Work Queues(工作队列)
1.模型
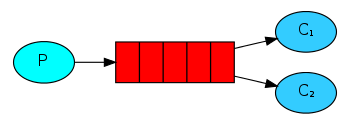
2.创建生产者
package com.dwz.rabbitmq.work; import java.io.IOException;
import java.util.concurrent.TimeoutException; import com.dwz.rabbitmq.util.ConnectionUtils;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection; /** |--c1
* p---Queue--|
* |--c2
*/
public class Send {
private static final String QUEUE_NAME = "test_work_queue"; public static void main(String[] args) throws IOException, TimeoutException {
Connection connection = ConnectionUtils.getConnection();
Channel channel = connection.createChannel();
//声明队列
channel.queueDeclare(QUEUE_NAME, false, false, false, null); for(int i = 0; i < 50; i++) {
String msg = "send:--" + i;
channel.basicPublish("", QUEUE_NAME, null, msg.getBytes());
} channel.close();
connection.close();
}
}
3.创建消费者1
package com.dwz.rabbitmq.work; import java.io.IOException;
import java.util.concurrent.TimeoutException; import com.dwz.rabbitmq.util.ConnectionUtils;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.DefaultConsumer;
import com.rabbitmq.client.Envelope;
import com.rabbitmq.client.AMQP.BasicProperties; public class rev01 {
private static final String QUEUE_NAME = "test_work_queue";
public static void main(String[] args) throws IOException, TimeoutException {
//获取一个连接
Connection connection = ConnectionUtils.getConnection();
//从连接中获取一个通道
Channel channel = connection.createChannel();
//队列声明
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
//定义消费者
DefaultConsumer consumer = new DefaultConsumer(channel) {
//自动接收消息
@Override
public void handleDelivery(String consumerTag, Envelope envelope, BasicProperties properties, byte[] body)
throws IOException {
String msg = new String(body, "utf-8");
System.out.println("rev01:" + msg);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
//监听队列
channel.basicConsume(QUEUE_NAME, false, consumer);
}
}
4.创建消费者2
package com.dwz.rabbitmq.work; import java.io.IOException;
import java.util.concurrent.TimeoutException; import com.dwz.rabbitmq.util.ConnectionUtils;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.DefaultConsumer;
import com.rabbitmq.client.Envelope;
import com.rabbitmq.client.AMQP.BasicProperties; public class rev02 {
private static final String QUEUE_NAME = "test_work_queue";
public static void main(String[] args) throws IOException, TimeoutException {
//获取一个连接
Connection connection = ConnectionUtils.getConnection();
//从连接中获取一个通道
Channel channel = connection.createChannel();
//队列声明
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
//定义消费者
DefaultConsumer consumer = new DefaultConsumer(channel) {
//自动接收消息
@Override
public void handleDelivery(String consumerTag, Envelope envelope, BasicProperties properties, byte[] body)
throws IOException {
String msg = new String(body, "utf-8");
System.out.println("rev02:" + msg);
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
//监听队列
channel.basicConsume(QUEUE_NAME, false, consumer);
}
}
5.运行代码
预期结果:
按照延迟加载时间获取消息数量不同,数量比例为 延时1:延时2
测试结果如下:
1.两个消费者先启动完成,再启动生产者,这时会采用轮询分发的方式,消费者1和消费者2各拿到一半的消息
2.生产者先启动完成,消费者按照先后顺序启动,会发现所有消息都被先启动的那个消费者接收
达到预期结果的解决方案:
消费者限流+手动签收确认
消费者限流:channel.basicQos(1);
手动签收确认:channel.basicAck(envelope.getDeliveryTag(), false);
Work Queues(工作队列)的更多相关文章
- 3、RabbitMQ-work queues 工作队列
work queues 工作队列 1.模型图: 为什么会出现 work queues? 前提:使用 simple 队列的时候 我们应用程序在是使用消息系统的时候,一般生产者 P 生产消息是毫不费力的( ...
- 译:2. RabbitMQ Java Client 之 Work Queues (工作队列)
在上篇揭开RabbitMQ的神秘面纱一文中,我们编写了程序来发送和接收来自命名队列的消息. 本篇我们将创建一个工作队列,工作队列背后的假设是每个任务都交付给一个工作者 本篇是译文,英文原文请移步:ht ...
- 译: 2. RabbitMQ Spring AMQP 之 Work Queues
在上一篇博文中,我们写了程序来发送和接受消息从一个队列中. 在这篇博文中我们将创建一个工作队列,用于在多个工作人员之间分配耗时的任务. Work Queues 工作队列(又称:任务队列)背后的主要思想 ...
- rabbitMQ常用方法说明 – 6中工作模式及关键点
首先,RabbitMQ解决什么问题? 1)信息的发送者和接收者如何维持连接,如果一方的连接中断,这期间的数据如何防止丢失? 2)如何降低发送者和接收者的耦合度? 3)如何让Priority高的接收者先 ...
- RabbitMQ 学习专栏
RabbitMQ 官网:http://www.rabbitmq.com/ 原创博文 1.揭开消息中间件RabbitMQ的神秘面纱 2. RabbitMQ 服务器之下载安装 3. RabbitMQ 之修 ...
- 译:3.RabbitMQ Java Client 之 Publish/Subscribe(发布和订阅)
在上篇 RabbitMQ 之Work Queues (工作队列)教程中,我们创建了一个工作队列,工作队列背后的假设是每个任务都交付给一个工作者. 在这一部分,我们将做一些完全不同的事情 - 我们将向多 ...
- 译:6.RabbitMQ Java Client 之 Remote procedure call (RPC,远程过程调用)
在 译:2. RabbitMQ 之Work Queues (工作队列) 我们学习了如何使用工作队列在多个工作人员之间分配耗时的任务. 但是如果我们需要在远程计算机上运行一个函数并等待结果呢?嗯,这 ...
- rabbitmq简单实例
JMS组件:activemq(慢)AMQP组件(advance message queue protocol):rabbitmq和kafka 一..消息队列解决了什么问题?异步处理应用解耦流量削锋日志 ...
- RabbitMQ--其他几种模式
本文是作者原创,版权归作者所有.若要转载,请注明出处. 本文RabbitMQ版本为rabbitmq-server-3.7.17,erlang为erlang-22.0.7.请各位去官网查看版本匹配和下载 ...
- RabbitMQ官方中文入门教程(PHP版) 第二部分:工作队列(Work queues)
工作队列 在第一篇教程中,我们已经写了一个从已知队列中发送和获取消息的程序.在这篇教程中,我们将创建一个工作队列(Work Queue),它会发送一些耗时的任务给多个工作者(Works ). 工作队列 ...
随机推荐
- [leetcode] 题解记录 11-20
博客园markdown太烂, 题解详情https://github.com/TangliziGit/leetcode/blob/master/solution/11-20.md Leetcode So ...
- MySQL数据库笔记一:简介及简单操作
一.初识MySQL数据库 1.数据库的概述 <1>数据库:Database 长期存储在计算机内的,有组织的,可共享的数据集合. 存储数据的仓库.(文件) <2>数据库管理系统: ...
- 视频大文件分片上传(使用webuploader插件)
背景 公司做网盘系统,一直在调用图片服务器的接口上传图片,以前写的,以为简单改一改就可以用 最初要求 php 上传多种视频格式,支持大文件,并可以封面截图,时长统计 问题 1.上传到阿里云服务器,13 ...
- 裸磁盘上ext4与xfs在线扩容,非LVM
虚拟机添加一个20G的硬盘,磁盘为sdb,分区为ext4 格式化一个5Gib的磁盘出来,用dd命令写入4G数据. 一.需求是容量为5G的磁盘,文件系统为ext4的sdb1扩容到10G. 操作步骤为 1 ...
- websocket 多聊天室功能
websocket 类也是在网上找到的. 修改后可以用来创建多房间聊天室.可以发送图片表情,图片,及文字. 分享的代码,已经测试.可正常运行 HTML 端代码 <!DOCTYPE html> ...
- 开关灯 ToggleButton
开关灯 ToggleButton textOn:对应true的时候:textOff:对应false的时候:给toggleButton设置监听器toggleButton.setOnCheckChange ...
- CF #546 D.E
D coun[i]表示[i]这个数右边有多少个数j能和他组成题中所给的二元组(i,j) 如果一个数的coun[i]=n-i-ans 那么说明他可以与最后一个交换 同时不计算贡献 因为它是向右走的 对左 ...
- Summer training #4
D:找到两个数 一个是另一个的整数倍(1也算) 因为N是600000 调和级数为ln(n+1) 算一下 可以直接爆 #include <bits/stdc++.h> #include &l ...
- php生成word并下载
1.前端代码: index.html <!DOCTYPE html> <html> <head> <title>PHP生成Word文档</ti ...
- 论文参考文献中的M R J意义
1 期刊作者.题名[J].刊名,出版年,卷(期):起止页码 2 专著作者.书名[M].版本(第一版不著录).出版地:出版者,出版年.起止页码 3 论文集作者.题名[C].//编者.论文集名.出版地:出 ...