HBase学习(四) 二级索引 rowkey设计
HBase学习(四)
一、HBase的读写流程
画出架构
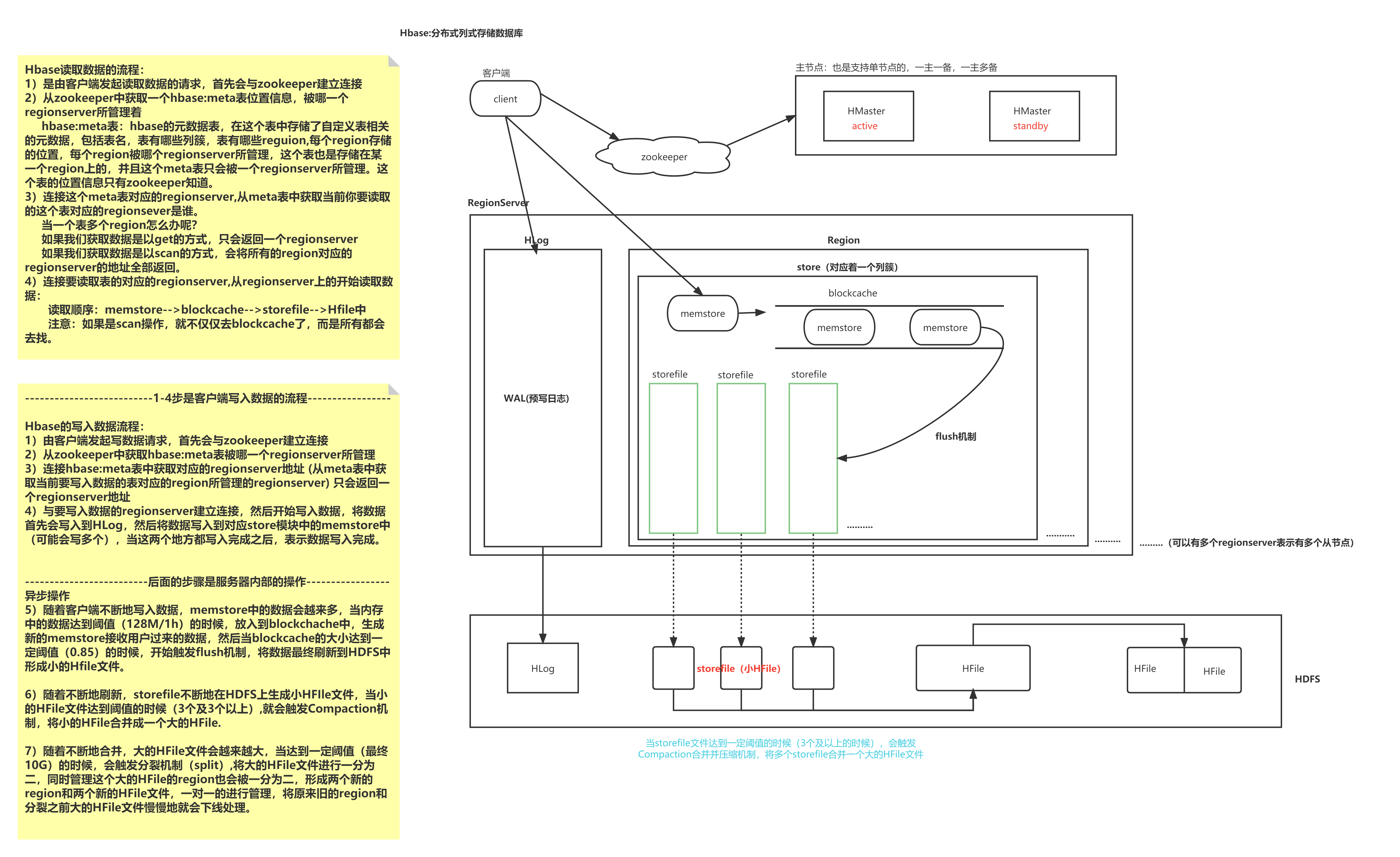
1.1 HBase读流程
- Hbase读取数据的流程:
1)是由客户端发起读取数据的请求,首先会与zookeeper建立连接
2)从zookeeper中获取一个hbase:meta表位置信息,被哪一个regionserver所管理着
hbase:meta表:hbase的元数据表,在这个表中存储了自定义表相关的元数据,包括表名,表有哪些列簇,表有哪些reguion,每个region存储的位置,每个region被哪个regionserver所管理,这个表也是存储在某一个region上的,并且这个meta表只会被一个regionserver所管理。这个表的位置信息只有zookeeper知道。
3)连接这个meta表对应的regionserver,从meta表中获取当前你要读取的这个表对应的regionsever是谁。
当一个表多个region怎么办呢?
如果我们获取数据是以get的方式,只会返回一个regionserver
如果我们获取数据是以scan的方式,会将所有的region对应的regionserver的地址全部返回。
4)连接要读取表的对应的regionserver,从regionserver上的开始读取数据:
读取顺序:memstore-->blockcache-->storefile-->Hfile中
注意:如果是scan操作,就不仅仅去blockcache了,而是所有都会去找。
1.2 HBase写流程
- --------------------------1-4步是客户端写入数据的流程-----------------
Hbase的写入数据流程:
1)由客户端发起写数据请求,首先会与zookeeper建立连接
2)从zookeeper中获取hbase:meta表被哪一个regionserver所管理
3)连接hbase:meta表中获取对应的regionserver地址 (从meta表中获取当前要写入数据的表对应的region所管理的regionserver) 只会返回一个regionserver地址
4)与要写入数据的regionserver建立连接,然后开始写入数据,将数据首先会写入到HLog,然后将数据写入到对应store模块中的memstore中
(可能会写多个),当这两个地方都写入完成之后,表示数据写入完成。
-------------------------后面的步骤是服务器内部的操作-----------------
异步操作
5)随着客户端不断地写入数据,memstore中的数据会越来多,当内存中的数据达到阈值(128M/1h)的时候,放入到blockchache中,生成新的memstore接收用户过来的数据,然后当blockcache的大小达到一定阈值(0.85)的时候,开始触发flush机制,将数据最终刷新到HDFS中形成小的Hfile文件。
6)随着不断地刷新,storefile不断地在HDFS上生成小HFIle文件,当小的HFile文件达到阈值的时候(3个及3个以上),就会触发Compaction机制,将小的HFile合并成一个大的HFile.
7)随着不断地合并,大的HFile文件会越来越大,当达到一定阈值(最终10G)的时候,会触发分裂机制(split),将大的HFile文件进行一分为二,同时管理这个大的HFile的region也会被一分为二,形成两个新的region和两个新的HFile文件,一对一的进行管理,将原来旧的region和分裂之前大的HFile文件慢慢地就会下线处理。
二、Region的分裂策略
region中存储的是一张表的数据,当region中的数据条数过多的时候,会直接影响查询效率。当region过大的时候,region会被拆分为两个region,HMaster会将分裂的region分配到不同的regionserver上,这样可以让请求分散到不同的RegionServer上,已达到负载均衡 , 这也是HBase的一个优点 。
ConstantSizeRegionSplitPolicy
0.94版本前,HBase region的默认切分策略
当region中最大的store大小超过某个阈值(hbase.hregion.max.filesize=10G)之后就会触发切分,一个region等分为2个region。
但是在生产线上这种切分策略却有相当大的弊端(切分策略对于大表和小表没有明显的区分):
阈值(hbase.hregion.max.filesize)设置较大对大表比较友好,但是小表就有可能不会触发分裂,极端情况下可能就1个,形成热点,这对业务来说并不是什么好事。
如果设置较小则对小表友好,但一个大表就会在整个集群产生大量的region,这对于集群的管理、资源使用、failover来说都不是一件好事。
IncreasingToUpperBoundRegionSplitPolicy
0.94版本~2.0版本默认切分策略
总体看和ConstantSizeRegionSplitPolicy思路相同,一个region中最大的store大小大于设置阈值就会触发切分。 但是这个阈值并不像ConstantSizeRegionSplitPolicy是一个固定的值,而是会在一定条件下不断调整,调整规则和region所属表在当前regionserver上的region个数有关系.
region split阈值的计算公式是:
设regioncount:是region所属表在当前regionserver上的region的个数
阈值 = regioncount^3 * 128M * 2,当然阈值并不会无限增长,最大不超过MaxRegionFileSize(10G),当region中最大的store的大小达到该阈值的时候进行region split
例如:
第一次split阈值 = 1^3 * 256 = 256MB
第二次split阈值 = 2^3 * 256 = 2048MB
第三次split阈值 = 3^3 * 256 = 6912MB
第四次split阈值 = 4^3 * 256 = 16384MB > 10GB,因此取较小的值10GB
后面每次split的size都是10GB了
特点
相比ConstantSizeRegionSplitPolicy,可以自适应大表、小表;
在集群规模比较大的情况下,对大表的表现比较优秀
对小表不友好,小表可能产生大量的小region,分散在各regionserver上
小表达不到多次切分条件,导致每个split都很小,所以分散在各个regionServer上
SteppingSplitPolicy
2.0版本默认切分策略
相比 IncreasingToUpperBoundRegionSplitPolicy 简单了一些 region切分的阈值依然和待分裂region所属表在当前regionserver上的region个数有关系
如果region个数等于1,切分阈值为flush size 128M * 2
否则为MaxRegionFileSize。
这种切分策略对于大集群中的大表、小表会比 IncreasingToUpperBoundRegionSplitPolicy 更加友好,小表不会再产生大量的小region,而是适可而止。
KeyPrefixRegionSplitPolicy
根据rowKey的前缀对数据进行分区,这里是指定rowKey的前多少位作为前缀,比如rowKey都是16位的,指定前5位是前缀,那么前5位相同的rowKey在相同的region中。
DelimitedKeyPrefixRegionSplitPolicy
保证相同前缀的数据在同一个region中,例如rowKey的格式为:userid_eventtype_eventid,指定的delimiter为 _ ,则split的的时候会确保userid相同的数据在同一个region中。 按照分隔符进行切分,而KeyPrefixRegionSplitPolicy是按照指定位数切分。
BusyRegionSplitPolicy
按照一定的策略判断Region是不是Busy状态,如果是即进行切分
如果你的系统常常会出现热点Region,而你对性能有很高的追求,那么这种策略可能会比较适合你。它会通过拆分热点Region来缓解热点Region的压力,但是根据热点来拆分Region也会带来很多不确定性因素,因为你也不知道下一个被拆分的Region是哪个。
DisabledRegionSplitPolicy
不启用自动拆分, 需要指定手动拆分
三、Compaction操作
Minor Compaction:
指选取一些小的、相邻的StoreFile将他们合并成一个更大的StoreFile,在这个过程中不会处理已经Deleted或Expired的Cell。一次 Minor Compaction 的结果是更少并且更大的StoreFile。
Major Compaction:
指将所有的StoreFile合并成一个StoreFile,这个过程会清理三类没有意义的数据:被删除的数据、TTL过期数据、版本号超过设定版本号的数据。另外,一般情况下,major compaction时间会持续比较长,整个过程会消耗大量系统资源,对上层业务有比较大的影响。因此线上业务都会将关闭自动触发major compaction功能,改为手动在业务低峰期触发。
四、面对百亿数据,HBase为什么查询速度依然非常快?
HBase适合存储PB级别的海量数据(百亿千亿量级条记录),如果根据记录主键Rowkey来查询,能在几十到百毫秒内返回数据。
那么HBase是如何做到的呢?
接下来,简单阐述一下数据的查询思路和过程。
查询过程
第1步:
项目有100亿业务数据,存储在一个HBase集群上(由多个服务器数据节点构成),每个数据节点上有若干个Region(区域),每个Region实际上就是HBase中一批数据的集合(一段连续范围rowkey的数据)。
我们现在开始根据主键RowKey来查询对应的记录,通过meta表可以帮我们迅速定位到该记录所在的数据节点,以及数据节点中的Region,目前我们有100亿条记录,占空间10TB。所有记录被切分成5000个Region,那么现在,每个Region就是2G。
由于记录在1个Region中,所以现在我们只要查询这2G的记录文件,就能找到对应记录。
第2步:
由于HBase存储数据是按照列族存储的。比如一条记录有400个字段,前100个字段是人员信息相关,这是一个列簇(列的集合);中间100个字段是公司信息相关,是一个列簇。另外100个字段是人员交易信息相关,也是一个列簇;最后还有100个字段是其他信息,也是一个列簇
这四个列簇是分开存储的,这时,假设2G的Region文件中,分为4个列族,那么每个列族就是500M。
到这里,我们只需要遍历这500M的列簇就可以找到对应的记录。
第3步:
如果要查询的记录在其中1个列族上,1个列族在HDFS中会包含1个或者多个HFile。
如果一个HFile一般的大小为100M,那么该列族包含5个HFile在磁盘上或内存中。
由于HBase的内存进而磁盘中的数据是排好序的,要查询的记录有可能在最前面,也有可能在最后面,按平均来算,我们只需遍历2.5个HFile共250M,即可找到对应的记录。
第4步:
每个HFile中,是以键值对(key/value)方式存储,只要遍历文件中的key位置并判断符合条件即可
一般key是有限的长度,假设key/value比是1:24,最终只需要10M的数据量,就可获取的对应的记录。
如果数据在机械磁盘上,按其访问速度100M/S,只需0.1秒即可查到。
如果是SSD的话,0.01秒即可查到。
当然,扫描HFile时还可以通过布隆过滤器快速定位到对应的HFile,以及HBase是有内存缓存机制的,如果数据在内存中,效率会更高。
总结
正因为以上大致的查询思路,保证了HBase即使随着数据量的剧增,也不会导致查询性能的下降。
同时,HBase是一个面向列存储的数据库(列簇机制),当表字段非常多时,可以把其中一些字段独立出来放在一部分机器上,而另外一些字段放到另一部分机器上,分散存储,分散列查询。
正由于这样复杂的存储结构和分布式的存储方式,保证了HBase海量数据下的查询效率。
五、HBase与Hive的集成
HBase与Hive的对比
hive:
数据仓库:Hive的本质其实就相当于将HDFS中已经存储的文件在Mysql中做了一个双射关系,以方便使用HQL去管理查询。
用于数据分析、清洗:Hive适用于离线的数据分析和清洗,延迟较高。
基于HDFS、MapReduce:Hive存储的数据依旧在DataNode上,编写的HQL语句终将是转换为MapReduce代码执行。
HBase
数据库:是一种面向列族存储的非关系型数据库。
用于存储结构化和非结构化的数据:适用于单表非关系型数据的存储,不适合做关联查询,类似JOIN等操作。
基于HDFS:数据持久化存储的体现形式是HFile,存放于DataNode中,被ResionServer以region的形式进行管理。
延迟较低,接入在线业务使用:面对大量的企业数据,HBase可以直线单表大量数据的存储,同时提供了高效的数据访问速度。
在
hive-site.xml中添加zookeeper的属性
- <property>
<name>hive.zookeeper.quorum</name>
<value>hadoop102,hadoop103,hadoop104</value>
</property>
<property>
<name>hive.zookeeper.client.port</name>
<value>2181</value>
</property>
HBase中已经存储了某一张表,在Hive中创建一个外部表来关联HBase中的这张表
建立外部表的字段名要和hbase中的列名一致
前提是hbase中已经有表了
- create external table students_hbase
(
id string,
name string,
age string,
gender string,
clazz string
)
stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
with serdeproperties ("hbase.columns.mapping" = "
:key,
info:name,
info:age,
info:gender,
info:clazz
")
tblproperties("hbase.table.name" = "default:students");
create external table score_hbase2
(
id string,
score_dan string
)
stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
with serdeproperties ("hbase.columns.mapping" = "
:key,
info:score_dan
")
tblproperties("hbase.table.name" = "default:score");
关联后就可以使用Hive函数进行一些分析操作了
六、Phoenix
Hbase适合存储大量的对关系运算要求低的NOSQL数据,受Hbase 设计上的限制不能直接使用原生的API执行在关系数据库中普遍使用的条件判断和聚合等操作。Hbase很优秀,一些团队寻求在Hbase之上提供一种更面向普通开发人员的操作方式,Apache Phoenix即是。
Phoenix 基于Hbase给面向业务的开发人员提供了以标准SQL的方式对Hbase进行查询操作,并支持标准SQL中大部分特性:条件运算,分组,分页,等高级查询语法。
1、Phoenix搭建
Phoenix 4.15 HBase 1.4.6 hadoop 2.7.6
1、关闭hbase集群,在master中执行
- stop-hbase.sh
2、上传解压配置环境变量
解压
tar -xvf apache-phoenix-4.15.0-HBase-1.4-bin.tar.gz -C /usr/local/soft/
改名
mv apache-phoenix-4.15.0-HBase-1.4-bin phoenix-4.15.0
3、将phoenix-4.15.0-HBase-1.4-server.jar复制到所有节点的hbase lib目录下
- scp /usr/local/soft/phoenix-4.15.0/phoenix-4.15.0-HBase-1.4-server.jar master:/usr/local/soft/hbase-1.4.6/lib/
scp /usr/local/soft/phoenix-4.15.0/phoenix-4.15.0-HBase-1.4-server.jar node1:/usr/local/soft/hbase-1.4.6/lib/
scp /usr/local/soft/phoenix-4.15.0/phoenix-4.15.0-HBase-1.4-server.jar node2:/usr/local/soft/hbase-1.4.6/lib/
4、启动hbase , 在master中执行
- start-hbase.sh
5、配置环境变量
- vim /etc/profile
2、Phoenix使用
1、连接sqlline
- sqlline.py master,node1,node2
- # 出现
- 163/163 (100%) Done
- Done
- sqlline version 1.5.0
- 0: jdbc:phoenix:master,node1,node2>
2、常用命令
- # 1、创建表
- CREATE TABLE IF NOT EXISTS student (
- id VARCHAR NOT NULL PRIMARY KEY,
- name VARCHAR,
- age BIGINT,
- gender VARCHAR ,
- clazz VARCHAR
- );
- # 2、显示所有表
- !table
- # 3、插入数据
- upsert into STUDENT values('1500100004','葛德曜',24,'男','理科三班');
- upsert into STUDENT values('1500100005','宣谷芹',24,'男','理科六班');
- upsert into STUDENT values('1500100006','羿彦昌',24,'女','理科三班');
- # 4、查询数据,支持大部分sql语法,
- select * from STUDENT ;
- select * from STUDENT where age=24;
- select gender ,count(*) from STUDENT group by gender;
- select * from student order by gender;
- # 5、删除数据
- delete from STUDENT where id='1500100004';
- # 6、删除表
- drop table STUDENT;
- # 7、退出命令行
- !quit
- 更多语法参照官网
- https://phoenix.apache.org/language/index.html#upsert_select
3、phoenix表映射
默认情况下,直接在hbase中创建的表,通过phoenix是查看不到的
如果需要在phoenix中操作直接在hbase中创建的表,则需要在phoenix中进行表的映射。映射方式有两种:视图映射和表映射
3.1、视图映射
Phoenix创建的视图是只读的,所以只能用来做查询,无法通过视图对源数据进行修改等操作
- # hbase shell 进入hbase命令行
- hbase shell
- # 创建hbase表
- create 'test','name','company'
- # 插入数据
- put 'test','001','name:firstname','zhangsan1'
- put 'test','001','name:lastname','zhangsan2'
- put 'test','001','company:name','数加'
- put 'test','001','company:address','合肥'
- upsert into TEST values('002','xiaohu','xiaoxiao','数加','合肥');
- # 在phoenix创建视图, primary key 对应到hbase中的rowkey
- create view "test"(
- empid varchar primary key,
- "name"."firstname" varchar,
- "name"."lastname" varchar,
- "company"."name" varchar,
- "company"."address" varchar
- );
- CREATE view "students" (
- id VARCHAR NOT NULL PRIMARY KEY,
- "info"."name" VARCHAR,
- "info"."age" VARCHAR,
- "info"."gender" VARCHAR ,
- "info"."clazz" VARCHAR
- ) column_encoded_bytes=0;
- # 在phoenix查询数据,表名通过双引号引起来
- select * from "test";
- # 删除视图
- drop view "test";
3.2、表映射
使用Apache Phoenix创建对HBase的表映射,有两类:
1) 当HBase中已经存在表时,可以以类似创建视图的方式创建关联表,只需要将create view改为create table即可。
2)当HBase中不存在表时,可以直接使用create table指令创建需要的表,并且在创建指令中可以根据需要对HBase表结构进行显示的说明。
第1)种情况下,如在之前的基础上已经存在了test表,则表映射的语句如下:
- create table "test" (
- empid varchar primary key,
- "name"."firstname" varchar,
- "name"."lastname"varchar,
- "company"."name" varchar,
- "company"."address" varchar
- )column_encoded_bytes=0;
- upsert into "students" values('150011000100','xiaohu','24','男','理科三班');
- upsert into "test" values('1001','xiaohu','xiaoxiao','数加','合肥');
- CREATE table "students" (
- id VARCHAR NOT NULL PRIMARY KEY,
- "info"."name" VARCHAR,
- "info"."age" VARCHAR,
- "info"."gender" VARCHAR ,
- "info"."clazz" VARCHAR
- ) column_encoded_bytes=0;
- upsert into "students" values('150011000100','xiaohu','24','男','理科三班');
- CREATE table "score" (
- id VARCHAR NOT NULL PRIMARY KEY,
- "info"."score_dan" VARCHAR
- ) column_encoded_bytes=0;
使用create table创建的关联表,如果对表进行了修改,源数据也会改变,同时如果关联表被删除,源表也会被删除。但是视图就不会,如果删除视图,源数据不会发生改变。
七、bulkLoad实现批量导入
优点:
如果我们一次性入库hbase巨量数据,处理速度慢不说,还特别占用Region资源, 一个比较高效便捷的方法就是使用 “Bulk Loading”方法,即HBase提供的HFileOutputFormat类。
它是利用hbase的数据信息按照特定格式存储在hdfs内这一原理,直接生成这种hdfs内存储的数据格式文件,然后上传至合适位置,即完成巨量数据快速入库的办法。配合mapreduce完成,高效便捷,而且不占用region资源,增添负载。
限制:
仅适合初次数据导入,即表内数据为空,或者每次入库表内都无数据的情况。
HBase集群与Hadoop集群为同一集群,即HBase所基于的HDFS为生成HFile的MR的集群
代码编写:
提前在Hbase中创建好表
生成Hfile基本流程:
设置Mapper的输出KV类型:
K: ImmutableBytesWritable(代表行键)
V: KeyValue (代表cell)
2. 开发Mapper
读取你的原始数据,按你的需求做处理
输出rowkey作为K,输出一些KeyValue(Put)作为V
3. 配置job参数
a. Zookeeper的连接地址
b. 配置输出的OutputFormat为HFileOutputFormat2,并为其设置参数
4. 提交job
导入HFile到RegionServer的流程
构建一个表描述对象
构建一个region定位工具
然后用LoadIncrementalHFiles来doBulkload操作
pom文件:
- <?xml version="1.0" encoding="UTF-8"?>
- <project xmlns="http://maven.apache.org/POM/4.0.0"
- xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
- xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
- <parent>
- <artifactId>hadoop-bigdata17</artifactId>
- <groupId>com.shujia</groupId>
- <version>1.0-SNAPSHOT</version>
- </parent>
- <modelVersion>4.0.0</modelVersion>
- <artifactId>had-hbase-demo</artifactId>
- <properties>
- <maven.compiler.source>8</maven.compiler.source>
- <maven.compiler.target>8</maven.compiler.target>
- </properties>
- <dependencies>
- <dependency>
- <groupId>org.apache.hadoop</groupId>
- <artifactId>hadoop-common</artifactId>
- </dependency>
- <dependency>
- <groupId>org.apache.hadoop</groupId>
- <artifactId>hadoop-client</artifactId>
- </dependency>
- <dependency>
- <groupId>org.apache.hadoop</groupId>
- <artifactId>hadoop-hdfs</artifactId>
- </dependency>
- <dependency>
- <groupId>org.apache.hbase</groupId>
- <artifactId>hbase-client</artifactId>
- </dependency>
- <dependency>
- <groupId>org.apache.hbase</groupId>
- <artifactId>hbase-server</artifactId>
- </dependency>
- <dependency>
- <groupId>junit</groupId>
- <artifactId>junit</artifactId>
- </dependency>
- <dependency>
- <groupId>org.apache.phoenix</groupId>
- <artifactId>phoenix-core</artifactId>
- </dependency>
- <dependency>
- <groupId>com.lmax</groupId>
- <artifactId>disruptor</artifactId>
- </dependency>
- </dependencies>
- <build>
- <plugins>
- <!-- compiler插件, 设定JDK版本 -->
- <plugin>
- <groupId>org.apache.maven.plugins</groupId>
- <artifactId>maven-compiler-plugin</artifactId>
- <version>2.3.2</version>
- <configuration>
- <encoding>UTF-8</encoding>
- <source>1.8</source>
- <target>1.8</target>
- <showWarnings>true</showWarnings>
- </configuration>
- </plugin>
- <!-- 带依赖jar 插件-->
- <plugin>
- <artifactId>maven-assembly-plugin</artifactId>
- <configuration>
- <descriptorRefs>
- <descriptorRef>jar-with-dependencies</descriptorRef>
- </descriptorRefs>
- </configuration>
- <executions>
- <execution>
- <id>make-assembly</id>
- <phase>package</phase>
- <goals>
- <goal>single</goal>
- </goals>
- </execution>
- </executions>
- </plugin>
- </plugins>
- </build>
- </project>
电信数据
- 手机号,网格编号,城市编号,区县编号,停留时间,进入时间,离开时间,时间分区
- D55433A437AEC8D8D3DB2BCA56E9E64392A9D93C,117210031795040,83401,8340104,301,20180503190539,20180503233517,20180503
- 手机号和进入时间
说明
最终输出结果,无论是map还是reduce,输出部分key和value的类型必须是: < ImmutableBytesWritable, KeyValue>或者< ImmutableBytesWritable, Put>。
最终输出部分,Value类型是KeyValue 或Put,对应的Sorter分别是KeyValueSortReducer或PutSortReducer。
MR例子中HFileOutputFormat2.configureIncrementalLoad(job, dianxin_bulk, regionLocator);自动对job进行配置。SimpleTotalOrderPartitioner是需要先对key进行整体排序,然后划分到每个reduce中,保证每一个reducer中的的key最小最大值区间范围,是不会有交集的。因为入库到HBase的时候,作为一个整体的Region,key是绝对有序的。
MR例子中最后生成HFile存储在HDFS上,输出路径下的子目录是各个列族。如果对HFile进行入库HBase,相当于move HFile到HBase的Region中,HFile子目录的列族内容没有了,但不能直接使用mv命令移动,因为直接移动不能更新HBase的元数据。
HFile入库到HBase通过HBase中 LoadIncrementalHFiles的doBulkLoad方法,对生成的HFile文件入库
八、HBase中rowkey的设计(重点!!面试题)
HBase的RowKey设计
HBase是三维有序存储的,通过rowkey(行键),column key(column family和qualifier)和TimeStamp(时间戳)这个三个维度可以对HBase中的数据进行快速定位。
HBase中rowkey可以唯一标识一行记录,在HBase查询的时候,有两种方式:
通过get方式,指定rowkey获取唯一一条记录
通过scan方式,设置startRow和stopRow参数进行范围匹配
全表扫描,即直接扫描整张表中所有行记录
rowkey长度原则
rowkey是一个二进制码流,可以是任意字符串,最大长度 64kb ,实际应用中一般为10-100bytes,以 byte[] 形式保存,一般设计成定长。
建议越短越好,不要超过16个字节,原因如下:
数据的持久化文件HFile中是按照KeyValue存储的,如果rowkey过长,比如超过100字节,1000w行数据,光rowkey就要占用100*1000w=10亿个字节,将近1G数据,这样会极大影响HFile的存储效率;
MemStore将缓存部分数据到内存,如果rowkey字段过长,内存的有效利用率就会降低,系统不能缓存更多的数据,这样会降低检索效率。
目前操作系统都是64位系统,内存8字节对齐,控制在16个字节,8字节的整数倍利用了操作系统的最佳特性。
rowkey散列原则
如果rowkey按照时间戳的方式递增,不要将时间放在二进制码的前面,建议将rowkey的高位作为散列字段,由程序随机生成,低位放时间字段,这样将提高数据均衡分布在每个RegionServer,以实现负载均衡的几率。如果没有散列字段,首字段直接是时间信息,所有的数据都会集中在一个RegionServer上,这样在数据检索的时候负载会集中在个别的RegionServer上,造成热点问题,会降低查询效率。
rowkey唯一原则
必须在设计上保证其唯一性,rowkey是按照字典顺序排序存储的,因此,设计rowkey的时候,要充分利用这个排序的特点,将经常读取的数据存储到一块,将最近可能会被访问的数据放到一块。
什么是热点
HBase中的行是按照rowkey的字典顺序排序的,这种设计优化了scan操作,可以将相关的行以及会被一起读取的行存取在临近位置,便于scan。然而糟糕的rowkey设计是热点的源头。 热点发生在大量的client直接访问集群的一个或极少数个节点(访问可能是读,写或者其他操作)。大量访问会使热点region所在的单个机器超出自身承受能力,引起性能下降甚至region不可用,这也会影响同一个RegionServer上的其他region,由于主机无法服务其他region的请求。 设计良好的数据访问模式以使集群被充分,均衡的利用。
为了避免写热点,设计rowkey使得不同行在同一个region,但是在更多数据情况下,数据应该被写入集群的多个region,而不是一个。
下面是一些常见的避免热点的方法以及它们的优缺点:
加盐
这里所说的加盐不是密码学中的加盐,而是在rowkey的前面增加随机数,具体就是给rowkey分配一个随机前缀以使得它和之前的rowkey的开头不同。分配的前缀种类数量应该和你想使用数据分散到不同的region的数量一致。加盐之后的rowkey就会根据随机生成的前缀分散到各个region上,以避免热点。
哈希
哈希会使同一行永远用一个前缀加盐。哈希也可以使负载分散到整个集群,但是读却是可以预测的。使用确定的哈希可以让客户端重构完整的rowkey,可以使用get操作准确获取某一个行数据
反转
第三种防止热点的方法时反转固定长度或者数字格式的rowkey。这样可以使得rowkey中经常改变的部分(最没有意义的部分)放在前面。这样可以有效的随机rowkey,但是牺牲了rowkey的有序性。
反转rowkey的例子以手机号为rowkey,可以将手机号反转后的字符串作为rowkey,这样的就避免了以手机号那样比较固定开头导致热点问题
时间戳反转
一个常见的数据处理问题是快速获取数据的最近版本,使用反转的时间戳作为rowkey的一部分对这个问题十分有用,可以用 Long.Max_Value - timestamp 追加到key的末尾,例如 [key]reverse_timestamp , [key] 的最新值可以通过scan [key]获得[key]的第一条记录,因为HBase中rowkey是有序的,第一条记录是最后录入的数据。
比如需要保存一个用户的操作记录,按照操作时间倒序排序,在设计rowkey的时候,可以这样设计
[userId反转]Long.Max_Value - timestamp,在查询用户的所有操作记录数据的时候,直接指定反转后的userId,startRow是[userId反转]000000000000,stopRow是[userId反转]Long.Max_Value - timestamp
如果需要查询某段时间的操作记录,startRow是[user反转]Long.Max_Value - 起始时间,stopRow是[userId反转]Long.Max_Value - 结束时间
其他一些建议
尽量减少行和列的大小在HBase中,value永远和它的key一起传输的。当具体的值在系统间传输时,它的rowkey,列名,时间戳也会一起传输。如果你的rowkey和列名很大,甚至可以和具体的值相比较,那么你将会遇到一些有趣的问题。HBase storefiles中的索引(有助于随机访问)最终占据了HBase分配的大量内存,因为具体的值和它的key很大。可以增加block大小使得storefiles索引再更大的时间间隔增加,或者修改表的模式以减小rowkey和列名的大小。压缩也有助于更大的索引。
列族尽可能越短越好,最好是一个字符
冗长的属性名虽然可读性好,但是更短的属性名存储在HBase中会更好
- # 原数据:以时间戳_user_id作为rowkey
- # 时间戳高位变化不大,太连续,最终可能会导致热点问题
- 1638584124_user_id
- 1638584135_user_id
- 1638584146_user_id
- 1638584157_user_id
- 1638584168_user_id
- 1638584179_user_id
- # 解决方案:加盐、反转、哈希
- # 加盐
- # 加上随即前缀,随机的打散
- # 该过程无法预测 前缀时随机的
- 00_1638584124_user_id
- 05_1638584135_user_id
- 03_1638584146_user_id
- 04_1638584157_user_id
- 02_1638584168_user_id
- 06_1638584179_user_id
- # 反转
- # 适用于高位变化不大,低位变化大的rowkey
- 4214858361_user_id
- 5314858361_user_id
- 6414858361_user_id
- 7514858361_user_id
- 8614858361_user_id
- 9714858361_user_id
- # 散列 md5、sha1、sha256......
- 25531D7065AE158AAB6FA53379523979_user_id
- 60F9A0072C0BD06C92D768DACF2DFDC3_user_id
- D2EFD883A6C0198DA3AF4FD8F82DEB57_user_id
- A9A4C265D61E0801D163927DE1299C79_user_id
- 3F41251355E092D7D8A50130441B58A5_user_id
- 5E6043C773DA4CF991B389D200B77379_user_id
- # 时间戳"反转"
- # rowkey:时间戳_user_id
- # rowkey是字典升序的,那么越新的记录会被排在最后面,不容易被获取到
- # 需求:让最新的记录排在最前面
- # 大数:9999999999
- # 大数-小数
- 1638584124_user_id => 8361415875_user_id
- 1638584135_user_id => 8361415864_user_id
- 1638584146_user_id => 8361415853_user_id
- 1638584157_user_id => 8361415842_user_id
- 1638584168_user_id => 8361415831_user_id
- 1638584179_user_id => 8361415820_user_id
- 1638586193_user_id => 8361413806_user_id
合理设计rowkey实战(电信)
- 手机号,网格编号,城市编号,区县编号,停留时间,进入时间,离开时间,时间分区
- D55433A437AEC8D8D3DB2BCA56E9E64392A9D93C,117210031795040,83401,8340104,301,20180503190539,20180503233517,20180503
- 将用户位置数据保存到hbase
- 查询需求
- 1、通过手机号查询用户最近10条位置记录
- 2、获取用户某一天在一个城市中的所有位置
- 怎么设计hbase表
- 1、rowkey
- 2、时间戳
九、二级索引
二级索引的本质就是建立各列值与行键之间的映射关系
Hbase的局限性:
HBase本身只提供基于行键和全表扫描的查询,而行键索引单一,对于多维度的查询困难。
所以我们引进一个二级索引的概念
常见的二级索引:
HBase的一级索引就是rowkey,我们只能通过rowkey进行检索。如果我们相对hbase里面列族的列列进行一些组合查询,就需要采用HBase的二级索引方案来进行多条件的查询。
MapReduce方案
ITHBASE(Indexed-Transanctional HBase)方案
IHBASE(Index HBase)方案
Hbase Coprocessor(协处理器)方案
Solr+hbase方案 redis+hbase 方案
CCIndex(complementalclustering index)方案
二级索引的种类
- 1、创建单列索引
- 2、同时创建多个单列索引
- 3、创建联合索引(最多同时支持3个列)
- 4、只根据rowkey创建索引
单表建立二级索引
- 1.首先disable ‘表名’
- 2.然后修改表
- alter 'LogTable',METHOD=>'table_att','coprocessor'=>'hdfs:///写好的Hbase协处理器(coprocessor)的jar包名|类的绝对路径名|1001'
- 3. enable '表名'
二级索引的设计思路
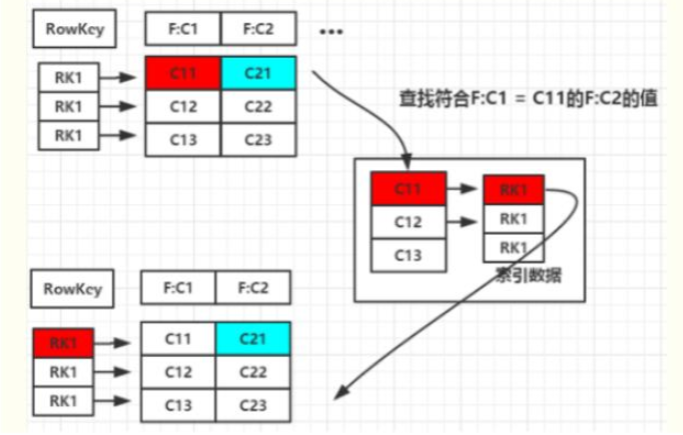
- 二级索引的本质就是建立各列值与行键之间的映射关系
- 如上图1,当要对F:C1这列建立索引时,只需要建立F:C1各列值到其对应行键的映射关系,如C11->RK1等,这样就完成了对F:C1列值的二级索引的构建,当要查询符合F:C1=C11对应的F:C2的列值时(即根据C1=C11来查询C2的值,图1青色部分)
- 其查询步骤如下:
- 1. 根据C1=C11到索引数据中查找其对应的RK,查询得到其对应的RK=RK1
- 2. 得到RK1后就自然能根据RK1来查询C2的值了 这是构建二级索引大概思路,其他组合查询的联合索引的建立也类似。
Mapreduce的方式创建二级索引
使用整合MapReduce的方式创建hbase索引。主要的流程如下:
1.1扫描输入表,使用hbase继承类TableMapper
1.2获取rowkey和指定字段名称和字段值
1.3创建Put实例, value=” “, rowkey=班级,column=学号
1.4使用IdentityTableReducer将数据写入索引表
案例:
1、在hbase中创建索引表 student_index
- create 'student_index','info'
2、编写mapreduce代码
- package com.shujia.hbaseapi.hbaseindexdemo;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.hbase.client.Mutation;
- import org.apache.hadoop.hbase.client.Put;
- import org.apache.hadoop.hbase.client.Result;
- import org.apache.hadoop.hbase.client.Scan;
- import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
- import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
- import org.apache.hadoop.hbase.mapreduce.TableMapper;
- import org.apache.hadoop.hbase.mapreduce.TableReducer;
- import org.apache.hadoop.hbase.util.Bytes;
- import org.apache.hadoop.io.NullWritable;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Job;
- import org.apache.hadoop.mapreduce.Mapper;
- import org.apache.hadoop.mapreduce.Reducer;
- import java.io.IOException;
- /**
- * 编写整个mapreduce程序建立索引表
- */
- class IndexMapper extends TableMapper<Text, NullWritable>{
- @Override
- protected void map(ImmutableBytesWritable key, Result value, Mapper<ImmutableBytesWritable, Result, Text, NullWritable>.Context context) throws IOException, InterruptedException {
- String id = Bytes.toString(key.get());
- String clazz = Bytes.toString(value.getValue("info".getBytes(), "clazz".getBytes()));
- String key1 = id+"_"+clazz;
- context.write(new Text(key1),NullWritable.get());
- }
- }
- /**
- *
- * reduce端获取map端传过来的key
- */
- class IndexReduce extends TableReducer<Text,NullWritable,NullWritable>{
- @Override
- protected void reduce(Text key, Iterable<NullWritable> values, Reducer<Text, NullWritable, NullWritable, Mutation>.Context context) throws IOException, InterruptedException {
- String[] strings = key.toString().split("_");
- String id = strings[0];
- String clazz = strings[1];
- //索引表也是属于hbase的表,需要使用put实例添加数据
- Put put = new Put(clazz.getBytes());
- put.add("info".getBytes(),id.getBytes(),"".getBytes());
- context.write(NullWritable.get(),put);
- }
- }
- public class HbaseIndex {
- public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
- Configuration conf = new Configuration();
- conf.set("hbase.zookeeper.quorum", "master:2181,node1:2181,node2:2181");
- Job job = Job.getInstance(conf);
- job.setJobName("建立学生索引表");
- job.setJarByClass(HbaseIndex.class);
- Scan scan = new Scan();
- scan.addFamily("info".getBytes());
- //指定对哪张表建立索引,以及指定需要建索引的列所属的列簇
- TableMapReduceUtil.initTableMapperJob("students",scan,IndexMapper.class,Text.class,NullWritable.class,job);
- TableMapReduceUtil.initTableReducerJob("student_index",IndexReduce.class,job);
- job.waitForCompletion(true);
- }
- }
3、打成jar包上传到hadoop中运行
- hadoop jar had-hbase-demo-1.0-SNAPSHOT-jar-with-dependencies.jar com.shujia.hbaseapi.hbaseindexdemo.HbaseIndex
4、编写查询代码,测试结果(先查询索引表,在查数据)
- package com.shujia.hbaseapi.hbaseindexdemo;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.hbase.Cell;
- import org.apache.hadoop.hbase.CellUtil;
- import org.apache.hadoop.hbase.client.*;
- import org.apache.hadoop.hbase.filter.CompareFilter;
- import org.apache.hadoop.hbase.filter.SingleColumnValueFilter;
- import org.apache.hadoop.hbase.filter.SubstringComparator;
- import org.apache.hadoop.hbase.util.Bytes;
- import org.junit.After;
- import org.junit.Before;
- import org.junit.Test;
- import java.io.IOException;
- import java.util.ArrayList;
- import java.util.List;
- public class HbaseIndexToStudents {
- private HConnection conn;
- private HBaseAdmin hAdmin;
- @Before
- public void connect() {
- try {
- //1、获取Hadoop的相关配置环境
- Configuration conf = new Configuration();
- //2、获取zookeeper的配置
- conf.set("hbase.zookeeper.quorum", "master:2181,node1:2181,node2:2181");
- //获取与Hbase的连接,这个连接是将来可以用户获取hbase表的
- conn = HConnectionManager.createConnection(conf);
- //将来我们要对表做DDL相关操作,而对表的操作在hbase架构中是有HMaster
- hAdmin = new HBaseAdmin(conf);
- System.out.println("建立连接成功:" + conn + ", HMaster获取成功:" + hAdmin);
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
- /**
- * 通过索引表进行查询数据
- * <p>
- * 需求:获取理科二班所有的学生信息,不适用过滤器,使用索引表查询
- */
- @Test
- public void scanData() {
- try {
- long start = System.currentTimeMillis();
- //创建一个集合存放查询到的学号
- ArrayList<Get> gets = new ArrayList<>();
- //获取到索引表
- HTableInterface student_index = conn.getTable("student_index");
- //创建Get实例
- Get get = new Get("理科二班".getBytes());
- Result result = student_index.get(get);
- List<Cell> cells = result.listCells();
- for (Cell cell : cells) {
- //每一个单元格的列名
- byte[] bytes = CellUtil.cloneQualifier(cell);
- String id = Bytes.toString(bytes);
- Get get1 = new Get(id.getBytes());
- //将学号添加到集合中
- gets.add(get1);
- }
- //获取真正的学生数据表 students
- HTableInterface students = conn.getTable("students");
- Result[] results = students.get(gets);
- for (Result result1 : results) {
- String id = Bytes.toString(result1.getRow());
- String name = Bytes.toString(result1.getValue("info".getBytes(), "name".getBytes()));
- String age = Bytes.toString(result1.getValue("info".getBytes(), "age".getBytes()));
- String gender = Bytes.toString(result1.getValue("info".getBytes(), "gender".getBytes()));
- String clazz = Bytes.toString(result1.getValue("info".getBytes(), "clazz".getBytes()));
- System.out.println("学号:" + id + ", 姓名:" + name + ", 年龄:" + age + ", 性别:" + gender + ", 班级:" + clazz);
- }
- long endtime = System.currentTimeMillis();
- System.out.println("=========================================");
- System.out.println((endtime - start) + "毫秒");
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
- @Test
- public void getData() {
- try {
- long start = System.currentTimeMillis();
- //获取真正的学生数据表 students
- HTableInterface students = conn.getTable("students");
- Scan scan = new Scan();
- SubstringComparator substringComparator = new SubstringComparator("理科二班");
- SingleColumnValueFilter singleColumnValueFilter = new SingleColumnValueFilter("info".getBytes(), "clazz".getBytes(), CompareFilter.CompareOp.EQUAL, substringComparator);
- scan.setFilter(singleColumnValueFilter);
- ResultScanner scanner = students.getScanner(scan);
- Result rs = null;
- while ((rs = scanner.next()) != null) {
- String id = Bytes.toString(rs.getRow());
- String name = Bytes.toString(rs.getValue("info".getBytes(), "name".getBytes()));
- String age = Bytes.toString(rs.getValue("info".getBytes(), "age".getBytes()));
- String gender = Bytes.toString(rs.getValue("info".getBytes(), "gender".getBytes()));
- String clazz = Bytes.toString(rs.getValue("info".getBytes(), "clazz".getBytes()));
- System.out.println("学号:" + id + ", 姓名:" + name + ", 年龄:" + age + ", 性别:" + gender + ", 班级:" + clazz);
- }
- long endtime = System.currentTimeMillis();
- System.out.println("=========================================");
- System.out.println((endtime - start) + "毫秒");
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
- @After
- public void close() {
- if (conn != null) {
- try {
- conn.close();
- } catch (IOException e) {
- e.printStackTrace();
- }
- System.out.println("conn连接已经关闭.....");
- }
- if (hAdmin != null) {
- try {
- hAdmin.close();
- } catch (IOException e) {
- e.printStackTrace();
- }
- System.out.println("HMaster已经关闭......");
- }
- }
- }
十、Phoenix二级索引
对于Hbase,如果想精确定位到某行记录,唯一的办法就是通过rowkey查询。如果不通过rowkey查找数据,就必须逐行比较每一行的值,对于较大的表,全表扫描的代价是不可接受的。
1、开启索引支持
- # 关闭hbase集群
- stop-hbase.sh
- # 在/usr/local/soft/hbase-1.4.6/conf/hbase-site.xml中增加如下配置
- <property>
- <name>hbase.regionserver.wal.codec</name>
- <value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value>
- </property>
- <property>
- <name>hbase.rpc.timeout</name>
- <value>60000000</value>
- </property>
- <property>
- <name>hbase.client.scanner.timeout.period</name>
- <value>60000000</value>
- </property>
- <property>
- <name>phoenix.query.timeoutMs</name>
- <value>60000000</value>
- </property>
- # 同步到所有节点
- scp hbase-site.xml node1:`pwd`
- scp hbase-site.xml node2:`pwd`
- # 修改phoenix目录下的bin目录中的hbase-site.xml
- <property>
- <name>hbase.rpc.timeout</name>
- <value>60000000</value>
- </property>
- <property>
- <name>hbase.client.scanner.timeout.period</name>
- <value>60000000</value>
- </property>
- <property>
- <name>phoenix.query.timeoutMs</name>
- <value>60000000</value>
- </property>
- # 启动hbase
- start-hbase.sh
- # 重新进入phoenix客户端
- sqlline.py master,node1,node2
2、创建索引
2.1、全局索引
全局索引适合读多写少的场景。如果使用全局索引,读数据基本不损耗性能,所有的性能损耗都来源于写数据。数据表的添加、删除和修改都会更新相关的索引表(数据删除了,索引表中的数据也会删除;数据增加了,索引表的数据也会增加)
注意: 对于全局索引在默认情况下,在查询语句中检索的列如果不在索引表中,Phoenix不会使用索引表将,除非使用hint。
- 手机号 进入网格的时间 离开网格的时间 区县编码 经度 纬度 基站标识 网格编号 业务类型
- # 创建DIANXIN.sql
- CREATE TABLE IF NOT EXISTS DIANXIN (
- mdn VARCHAR ,
- start_date VARCHAR ,
- end_date VARCHAR ,
- county VARCHAR,
- x DOUBLE ,
- y DOUBLE,
- bsid VARCHAR,
- grid_id VARCHAR,
- biz_type VARCHAR,
- event_type VARCHAR ,
- data_source VARCHAR ,
- CONSTRAINT PK PRIMARY KEY (mdn,start_date)
- ) column_encoded_bytes=0;
- # 上传数据DIANXIN.csv
- # 导入数据
- psql.py master,node1,node2 DIANXIN.sql DIANXIN.csv
- # 创建全局索引
- CREATE INDEX DIANXIN_INDEX ON DIANXIN ( end_date );
- # 查询数据 ( 索引未生效)
- select * from DIANXIN where end_date = '20180503154014';
- # 强制使用索引 (索引生效) hint
- select /*+ INDEX(DIANXIN DIANXIN_INDEX) */ * from DIANXIN where end_date = '20180503154014';
- select /*+ INDEX(DIANXIN DIANXIN_INDEX) */ * from DIANXIN where end_date = '20180503154014' and start_date = '20180503154614';
- # 取索引列,(索引生效)
- select end_date from DIANXIN where end_date = '20180503154014';
- # 创建多列索引
- CREATE INDEX DIANXIN_INDEX1 ON DIANXIN ( end_date,COUNTY );
- # 多条件查询 (索引生效)
- select end_date,MDN,COUNTY from DIANXIN where end_date = '20180503154014' and COUNTY = '8340104';
- # 查询所有列 (索引未生效)
- select * from DIANXIN where end_date = '20180503154014' and COUNTY = '8340104';
- # 查询所有列 (索引生效)
- select /*+ INDEX(DIANXIN DIANXIN_INDEX1) */ * from DIANXIN where end_date = '20180503154014' and COUNTY = '8340104';
- # 单条件 (索引未生效)
- select end_date from DIANXIN where COUNTY = '8340103';
- # 单条件 (索引生效) end_date 在前
- select COUNTY from DIANXIN where end_date = '20180503154014';
- # 删除索引
- drop index DIANXIN_INDEX on DIANXIN;
2.2、本地索引
本地索引适合写多读少的场景,或者存储空间有限的场景。和全局索引一样,Phoenix也会在查询的时候自动选择是否使用本地索引。本地索引因为索引数据和原数据存储在同一台机器上,避免网络数据传输的开销,所以更适合写多的场景。由于无法提前确定数据在哪个Region上,所以在读数据的时候,需要检查每个Region上的数据从而带来一些性能损耗。
注意:对于本地索引,查询中无论是否指定hint或者是查询的列是否都在索引表中,都会使用索引表。
- # 创建本地索引
- CREATE LOCAL INDEX DIANXIN_LOCAL_IDEX ON DIANXIN(grid_id);
- # 索引生效
- select grid_id from dianxin where grid_id='117285031820040';
- # 索引生效
- select * from dianxin where grid_id='117285031820040';
2.3、覆盖索引
覆盖索引是把原数据存储在索引数据表中,这样在查询时不需要再去HBase的原表获取数据就,直接返回查询结果。
注意:查询是 select 的列和 where 的列都需要在索引中出现。
- # 创建覆盖索引
CREATE INDEX DIANXIN_INDEX_COVER ON DIANXIN ( x,y ) INCLUDE ( county );
# 查询所有列 (索引未生效)
select * from DIANXIN where x=117.288 and y =31.822;
# 强制使用索引 (索引生效)
select /*+ INDEX(DIANXIN DIANXIN_INDEX_COVER) */ * from DIANXIN where x=117.288 and y =31.822;
# 查询索引中的列 (索引生效) mdn是DIANXIN表的RowKey中的一部分
select x,y,county from DIANXIN where x=117.288 and y =31.822;
select mdn,x,y,county from DIANXIN where x=117.288 and y =31.822;
# 查询条件必须放在索引中 select 中的列可以放在INCLUDE (将数据保存在索引中)
select /*+ INDEX(DIANXIN DIANXIN_INDEX_COVER) */ x,y,count(*) from DIANXIN group by x,y;
十一、Phoenix JDBC
- # 导入依赖
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-core</artifactId>
<version>4.15.0-HBase-1.4</version>
</dependency>
<dependency>
<groupId>com.lmax</groupId>
<artifactId>disruptor</artifactId>
<version>3.4.2</version>
</dependency>
- Connection conn = DriverManager.getConnection("jdbc:phoenix:master,node1,node2:2181");
PreparedStatement ps = conn.prepareStatement("select /*+ INDEX(DIANXIN DIANXIN_INDEX) */ * from DIANXIN where end_date=?");
ps.setString(1, "20180503212649");
ResultSet rs = ps.executeQuery();
while (rs.next()) {
String mdn = rs.getString("mdn");
String start_date = rs.getString("start_date");
String end_date = rs.getString("end_date");
String x = rs.getString("x");
String y = rs.getString("y");
String county = rs.getString("county");
System.out.println(mdn + "\t" + start_date + "\t" + end_date + "\t" + x + "\t" + y + "\t" + county);
}
ps.close();
conn.close();
HBase学习(四) 二级索引 rowkey设计的更多相关文章
- Hbase 学习(七) rowkey设计
一直以来对rowkey的设计都比较迷茫,<hbase权威指南>倒是给出了个还算靠谱的例子. 下面这个例子有点儿像帖子表结构,它的rowkey设计是这样的,可以简单的理解为,什么人在什么时间 ...
- HBase二级索引的设计(案例讲解)
摘要 最近做的一个项目涉及到了多条件的组合查询,数据存储用的是HBase,恰恰HBase对于这种场景的查询特别不给力,一般HBase的查询都是通过RowKey(要把多条件组合查询的字段都拼接在RowK ...
- HBase二级索引的设计
摘要 最近做的一个项目涉及到了多条件的组合查询,数据存储用的是HBase,恰恰HBase对于这种场景的查询特别不给力,一般HBase的查询都是通过RowKey(要把多条件组合查询的字段都拼接在RowK ...
- HBase之八--(1):HBase二级索引的设计(案例讲解)
摘要 最近做的一个项目涉及到了多条件的组合查询,数据存储用的是HBase,恰恰HBase对于这种场景的查询特别不给力,一般HBase的查询都是通过RowKey(要把多条件组合查询的字段都拼接在RowK ...
- HBase协处理器同步二级索引到Solr
一. 背景二. 什么是HBase的协处理器三. HBase协处理器同步数据到Solr四. 添加协处理器五. 测试六. 协处理器动态加载 一. 背景 在实际生产中,HBase往往不能满足多维度分析,我们 ...
- Hbase(三) hbase协处理器与二级索引
一.协处理器—Coprocessor 1. 起源Hbase 作为列族数据库最经常被人诟病的特性包括:无法轻易建立“二级索引”,难以执 行求和.计数.排序等操作.比如,在旧版本的(<0.92)Hb ...
- 通过phoenix在hbase上创建二级索引,Secondary Indexing
环境描述: 操作系统版本:CentOS release 6.5 (Final) 内核版本:2.6.32-431.el6.x86_64 phoenix版本:phoenix-4.10.0 hbase版本: ...
- HBase Region级别二级索引
我们会经常谈及二级索引,这是对全表数据进行另外一种方式的组织存储,是针对table级别的.如果要为HBase上的表实现一个强一致性的二级索引,那么就无法逃避分布式事务,而这一直是用户最期待的功能. 而 ...
- HBase协处理器同步二级索引到Solr(续)
一. 已知的问题和不足二.解决思路三.代码3.1 读取config文件内容3.2 封装SolrServer的获取方式3.3 编写提交数据到Solr的代码3.4 拦截HBase的Put和Delete操作 ...
随机推荐
- Docker系列教程03-Docker私有仓库搭建(registry)
简介 仓库(Repository)是集中存放镜像的地方,又分为公共镜像和私有仓库. 当我们执行docker pull xxx的时候,它实际上是从registry.docker.com这个地址去查找,这 ...
- 记将一个大型客户端应用项目迁移到 dotnet 6 的经验和决策
在经过了两年的准备,以及迁移了几个应用项目积累了让我有信心的经验之后,我最近在开始将团队里面最大的一个项目,从 .NET Framework 4.5 迁移到 .NET 6 上.这是一个从 2016 时 ...
- 解读先电2.4版 iaas-install-mysql.sh 脚本
#!/bin/bash #声明解释器路径 source /etc/xiandian/openrc.sh #生效环境变量 ping $HOST_IP -c 4 >> /dev/null 2& ...
- 论文解读(SimGRACE)《SimGRACE: A Simple Framework for Graph Contrastive Learning without Data Augmentation》
论文信息 论文标题:SimGRACE: A Simple Framework for Graph Contrastive Learning without Data Augmentation论文作者: ...
- mybatis plus 更新字段的时候设置为 null 后不生效
mybatis plus 将属性设置为 null 值会被忽略,最终生成的 sql 中不会有 set field = null(可能是某些情况) mybatis-plus 更新字段的时候设置为 null ...
- Install Ubuntu on Windows Subsystem for Linux
安装参考 ubuntu.com/wsl microsoft/wsl/install-manual microsoft/terminal 错误解决方案 github/启动 WSL 2时警告"参 ...
- 566. Reshape the Matrix - LeetCode
Question 566. Reshape the Matrix Solution 题目大意:给一个二维数组,将这个二维数组转换为r行c列 思路:构造一个r行c列的二维数组,遍历给出二给数组nums, ...
- 安装Zabbix到Ubuntu(APT)
运行环境 系统版本:Ubuntu 16.04.2 LTS 软件版本:Zabbix-4.0.2 硬件要求:无 安装过程 1.安装APT-Zabbix存储库 APT-Zabbix存储库由Zabbix官网提 ...
- redis高可用、redis集群、redis缓存优化
今日内容概要 redis高可用 redis集群 redis缓存优化 内容详细 1.redis高可用 # 主从复制存在的问题: 1 主从复制,主节点发生故障,需要做故障转移,可以手动转移:让其中一个sl ...
- 【单片机】CH32V103C8T6 ——窗口看门狗
本章教程通过串口调试助手打印显示程序运行状态,具体现象如下: 若计数器值在上窗口值和下窗口值0X40之间的时候,进行喂狗操作,计数器重新计数,程序正常运行,串口打印显示:The program run ...