day48-JDBC和连接池04-2
JDBC和连接池04-2
10.数据库连接池
10.5Apache-DBUtils
10.5.1resultSet问题
先分析一个问题
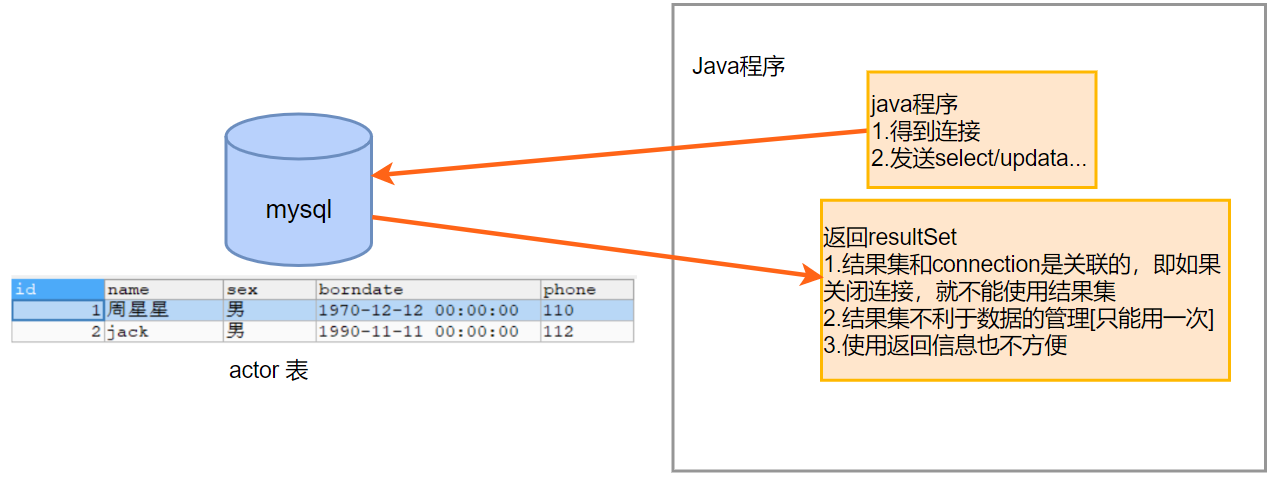
在之前的程序中,执行sql语句后返回的结果集存在如下问题:
关闭connection后,resultSet结果集无法使用
如果要使用结果集,就不能关闭连接,不能关闭连接,就会反过来影响别的程序去连接数据库,就会对多并发程序造成很大的影响
resultSet不利于数据的管理
如果其它的方法或者程序想要使用结果集,也需要一直保持连接,影响其他程序对数据库的连接
使用返回信息也不方便
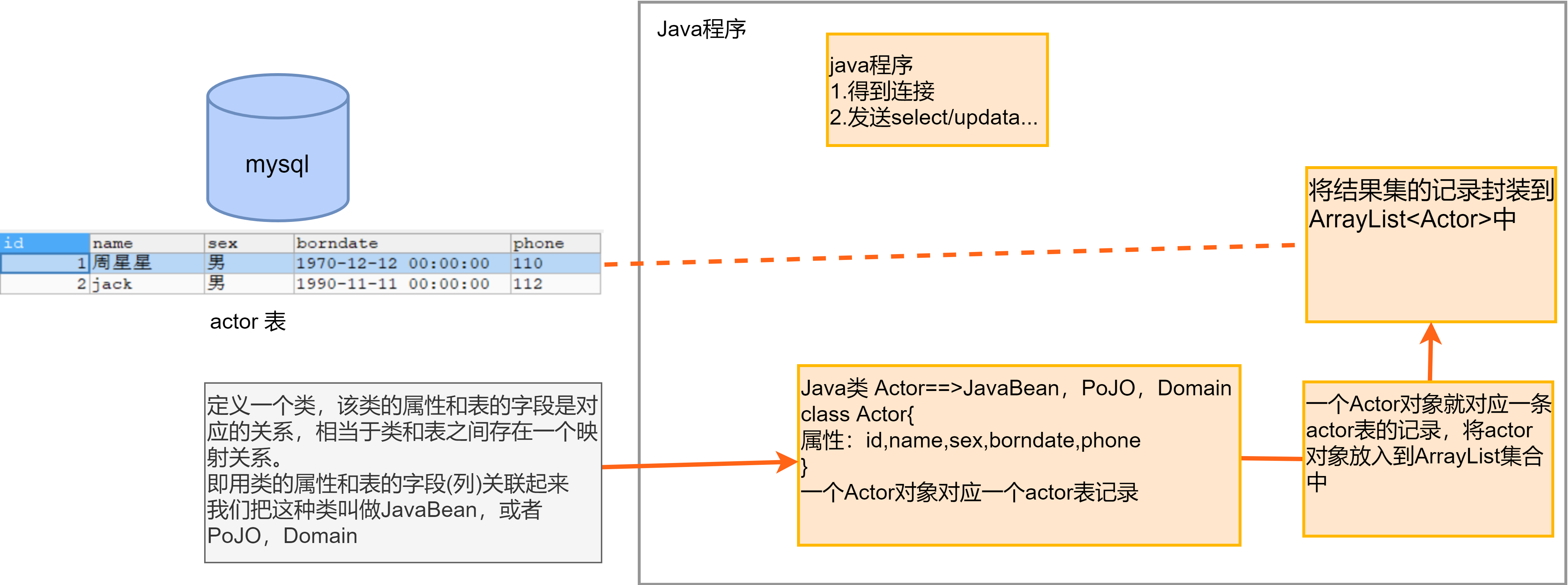
解决方法:
定义一个类,该类的属性和表的字段是对应关系/映射关系,即用类的属性和表的字段(列)关联起来
我们把这种类叫做JavaBean,或者POJO,Domain。
一个Actor对象就对应一条actor表的记录,将Actor对象放入到ArrayList集合中(将结果集的记录封装到ArrayList中)
10.5.2土方法完成封装
Actor类(JavaBean):
package li.jdbc.datasource;
import java.util.Date;
/**
* Actor对象和actor表的记录对应
*/
public class Actor {//JavaBean/POJO/Domain
private Integer id;
private String name;
private String sex;
private Date borndate;
private String phone;
public Actor() {//一定要给一个无参构造器[反射需要]
}
public Actor(Integer id, String name, String sex, Date borndate, String phone) {
this.id = id;
this.name = name;
this.sex = sex;
this.borndate = borndate;
this.phone = phone;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public Date getBorndate() {
return borndate;
}
public void setBorndate(Date borndate) {
this.borndate = borndate;
}
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
@Override
public String toString() {
return "\nActor{" +
"id=" + id +
", name='" + name + '\'' +
", sex='" + sex + '\'' +
", borndate=" + borndate +
", phone='" + phone + '\'' +
'}';
}
}
测试程序:
package li.jdbc.datasource;
import org.junit.Test;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.Date;
public class JDBCUtilsByDruid_Use {
//使用土方法尝试解决ResultSet问题==封装=>ArrayList
@Test
public void testSelectToArrayList() {//也可以设置返回值
System.out.println("使用druid方式完成");
//1.得到连接
Connection connection = null;
//2.组织一个sql语句
String sql = "Select * from actor where id >=?";
//3.创建PreparedStatement对象
PreparedStatement preparedStatement = null;
ResultSet set = null;
ArrayList<Actor> list = new ArrayList<>();//创建ArrayList对象,存放actor对象
try {
connection = JDBCUtilsByDruid.getConnection();
preparedStatement = connection.prepareStatement(sql);
preparedStatement.setInt(1, 1);//给?号赋值
//执行sql,得到结果集
set = preparedStatement.executeQuery();
//遍历该结果集
while (set.next()) {
int id = set.getInt("id");
String name = set.getString("name");
String sex = set.getString("sex");
Date borndate = set.getDate("borndate");
String phone = set.getString("phone");
//把得到的当前 resultSet的一条记录,封装到一个Actor对象中,并放入arraylist集合
list.add(new Actor(id,name,sex,borndate,phone));
}
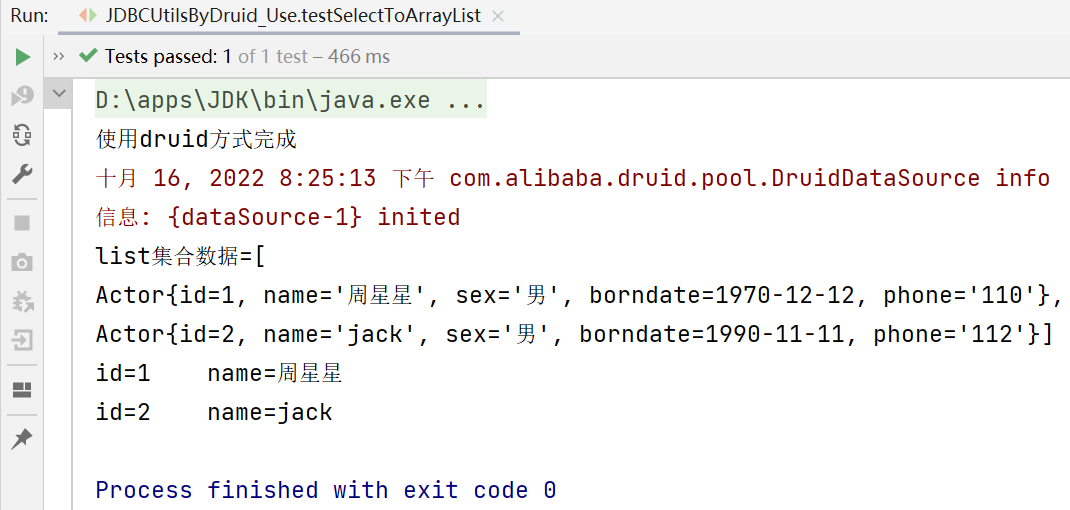
System.out.println("list集合数据="+list);
//or
for (Actor actor:list) {
System.out.println("id="+actor.getId()+"\t"+"name="+actor.getName());
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
//关闭资源(不是真的关闭连接,而是将Connection对象放回连接池中)
JDBCUtilsByDruid.close(set, preparedStatement, connection);
}
//因为ArrayList 和 connection 没有任何关联,所以该集合可以复用
//return list;
}
}
10.5.3Apache-DBUtils
基本介绍
commons-dbutils是Apache组织提供的一个开源 JDBC工具类库,它是对 JDBC的封装,使用dbutils能极大简化 JDBC编码的工作量。
DbUtils类
- QueryRunner类:该类封装了SQL的执行,是线程安全的。可以实现增、删、改、查、批处理
- 使用QueryRunner类实现查询
- ResultSetHandler接口:该接口用于处理 java.sql.ResultSet,将数据按要求转换为另一种形式
| 方法 | 解释 |
|---|---|
| ArrayHandler | 将结果集中的第一行数据转成对象数组 |
| ArrayListHandler | 把结果集中的每一行数据都转成一个数组,再存放到List中 |
| BeanHandler | 将结果集中的第一行数据封装到一个对应的JavaBean实例中 |
| BeanListHandler | 将结果集中的每一行数据都封装到一个对应的JavaBean实例中,再存放到List中 |
| ColumnListHandler | 将结果集中某一列的数据存放到List中 |
| KeyedHandler(name) | 将结果集中的每行数据都封装到Map中,再把这些map再存放到一个map里,其key为指定的key |
| MapHandler | 将结果集中的第一行数据封装到一个Map里,key是列名,value就是对应的值 |
| MapListHandler | 将结果集中的每一行数据都封装到一个Map里,然后再存放到List |
DBUtils的jar包下载可以去官网下载
应用实例
使用DBUtils+数据库连接池(德鲁伊)方式,完成对表actor的crud操作

首先将DBUtils的jar包添加到项目的libs文件夹下面,右键选择add as library
Actor类详见10.5.2
DBUtils_USE:
package li.jdbc.datasource;
import org.apache.commons.dbutils.QueryRunner;
import org.apache.commons.dbutils.handlers.BeanListHandler;
import org.junit.Test;
import java.sql.Connection;
import java.sql.SQLException;
import java.util.List;
public class DBUtils_USE {
//使用Apache-DBUtils工具类 + Druid 完成对表的crud操作
@Test
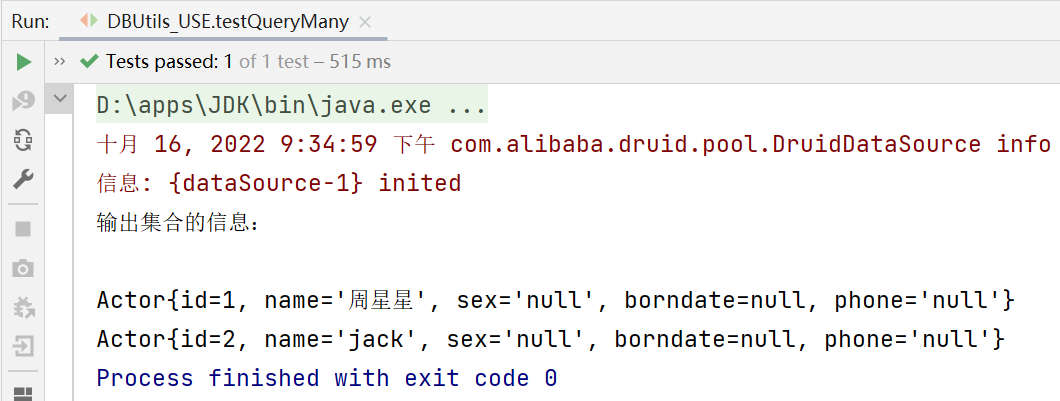
public void testQueryMany() throws SQLException {//返回结果是多行多列的情况
//1.得到连接(Druid)
Connection connection = JDBCUtilsByDruid.getConnection();
//2.使用DBUtils类和接口(先引入相关的jar,加入到本地的project)
//3.创建QueryRunner
QueryRunner queryRunner = new QueryRunner();
//4.然后就可以执行相关的方法,返回ArrayList结果集
//String sql = "Select * from actor where id >=?";
//注意 :sql语句也可以查询部分的列,没有查询的属性就在actor对象中置空
String sql = "Select id,name from actor where id >=?";
/**
* (1) query方法就是执行sql语句,得到resultSet--封装到-->Arraylist集合中
* (2) 然后返回集合
* (3) connection就是连接
* (4) sql:执行的sql语句
* (5) new BeanListHandler<>(Actor.class): 将resultSet->Actor对象->封装到ArrayList
* 底层使用反射机制,去获取 Actor的属性,然后进行封装
* (6) 1 就是给sql语句中的?赋值,可以有多个值,因为是可变参数
* (7) 底层得到的resultSet,会在query关闭,同时也会关闭PreparedStatement对象
*/
List<Actor> list =
queryRunner.query(connection, sql, new BeanListHandler<>(Actor.class), 1);
System.out.println("输出集合的信息:");
for (Actor actor : list) {
System.out.print(actor);
}
//释放资源
JDBCUtilsByDruid.close(null, null, connection);
}
}
10.5.4ApDBUtils源码分析
在上述10.5.3代码中,在List<Actor> list = queryRunner.query(connection, sql, new BeanListHandler<>(Actor.class), 1);语句旁打上断点,点击debug,点击step into

光标跳转到如下方法:
public <T> T query(Connection conn, String sql, ResultSetHandler<T> rsh,
Object... params) throws SQLException {
PreparedStatement stmt = null;//定义PreparedStatement对象
ResultSet rs = null;//接收返回的resultSet
T result = null;//返回ArrayList
try {
stmt = this.prepareStatement(conn, sql);//创建PreparedStatement
this.fillStatement(stmt, params);//对SQL语句进行?赋值
rs = this.wrap(stmt.executeQuery());//执行SQL,返回resultSet
result = rsh.handle(rs);//将返回的resultSet-->封装到ArrayList中[使用反射,对传入的class对象进行处理]
} catch (SQLException e) {
this.rethrow(e, sql, params);
} finally {
try {
close(rs);//关闭resultSet
} finally {
close(stmt);//关闭preparedStatement
}
}
return result;//返回ArrayList
}
10.5.5ApDBUtils查询
使用DBUtils+数据库连接池(德鲁伊)方式,完成对表actor的查询操作
1.多行多列
package li.jdbc.datasource;
import org.apache.commons.dbutils.QueryRunner;
import org.apache.commons.dbutils.handlers.BeanListHandler;
import org.junit.Test;
import java.sql.Connection;
import java.sql.SQLException;
import java.util.List;
public class DBUtils_USE {
//返回结果是多行多列的情况
@Test
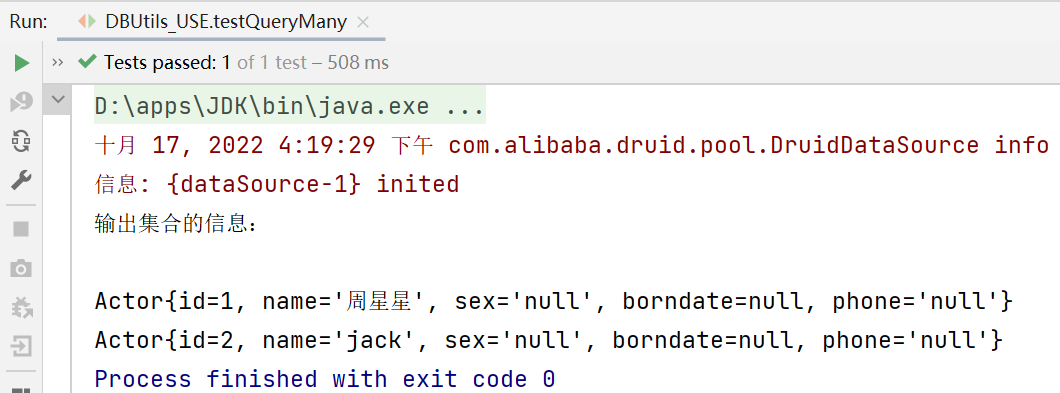
public void testQueryMany() throws SQLException {
//得到连接(Druid)
Connection connection = JDBCUtilsByDruid.getConnection();
//创建QueryRunner
QueryRunner queryRunner = new QueryRunner();
//然后就可以执行相关的方法,返回ArrayList结果集
//sql语句也可以查询部分的列,没有查询的属性就在actor对象中置空
String sql = "Select id,name from actor where id >=?";
List<Actor> list =
queryRunner.query(connection, sql, new BeanListHandler<>(Actor.class), 1);
System.out.println("输出集合的信息:");
for (Actor actor : list) {
System.out.print(actor);
}
//释放资源
JDBCUtilsByDruid.close(null, null, connection);
}
}
2.单行多列
package li.jdbc.datasource;
import org.apache.commons.dbutils.QueryRunner;
import org.apache.commons.dbutils.handlers.BeanHandler;
import org.junit.Test;
import java.sql.Connection;
public class DBUtils_USE {
//演示DBUtils+druid完成-返回的结果是单行记录(单个对象)的情况-单行多列
@Test
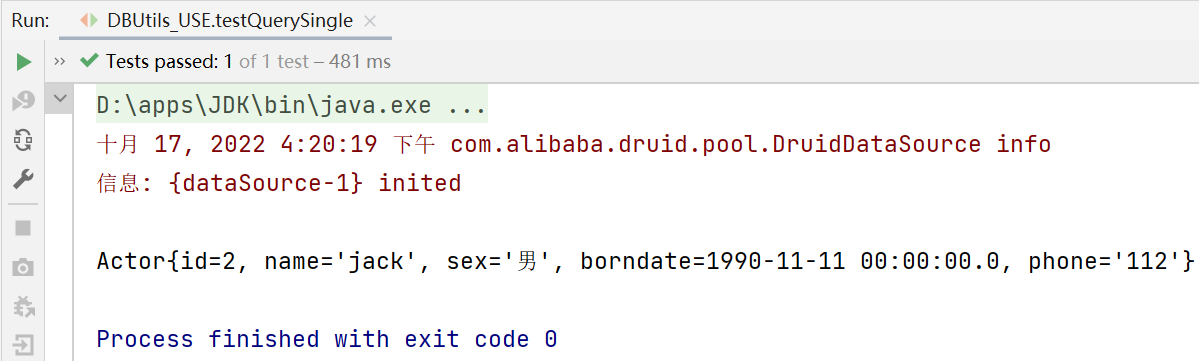
public void testQuerySingle() throws Exception {
//1.得到连接
Connection connection = JDBCUtilsByDruid.getConnection();
//2.创建QueryRunner对象
QueryRunner queryRunner = new QueryRunner();
//3.执行相关方法,返回单个对象
String sql = "Select * from actor where id =?";
//因为我们返回的是单行记录,对应单个对象,
// 因此使用的 Handler是BeanHandler:将结果集中的第一行数据封装到一个对应的JavaBean实例中
Actor actor =
queryRunner.query(connection, sql, new BeanHandler<>(Actor.class), 2);
System.out.println(actor);
//释放资源
JDBCUtilsByDruid.close(null, null, connection);
}
}
3.单行单列
package li.jdbc.datasource;
import org.apache.commons.dbutils.QueryRunner;
import org.apache.commons.dbutils.handlers.ScalarHandler;
import org.junit.Test;
import java.sql.Connection;
public class DBUtils_USE {
//演示DBUtils+druid完成-查询结果是单行单列的情况-返回的就是Object
@Test
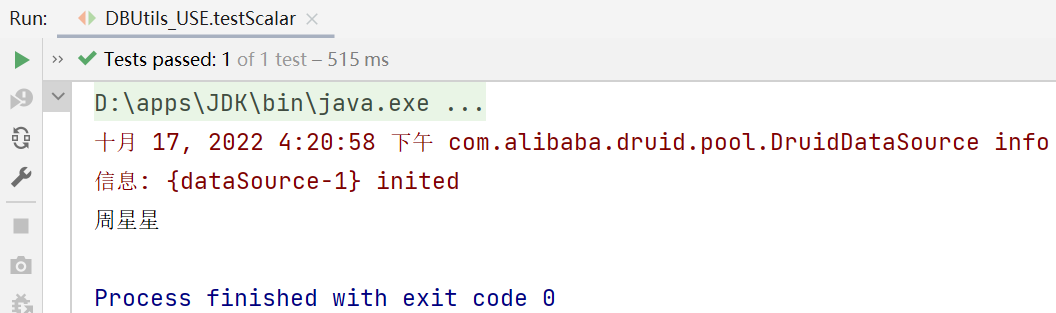
public void testScalar() throws Exception {//Scalar 单一值
//获取连接
Connection connection = JDBCUtilsByDruid.getConnection();
//创建QueryRunner对象
QueryRunner queryRunner = new QueryRunner();
//执行相关方法,返回单行单列
String sql = "Select name from actor where id =?";
//因为返回的是一个对象,因此使用的 Handler是 ScalarHandler
Object obj = queryRunner.query(connection, sql, new ScalarHandler(), 1);
System.out.println(obj);
//释放资源
JDBCUtilsByDruid.close(null,null,connection);
}
}
10.5.6ApDBUtilsDML
使用DBUtils+数据库连接池(德鲁伊)方式,完成对表actor的DML(update,insert,delete)操作
package li.jdbc.datasource;
import org.apache.commons.dbutils.QueryRunner;
import org.junit.Test;
import java.sql.Connection;
import java.sql.SQLException;
public class DBUtils_USE {
//演示DBUtils+druid完成 dml操作
@Test
public void testDML() throws SQLException {
//获取连接
Connection connection = JDBCUtilsByDruid.getConnection();
//创建QueryRunner对象
QueryRunner queryRunner = new QueryRunner();
//这里组织sql完成update,insert,delete
//String sql = "update actor set name =? where id =?";
//String sql = "insert into actor values (null,?,?,?,?)";
String sql = "delete from actor where id =?";
/**
* 1.执行dml的操作是queryRunner.update()
* 2.返回的值是受影响的行数,如果返回的是0,代表sql执行失败 或者 执行成功但是表没受影响
*/
//int affectedRow = queryRunner.update(connection, sql,"黎明","女","1999-10-09","123");
int affectedRow = queryRunner.update(connection, sql,1000);
System.out.println(affectedRow > 0 ? "执行成功" : "执行没有影响到表");
//释放资源
JDBCUtilsByDruid.close(null, null, connection);
}
}
10.6表和JavaBean的类型映射关系

day48-JDBC和连接池04-2的更多相关文章
- day48-JDBC和连接池04
JDBC和连接池04 10.数据库连接池 10.1传统连接弊端分析 传统获取Connection问题分析 传统的 JDBC 数据库连接使用DriverManager来获取,每次向数据库建立连接的时候都 ...
- c3p0、dbcp、tomcat jdbc pool 连接池配置简介及常用数据库的driverClass和驱动包
[-] DBCP连接池配置 dbcp jar包 c3p0连接池配置 c3p0 jar包 jdbc-pool连接池配置 jdbc-pool jar包 常用数据库的driverClass和jdbcUrl ...
- jdbc数据连接池dbcp要导入的jar包
jdbc数据连接池dbcp要导入的jar包 只用导入commons-dbcp-x.y.z.jarcommons-pool-a.b.jar
- 关于JDBC和连接池我学到的(转载保存)
1.JDBC数据库连接池的必要性 在使用开发基于数据库的web程序时,传统的模式基本是按以下步骤: 在主程序(如servlet.beans)中建立数据库连接. 进行sql操作 断开数据库连接. 这种模 ...
- JDBC之 连接池
JDBC之 连接池 有这样的一种现象: 用java代码操作数据库,需要数据库连接对象,一个用户至少要用到一个连接.现在假设有成千上百万个用户,就要创建十分巨大数量的连接对象,这会使数据库承受极大的压力 ...
- JDBC数据源连接池(4)---自定义数据源连接池
[续上文<JDBC数据源连接池(3)---Tomcat集成DBCP>] 我们已经 了解了DBCP,C3P0,以及Tomcat内置的数据源连接池,那么,这些数据源连接池是如何实现的呢?为了究 ...
- JDBC数据源连接池(3)---Tomcat集成DBCP
此文续<JDBC数据源连接池(2)---C3P0>. Apache Tomcat作为一款JavaWeb服务器,内置了DBCP数据源连接池.在使用中,只要进行相应配置即可. 首先,确保Web ...
- JDBC数据源连接池(2)---C3P0
我们接着<JDBC数据源连接池(1)---DBCP>继续介绍数据源连接池. 首先,在Web项目的WebContent--->WEB-INF--->lib文件夹中添加C3P0的j ...
- DBCP,C3P0与Tomcat jdbc pool 连接池的比较
hibernate开发组推荐使用c3p0; spring开发组推荐使用dbcp(dbcp连接池有weblogic连接池同样的问题,就是强行关闭连接或数据库重启后,无法reconnect,告诉连接被重置 ...
- mysql,jdbc、连接池
show processlist; select * from information_schema.processlist; Command: The type of command the thr ...
随机推荐
- Mysql8基础知识
系统表都变为InnoDb表 从MySQL 8.0开始,系统表全部换成事务型的InnoDB表,默认的MySQL实例将不包含任何MyISAM表,除非手动创建MyISAM表 基本操作 创建数据表的语句为CR ...
- Java版的防抖(debounce)和节流(throttle)
概念 防抖(debounce) 当持续触发事件时,一定时间段内没有再触发事件,事件处理函数才会执行一次,如果设定时间到来之前,又触发了事件,就重新开始延时. 防抖,即如果短时间内大量触发同一事件,都会 ...
- PerfView专题 (第一篇):如何寻找热点函数
一:背景 准备开个系列来聊一下 PerfView 这款工具,熟悉我的朋友都知道我喜欢用 WinDbg,这东西虽然很牛,但也不是万能的,也有一些场景他解决不了或者很难解决,这时候借助一些其他的工具来辅助 ...
- 从零开始Blazor Server(11)--编辑用户
用户编辑和角色编辑几乎一模一样,这里先直接贴代码. @page "/user" @using BlazorLearn.Entity @using Furion.DataEncryp ...
- MyBatis 01 概述
官网 http://www.mybatis.org/mybatis-3/zh/index.html GitHub https://github.com/mybatis/mybatis-3 简介 MyB ...
- Spring 02: Spring接管下的三层项目架构
业务背景 需求:使用三层架构开发,将用户信息导入到数据库中 目标:初步熟悉三层架构开发 核心操作:开发两套项目,对比Spring接管下的三层项目构建和传统三层项目构建的区别 注意:本例中的数据访问层, ...
- Windows权限维持总结
windows权限维持 注册服务 sc create 服务名 binpath= "cmd.exe /k 木马路径" start="auto" obj=" ...
- 在cmd中使用doskey来实现alias别名功能
作为一枚网络工程师,经常就是面对一堆黑框框,也是就是终端.不同操作系统.不同厂家的目录,功能相同但是键入的命令又大不相同,这些差异化容易让脑子混乱.比如华为.思科.H3C.锐捷的设备, ...
- AtCoder Beginner Contest 255(E-F)
Aising Programming Contest 2022(AtCoder Beginner Contest 255) - AtCoder E - Lucky Numbers 题意: 给两个数组a ...
- 数据结构与算法【Java】05---排序算法总结
前言 数据 data 结构(structure)是一门 研究组织数据方式的学科,有了编程语言也就有了数据结构.学好数据结构才可以编写出更加漂亮,更加有效率的代码. 要学习好数据结构就要多多考虑如何将生 ...