Flink Window&Time 原理
Flink 中可以使用一套 API 完成对有界数据集以及无界数据的统一处理,而无界数据集的处理一般会伴随着对某些固定时间间隔的数据聚合处理。比如:每五分钟统计一次系统活跃用户、每十秒更新热搜榜单等等
这些需求在 Flink 中都由 Window 提供支持,Window 本质上就是借助状态后端缓存着一定时间段内的数据,然后在达到某些条件时触发对这些缓存数据的聚合计算,输出外部系统。
实际上,有的时候对于一些实时性要求不高的、下游系统无法负载实时输出的场景,也会通过窗口做一个聚合,然后再输出下游系统。
Time
时间类型
Flink 是基于事件流的实时处理引擎,那么流入系统的每一件事件都应该有一个时间,Flink 提供以下四种时间类型来定义你的事件时间:
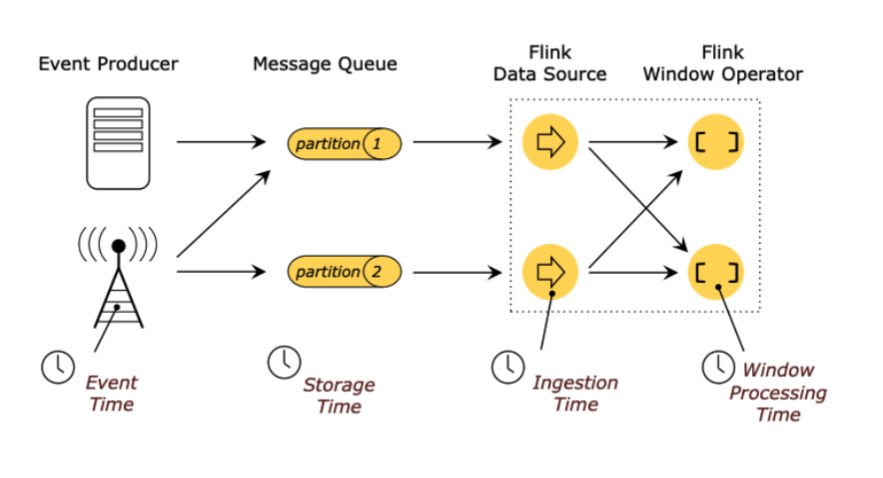
Event Time:这是我们最常用的时间类型,它表示事件真实发生时的时间(比如你点击一个按钮,就是点击的一瞬间的那个时间) Storage Time:不常用,表示事件以消息的形式进入队列时的时间 Ingestion Time:不常用,表示事件进入 Flink Source 的时间 Processing Time:相对常用一些,表示事件实际进入到 window 算子被处理的时间
以上四种实际上用的最多的还是 EventTime,ProcessingTime 偶尔会用一用。
因为 EventTime 是描述事件真实发生的时间,我们知道事件发生是有顺序的,但经过网络传输后不一定能保证接收顺序。比如:你先买了 A 商品,再买了 B 商品,那么其实有很大可能 Flink 先收到 B 商品的购买事件,再收到 A 的。通过 EventTime 就可以保证即便 A 事件后到来我也知道它是先发生的。
而 ProcessingTime 描述的是事件被处理时的时间,准确来说并不是事件真实发生的时间,所以它往往在一些不关注事件到达顺序的情境中使用。
Watermark 水位线
Watermark 在很多系统中都有应用,可能各个系统的叫法不同,但这种思想还是比较常见的。比如:Kafka 中副本同步机制中的高水位、MySQL 事务隔离机制中可见事务的高低水位等等。
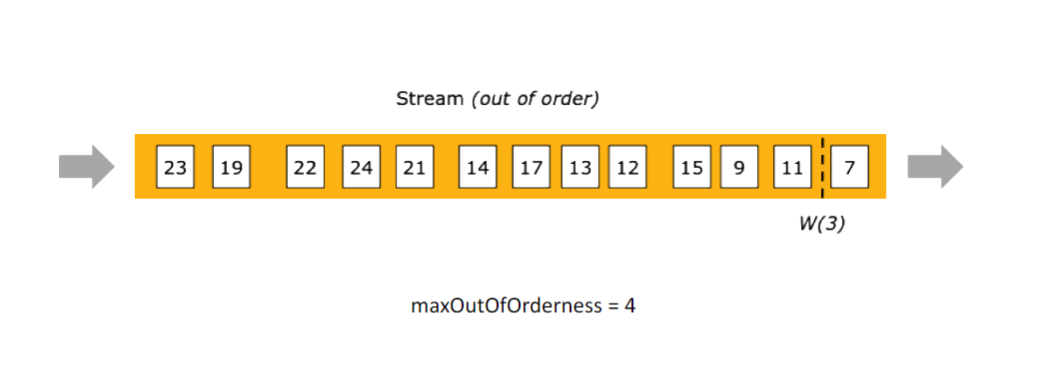
在 Flink 中 Watermark 描述的也是一种水位线的概念,他表示水位线之下的所有数据都已经被 Flink 接收并处理了。
窗口的触发一般就会基于 Watermark 来实现,水位线动态更新,当达到某某条件就触发哪些窗口的计算。
关于 Watermark 如何更新,Flink 是开放给你实现的,当然它也提供了一些默认实现。
Timestamp 的抽取
如果你指定 Flink 需要使用 EventTime,那么你就需要在 WatermarkStrategy 策略中通过 withTimestampAssigner 指定如何从你的事件中抽取出 Timestamp 作为 EventTime。比如:

Watermark 的生成
Watermark 的生成方式本质上是有两种:周期性生成和标记生成。
/**
* {@code WatermarkGenerator} 可以基于事件或者周期性的生成 watermark。
*
* <p><b>注意:</b> WatermarkGenerator 将以前互相独立的 {@code AssignerWithPunctuatedWatermarks}
* 和 {@code AssignerWithPeriodicWatermarks} 一同包含了进来。
*/
@Public
public interface WatermarkGenerator<T> {
/**
* 每来一条事件数据调用一次,可以检查或者记录事件的时间戳,或者也可以基于事件数据本身去生成 watermark。
*/
void onEvent(T event, long eventTimestamp, WatermarkOutput output);
/**
* 周期性的调用,也许会生成新的 watermark,也许不会。
*
* <p>调用此方法生成 watermark 的间隔时间由 {@link ExecutionConfig#getAutoWatermarkInterval()} 决定。
*/
void onPeriodicEmit(WatermarkOutput output);
}
周期性生成器通常通过 onEvent() 观察传入的事件数据,然后在框架调用 onPeriodicEmit() 时更新 Watermark。
标记生成器将查看 onEvent() 中的事件数据,然后根据你自定义的逻辑是否需要更新 Watermark。
比如这是一个官网给出的例子:
/**
* 该 watermark 生成器可以覆盖的场景是:数据源在一定程度上乱序。
* 即某个最新到达的时间戳为 t 的元素将在最早到达的时间戳为 t 的元素之后最多 n 毫秒到达。
*/
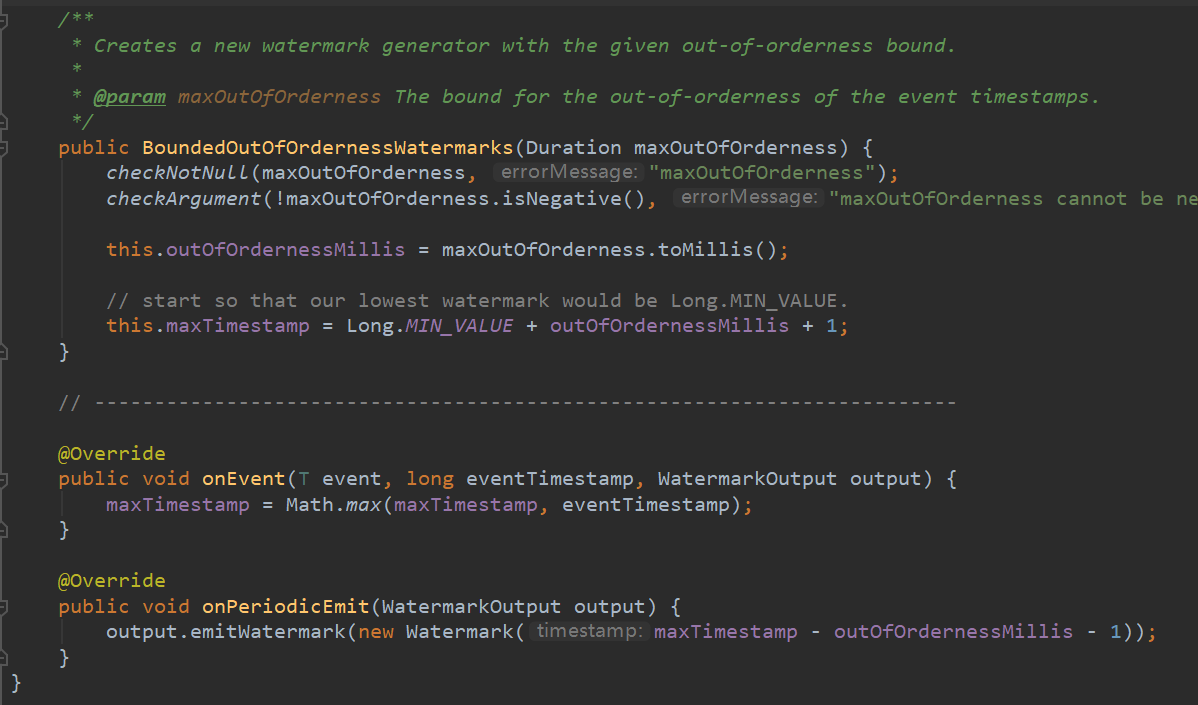
public class BoundedOutOfOrdernessGenerator implements WatermarkGenerator<MyEvent> {
private final long maxOutOfOrderness = 3000; // 3 秒
private long currentMaxTimestamp;
@Override
public void onEvent(MyEvent event, long eventTimestamp, WatermarkOutput output) {
currentMaxTimestamp = Math.max(currentMaxTimestamp, eventTimestamp);
}
@Override
public void onPeriodicEmit(WatermarkOutput output) {
// 发出的 watermark = 当前最大时间戳 - 最大乱序时间
output.emitWatermark(new Watermark(currentMaxTimestamp - maxOutOfOrderness - 1));
}
}
它实现的逻辑就是:每个事件到来会根据自身携带的 EventTime 和当前已到达的最大时间戳进行对比,保留两者较大的时间戳用以描述当前已到达的最大事件。
然后 onPeriodicEmit 周期性的更新 WaterMark:最多接收 3s 的延迟数据,也就是 "2022 07-24 10:10:20" 的事件到达就会生成一个 "2022 07-24 10:10:17" 的 WaterMark 表示在此水位线之前的数据全部收到并且不再接收此水位线之前的事件。(这部分不再被接收的数据实际上会被叫做迟到数据)
Flink 中内置的一个用的比较多的生成器就是:
WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(3));
这个其实就是我们上面的示例封装,它的内部实现就是这样:
Watermark 的传播
在多并行度下,Watermark 具有木桶效应,取最小的。比如下图中
map1 和 map2 会 keyby 把部分数据流到 window1,map1 产生的 w(29) 和 map2 产生的 w(14),最终 window1 会以 w(14) 往下游算子传播。
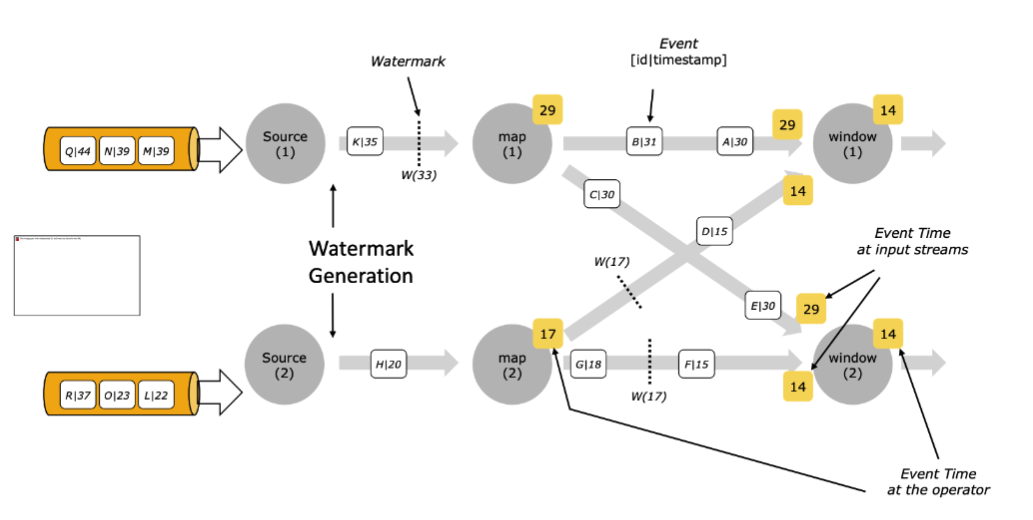
传小不传大应该是比较好理解的,如果传大的就会让进度慢的 map2 后续的数据全部被认为迟到数据而被丢弃。
这里其实会存在一个问题,如果 map2 突然没数据了,也就是不再更新 Watermark 往下游传播了,那么是不是就整个数据流再也不会推进 Watermark 了?
实际上,这种情况是存在的,Flink 中提供如下配置可以将某个源标记为空闲,即将它刨除 Watermark 的计算列表中。比如一分钟没有数据流出即标记为空闲数据源。
WatermarkStrategy
.<Tuple2<Long, String>>forBoundedOutOfOrderness(Duration.ofSeconds(20))
.withIdleness(Duration.ofMinutes(1));
Window
Window 本质上就是借助状态后端缓存着一定时间段内的数据,然后在达到某些条件时触发对这些缓存数据的聚合计算,输出外部系统。
Flink 中会根据当前数据流是否经过 keyby 算子分为「Keyed 和 Non-Keyed Windows」
KeyedWindow 实际上就是每个 key 都对应一个窗口,而 Non-KeyedWindow 实际上是全局并行度为1的窗口(即便你手动指定多并行度也是无效的)
一个完整的 WindowStream 的处理流程大概是这样的,数据经过 assigner 的挑选进入对应的窗口,经过 trigger 的逻辑触发窗口,再经过 evictor 的剔除逻辑,然后由 WindowFuction 完成处理逻辑,最终输出结果。
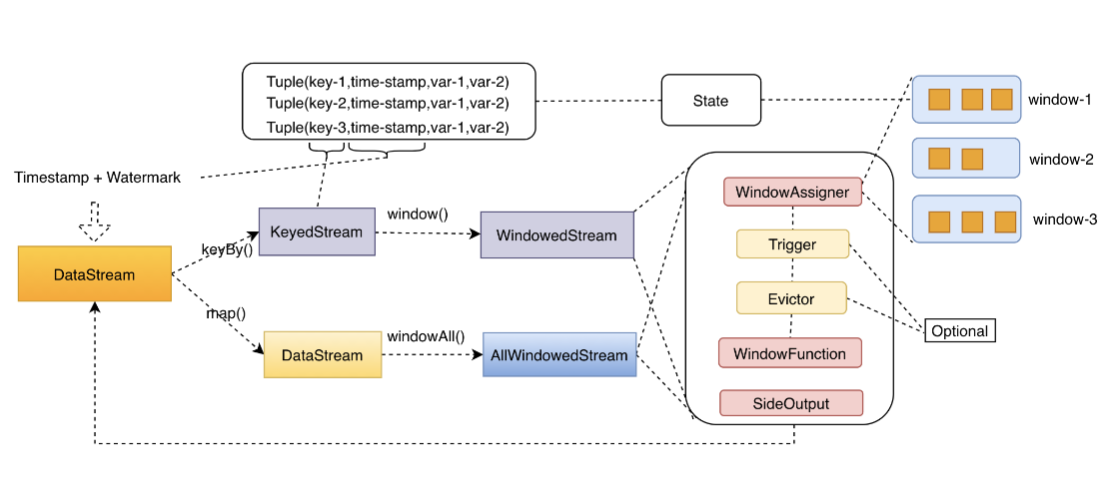
Window Assigners
Window assigner 定义了 stream 中的元素如何被分发到各个窗口。换句话说,每一个事件数据到来,Flink 通过 assigner 的逻辑来确定当前事件数据应该发往哪个或者哪几个窗口。
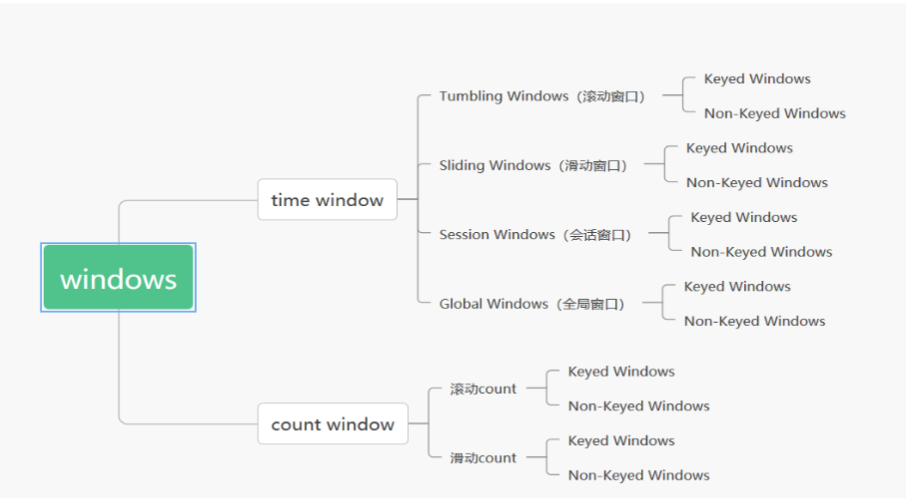
内置的 WindowAssigners
Flink 中预定义好了四款 WindowAssigner,几乎可以满足日常百分之八九十的场景需求。
滚动窗口(Tumbling Windows)
滚动窗口的 assigner 分发元素到指定大小的窗口。滚动窗口的大小是固定的,且各自范围之间不重叠。
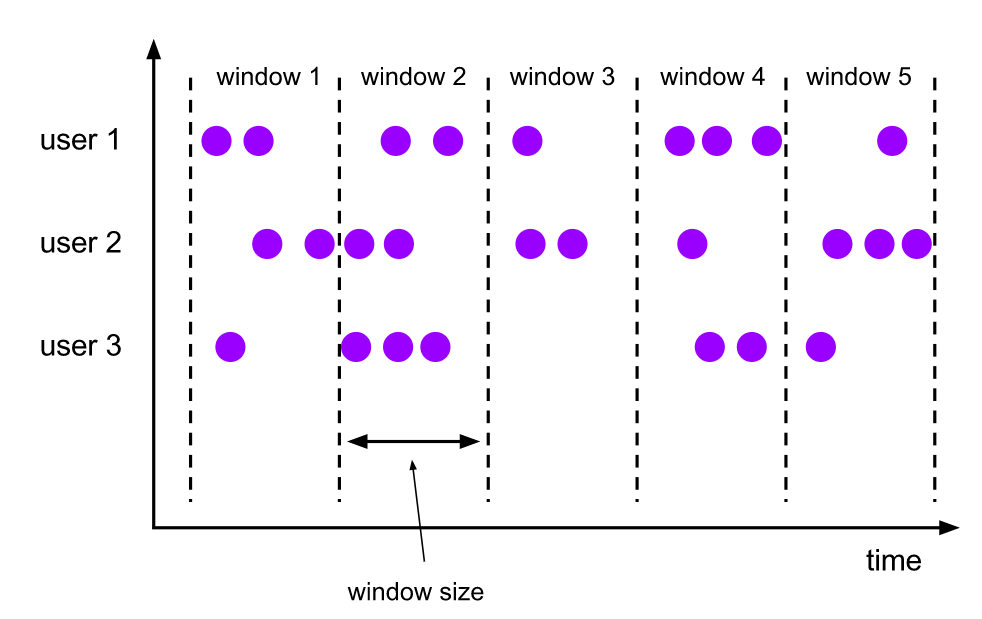
通过使用 TumblingEventTimeWindows 或者 TumblingProcessingTimeWindows 来指定使用滚动窗口。
除此之外,滚动窗口还实现好了一个默认的 Trigger 触发器 EventTimeTrigger,也就是说使用滚动窗口默认不需要再指定触发器了,至于触发器是什么待会儿会介绍,这里只是需要知道它是有默认触发器实现的。
滑动窗口(Sliding Windows)
滑动窗口和滚动窗口的区别在于,多了一个滑动维度,也就是说窗口仍然是固定长度,但是窗口会以一个固定步长进行滑动。
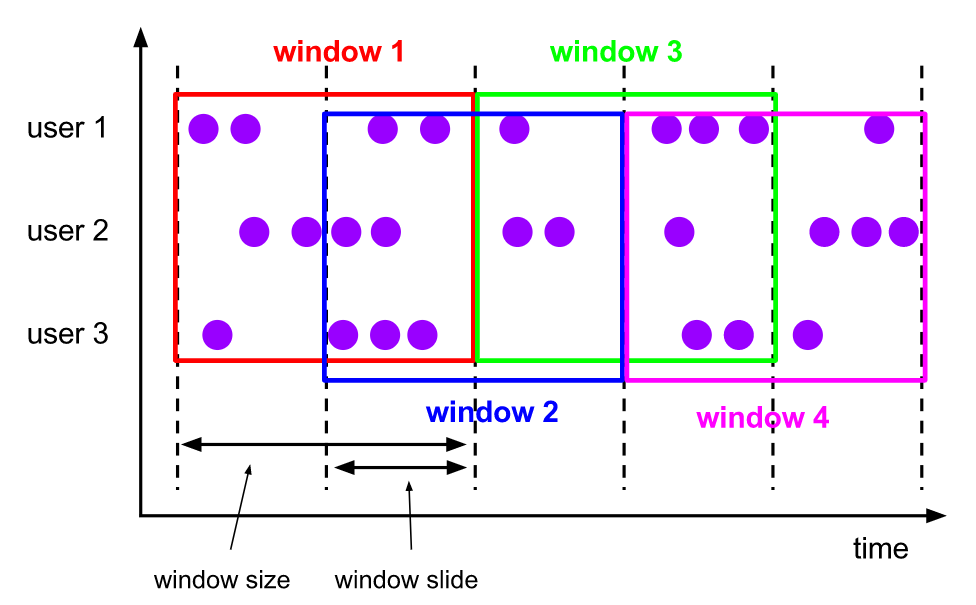
比如窗口是 10m,滑动步长是 5m,那么 window1 后 5m 的数据其实也是 window2 前 5m 的数据,这种窗口的特点就是存在数据重复。
这种窗口的数据场景还是比较多的,比如:每隔 5 分钟输出最近一小时内点击量最多的前 N 个商品。(windowsize=1h,slide=5m,每间隔 5m 会有一个窗口产生,而每个窗口包含 1h 的数据)
通过 SlidingEventTimeWindows 和 SlidingProcessingTimeWindows 来指定使用滑动窗口。区别的是,滑动窗口对于一个事件可能返回多个窗口,以表示该数据同时存在于多个窗口之中。
滑动窗口和滚动窗口使用的是同一个触发器 EventTimeTrigger。
会话窗口(Session Windows)
会话窗口的 assigner 会把数据按活跃的会话分组。会话窗口没有固定的开始和结束时间,我们唯一需要指定的 sessionGap,表示如果两条数据之间差距查过这个时间间隔即切分两个窗口。
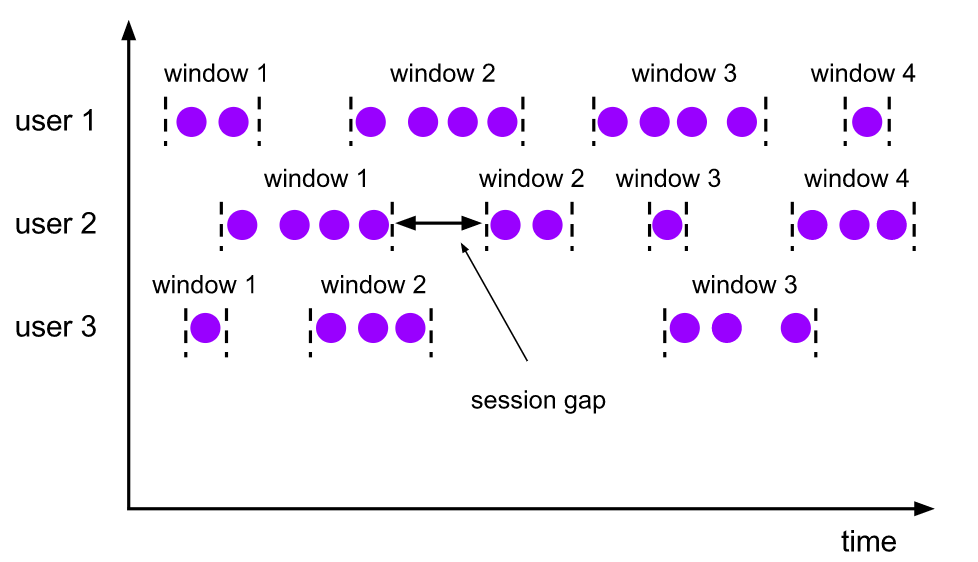
其实从 Flink 源码的角度看会话窗口的实现就是:每条数据过来都会创建一个窗口(timestamp, timestamp+sessionGap),然后会对重合的窗口集进行不断的 merge 输出成一个窗口。这样,窗口的截止就是最后一个活跃事件加上 sessionGap。非常巧妙的实现了 gap 这个语义。
默认的窗口触发器依然是 EventTimeTrigger。
全局窗口(Global Windows)
全局窗口就是会将所有的数据 Shuffle 到一个实例上,单并行度收集所有数据。

通过使用 GlobalWindows 来指定使用全局窗口,需要注意的是:全局窗口没有默认的触发器,也就是数据默认永远不会触发。
所以,如果需要用到全局窗口,一定记得指定窗口触发器。实际上 countWindow 本质上就是一个全局窗口,全局计数的窗口。
自定义 WindowAssigners
上面说的四种 WindowAssigners 是 Flink 内置的默认的实现,应该可以满足大家平常百分之八九十的需求。除此之外的是,Flink 也允许你自定义实现 WindowAssigner,以下是它的一些核心方法:
assignWindows getDefaultTrigger isEventTime getWindowSerializer
其中 assignWindows 方法它将返回一个 window 用以表示当前事件处于哪个窗口中。
getDefaultTrigger 方法返回一个默认实现的触发器,这个触发器默认和当前 WindowAssigner 绑定,当然你也可以外部再显式指定替换。
isEventTime 用于标记当前 WindowAssigner 是否是基于 EventTime 实现的,getWindowSerializer 方法将告诉 Flink 应该如何序列化当前窗口。
总之,重点重写 assignWindows 的逻辑即可,你也可以去打开 Flink 内置的四种 WindowAssigner 的源码实现进行参考。
窗口函数(Window Functions)
WindowFunction 就是定义了窗口在触发后应该如何计算的逻辑。
窗口函数有三种:ReduceFunction、AggregateFunction 或 ProcessWindowFunction。
ReduceFunction 指定两条输入数据如何合并起来产生一条输出数据,输入和输出数据的类型必须相同。 AggregateFunction 会在每条数据到达窗口后 进行增量聚合,相对性能较好。 ProcessWindowFunction 只会在触发器生效时将窗口中所有的数据全部发到 ProcessWindowFunction 进行计算,更灵活但性能更差。
Triggers
顾名思义,触发器用于决定窗口是否触发,Flink 中内置了一些触发器,如图:

其中,EventTimeTrigger 已经在上文中多次出现,它的逻辑也比较简单,就是当每个事件过来时判断当前 Watermark 是否越过窗口边界,如果是则触发窗口,Flink 也将调用你的 ProcessFunction 传入窗口中所有数据进行计算。
Trigger 接口中有如下一下核心方法需要关注:
onElement onEventTime onProcessingTime
其中,onElement 会在每个事件到来被调用,onEventTime 和 onProcessingTime 都将在 Flink timer 的定时器中被调用。
其余的一些 Triggers 相对不是特别常用,不过也没有特别复杂,你可以直接查看它的源码实现。
比如:ContinuousEventTimeTrigger,它就是在 EventTimeTrigger 的基础上增加了固定时间间隔触发,每个事件过来如果没有达到触发条件,会通过 ReducingState 记录下 "time+interval" 也就是下一次触发的时间并注册一个 timer,最终会在 timer 的调度下执行 onEventTime 完成窗口触发。
Evictors
Flink 的窗口模型允许在 WindowAssigner 和 Trigger 之外指定可选的 Evictor,在 trigger 触发后、调用窗口函数之前或之后从窗口中删除元素,我们也称它为剔除器。
用法也比较简单,就是在 windowStream 后调用 evictor()方法,并提供 Evictor 实现类,Evictor 类中有两个方法需要实现,evictBefore() 包含在调用窗口函数前的逻辑,而 evictAfter() 包含在窗口函数调用之后的逻辑。
Flink 中也提供了内置的一些剔除器:
CountEvictor:仅记录用户指定数量的元素,一旦窗口中的元素超过这个数量,多余的元素会从窗口缓存的开头移除 DeltaEvictor:接收 DeltaFunction 和 threshold 参数,计算最后一个元素与窗口缓存中所有元素的差值, 并移除差值大于或等于 threshold 的元素 TimeEvictor:接收 interval 参数,以毫秒表示。 它会找到窗口中元素的最大 timestamp max_ts 并移除比 max_ts - interval 小的所有元素
最后说一下关于迟到数据,没有被窗口包含的数据在 Flink 中可以不被丢弃,Flink 中有 Allowed Lateness 策略,即通过 allowedLateness 方法指定一个最大可接受的延迟时间,那么这部分迟到的数据将可以通过旁路输出(sideOutputLateData)获取到。

Flink Window&Time 原理的更多相关文章
- 一文搞懂Flink Window机制
Windows是处理无线数据流的核心,它将流分割成有限大小的桶(buckets),并在其上执行各种计算. 窗口化的Flink程序的结构通常如下,有分组流(keyed streams)和无分组流(non ...
- Flink架构、原理与部署测试
Apache Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,它能够基于同一个Flink运行时,提供支持流处理和批处理两种类型应用的功能. 现有的开源计算方案,会把流处理和批处理作为 ...
- Flink架构、原理与部署测试(转)
Apache Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,它能够基于同一个Flink运行时,提供支持流处理和批处理两种类型应用的功能. 现有的开源计算方案,会把流处理和批处理作为 ...
- flink window实例分析
window是处理数据的核心.按需选择你需要的窗口类型后,它会将传入的原始数据流切分成多个buckets,所有计算都在window中进行. flink本身提供的实例程序TopSpeedWindowin ...
- 【翻译】Flink window
本文翻译自flink官网:https://ci.apache.org/projects/flink/flink-docs-release-1.9/dev/stream/operators/window ...
- Flink – window operator
参考, http://wuchong.me/blog/2016/05/25/flink-internals-window-mechanism/ http://wuchong.me/blog/201 ...
- flink window的early计算
Tumbing Windows:滚动窗口,窗口之间时间点不重叠.它是按照固定的时间,或固定的事件个数划分的,分别可以叫做滚动时间窗口和滚动事件窗口.Sliding Windows:滑动窗口,窗口之间时 ...
- flink Window的Timestamps/Watermarks和allowedLateness的区别
Watermartks是通过additional的时间戳来控制窗口激活的时间,allowedLateness来控制窗口的销毁时间. 注: 因为此特性包括官方文档在1.3-1.5版本均未做改变,所以 ...
- Flink window机制
此文已由作者岳猛授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. 问题 window是解决流计算中的什么问题? 怎么划分window?有哪几种window?window与时间属 ...
随机推荐
- NLP教程(7) - 问答系统
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www.showmeai.tech/article-det ...
- (AAAI2020 Yao) Graph Few-shot Learning via knowledge transfer
22-5-13 seminar上和大家分享了这篇文章 [0]Graph few-shot learning via knowledge transfer 起因是在MLNLP的公众号上看到了张初旭老师讲 ...
- 590. N-ary Tree Postorder Traversal - LeetCode
Question 590. N-ary Tree Postorder Traversal Solution 题目大意:后序遍历一个树 思路: 1)递归 2)迭代 Java实现(递归): public ...
- UNION 与 UNION ALL 的区别
UNION:合并查询结果,并去掉重复的行. UNION ALL:合并查询结果,保留重复的行. 举例验证说明: 创建两个表:user_info 和 user_info_b,设置联合主键约束,联合主键的列 ...
- 解决WIN7无法安装高版本Node.js问题
网上很多文章都让去安装低版本node 由于业务需求,低版本node npm 有一些包支持的不好 npm出cb() never call 本着更新npm 顺带弄个高版本的node 单独更新npm npm ...
- 从零开始实现lmax-Disruptor队列(一)RingBuffer与单生产者、单消费者工作原理解析
1.lmax-Disruptor队列介绍 disruptor是英国著名的金融交易所lmax旗下技术团队开发的一款java实现的高性能内存队列框架 其发明disruptor的主要目的是为了改进传统的内存 ...
- 【物联网串口服务器通信经验教程】Modbus网关协议转换
在前面的文章中,我们已经详细地介绍了Modbus网关的几种主要类型,今天,就让我们来介绍一下其中简单协议转换的处理过程. 简单协议转换是最常规.最普遍的Modbus网关功能,也是数据处理效率最高Mod ...
- Linux(Centos7)静默安装Oracle19C
Oracle数据库服务器一般都是Linux,Linux服务器一般都是在非图形界面的操作,本文章手把手教你如何在非图形界面安装Oracle19C. ORACLE 19C 的安装包自行在官网下载,下载免费 ...
- vue海康视频播放组件
海康视频插件web文档 渲染组件后,调用initPlugin函数,传入一个code数组 <template> <div :title="name" :id=&qu ...
- 开发工具-RSA加解密
更新日志 2022年6月10日 初始化链接. https://toolb.cn/rsa