CUDA 笔记
名词解释
SM :Streaming Multiprocessor 而 Block 大致就是对应到 SM 所有的blocks 按照流水线被送到6个SM中进行计算
在 Compute Capability 1.0/1.1 中,每个 SM 最多可以同时管理 768 个 thread(768 active threads)或 8 个 block(8 active blocks);而每一个 warp 的大小,则是 32 个 thread,也就是一个 SM 最多可以有 768 / 32 = 24 个 warp(24 active warps)。到了 Compute Capability 1.2 的话,则是 active warp 则是变为 32,所以 active thread 也增加到 1024。
SP: thread 则大致对应到 SP
MP: Multiprocessor ?????
Compute Capability 1.0/1.1 的硬件上,每个grid最多可以允许65535×65535个block。每个block最多可以允许512个thread,但是第三维上的最大值为64。而官方的建议则是一个 block 里至少要有 64 个 thread,192 或 256 个也是通常比较合适的数字(请参考 Programming Guide)。
所以 一个Block 的thread的个数是 64-256 然后根据这个去算GridSize
thread,block,grid,warp是CUDA编程上的概念,以方便程序员软件设计,组织线程,同样的我们给出一个示意图来表示。
- thread:一个CUDA的并行程序会被以许多个threads来执行。
- block:数个threads会被群组成一个block,同一个block中的threads可以同步,也可以通过shared memory通信。
- grid:多个blocks则会再构成grid。
- warp:GPU执行程序时的调度单位,目前cuda的warp的大小为32,同在一个warp的线程,以不同数据资源执行相同的指令,这就是所谓 SIMT(单指令多线程)。
- GTX1550
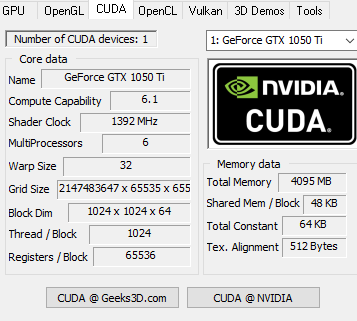
从上图可以看出来
1. 每个Block最多1024个 thread , 每个Block最大48KB 的 SMEM, 即最大float[96][96] 内存 或者uchar[384][384]
2. Grid 的threads实际上就可以有那么多!!

1. grid 和 block 的size 分配
Block的size 应该为32的整数倍
在程序运行的时候,实际上每32个Thread组成一个Warp,每个 warp 块都包含连续的线程,递增线程 ID 。Warp是MP的基本调度单位,每次运行的时候,由于MP数量不同,所以一个Block内的所有Thread不一定全部同时运行,但是每个Warp内的所有Thread一定同时运行。因此,我们在定义Thread Size的时候应使其为Warp Size的整数倍,也就是Thread Size应为32的整数倍
一个block内的thread 不是越多越好, thread 太多了
理论上Thread越多,就越能弥补单个Thread读取数据的latency ,但是当Thread越多,每个Thread可用的寄存器也就越少,严重的时候甚至能造成Kernel无法启动。因此每个Block最少应包含64个Thread,一般选择128或者256,具体视MP数目而定。一个MP最多可以同时运行768个Thread,但每个MP最多包含8个Block,因此要保持100%利用率,Block数目与其Size有如下几种设定方式: Ø 2 blocks x 384 threads Ø 3 blocks x 256 threads Ø 4 blocks x 192 threads Ø 6 blocks x 128 threads Ø 8 blocks x 96 threads
比如我的MX150 有1024个核心(MP),
2. 动态共享内存


shared memory 的生命周期:
当每个线程块开始执行时, 会分配给它一定数量的共享内存。 这
个共享内存的地址空间被线程块中所有的线程共享。 它的内容和创建
时所在的线程块具有相同生命周期
3. 一些术语
warp 每32个thread 是一个warp
CUDA采用单指令多线程(SIMT) 架构来管理和执行线程, 每
32个线程为一组, 被称为线程束(warp) 。 线程束中的所有线程同时
执行相同的指令。 每个线程都有自己的指令地址计数器和寄存器状
态, 利用自身的数据执行当前的指令。 每个SM都将分配给它的线程
块划分到包含32个线程的线程束中, 然后在可用的硬件资源上调度执
行
SM : 是GPU架构的核心
4 . 不要单线程地去拷贝很大的数据 , 比如如下, 非常耗时.
if (threadIdx.x == && threadIdx.y == ) {
for (int j = ; j != h_plus_2r; ++j) {
for (int i = ; i != w_plus_2r; ++i) {
data[j][i] = (uchar)(int)(tex2D<YuvUnit>(tex, ix0 + i - op->radius, iy0 + j - radius));
}
}
}
__syncthreads();
5. cublas 矩阵乘法
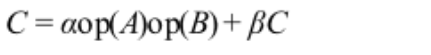
ret = cublasSgemm(handle, CUBLAS_OP_N, CUBLAS_OP_N, matrix_size.uiHA, matrix_size.uiHB, matrix_size.uiWB,
&alpha, dev_A, matrix_size.uiWA, dev_B, matrix_size.uiWB, &beta, dev_C, matrix_size.uiWB);
https://www.cnblogs.com/243864952blogs/p/3903247.html
6. 核函数中调用的函数必须是 __device__ 函数
__shared__ 可以作为char * 参数 传递给 __device__ 函数
class DeviceClass {
public:
__device__ DeviceClass() //必须使用__device__ 修饰
{printf("constructor DeviceClass \n");};
};
__device__ void __print(char*ptr)//这里可以传递shared 数组进来
{
DeviceClass a;
printf("%c %c %c %c\n", ptr[], ptr[], ptr[], ptr[]);
}
7. sm_31 对性能的影响
compute_60,sm_60; 15.54 fps
compute_30,sm_30; 15.50 fps
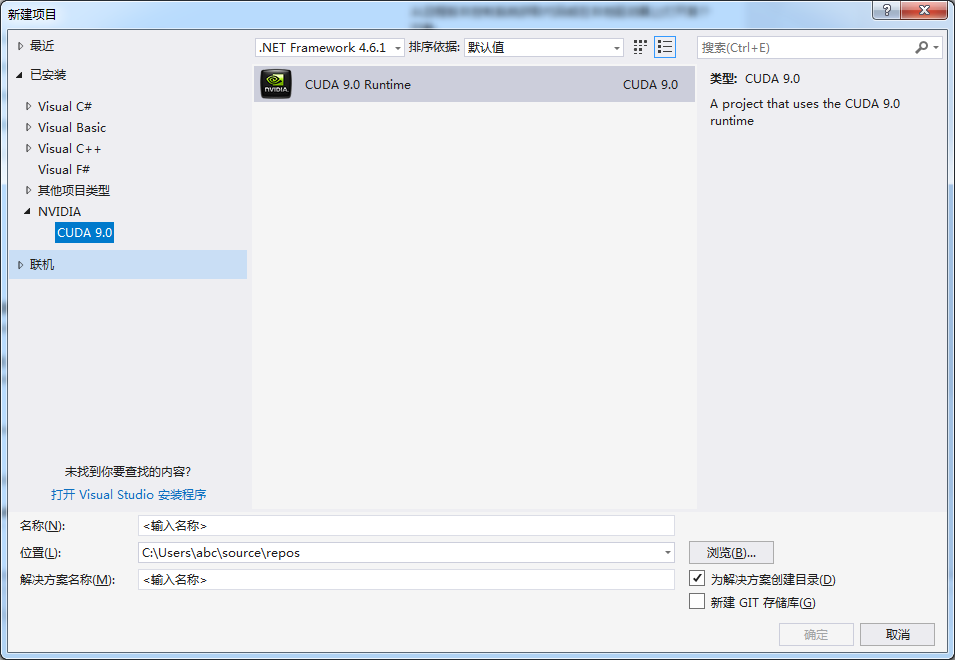
8 VS 新建cuda 项目
9. Stream 性能实测
1. 不使用stream:58.5ms
2. upload 使用stream[0] run 使用stream[1] download 使用stream[2]
58.04 ms
10 CUDA 编程的几个坑不要踩:
1. 三个尖括号要连起来写!!! 不然会报错“ 应输入表达式 ”

2. cu文件不能有中文!!! 目录页不能有中文!!!
11 CUDA 里面的同步函数
__syncthreads():线程块内线程同步;保证线程会肿的所有线程都执行到同一位置; 当整个线程块走向同一分支时才可以使用_syncthreads(),否则造成错误;一个warp内的线程不需要同步;即当执行的线程数小于warpsize时,不需要同步函数,调用一次至少需要四个时钟周期,一般需要更多时钟周期,应尽量避免使用。每个SM包含8个CUDA内核,并且在任何一个时刻执行32个线程的单个warp , 因此需要4个时钟周期来为整个warp发布单个指令。你可以假设任何给定warp中的线程在锁步(LOCKSTEP)中执行,。LOCKSTEP技术可以保持多个CPU、内存精确的同步,在正确的相同时钟周期内执行相同的指令。但要跨warp进行同步,您需要使用 __ syncthreads()。
这里主要区别三个同步函数:cudaStreamSynchronize、CudaDeviceSynchronize 和 cudaThreadSynchronize。在文档中,这三个函数叫做barriers,只有满足一定的条件后,才能通过barriers向后执行。三者的区别如下:
cudaDeviceSynchronize():该方法将停止CPU端线程的执行,直到GPU端完成之前CUDA的任务,包括kernel函数、数据拷贝等。
cudaThreadSynchronize():该方法的作用和cudaDeviceSynchronize()基本相同,但它不是一个被推荐的方法,也许在后期版本的CUDA中会被删除。
cudaStreamSynchronize():这个方法接受一个stream ID,它将阻止CPU执行直到GPU端完成相应stream ID的所有CUDA任务,但其它stream中的CUDA任务可能执行完也可能没有执行完。
在CUDA里面,不同线程间的数据读写会彼此影响,这种影响的作用效果根据不同的线程组织单位和不同的读写对象是不同。
12 cuda 使用stream 必须使用 必须使用pinned内存(页锁定内存)
在使用异步的数据传输函数时,需要将主机内存定义为\textbf{固定内存}(pinned memory)。固定内存是相对于非固定内存,即\textbf{可分页内存}(pageable memory)的。操作系统有权在一个程序运行期间改变程序中使用的可分页主机内存的物理地址。相反,若主机中的内存声明为固定内存,则在程序运行期间,其物理地址将保持不变。如果将可分页内存传给~\verb"cudaMemcpyAsync()"~函数,则会导致同步传输,达不到重叠核函数执行与数据传输并发的效果。主机内存为可分页内存时,数据传输过程就不能用~GPU~中的~DMA,必须与主机同步。主机无法在发出数据传输的命令后立刻获得程序的控制权,从而无法实现不同CUDA流之间的并发。
固定主机内存的分配可以由以下两个~API~函数中的任何一个实现:
\begin{verbatim}
cudaError_t cudaMallocHost(void** ptr, size_t size);
cudaError_t cudaHostAlloc(void** ptr, size_t size, size_t flags);
\end{verbatim}
注意,第二个函数的名字中没有字母~\verb"M"。若函数~\verb"cudaHostAlloc"~的第三个参数取默认值~\verb"cudaHostAllocDefault",则以上两个函数完全等价。本书不讨论函数~\verb"cudaHostAlloc"~的第三个参数取其它值的用法。由以上函数分配的主机内存必须由如下函数释放:
\begin{verbatim}
cudaError_t cudaFreeHost(void* ptr);
\end{verbatim}
如果不小心用了~C++~中的~malloc~函数释放固定的主机内存,会出现运行时错误。
13 CUDA profile 使用
https://cloud.tencent.com/developer/article/1151488
14 cuda convolution
https://www.evl.uic.edu/sjames/cs525/final.html
15 cuda 各种内存访问速度的比较
全局内存:容量最大,可达几g,但读取速度最慢
常量内存:全局内存的一种缓存映射,能够令线程束以广播的方式读取
共享内存:距gpu核最近的内存,读取速度很快,能达到全局内存的10倍左右,但容量最小,按每个block算的
纹理内存:全局内存的另一种缓存映射,在某些方面比较有用。
寄存器:读取速度最快的存储单元,但是按数量算的,资源最有限。
16 . VS 将VS编译器设置为 CUDA编译器 : 生成依赖项-生成自定义- CUDA10.2
17 驱动的适配
https://docs.nvidia.com/deploy/cuda-compatibility/index.html
18 nvprof 使用
https://blog.csdn.net/u010454261/article/details/72628343
19 nvida 文档
20 查看nvidia 性能
nvidia-smi dmon
21 编程指南
https://docs.nvidia.com/cuda/cuda-c-programming-guide/
22 一个wrap 中尽量不要出现一部分线程执行if 一部分线程执行else , 因为这样的效率会很低
因为一个wrap的的任务是同时执行的, 先执行完的线程会等待后执行完的线程, 这样造成了thread的闲置
23 查看 nvidia-smi 参数的含义
nvidia-smi --help-query-gpu
24 PCIE 总线性能

25 GPU 硬件架构
https://blog.csdn.net/asasasaababab/article/details/80447254
26
Using Nsight Compute to Inspect your Kernels
https://devblogs.nvidia.com/using-nsight-compute-to-inspect-your-kernels/
27 nvidia-smi 的一些命令
锁频
nvidia-smi -i 1 -lgc 1300,1500
重置频率
nvidia-smi -i 1 -rgc
显示是否遇到功耗限制
nvidia-smi -q -l 1 -i 1 | grep "SW Power"
28 cuda 计时
cudaEvent_t start, stop;
float gpu_time = 0.0f;
cutilSafeCall( cudaEventCreate(&start) );
cutilSafeCall( cudaEventCreate(&stop) );
cudaEventRecord(start, );
<<< kernel >>>
cudaThreadSynchronize();
cudaEventRecord(stop, );
cudaEventSynchronize(stop);
cutilSafeCall( cudaEventElapsedTime(&gpu_time, start, stop) );
printf("Time spent: %.5f\n", total_elapsed_coeffs);
cudaEventDestroy(start);
cudaEventDestroy(stop);
29 : cuda lauchkernel
cuLaunchKernel ( CUfunction f, unsigned int gridDimX, unsigned int gridDimY, unsigned int gridDimZ, unsigned int blockDimX, unsigned int blockDimY, unsigned int blockDimZ,
unsigned int sharedMemBytes, CUstream hStream, void** kernelParams, void** extra )
30 cuda 函数指针做形参
typedef int(*funcptr) ();
__device__ int f() { return ; }
__device__ funcptr f_ptr = f;
__global__ void kernel(funcptr func)
{
int k = func();
printf("%d\n", k);
funcptr func2 = f; // does not use a global-scope variable
printf("%d\n", func2());
}
int main()
{
funcptr h_funcptr;
if (cudaSuccess != cudaMemcpyFromSymbol(&h_funcptr, f_ptr, sizeof(funcptr)))
printf("FAILED to get SYMBOL\n");
kernel << <, >> > (h_funcptr);
if (cudaDeviceSynchronize() != cudaSuccess)
printf("FAILED\n");
else
printf("SUCCEEDED\n");
}
CUDA 笔记的更多相关文章
- CUDA笔记12
这几天配置了新环境,而且流量不够了就没写. 看到CSDN一个人写了些机器学习的笔记,于是引用一下http://blog.csdn.net/yc461515457/article/details/504 ...
- CUDA笔记(11)
CUDA提供了一种cudaEvent_t的类型,这种类型Event可以统计GPU上面某一个任务或者代码段的精确运行时间 使用常量内存的光线跟踪器的性能比使用全局内存的性能提升了50% __consta ...
- CUDA笔记(八)
今天真正进入了攻坚期.不光是疲劳,主要是遇到的问题指数级上升,都是需要绕道的. 以visual profile来说,刚刚发现自己还没使用过. http://bbs.csdn.net/topics/39 ...
- CUDA笔记(七)
今天集中时间找程序的问题.于是发现: 首先,程序里的kernel想要调试,必须用nsight. 于是一堆找.http://www.nvidia.com/object/nsight.html http: ...
- CUDA笔记(六)
dim3是NVIDIA的CUDA编程中一种自定义的整型向量类型,基于用于指定维度的uint3 忽然发现需要再搞多机MPI的配置,多机GPU集群.好麻烦.. 这两天考完两门了,还剩下三门,并行计算太多了 ...
- CUDA笔记13
在新的环境上用CUTIL的时候,出现了问题.无法解析的外部符号 __imp_cutCheckCmdLineFlag 问题描述: kernel.cu.obj : error LNK2019: 无法解析的 ...
- CUDA笔记(十)
下午仔细研究了两个程序,然后搜了一下解决方法 http://blog.sina.com.cn/s/blog_6de28fbd01011cru.html http://blog.csdn.net/che ...
- CUDA笔记(九)
找了不知道多少教程,终于找到靠谱的nsight的: http://blog.csdn.net/mysniper11/article/details/8003644 还有两个视频的相关: http:// ...
- 基于Ubuntu14.04系统的nvidia tesla K40驱动和cuda 7.5安装笔记
基于Ubuntu14.04系统的nvidia tesla K40驱动和cuda 7.5安装笔记 飞翔的蜘蛛人 注1:本人新手,文章中不准确的地方,欢迎批评指正 注2:知识储备应达到Linux入门级水平 ...
随机推荐
- linux内核中设备树的维护者仓库地址
1. 仓库地址 git://git.kernel.org/pub/scm/linux/kernel/git/robh/linux.git https://kernel.googlesource.com ...
- python下multiprocessing和gevent的组合使用
python下multiprocessing和gevent的组合使用 对于有些人来说Gevent和multiprocessing组合在一起使用算是个又高大上又奇葩的工作模式. Python的多线程受制 ...
- MySQL数据库备份之xtrabackup工具使用
一.Xtrabackup备份介绍及原理 二.Xtrabackup的安装 1.在centos7上基于yum源安装percona-xtrabackup软件 [root@node7 ~]# yum -y i ...
- Selenium ? 也要学...!
一.selenium 简介 Selenium是ThroughtWorks公司一个强大的开源Web功能测试工具系列,包括Selenium-IDE.Selenium-RC.Selenium-Webdriv ...
- nginx 工作原理总结
1. Nginx的模块与工作原理 Nginx由内核和模块组成,其中,内核的设计非常微小和简洁,完成的工作也非常简单,仅仅通过查找配置文件将客户端请求映射到一个location block(locat ...
- 【转】Entity Framework简介
Entity Framework Core 可基于现有数据库创建模型,也可基于模型创建数据库. 以下文字来源于:http://www.entityframeworktutorial.net/what- ...
- cent8安装postgres
postgres是一款免费.开源的对象型关系数据库,其在cent8的安装方式与cent7的不太一样,特此记录. 步骤: 1 安装postgres server dnf install postgres ...
- 【leetcode算法-简单】38. 报数
[题目描述] 报数序列是一个整数序列,按照其中的整数的顺序进行报数,得到下一个数.其前五项如下: 1. 12. 113. 214. 12115. 1112211 被读作 "one 1&qu ...
- 乐字节Java反射之四:反射相关操作
大家好,乐字节小乐继续为Java初学者讲述Java基础知识.上次说到乐字节Java反射之三:方法.数组.类加载器,这次是Java反射之四:反射相关操作 1.操作属性 //1.获取Class对象 Cla ...
- Python 用hashlib求中文字符串的MD5值 (转自 haungrui的专栏)
使用过hashlib库的朋友想必都遇到过以下的错误吧:“Unicode-objects must be encoded before hashing”,意思是在进行md5哈希运算前,需要对数据进行编码 ...