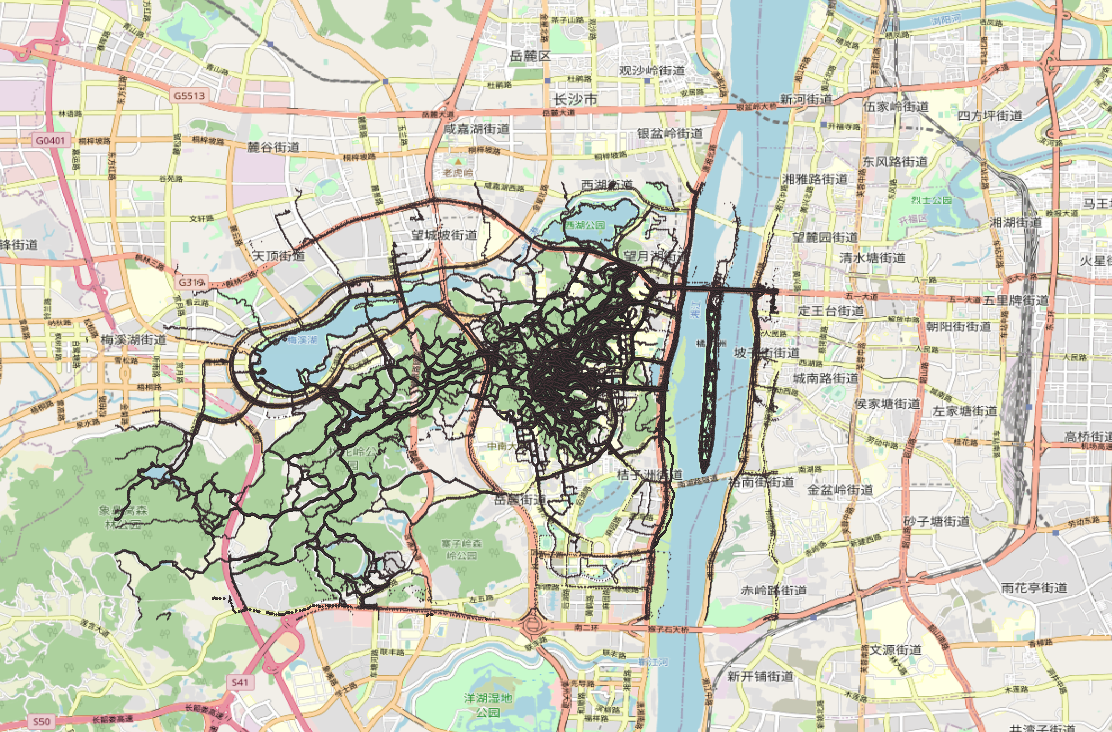
以下是对另一个剪裁进行跳跃点剔除:
import os
file = os.listdir('./trackdata/clip/')
trip_files = []
for trip_file in file:
if trip_file.startswith('trip_'):
trip_files.append(trip_file)
trip_files.__len__()1013dir = './trackdata/clip/'
MAX_SAPN = 20
for trip_file in trip_files:
with open(dir+trip_file) as tf:
# print(trip_file)
tmp = []
num = 0
tag = ''
lines = tf.readlines()
for i in range(len(lines)-1):
point1 = lines[i].split(' ')
point2 = lines[i+1].split(' ')
if distance(SPoint(float(point1[0]),float(point1[1])),SPoint(float(point2[0]),float(point2[1]))) < MAX_SAPN:
tmp.append(lines[i])
else:
if(len(tmp) > 1):
if num > 0:
tag = '_' + str(num)
with open('./trackdata/'+'jumpfilter/'+trip_file[:-4]+tag+'.txt','w') as cf:
cf.writelines(tmp)
with open('./trackdata/'+'jumpfilter/all.csv','a') as af:
af.writelines(tmp)
num = num + 1
tmp.clear()
if(len(tmp) > 1):
tmp.append(lines[len(lines)-1])
if num > 0:
tag = '_' + str(num)
with open('./trackdata/'+'jumpfilter/'+trip_file[:-4]+tag+'.txt','w') as cf:
cf.writelines(tmp)
with open('./trackdata/'+'jumpfilter/all.csv','a') as af:
af.writelines(tmp)4. 关于滞留点¶
滞留点就是游客停留或者以很慢速度行走的地方,这些地方会造成点聚集,对结果有一定影响,但同时这些点也是重要的点,可以用来挖掘重要区域
5. 关于运动方式¶
运动方式其实主要是对于游客运动模式的思考,游客主要的运动方式为步行,但也有骑行、驾车、缆车等方式
可以根据速度进行一个划分,根据速度大小进行相应的剔除
考虑到实际情况,一般,景区内车辆能走的道路行人都能走,行人能走的车辆不一定能走
笔者想要的是面向行人的导航地图,所以此处笔者认为可以不处理,另外,在跳跃点剔除那里,由于手机的GPS采样时间有个默认值,我们可以认为对速度过快的也进行了剔除
GPS地图生成04之数据预处理的更多相关文章
- 借助 SIMD 数据布局模板和数据预处理提高 SIMD 在动画中的使用效率
原文链接 简介 为发挥 SIMD1 的最大作用,除了对其进行矢量化处理2外,我们还需作出其他努力.可以尝试为循环添加 #pragma omp simd3,查看编译器是否成功进行矢量化,如果性能有所提升 ...
- R语言进行数据预处理wranging
R语言进行数据预处理wranging li_volleyball 2016年3月22日 data wrangling with R packages:tidyr dplyr Ground rules ...
- Scikit-Learn模块学习笔记——数据预处理模块preprocessing
preprocessing 模块提供了数据预处理函数和预处理类,预处理类主要是为了方便添加到 pipeline 过程中. 数据标准化 标准化预处理函数: preprocessing.scale(X, ...
- Deep Learning 11_深度学习UFLDL教程:数据预处理(斯坦福大学深度学习教程)
理论知识:UFLDL数据预处理和http://www.cnblogs.com/tornadomeet/archive/2013/04/20/3033149.html 数据预处理是深度学习中非常重要的一 ...
- weka数据预处理
Weka数据预处理(一) 对于数据挖掘而言,我们往往仅关注实质性的挖掘算法,如分类.聚类.关联规则等,而忽视待挖掘数据的质量,但是高质量的数据才能产生高质量的挖掘结果,否则只有"Garbag ...
- 对数据预处理的一点理解[ZZ]
数据预处理没有统一的标准,只能说是根据不同类型的分析数据和业务需求,在对数据特性做了充分的理解之后,再选择相关的数据预处理技术,一般会用到多种预处理技术,而且对每种处理之后的效果做些分析对比,这里面经 ...
- 【深度学习系列】PaddlePaddle之数据预处理
上篇文章讲了卷积神经网络的基本知识,本来这篇文章准备继续深入讲CNN的相关知识和手写CNN,但是有很多同学跟我发邮件或私信问我关于PaddlePaddle如何读取数据.做数据预处理相关的内容.网上看的 ...
- [数据预处理]-中心化 缩放 KNN(一)
据预处理是总称,涵盖了数据分析师使用它将数据转处理成想要的数据的一系列操作.例如,对某个网站进行分析的时候,可能会去掉 html 标签,空格,缩进以及提取相关关键字.分析空间数据的时候,一般会把带单位 ...
- 数据准备<3>:数据预处理
数据预处理是指因为算法或者分析需要,对经过数据质量检查后的数据进行转换.衍生.规约等操作的过程.整个数据预处理工作主要包括五个方面内容:简单函数变换.标准化.衍生虚拟变量.离散化.降维.本文将作展开介 ...
- Python数据预处理:机器学习、人工智能通用技术(1)
Python数据预处理:机器学习.人工智能通用技术 白宁超 2018年12月24日17:28:26 摘要:大数据技术与我们日常生活越来越紧密,要做大数据,首要解决数据问题.原始数据存在大量不完整.不 ...
随机推荐
- 前端入门 HTTP协议 HTML简介 head内常见标签 body内常见标签 特殊符号 列表标签 表格标签 表单标签
目录 前端和后端的概念 前端前戏之B/S架构 数据交互的协议 HTTP协议 1.四大特性 1. 基于请求响应 2. 基于TCP.IP作用与应用层之上的协议 3. 无状态 4. 无\短连接 2.数据格式 ...
- adb安装电视apk
adb 是什么? 百度说明:adb工具即Android Debug Bridge(安卓调试桥) tools.它就是一个命令行窗口,用于通过电脑端与模拟器或者真实设备交互.在某些特殊的情况下进入不了系统 ...
- python 数据迁移
Python数据库迁移 操作数据库 mysql uroot -p create database Python1031 charset=utf8; 数据迁移 from flask_migrate im ...
- 深入理解 dbt 增量模型
想要实现数据增量写入数据库,可以选择 dbt 增量模型.通过 dbt 增量模型,我们只用专注于写日增 SQL,不用去关注于如何安全的实现增量写入. dbt 增量模型解决了什么问题 原子性写入:任何情况 ...
- Auto-Job任务调度框架
Auto-Job 任务调度框架 一.背景 生活中,业务上我们会碰到很多有关作业调度的场景,如每周五十二点发放优惠券.或者每天凌晨进行缓存预热.亦或每月定期从第三方系统抽数等等,Spring和java目 ...
- Spring Boot 3.0横空出世,快来看看是不是该升级了
目录 简介 对JAVA17和JAVA19的支持 record Text Blocks Switch Expressions instanceof模式匹配 Sealed Classes and Inte ...
- JSONObject 相关
/** * 将json转为对应实体类 */ public static Object jsonToJavaObj(String json, Class cs) { return jsonToJavaO ...
- python之路47 django路由层配置 虚拟环境
可视化界面之数据增删改查 针对数据对象主键字段的获取可以使用更加方便的obj.pk获取 在模型类中定义双下str方法可以在数据对象被执行打印操作的时候方便的查看 ''' form表单中能够触发提交动作 ...
- Java入门及环境搭建
1.JAVA三大版本 JAVASE(标准版:桌面程序开发.控制台开发...) JAVAME(嵌入式:手机程序.小家电...) JAVAEE(企业级:web端.服务器开发...) 2.开发环境 JDK: ...
- vulnhub靶场之HACKATHONCTF: 2
准备: 攻击机:虚拟机kali.本机win10. 靶机:HackathonCTF: 2,下载地址:https://download.vulnhub.com/hackathonctf/Hackathon ...