爬虫(十七):scrapy分布式原理
一:scrapy工作流程
scrapy单机架构:
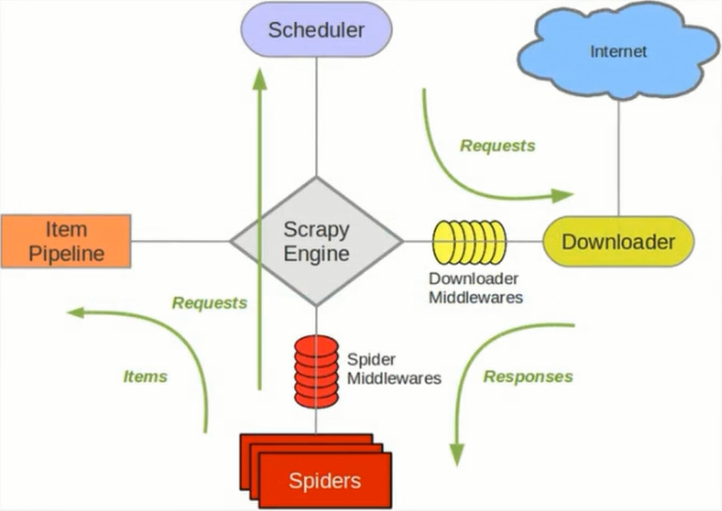
单主机爬虫架构:

分布式爬虫架构:

这里重要的就是我的队列通过什么维护?
这里一般我们通过Redis为维护,Redis,非关系型数据库,Key-Value形式存储,结构灵活。
并且redis是内存中的数据结构存储系统,处理速度快,提供队列集合等多种存储结构,方便队列维护
如何去重?
这里借助redis的集合,redis提供集合数据结构,在redis集合中存储每个request的指纹
在向request队列中加入Request前先验证这个Request的指纹是否已经加入集合中。如果已经存在则不添加到request队列中,如果不存在,则将request加入到队列并将指纹加入集合
如何防止中断?如果某个slave因为特殊原因宕机,如何解决?
这里是做了启动判断,在每台slave的Scrapy启动的时候都会判断当前redis request队列是否为空
如果不为空,则从队列中获取下一个request执行爬取。如果为空则重新开始爬取,第一台丛集执行爬取向队列中添加request
如何实现上述这种架构?
这里有一个scrapy-redis的库,为我们提供了上述的这些功能
scrapy-redis改写了Scrapy的调度器,队列等组件,利用他可以方便的实现Scrapy分布式架构
关于scrapy-redis的地址--》scrapy-redis GitHub地址
二:搭建分布式爬虫
参考--》官网地址
前提是要安装scrapy_redis模块:pip install scrapy_redis
这里的爬虫代码是用的之前写过的爬取知乎用户信息的爬虫
修改该settings中的配置信息:
替换scrapy调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
添加去重的class
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
添加pipeline
如果添加这行配置,每次爬取的数据也都会入到redis数据库中,所以一般这里不做这个配置
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 300
}
共享的爬取队列,这里用需要redis的连接信息
这里的user:pass表示用户名和密码,如果没有则为空就可以
REDIS_URL = 'redis://user:pass@hostname:9001'
设置为为True则不会清空redis里的dupefilter和requests队列
这样设置后指纹和请求队列则会一直保存在redis数据库中,默认为False,一般不进行设置
SCHEDULER_PERSIST = True
设置重启爬虫时是否清空爬取队列
这样每次重启爬虫都会清空指纹和请求队列,一般设置为False
SCHEDULER_FLUSH_ON_START=True
分布式
将上述更改后的代码拷贝的各个服务器,当然关于数据库这里可以在每个服务器上都安装数据,也可以共用一个数据,我这里方面是连接的同一个mongodb数据库,当然各个服务器上也不能忘记:
所有的服务器都要安装scrapy,scrapy_redis,pymongo
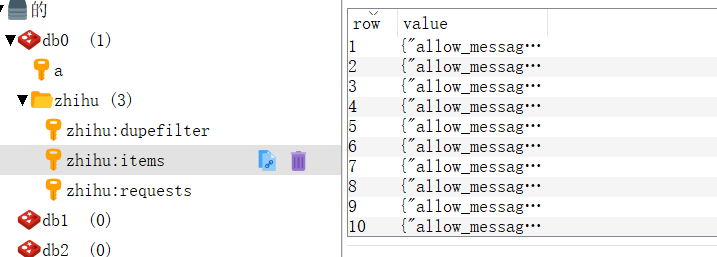
这样运行各个爬虫程序启动后,在redis数据库就可以看到如下内容,dupefilter是指纹队列,requests是请求队列
项目代码GitHub地址--》分布式爬取知乎
爬虫(十七):scrapy分布式原理的更多相关文章
- Python 爬虫之 Scrapy 分布式原理以及部署
Scrapy分布式原理 关于Scrapy工作流程 Scrapy单机架构 上图的架构其实就是一种单机架构,只在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键就是共享 ...
- scrapy分布式原理
scrapy分布式原理 关于Scrapy工作流程回顾 Scrapy单机架构 上图的架构其实就是一种单机架构,只在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键 ...
- Python爬虫从入门到放弃(二十)之 Scrapy分布式原理
关于Scrapy工作流程回顾 Scrapy单机架构 上图的架构其实就是一种单机架构,只在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键就是共享爬取队列. 分布式架 ...
- Python爬虫【五】Scrapy分布式原理笔记
Scrapy单机架构 在这里scrapy的核心是scrapy引擎,它通过里面的一个调度器来调度一个request的队列,将request发给downloader,然后来执行request请求 但是这些 ...
- Python之爬虫(二十二) Scrapy分布式原理
关于Scrapy工作流程回顾 Scrapy单机架构 上图的架构其实就是一种单机架构,只在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键就是共享爬取队列. 分布式架 ...
- 第三百五十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy分布式爬虫要点
第三百五十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy分布式爬虫要点 1.分布式爬虫原理 2.分布式爬虫优点 3.分布式爬虫需要解决的问题
- python网络爬虫之scrapy 工程创建以及原理介绍
执行scrapy startproject XXXX的命令,就会在对应的目录下生成工程 在pycharm中打开此工程目录:并在Run中选择Edit Configuration 点击+创建一个Pytho ...
- scrapy分布式爬虫scrapy_redis二篇
=============================================================== Scrapy-Redis分布式爬虫框架 ================ ...
- 一篇文章教会你理解Scrapy网络爬虫框架的工作原理和数据采集过程
今天小编给大家详细的讲解一下Scrapy爬虫框架,希望对大家的学习有帮助. 1.Scrapy爬虫框架 Scrapy是一个使用Python编程语言编写的爬虫框架,任何人都可以根据自己的需求进行修改,并且 ...
随机推荐
- Spring的事件监听ApplicationListener
ApplicationListener是Spring事件机制的一部分,与抽象类ApplicationEvent类配合来完成ApplicationContext的事件机制. 如果容器中存在Applica ...
- 修改mysql远程数据库链接密码(转)
原文:https://blog.csdn.net/jianjiao7869/article/details/81029171 原来root用户有两个,一个只允许localhost登陆,一个可运行所有用 ...
- springboot 使用consul 读取配置文件(遇到的坑太多,没记录)
最终成功版. pom引入mavn依赖: <!--consul--> <dependency> <groupId>org.springframework.cloud& ...
- Spring循环依赖的三种方式以及解决办法
一. 什么是循环依赖? 循环依赖其实就是循环引用,也就是两个或者两个以上的bean互相持有对方,最终形成闭环.比如A依赖于B,B依赖于C,C又依赖于A.如下图: 注意,这里不是函数的循环调用,是对象的 ...
- 哈夫曼树详解——PHP代码实现
在介绍哈夫曼树之前需要先了解一些专业术语 路径和路径长度 在一棵树中,从一个结点往下可以达到的孩子或孙子结点之间的通路,称为路径.通路中分支的数目称为路径长度.若规定根结点的层数为1,则从根结点到第L ...
- Integer和int踩过的坑
在做SSM项目时发现一个有趣的bug,在这里记录一下. 数据库表如下: 实体类:grade字段初始设定为int类型 在用mybatis对第三条数据进行修改时,希望赋值的更改,未赋值的不更改,测试运行 ...
- nginx的proxy模块详解以及参数
文章来源 运维公会:nginx的proxy模块详解以及参数 使用nginx配置代理的时候,肯定是要用到http_proxy模块.这个模块也是在安装nginx的时候默认安装.它的作用就是将请求转发到相应 ...
- WinServer-SMTP服务
摘要 SMTP服务是用来发送邮件的,常用于代码中发送邮件,不能接收.本章介绍SMTP服务的安装,配置. 搭建F5负载均衡集群注意事项: 1.集群不能与exchang在同网段,否则发不出邮件. 2.AP ...
- inotify文件监控
参考:xxxx /*************************************************************************\* Copyright (C) M ...
- spark 实现多文件输出
需求 不同的key输出到不同的文件 txt文件 multiple.txt 中国;22 美国;4342 中国;123 日本;44 日本;6 美国;55 美国;43765 日本;786 日本;55 sca ...