ChatGPT 加图数据库 NebulaGraph 预测 2022 世界杯冠军球队

一次利用 ChatGPT 给出数据抓取代码,借助 NebulaGraph 图数据库与图算法预测体坛赛事的尝试。
作者:古思为
蹭 ChatGPT 热度
最近因为世界杯正在进行,我受到这篇 Cambridge Intelligence 的文章启发(在这篇文章中,作者仅仅利用有限的信息量和条件,借助图算法的方法做出了合理的冠军预测),想到可以试着用图数据库 NebulaGraph 玩玩冠军预测,还能顺道科普一波图库技术和图算法。
本来想着几个小时撸出来一个方案,但很快被数据集的收集工作劝退了,我是实在懒得去「FIFA 2022 的维基」抓取所需的数据,索性就搁浅、放了几天。
同时,另一个热潮是上周五 OpenAI 发布了 ChatGPT 服务,它可以实现各种语言编码。ChatGPT 可实现的复杂任务设计包括:
- 随时帮你实现一段指定需求的代码
- 模拟任意一个 prompt 界面:Shell、Python、Virtual Machine、甚至你创造的语言
- 带入给定的人设,和你聊天
- 写诗歌、rap、散文
- 找出一段代码的 bug
- 解释一段复杂的正则表达式的含义
ChatGPT 的上下文联想力和理解力到了前所未有的程度,以至于所有接触它的人都在讨论新的工作方式:如何掌握让机器帮助我们完成特定任务。
所以,当我试过让 ChatGPT 帮我写复杂的图数据库查询语句、解释复杂图查询语句的含义、解释一大段 Bison 代码含义之后,我突然意识到:为什么不让 ChatGPT 帮我写好抓取数据的代码呢?
抓取世界杯数据
我真试了下 ChatGPT,结果是:完全可以,而且似乎真的很容易。
整个实现过程,基本上我像是一个代码考试的面试官,或是一个产品经理,提出我的需求,ChatGPT 给出具体的代码实现。我再试着运行代码,找到代码中不合理的地方,指出来并给出建议,ChatGPT 真的能理解我指出的点,并给出相应的修正,像是:
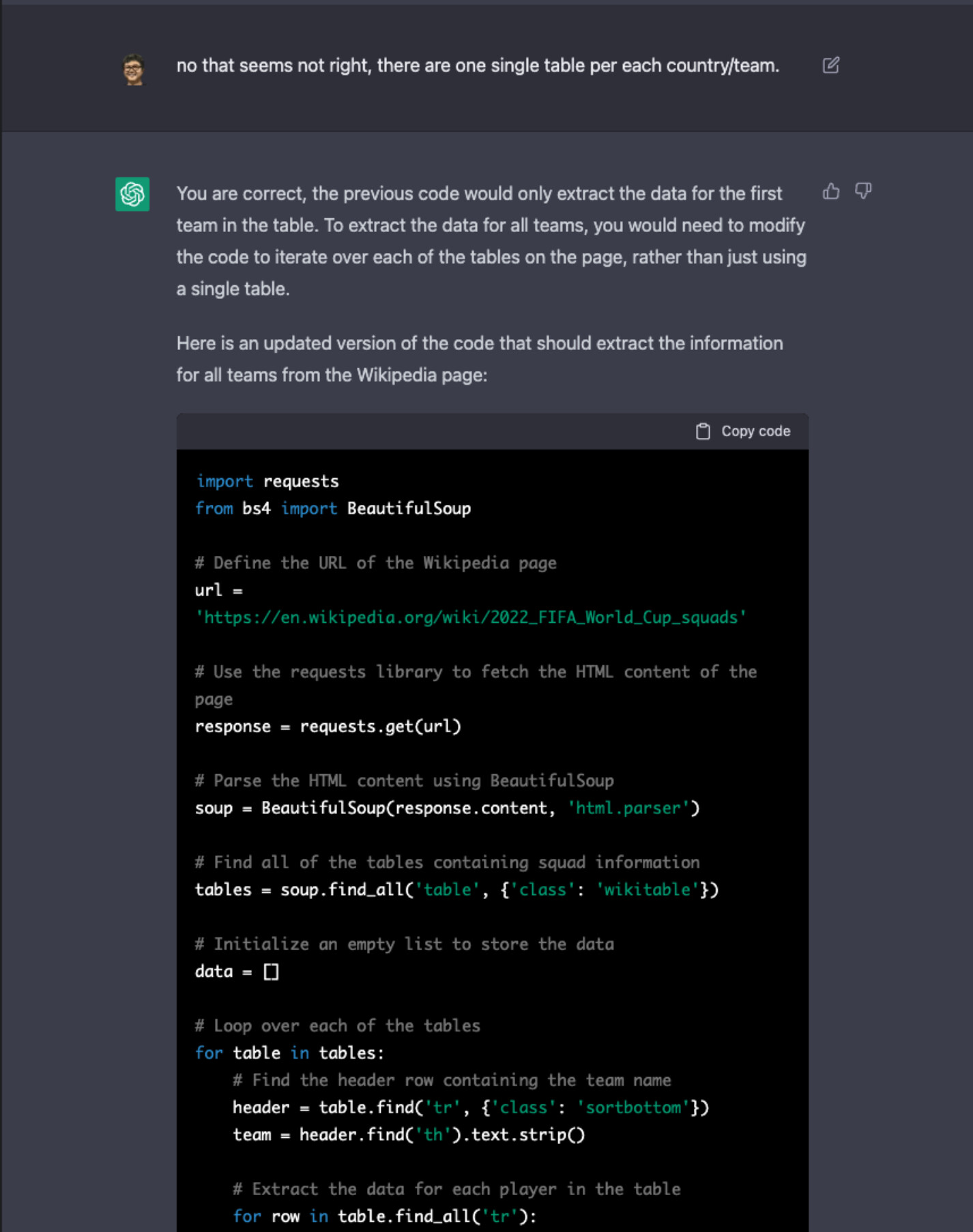
这一全过程我就不在这里列出来了,不过我把生成的代码和整个讨论的过程都分享在这里,感兴趣的同学可以去看看。
最终生成的数据是一个 CSV 文件:
- 代码生成的文件 world_cup_squads.csv
- 手动修改、分开了生日和年龄的列 world_cup_squads_v0.csv
上面的数据集包含的信息有:球队、小组、编号、位置、球员名字、生日、年龄、参加国际比赛场次、进球数、服役俱乐部。
Team,Group,No.,Pos.,Player,DOB,Age,Caps,Goals,Club
Ecuador,A,1,1GK,Hernán Galíndez,(1987-03-30)30 March 1987,35,12,0,Aucas
Ecuador,A,2,2DF,Félix Torres,(1997-01-11)11 January 1997,25,17,2,Santos Laguna
Ecuador,A,3,2DF,Piero Hincapié,(2002-01-09)9 January 2002,20,21,1,Bayer Leverkusen
Ecuador,A,4,2DF,Robert Arboleda,(1991-10-22)22 October 1991,31,33,2,São Paulo
Ecuador,A,5,3MF,José Cifuentes,(1999-03-12)12 March 1999,23,11,0,Los Angeles FC
这是手动删除了 CSV 表头的数据集 world_cup_squads_no_headers.csv。
图方法预测 2022 世界杯
图建模
本文用到了图数据库 NebulaGraph 和可视化图探索工具 NebulaGraph Explorer,你可以在阿里云免费申请半个月的试用,入口链接是 申请使用云端 NebulaGraph。
图建模(Graph Modeling)是把真实世界信息以”点-->边“的图形式去抽象与表示。
这里,我们把在公共领域获得的信息映射成如下的点与边:
点:
- player(球员)
- team(球队)
- group(小组)
- club(俱乐部)
边:
- groupedin(球队属于哪一小组)
- belongto(队员属于国家队)
- serve(队员在俱乐部服役)
而队员的年龄、参加国际场次(caps)、进球数(goals)则很自然作为 player 这一类点的属性。
下图是这个 schema 在 NebulaGraph Studio/Explorer(后边称 Studio/Explorer) 中的截图:

我们点击右上角的保存后,便能创建一个新的图空间,将这个图建模应用到图空间里。
这里可以参考下 Explore 草图的文档:https://docs.nebula-graph.com.cn/3.3.0/nebula-explorer/db-management/draft/
导入数据进 NebulaGraph
有了图建模,我们可以把之前的 CSV 文件(无表头版本)上传到 Studio 或者 Explorer 里,通过点、选关联不同的列到点边中的 vid 和属性:

完成关联之后,点击导入,就能把整个图导入到 NebulaGraph。成功之后,我们还得到了整个 csv --> Nebula Importer 的关联配置文件:nebula_importer_config_fifa.yml,你可以直接拖拽整个配置,不用自己去配置它了。
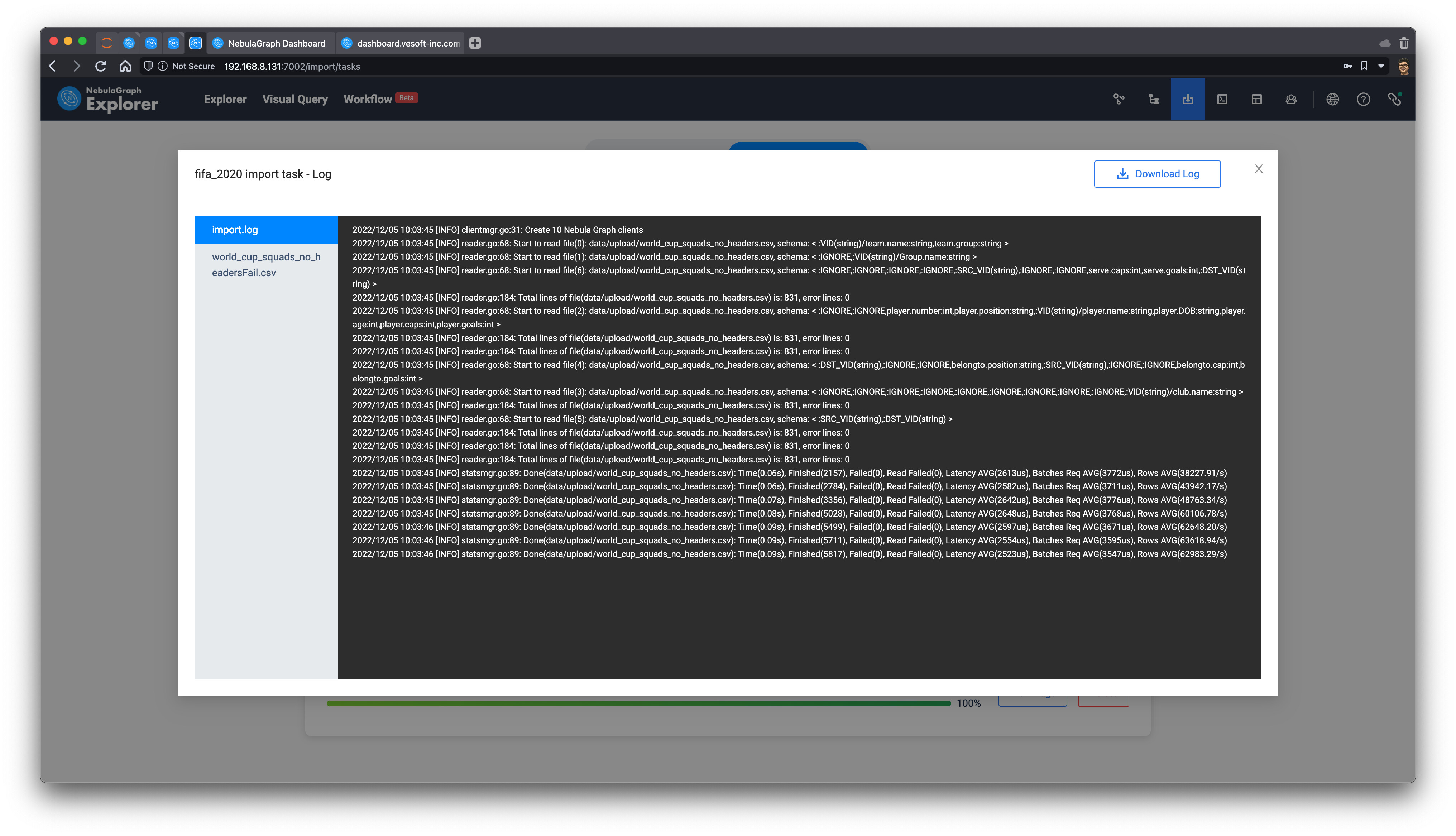
这里可以参考 Explorer 数据导入的文档:https://docs.nebula-graph.com.cn/3.3.0/nebula-explorer/db-management/11.import-data/
数据导入后,我们可以在 schema 界面查看数据统计。可以看到,有 831 名球员参加了 2022 卡塔尔世界杯,他们服役在 295 个不同的俱乐部:
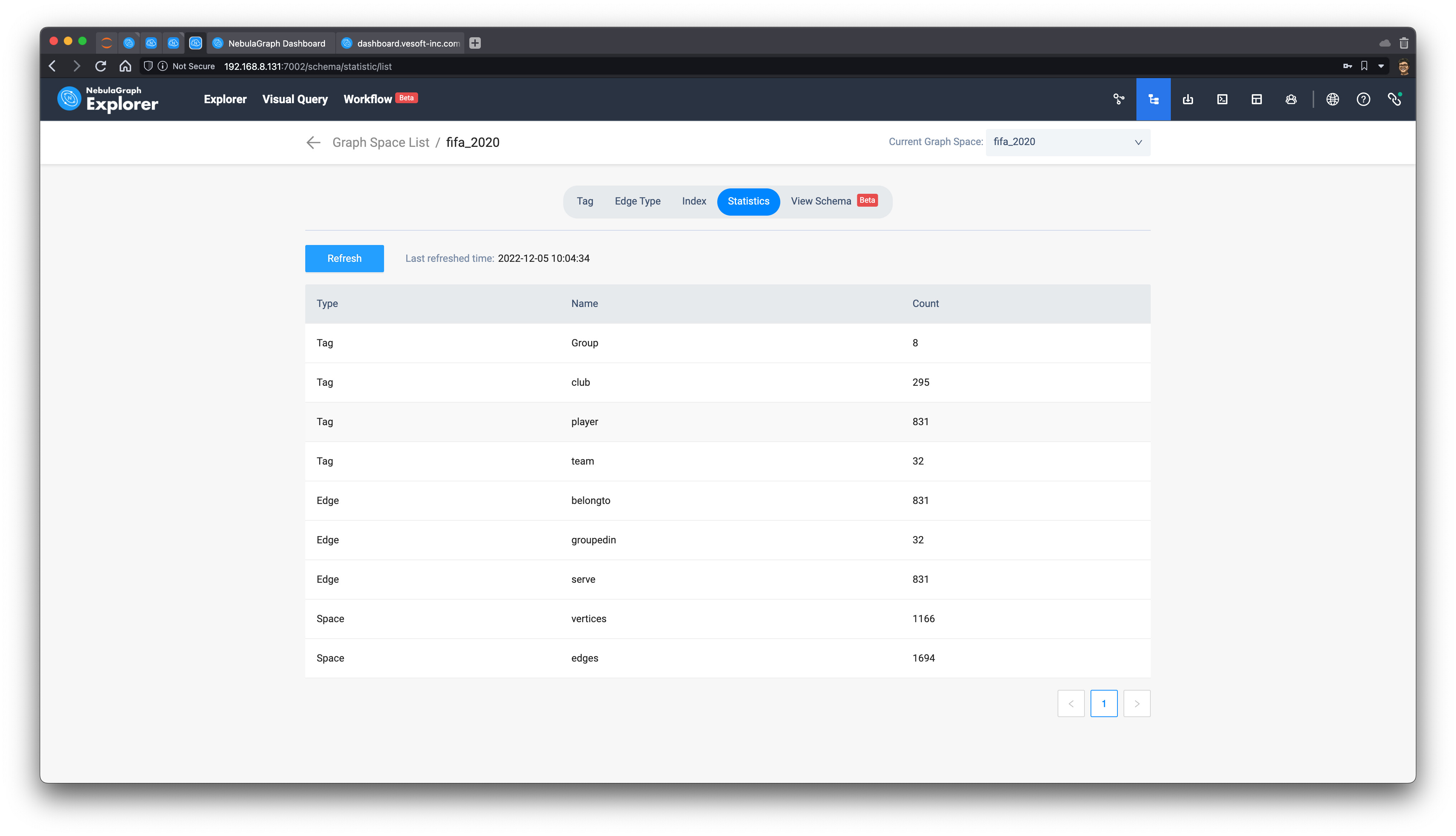
这里我们用到了 Explorer 的 schema 创建的文档:https://docs.nebula-graph.com.cn/3.3.0/nebula-explorer/db-management/10.create-schema/#_6
探索数据
查询数据
下面,我们试着把所有的数据展示出来看看。
首先,借助 NebulaGraph Explorer,我用拖拽的方式画出了任意类型的点(TAG)和任意类型点(TAG)之间的边。这里,我们知道所有的点都包含在至少一个边里,所以不会漏掉任何孤立的点。
让 Explorer 它帮我生成查询的语句。这里,它默认返回 100 条数据(LIMIT 100),我们手动改大一些,将 LIMIT 后面的参数改到 10000,并让它在 Console 里执行。
初步观察数据
结果渲染出来是这样子,可以看到结果自然而然地变成一簇簇的模式。
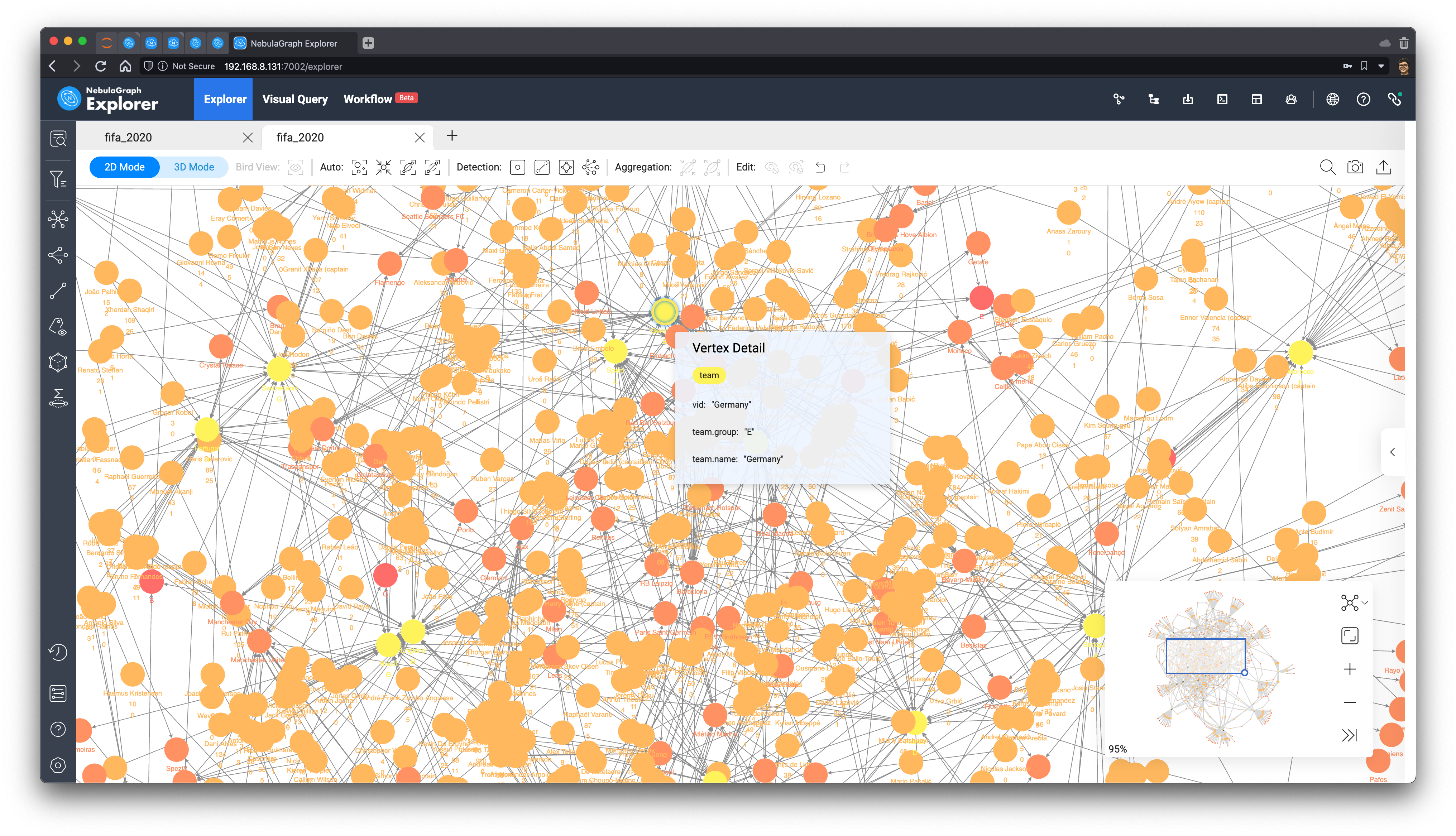
这些外围、形成的簇多是由不怎么知名的足球俱乐部,和不怎么厉害的国家队的球员组成,因为通常这些俱乐部只有一两个球员参加世界杯,而且他们还集中在一个国家队、地区,所以没有和很多其他球员、国家队产生连接。
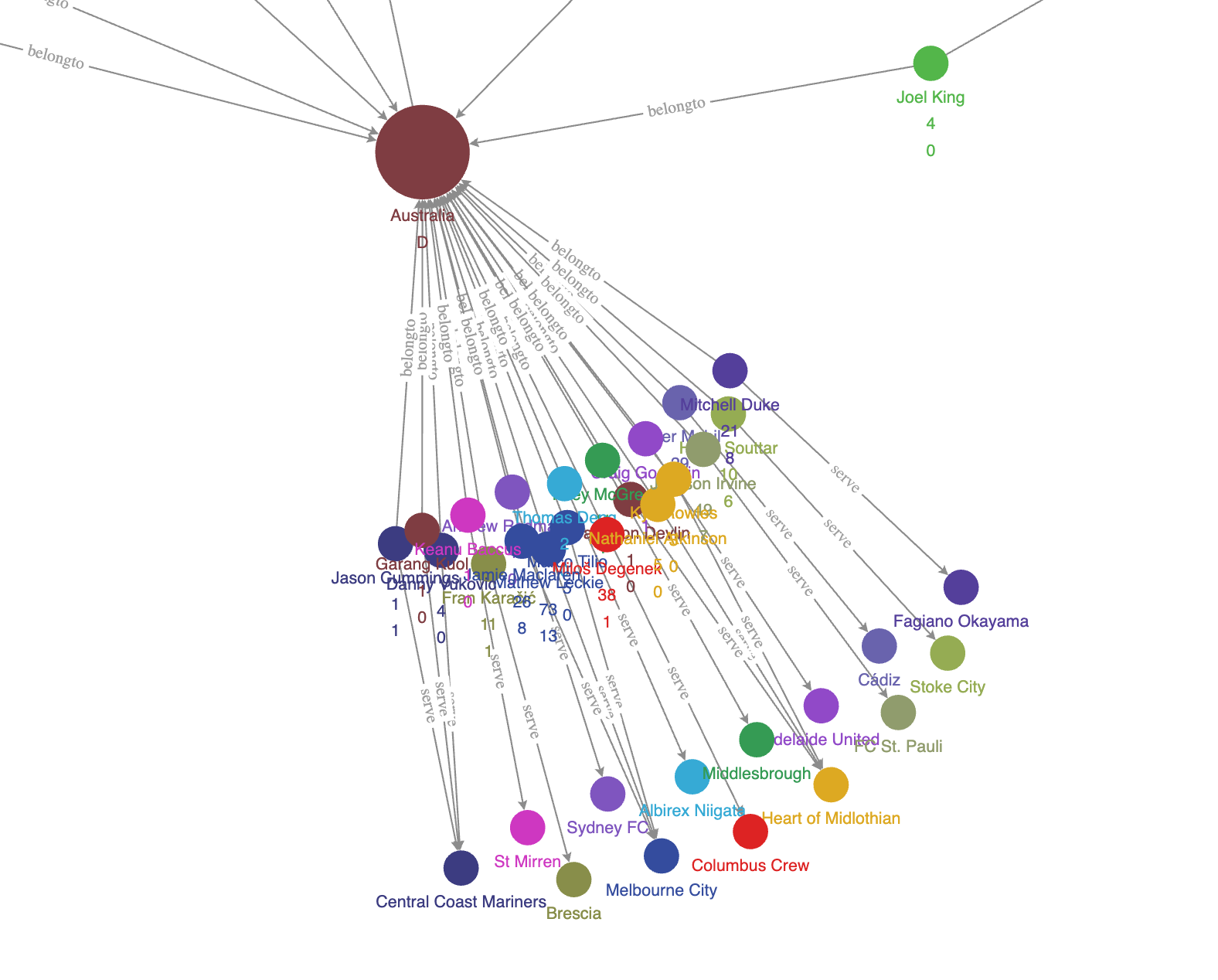
图算法辅助分析
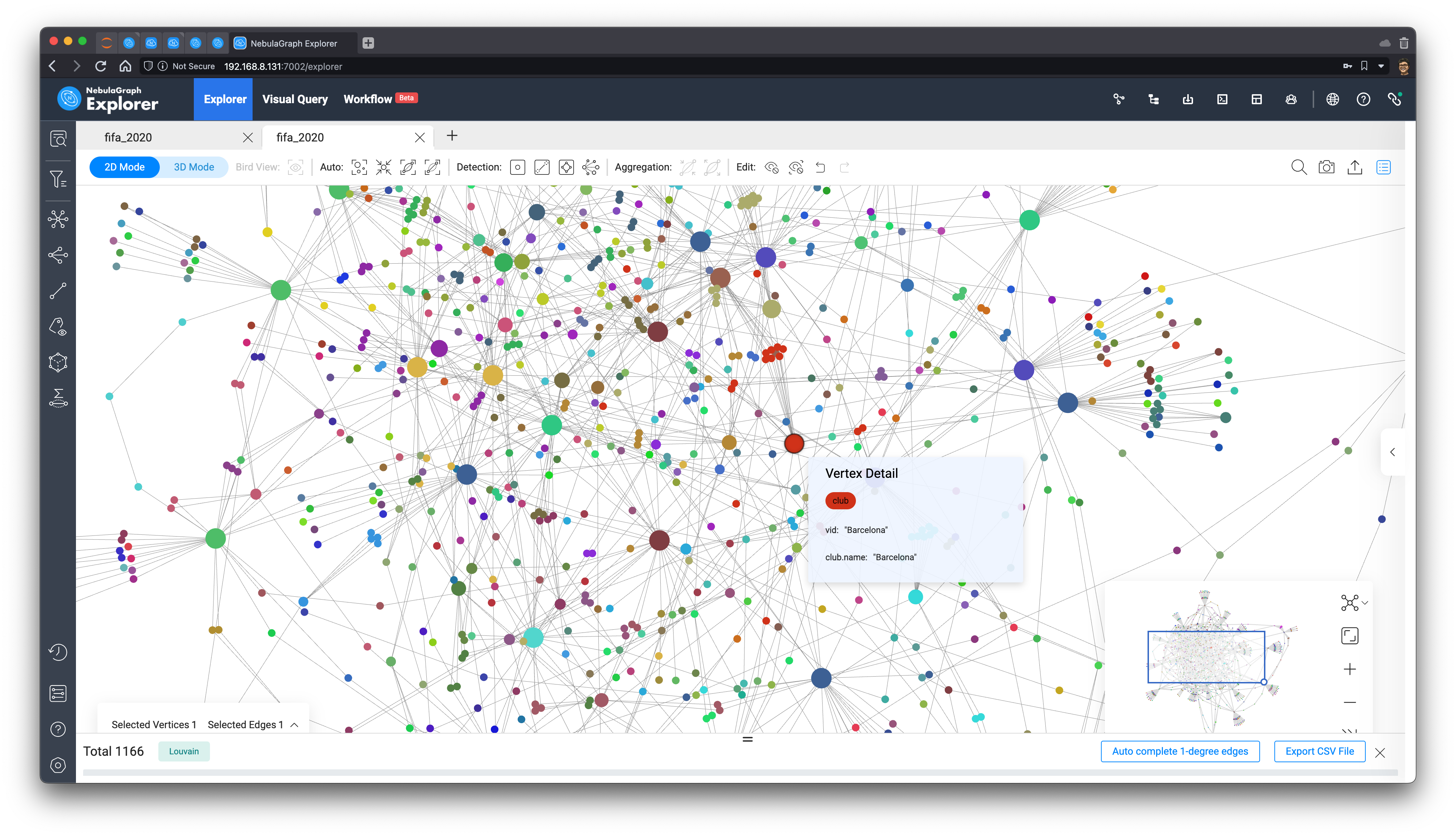
在我点击了 Explorer 中的两个按钮之后(详细参考后边的文档链接),在浏览器里,我们可以看到整个图已经变成:
这里可以参考 Explorer 的图算法文档:https://docs.nebula-graph.com.cn/3.3.0/nebula-explorer/graph-explorer/graph-algorithm/
其实,Explorer 这里利用到了两个图算法来分析这里的洞察:
- 利用点的出入度,改变它们的显示大小突出重要程度
- 利用 Louvain 算法区分点的社区分割
可以看到红色的大点是鼎鼎大名的巴塞罗那,而它的球员们也被红色标记了。
预测冠军算法
为了能充分利用图的魔法(与图上的隐含条件、信息),我的思路是选择一种利用连接进行节点重要程度分析的图算法,找出拥有更高重要性的点,对它们进行全局迭代、排序,从而获得前几名的国家队排名。
这些方法其实就体现了厉害的球员同时拥有更大的社区、连接度。同时,为了增加强队之间的区分度,我准备把出场率、进球数的信息也考虑进来。
最终,我的算法是:
- 取出所有的
(球员)-服役->(俱乐部)的关系,过滤其中进球数过少、单场进球过少的球员(以平衡部分弱队的老球员带来的过大影响) - 从过滤后的球员中向外探索,获得国家队
- 在以上的子图上运行 Betweenness Centrality 算法,计算节点重要度评分
算法过程
首先,我们取出所有进球数超过 10,场均进球超过 0.2 的 (球员)-服役->(俱乐部) 的子图:
MATCH ()-[e]->()
WITH e LIMIT 10000
WITH e AS e WHERE e.goals > 10 AND toFloat(e.goals)/e.caps > 0.2
RETURN e
为了方便,我把进球数和出场数也作为了 serve 边上的属性了。
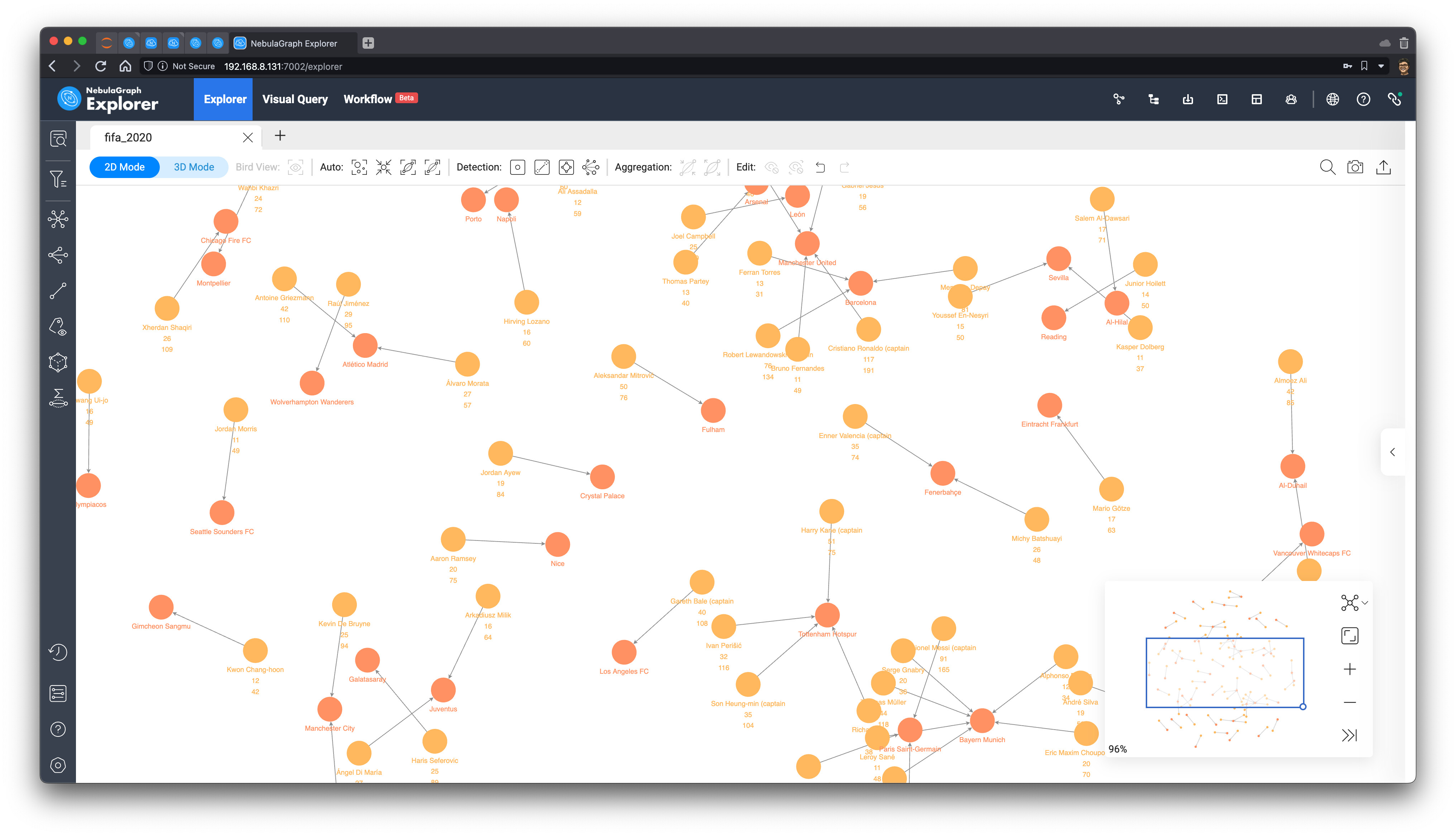
然后,我们全选图上的所有点,点击左边的工具栏,选择出方向的 belongto 边,向外进行图拓展(遍历),同时选择将拓展得到的新点标记为旗帜的 icon:
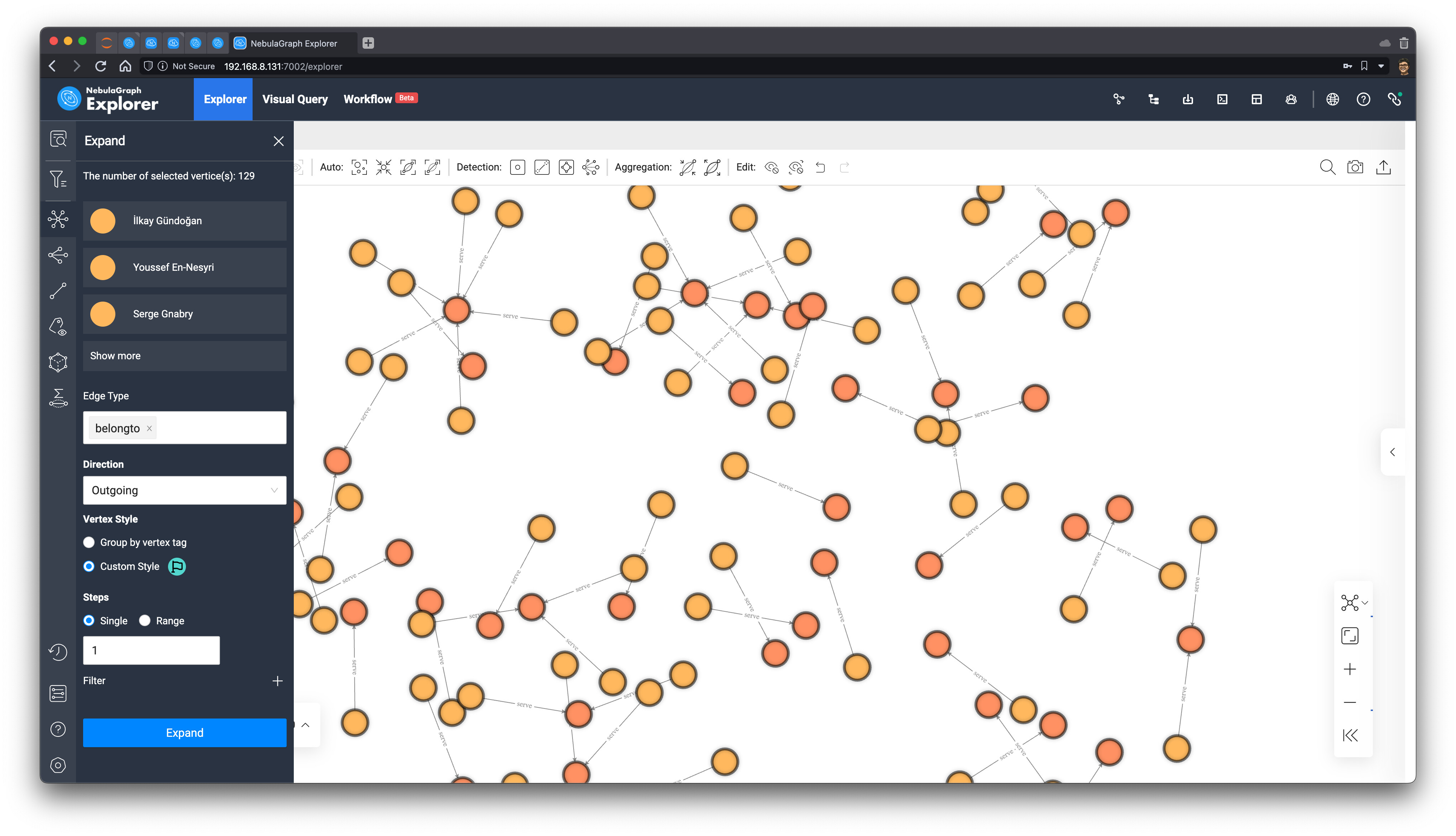
现在,我们获得了最终的子图,我们利用工具栏里的浏览器内的图算法功能,执行 BNC(Betweenness Centrality)
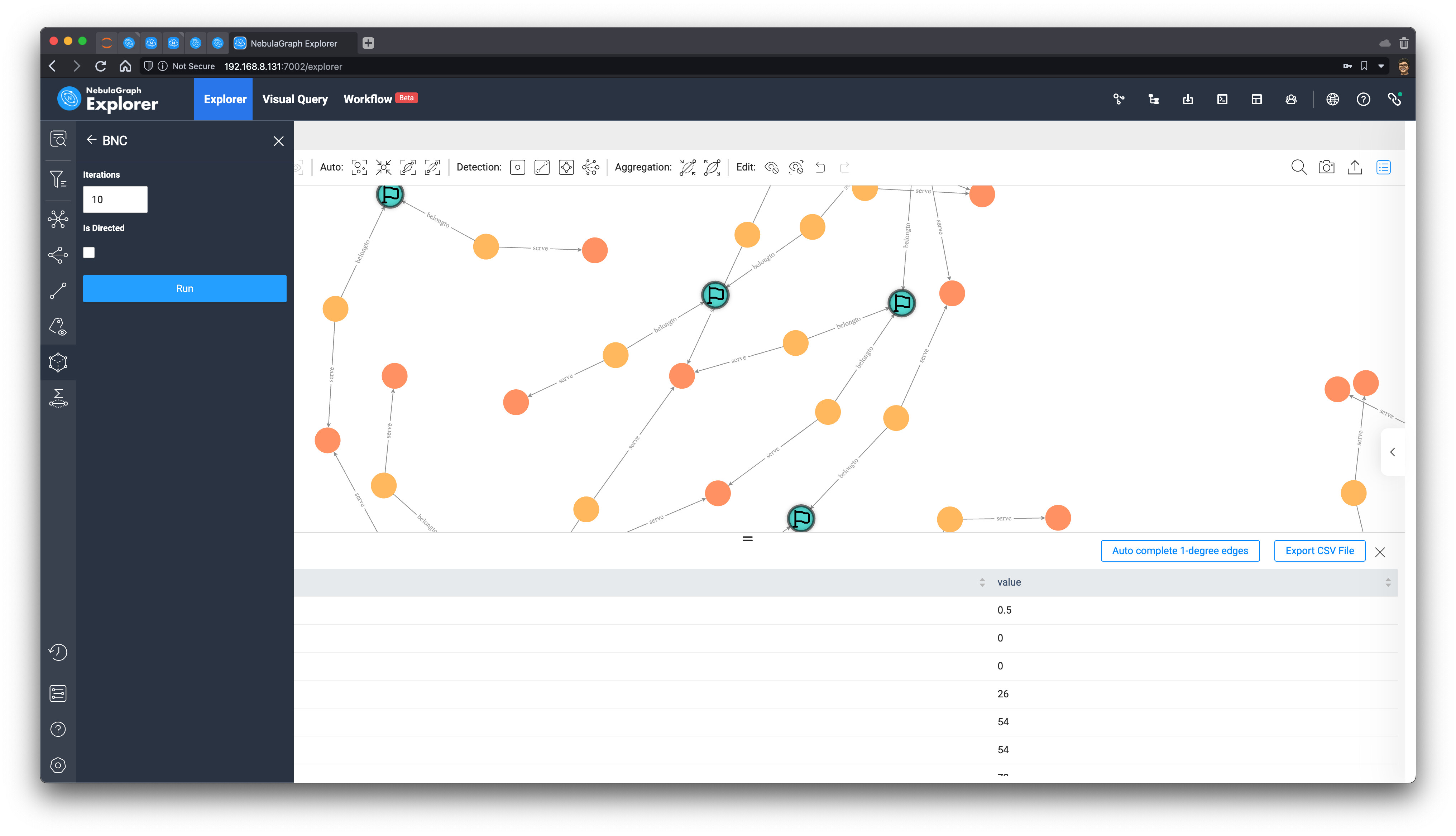
最后,这个子图变成了这样子:

预测结果
最终,我们根据 Betweenness Centrality 的值排序,可以得到最终的获胜球队应该是:巴西 !
其次是比利时、德国、英格兰、法国、阿根廷,让我们等两个礼拜回来看看预测结果是否准确吧 。
注:排序数据(其中还有非参赛球队的点)
| Vertex | Betweenness Centrality |
|---|---|
| Brazil | 3499 |
| Paris Saint-Germain | 3073.3333333333300 |
| Neymar | 3000 |
| Tottenham Hotspur | 2740 |
| Belgium | 2587.833333333330 |
| Richarlison | 2541 |
| Kevin De Bruyne | 2184 |
| Manchester City | 2125 |
| İlkay Gündoğan | 2064 |
| Germany | 2046 |
| Harry Kane (captain | 1869 |
| England | 1864 |
| France | 1858.6666666666700 |
| Argentina | 1834.6666666666700 |
| Bayern Munich | 1567 |
| Kylian Mbappé | 1535.3333333333300 |
| Lionel Messi (captain | 1535.3333333333300 |
| Gabriel Jesus | 1344 |
原文地址:https://discuss.nebula-graph.com.cn/t/topic/11584
谢谢你读完本文 (///▽///)
如果你想尝鲜图数据库 NebulaGraph,记得去 GitHub 下载、使用、(з)-☆ star 它 -> GitHub;和其他的 NebulaGraph 用户一起交流图数据库技术和应用技能,留下「你的名片」一起玩耍呀~
ChatGPT 加图数据库 NebulaGraph 预测 2022 世界杯冠军球队的更多相关文章
- Nebula Graph 技术总监陈恒:图数据库怎么和深度学习框架进行结合?
引子 Nebula Graph 的技术总监在 09.24 - 09.30 期间同开源中国·高手问答的小伙伴们以「图数据库的设计和实践」为切入点展开讨论,包括:「图数据库的存储设计」.「图数据库的计算设 ...
- Nebula 架构剖析系列(零)图数据库的整体架构设计
Nebula Graph 是一个高性能的分布式开源图数据库,本文为大家介绍 Nebula Graph 的整体架构. 一个完整的 Nebula 部署集群包含三个服务,即 Query Service,S ...
- COSCon'19 | 如何设计新一代的图数据库 Nebula
11 月 2 号 - 11 月 3 号,以"大爱无疆,开源无界"为主题的 2019 中国开源年会(COSCon'19)正式启动,大会以开源治理.国际接轨.社区发展和开源项目为切入点 ...
- 图数据库对比:Neo4j vs Nebula Graph vs HugeGraph
本文系腾讯云安全团队李航宇.邓昶博撰写 图数据库在挖掘黑灰团伙以及建立安全知识图谱等安全领域有着天然的优势.为了能更好的服务业务,选择一款高效并且贴合业务发展的图数据库就变得尤为关键.本文挑选了几款业 ...
- 初识分布式图数据库 Nebula Graph 2.0 Query Engine
摘要:本文主要介绍 Query 层的整体结构,并通过一条 nGQL 语句来介绍其通过 Query 层的四个主要模块的流程. 一.概述 分布式图数据库 Nebula Graph 2.0 版本相比 1.0 ...
- 图数据库|基于 Nebula Graph 的 BetweennessCentrality 算法
本文首发于 Nebula Graph Community 公众号 在图论中,介数(Betweenness)反应节点在整个网络中的作用和影响力.而本文主要介绍如何基于 Nebula Graph 图数据 ...
- 图数据库(graph database)资料收集和解析 - daily
Motivation 图数据库中的高科技和高安全性中引用了一个关于图数据库(graph database)的应用前景的乐观估计: 预计到2017年,图数据库产业在数据库市场的份额将从2个百分点增长到2 ...
- Android之数据存储----使用LoaderManager异步加载数据库
一.各种概念: 1.Loaders: 适用于Android3.0以及更高的版本,它提供了一套在UI的主线程中异步加载数据的框架.使用Loaders可以非常简单的在Activity或者Fragment中 ...
- 图数据库项目DGraph的前世今生
本文由云+社区发表 作者:ManishRai Jain 作者:ManishRai Jain Dgraph Labs创始人 版权声明:本文由腾讯云数据库产品团队整理,页面原始内容来自于db weekly ...
- Neo4j图数据库使用
最近在处理一些图的数据,主要是有向图,如果图的节点不是特别大可以直接加载到内存里来处理,但是当图的节点个数特别大时,内存就放不下了:我 们牵涉到的图的节点数最大可以达到数亿个节点,已经超出的机器内存的 ...
随机推荐
- Ubuntu20.04本地安装Redash中文版
一.安装基础环境: # 1.更换APT国内源 sudo sed -i s@/cn.archive.ubuntu.com/@/mirrors.aliyun.com/@g /etc/apt/sources ...
- 【前端必会】前端开发利器VSCode
介绍 工欲善其事必先利其器,开发工具方面选择一个自己用的顺手的,这里就用VSCode 安装参考 https://www.runoob.com/w3cnote/vscode-tutorial.html ...
- python实现给定K个字符数组,从这k个字符数组中任意取一个字符串,按顺序拼接,列出所有可能的字符串组合结果!
题目描述:给定K个字符数组,从这k个字符数组中任意取一个字符串,按顺序拼接,列出所有可能的字符串组合结果! 样例: input:[["a","b"," ...
- 如何在服务器上部署WebDeploy
之前项目中网站发布都是手工拷贝文件,特别麻烦,看到好多用webdeploy一键部署网站到IIS服务器,我也学习了一下. 第一步,打开服务器管理器 打开方式是开始菜单=>管理工具=>服务器管 ...
- 猫狗识别-CNN与VGG实现
本次项目首先使用CNN卷积神经网络模型进行训练,最终训练效果不太理想,出现了过拟合的情况.准确率达到0.72,loss达到0.54.使用预训练的VGG模型后,在测试集上准确率达到0.91,取得了不错的 ...
- 【pytest官方文档】解读- 插件开发之hooks 函数(钩子)
上一节讲到如何安装和使用第三方插件,用法很简单.接下来解读下如何自己开发pytest插件. 但是,由于一个插件包含一个或多个钩子函数开发而来,所以在具体开发插件之前还需要先学习hooks函数. 一.什 ...
- 2022“杭电杯”中国大学生算法设计超级联赛(6)- 1011 Find different
2022"杭电杯"中国大学生算法设计超级联赛(6)- 1011 Find different 比赛时队友开摆,还剩半个小时,怎么办?? 当然是一起摆 Solution 看到这个题没 ...
- 关于Springboot启动报错 Whitelabel Error Page: This application has no explicit mapping
Whitelabel Error Page This application has no explicit mapping for /error, so you are seeing this as ...
- Selenium4.0+Python3系列(四) - 常见元素操作(含鼠标键盘事件)
一.写在前面 上篇文章介绍的是关于浏览器的常见操作,接下来,我们将继续分享关于元素的常见操作,建议收藏.转发! 二.元素的状态 在操作元素之前,我们需要了解元素的常见状态. 1.常见元素状态判断,傻傻 ...
- 京东云开发者|IoT运维 - 如何部署一套高可用K8S集群
环境 准备工作 配置ansible(deploy 主机执行) # ssh-keygen # for i in 192.168.3.{21..28}; do ssh-copy-id -i ~/.ssh/ ...