windows上用vs2017静态编译onnxruntime-gpu CUDA cuDNN TensorRT的坎坷之路
因为工作业务需求的关系,需编译onnxruntime引入项目中使用,主项目exe是使用的vs2017+qt5.12。
onnxruntime就不用介绍是啥了撒,在优化和加速AI机器学习推理和训练这块赫赫有名就是了。
有现成的别人编译好的只有dll动态库,当然我们显然是不可能使用的,因为BOSS首先就提出一定要让发布出去的程序体积尽量变少,我肯定是无法精细的拆分哪一些用到了的,哪一些代码是没用到的,还多次强调同时执行效率当然也要杠杠滴。
所以下面就开始描述这几天一系列坎坷之路,留个记录,希望过久了自己不会忘记吧,如果能帮助到某些同行少走些弯路也最好:
1. Clone repo
诧一听你可能会觉得一个大名鼎鼎的Microsoft开源项目,又是在自家的Windows上编译应该很简单很容易吧?
的确我一开始也是这样认为的,犯了太藐视的心态来对待他。
一开始就使用git clone下来代码,分支先锁定在rel-1.13.1发行版上。
简单cmake跑了下,这些就省略,发现少了一些external里面的子项目的引用,
这当然难不倒我,简单,git --recursive 重新下载所有的submodules。
碍于网络情况,等待许久时间下载到一半就断了,后来给git设置了代理,下载完成。
2. CMake Configure
后来等待cmake跑先编译纯cpu的版本(不带gpu并行运算加速)。
具体表现在cmake上是设置 onnxruntime_USE_CUDA 、onnxruntime_USE_TENSORRT、onnxruntime_USE_ROCM 等等一系列环境变量设置 False。
现在都忘记中间的过程了,反正自己鼓弄后来发现这步骤,最好是使用他所提供的一个python脚本,内部去调用cmake生成项目。这个步骤在它onnxruntime的官方文档上有说。
大概就是用这个脚本项目根目录上的build.bat 去执行。
内部会调用 onnxruntime\tools\ci_build\build.py 去跑cmake,内部会用cmake Configure和Generate版本。
前提是很多参数需要提前设置好,比如说我是预先执行这一串命令:
set ZLIB_INCLUDE_DIR=D:\extlibs\zlib\build-msvc-static\install\include/
set ZLIB_LIBRARY=D:/extlibs/zlib/build-msvc-static/install/lib/
set ZLIB_LIBRARY_DEBUG=D:/extlibs/zlib/build-msvc-static/install/lib/zlibstaticd.lib
set ZLIB_LIBRARY_RELEASE=D:/extlibs/zlib/build-msvc-static/install/lib/zlibstatic.lib
set CUDA_HOME=F:\NVIDIA\CUDA\v11.6
set CUDNN_HOME=F:\NVIDIA\CUDNN\v8.5
set TENSORRT_HOME=F:\NVIDIA\TensorRT\v8.4.3.1
set HTTP_PROXY=http://127.0.0.1:10809 rem 你懂的
set HTTPS_PROXY=http://127.0.0.1:10809 rem 你懂的
然后执行:
build.bat --config RelWithDebInfo --skip_tests --parallel --cmake_generator "Visual Studio 15 2017"
中间肯定是不会一次成功的,相信我,后来再跑到cmake成功后,我用cmake-gui重新打开刚刚generate好的project,发现有不少环境变量需要调整,比如一些test不需要,一些unit_test不需要,所有shared_lib都改成static_lib,还有absl需要使用自己编译的,AVX2和AVX等CPU指令加速都开启来。当然这些只是小试牛刀,后面还有更多隐晦的参数需要改动。
3. 开始用vs2017编译
一切都生成sln解决方案文件之后,开始编译,大概等待了30分钟之后,发现编译错误: 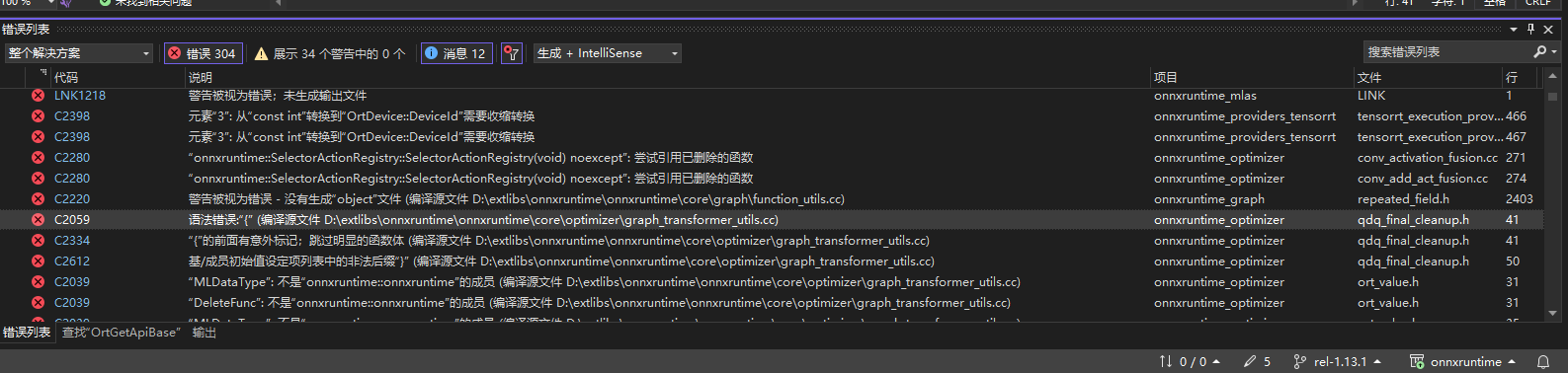
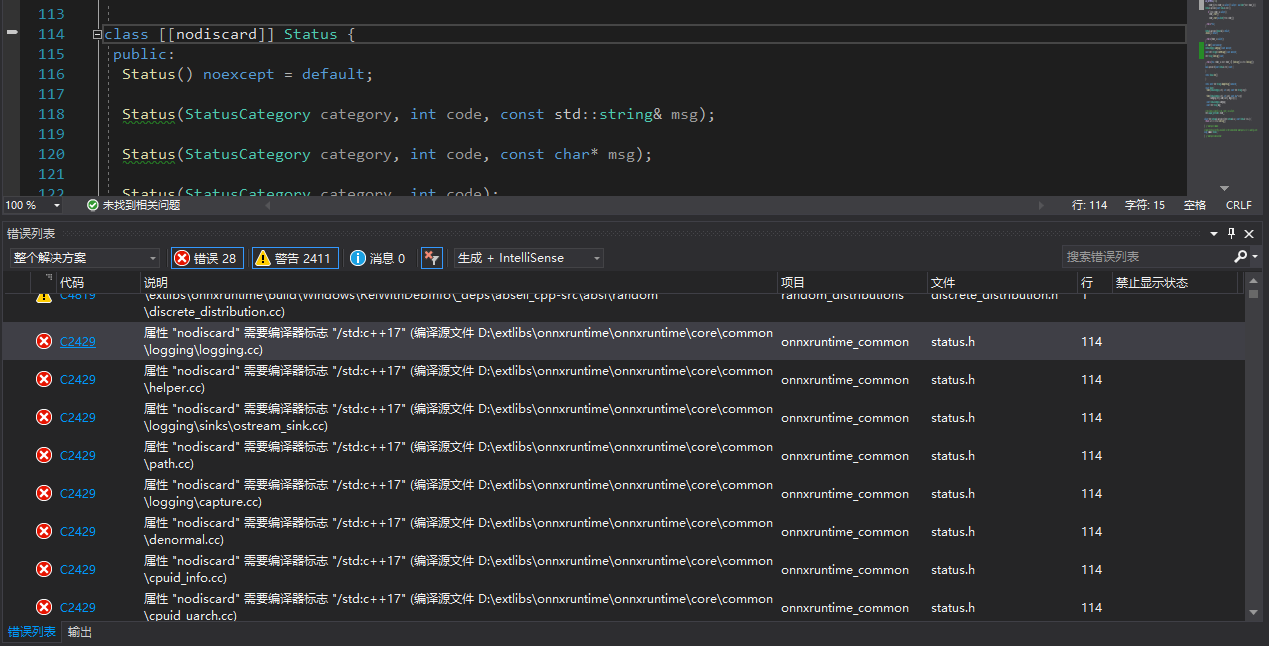
看了下报错这个地方代码,大概我判断是因为项目使用了一些 c++17 的新特性,但是编译器不认识,所以就报奇怪的{ }大括号错了,又有使用了nodiscard关键字,遂返回去CMake将这两个变量设置成如图所示:
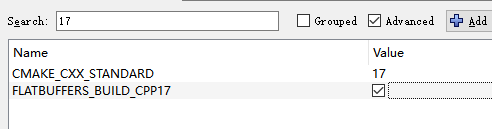
查了下vs2017是支持c++17的,满怀欣喜的喝了一口茶,回来看还是一样错误,后来就在折腾cppreference,和模拟onnxruntime项目上那种写法去(c++17的noexcept用法)测试,为什么vs2017上那样使用noexcept就会报错,用在线的gcc和clang都可以,在vs2017上就是不行,摆脱喂,c++17既然支持不完整,那就别说支持呀,最后直接放弃vs2017了。
后来不想折腾了,重新下载安装了vs2022,等待许久,还好公司网络还好,在线安装下载vs速度都是10MB/s左右跑满百兆,这里充分体现了网速对工作效率的重要性XD。
4. 改用vs2022编译cpu版本
vs2022安装好后,直接修改了下build.bat参数
build.bat --config RelWithDebInfo --skip_tests --parallel --cmake_generator "Visual Studio 17 2022"
然后重新走上面的流程,直接就很顺利的编译完了所有lib文件,竟很讶异,隐隐觉得事情绝对没有这么简单。
体积也还很小哦。
5. 加入CUDA + cuDNN + TensorRT环境
这里有一个坑,必须必须要按照文档所说的版本号去对照,不能什么都去直接装最新版!
打个比方如果你打算编译的是onnxruntime 1.13.1
那么能够与之搭配的TensorRT版本就是8.4.*.*,
TensorRT又依赖的cuDNN版本是8.5.0.96 和 CUDA 11.4,如果你安装的是CUDA10或者CUDA12,那么将会在CUDA编译的时候报错各种函数找不到!
ONNX Runtime TensorRT CUDA版本对应表:
https://onnxruntime.ai/docs/execution-providers/TensorRT-ExecutionProvider.html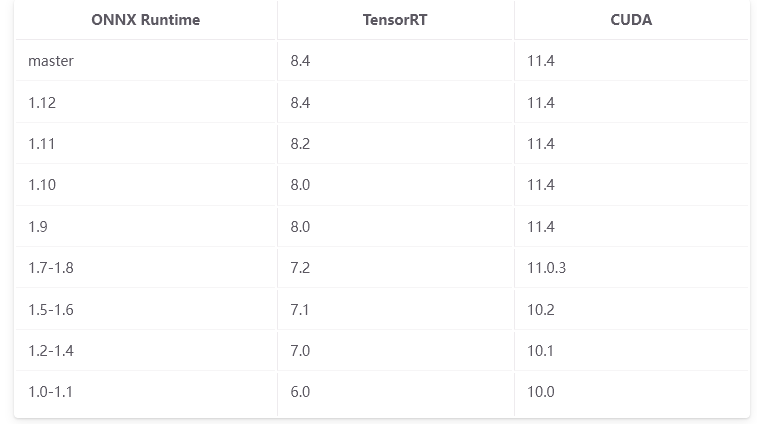
ONNX Runtime CUDA cuDNN版本对应表:
https://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.html#requirements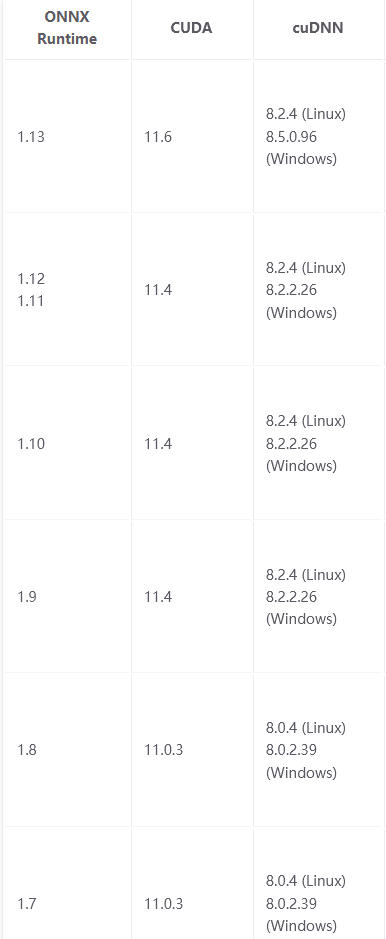
TensorRT components版本对应表:
https://docs.nvidia.com/deeplearning/tensorrt/archives/tensorrt-843/install-guide/index.html
这里放出我当初记录的下载地址:
CUDA各版本下载地址:
https://developer.nvidia.com/cuda-toolkit-archive
cuDNN各版本下载地址:
https://developer.nvidia.com/rdp/cudnn-archive
TensortRT各版本下载地址:
https://developer.nvidia.com/nvidia-tensorrt-download
TensorRT依赖库版本对应表:
https://docs.nvidia.com/deeplearning/tensorrt/release-notes/tensorrt-8.html#rel-8-4-3
TensortRT文档手册:
https://docs.nvidia.com/deeplearning/tensorrt/archives/index.html#trt_8
cuDNN安装教程:
https://docs.nvidia.com/deeplearning/cudnn/install-guide/index.html#installdriver-windows
TensortRT安装教程:
https://docs.nvidia.com/deeplearning/tensorrt/install-guide/index.html#installing-zip
下载之后 最后分别按照顺序(先CUDA、再CUDNN,最后TensorRT)安装解压到磁盘上。
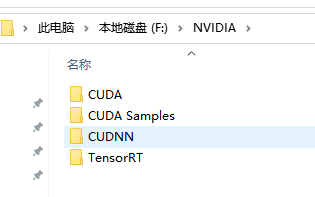
最后设置环境变量
CUDA_HOME=F:\NVIDIA\CUDA\v11.6
CUDA_PATH=F:\NVIDIA\CUDA\v11.6
CUDA_PATH_V11_6=F:\NVIDIA\CUDA\v11.6
CUDNN_HOME=F:\NVIDIA\CUDNN\v8.5
TENSORRT_HOME=F:\NVIDIA\TensorRT\v8.4.3.1
PATH+=F:\NVIDIA\CUDA\v11.6\bin
PATH+=F:\NVIDIA\CUDA\v11.6\libnvvp
PATH+=F:\NVIDIA\CUDNN\v8.5\bin
PATH+=F:\NVIDIA\TensorRT\v8.4.3.1\lib
然后勾上CMake上的这三个变量,再重新generate
onnxruntime_USE_CUDA
onnxruntime_USE_TENSORRT
onnxruntime_USE_TENSORRT_BUILTIN_PARSER
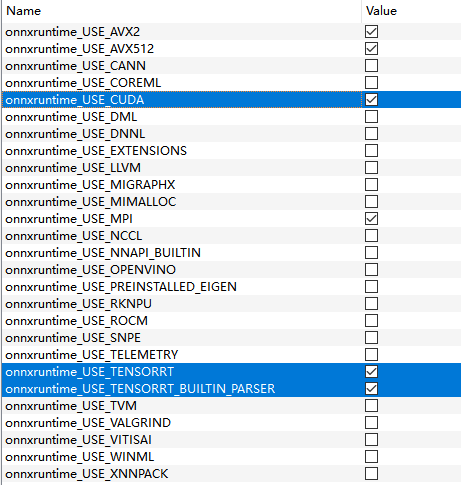
其中ROCm和MiGraphX、oneDNN和OpenVINO应该也类似,我没去试。
另外放出所有onnxruntime C++它支持的硬件加速库有这些:
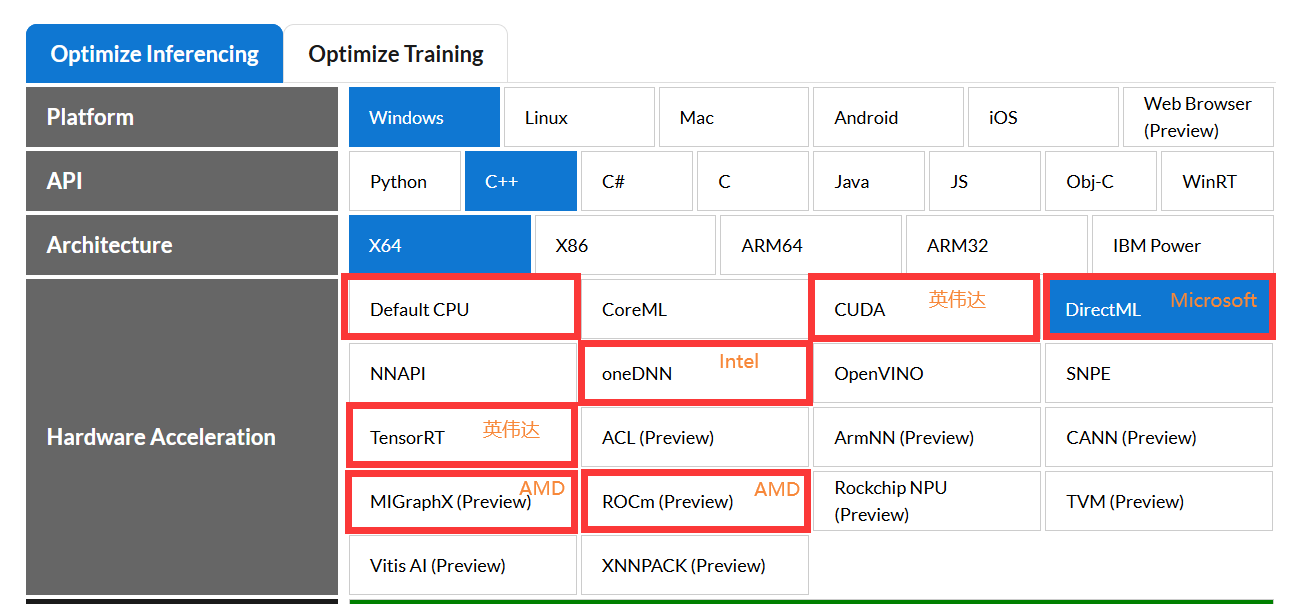
CoreML(Apple Machine Learning framework)
cuDNN(NVIDIA CUDA(Compute Unified Device Architecture) Deep Neural Network Library)
Direct ML(Microsoft DirectX 12 library for machine learning)
NNAPI(Android Neural Networks API)
oneDNN(Intel oneAPI Deep Neural Network Library)
OpenVINO(Open Visual Inference and Neural network Optimization)
SNPE(Qualcomm Snapdragon Neural Processing Engine SDK)
TensorRT(NVIDIA Machine Learning framework)
ACL(Arm Compute Library)
ArmNN(machine learning inference engine for Android and Linux)
CANN(HuaWei Compute Architecture for Neural Networks)
MIGraphX(AMD's graph inference engine that accelerates machine learning model inference)
ROCm(AMD's Open Software Platform for GPU Compute)
6. 测试项目中去链接静态库
将lib文件拷贝过去qt写的demo,pro上引入lib文件和include文件。
pro加入c++17的支持:CONFIG += c++17
加入:
#Dbghelp.lib
LIBS += -lDbghelp
#Advapi32.lib
LIBS += -lAdvapi32
这些全部配好之后,以编译demo项目,报LNK2001链接错误,如图所示:
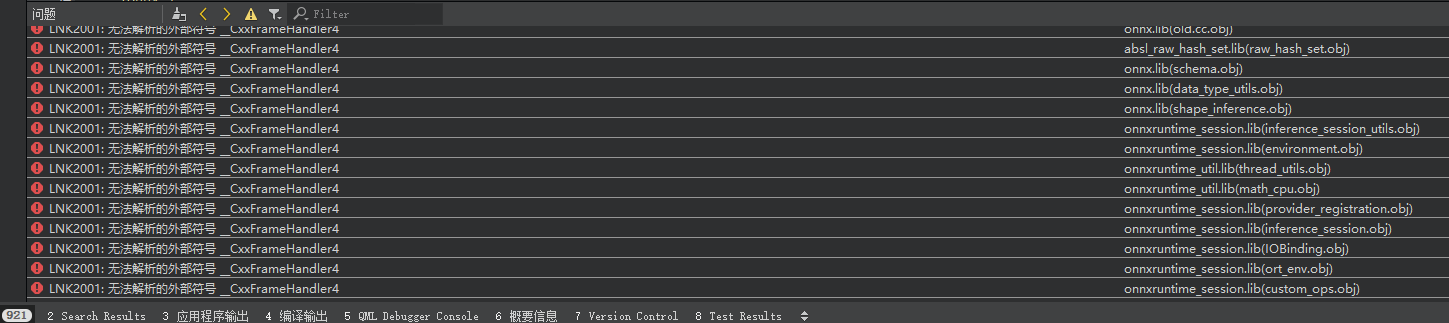
Google查了下这个错误是因为 Modi Mo 这家伙干的,从2019年之后有一个vcrt新特性,c++的exception在x64 runtime下的libraries文件结构进行了调整,可以节约了exe大量体积。
详见:https://devblogs.microsoft.com/cppblog/making-cpp-exception-handling-smaller-x64/
所以我使用vs2022编译的lib文件,在vs2017的exe中去引用,会报 __CxxFrameHandler4 不兼容的错误。
在这篇blog下,还不乏各种因为失去兼容性而带来的抱怨之声,更多的是问如果关闭这个特性。
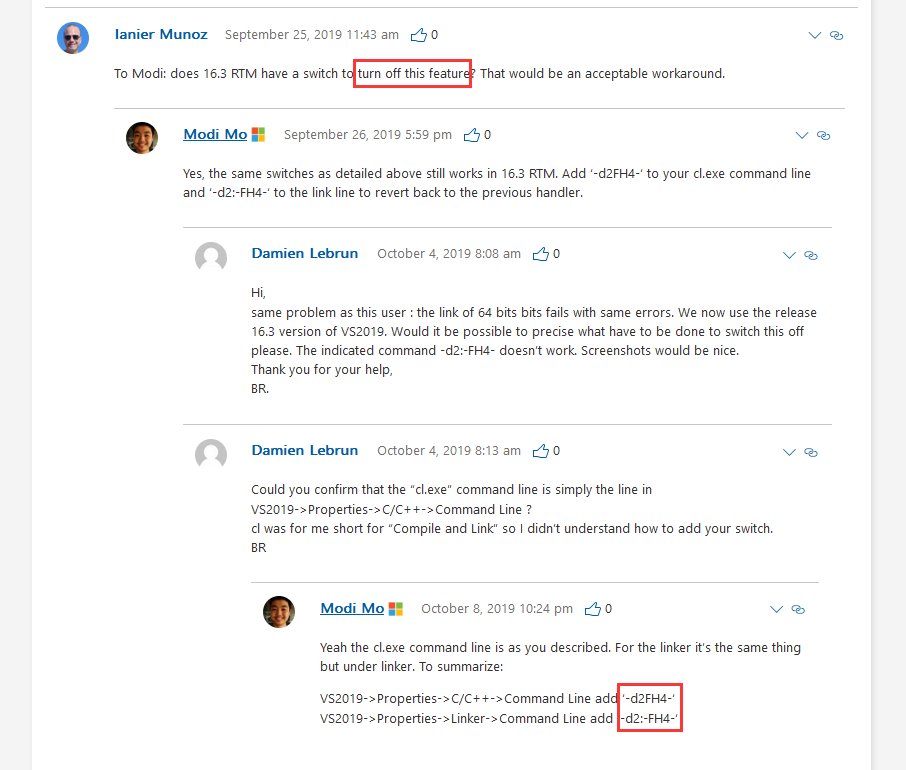
按照他的方法,我在CMake中将CMAKE_CXX_FLAGS 末尾加上 -d2FH4-
以及在CMake的 LINKER_FLAGS相关的几个末尾加上 -d2:-FH4-
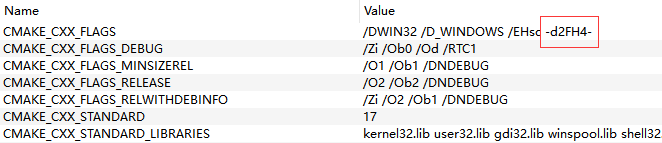
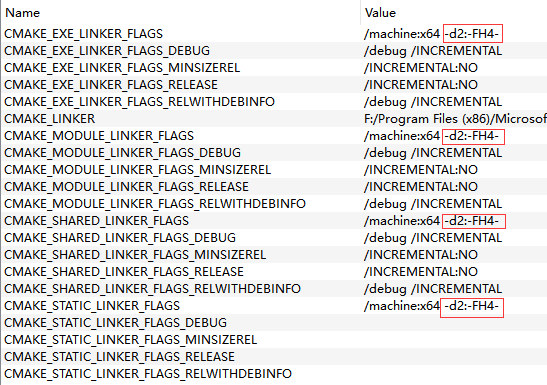
设置了这个标志之后再重新编译,再重新copy到demo项目中去引用,就没报__CxxFrameHandler4找不到符号的链接错误了。
只能库比程序vcrt版本低(向前兼容),但是不能反过来程序比库版本还低
但是又变成报另外一种奇奇怪怪的链接错误,如下图所示:
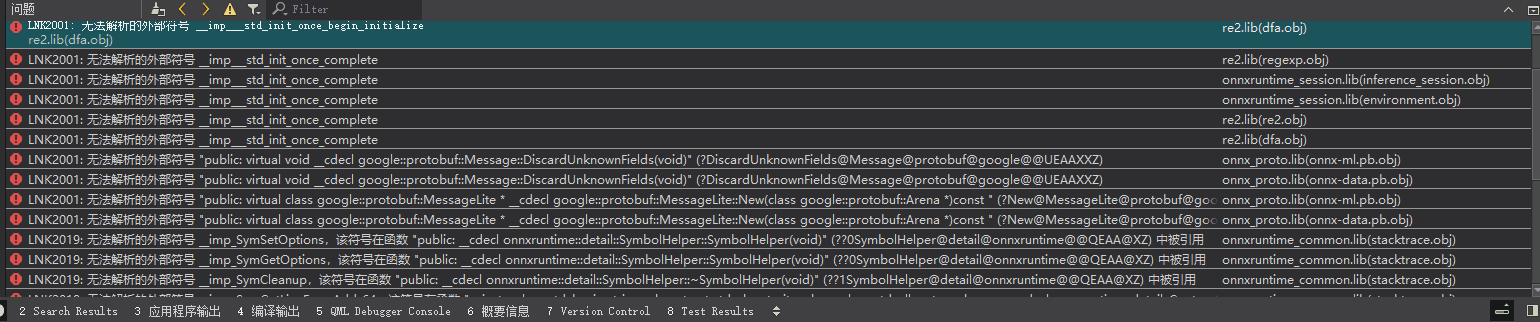
7. 改用vs2019编译
查了下上面的 __imp__std_init_once_complete的错误原因,网上基本上说的就是因为vcrt版本不一致所导致的错误。
解决办法就只有统一使用同一种编译器进行编译,我简直要醉了。
我装个vs2019再改这两个编译flag试试吧,毕竟vs2022和vs2017间隔太远了,谁知道期间除了__CxxFrameHandler4还有别的什么二进制不兼容的问题。
漫长的下载安装等待中,结束之后,里面去使用vs2019重新走一遍之前的操作,居然一样,还是报跟2022一样的错误,看来vcrt2017到2019发生了重大更新呀。
那么我尝试将有报__imp__std_init_once_complete错误的项目更改他们的编译器(平台工具集),部分项目降级修改成Visual Studio 2017(v141),
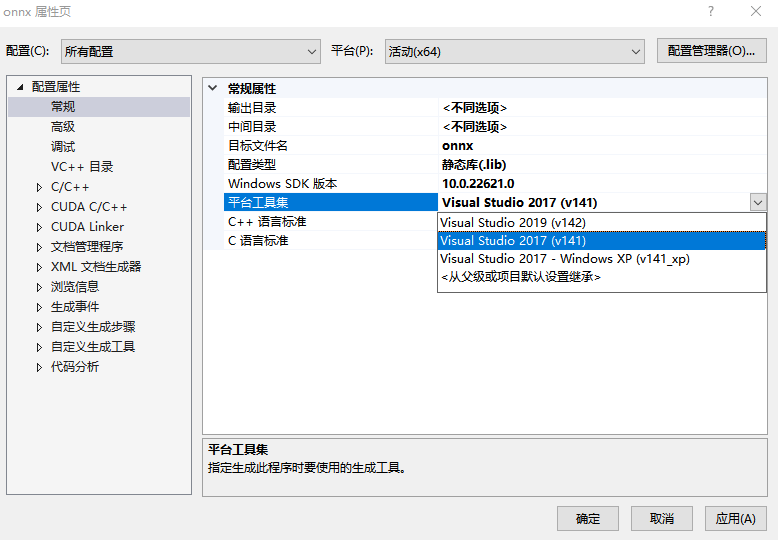
再尝试编译。
错误:LINK : error LNK1218: 警告被视为错误;未生成输出文件
警告:warning LNK4221: 此对象文件未定义任何之前未定义的公共符号,因此任何耗用此库的链接操作都不会使用此文件
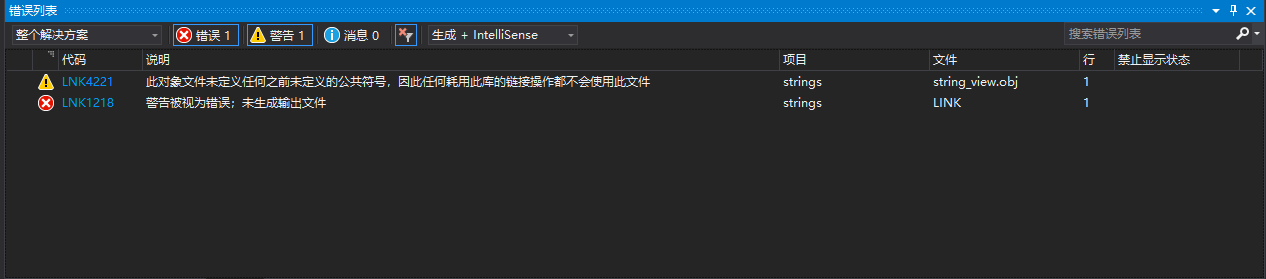
查了原因是因为,官方解释:
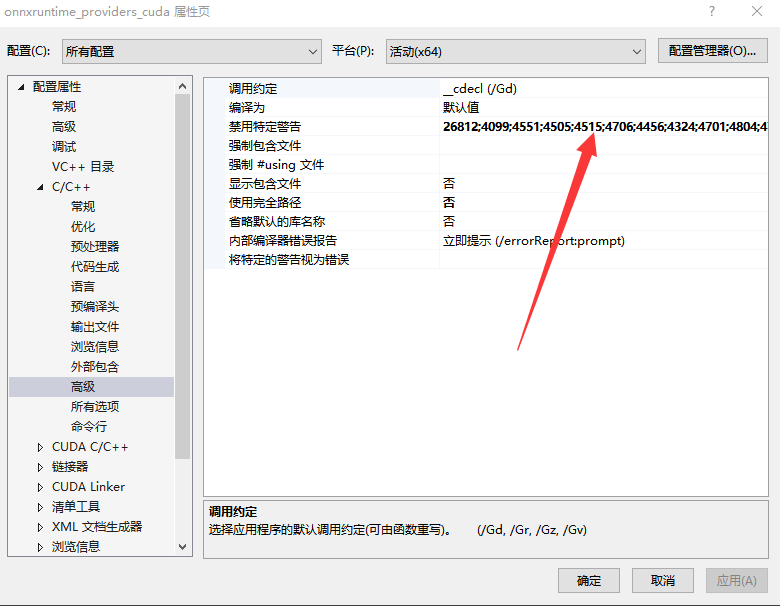
是因为vs2017比较严格一些?这个会报警告出来,查了下有两种解决方法,
一是将这个警告忽略,即在【配置属性】 【C/C++】 【高级设置】中将这个警告禁用掉:
第二种是去【配置属性】 【C/C++】 【常规】,有一个选项叫’将警告视为错误‘,将其设置成【否】。
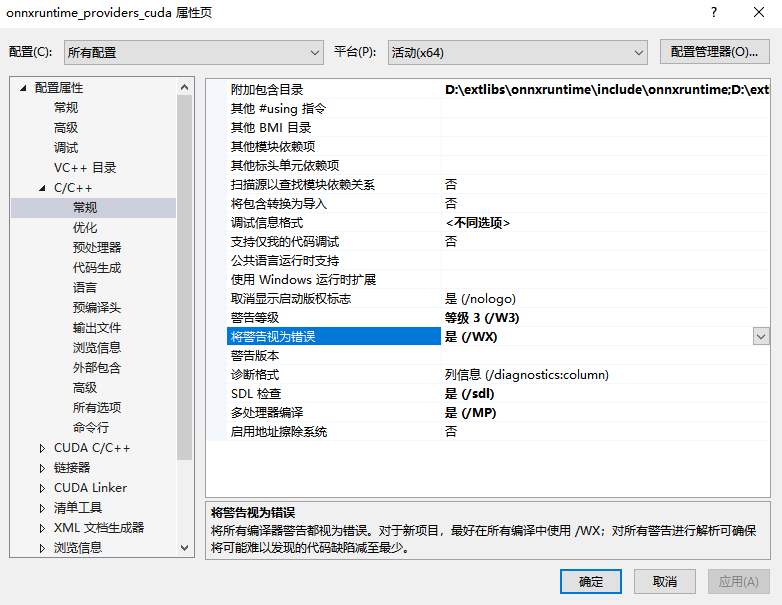
但是我按照这样操作一波,仍然不行,重启了vs也不行,难道这是遇到vc的bug了?仔细看错误信息发现就是那个cpuid_uarch.cc和string_view.cc文件有问题,阅读了下代码,发现是有一个宏,只在arm环境下会编译,在win下应该不会产生任何函数和类的实现体,相当于是一个空的namespace而已。
我修改它这个文件,把它的#ifdef 从namespace里面移到上一级namespace外面来,就解决这个问题了。
这样就还剩下只有protobuf的库的静态链接没有解决。

onnx_proto.lib(onnx-ml.pb.obj) : error LNK2001: 无法解析的外部符号 "public: virtual class google::protobuf::MessageLite * __cdecl google::protobuf::MessageLite::New(class google::protobuf::Arena *)const " (?New@MessageLite@protobuf@google@@UEBAPEAV123@PEAVArena@23@@Z)
onnx_proto.lib(onnx-data.pb.obj) : error LNK2001: 无法解析的外部符号 "public: virtual class google::protobuf::MessageLite * __cdecl google::protobuf::MessageLite::New(class google::protobuf::Arena *)const " (?New@MessageLite@protobuf@google@@UEBAPEAV123@PEAVArena@23@@Z)
onnx_proto.lib(onnx-ml.pb.obj) : error LNK2001: 无法解析的外部符号 "public: virtual void __cdecl google::protobuf::Message::DiscardUnknownFields(void)" (?DiscardUnknownFields@Message@protobuf@google@@UEAAXXZ)
onnx_proto.lib(onnx-data.pb.obj) : error LNK2001: 无法解析的外部符号 "public: virtual void __cdecl google::protobuf::Message::DiscardUnknownFields(void)" (?DiscardUnknownFields@Message@protobuf@google@@UEAAXXZ)
debug\videoonnxdemo.exe : fatal error LNK1120: 2 个无法解析的外部命令
看了下项目的CMakeLists里面似乎有个注释
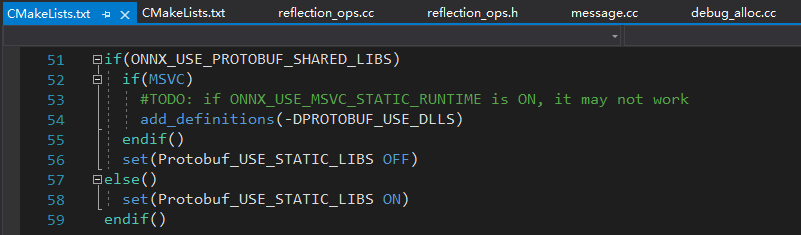
还有一段话:The onnxruntime_PREFER_SYSTEM_LIB is mainly designed for package managers like apt/yum/vcpkg.
Please note, by default Protobuf_USE_STATIC_LIBS is OFF but it's recommended to turn it ON on Windows. You should set it properly when onnxruntime_PREFER_SYSTEM_LIB is ON otherwise you'll hit linkage errors.
If you have already installed protobuf(or the others) in your system at the default system paths(like /usr/include), then it's better to set onnxruntime_PREFER_SYSTEM_LIB ON. Otherwise onnxruntime may see two different protobuf versions and we won't know which one will be used, the worst case could be onnxruntime picked up header files from one of them but the binaries from the other one.
机翻译过来就是onnxruntime_PREFER_SYSTEM_LIB 主要是为像 apt/yum/vcpkg 这样的包管理器设计的。
请注意,默认情况下 Protobuf_USE_STATIC_LIBS 是关闭的,但建议在 Windows 上将其打开。 当 onnxruntime_PREFER_SYSTEM_LIB 为 ON 时,您应该正确设置它,否则您会遇到链接错误。
如果您已经在系统中的默认系统路径(如 /usr/include)安装了 protobuf(或其他),那么最好将 onnxruntime_PREFER_SYSTEM_LIB 设置为 ON。 否则 onnxruntime 可能会看到两个不同的 protobuf 版本,我们不知道将使用哪个版本,最坏的情况可能是 onnxruntime 从其中一个获取头文件,但从另一个获取二进制文件。
发现虽然没有开启onnxruntime的 ONNX_USE_LITE_PROTO选项,
ONNX_USE_LITE_PROTO选项,
但是链接的libprotobuf仍然会引用到几个lite相关的函数,所以有此链接错误。
因此手动打开\external\protobuf\cmake\protobuf.sln,进行手动编译。
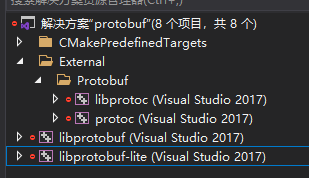
很顺利就编译成功,最终生成lite相关的lib文件:
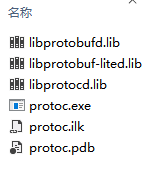
最后大功告成,demo链接错误完全不报了。
这时候看到 error 0, warning 0 有一种异样到无以言表的感觉。
全篇完结。
windows上用vs2017静态编译onnxruntime-gpu CUDA cuDNN TensorRT的坎坷之路的更多相关文章
- 在Windows下使用MinGW静态编译Assimp
使用MinGW静态编译Assimp 到了5月份了,没有写一篇日志,于是自己从知识库里面拿出一篇文章充数吧.这次将要解说怎样在Windows下使用MinGW静态编译Assimp. Assimp是眼下比較 ...
- 在Windows通过使用MinGW静态编译Assimp
使用MinGW静态编译Assimp 到了5月份了.没有写一篇日志,于是自己从知识库里面拿出一篇文章充数吧.这次将要解说怎样在Windows下使用MinGW静态编译Assimp. Assimp是眼下比較 ...
- 真实机下 ubuntu 18.04 安装GPU +CUDA+cuDNN 以及其版本选择(亲测非常实用)【转】
本文转载自:https://blog.csdn.net/u010801439/article/details/80483036 ubuntu 18.04 安装GPU +CUDA+cuDNN : 目前, ...
- Qt5.10.1 在windows下vs2017静态编译
1.在计算机上安装python库和perl库(因为后续的静态编译需要用到这两种语言),可以在命令行敲击“python”和“perl -v”检查是否安装成功. 2.修改msvc-desktop.conf ...
- Linux 上GCC的静态编译和动态编译
静态编译 常规编译示例: $gcc xxx.c yyy.c zzz.c -o rslt 注明: gcc编译器会对源文件min.c进行预处理, 编译, 以及链接, 最后生成可执行文件 $gcc -c x ...
- 如何在Windows上从源码编译Chromium (CEF3) 加入mp3支持
一.什么是CEF CEF即Chromium Embeded Framework,由谷歌的开源浏览器项目Chromium扩展而来,可方便地嵌入其它程序中以得到浏览器功能. CEF包括CEF1和CEF3两 ...
- ubuntu16.04+caffe+GPU+cuda+cudnn安装教程
步骤简述: 1.安装GPU驱动(系统适配,不采取手动安装的方式) 2.安装依赖(cuda依赖库,caffe依赖) 3.安装cuda 4.安装cudnn(只是复制文件加链接,不需要编译安装的过程) 5. ...
- GPU,CUDA,cuDNN的理解
最近用到这方面的知识,感觉这篇文章写的很好,为了方便自己查阅,就搬运了过来,如果牵涉到侵权,请联系我,我会删除该博文!!! 我们知道做深度学习离不开GPU,不过一直以来对GPU和CPU的差别,CUDA ...
- TensorFlow在Windows上的CPU版本和GPU版本的安装指南(亲测有效)
安装说明 平台:Window.Ubuntu.Mac等操作系统 版本:支持GPU版本和CPU版本 安装方式:pip方式.Anaconda方式 attention: 在Windows上目前支持python ...
- Qt5.5.0在Windows下静态编译(修改参数以后才能支持XP)good
测试系统环境: windows 7 编译软件环境: vs2013 + QT5.5.0 [源码地址:http://download.qt.io/official_releases/qt/5.5/5.5. ...
随机推荐
- CentOS使用yum方式安装yarn和nodejs
# 使用epel-release.repo源安装的nodejs版本是6.17.1,有些前端项目使用的话会提示版本太低,具体下图 # 命令执行后的详细情况:curl -sL https://rpm.no ...
- Linux Hardening Guide
文章转载自:https://madaidans-insecurities.github.io/guides/linux-hardening.html 1. Choosing the right Lin ...
- Alertmanager篇
报一直是整个监控系统中的重要组成部分,Prometheus监控系统中,采集与警报是分离的.警报规则在 Prometheus 定义,警报规则触发以后,才会将信息转发到给独立的组件 Alertmanage ...
- css文字超出后显示...
多行 overflow: hidden; //超出的文本隐藏 text-overflow: ellipsis; //溢出用省略号显示 display: -webkit-box; -webkit-lin ...
- Java之POI导出Excel(二):多个sheet
相信在大部分的web项目中都会有导出导入Excel的需求,之前我也写过一篇导出单个sheet工作表的文章,没看过的小伙伴可以去看哈,链接也给大家放出来了:导出单个sheet 但是在我们日常的工作中,需 ...
- 关于aws-Global区的新账户的一些限制坑点
在使用global-aws的时候,遇到几个限制坑点记录如下(都是需要发请求找aws服务支持才能提高) 1.关于Elastic IPs的限制,默认为 5,这样在ec2下的Elastic IPs中最多只能 ...
- 洛谷P1719 最大加权矩形 (DP/二维前缀和)
题目描述也没啥好说的,就是给你个你n*n的矩形(带权),求其中最大权值的子矩阵. 首先比较好想的就是二维前缀和,n<=120,所以可以用暴力. 1 #include<bits/stdc++ ...
- Java学生管理系统(详解)
相信大部分人都有接触过这个 Java 小项目--学生管理系统,下面会分享我在做这个项目时的一些方法以及程序代码供大家参考(最后附上完整的项目代码). 首本人只是个初学Java的小白,可能项目中有许多地 ...
- 为了讲明白继承和super、this关键字,群主发了20块钱群红包
摘要:以群主发红包为例,带你深入了解继承和super.this关键字. 本文分享自华为云社区<群主发红包带你深入了解继承和super.this关键字>,作者:共饮一杯无 . 需求 群主发随 ...
- VSCode设置鼠标滚轮滑动设置字体大小
1. 打开"文件->首选项->设置 2. 打开settings.json文件 3. 在setting.json 中添加"editor.mouseWheelZoom&qu ...