19.通过MAPREDUCE 把收集数据进行清洗
在eclipse软件里创建一个maven项目
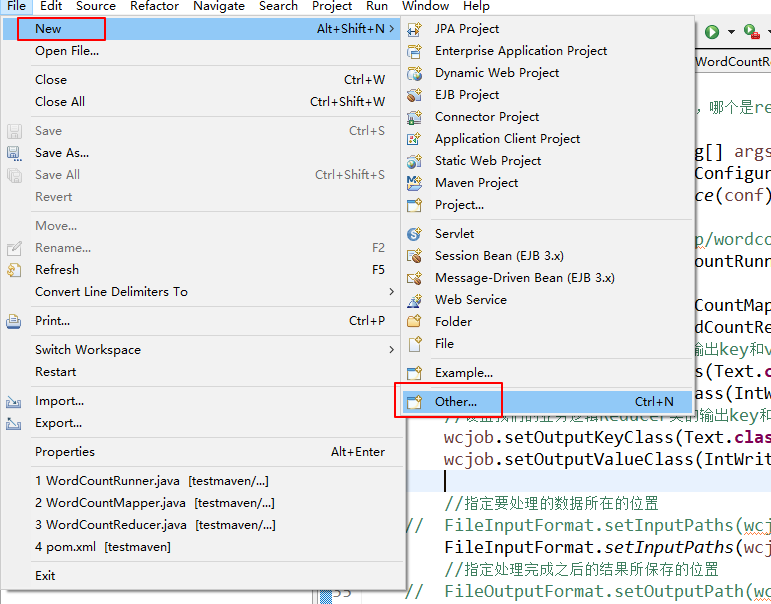
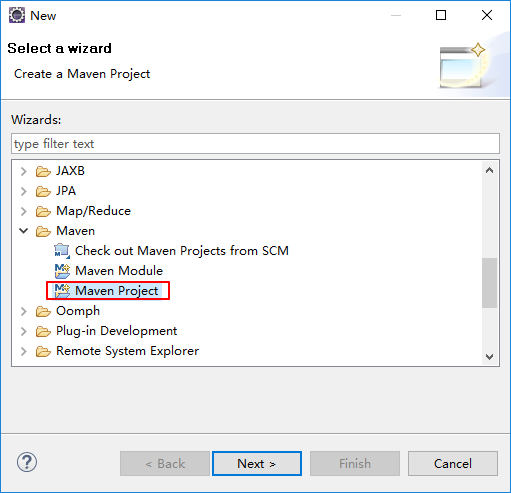
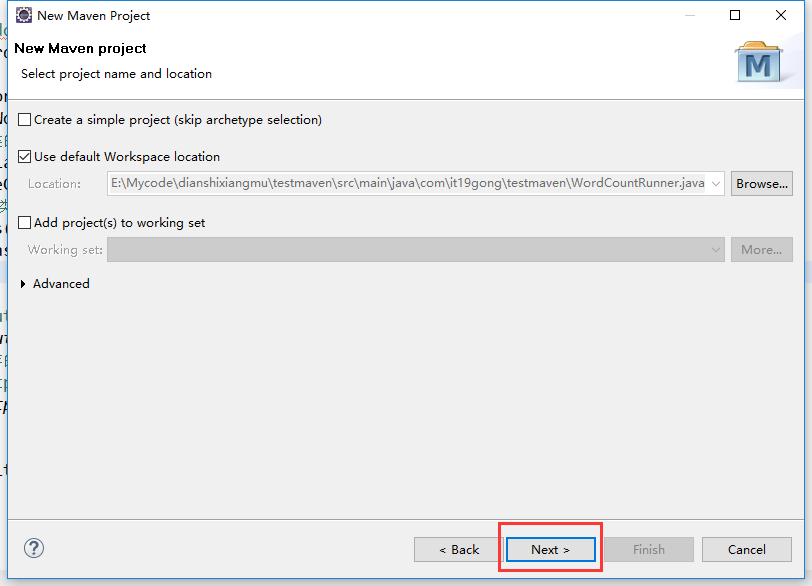
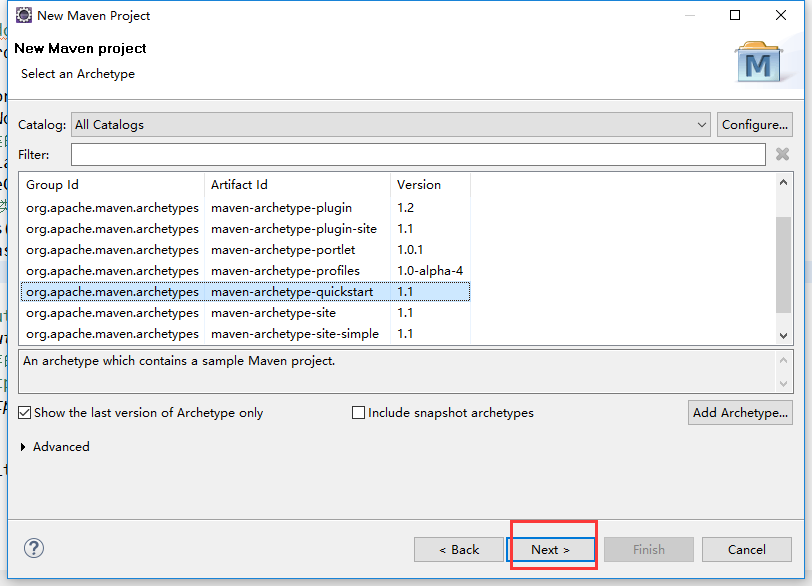
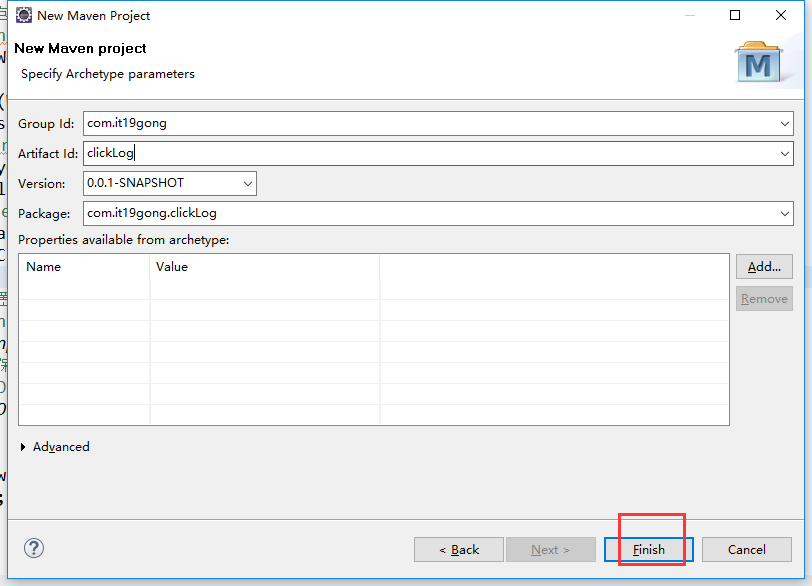
jdk要换成本地安装的1.8版本的
加载pom.xml文件
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>com.it19gong</groupId>
<artifactId>clickLog</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging> <name>clickLog</name>
<url>http://maven.apache.org</url> <properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties> <dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0</version>
</dependency> <dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.8</version>
<scope>system</scope>
<systemPath>E:/software/jdk1.8/lib/tools.jar</systemPath>
</dependency> <dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>2.1.0</version>
</dependency> <dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.33</version>
</dependency>
</dependencies> </project>
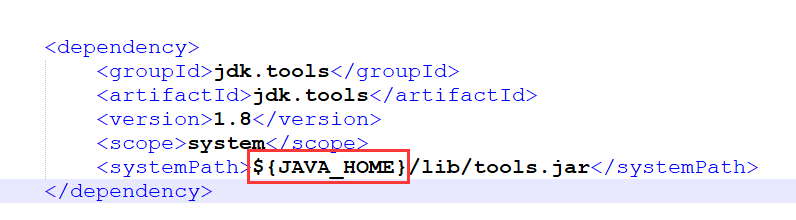
在加载依赖包的时候如果出现错误,在仓库里找不到1.8jdk.tools
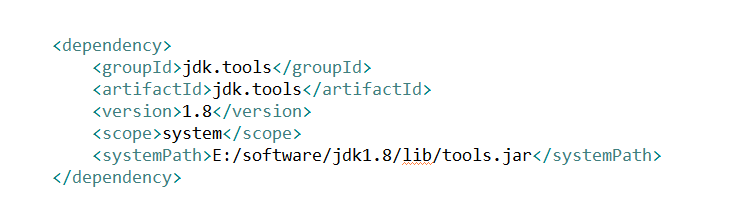
在这个地方改成本地的jdk绝对路径,再重新加载一次maven的依赖包
我这里修改成
在项目下新建AccessLogPreProcessMapper类
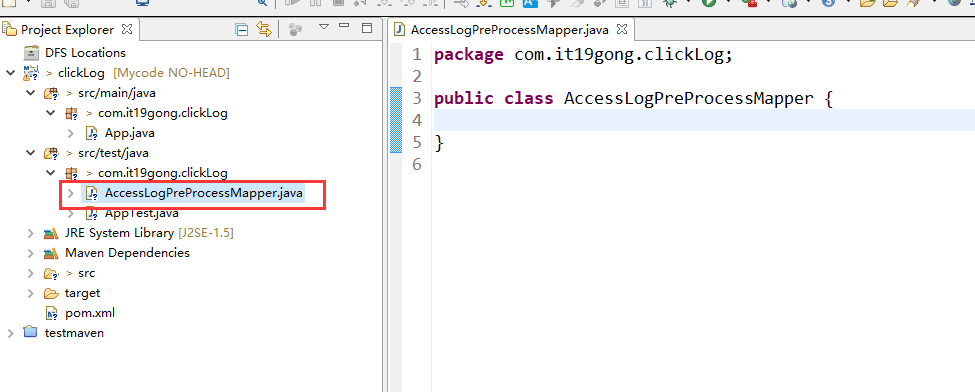
package com.it19gong.clickLog; import java.io.IOException; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; public class AccessLogPreProcessMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
Text text = new Text();
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
String itr[] = value.toString().split(" ");
if (itr.length < 11)
{
return;
}
String ip = itr[0];
String date = AnalysisNginxTool.nginxDateStmpToDate(itr[3]);
String url = itr[6];
String upFlow = itr[9]; text.set(ip+","+date+","+url+","+upFlow);
context.write(text, NullWritable.get()); }
}
创建AnalysisNginxTool类
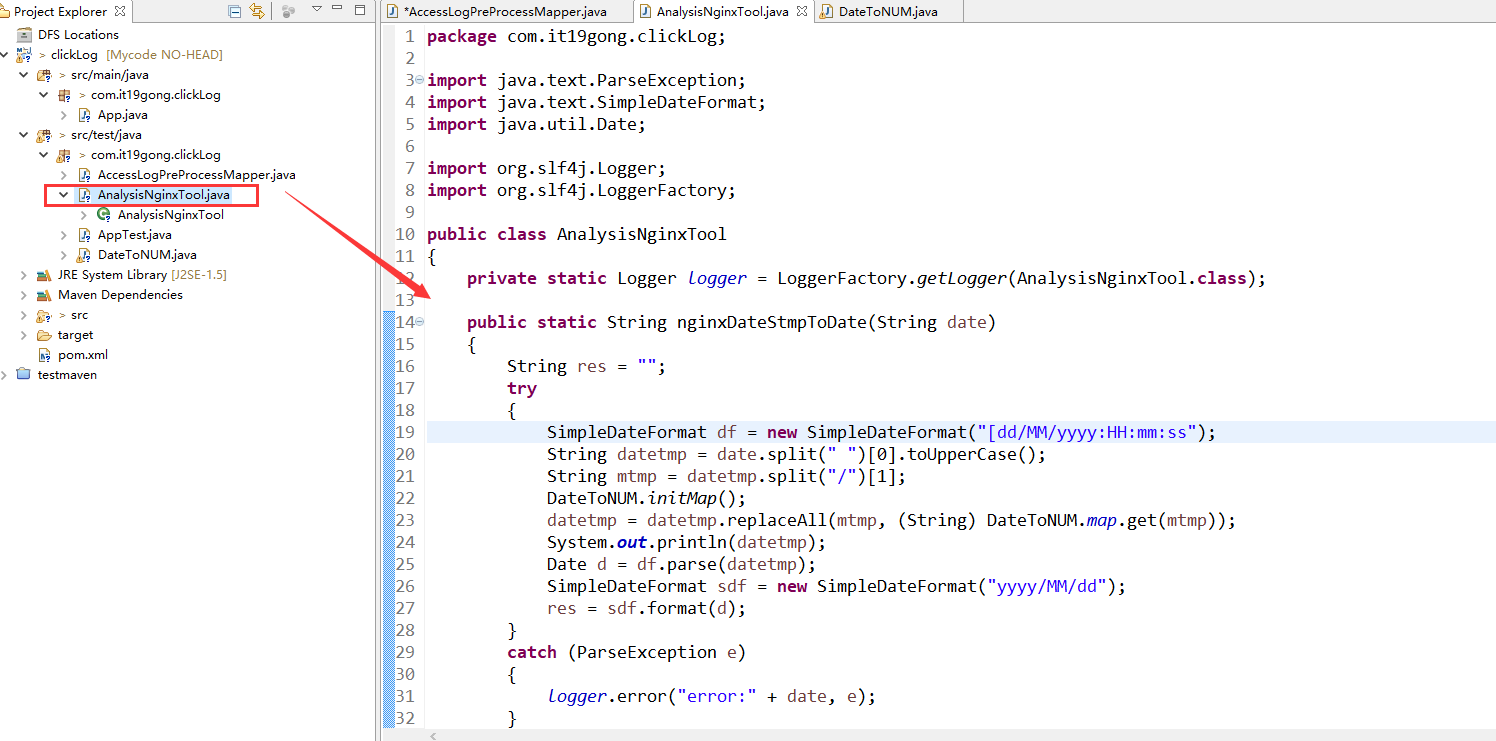
package com.it19gong.clickLog; import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date; import org.slf4j.Logger;
import org.slf4j.LoggerFactory; public class AnalysisNginxTool
{
private static Logger logger = LoggerFactory.getLogger(AnalysisNginxTool.class); public static String nginxDateStmpToDate(String date)
{
String res = "";
try
{
SimpleDateFormat df = new SimpleDateFormat("[dd/MM/yyyy:HH:mm:ss");
String datetmp = date.split(" ")[0].toUpperCase();
String mtmp = datetmp.split("/")[1];
DateToNUM.initMap();
datetmp = datetmp.replaceAll(mtmp, (String) DateToNUM.map.get(mtmp));
System.out.println(datetmp);
Date d = df.parse(datetmp);
SimpleDateFormat sdf = new SimpleDateFormat("yyyy/MM/dd");
res = sdf.format(d);
}
catch (ParseException e)
{
logger.error("error:" + date, e);
}
return res;
} public static long nginxDateStmpToDateTime(String date)
{
long l = 0;
try
{
SimpleDateFormat df = new SimpleDateFormat("[dd/MM/yyyy:HH:mm:ss");
String datetmp = date.split(" ")[0].toUpperCase();
String mtmp = datetmp.split("/")[1];
datetmp = datetmp.replaceAll(mtmp, (String) DateToNUM.map.get(mtmp)); Date d = df.parse(datetmp);
l = d.getTime();
}
catch (ParseException e)
{
logger.error("error:" + date, e);
}
return l;
}
}
创建DateToNUM类
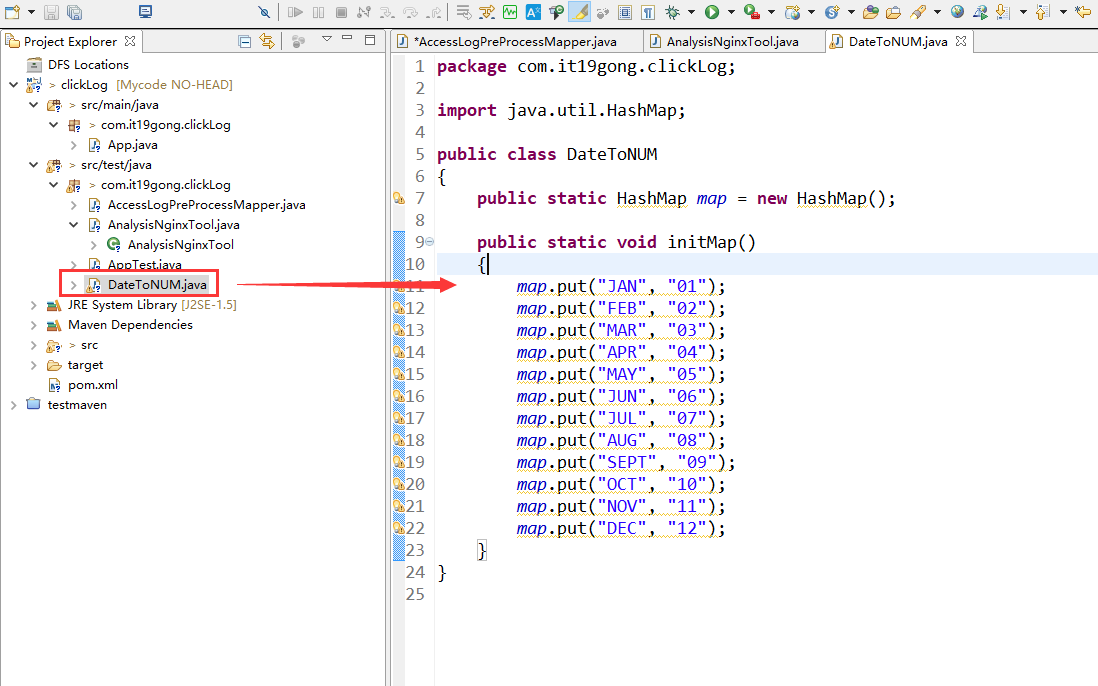
package com.it19gong.clickLog; import java.util.HashMap; public class DateToNUM
{
public static HashMap map = new HashMap(); public static void initMap()
{
map.put("JAN", "01");
map.put("FEB", "02");
map.put("MAR", "03");
map.put("APR", "04");
map.put("MAY", "05");
map.put("JUN", "06");
map.put("JUL", "07");
map.put("AUG", "08");
map.put("SEPT", "09");
map.put("OCT", "10");
map.put("NOV", "11");
map.put("DEC", "12");
}
}
新建AccessLogDriver类
package com.it19gong.clickLog; import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class AccessLogDriver { public static void main(String[] args) throws Exception {
DateToNUM.initMap();
Configuration conf = new Configuration();
if(args.length != 2){
args = new String[2];
args[0] = "hdfs://node1/data/clickLog/20190620/";
args[1] = "hdfs://node1/uvout/hive" ;
} Job job = Job.getInstance(conf); // 设置一个用户定义的job名称
job.setJarByClass(AccessLogDriver.class);
job.setMapperClass(AccessLogPreProcessMapper.class); // 为job设置Mapper类
// 为job设置Reducer类
job.setNumReduceTasks(0);
job.setMapOutputKeyClass(Text.class);// 为job的输出数据设置Key类
job.setMapOutputValueClass(NullWritable.class);// 为job输出设置value类
FileInputFormat.addInputPath(job, new Path(args[0])); // 为job设置输入路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));// 为job设置输出路径
System.exit(job.waitForCompletion(true) ? 0 : 1); // 运行job
} }
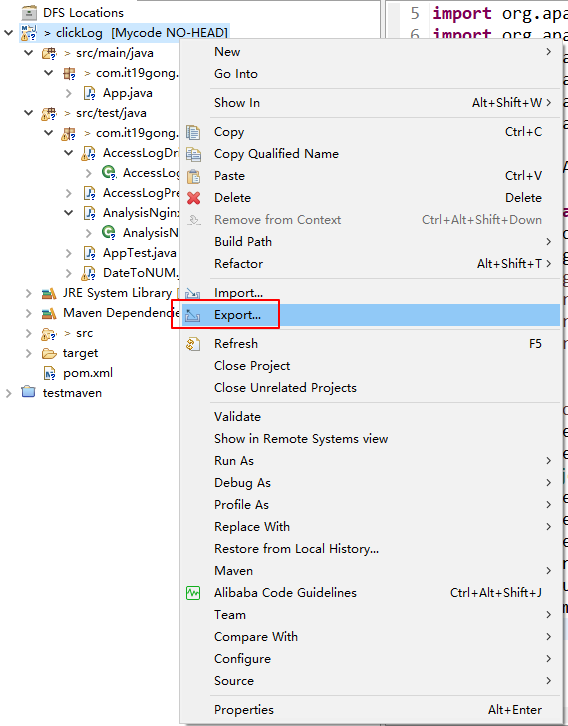
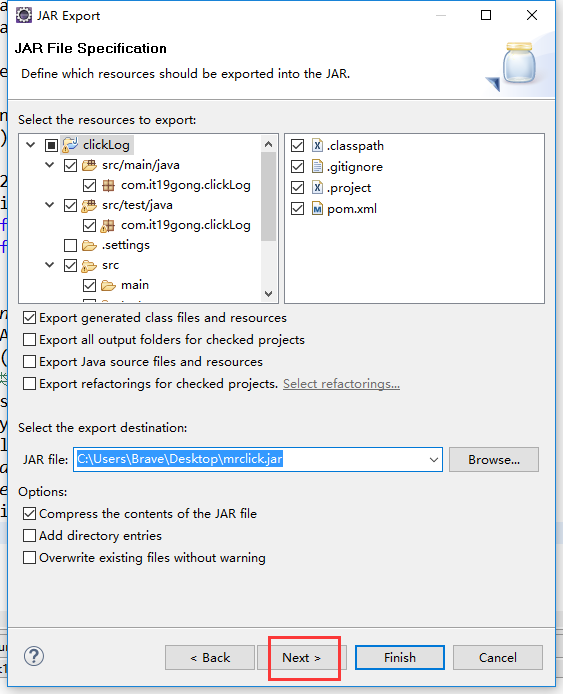
把工程打包成Jar包
把jar包上传到集群

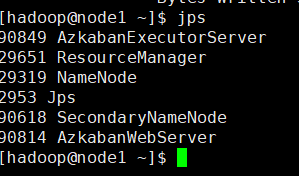
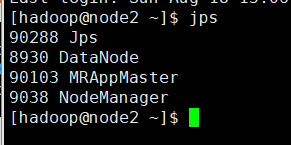
在集群上运行一下,先检查一下集群的启动进程

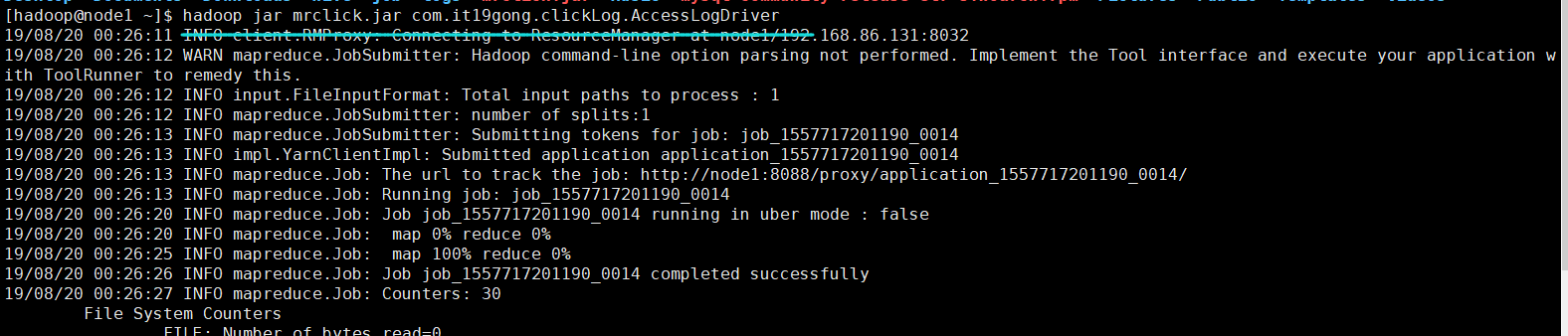
hadoop jar mrclick.jar com.it19gong.clickLog.AccessLogDriver
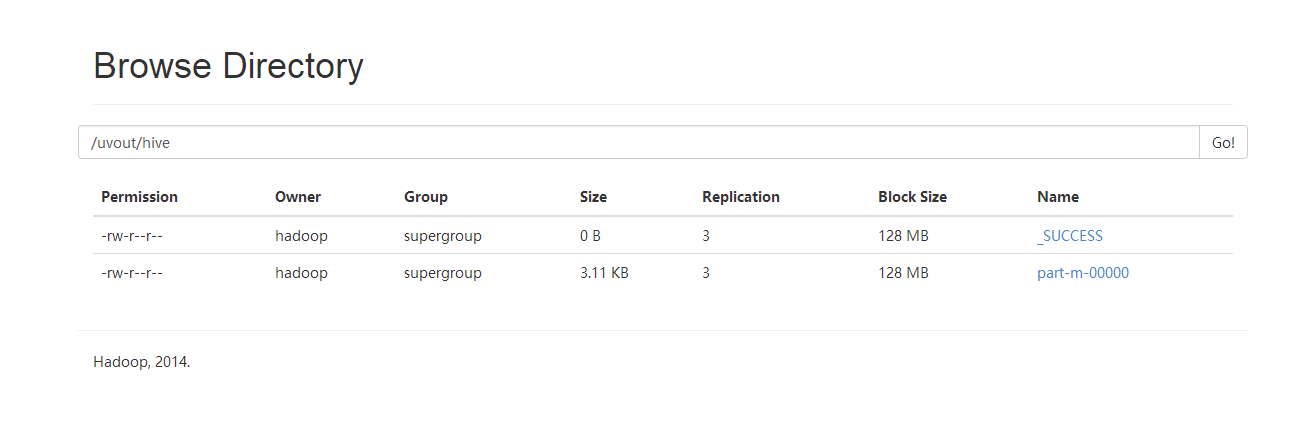
可以看到输出目录
查看清洗后的数据
19.通过MAPREDUCE 把收集数据进行清洗的更多相关文章
- Hadoop 中利用 mapreduce 读写 mysql 数据
Hadoop 中利用 mapreduce 读写 mysql 数据 有时候我们在项目中会遇到输入结果集很大,但是输出结果很小,比如一些 pv.uv 数据,然后为了实时查询的需求,或者一些 OLAP ...
- Hadoop生态圈-使用MapReduce处理HBase数据
Hadoop生态圈-使用MapReduce处理HBase数据 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.对HBase表中数据进行单词统计(TableInputFormat) ...
- 使用MapReduce将HDFS数据导入Mysql
使用MapReduce将Mysql数据导入HDFS代码链接 将HDFS数据导入Mysql,代码示例 package com.zhen.mysqlToHDFS; import java.io.DataI ...
- 使用MapReduce将mysql数据导入HDFS
package com.zhen.mysqlToHDFS; import java.io.DataInput; import java.io.DataOutput; import java.io.IO ...
- 使用hadoop mapreduce分析mongodb数据
使用hadoop mapreduce分析mongodb数据 (现在很多互联网爬虫将数据存入mongdb中,所以研究了一下,写此文档) 版权声明:本文为yunshuxueyuan原创文章.如需转载请标明 ...
- 【原创】MapReduce备份Elasticsearch数据到HDFS(JAVA)
一.环境:JAVA8,Elasticsearch-5.6.2,Hadoop-2.8.1二.实现功能:mapreduce读elasticsearch数据.输出parquet文件.多输出路径三.主要依赖 ...
- Java 8 (5) Stream 流 - 收集数据
在前面已经使用过collect终端操作了,主要是用来把Stream中的所有元素结合成一个List,在本章中,你会发现collect是一个归约操作,就像reduce一样可以接受各种做法作为参数,将流中的 ...
- java8中用流收集数据
用流收集数据 汇总 long howManyDishes = menu.stream().collect(Collectors.counting()); int totalCalories = men ...
- 《Java 8 in Action》Chapter 6:用流收集数据
1. 收集器简介 collect() 接收一个类型为 Collector 的参数,这个参数决定了如何把流中的元素聚合到其它数据结构中.Collectors 类包含了大量常用收集器的工厂方法,toLis ...
随机推荐
- 如何复制word的图文到ueditor中自动上传?
官网地址http://ueditor.baidu.com Git 地址 https://github.com/fex-team/ueditor 参考博客地址 http://blog.ncmem.com ...
- java超大文件上传
上周遇到这样一个问题,客户上传高清视频(1G以上)的时候上传失败. 一开始以为是session过期或者文件大小受系统限制,导致的错误. 查看了系统的配置文件没有看到文件大小限制, web.xml中se ...
- Java进阶知识10 Hibernate一对多_多对一双向关联(Annotation+XML实现)
本文知识点(目录): 1.Annotation 注解版(只是测试建表) 2.XML版 的实现(只是测试建表) 3.附录(Annotation 注解版CRUD操作)[注解版有个问题:插入值时 ...
- JavaScript设计模式—代理模式
代理模式介绍 使用者无权访问目标对象,中间加代理,通过代理做授权和控制 代理(proxy)是一个对象,它可以用来控制对另外一个对象的访问: 代理对象和本体对象实现了同样的接口,并且会把任何方法调用传递 ...
- 安装完Pycharm,启动时碰到"failed to load jvm dll"的解决方案
今天安装完系统,配置pycharm的环境的时候,启动pycharm时,碰到"failed to load jvm dll"的错误, 下面给出其解决方案: 安装Microsoft V ...
- Beta冲刺(2/5)
队名:new game 组长博客 作业博客 组员情况 鲍子涵(队长) 过去两天完成了哪些任务 验收游戏素材 学习Unity 2D Animation系统 基本做完了人物的各个动画 接下来的计划 冲击E ...
- sql 查询存在一个表而不在另一个表中的数据
方法一(效率底) select A.* from 办卡 A where A.namedh not in (select namedh from 银行) 方法二(效率中) select A.* from ...
- python 格式化输出用户名/密码
格式化输出用户名/密码 内容来自网络 def get_account(num): accounts = [] for index in range(1, num+1): accounts.append ...
- APScheduler 3.0.1浅析
简介 APScheduler是一个小巧而强大的Python类库,通过它你可以实现类似Unix系统cronjob类似的定时任务系统.使用之余,阅读一下源码,一方面有助于更好的使用它,另一方面,个人认为a ...
- 浅谈WebView在新窗口浏览网页(setSupportMultipleWindows()与onCreateWindow()关系)
一,写在前面 我们平常使用电脑浏览器浏览网页可能会有三种方式: 1.新窗口 2.当前窗口种的新选项卡 3.当前选项卡或者窗口 我们知道在电脑系统中同一时间可以开启多个相同的进程,就像你可以同时登陆2个 ...