万字长文,带你轻松学习 Spark
大家好,我是大D。
今天给大家分享一篇 Spark 核心知识点的梳理,对知识点的讲解秉承着能用图解的就不照本宣科地陈述,力求精简、通俗易懂。希望能为新手的入门学习扫清障碍,从基础概念入手、再到原理深入,由浅入深地轻松掌握 Spark。
1、初识 Spark
Spark不仅能够在内存中进行高效运算,还是一个大一统的软件栈,可以适用于各种各样原本需要多种不同的分布式平台的场景。
背景
Spark作为一个用来快速实现大规模数据计算的通用分布式大数据计算引擎,是大数据开发工程师必备的一项技术栈。Spark相对Hadoop具有较大优势,但Spark并不能完全替代Hadoop。实际上,Spark已经很好地融入了Hadoop家族,作为其中一员,主要用于替代Hadoop中的MapReduce计算模型。
Spark的优势
Spark拥有Hadoop MapReduce所具备的优点,但不同的是,Hadoop每次经过job执行的中间结果都会存储在HDFS上,而Spark执行job的中间过程数据可以直接保存在内存中,无需读写到HDFS磁盘上。因为内存的读写速度与磁盘的读写速度不在一个数量级上,所以Spark利用内存中的数据可以更快地完成数据的计算处理。
此外,由于Spark在内部使用了弹性分布式数据集(Resilient Distributed Dataset,RDD),经过了数据模型的优化,即便在磁盘上进行分布式计算,其计算性能也是高于Hadoop MapReduce的。
Spark的特点
- 计算速度快
Spark将处理的每个任务都构造出一个有向无环图(Directed Acyclic Graph,DAG)来执行,实现原理是基于RDD在内存中对数据进行迭代计算的,因此计算速度很快。官方数据表明,如果计算数据是从磁盘中读取,Spark计算速度是Hadoop的10倍以上;如果计算数据是从内存中读取,Spark计算速度则是Hadoop的100倍以上。 - 易于使用
Spark提供了80多个高级运算操作,支持丰富的算子。开发人员只需调用Spark封装好的API来实现即可,无需关注Spark的底层架构。 - 通用大数据框架
大数据处理的传统方案需要维护多个平台,比如,离线任务是放在Hadoop MapRedue上运行,实时流计算任务是放在Storm上运行。而Spark则提供了一站式整体解决方案,可以将即时查询、离线计算、实时流计算等多种开发库无缝组合使用。 - 支持多种资源管理器
Spark支持多种运行模式,比如Local、Standalone、YARN、Mesos、AWS等部署模式。用户可以根据现有的大数据平台灵活地选择运行模式。 - Spark生态圈丰富
Spark不仅支持多种资源管理器调度job,也支持HDFS、HBase等多种持久化层读取数据,来完成基于不同组件实现的应用程序计算。目前,Spark生态圈已经从大数据计算和数据挖掘扩展到机器学习、NLP、语音识别等领域。
2、Spark 的模块组成
Spark 是包含多个紧密集成的组件,这些组件结合密切并且可以相互调用,这样我们可以像在平常软件项目中使用程序库一样,组合使用这些的组件。
Spark的各个组成模块如下: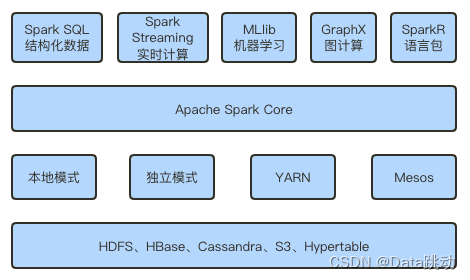
- Spark 基于 Spark Core 建立了 Spark SQL、Spark Streaming、MLlib、GraphX、SparkR等核心组件;
- 基于这些不同组件又可以实现不同的计算任务;
- 这些计算任务的运行模式有:本地模式、独立模式、YARN、Mesos等;
- Spark任务的计算可以从HDFS、HBase、Cassandra等多种数据源中存取数据。
Spark Core
Spark Core实现了Spark基本的核心功能,如下:
基础设施
SparkConf :用于定义Spark应用程序的配置信息;
SparkContext :为Spark应用程序的入口,隐藏了底层逻辑,开发人员只需使用其提供的API就可以完成应用程序的提交与执行;
SparkRPC :Spark组件之间的网络通信依赖于基于Netty实现的Spark RPC框架;
SparkEnv :为Spark的执行环境,其内部封装了很多Spark运行所需要的基础环境组件;
ListenerBus :为事件总线,主要用于SparkContext内部各组件之间的事件交互;
MetricsSystem :为度量系统,用于整个Spark集群中各个组件状态的监控;存储系统
用于管理Spark运行过程中依赖的数据的存储方式和存储位置,Spark的存储系统首先考虑在各个节点的内存中存储数据,当内存不足时会将数据存储到磁盘上,并且内存存储空间和执行存储空间之间的边界也可以灵活控制。调度系统
DAGScheduler :负责创建job、将DAG中的RDD划分到不同Stage中、为Stage创建对应的Task、批量提交Task等;
TaskScheduler :负责按照FIFO和FAIR等调度算法对Task进行批量调度;计算引擎
主要由内存管理器、任务管理器、Task、Shuffle管理器等组成。
Spark SQL
Spark SQL 是 Spark 用来操作结构化数据的程序包,支持使用 SQL 或者 Hive SQL 或者与传统的RDD编程的数据操作结合的方式来查询数据,使得分布式数据的处理变得更加简单。
Spark Streaming
Spark Streaming 提供了对实时数据进行流式计算的API,支持Kafka、Flume、TCP等多种流式数据源。此外,还提供了基于时间窗口的批量流操作,用于对一定时间周期内的流数据执行批量处理。
MLlib
Spark MLlib 作为一个提供常见机器学习(ML)功能的程序库,包括分类、回归、聚类等多种机器学习算法的实现,其简单易用的 API 接口降低了机器学习的门槛。
GraphX
GraphX 用于分布式图计算,比如可以用来操作社交网络的朋友关系图,能够通过其提供的 API 快速解决图计算中的常见问题。
SparkR
SparkR 是一个R语言包,提供了轻量级的基于 R 语言使用 Spark 的方式,使得基于 R 语言能够更方便地处理大规模的数据集。
3、Spark 的运行原理
Spark 是包含多个紧密集成的组件,这些组件结合密切并且可以相互调用,这样我们可以像在平常软件项目中使用程序库一样,组合使用这些的组件。
Spark的运行模式
就底层而言,Spark 设计为可以高效地在一个到数千个计算节点之间伸缩计算。为了实现这样的要求,同时获得最大灵活性,Spark支持在各种集群管理器上运行。
Spark 的运行模式主要有:
- Local 模式 :学习测试使用,分为 Local 单线程和 Local-Cluster 多线程两种方式;
- Standalone 模式 :学习测试使用,在 Spark 自己的资源调度管理框架上运行;
- ON YARN :生产环境使用,在 YARN 资源管理器框架上运行,由 YARN 负责资源管理,Spark 负责任务调度和计算;
- ON Mesos :生产环境使用,在 Mesos 资源管理器框架上运行,由 Mesos 负责资源管理,Spark 负责任务调度和计算;
- On Cloud :运行在 AWS、阿里云、华为云等环境。
Spark的集群架构
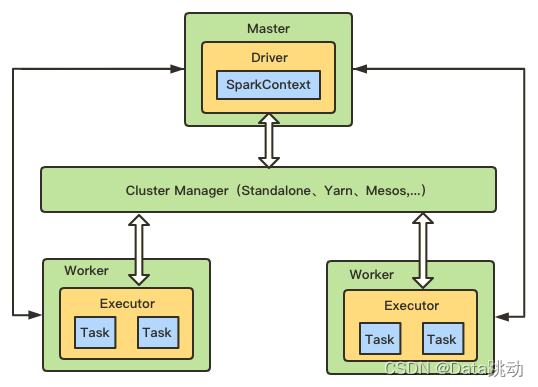
Spark 的集群架构主要由 Cluster Manager(资源管理器)、Worker (工作节点)、Executor(执行器)、Driver(驱动器)、Application(应用程序) 5部分组成,如下图: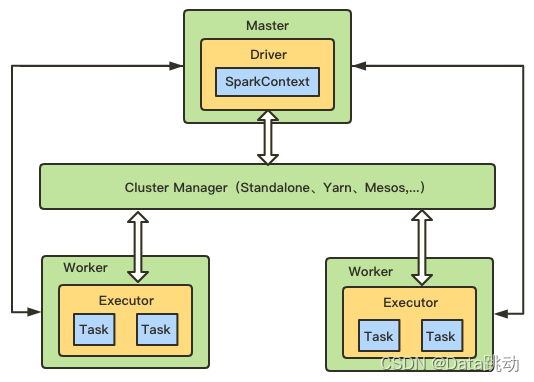
- Cluster Manager :Spark 集群管理器,主要用于整个集群资源的管理和分配,有多种部署和运行模式;
- Worker :Spark 的工作节点,用于执行提交的任务;
- Executor :真正执行计算任务的一个进程,负责 Task 的运行并且将运行的结果数据保存到内存或磁盘上;
- Driver :Application 的驱动程序,可以理解为驱动程序运行中的 main() 函数,Driver 在运行过程中会创建 Spark Context;
- Application :基于 Spark API 编写的应用程序,包括实现 Driver 功能的代码和在集群中多个节点上运行的 Executor 代码。
Worker 的工作职责
- 通过注册机制向 Cluster Manager汇报自身的 CPU 和内存等资源使用信息;
- 在 Master 的指示下,创建并启动 Executor(真正的计算单元);
- 将资源和任务进一步分配给 Executor 并运行;
- 同步资源信息和 Executor 状态信息给 Cluster Manager。
Driver 的工作职责
Application 通过 Driver 与 Cluster Manager 和 Executor 进行通信。
- 运行 Application 的 main() 函数;
- 创建 SparkContext;
- 划分 RDD 并生成 DAG;
- 构建 Job 并将每个 Job 都拆分为多个 Stage,每个 Stage 由多个 Task 构成,也被称为 Task Set;
- 与 Spark 中的其他组件进行资源协调;
- 生成并发送 Task 到 Executor。
4、RDD 概念及核心结构
本节将介绍 Spark 中一个抽象的概念——RDD,要学习 Spark 就必须对 RDD 有一个清晰的认知,RDD是 Spark 中最基本的数据抽象,代表一个不可变、可分区、元素可并行计算的集合。
RDD的概念
RRD全称叫做弹性分布式数据集(Resilient Distributed Dataset),从它的名字中可以拆解出三个概念。
- Resilient :弹性的,包括存储和计算两个方面。RDD 中的数据可以保存在内存中,也可以保存在磁盘中。RDD 具有自动容错的特点,可以根据血缘重建丢失或者计算失败的数据;
- Distributed :RDD 的元素是分布式存储的,并且用于分布式计算;
- Dataset : 本质上还是一个存放元素的数据集。
RDD的特点
RDD 具有自动容错、位置感知性调度以及可伸缩等特点,并且允许用户在执行多个查询时,显式地将数据集缓存在内存中,后续查询能够重用该数据集,这极大地提升了查询效率。
下面是源码中对RDD类介绍的注释:
Internally, each RDD is characterized by five main properties:
- A list of partitions
- A function for computing each split
- A list of dependencies on other RDDs
- Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
- Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)
- 一组分区(Partition)的列表,其中分区也就是RDD的基本组成单位;
- 一个函数会被作用到每个分区上,RDD 的计算是以分区为单位的;
- 一个 RDD 会依赖其他多个 RDD,它们之间具有依赖关系;
- 可选,对于K-V型的RDD会有一个分区函数,控制key分到哪个reduce;
- 一个存储每个分区优先位置的列表。
从源码对 RDD 的定义中,可以看出 RDD 不仅能表示存有多个元素的数据集,而且还能通过依赖关系推算出这个数据集是从哪来的,在哪里计算更合适。
RDD的核心结构
在学习 RDD 转换操作算子之前,根据 RDD 的特点对 RDD 中的核心结构进行一下梳理,这样对 Spark 的执行原理会有一个更深的理解。
分区(Partition)
RDD 内部的数据集在逻辑上和物理上都被划分为了多个分区(Partition),每一个分区中的数据都可以在单独的任务中被执行,这样分区数量就决定了计算的并行度。如果在计算中没有指定 RDD 中的分区数,那么 Spark 默认的分区数就是为 Applicaton 运行分配到的 CPU 核数。分区函数(Partitioner)
分区函数不但决定了 RDD 本身的分区数量,也决定了其父 RDD (即上一个衍生它的RDD)Shuffle 输出时的分区数量。Spark 实现了基于 HashPartitioner 的和基于 RangePartitoner 的两种分区函数。
需要特别说明的是,只有对 K-V 类型的 RDD 才会有分区函数。依赖关系
RDD 表示只读的分区的数据集,如果对 RDD 中的数据进行改动,就只能通过转化操作,由一个或多个 RDD 计算得到一个新的 RDD,并且这些 RDD 之间存在着前后依赖关系,前面的称为父 RDD,后面的称为子 RDD。RDD 之间的依赖可分为宽依赖和窄依赖。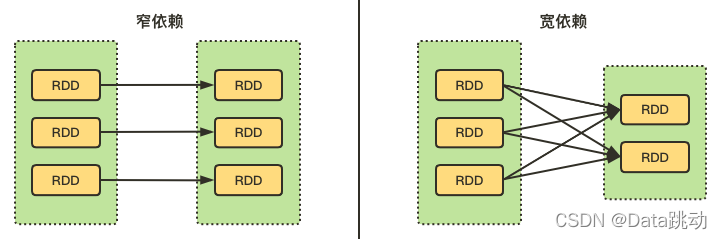
当计算过程中出现异常情况导致部分分区数据丢失时,Spark 可以通过这种依赖关系从父 RDD 中重新计算丢失的分区数据,而不需要对 RDD 中的所有分区全部重新计算。Stage
当 Spark 执行作业时,会根据 RDD 之间的依赖关系,按照宽窄依赖生成一个最优的执行计划。如果 RDD 之间为窄依赖,则会被划到一个 Stage 中;如果 RDD 之间为宽依赖,则会被划分到不同的 Stage 中,这样做的原因就是每个 Stage 内的 RDD 都尽可能在各个节点上并行地被执行,以提高运行效率。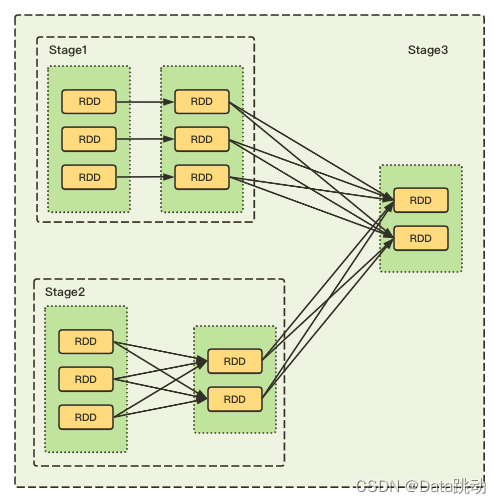
优先列表(PreferredLocation)
用于存储每个分区优先位置的列表,对于每个 HDFS 文件来说,就是保存下每个分区所在 block 的位置。按照“移动数据不如移动计算”的理念,Spark 在执行任务调度时会优先选择有存储数据的 Worker 节点进行任务运算。CheckPoint
CheckPoint 是 Spark 提供的一种基于快照的缓存机制,如果在任务运算中,多次使用同一个 RDD,可以将这个 RDD 进行缓存处理。这样,该 RDD 只有在第一次计算时会根据依赖关系得到分区数据,在后续使用到该 RDD 时,直接从缓存处取而不是重新进行计算。如下图,对 RDD-1 做快照缓存处理,那么当RDD-n 在用到 RDD-1 数据时,无需重新计算 RDD-1,而是直接从缓存处取数重算。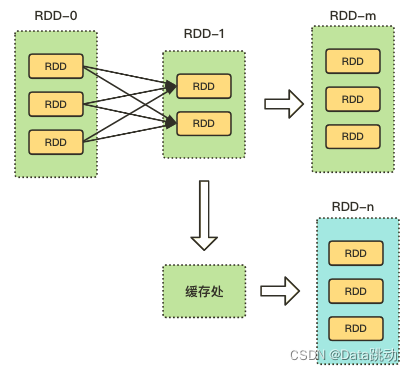
此外,Spark 还提供了另一种缓存机制 Cache,其中的数据是由 Executor 管理的,当 Executor 消失时,Cache 缓存的数据也将会消失。而 CheckPoint 是将数据保存到磁盘或者 HDFS 中的,当任务运行错误时,Job 会从 CheckPoint 缓存位置取数继续计算。
5、Spark RDD 的宽窄依赖关系
RDD的依赖关系
在 Spark 中,RDD 分区的数据不支持修改,是只读的。如果想更新 RDD 分区中的数据,那么只能对原有 RDD 进行转化操作,也就是在原来 RDD 基础上创建一个新的RDD。
那么,在整个任务的运算过程中,RDD 的每次转换都会生成一个新的 RDD,因此 RDD 们之间会产生前后依赖的关系。
说白了,就是相当于将对原始 RDD 分区数据的整个运算进行了拆解,当运算中出现异常情况导致分区数据丢失时,Spark 可以还通过依赖关系从上一个 RDD 中重新计算丢失的数据,而不是对最开始的 RDD 分区数据重新进行计算。
在 RDD 的依赖关系中,我们将上一个 RDD 称为父RDD,下一个 RDD 称为子RDD。
如何区分宽窄依赖
RDD 们之间的依赖关系,也分为宽依赖和窄依赖。
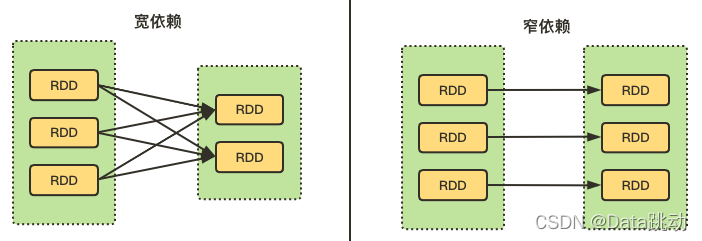
- 宽依赖 :父 RDD 中每个分区的数据都可以被子 RDD 的多个分区使用(涉及到了shuffle);
- 窄依赖 :父 RDD 中每个分区的数据最多只能被子 RDD 的一个分区使用。
说白了,就是看两个 RDD 的分区之间,是不是一对一的关系,若是则为窄依赖,反之则为宽依赖。
有个形象的比喻,如果父 RDD 中的一个分区有多个孩子(被多个分区依赖),也就是超生了,就为宽依赖;反之,如果只有一个孩子(只被一个分区依赖),那么就为窄依赖。
常见的宽窄依赖算子:
- 宽依赖的算子 :groupByKey、partitionBy、join(非hash-partitioned);
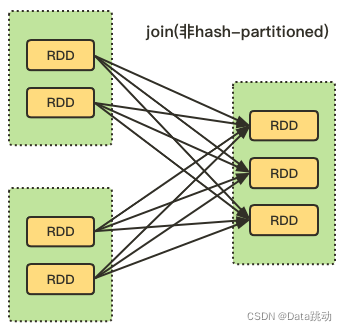
- 窄依赖的算子 :map、filter、union、join(hash-partitioned)、mapPartitions、mapValues;

为何设计要宽窄依赖
从上面的分析,不难看出,在窄依赖中子 RDD 的每个分区数据的生成操作都是可以并行执行的,而在宽依赖中需要所有父 RDD 的 Shuffle 结果完成后再被执行。
在 Spark 执行作业时,会按照 Stage 划分不同的 RDD,生成一个完整的最优执行计划,使每个 Stage 内的 RDD 都尽可能在各个节点上并行地被执行。
如下图,Stage3 包含 Stage1 和 Stage2,其中, Stage1 为窄依赖,Stage2 为宽依赖。
因此,划分宽窄依赖也是 Spark 优化执行计划的一个重要步骤,宽依赖是划分执行计划中 Stage 的依据,对于宽依赖必须要等到上一个 Stage 计算完成之后才能计算下一个阶段。
6、Spark RDD 的转换操作与行动操作
1. RDD 的创建
Spark 提供了两种创建 RDD 的方式:对一个集合进行并行化操作和利用外部数据集生成 RDD 。
对一个集合进行并行化操作
Spark 创建 RDD 最简单的方式就是把已经存在的集合传给 parallelize() 方法,不过,这种方式在开发中并不常用,毕竟需要将整个的数据集先放到一个节点内存中。
利用 parallelize() 方法将已经存在的一个集合转换为 RDD,集合中的数据也会被复制到 RDD 中并参与并行计算。
val lines = sc.parallelize(Arrays.asList(1,2,3,4,5),n)
其中,n 为并行集合的分区数量,Spark 将为集群的每个分区都运行一个任务。该参数设置太小不能很好地利用 CPU,设置太大又会导致任务阻塞等待,一般 Spark 会尝试根据集群的 CPU 核数自动设置分区数量。
利用外部数据集生成 RDD
在开发中,Spark 创建 RDD 最常用的一个方式就是从 Hadoop 或者其他外部存储系统创建 RDD,包括本地文件系统、HDFS、Cassandra、HBase、S3 等。
通过 SparkContext 的 textFile() 方法来读取文本文件创建 RDD 的代码,如下:
val lines = sc.textFile("../temp.txt")
其中,textFile() 方法的 url 参数可以是本地文件或路径、HDFS路径等,Spark 会读取该路径下所有的文件,并将其作为数据源加载到内存生成对应的 RDD。
当然, RDD 也可以在现有 RDD 的基础上经过算子转换生成新的 RDD,这是接下来要讲的RDD 算子转换的内容,Spark RDD 支持两种类型的操作:转换操作(Transformation) 和行动操作(Action)。
2. RDD 的转换操作
转换操作是指从现有 RDD 的基础上创建新的 RDD,是返回一个新 RDD 的操作。转换操作是惰性求值的,也就是不会立即触发执行实际的转换,而是先记录 RDD 之间的转换关系,只有当触发行动操作时才会真正地执行转换操作,并返回计算结果。
举个栗子,有一个日志文件 log.txt,需要从里面若干条信息中,筛选出其中错误的报警信息,我们可以用转化操作 filter() 即可完成,代码如下:
val inputRDD = sc.textFile("log.txt")
val errorsRDD = inputRDD.filter(line => line.contains("error"))
其中,textFile() 方法定义了名为 inputRDD 的RDD,但是此时 log.txt 文件并没有加载到内存中,仅仅是指向文件的位置。然后通过 filter() 方法进行筛选定义了名为 errorsRDD 的转换RDD,同样也属于惰性计算,并没有立即执行。
3. RDD 的行动操作
了解了如何通过转换操作从已有的 RDD 中创建一个新的 RDD,但有时我们希望可以对数据集进行实际的计算。行动操作就是接下来要讲的第二种 RDD 操作,它会强制执行那些求值必须用到的 RDD 的转换操作,并将最终的计算结果返回给 Driver 程序,或者写入到外部存储系统中。
继续刚才的栗子,我们需要将上一步统计出来的报警信息的数量打印出来,我们可以借助count() 方法进行计数。
val countRDD = errorsRDD.count()
其中,count() 可以触发实际的计算,强制执行前面步骤中的转换操作。实际上,Spark RDD 会将 RDD 计算分解到不同的 Stage 并在不同的节点上进行运算,每个节点都会运行 count() 结果,所有运算完成之后会聚合一个结果返回给 Driver 程序。
如果分不清楚给定的一个 RDD 操作方法是属于转换操作还是行动操作,去看下它的返回类型,转换操作返回的是 RDD 类型,而行动操作则返回的是其他的数据类型。
4. 惰性求值
前面,我们多次提到转换操作都是惰性求值,这也就意味着调用的转换操作(textFile、filter等)时,并不会立即去执行,而是 Spark 会记录下所要求执行的操作的相关信息。
因此,我们对 RDD 的理解应该更深一步,不仅要它看作是一个存放分布式数据的数据集,而且也可以把它当作是通过转换操作构建出来的、记录如何计算数据的指令列表。
惰性操作避免了所有操作都进行一遍 RDD 运算,它可以将很多操作合并在一起,来减少计算数据的步骤,提高 Spark 的运算效率。
7、Spark RDD 中常用的操作算子
1. 向Spark 传递函数
Spark API 依赖 Driver 程序中的传递函数完成在集群上执行 RDD 转换并完成数据计算。在 Java API 中,函数所在的类需要实现 org.apache.spark.api.java.function 包中的接口。
Spark 提供了 lambda 表达式和 自定义 Function 类两种创建函数的方式。前者语法简洁、方便使用;后者可以在一些复杂应用场景中自定义需要的 Function 功能。
举个栗子,求 RDD 中数据的平方,并只保留不为0的数据。
可以用 lambda 表达式简明地定义 Function 实现,代码如下:
val input = sc.parallelize(List(-2,-1,0,1,2))
val rdd1 = input.map(x => x * x)
val rdd2 = rdd1.filter(x => x != 0 )
首先用 map() 对 RDD 中所有的数据进行求平方,然后用到 filter() 来筛选不为0的数据。
其中,map() 和 filter() 就是我们最常用的转换算子,map() 接收了 一个 lambda 表达式定义的函数,并把这个函数运用到 input 中的每一个元素,最后把函数计算后的返回结果作为结果 rdd1 中对应元素的值。
同样, filter() 也接收了一个 lambda 表达式定义的函数,并将 rdd1 中满足该函数的数据放入到了新的 rdd2 中返回。
Spark 提供了很丰富的处理 RDD 数据的操作算子,比如使用 distinct() 还可以继续对 rdd2 进行去重处理。
如果需要对 RDD 中每一个元素处理后生成多个输出,也有相应的算子,比如 flatMap(),它和 map() 类似,也是将输入函数应用到 RDD 中的每个元素,不过返回的不是一个元素了,而是一个返回值序列的迭代器。
最终得到的输出是一个包含各个迭代器可访问的所有元素的 RDD,flatMap() 最经典的一个用法就是把输入的一行字符串切分为一个个的单词。
举个栗子,将行数据切分成单词,对比下 map() 与 flat() 的不同。
val lines = sc.parallelize(List("hello spark","hi,flink"))
val rdd1 = lines.map(line => line.split(","))
val rdd2 = lines.flatMap(line => line.split(","))
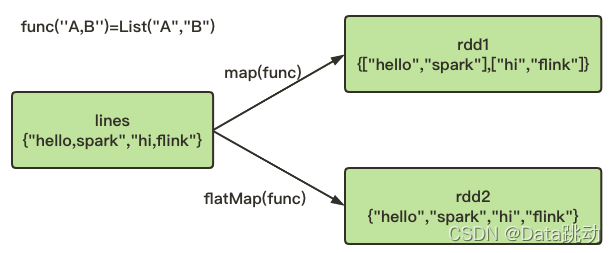
可以看到,把 lines 中的每一个 line,使用所提供的函数执行一遍,map() 输出的 rdd1 中仍然只有两个元素;而 flatMap() 输出的 rdd2 则是将原 RDD 中的数据“拍扁”了,这样就得到了一个由各列表中元素组成的 RDD,而不是一个由列表组成的 RDD。
2. RDD 的转换算子
Spark 中的转换算子主要用于 RDD 之间的转化和数据处理,常见的转换算子具体如下:
| 转换算子 | 含义 |
|---|---|
| map(func) | 返回每一个元素经过 func 方法处理后生成的新元素所组成的数据集合 |
| filter(func) | 返回一个通过 func 方法计算返回 true 的元素所组成的数据集合 |
| flatMap(func) | 与 map 操作类似,但是每一个输入项都能被映射为 0 个或者多个输出项 |
| mapPartitions(func) | 与 map 操作类似,但是 mapPartitions 单独运行在 RDD 的一个分区上 |
| mapPartitionsWithIndex(func) | 与 mapPartitions 操作类似,但是该操作提供一个整数值代表分区的下表 |
| union(otherDataset) | 对两个数据集执行合并操作 |
| intersection(otherDataset) | 对两个数据集执行求交集运算 |
| distinct([numTasks]) | 对数据集执行去重操作 |
| groupByKey([numTasks]) | 返回一个根据 Key 分组的数据集 |
| reduceByKey(func,[numTasks]) | 返回一个在不同 Key 上进行了聚合 Value 的新的 <Key, Value> 数据集,聚合方式由 func 方法指定 |
| sortByKey([ascending],[numTasks]) | 返回排序后的键值对 |
| join(otherDataset,[numTasks]) | 按照 Key 将源数据集合与另一数据集合进行 join 操作,<Key, Value1> 和 <Key, Value2> 的 join 结果就是 <Key, <Value1,Value2>> |
| repatition(numPartitions) | 通过修改 Partiton 的个数对 RDD 中的数据重新进行分区平衡 |
3. RDD 的行动算子
Spark 中行动算子主要用于对分布式环境中 RDD 的转化操作结果进行统一地执行处理,比如结果收集、数据保存等,常用的行动算子具体如下:
| 行动算子 | 含义 |
|---|---|
| reduce(func) | 使用一个 func 方法来聚合一个数据集 |
| collect() | 以数组的形式返回在驱动器上的数据集的所有元素 |
| collectByKey() | 按照数据集中的 Key 进行分组,计算各个 Key 对应的个数 |
| foreach(func) | 在数据集的每个元素上都遍历执行 func 方法 |
| first() | 返回数据集行的第一个元素 |
| take(n) | 以数组的形式返回数据集上的前 n 个元素 |
| takeOrdered(n,[ordering]) | 返回 RDD 排序后的前 n 个元素。排序方式要么使用原生的排序方式,要么使用自定义的比较器排序 |
| saveAsTextFile(path) | 将数据集中的元素写成一个或多个文本文件。参数就是文件路径,可以写在本地文件系统、HDFS,或者其他 Hadoop 支持的文件系统 |
| saveAsSequenceFile(path) | 将 RDD 中的元素写成 Hadoop SequenceFile 保存到本地文件系统、HDFS,或者其他 Hadoop 支持的文件系统,并且 RDD 中可用的键值对必须实现 Hadoop 的 Writable 接口 |
| saveAsObjectFile(path) | 使用 Java 序列化方式将 RDD 中的元素进行序列化并存储到文件系统中,可以使用 SparkContext.objectFile() 方法来加载该数据 |
8、Spark 的共享变量之累加器和广播变量
本节将介绍下 Spark 编程中两种类型的共享变量:累加器和广播变量。
简单说,累加器是用来对信息进行聚合的,而广播变量则是用来高效分发较大对象的。
1. 闭包的概念
在讲共享变量之前,我们先了解下啥是闭包,代码如下。
var n = 1
val func = (i:Int) => i + n
函数 func 中有两个变量 n 和 i ,其中 i 为该函数的形式参数,也就是入参,在 func 函数被调用时, i 会被赋予一个新的值,我们称之为绑定变量(bound variable)。而 n 则是定义在了函数 func 外面的,该函数并没有赋予其任何值,我们称之为自由变量(free variable)。
像 func 函数这样,返回结果依赖于声明在函数外部的一个或多个变量,将这些自由变量捕获并构成的封闭函数,我们称之为“闭包”。
先看一个累加求和的栗子,如果在集群模式下运行以下代码,会发现结果并非我们所期待的累计求和。
var sum = 0
val arr = Array(1,2,3,4,5)
sc.parallelize(arr).foreach(x => sum + x)
println(sum)
sum 的结果为0,导致这个结果的原因就是存在闭包。
在集群中 Spark 会将对 RDD 的操作处理分解为 Tasks ,每个 Task 由 Executor 执行。而在执行之前,Spark会计算 task 的闭包(也就是 foreach() )。闭包会被序列化并发送给每个 Executor,但是发送给 Executor 的是副本,所以在 Driver 上输出的依然是 sum 本身。
如果想对 sum 变量进行更新,则就要用到接下来我们要讲的累加器。
2. 累加器的原理
累加器是对信息进行聚合的,通常在向 Spark 传递函数时,比如使用 map() 或者 filter() 传条件时,可以使用 Driver 中定义的变量,但是集群中运行的每个任务都会得到这些变量的一份新的副本,然而,正如前面所述,更新这些副本的值,并不会影响到 Driver 中对应的变量。
累加器则突破了这个限制,可以将工作节点中的值聚合到 Driver 中。它的一个典型用途就是对作业执行过程中的特定事件进行计数。
举个栗子,给了一个日志记录,需要统计这个文件中有多少空行。
val sc = new SparkContext(...)
val logs = sc.textFile(...)
val blanklines = sc.accumulator(0)
val callSigns = logs.flatMap(line => {
if(line == ""){
blanklines += 1
}
line.split("")
})
callSigns.count()
println("日志中的空行数为:" + blanklines.value)
总结下累加器的使用,首先 Driver 调用了 SparkContext.accumulator(initialValue) 方法,创建一个名为 blanklines 且初始值为0的累加器。然后在遇到空行时,Spark 闭包里的执行器代码就会对其 +1 。执行完成之后,Driver 可以调用累加器的 value 属性来访问累加器的值。
需要说明的是,只有在行动算子 count() 运行之后,才可以 println 出正确的值,因为我们之前讲过 flatMap() 是惰性计算的,只有遇到行动操作之后才会出发强制执行运算进行求值。
另外,工作节点上的任务是不可以访问累加器的值,在这些任务看来,累加器是一个只写的变量。
对于累加器的使用,不仅可以进行数据的 sum 加法,也可以跟踪数据的最大值 max、最小值 min等。
3. 广播变量的原理
前面说了,Spark 会自动把闭包中所有引用到的自由变量发送到工作节点上,那么每个 Task 的闭包都会持有自由变量的副本。如果自由变量的内容很大且 Task 很多的情况下,为每个 Task 分发这样的自由变量的代价将会巨大,必然会对网络 IO 造成压力。
广播变量则突破了这个限制,不是把变量副本发给所有的 Task ,而是将其分发给所有的工作节点一次,这样节点上的 Task 可以共享一个变量副本。
Spark 使用的是一种高效的类似 BitTorrent 的通信机制,可以降低通信成本。广播的数据只会被发动各个节点一次,除了 Driver 可以修改,其他节点都是只读,并且广播数据是以序列化形式缓存在系统中的,当 Task 需要数据时对其反序列化操作即可。
在使用中,Spark 可以通过调用 SparkContext.broadcast(v) 创建广播变量,并通过调用 value 来访问其值,举栗代码如下:
val broadcastVar = sc.broadcast(Array(1,2,3))
broadcastVar.value万字长文,带你轻松学习 Spark的更多相关文章
- 五万字长文带你学会Spring
Sping Spring概念介绍 spring是啥呢,你在斗地主的时候把别人打爆了那叫spring, 你成功的追到了你爱慕已久的女神,人生中的春天来了,那也叫sping 好了别看我老婆了,咱来讲讲啥是 ...
- 又长又细,万字长文带你解读Redisson分布式锁的源码
前言 上一篇文章写了Redis分布式锁的原理和缺陷,觉得有些不过瘾,只是简单的介绍了下Redisson这个框架,具体的原理什么的还没说过呢.趁年前项目忙的差不多了,反正闲着也是闲着,不如把Rediss ...
- [Redis] 万字长文带你总结Redis,助你面试升级打怪
文章目录 Redis的介绍.优缺点.使用场景 Linux中的安装 常用命令 Redis各个数据类型及其使用场景 Redis字符串(String) Redis哈希(Hash) Redis列表(List) ...
- 万字长文带你入门Zookeeper!!!
导读 文章首发于微信公众号[码猿技术专栏],原创不易,谢谢支持. Zookeeper 相信大家都听说过,最典型的使用就是作为服务注册中心.今天陈某带大家从零基础入门 Zookeeper,看了本文,你将 ...
- 万字长文带你掌握Java数组与排序,代码实现原理都帮你搞明白!
查找元素索引位置 基本查找 根据数组元素找出该元素第一次在数组中出现的索引 public class TestArray1 { public static void main(String[] arg ...
- 5分钟学习spark streaming之 轻松在浏览器运行和修改Word Counts
方案一:根据官方实例,下载预编译好的版本,执行以下步骤: nc -lk 9999 作为实时数据源 ./bin/run-example org.apache.spark.examples.sql.str ...
- 性能追击:万字长文30+图揭秘8大主流服务器程序线程模型 | Node.js,Apache,Nginx,Netty,Redis,Tomcat,MySQL,Zuul
本文为<高性能网络编程游记>的第六篇"性能追击:万字长文30+图揭秘8大主流服务器程序线程模型". 最近拍的照片比较少,不知道配什么图好,于是自己画了一个,凑合着用,让 ...
- 学习Spark——那些让你精疲力尽的坑
这一个月我都干了些什么-- 工作上,还是一如既往的写bug并不亦乐乎的修bug.学习上,最近看了一些非专业书籍,时常在公众号(JackieZheng)上写点小感悟,我刚稍稍瞄了下,最近五篇居然都跟技术 ...
- 轻松学习 JavaScript——第 6 部分:JavaScript 箭头函数
JavaScript箭头函数是ECMAScript 6中引入的编写函数表达式的一种简便方法.通常,在JavaScript中,可以通过两种方式创建函数: 函数语句. 函数表达式. 可以如下所示创建函数语 ...
随机推荐
- C++ | 虚函数初探
虚函数 虚函数 是在基类中使用关键字 virtual 声明的函数.在派生类中重新定义基类中定义的虚函数时,会告诉编译器不要静态链接到该函数. 我们想要的是在程序中任意点可以根据所调用的对象类型来选择调 ...
- 可想实现一个自己的简单jQuery库?(九)
Lesson-8 事件机制 在讲事件机制之前呢,我们有一个很重要的东西要先讲,那就是如何实现事件委托(代理). 只有必须先明白了如何实现一个事件委托,我们才能更好的去实现on和off.在我看来,on和 ...
- JavaScript の 内容属性(HTML属性attribute)和 DOM 属性(property)
[博文]内容属性(HTML属性)和 DOM 属性 标签: 博文 JavaScript 粗略解读(与jQuery做对比) 内容属性(HTML属性) : attribute DOM 属性(Element属 ...
- ES6-11学习笔记--异步迭代
ES9提供异步迭代: for await of Symbol.asyncIterator function getPromise(time) { return new Promise((resol ...
- ES6-11学习笔记--Promise
Promise是ES6异步编程解决方案之一,简化以前ajax的嵌套地狱,增加代码可读性. 基本用法: resolve,成功 reject,失败 let p = new Promise((resol ...
- 洛谷 P5706 【深基2.例8】再分肥宅水
题目连接: P5706 [深基2.例8]再分肥宅水 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) 我提交的: 1 #include<iostream> 2 #inclu ...
- [ Skill ] map mapc mapcan mapcar mapcon maplist mapinto
https://www.cnblogs.com/yeungchie/ 几种 map 函数的差异 map map( lambda(( a b ) println( list( a b )) ) list ...
- python---概述
python的主要应用领域 云计算:云计算的最火的语言,典型应用OpenStack. web开发:众多优秀的web框架,典型地有Django,众多大型网站也是python开发,比如YouTube.豆瓣 ...
- Mybatis更新和删除数据
接上文->Mybatis快速入门<- 1.在UserMapper.xml配置更新和删除 <!-- 更新操作--> <update id="update" ...
- 攻防世界 favorite_number
favorite_number 进入环境得到源码 <?php //php5.5.9 $stuff = $_POST["stuff"]; $array = ['admin', ...