数仓Hive和分布式计算引擎Spark多整合方式实战和调优方向
@
概述
前面的文章都单独熟悉Hive和Spark原理和应用,本篇则来进一步研究Hive与Spark之间整合的3种模式:
- Hive on Spark:在这种模式下,数据是以table的形式存储在hive中的,用户处理和分析数据,使用的是hive语法规范的 hql (hive sql)。 但这些hql,在用户提交执行时(一般是提交给hiveserver2服务去执行),底层会经过hive的解析优化编译,最后以spark作业的形式来运行。hive在spark 因其快速高效占领大量市场后通过改造自身代码支持spark作为其底层计算引擎。这种方式是Hive主动拥抱Spark做了对应开发支持,一般是依赖Spark的版本发布后实现。
- Spark on Hive:spark本身只负责数据计算处理,并不负责数据存储。其计算处理的数据源,可以以插件的形式支持很多种数据源,这其中自然也包括hive,spark 在推广面世之初就主动拥抱hive,使用spark来处理分析存储在hive中的数据时,这种模式就称为为Spark on Hive。这种方式是是Spark主动拥抱Hive实现基于Hive使用。
- Spark + Spark Hive Catalog。这是spark和hive结合的一种新形势,随着数据湖相关技术的进一步发展,其本质是,数据以orc/parquet/delta lake等格式存储在分布式文件系统如hdfs或对象存储系统如s3中,然后通过使用spark计算引擎提供的scala/java/python等api或spark 语法规范的sql来进行处理。由于在处理分析时针对的对象是table, 而table的底层对应的才是hdfs/s3上的文件/对象,所以我们需要维护这种table到文件/对象的映射关系,而spark自身就提供了 spark hive catalog来维护这种table到文件/对象的映射关系。使用这种模式,并不需要额外单独安装hive。
Spark on Hive
# 启动hiveserver2,两种方式选一
hive --service hiveserver2 &
nohup hive --service hiveserver2 >> ~/hiveserver2.log 2>&1 &
# 启动metastore,两种方式选一
hive --service metastore &
nohup hive --service metastore >> ~/metastore.log 2>&1 &
通过hive连接创建数据库、表和导入数据,Hive部署详细查看之前文章
# 测试beeline客户端
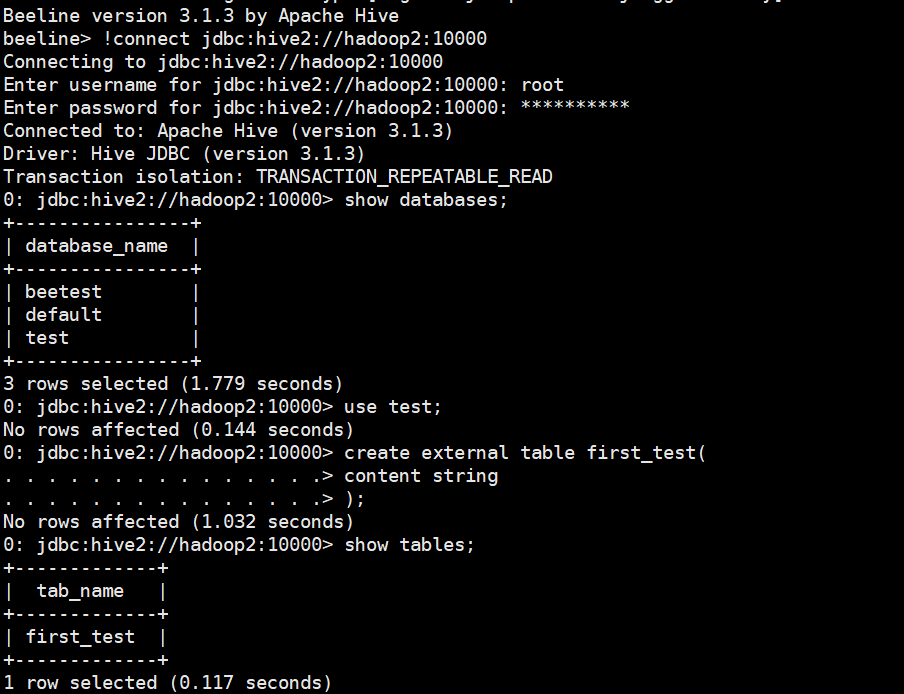
beeline
!connect jdbc:hive2://hadoop2:10000
create database if not exists test;
use test;
create external table first_test(
content string
);
# 测试hive客户端
hive
load data local inpath '/home/commons/apache-hive-3.1.3-bin/first_test.txt' into table first_test;
select * from first_test;
select count(*) from first_test;
# 将部署好的hive的路径下的conf/hive-site.xml复制到spark安装路径下的conf/
cp /home/commons/apache-hive-3.1.3-bin/conf/hive-site.xml conf/
# 将部署好的hive的路径下的lib/mysql驱动包,我的是(mysql-connector-java-8.0.15.jar)拷贝到spark安装路径下的jars/
cp /home/commons/apache-hive-3.1.3-bin/lib/mysql-connector-java-8.0.28.jar jars/
# 启动park-shell的yarn client模式
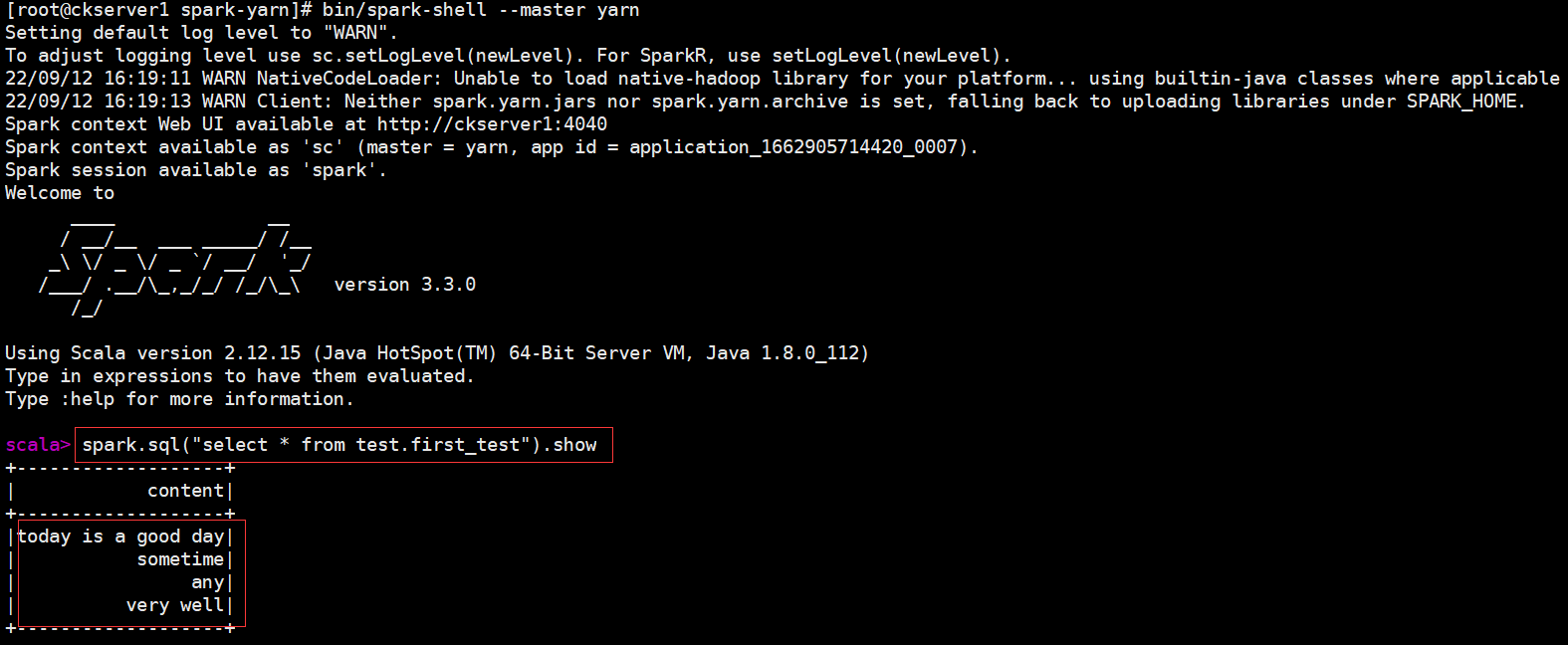
bin/spark-shell \
--master yarn
spark.sql("select * from test.first_test").show
经过上面简单部署,Spark就可以操作Hive的数据,查看Spark on Hive显示结果如下
# 这里我们使用Standalone模式运行,启动Spark Standalone集群
./start-all.sh
# 创建scala maven项目
package cn.itxs
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
object SparkDemo {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().enableHiveSupport().appName("spark-hive").master("spark://hadoop1:7077").getOrCreate()
spark.sql("select * from test.first_test").show()
}
}
maven pom依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.13</artifactId>
<version>3.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.13</artifactId>
<version>3.3.0</version>
<scope>provided</scope>
</dependency>
<!-- SparkSQL ON Hive-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.13</artifactId>
<version>3.3.0</version>
<scope>provided</scope>
</dependency>
<!--mysql依赖的jar包-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.28</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.12.16</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.3</version>
</dependency>
Hive on Spark
概述
Hive on Spark 官网文档地址 https://cwiki.apache.org/confluence/display/Hive/Hive+on+Spark%3A+Getting+Started
hive支持了三种底层计算引擎包括mr、tez和spark。从hive的配置文件hive-site.xml中就可以看到
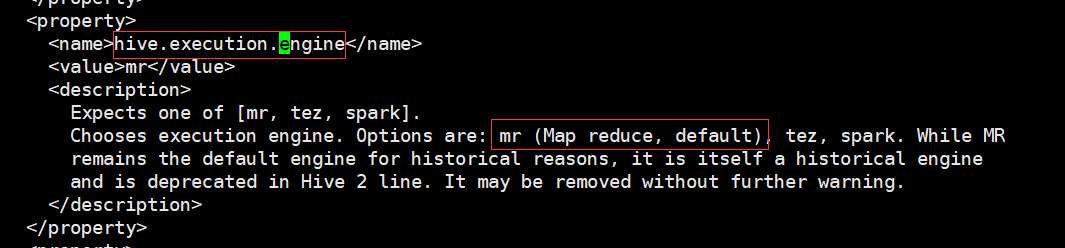
Hive on Spark为Hive提供了使用Apache Spark作为执行引擎的能力,可以指定具体使用spark计算引擎 set hive.execution.engine=spark;
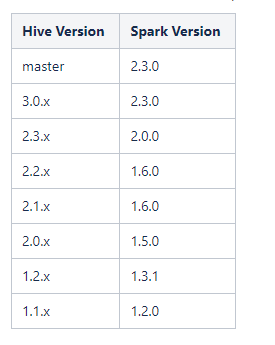
注意,一般来说hive版本需要与spark版本对应,官网有给出对应版本。这里使用的hive版本,spark版本,hadoop版本都没有使用官方推荐。只是我们学习研究,如生产使用的话建议按照官网版本。下面为官网的说明:Hive on Spark只在特定版本的Spark上进行测试,因此一个特定版本的Hive只能保证与特定版本的Spark一起工作。其他版本的Spark可能会与指定版本的Hive一起工作,但不能保证。以下是Hive的版本列表以及与之配套的Spark版本。
编译Spark源码
# 下载Spark3.3.0的源码
wget https://github.com/apache/spark/archive/refs/tags/v3.3.0.zip
# 解压
unzip v3.3.0.zip
# 进入源码根目录
cd spark-3.3.0
# 执行编译,主要不包含hive的依赖,当前需要以前安装好maven
./dev/make-distribution.sh --name "hadoop3-without-hive" --tgz "-Pyarn,hadoop-3.3,scala-2.12,parquet-provided,orc-provided" -Dhadoop.version=3.3.4 -Dscala.version=2.12.15 -Dscala.binary.version=2.12
编译需要等待一段时间,下载相关依赖包执行编译步骤
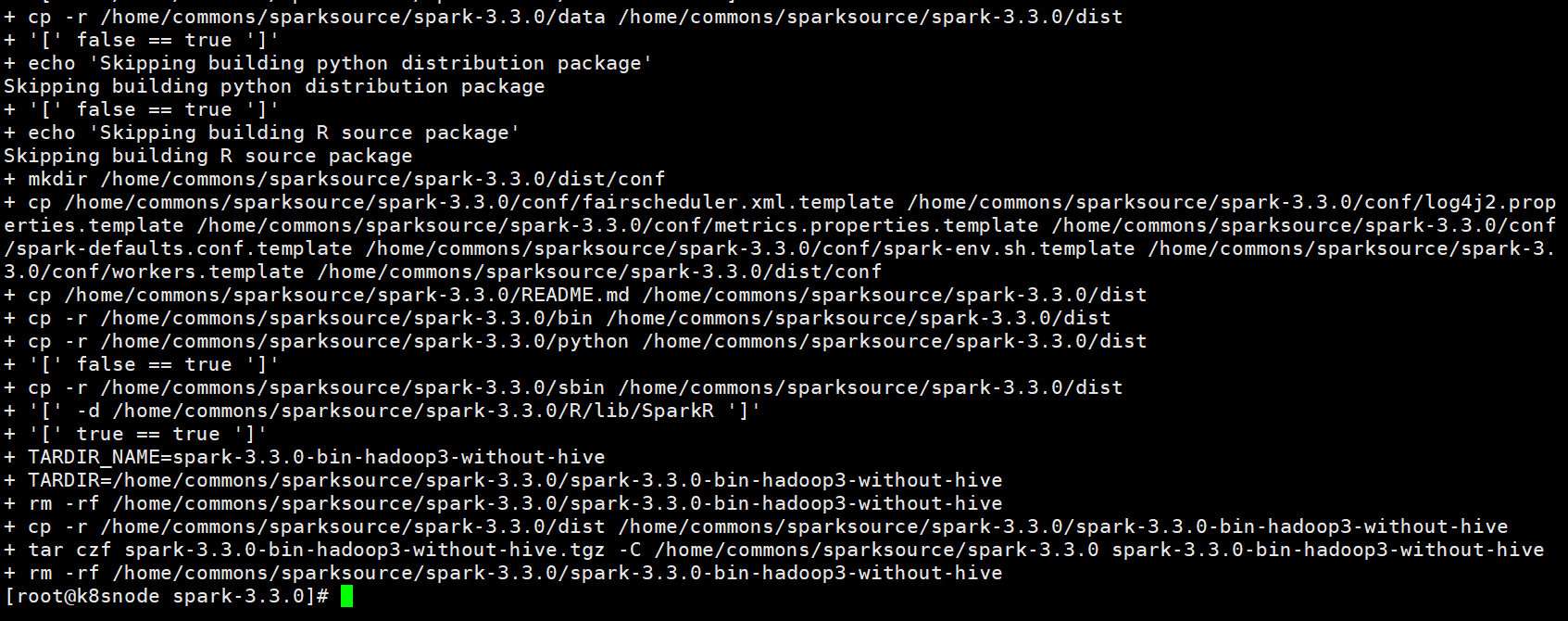
编译完成后在根目录下生成spark-3.3.0-bin-hadoop3-without-hive.tgz打包文件
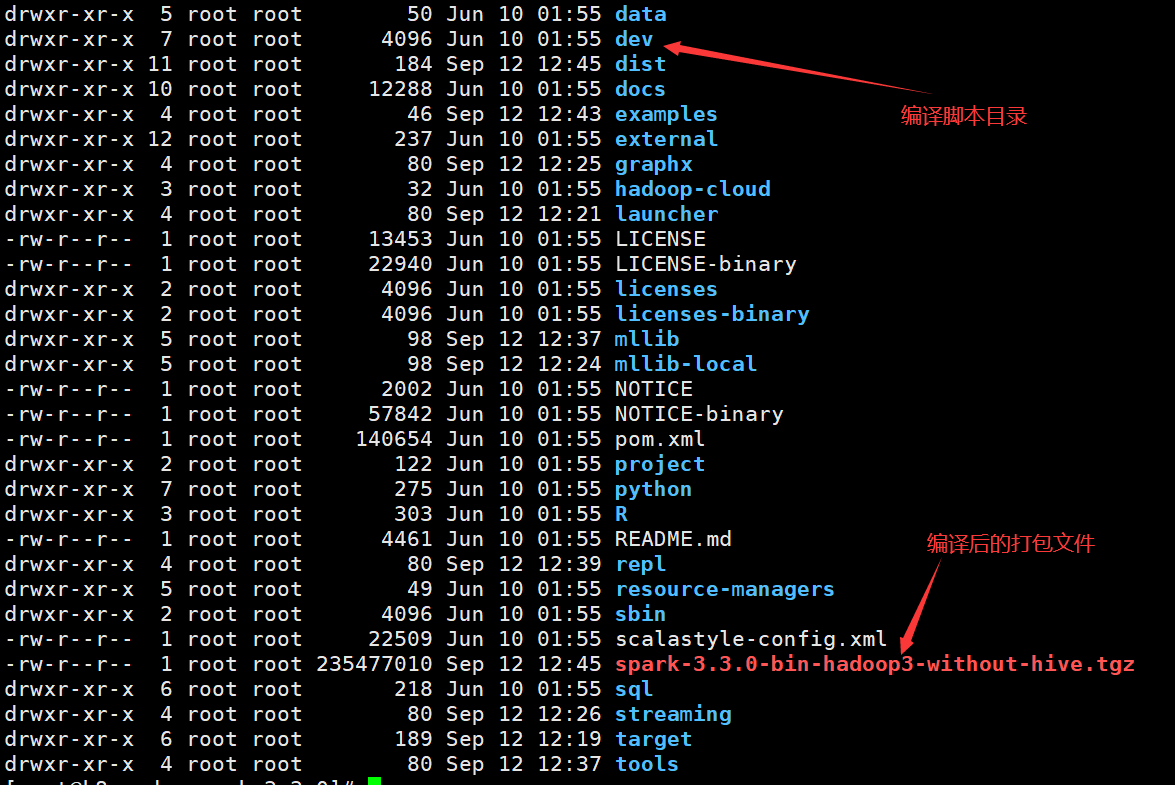
之前在官网下载Spark3.3.0的大小要比刚才大,其差异就是去除Hive的依赖

配置
# 将spark-3.3.0-bin-hadoop3-without-hive.tgz拷贝到安装目录
tar -xvf spark-3.3.0-bin-hadoop3-without-hive.tgz
# spark-3.3.0-bin-hadoop3-without-hive
- 全局配置置Hive执行引擎使用Spark,在hive-site.sh中配置
<property> <name>spark.executor.cores</name> <value>3</value></property>
- 局部配置Hive执行引擎使用Spark,如在命令行中设置
set hive.execution.engine=spark;hive -e "hive.execution.engine=spark"
配置Hive的Spark-application配置,可以通过添加一个带有这些属性的文件“spark-defaults.conf”到Hive类路径中,或者通过在Hive配置文件(Hive -site.xml)中设置它们来实现。在hive-site.sh增加Spark的配置如下
<property>
<name>spark.serializer</name>
<value>org.apache.spark.serializer.KryoSerializer</value>
<description>配置spark的序列化类</description>
</property>
<property>
<name>spark.eventLog.enabled</name>
<value>true</value>
</property>
<property>
<name>spark.eventLog.dir</name>
<value>hdfs://myns:8020/hive/log</value>
</property>
<property>
<name>spark.executor.instances</name>
<value>3</value>
</property>
<property>
<name>spark.executor.cores</name>
<value>3</value>
</property>
<property>
<name>spark.yarn.jars</name>
<value>hdfs://myns:8020/spark/jars-hive/*</value>
</property>
<property>
<name>spark.home</name>
<value>/home/commons/spark-3.3.0-bin-hadoop3-without-hive</value>
</property>
<property>
<name>spark.master</name>
<value>yarn</value>
<description>配置spark on yarn</description>
</property>
<property>
<name>spark.executor.extraClassPath</name>
<value>/home/commons/apache-hive-3.1.3-bin/lib</value>
<description>配置spark 用到的hive的jar包</description>
</property>
<property>
<name>spark.eventLog.enabled</name>
<value>true</value>
</property>
<property>
<name>spark.executor.memory</name>
<value>4g</value>
</property>
<property>
<name>spark.yarn.executor.memoryOverhead</name>
<value>2048m</value>
</property>
<property>
<name>spark.driver.memory</name>
<value>2g</value>
</property>
<property>
<name>spark.yarn.driver.memoryOverhead</name>
<value>400m</value>
</property>
<property>
<name>spark.executor.cores</name>
<value>3</value>
</property>
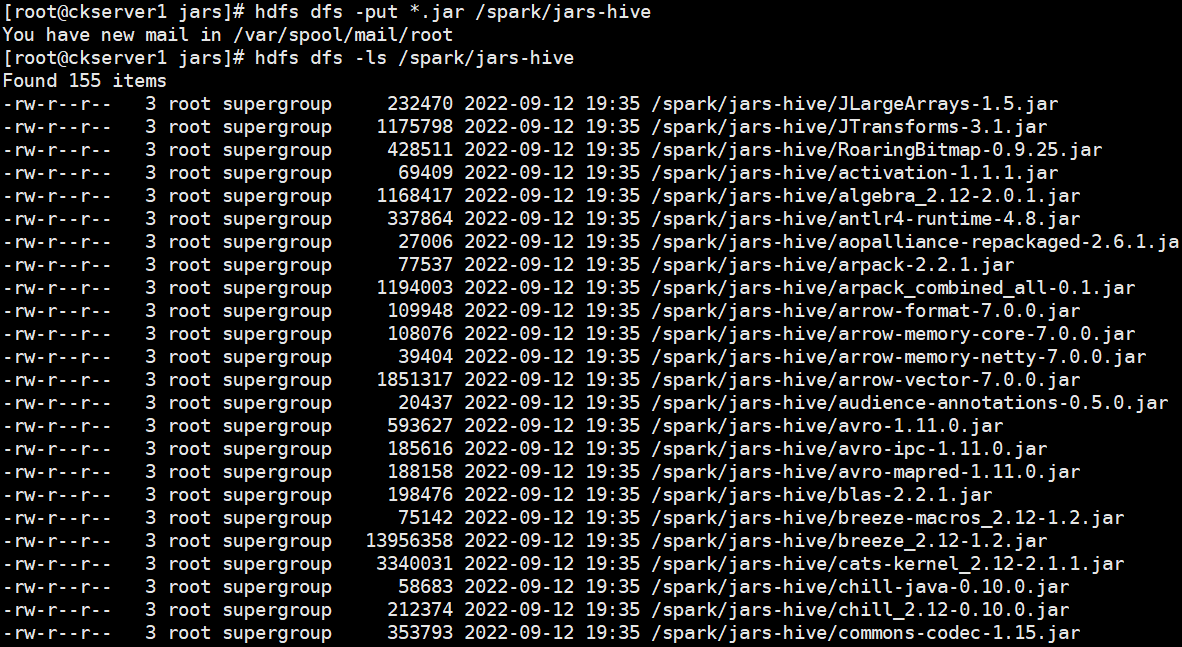
# HDFS创建/hive/log目录hdfs dfs -mkdir -p /hive/log# HDFS创建/spark/jars-hiveg目录hdfs dfs -mkdir -p /spark/jars-hivehdfs dfs -mkdir -p /hive/loghis# 进入jars目录cd spark-3.3.0-bin-hadoop3-without-hive/jars# 上传hdfs dfs -put *.jar /spark/jars-hive
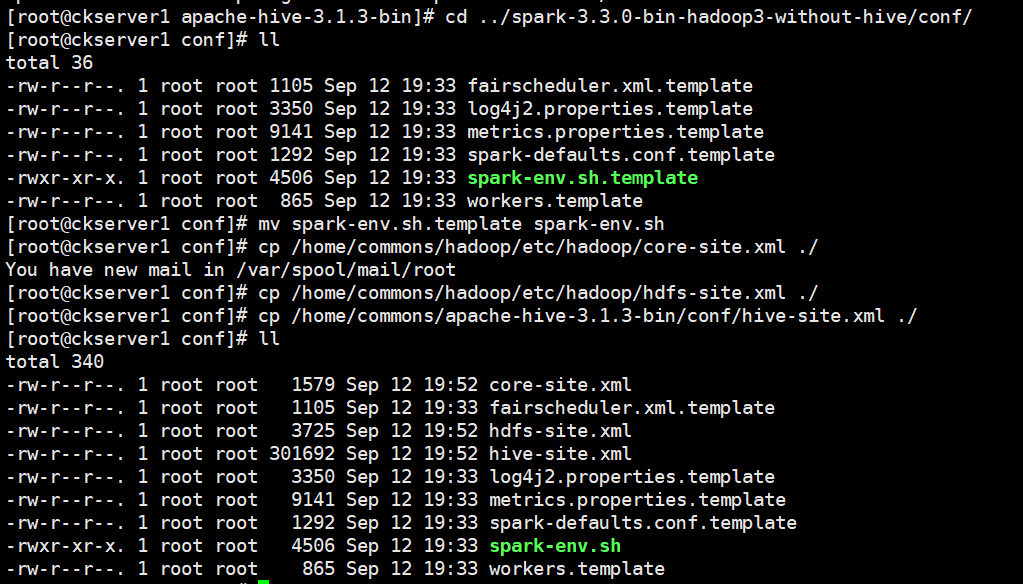
# 从Hive 2.2.0开始,Hive on Spark运行在Spark 2.0.0及以上版本,没有assembly jar。要使用YARN模式(YARN -client或YARN -cluster)运行,请将以下jar文件链接到HIVE_HOME/lib。scala-library、spark-core、spark-network-commoncp scala-library-2.12.15.jar /home/commons/apache-hive-3.1.3-bin/lib/cp spark-core_2.12-3.3.0.jar /home/commons/apache-hive-3.1.3-bin/lib/cp spark-network-common_2.12-3.3.0.jar /home/commons/apache-hive-3.1.3-bin/lib/# 拷贝配置文件到spark conf目录mv spark-env.sh.template spark-env.shcp /home/commons/hadoop/etc/hadoop/core-site.xml ./cp /home/commons/hadoop/etc/hadoop/hdfs-site.xml ./cp /home/commons/apache-hive-3.1.3-bin/conf/hive-site.xml ./
# spark-env.sh增加如下内容
vi spark-env.sh
SPARK_CONF_DIR=/home/commons/spark-3.3.0-bin-hadoop3-without-hive/conf
HADOOP_CONF_DIR=/home/commons/hadoop/etc/hadoop
YARN_CONF_DIR=//home/commons/hadoop/etc/hadoop
SPARK_EXECUTOR_CORES=3
SPARK_EXECUTOR_MEMORY=4g
SPARK_DRIVER_MEMORY=2g
# spark-defaults.conf增加增加如下内容
spark.yarn.historyServer.address=hadoop1:18080
spark.yarn.historyServer.allowTracking=true
spark.eventLog.dir=hdfs://myns:8020/hive/log
spark.eventLog.enabled=true
spark.history.fs.logDirectory=hdfs://myns:8020/hive/loghis
spark.yarn.jars=hdfs://myns:8020/spark/jars-hive/*
# 分发到其他机器
scp spark-env.sh hadoop2:/home/commons/spark-3.3.0-bin-hadoop3-without-hive/conf/
scp spark-env.sh hadoop2:/home/commons/spark-3.3.0-bin-hadoop3-without-hive/conf/
# 将Spark分发到其他两台上
scp -r /home/commons/spark-3.3.0-bin-hadoop3-without-hive/ hadoop2:/home/commons/
scp -r /home/commons/spark-3.3.0-bin-hadoop3-without-hive/ hadoop3:/home/commons/
# 分发hive的配置或目录到另外一台
scp -r apache-hive-3.1.3-bin hadoop2:/home/commons/
# 启动hiveserver2,两种方式选一
nohup hive --service hiveserver2 >> ~/hiveserver2.log 2>&1 &
# 启动metastore,两种方式选一
nohup hive --service metastore >> ~/metastore.log 2>&1 &
通过hive提交任务
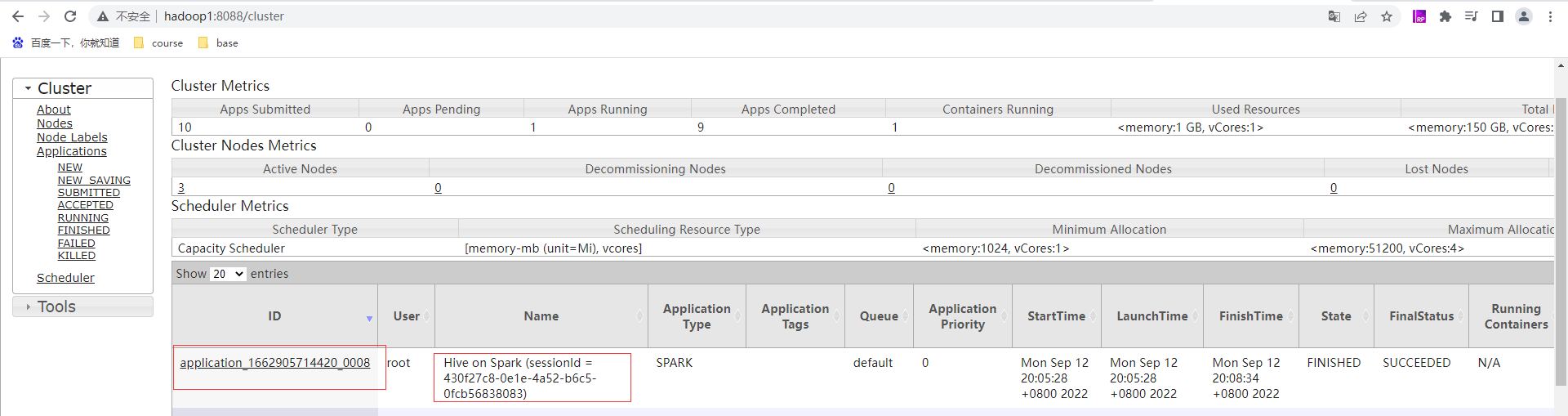
调优思路
编程方向
分组聚合优化
优化思路为map-side聚合。所谓map-side聚合,就是在map端维护一个hash table,利用其完成分区内的、部分的聚合,然后将部分聚合的结果,发送至reduce端,完成最终的聚合。map-side聚合能有效减少shuffle的数据量,提高分组聚合运算的效率。map-side 聚合相关的参数如下:--启用map-side聚合set hive.map.aggr=true;--hash map占用map端内存的最大比例set hive.map.aggr.hash.percentmemory=0.5;
join优化
参与join的两表一大一小,可考虑map join优化。Map Join相关参数如下:--启用map join自动转换set hive.auto.convert.join=true;--common join转map join小表阈值set hive.auto.convert.join.noconditionaltask.size
数据倾斜
group导致数据倾斜map-side聚合skew groupby优化其原理是启动两个MR任务,第一个MR按照随机数分区,将数据分散发送到Reduce,完成部分聚合,第二个MR按照分组字段分区,完成最终聚合。相关参数如下:--启用分组聚合数据倾斜优化set hive.groupby.skewindata=true; join导致数据倾斜使用map join启动skew join相关参数如下:--启用skew join优化set hive.optimize.skewjoin=true;--触发skew join的阈值,若某个key的行数超过该参数值,则触发set hive.skewjoin.key=100000;需要注意的是,skew join只支持Inner Join
任务并行度
对于一个分布式的计算任务而言,设置一个合适的并行度十分重要。在Hive中,无论其计算引擎是什么,所有的计算任务都可分为Map阶段和Reduce阶段。所以并行度的调整,也可从上述两个方面进行调整。
Map阶段并行度
Map端的并行度,也就是Map的个数。是由输入文件的切片数决定的。一般情况下,Map端的并行度无需手动调整。Map端的并行度相关参数如下:
--可将多个小文件切片,合并为一个切片,进而由一个map任务处理
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
--一个切片的最大值
set mapreduce.input.fileinputformat.split.maxsize=256000000;
Reduce阶段并行度
Reduce端的并行度,相对来说,更需要关注。默认情况下,Hive会根据Reduce端输入数据的大小,估算一个Reduce并行度。但是在某些情况下,其估计值不一定是最合适的,此时则需要人为调整其并行度。
Reduce并行度相关参数如下:
--指定Reduce端并行度,默认值为-1,表示用户未指定
set mapreduce.job.reduces;
--Reduce端并行度最大值
set hive.exec.reducers.max;
--单个Reduce Task计算的数据量,用于估算Reduce并行度
set hive.exec.reducers.bytes.per.reducer;
Reduce端并行度的确定逻辑为,若指定参数mapreduce.job.reduces的值为一个非负整数,则Reduce并行度为指定值。否则,Hive会自行估算Reduce并行度,估算逻辑如下:
假设Reduce端输入的数据量大小为totalInputBytes
参数hive.exec.reducers.bytes.per.reducer的值为bytesPerReducer
参数hive.exec.reducers.max的值为maxReducers
则Reduce端的并行度为:
min(ceil2×totalInputBytesbytesPerReducer,maxReducers)
其中,Reduce端输入的数据量大小,是从Reduce上游的Operator的Statistics(统计信息)中获取的。为保证Hive能获得准确的统计信息,需配置如下参数:
--执行DML语句时,收集表级别的统计信息
set hive.stats.autogather=true;
--执行DML语句时,收集字段级别的统计信息
set hive.stats.column.autogather=true;
--计算Reduce并行度时,从上游Operator统计信息获得输入数据量
set hive.spark.use.op.stats=true;
--计算Reduce并行度时,使用列级别的统计信息估算输入数据量
set hive.stats.fetch.column.stats=true;
小文件合并
Map端输入文件合并
合并Map端输入的小文件,是指将多个小文件划分到一个切片中,进而由一个Map Task去处理。目的是防止为单个小文件启动一个Map Task,浪费计算资源。
相关参数为:
--可将多个小文件切片,合并为一个切片,进而由一个map任务处理
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
Reduce输出文件合并
合并Reduce端输出的小文件,是指将多个小文件合并成大文件。目的是减少HDFS小文件数量。
相关参数为:
--开启合并Hive on Spark任务输出的小文件
set hive.merge.sparkfiles=true;
CBO
开启CBO可以自动调整join顺序相关参数为:--是否启用cbo优化set hive.cbo.enable=true;
谓词下推
将过滤操作前移相关参数为:--是否启动谓词下推(predicate pushdown)优化set hive.optimize.ppd = true;需要注意的是:CBO优化也会完成一部分的谓词下推优化工作,因为在执行计划中,谓词越靠前,整个计划的计算成本就会越低。
矢量化查询
Hive的矢量化查询,可以极大的提高一些典型查询场景(例如scans, filters, aggregates, and joins)下的CPU使用效率。相关参数如下:set hive.vectorized.execution.enabled=true;
Yarn配置推荐
需要调整的Yarn参数均与CPU、内存等资源有关,核心配置参数如下
yarn.nodemanager.resource.memory-mb 64
yarn.nodemanager.resource.cpu-vcores 16
yarn.scheduler.minmum-allocation-mb 512
yarn.sheduler.maximum-allocation-vcores 16384
yarn.scheduler.minimum-allocation-vcores 1
yarn.sheduler.maximum-allocation-vcores 2-4
yarn.nodemanager.resource.memory-mb该参数的含义是,一个NodeManager节点分配给Container使用的内存。该参数的配置,取决于NodeManager所在节点的总内存容量和该节点运行的其他服务的数量。考虑上述因素,此处可将该参数设置为64G,如下:<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>65536</value>
</property>
yarn.nodemanager.resource.cpu-vcores该参数的含义是,一个NodeManager节点分配给Container使用的CPU核数。该参数的配置,同样取决于NodeManager所在节点的总CPU核数和该节点运行的其他服务。考虑上述因素,此处可将该参数设置为16。<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>16</value>
</property>
yarn.scheduler.maximum-allocation-mb该参数的含义是,单个Container能够使用的最大内存。由于Spark的yarn模式下,Driver和Executor都运行在Container中,故该参数不能小于Driver和Executor的内存配置,推荐配置如下:<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>16384</value>
</property>
yarn.scheduler.minimum-allocation-mb该参数的含义是,单个Container能够使用的最小内存,推荐配置如下:<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
yarn调度策略使用容量调度,配置多个队列如小任务队列、大任务队列、临时需求队列
根据设置队列容量,在客户端提交任务指定队列
Spark配置推荐
Executor CPU核数配置
单个Executor的CPU核数,由spark.executor.cores参数决定,建议配置为4-6,具体配置为多少,视具体情况而定,原则是尽量充分利用资源。如单个节点共有16个核可供Executor使用,则spark.executor.core配置为4最合适。原因是,若配置为5,则单个节点只能启动3个Executor,会剩余1个核未使用;若配置为6,则只能启动2个Executor,会剩余4个核未使用。
spark.executor-cores 4
Executor CPU内存配置
spark.executor.memory用于指定Executor进程的堆内存大小,这部分内存用于任务的计算和存储;spark.executor.memoryOverhead用于指定Executor进程的堆外内存,这部分内存用于JVM的额外开销,操作系统开销等。两者的和才算一个Executor进程所需的总内存大小。默认情况下spark.executor.memoryOverhead的值等于spark.executor.memory*0.1。先按照单个NodeManager的核数和单个Executor的核数,计算出每个NodeManager最多能运行多少个Executor。在将NodeManager的总内存平均分配给每个Executor,最后再将单个Executor的内存按照大约10:1的比例分配到spark.executor.memory和spark.executor.memoryOverhead。
spark.executor-memory 14G
spark.executor.memoryOverhead 2G
Executor 个数配置
一个Spark应用Executor个数配置:executor个数是指分配给一个Spark应用的Executor个数,Executor个数对于Spark应用的执行速度有很大的影响,所以Executor个数的确定十分重要。一个Spark应用的Executor个数的指定方式有两种,静态分配和动态分配。
静态分配可通过spark.executor.instances指定一个Spark应用启动的Executor个数。这种方式需要自行估计每个Spark应用所需的资源,并为每个应用单独配置Executor个数。
动态分配动态分配可根据一个Spark应用的工作负载,动态的调整其所占用的资源(Executor个数)。这意味着一个Spark应用程序可以在运行的过程中,需要时,申请更多的资源(启动更多的Executor),不用时,便将其释放。在生产集群中,推荐使用动态分配。
动态分配相关参数如下:
#启动动态分配
spark.dynamicAllocation.enabled true
#启用Spark shuffle服务
spark.shuffle.service.enabled true
#Executor个数初始值
spark.dynamicAllocation.initialExecutors 1
#Executor个数最小值
spark.dynamicAllocation.minExecutors 1
#Executor个数最大值
spark.dynamicAllocation.maxExecutors 12
#Executor空闲时长,若某Executor空闲时间超过此值,则会被关闭
spark.dynamicAllocation.executorIdleTimeout 60s
#积压任务等待时长,若有Task等待时间超过此值,则申请启动新的Executor
spark.dynamicAllocation.schedulerBacklogTimeout 1s
spark.shuffle.useOldFetchProtocol true
说明:Spark shuffle服务的作用是管理Executor中的各Task的输出文件,主要是shuffle过程map端的输出文件。由于启用资源动态分配后,Spark会在一个应用未结束前,将已经完成任务,处于空闲状态的Executor关闭。Executor关闭后,其输出的文件,也就无法供其他Executor使用了。需要启用Spark shuffle服务,来管理各Executor输出的文件,这样就能关闭空闲的Executor,而不影响后续的计算任务了。
Driver配置
Driver主要配置内存即可,相关的参数有
spark.driver.memory和spark.driver.memoryOverhead。
spark.driver.memory用于指定Driver进程的堆内存大小
spark.driver.memoryOverhead用于指定Driver进程的堆外内存大小。
默认情况下,两者的关系如下:
spark.driver.memoryOverhead=spark.driver.memory*0.1。两者的和才算一个Driver进程所需的总内存大小。
一般情况下,按照如下经验进行调整即可:
假定yarn.nodemanager.resource.memory-mb设置为X,
若X>50G,则Driver可设置为12G,
若12G<X<50G,则Driver可设置为4G。
若1G<X<12G,则Driver可设置为1G。
yarn.nodemanager.resource.memory-mb为64G,则Driver的总内存可分配12G,所以上述两个参数可配置为
spark.driver.memory 10G
spark.yarn.driver.memoryOverhead 2G
整体配置
修改spark-defaults.conf文件
修改$HIVE_HOME/conf/spark-defaults.confspark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://myNameService1/spark-history
spark.executor.cores 4
spark.executor.memory 14g
spark.executor.memoryOverhead 2g
spark.driver.memory 10g
spark.driver.memoryOverhead 2g
spark.dynamicAllocation.enabled true
spark.shuffle.service.enabled true
spark.dynamicAllocation.executorIdleTimeout 60s
spark.dynamicAllocation.initialExecutors 1
spark.dynamicAllocation.minExecutors 1
spark.dynamicAllocation.maxExecutors 12
spark.dynamicAllocation.schedulerBacklogTimeout 1s
配置Spark shuffle服务Spark Shuffle服务的配置因Cluster Manager(standalone、Mesos、Yarn)的不同而不同。此处以Yarn作为Cluster Manager。
拷贝$SPARK_HOME/yarn/spark-3.0.0-yarn-shuffle.jar
到$HADOOP_HOME/share/hadoop/yarn/lib
$HADOOP_HOME/share/hadoop/yarn/lib/yarn/spark-3.0.0-yarn-shuffle.jar
修改$HADOOP_HOME/etc/hadoop/yarn-site.xml文件
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle,spark_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.spark_shuffle.class</name>
<value>org.apache.spark.network.yarn.YarnShuffleService</value>
</property>
**本人博客网站 **IT小神 www.itxiaoshen.com
数仓Hive和分布式计算引擎Spark多整合方式实战和调优方向的更多相关文章
- Spark数据本地化-->如何达到性能调优的目的
Spark数据本地化-->如何达到性能调优的目的 1.Spark数据的本地化:移动计算,而不是移动数据 2.Spark中的数据本地化级别: TaskSetManager 的 Locality L ...
- Spark机器学习——模型选择与参数调优之交叉验证
spark 模型选择与超参调优 机器学习可以简单的归纳为 通过数据训练y = f(x) 的过程,因此定义完训练模型之后,就需要考虑如何选择最终我们认为最优的模型. 如何选择最优的模型,就是本篇的主要内 ...
- Spark SQL概念学习系列之性能调优
不多说,直接上干货! 性能调优 Caching Data In Memory Spark SQL可以通过调用sqlContext.cacheTable("tableName") 或 ...
- 数仓建设 | ODS、DWD、DWM等理论实战(好文收藏)
本文目录: 一.数据流向 二.应用示例 三.何为数仓DW 四.为何要分层 五.数据分层 六.数据集市 七.问题总结 导读 数仓在建设过程中,对数据的组织管理上,不仅要根据业务进行纵向的主题域划分,还需 ...
- Spark Shuffle数据处理过程与部分调优(源码阅读七)
shuffle...相当重要,为什么咩,因为shuffle的性能优劣直接决定了整个计算引擎的性能和吞吐量.相比于Hadoop的MapReduce,可以看到Spark提供多种计算结果处理方式,对shuf ...
- Spark性能优化:数据倾斜调优
前言 继<Spark性能优化:开发调优篇>和<Spark性能优化:资源调优篇>讲解了每个Spark开发人员都必须熟知的开发调优与资源调优之后,本文作为<Spark性能优化 ...
- Spark(十二)--性能调优篇
一段程序只能完成功能是没有用的,只能能够稳定.高效率地运行才是生成环境所需要的. 本篇记录了Spark各个角度的调优技巧,以备不时之需. 一.配置参数的方式和观察性能的方式 额...从最基本的开始讲, ...
- 看SparkSql如何支撑企业数仓
企业级数仓架构设计与选型的时候需要从开发的便利性.生态.解耦程度.性能. 安全这几个纬度思考.本文作者:惊帆 来自于数据平台 EMR 团队 前言 Apache Hive 经过多年的发展,目前基本已经成 ...
- 基于MaxCompute的数仓数据质量管理
声明 本文中介绍的非功能性规范均为建议性规范,产品功能无强制,仅供指导. 参考文献 <大数据之路——阿里巴巴大数据实践>——阿里巴巴数据技术及产品部 著. 背景及目的 数据对一个企业来说已 ...
随机推荐
- MYSQL的事务和索引
事务 什么是事务 事务就是将一组SQL语句放在同一批次内去执行 如果一个SQL语句出错,则该批次内的所有SQL都将被取消执行 MySQL事务处理只支持InnoDB和BDB数据表类型 事务的ACID原则 ...
- 零基础学Python:元组(Tuple)详细教程
Python的元组与列表类似,不同之处在于元组的元素不能修改,元组使用小括号,列表使用方括号,元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可https://jq.qq.com/?_wv=1 ...
- .NET ORM框架HiSql实战-第一章-集成HiSql
一.引言 做.Net这么多年,出现了很多很多ORM框架,比如Dapper,Sqlsugar,Freesql等等.在之前的项目中,用到的ORM框架也大多数是这几个老牌的框架. 不过最近园子关于.NET ...
- HDFS数据平衡
一.datanode之间的数据平衡 1.1.介绍 Hadoop 分布式文件系统(Hadoop Distributed FilSystem),简称 HDFS,被设计成适合运行在通用硬件上的分布式文件 ...
- 阿里云有奖体验:用PolarDB-X搭建一个高可用系统
体验简介 场景将提供一台配置了CentOS 8.5操作系统和安装部署PolarDB-X集群的ECS实例(云服务器).通过本教程的操作,带您体验如何使用PolarDB-X搭建一个高可用系统,通过直接ki ...
- 本地使用 Docker Compose 与 Nestjs 快速构建基于 Dapr 的 Redis 发布/订阅分布式应用
Dapr(分布式应用程序运行时)介绍 Dapr 是一个可移植的.事件驱动的运行时,它使任何开发人员能够轻松构建出弹性的.无状态和有状态的应用程序,并可运行在云平台或边缘计算中,它同时也支持多种编程语言 ...
- Hadoop-HA 搭建高可用集群Hadoop Zookeeper
Hadoop Zookeeper 搭建(一) 一.准备工作 VMWARE虚拟机 CentOS 7 系统 虚拟机1:master 虚拟机2:node1 虚拟机3:node2 时间同步 ntpdate n ...
- Java开发学习(十五)----AOP入门案例及其工作流程解析
一.AOP简介 1.1 什么是AOP AOP(Aspect Oriented Programming)面向切面编程,一种编程范式,指导开发者如何组织程序结构. OOP(Object Oriented ...
- 利用Kaptcha.jar生成图片验证码(以下源码可以直接复制并自定义修改)
说明:Kaptcha是一个很实用的验证码生成工具,它可以生成各种样式的验证码,因为它是可以配置的 目录: 一 实现步骤 二 实例 A 编写jsp页面 B 配置web.xml C 验证输入正确与否. 一 ...
- nginx反向代理缓存配置
关于nginx的反向代理缓存配置,用的最多的就是CDN公司,目前CDN公司用纯nginx做缓存的已经很少了,基本都用tnginx(阿里的).openresty:但是这两款软件都是基于nignx开发的, ...