一文带你入木三分地理解字符串KMP算法(next指针解法)
1. KMP算法简介
温馨提示:在通篇阅读完并理解后再看简介效果更佳
以下简介由百度百科提供https://baike.baidu.com/item/KMP%E7%AE%97%E6%B3%95/10951804:
KMP算法是一种改进的字符串匹配算法,由D.E.Knuth,J.H.Morris和V.R.Pratt提出的,因此人们称它为克努特—莫里斯—普拉特操作(简称KMP算法)。KMP算法的核心是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。具体实现就是通过一个next()函数实现,函数本身包含了模式串的局部匹配信息。KMP算法的时间复杂度O(m+n)
2. 对算法本质的理解
注意:为了叙述方便,本小节中的索引都从1开始而非0
· 抽象理解人眼是如何匹配字符串的
我们要在字符串1中查找字符串2,则把字符串1称为文本串,字符串2成为匹配串。
人眼在文本串与匹配串中来回扫描,一个个判断两串字符是否相等(你可能觉得你能一下子比较五个以上字符,但不妨理解为你的大脑还是一个个比较的)。如下图所示:当人眼发现两个字符不相等时,视线(图中红色区块)不会移到两串的起始位置重新比较,而是会找到文本串视线曾经过区域中与匹配串某前缀(图中黄色区块)相等的地方开始比较,
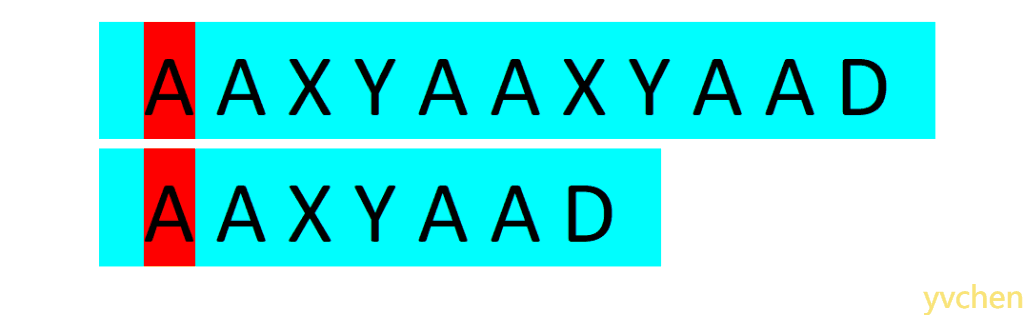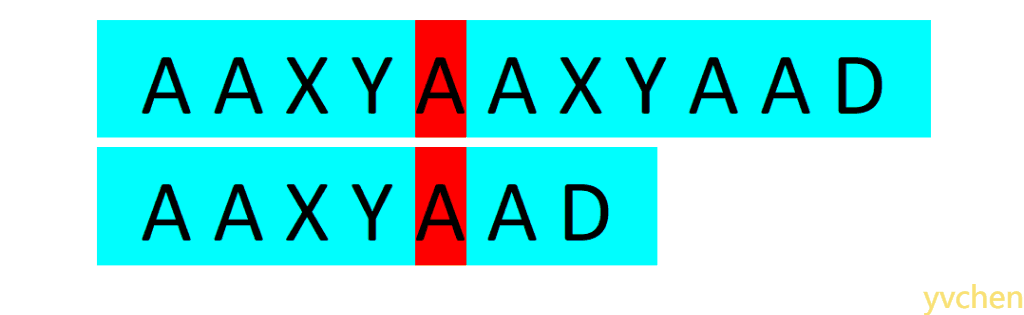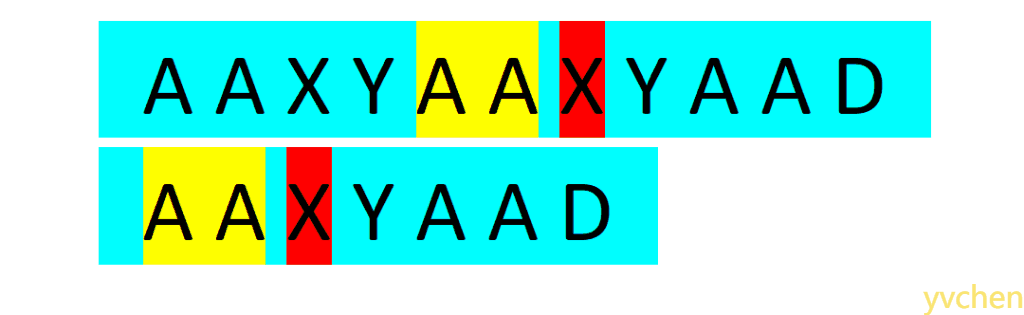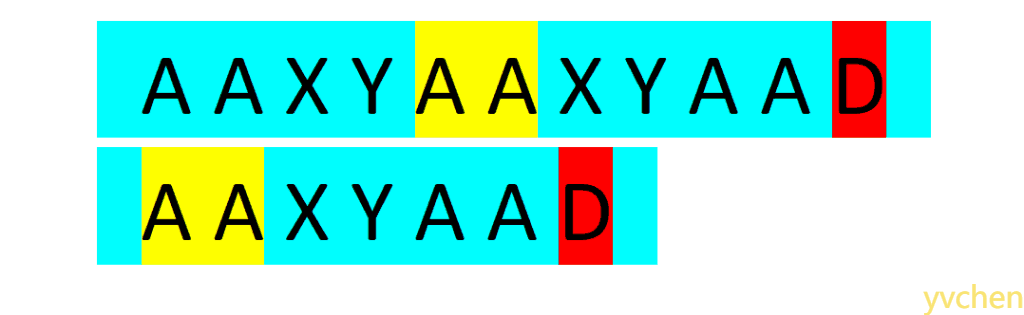
当我们对匹配字符串时人视线的移动进行模拟便可以实现KMP这一高效的匹配算法。
· 用最大公共前后缀与指针模拟人眼操作
我们如此定义最大公共前后缀:在匹配串位置[1,N]的区块中找一个子串,使得该子串既是最长的前缀,又是最长的后缀,并且该子串不能等于该区块本身,则称该子串为匹配串位置[1,N]的区块的最大公共前后缀。
例如下图:
对于匹配串AAXAAXAA,可以发现AAXAA就是它的最大公共前后缀。
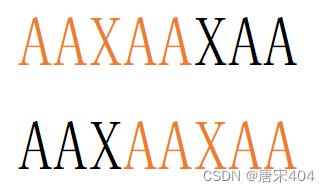
需要用到最大公共前后缀做什么呢?别急,咱们根据以下几个步骤循序渐进地理解:
1.假设匹配串与文本串在位置[1,W-1]都相等,在位置W字符不等,在此条件下我们设pre为[1,W-1]区域中匹配串的某前缀(下文会确定下来),设指针i指向文本串中的字符,指针j指向匹配串中的字符。
模拟人眼的操作,此时我们要在文本串[1,W-1]之间(去除已经和pre比较过的部分)寻找pre并由此移动指针。
2.由于是从前向后匹配字符串的,所以如果pre在[1,W-1]这个文本串区块间存在,其第一次出现一定是出现在区块的末尾,也就是说它就是区块的后缀。又由于匹配串与文本串在位置[1,W-1] 都相等,所以pre也是匹配串的后缀,于是成为了匹配串[1,W-1]区域的公共前后缀。
图例:
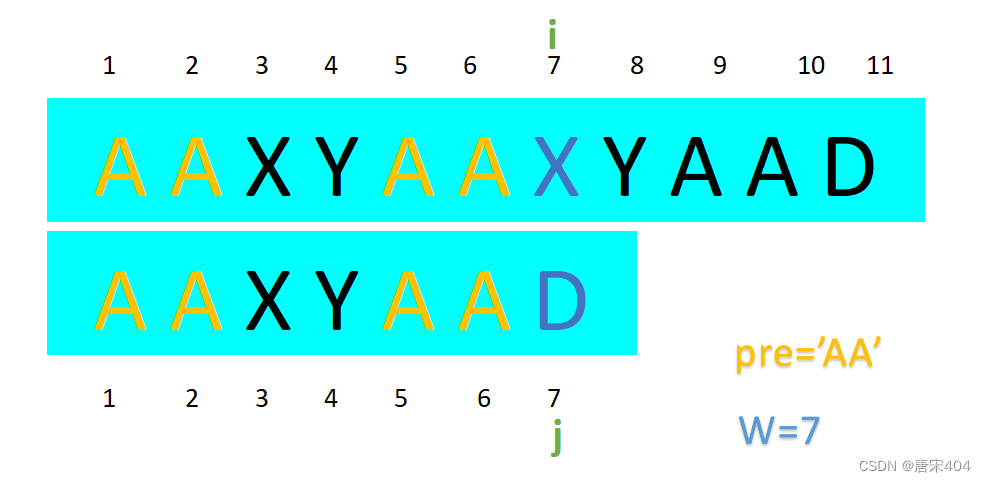
3.我们这时候就可以尝试着使用公共前后缀将比较字符串的视线移动用指针具象化。当双指针所指的字符相同时,令i++;j++即可;若字符不同时,我们如此考虑:
- 当文本串[1,W-1] (去除已经和pre比较过的部分)中含有pre,即在[1,W-1] 有公共前后缀(pre长大于0)时。我们记len[W-1]为匹配串的前缀终止位置,从上文得文本串后缀的终止位置为W-1,由于匹配串的前缀与文本串的后缀相对应,所以我们只需要从匹配串前缀与文本串后缀之后开始比较即可。即令i不变仍为W;j=len[W-1]+1。
- 我们又额外考虑当文本串[1,W-1] (去除已经和pre比较过的部分)中不含pre,即在[1,W-1] 无公共前后缀(pre长为0)时的情况。这时完全可以看作len[W-1]=0,与上一种情况一致,i不变保持W;j=len[W-1]+1。
指针移动图例:
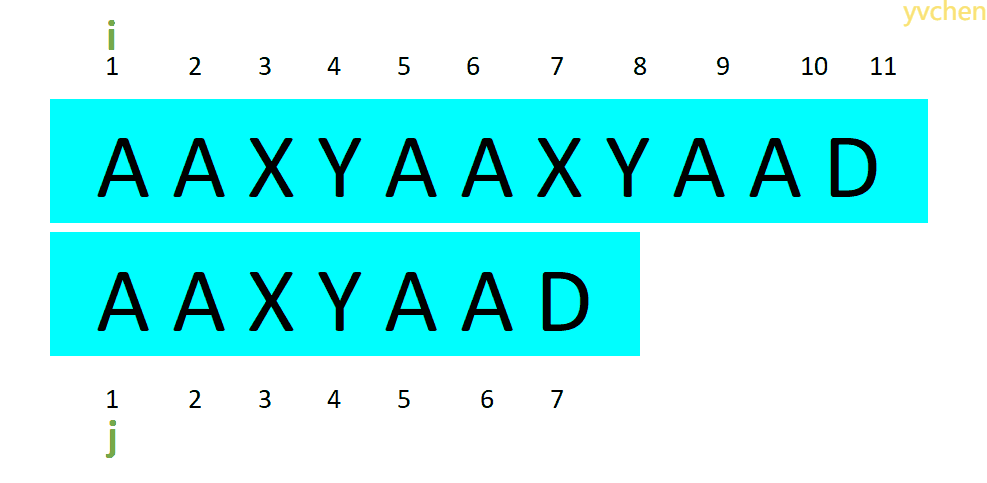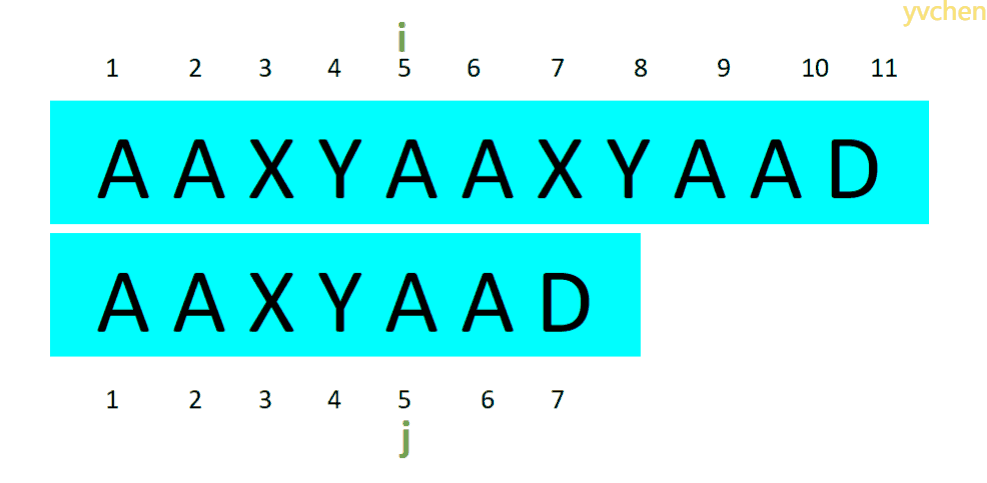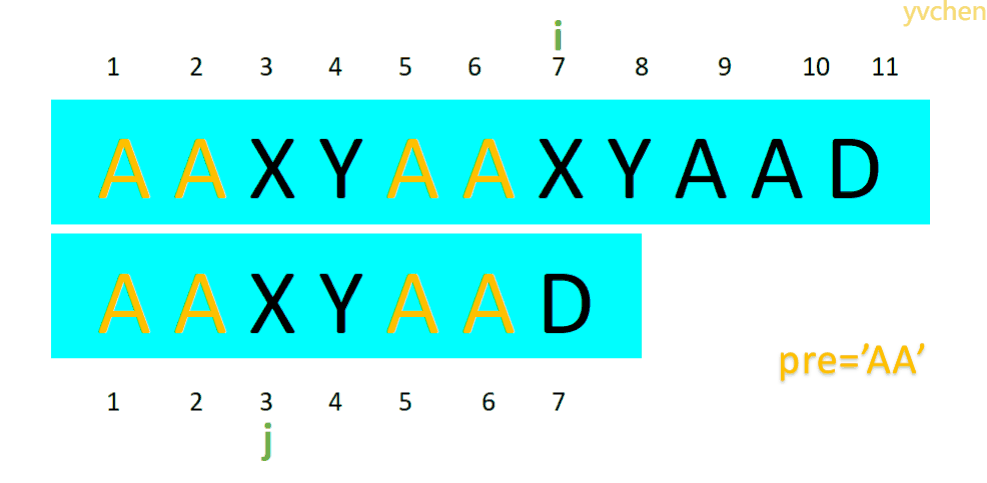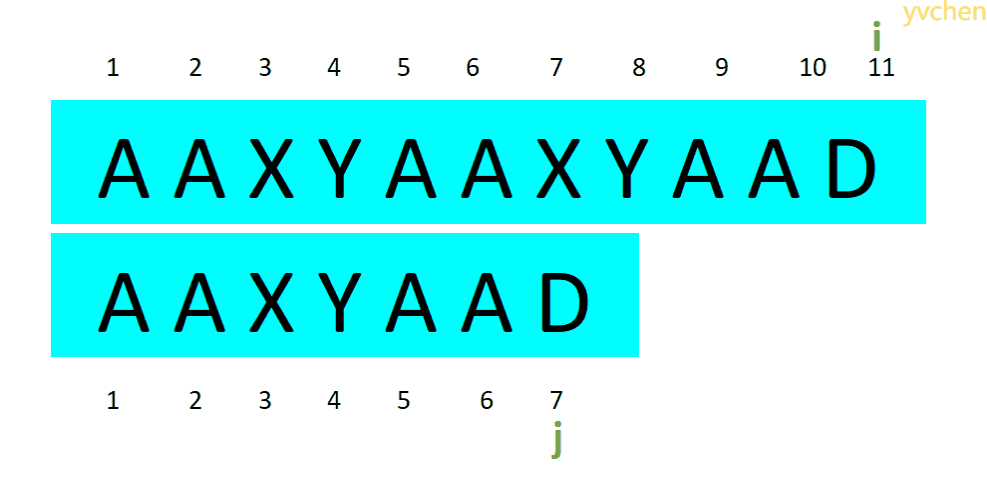
所以无论哪种情况,文本串上的指针i不会回退,而匹配串的指针j则会根据不同情况而回退
4.到这公共前后缀的价值已经很明确了,只要找出每一个[1,W-1]区域匹配串的公共前后缀之长len[W-1],那么就可以得到如下指针移动公式,使得每次字符不同时,指针的移动模拟了人眼的匹配过程。


5.这里我们应当确立步骤1中的某前缀应当为满足匹配串[1,W-1]区域的公共前后缀最大时的前缀。也就是说要pre满足其为匹配串[1,W-1]区域的最大公共前后缀。理由:见下图两个取不同大小公共前后缀的示例的比较次数,其中橙色区块为公共前后缀,蓝色区块为指针j回退后还需要比较的字符,明显取大的公共前后缀的比较字符更少(因为大的公共前后缀中包括了小的公共前后缀情况下还需要比较的字符)。
以AA为公共前后缀时:还需比较7个字符
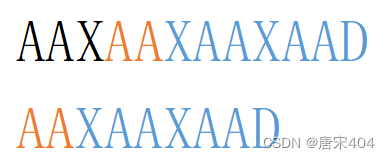
以AAXAA为公共前后缀时:还需比较4个字符
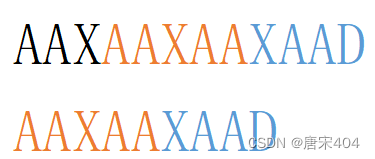
归纳:到这里为止,我们所有的问题就转化为了求len[W-1],即求匹配串[1,W-1]中最大公共前后缀的值。
3. 使用next数组求解最大公共前后缀长度
注意:上文说到,我们只要知道len[W-1]的值,便可以在位置W处字符不等式快速找到指针回退的位置。然而在大多数官方的解释中,这个len数组被命名为next,为了规范化,我们下文中会用next数组来称呼len数组。此外,索引仍从1开始。
我们设字符串F表示匹配串,设next[index]表示匹配串[1,index]区域中最大公共前后缀的长度。并使用使用双指针求解,指针i指向当前字符位置(也可以看作就是后缀终止位置),用指针j指向[1,i]间最大公共前后缀的前缀终止位置(同时可以发现j就是最大公共前后缀长度),
求最大公共前后缀的过程如下,当i从1向匹配串末尾遍历时
- 若F[j+1]=F[i],说明当下前缀之后的第一个位置与后缀终止字符相等,那么最大公共前后缀就可以增加一个字符,前缀终止位置可以指向下一个字符,即next[i]=j+1;j++。
- 若F[j+1]\(\neq\)F[i],此时的情况就需要分多步进行理解:
1.可以把当前的状态用下图表示,其中整个矩形为匹配串[1,i]的部分,可见A=F[j+1],B=F[i]。
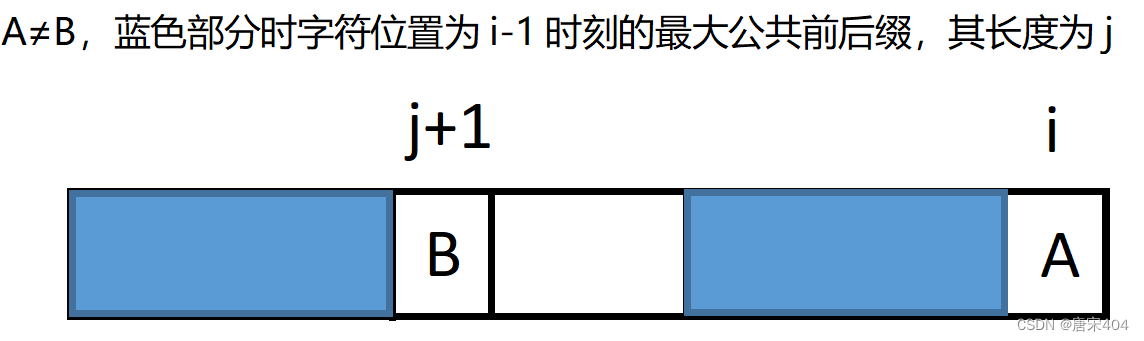
2.现在我们先将问题转化为以下这种情况,找到一个如下的橙色部分,判断A是否与C相等,相等则橙色部位加上F[i]即为[1,i]的最大公共前后缀。
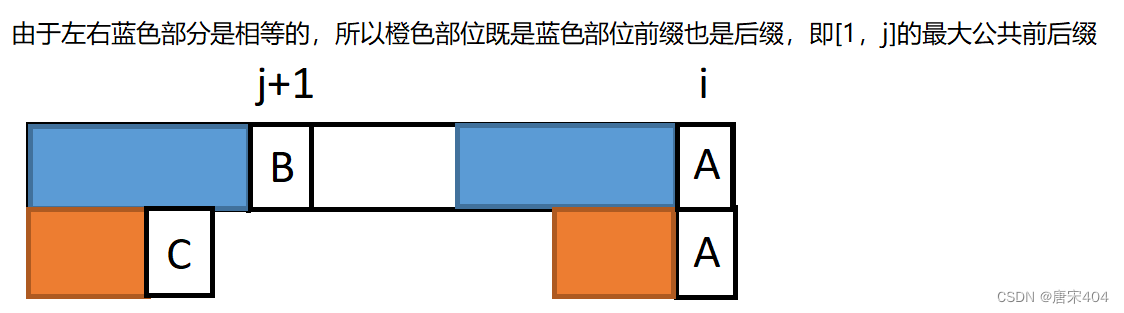
所以我们可以确定橙色部分长度为next[j]。
3.将上图简化为下图,我们发现这个状态是似曾相识的
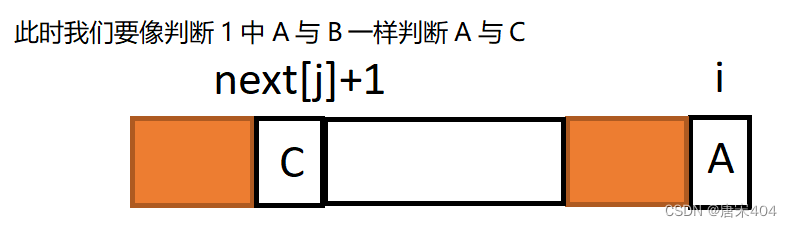
我们不如直接令j回退到next[j]处,然后再判断F[j+1]与F[i]是否相等,这时一切又转化为整个过程的开始。
4.可以发现,当F[j+1]\(\neq\)F[i]时,我们总是周而复始找到j这个最大公共前后缀的最大公共前后缀,然后重新判断,直到无最大公共前后缀或者判断出相等。
归纳:至此我们已经可以对于任意索引index,求出匹配串[1,index]区间的最大公共前后缀长度,结合上部分指针移动公式即可完成KMP算法。
4. 用c++代码实现
#include<bits/stdc++.h>
using namespace std;
//索引仍然从1开始
void getNext(int* next,string key){
//输入空next数组与匹配串key,将next数组生成为key的最大公共前后缀数组
int j=0;next[1]=0;
for(int i=2;i<key.length();i++){
while(j>0 && key[i]!=key[j+1]) j=next[j];//不断寻找最大公共前后缀的最大公共前缀,直到最大公共前后缀或者判断出相等。
if(key[i]==key[j+1]) j++;//判断出相等,最大公共前后缀增长
next[i]=j;
}
}
int KMP(string text,string key){
/*输入文本串与匹配串,返回匹配串在文本串中的位置
找不到则返回-1*/
text=" "+text;key=" "+key;//因为索引从1开始,所以要在0的位置垫上空格
if(key.length() == 0)return -1;
int next[key.length()+1];
getNext(next, key);//生成匹配串的next数组
int j=1,i=1;
while(j < key.length() && i < text.length()){
if(text[i] == key[j])i++,j++;//当字符相等时的公式
else j = next[i-1]+1;//当字符不等时的公式
}
if(j == key.length())return i-key.length()+1;
return -1;
}
int main() {
string text,key;//文本串与匹配串
cin>>text>>key;
int i=KMP(text,key);
printf("匹配串出现在文本串第%d位",i);
return 0;
}
输入:AAXAAXAAXAAD AAXAAXAAD
输出:匹配串出现在文本串第4位
写文不易,若对您有帮助请给予鼓励。
一文带你入木三分地理解字符串KMP算法(next指针解法)的更多相关文章
- 理解字符串 Boyer-Moore 算法
作者: 阮一峰 上一篇介绍了 kmp算法 但是,它并不是效率最高的算法,实际采用并不多. 各种文本编辑器的"查找"功能(Ctrl+F),大多采用Boyer-Moore算法. Boy ...
- 数据结构(复习)---------字符串-----KMP算法(转载)
字符串匹配是计算机的基本任务之一. 举例来说,有一个字符串"BBC ABCDAB ABCDABCDABDE",我想知道,里面是否包含另一个字符串"ABCDABD" ...
- 通过图片对比带给你不一样的KMP算法体验
KMP 算法,俗称“看毛片”算法,是字符串匹配中的很强大的一个算法,不过,对于初学者来说,要弄懂它确实不易. 笔者认为,KMP 算法之所以难懂,很大一部分原因是很多实现的方法在一些细节的差异.体现在几 ...
- 查找子字符串----KMP算法深入剖析
假设主串:a b a b c a b c a c b a b 子串:a b c a c 1.一般匹配算法 逐个字符的比较,匹配过程如下: 第一趟匹配 a b a b c a b c a c ...
- 模板 - 字符串 - KMP算法
要先理解前缀函数的定义,前缀函数 \(\pi(i)\) 表示字符串 \(s[0,i]\) 的同时是其最长真前缀及最长真后缀的长度,简单来说就是这个 \(s[0,i]\) 首尾最长的重叠长度(不能完全重 ...
- 字符串KMP算法
讲解:http://blog.csdn.net/starstar1992/article/details/54913261 #include <bits/stdc++.h> using n ...
- 字符串 kmp算法 codeforce 625B 题解(模板)
题解:kmp算法 代码: #include <iostream>#include <algorithm>#include <cstring>#include < ...
- KMP算法的理解
---恢复内容开始--- 在看数据结构的串的讲解的时候,讲到了KMP算法——一个经典的字符串匹配的算法,具体背景自行百度之,是一个很牛的图灵奖得主和他的学生提出的. 一开始看算法的时候很困惑,但是算法 ...
- KMP算法最浅显理解——一看就明确
说明 KMP算法看懂了认为特别简单,思路非常easy,看不懂之前.查各种资料,看的稀里糊涂.即使网上最简单的解释,依旧看的稀里糊涂. 我花了半天时间,争取用最短的篇幅大致搞明确这玩意究竟是啥. 这里不 ...
- KMP算法最浅显理解——一看就明白
https://blog.csdn.net/starstar1992/article/details/54913261 说明 KMP算法看懂了觉得特别简单,思路很简单,看不懂之前,查各种资料,看的稀里 ...
随机推荐
- MySQL用户中的%到底包不包括localhost?
1 前言 操作MySQL的时候发现,有时只建了%的账号,可以通过localhost连接,有时候却不可以,网上搜索也找不到满意的答案,干脆手动测试一波 2 两种连接方法 这里说的两种连接方法指是执行my ...
- C#-01 关于C#中传入参数的一些用法
实验环境 实验所处环境位于vs2019环境中 学习内容 一.最基础的参数传入:值参数 对于这种传入,和其他的c,c++编程语言参数传入一样,没有太大差别,在这里给如下例子: 虽然这里并没有进行传参但是 ...
- 深入理解AQS--jdk层面管程实现【管程详解的补充】
什么是AQS 1.java.util.concurrent包中的大多数同步器实现都是围绕着共同的基础行为,比如等待队列.条件队列.独占获取.共享获取等,而这些行为的抽象就是基于AbstractQueu ...
- P7962 [NOIP2021] 方差 (DP)
题目的意思就是可以交换差分数组,对答案进行化简:n∑ai2−(∑ai)2 ,再通过手玩分析可得最优解的差分数组一定是单谷(可以感性理解一下),因此我们将差分数组排序,依次加入,每次可以选择加在左边 ...
- IDEA生成带参数和返回值注释
步骤说明 打开IDEA进入点击左上角 - 文件 - 设置 - 编辑器 - 活动模板 新建活动模板 填写模板文本 编辑变量 添加变量表达式 设置模板使用范围-设置全部范围应用-或者设置只在Java代码中 ...
- 一篇文章带你了解热门版本控制系统——Git
一篇文章带你了解热门版本控制系统--Git 这篇文章会介绍到关于版本控制的相关知识以及版本控制神器Git 我们可能在生活中经常会使用GitHub网页去查询一些开源的资源或者项目,GitHub就是基于G ...
- dotnet 用 SourceGenerator 源代码生成技术实现中文编程语言
相信有很多伙伴都很喜欢自己造编程语言,在有现代的很多工具链的帮助下,实现一门编程语言,似乎已不是一件十分困难的事情.我利用 SourceGenerator 源代码生成技术实现了一个简易的中文编程语言, ...
- Linux实战笔记__Ubuntu20.04上搭建Vulhub漏洞环境
安装python3和pip3 安装docker 安装docker-compose 上传解压vulhub-master.zip 启动漏洞环境 进入某漏洞目录,执行docker-compose up -d ...
- LeetCode------两数之和(3)【数组】
来源:力扣(LeetCode) 链接:https://leetcode-cn.com/problems/two-sum 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 ...
- 3.pygame快速入门-游戏循环及动画实现
游戏循环的开始,意味着游戏的正式开始,游戏循环的作用如下 1.保证游戏不会直接退出 2.变化图像的位置--动画效果 3.检测用户交互--按键.鼠标等 游戏时钟 pyagame提供了一个pyga ...