CPU流水线与指令乱序执行
青蛙见了蜈蚣,好奇地问:"蜈蚣大哥,我很好奇,你那么多条腿,走路的时候先迈哪一条啊?"
蜈蚣听后说:"青蛙老弟,我一直就这么走路,从没想过先迈哪一条腿,等我想一想再回答你。"
蜈蚣站立了几分钟,它一边思考一边向前,蹒跚了几步,终于趴下去了。
它对青蛙说:“请你再也别问其它蜈蚣这个问题了!我一直都在这样走路,这根本不成问题!可现在你问我先移动哪一条腿,我也不知道了。搞得我现在连路都不会走了,我该怎么办呢?”
这个小故事属实反映了我最近的心态:
越学越不会了。。。
本来synchronized和volatile关键字用得好好的,我非要深入研究一下他们的原理,所以研究了内存屏障,又研究了和内存屏障相关的MESI,又研究了Cache Coherence和Memory Consistency,发现一切问题都出在CPU身上。于是又惊叹Java一次编写到处运行的特性,最终又研究到JMM。
说是研究,其实就是把学习过程中自己抛出来的问题解决掉,把所有知识穿成一条线罢了。
这条线的线头就从指令的乱序执行开始了。
经典的指令乱序执行的原因有两种,分别是Compiler Reordering和CPU Reordering。
1. Compiler Reordering
编译器会对高级语言的代码进行分析,如果它认为你的代码可以优化,那么他会对你的代码进行各种优化然后生成汇编指令。当然,本文说的优化主要是指令重排(Compiler Reordering)。
但是编译器的优化必须满足特定的条件,一个非常重要的原则就是as-if-serial语义:
Allows any and all code transformations that do not change the observable behavior of the program.
编译器必须遵守as-if-serial语义,也就是编译器不会对存在数据依赖关系的操作做重排序,因为这种重排序会改变执行结果。 但是,如果操作之间不存在数据依赖关系,这些操作就可能被编译器和处理器重排序。
我们用非常简单的C++代码举个例子(因为编译更简单,看起来也更直观)。
int a,b,c;
void bar()
{
a = c + 1;
b = 1;
}
int main()
{
bar();
return 0;
}
我们对这段代码进行变异,让编译器在O2级别优化的情况下编译代码,我截取其中的bar()的汇编代码,如下所示:
_Z3barv:
.LFB0:
.cfi_startproc
endbr64
movl $1, b(%rip) #将1的值赋给b,即b = 1
movl c(%rip), %eax #将c的值放到寄存器%eax中
addl $1, %eax #将寄存器%eax的值+1,即c + 1
movl %eax, a(%rip) #将寄存器%eax的值赋给a,即a = c + 1
ret
我们发现,编译得到的汇编代码和我们原本的C语言代码顺序并不一致。
汇编指令先执行了b = 1,之后才执行了a = c + 1。说明变量a和b的store操作并没有按照他们在程序中定义的顺序来执行。
既然汇编指令被重排了,CPU的执行顺序自然是根据汇编指令对应的机器指令执行的,大概率也会被重排。其实除此之外,CPU本身也会对指令进行重排(CPU Reordering)。
2. CPU 流水线
谈及处理器必谈及流水线,处理器的流水线结构是处理器微架构最基本的一个要素,也是造成CPU Reordering的主要因素。
2.1. 从汽车装配谈起
流水线的概念始于工业制造领域,但是鉴于大部分人其实都没接触过流水线,我们不妨举一个汽车生产的例子来解释流水线的诞生。
我们首先粗浅地认为汽车的装配需要两个步骤:
- 制作零件:制作车身外壳、发动机和各种其他部件;
- 组装:将各零部件(自己制作和外采的所有零部件)组装成车。
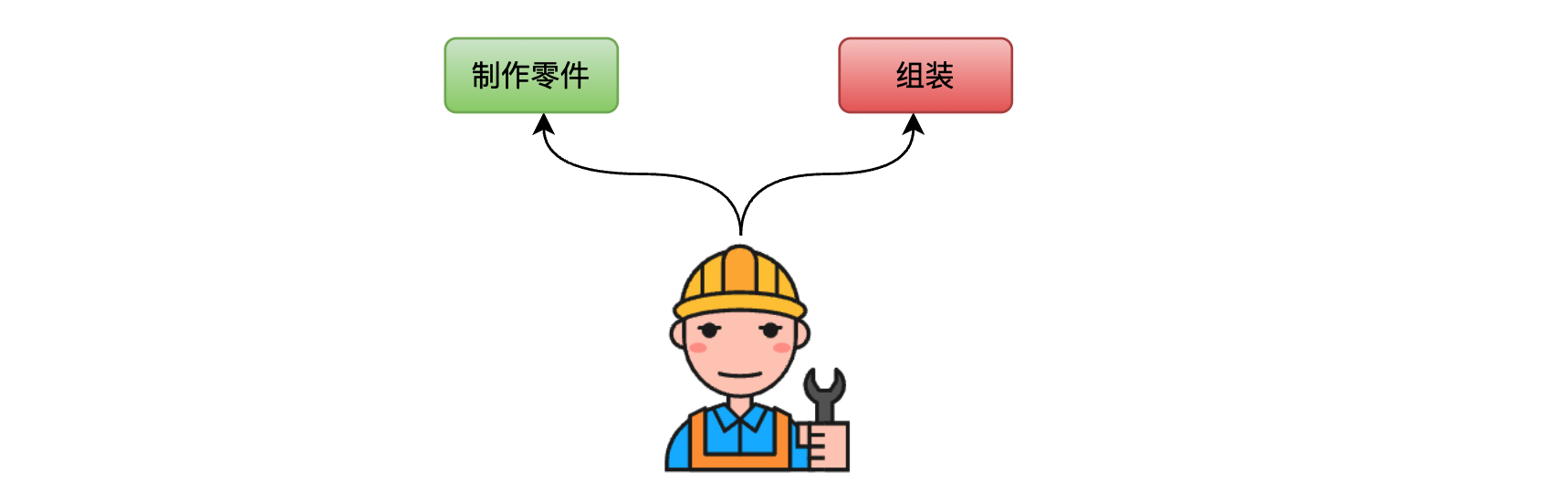
假设一个工人进行每个步骤都占用1个月,如果不采用流水线,而采用串行方式来执行的话,一年时间可以装配6辆汽车,过程见下图:

串行的效率实在是太有限了,根本原因就是装配的两个步骤都是由一个人完成的。如果有人能在组装进行的同时制作零件,效率会大大提升,也就是每个流程只专注一件事情,我们再引入一个工人。
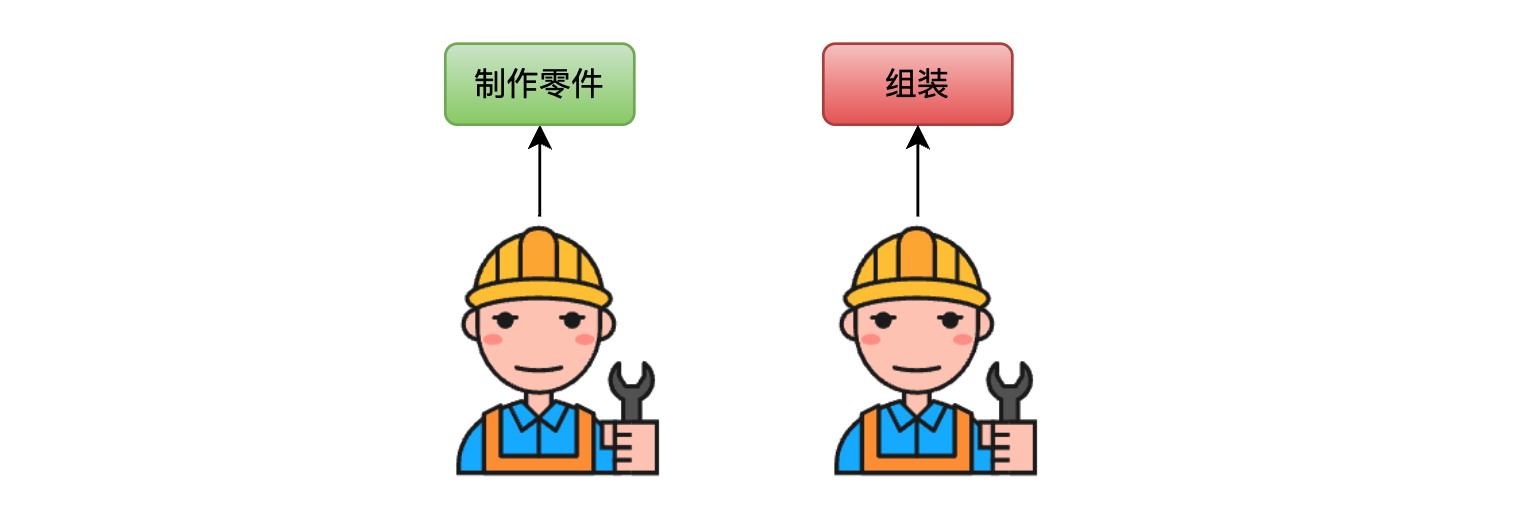
这样一个人专门负责制作零件,另一个人专门组装零件,两个工作交叠进行,过程见下图:
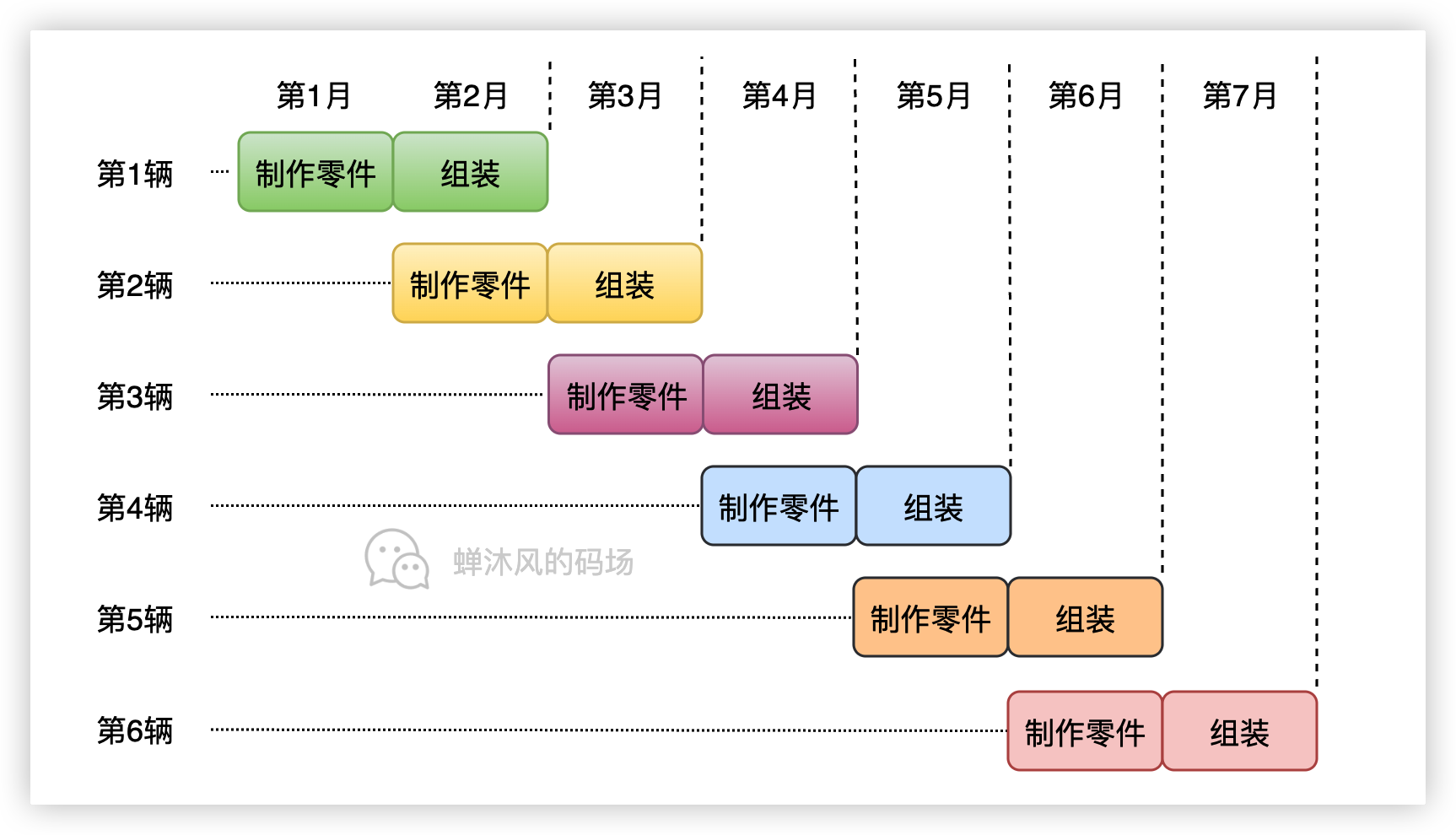
增加一个人手之后,除了第一个月,每一个月都有完整的制作零件和组装流程,因此一年内可以完成11台汽车的装配(相比于串行方式的6台,几乎翻倍了),从第二年开始,每年就能装配12台了(直接翻倍)。
这个过程就是流水线的执行过程,因为我们把汽车的制作过程分成了两个步骤,因此以上流水线成为二级流水线。
我们继续优化,我们将制作零件的步骤分成时间周期更短的冲压和焊接两步,将组装步骤分为时间周期更短的涂装和总装两步,并且假设每个步骤的时间周期为0.5个月。
当然喽,我们得再雇佣俩人。
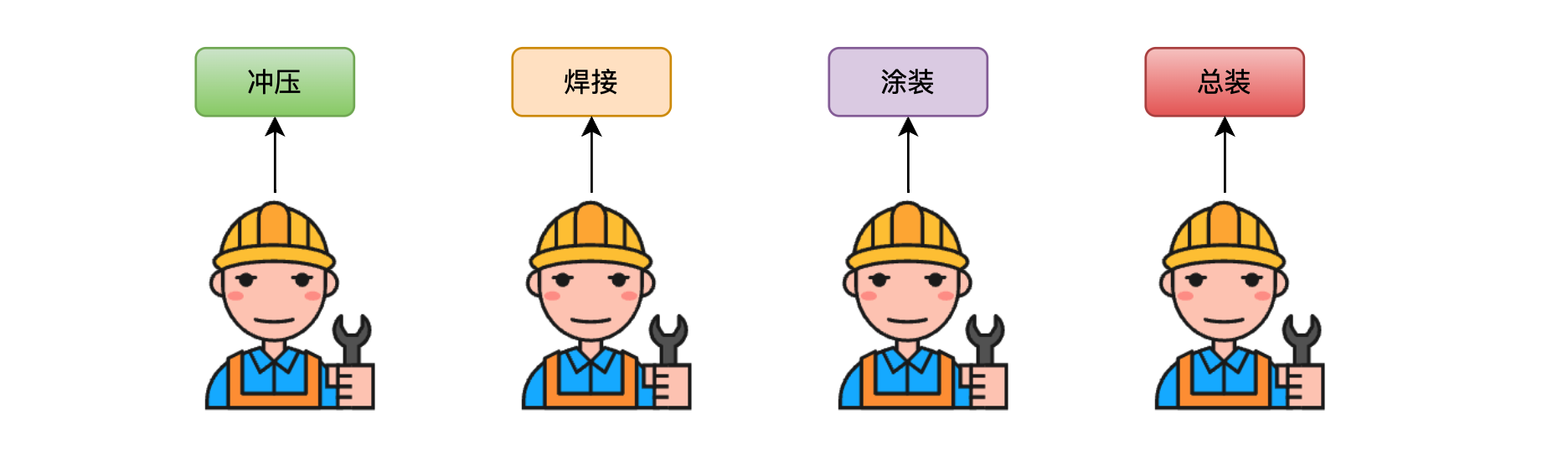
现在就是四级流水线了,神奇的事情发生了,四级流水线使得原本需要一年时间的任务现在只需要4.5个月便可以完成,再次提升了效率。如下图所示:
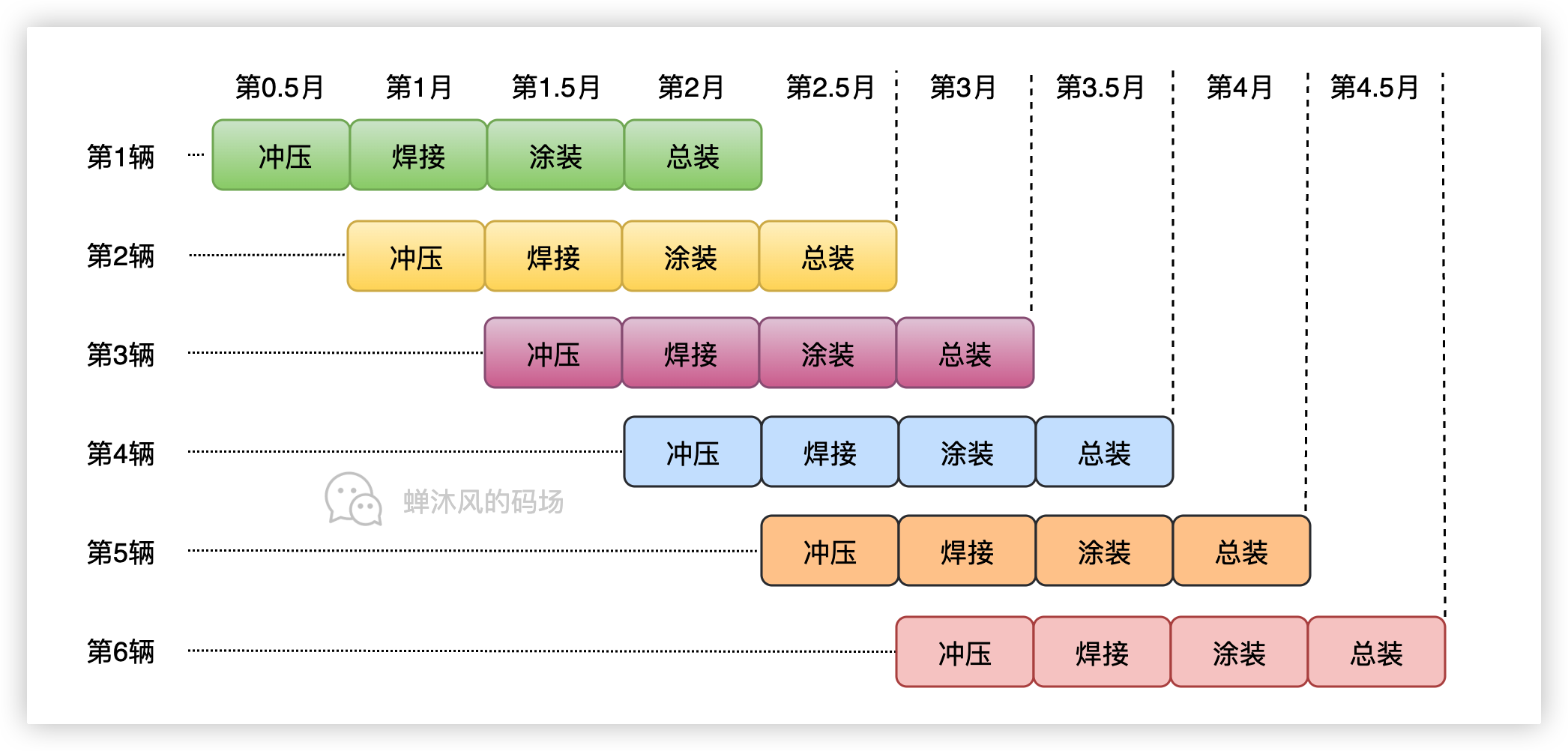
2.2. 现代CPU的流水线
现代 CPU 支持多级指令流水线,例如支持同时执行 取指令 - 指令译码 - 执行指令 - 内存访问 - 数据写回的处理器,就可以称之为五级指令流水线。
这时 CPU 可以在一个时钟周期内,同时运行五条指令的不同阶段,其中每个阶段的都占用一个或多个指令周期(CPU以执行时间最长),本质上,流水线技术井不能缩短单条指令的执行时间,但它变相地提高了指令的吞吐率。
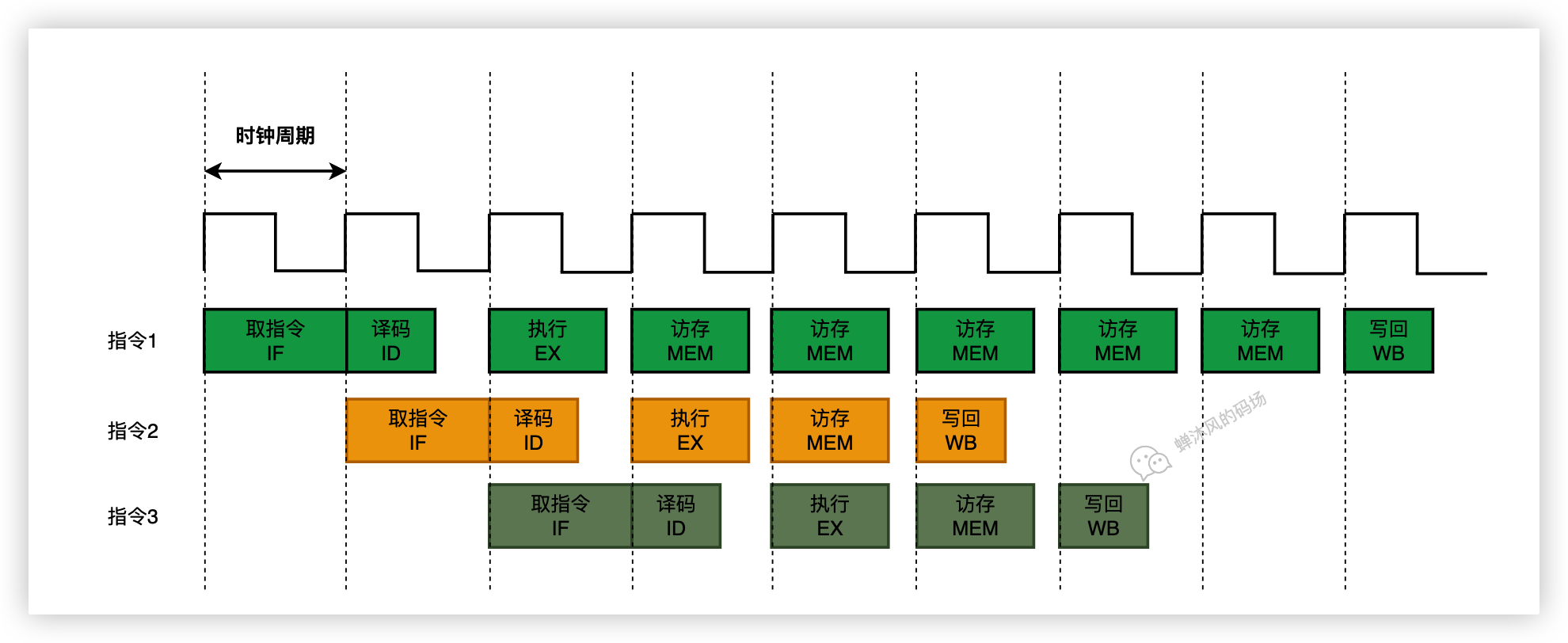
上面的CPU流水线图并非特定型号的CPU的示例,而是为了说明几个问题特意画成了这个样子。
通常而言,CPU设计者会选择执行时间最长的流水线阶段作为一个时钟周期,这样能保证其他阶段能在一个时钟周期内完成,避免出现流水线断流。
每一个流水线级的时间都是一个时钟周期,但是其中实际操作的时间,可能短于一个时钟周期。比如译码器其实就是一个组合逻辑电路,门延迟很低,就不需要一个完整的时钟周期就能完成自己的任务,任务完成之后CPU其实是在“等待”。
很多人可能会问,既然流水线这么好用,那为什么CPU设计者不设计一个超长流水线呢?这就需要说明一下超长流水线的瓶颈了。
3. 超长流水线的瓶颈
3.1. 性能瓶颈
流水线长度的增加,是有性能成本的。
每一级流水线的输出都需要放在流水线寄存器中,然后再下一个时钟周期,交给下一个流水线级去处理。每增加一级流水线,就要多一级写入流水线寄存器的操作。
以多线程为例,数量合适的多线程会提高数据的处理速度,但是当线程数量太多,线程之间的时间切换成本就无法被忽视,线程的增加甚至可能成为性能提升的负担。
3.2. 功耗瓶颈
提升流水线的深度,需要同步提高CPU的主频。再看一下这个图:
由于流水线的每一级被分得特别细,甚至有的还没有完全占满单个时钟周期,也就意味着单个时钟周期内能完成的事情变少了,因此只有提升主频,CPU 在指令的响应时间这个指标上才能保持和原来相同的性能。
提升主频和流水线深度就以为这晶体管的增加,也就以为这功耗变大。
没人想拥有一台“充电3小时,办公20分钟”的一台笔记本电脑吧。
3.3. 指令乱序
还是以上面的图为例(就不再贴一遍了),指令1的访存操作使用了多个时钟周期,导致指令2和指令3在指令1之前完成了。
如果是一般的代码还好,但如果是具有依赖性的代码,比如:
float a = 3.14159 * 0.2; // 指令1
float b = a * 2; // 指令2
float c = b + 1; // 指令3
float d = 10; // 指令4
指令1、2、3的执行顺序就绝不能向图中表示的那样乱序执行。其中有两点需要我们注意:
- 由于上图中情形的存在,导致CPU确实有可能出现乱序执行的情况;
- CPU需要阻止具有依赖关系的指令乱序执行(指令1,2,3),转而让后续没有依赖关系的指令(指令4)先执行。
对于第2条,如果流水线只有5级还好说,CPU自然有办法判断哪些指令具有依赖性,并拒绝做出指令乱序。但是如果有20条流水线,CPU肯定还有办法判断,但是可想而知,这种判断势必会影响CPU的性能。
回到本文一开始说的编译器指令重排序,当然喽,也包含Java的JIT将字节码编译成机器码时的指令重排序,就是为了把没有依赖关系的指令放一起,本质上都是为了适配CPU,更好地发挥出CPU流水线的功能,从而提升性能罢了。
4. 总结
说了这么多,很可能在我之后的文章中被一句话带过。
其实我想表达的思想就是,实际代码运行的顺序可能和我们代码编写的顺序并不一致。记住这句话很容易,但或许总会有人像我一样想稍微深入一点来了解这句话的本质吧。
除了本文所述,CPU和高速缓存之间的交互过程中,硬件工程师也着实给软件开发者挖了不少坑,内存屏障就是在这种背景下产生的。
更多内容,下期见!
CPU流水线与指令乱序执行的更多相关文章
- 深入设计电子计算器(一)——CPU框架及指令集设计
版权申明:本文为博主窗户(Colin Cai)原创,欢迎转帖.如要转贴,必须注明原文网址 http://www.cnblogs.com/Colin-Cai/p/8278418.html 作者:窗户 Q ...
- 使用logisim搭建单周期CPU与添加指令
使用logisim搭建单周期CPU与添加指令 搭建 总设计 借用高老板的图,我们只需要分别做出PC.NPC.IM.RF.EXT.ALU.DM.Controller模块即可,再按图连线,最后进行控制信号 ...
- 聊聊CPU的LOCK指令
本文转载自聊聊CPU的LOCK指令 导语 在多线程操作中,可能最经常被提起的就是数据的可见性.原子性.有序性.不管是硬件方面.软件方面都在这三方面做了很足的工作,才能保证程序的正常运行. 之前发表过一 ...
- CPU结构与指令执行过程简介
CPU(Central Processing Unit)是计算机中进行算术和逻辑计算处理指令的主要部件. CPU结构 CPU由通用寄存器组,运算器,控制器和数据通路等部件组成. 寄存器包括 数据寄存器 ...
- 【操作系统之十一】任务队列、CPU Load、指令乱序、指令屏障
一.CPU Loadcpu load是对使用或者等待cpu进程的统计(数量的累加):每一个使用(running)或者等待(runnable)CPU的进程,都会使load值+1;每一个结束的进程,都会使 ...
- 使用CPU的AVX指令
arch:AVX 很抱歉GCC还不行……有……倒是 但是不是这么写的 我忘记了……官网上有 http://www.oschina.net/news/66980/kreogist-0-9
- 用 CPI 火焰图分析 Linux 性能问题
https://yq.aliyun.com/articles/465499 用 CPI 火焰图分析 Linux 性能问题 yangoliver 2018-02-11 16:05:53 浏览1076 ...
- Intel系列CPU的流水线技术的发展
Intel系列CPU的流水线技术的发展 CPU(Central processing Unit),又称“微处理器(Microprocessor)”,是现代计算机的核心部件.对于PC而言,CPU的规格与 ...
- verilog实现16位五级流水线的CPU带Hazard冲突处理
verilog实现16位五级流水线的CPU带Hazard冲突处理 该文是基于博主之前一篇博客http://www.cnblogs.com/wsine/p/4292869.html所增加的Hazard处 ...
随机推荐
- 关于Node.js 链接mysql超时处理(默认8小时)
备注:这是在pm2配置node环境下,超过8小时mysql自动关闭的情况下出现的解决方法:1.封装mysql.js var mysql = require('mysql'); var connecti ...
- WPF开发随笔收录-自定义图标控件
一.前言 1.在以前自学的过程中,软件需要使用到图标的时候,总是第一个想法是下载一个图片来充当图标使用,但实际得出来的效果会出现模糊的现象.后来网上学习了字体图标库的用法,可以在阿里云矢量图网站那里将 ...
- [LINUX] 像电影里的黑客一样用 terminal 作为日常开发
目录 1.效果预览 2.具体实现 2.1 定位鼠标位置 2.2 获取屏幕位置 2.3 计算鼠标在哪个窗口 2.4 1920x1080 平铺效果设计 2.5 1280x1024 平铺效果设计 3 代码 ...
- Linux操作系统(5):网络命令
Linux 网络环境配置①自动获取 缺点: linux 启动后会自动获取 IP,缺点是每次自动获取的 ip 地址可能不一样.这个不适用于做服务器,因为我们的服务器的 ip 需要时固定的. ②直 接 修 ...
- STM32液晶显示HT1621驱动原理及程序代码
1.HT1621电路分析 HT1621为32×4即128点内存映像LCD驱动器,包含内嵌的32×4位显示RAM内存和时基发生器以及WDT看门狗定时器. HT1621驱动电路如下图所示: 图1 与单片机 ...
- Hashtable集合 --练习题_计算一个字符串中每个字符出现次数
Hashtable集合 java.util.Hashtable<K,V>集合 implements Map<K,V>接口 Hashtable:底层也是一个哈希表,是一个线程安 ...
- Java学习第二周
这一周观看了黑马程序员毕向东的教学视频学习了数组的创建:数组元素的使用及遍历,类的声明,成员方法的声明,构造器的声明 数据类型[] 数组名 = new 数据类型[长度];数据类型[] 数组名 = {数 ...
- GitHub相关资料&&可以参加的开源项目
GitHub相关的资料 有不懂的地方时可以看GitHub Docs. GitHub tutorial GitHub glossary GitHub的字典,可以看到里面特定的概念. All about ...
- SpringBoot配置文件读取过程分析
整体流程分析 SpringBoot的配置文件有两种 ,一种是 properties文件,一种是yml文件.在SpringBoot启动过程中会对这些文件进行解析加载.在SpringBoot启动的过程中, ...
- Blazor快速实现扫雷(MineSweeper)
如何快速的实现一个扫雷呢,最好的办法不是从头写,而是移植一个已经写好的! Blazor出来时间也不短了,作为一个.net开发者就用它来作吧.Blazor给我的感觉像是Angular和React的结合体 ...