《浏览器工作原理与实践》<04>从输入URL到页面展示,这中间发生了什么?
“在浏览器里,从输入 URL 到页面展示,这中间发生了什么? ”这是一道经典的面试题,能比较全面地考察应聘者知识的掌握程度,其中涉及到了网络、操作系统、Web 等一系列的知识。
在面试应聘者时也必问这道题,但遗憾的是大多数人只能回答其中部分零散的知识点,并不能将这些知识点串联成线,无法系统而又全面地回答这个问题。
那么今天我们就一起来探索下这个流程,下图是梳理出的“从输入 URL 到页面展示完整流程示意图”:
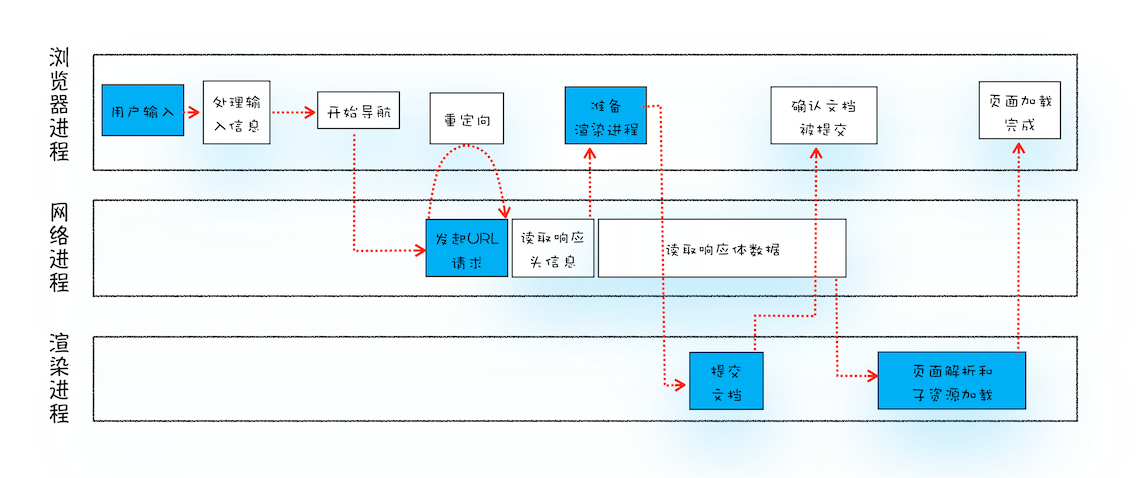
从图中可以看出,整个过程需要各个进程之间的配合,所以在开始正式流程之前,我们还是先来快速回顾下浏览器进程、渲染进程和网络进程的主要职责。
1.浏览器进程主要负责用户交互、子进程管理和文件储存等功能。
2.网络进程是面向渲染进程和浏览器进程等提供网络下载功能。
3.渲染进程的主要职责是把从网络下载的 HTML、JavaScript、CSS、图片等资源解析为可以显示和交互的页面。因为渲染进程所有的内容都是通过网络获取的,会存在一些恶意代码利用浏览器漏洞对系统进行攻击,所以运行在渲染进程里面的代码是不被信任的。这也是为什么 Chrome 会让渲染进程运行在安全沙箱里,就是为了保证系统的安全。
通过分析,这个过程可以大致描述为如下:
首先,用户从浏览器进程里输入请求信息。
然后,网络进程发起 URL 请求。
服务器响应 URL 请求之后,浏览器进程就又要开始准备渲染进程了。
渲染进程准备好之后,就需要通知浏览器进程:“我已经准备好了,可以向用户展示页面状态了”,我们把这个渲染进程通知浏览器进程的阶段,称为“提交文档”阶段。
浏览器进程接收到渲染进程“提交文档”的消息之后,便开始移除之前旧的文档,然后通知渲染进程“文档已提交”,此时渲染进程便进入了“解析页面”阶段。
这其中,用户发出 URL 请求到页面开始解析的这个过程,就叫做导航。
从输入 URL 到页面展示
现在我们知道了浏览器几个主要进程的职责,还有在导航过程中需要经历的几个主要的阶段,下面我们就来详细分析下这些阶段,同时也就解答了开头所说的那道经典的面试题。
1. 用户输入
当用户在地址栏中输入一个查询关键字时,地址栏会判断输入的关键字是搜索内容,还是请求的 URL。
如果是搜索内容,地址栏会使用浏览器默认的搜索引擎,来合成新的带搜索关键字的 URL。
如果判断输入内容符合 URL 规则,比如输入的是 time.geekbang.org,那么地址栏会根据规则,把这段内容加上协议,合成为完整的 URL,如 https://time.geekbang.org。
当用户输入关键字并键入回车之后,这意味着当前页面即将要被替换成新的页面,不过在这个流程继续之前,浏览器还给了当前页面一次执行 beforeunload 事件的机会,beforeunload 事件允许页面在退出之前执行一些数据清理操作,还可以询问用户是否要离开当前页面,比如当前页面可能有未提交完成的表单等情况,因此用户可以通过 beforeunload 事件来取消导航,让浏览器不再执行任何后续工作。当前页面没有监听 beforeunload 事件或者同意了继续后续流程,那么浏览器便进入下图的状态:
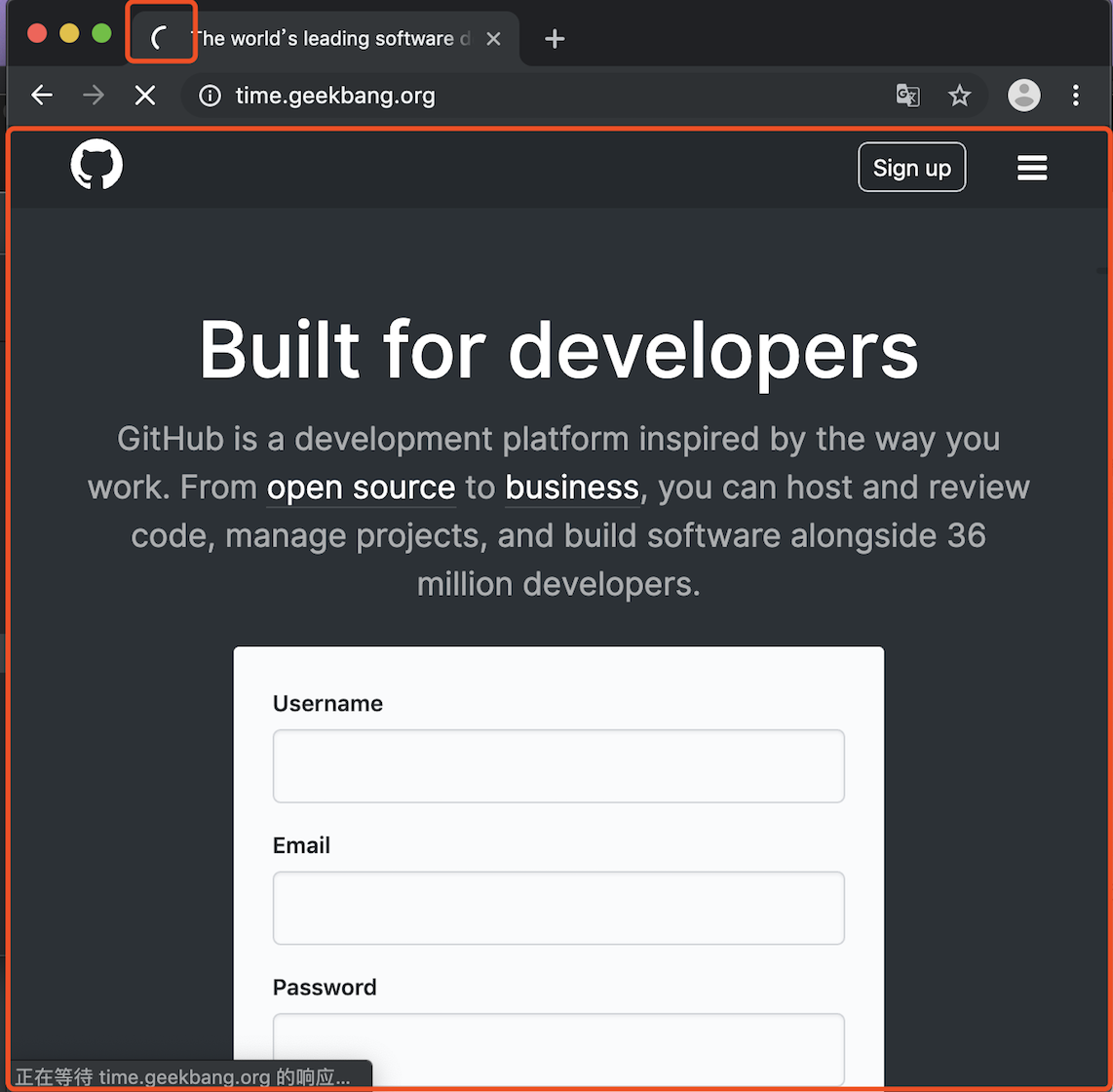
从图中可以看出,当浏览器刚开始加载一个地址之后,标签页上的图标便进入了加载状态。但此时图中页面显示的依然是之前打开的页面内容,并没立即替换为极客时间的页面。因为需要等待提交文档阶段,页面内容才会被替换。
2. URL 请求过程
接下来,便进入了页面资源请求过程。这时,浏览器进程会通过进程间通信(IPC)把 URL 请求发送至网络进程,网络进程接收到 URL 请求后,会在这里发起真正的 URL 请求流程。那具体流程是怎样的呢?
首先,网络进程会查找本地缓存是否缓存了该资源。如果有缓存资源,那么直接返回资源给浏览器进程;如果在缓存中没有查找到资源,那么直接进入网络请求流程。这请求前的第一步是要进行 DNS 解析,以获取请求域名的服务器 IP 地址。如果请求协议是 HTTPS,那么还需要建立 TLS 连接。
接下来就是利用 IP 地址和服务器建立 TCP 连接。连接建立之后,浏览器端会构建请求行、请求头等信息,并把和该域名相关的 Cookie 等数据附加到请求头中,然后向服务器发送构建的请求信息。
服务器接收到请求信息后,会根据请求信息生成响应数据(包括响应行、响应头和响应体等信息),并发给网络进程。等网络进程接收了响应行和响应头之后,就开始解析响应头的内容了。(为了方便讲述,下面我将服务器返回的响应头和响应行统称为响应头。)
(1)重定向
在接收到服务器返回的响应头后,网络进程开始解析响应头,如果发现返回的状态码是 301 或者 302,那么说明服务器需要浏览器重定向到其他 URL。这时网络进程会从响应头的 Location 字段里面读取重定向的地址,然后再发起新的 HTTP 或者 HTTPS 请求,一切又重头开始了。
curl -I http://time.geekbang.org/
curl -I + URL的命令是接收服务器返回的响应头的信息。执行命令后,我们看到服务器返回的响应头信息如下:

从图中可以看出,极客时间服务器会通过重定向的方式把所有 HTTP 请求转换为 HTTPS 请求。也就是说你使用 HTTP 向极客时间服务器请求时,服务器会返回一个包含有 301 或者 302 状态码响应头,并把响应头的 Location 字段中填上 HTTPS 的地址,这就是告诉了浏览器要重新导航到新的地址上。
下面我们再使用 HTTPS 协议对极客时间发起请求,看看服务器的响应头信息是什么样子的。
curl -I https://time.geekbang.org/
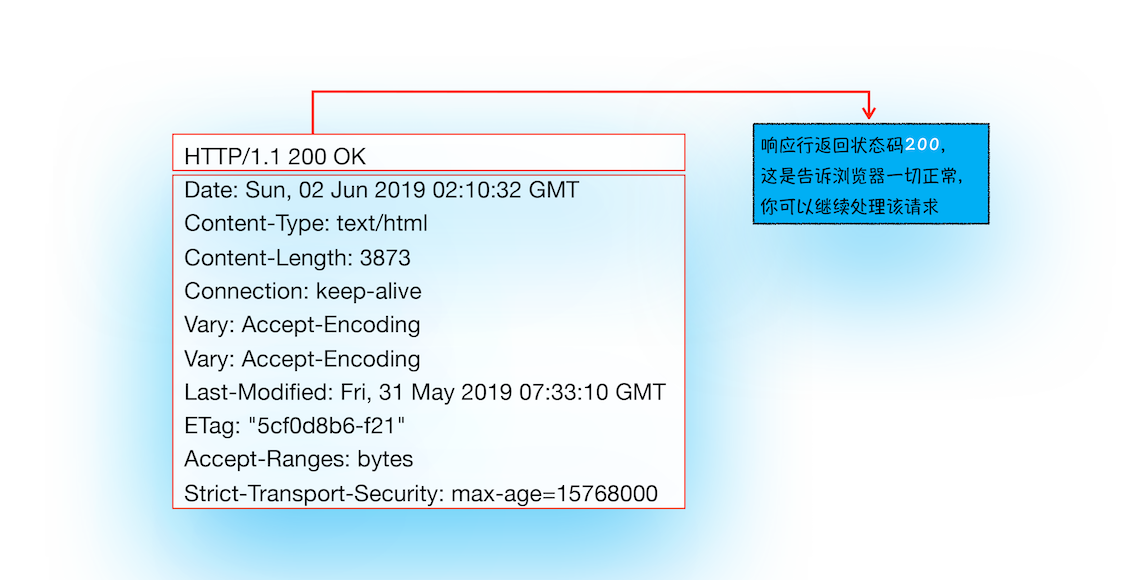
从图中可以看出,服务器返回的响应头的状态码是 200,这是告诉浏览器一切正常,可以继续往下处理该请求了。
(2)响应数据类型处理
在处理了跳转信息之后,我们继续导航流程的分析。URL 请求的数据类型,有时候是一个下载类型,有时候是正常的 HTML 页面,那么浏览器是如何区分它们呢?
答案是 Content-Type。Content-Type 是 HTTP 头中一个非常重要的字段, 它告诉浏览器服务器返回的响应体数据是什么类型,然后浏览器会根据 Content-Type 的值来决定如何显示响应体的内容。这里我们还是以极客时间为例,看看极客时间官网返回的 Content-Type 值是什么。在终端输入以下命令:
这里我们还是以极客时间为例,看看极客时间官网返回的 Content-Type 值是什么。在终端输入以下命令:
curl -I https://time.geekbang.org/
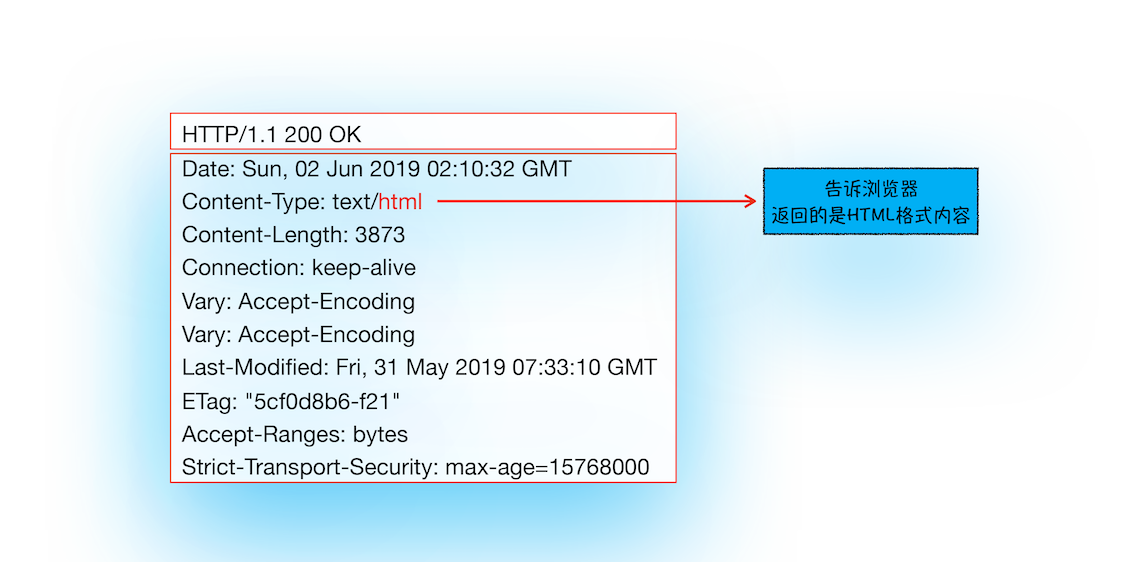
从图中可以看到,响应头中的 Content-type 字段的值是 text/html,这就是告诉浏览器,服务器返回的数据是 HTML 格式。
如果服务器配置 Content-Type 不正确,比如将 text/html 类型配置成 application/octet-stream 类型,那么浏览器可能会曲解文件内容,比如会将一个本来是用来展示的页面,变成了一个下载文件。
所以,不同 Content-Type 的后续处理流程也截然不同。如果 Content-Type 字段的值被浏览器判断为下载类型,那么该请求会被提交给浏览器的下载管理器,同时该 URL 请求的导航流程就此结束。但如果是 HTML,那么浏览器则会继续进行导航流程。由于 Chrome 的页面渲染是运行在渲染进程中的,所以接下来就需要准备渲染进程了。
3. 准备渲染进程
默认情况下,Chrome 会为每个页面分配一个渲染进程,也就是说,每打开一个新页面就会配套创建一个新的渲染进程。但是,也有一些例外,在某些情况下,浏览器会让多个页面直接运行在同一个渲染进程中。比如我从极客时间的首页里面打开了另外一个页面——算法训练营,我们看下图的 Chrome 的任务管理器截图: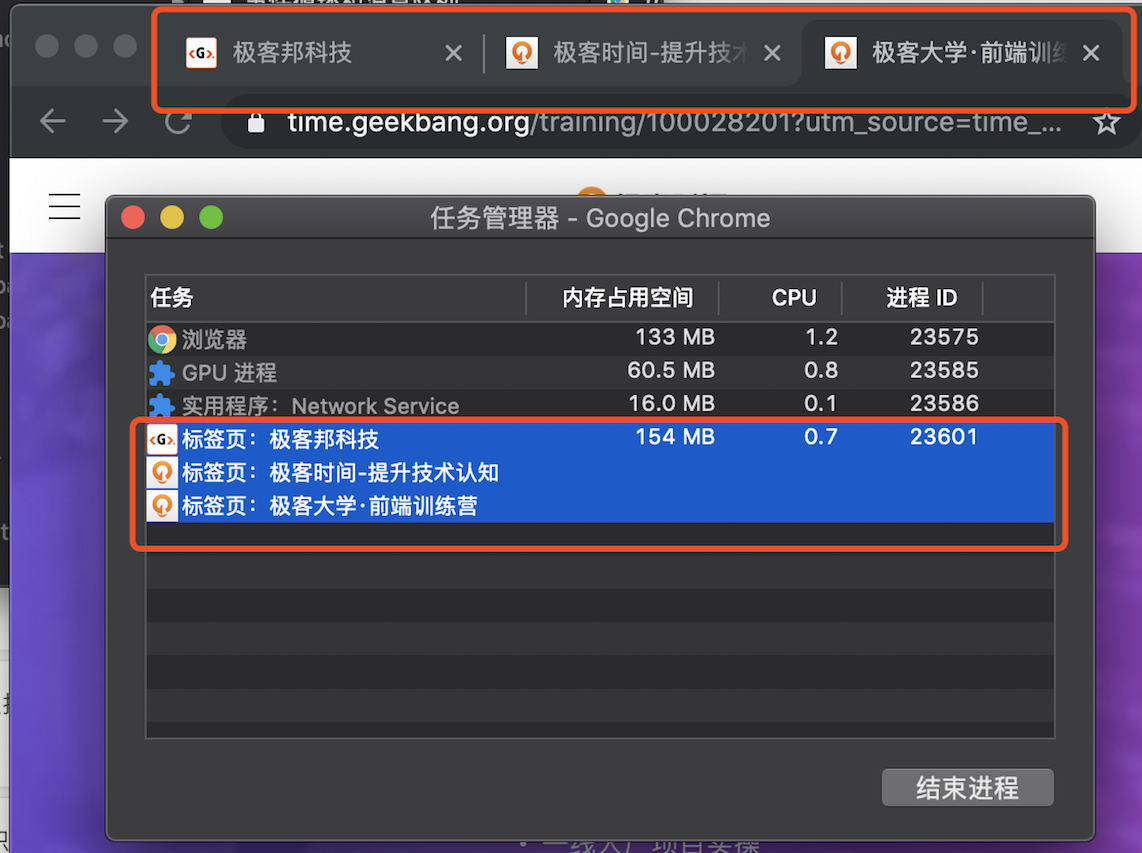
从图中可以看出,打开的这三个页面都是运行在同一个渲染进程中,进程 ID 是 23601。
那什么情况下多个页面会同时运行在一个渲染进程中呢?
要解决这个问题,我们就需要先了解下什么是同一站点(same-site)。具体地讲,我们将“同一站点”定义为根域名(例如,geekbang.org)加上协议(例如,https:// 或者 http://),还包含了该根域名下的所有子域名和不同的端口,比如下面这三个:
https://time.geekbang.org
https://www.geekbang.org
https://www.geekbang.org:8080
它们都是属于同一站点,因为它们的协议都是 HTTPS,而且根域名也都是 geekbang.org。
Chrome 的默认策略是,每个标签对应一个渲染进程。但如果从一个页面打开了另一个新页面,而新页面和当前页面属于同一站点的话,那么新页面会复用父页面的渲染进程。官方把这个默认策略叫 process-per-site-instance。
总结来说,打开一个新页面采用的渲染进程策略就是:
通常情况下,打开新的页面都会使用单独的渲染进程;如果从 A 页面打开 B 页面,且 A 和 B 都属于同一站点的话,那么 B 页面复用 A 页面的渲染进程;
如果是其他情况,浏览器进程则会为 B 创建一个新的渲染进程。
渲染进程准备好之后,还不能立即进入文档解析状态,因为此时的文档数据还在网络进程中,并没有提交给渲染进程,所以下一步就进入了提交文档阶段。
4. 提交文档
在上面我们分析过了,渲染进程准备好之后,它就会通知浏览器进程,可以替换当前旧的文档了,具体地讲,需要经过下列几个步骤:
1.首先“提交文档”的消息是由渲染进程发出给浏览器进程的,这是告诉浏览器进程,它已经准备好了,可以执行解析渲染等后续操作了。
2.浏览器进程接收到当前渲染进程的“提交文档”消息后,便开始清理当前的旧文档,然后会发出“确认提交”的消息给渲染进程。同时,浏览器进程会更新浏览器界面状态,包括了安全状态、地址栏的 URL、前进后退的历史状态,并更新 Web 页面。
3.当渲染进程接收到“确认提交”的消息后,便开始执行解析数据、下载子资源等后续流程,并实时向浏览器进程更新最新的渲染状态。
其中,当浏览器进程确认提交之后,更新内容如下图所示:
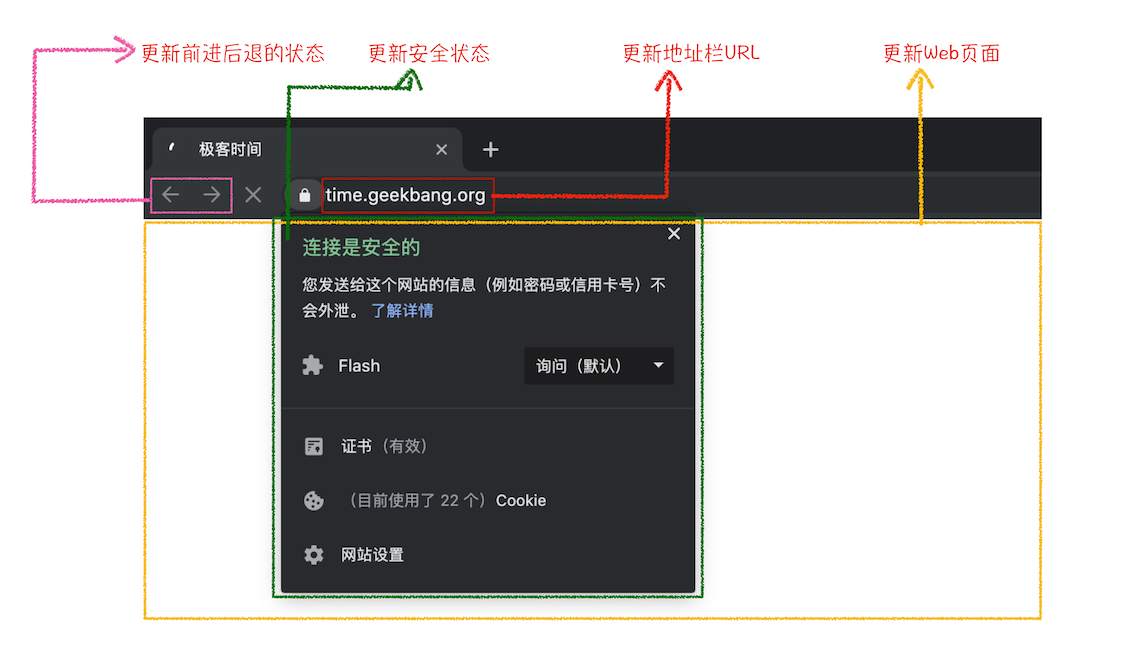
这也就解释了为什么在浏览器的地址栏里面输入了一个地址后,之前的页面没有立马消失,而是要加载一会儿才会更新页面。
到这里,一个完整的导航流程就“走”完了,这之后就要进入渲染阶段了。
5. 渲染阶段
一旦文档被提交,渲染进程便开始页面解析和子资源加载了,关于这个阶段的完整过程,我会在下一篇文章中来专门介绍。这里你只需要先了解一旦页面生成完成,渲染进程会发送一个消息给浏览器进程,浏览器接收到消息后,会停止标签图标上的加载动画。如下所示:

至此,一个完整的页面就生成了。那文章开头的“从输入 URL 到页面展示,这中间发生了什么?”这个过程极其“串联”的问题也就解决了。
后续会讲讲页面的渲染过程
注: 本文出自极客时间(浏览器工作原理与实践),请大家多多支持李兵老师。如有侵权,请及时告知。
《浏览器工作原理与实践》<04>从输入URL到页面展示,这中间发生了什么?的更多相关文章
- 从输入 URL 到页面展示,到底发生了什么
从输入 URL 到页面展示,到底发生了什么 1.输入URL 当我们开始在浏览器中输入网址的时候,浏览器其实就已经在智能的匹配可能得 url 了,他会从历史记录,书签等地方,找到已经输入的字符串可能对应 ...
- 《浏览器工作原理与实践》<11>this:从JavaScript执行上下文的视角讲清楚this
在上篇文章中,我们讲了词法作用域.作用域链以及闭包,接下来我们分析一下这段代码: var bar = { myName:"time.geekbang.com", printName ...
- 《浏览器工作原理与实践》<07>变量提升:JavaScript代码是按顺序执行的吗?
讲解完宏观视角下的浏览器后,从这篇文章开始,我们就进入下一个新的模块了,这里我会对 JavaScript 执行原理做深入介绍. 今天在该模块的第一篇文章,我们主要讲解执行上下文相关的内容.那为什么先讲 ...
- 《浏览器工作原理与实践》<05>渲染流程(上):HTML、CSS和JavaScript,是如何变成页面的?
在上一篇文章中我们介绍了导航相关的流程,那导航被提交后又会怎么样呢?就进入了渲染阶段.这个阶段很重要,了解其相关流程能让你“看透”页面是如何工作的,有了这些知识,你可以解决一系列相关的问题,比如能熟练 ...
- 《浏览器工作原理与实践》<03>HTTP请求流程:为什么很多站点第二次打开速度会很快?
一个 TCP 连接过程包括了建立连接.传输数据和断开连接三个阶段. 而 HTTP 协议,正是建立在 TCP 连接基础之上的.HTTP 是一种允许浏览器向服务器获取资源的协议,是 Web 的基础,通常由 ...
- 《浏览器工作原理与实践》 <12>栈空间和堆空间:数据是如何存储的?
对于前端开发者来说,JavaScript 的内存机制是一个不被经常提及的概念 ,因此很容易被忽视.特别是一些非计算机专业的同学,对内存机制可能没有非常清晰的认识,甚至有些同学根本就不知道 JavaSc ...
- 《浏览器工作原理与实践》<10>作用域链和闭包 :代码中出现相同的变量,JavaScript引擎是如何选择的?
在上一篇文章中我们讲到了什么是作用域,以及 ES6 是如何通过变量环境和词法环境来同时支持变量提升和块级作用域,在最后我们也提到了如何通过词法环境和变量环境来查找变量,这其中就涉及到作用域链的概念. ...
- 《浏览器工作原理与实践》<09>块级作用域:var缺陷以及为什么要引入let和const?
在前面我们已经讲解了 JavaScript 中变量提升的相关内容,正是由于 JavaScript 存在变量提升这种特性,从而导致了很多与直觉不符的代码,这也是 JavaScript 的一个重要设计缺陷 ...
- 《浏览器工作原理与实践》<08>调用栈:为什么JavaScript代码会出现栈溢出?
在上篇文章中,我们讲到了,当一段代码被执行时,JavaScript 引擎先会对其进行编译,并创建执行上下文.但是并没有明确说明到底什么样的代码才算符合规范. 那么接下来我们就来明确下,哪些情况下代码才 ...
随机推荐
- 【leetcode】521. Longest Uncommon Subsequence I
problem 521. Longest Uncommon Subsequence I 最长非共同子序列之一 题意: 两个字符串的情况很少,如果两个字符串相等,那么一定没有非共同子序列,反之,如果两个 ...
- shell之判断文件是否存在
#!/bin/sh myPath="/var/log/httpd/" myFile="/var /log/httpd/access.log" #这里的-x 参数 ...
- Docker Java程序镜像制作
Docker Java程序镜像制作 制作前的准备 jre:不需要完整的jdk,jre即可,到Oracle进行下载即可,下载链接,根据自己的情况进行选择,这里选择jre-8u221-linux-x64. ...
- PJzhang:钓鱼域名生成工具urlcrazy
猫宁!!! www.baidu.com和www.baibu.com是不是很相似,urlcrazy可以自动生成一大批. 这款工具的作者是Andrew Horton 工具下载地址: http://www. ...
- Volatility取证使用笔记
最近简单的了解了一下Volatility这个开源的取证框架,这个框架能够对导出的内存镜像镜像分析,能过通过获取内核的数据结构,使用插件获取内存的详细情况和运行状态,同时可以直接dump系统文件,屏幕截 ...
- leetcode548 Split Array with Equal Sum
思路: 使用哈希表降低复杂度.具体来说: 枚举j: 枚举i,如果sum[i - 1] == sum[j - 1] - sum[i],就用哈希表把sum[i - 1]记录下来: 枚举k,如果sum[k ...
- 【计算机视觉】关于OpenCV中GPU配置编译的相关事项
[计算机视觉]关于OpenCV中GPU配置编译的相关事项 标签(空格分隔): [计算机视觉] 前一段发现了OpenCV中关于GPU以及opencl的相关知识,打算升级一下对OpenCV的使用,但是发现 ...
- java新特性stream
java新特性stream,也称为流式编程. 在学习stream之前先了解一下java内置的四大函数 第一种函数式函数,后面是lambda表达式写法 /*Function<String,Inte ...
- 记一次 vmware ESXI 升级
旧服务器的esxi版本为 60(6765062),计划安装成为最新版 的为ESXI 60 (14513180),中间波折遇坑多次,现记录如下: 一.开启ESXI的SSH 访问权限(可以通过按F2进入 ...
- Git Bash输错账号密码如何重新输入
很多时候我们容易在Git Bash操作的时候,不慎输入错误的用户名或密码,此时一直提示: remote: Incorrect username or password ( access token ) ...