hadoop-hive的内表和外表
--创建内表
create table if not exists employee(
id int comment 'empoyeeid',
dateincompany string comment 'data come in company',
money float comment 'work money',
mapdatamap array<string>,
arraydata array<int>,
structordata struct<col1:string,col2:string>)
partitioned by (century string comment 'centruycome in company',
year string comment 'come in comany year')
row format delimited fields terminated by ','
collection items terminated by '@'
map keys terminated by '$'
stored as textfile;
数据文件:
[hadoop@master hivetest]$ more employee.txt
1,huawei,1000.2,m1$a,1@2@3@4,c1@c2
装载数据:
hive>LOAD DATA LOCAL INPATH '/home/hadoop/tmp/hivetest/employee.txt' INTO TABLE employee PARTITION(century='zhengzhou', year='20180910');
查询数据:
hive> select * from employee;
OK
1 huawei 1000.2 ["m1$a"] [1,2,3,4] {"col1":"c1","col2":"c2"} zhengzhou 20180910
Time taken: 0.638 seconds, Fetched: 1 row(s)
给出的现象是:
在HDFS上,默认的路径下/user/hive/warehouse/employee生成一个目录,在前台界面,也是一个目录。

删除内表,目录都不存在了。
还可以指定目录(HDFS上)
create table if not exists test1(id int, name string)
row format delimited fields terminated by ',' stored as textfile location '/tmp/data';
> load data inpath '/tmp/test1.txt' into table test1 ;
> select * from test1;
OK
1 zhangwei
Time taken: 0.593 seconds, Fetched: 1 row(s)
/tmp/test1.txt在加载的时候,删除掉了,数据加载到表里,其实就是落成文件到/tmp/data/test1.txt
删除表后,数据都删除了,data目录都删除了。
--创建外表
create external table if not exists test2 (id int,name string)
row format delimited fields terminated by ',' stored as textfile;
会在/user/hive/warehouse/新建一个表目录test2
hive> load data inpath '/tmp/test1.txt' into table test2 ;
Loading data to table default.test2
OK
Time taken: 1.053 seconds
hive> select * from test2;
OK
1 zhangwei
Time taken: 0.281 seconds, Fetched: 1 row(s)
现象: 在load的那一步,会把/tmp/test1.txt文件移动到/user/hive/warehouse/test2这个目录下。
数据的位置发生了变化!
本质是load一个hdfs上的数据时会转移数据!删除表后,数据文件在留在HDFS上。
2、在删除内部表的时候,Hive将会把属于表的元数据和数据全部删掉;而删除外部表的时候,Hive仅仅删除外部表的元数据,数据是不会删除的!
3. 在创建内部表或外部表时加上location 的效果是一样的,只不过表目录的位置不同而已,加上partition用法也一样,只不过表目录下会有分区目录而已,load data local inpath直接把本地文件系统的数据上传到hdfs上,有location上传到location指定的位置上,没有的话上传到hive默认配置的数据仓库中。
外部表相对来说更加安全些,数据组织也更加灵活,方便共享源数据。
那么,应该如何选择使用哪种表呢?在大多数情况没有太多的区别,因此选择只是个人喜好的问题。但是作为一个经验,如果所有处理都需要由Hive完成,那么你应该创建表,否则使用外部表!
有一个命令:
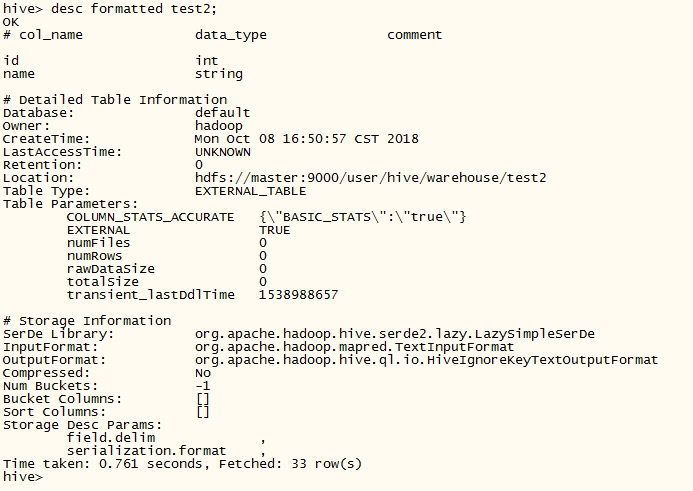
时光如水,悄然而逝。
hadoop-hive的内表和外表的更多相关文章
- Hive 7、Hive 的内表、外表、分区(22)
Hive 7.Hive 的内表.外表.分区 1.Hive的内表 Hive 的内表,就是正常创建的表,在 http://www.cnblogs.com/raphael5200/p/5208437.h ...
- Hive的内表和外表以及分区表
1. 内表和外表的区别 内表和外表之间是通过关键字EXTERNAL来区分.删除表时: 内表:在删除时,既删除内表的元数据,也删除内表的数据 外表:删除时,仅仅删除外表的元数据. CREATE [EXT ...
- Hive 7、Hive 的内表、外表、分区
1.Hive的内表 Hive 的内表,就是正常创建的表,在 http://www.cnblogs.com/raphael5200/p/5208437.html 中已经提到: 2.Hive的外表 创建H ...
- Hive内表和外表的区别
本文以例子的形式介绍一下Hive内表和外表的区别.例子共有4个:不带分区的内表.带分区的内表.不带分区的外表.带分区的外表. 1 不带分区的内表 #创建表 create table innerTabl ...
- hive内表和外表的创建、载入数据、区别
创建表 创建内表 create table customer( customerId int, firstName string, lastName STRING, birstDay timestam ...
- hadoop Hive 的建表 和导入导出及索引视图
1.hive 的导入导出 1.1 hive的常见数据导入方法 1.1.1 从本地系统中导入数据到hive表 1.创建student表 [ROW FORMAT DELIMITED]关键字,是用来设 ...
- hadoop系列 第二坑: hive hbase关联表问题
关键词: hive创建表卡住了 创建hive和hbase关联表卡住了 其实针对这一问题在info级别的日志下是看出哪里有问题的(为什么只能在debug下才能看见呢,不太理解开发者的想法). 以调试模式 ...
- kylin加载hive表错误:ERROR [http-bio-7070-exec-10] controller.TableController:189 : org/apache/hadoop/hive/conf/HiveConf java.lang.NoClassDefFoundError: org/apache/hadoop/hive/conf/HiveConf 解决办法
一.问题背景 在kylin中加载hive表时,弹出提示框,内容是“oops!org/apache/hadoop/hive/conf/HiveConf”,无法加载hive表,查找kylin的日志时发现, ...
- hive中删除表的错误Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. MetaException
hive使用drop table 表名删除表时报错,return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. MetaException 刚 ...
随机推荐
- selenium死活定位不到元素以及radio单选框点击不生效
今天操作一个单选框浪费太多时间,现在其实很简单得东西,记录一下: 1,问题一,定位不到 如图,使用selenium IDE和xpath helper都试过,无法成功定位到这个单选框,实际上是因为,这个 ...
- idea忽略隐藏文件、文件夹的设置操作
左上角setting 如果要忽略文件夹,则直接填写文件夹名字即可,例如:要忽略target文件夹[建议:尽量不要把target忽略,因为可能编译出问题排查,还需要查看target文件夹中的编译结果] ...
- mongodb操作二
{ "_id" : ObjectId("5d4d74e1685764420c4f9337"), "createTime" : ISODate ...
- [CDH] Process data: integrate Spark with Spring Boot
c 一.Spark 统计计算 简单统计后写入Redis. /** * 订单统计和乘车人数统计 */ object OrderStreamingProcessor { def main(args: Ar ...
- Delphi7-TClientDataSet: 查找
TClientDataSet[12]: 查找 方法有:1.Locate: 根据字段列表和对应的字段值查找并定位, 找到返回 True.2.Lookup: 根据字段列表和对应的字段值查找, 返回需要的字 ...
- Fidessa
Fidessa这样为券商提供交易系统和与交易所连接的公司被称作Independent Software Vendor, 同类的还有FIS(前SunGuard), Bloomberg(AIM), Tho ...
- NLP 计算机视觉 cv 机器学习 ,入们基础
吴恩达的deep Learning 吴恩达机器学习 李宏毅 的机器学习 http://speech.ee.ntu.edu.tw/~tlkagk/courses.html 斯坦福的概率图模型 ...
- mapreduce案例:获取PI的值
mapreduce案例:获取PI的值 * content:核心思想是向以(0,0),(0,1),(1,0),(1,1)为顶点的正方形中投掷随机点. * 统计(0.5,0.5)为圆心的单位圆中落点占总落 ...
- dfs入门-cogs1640[黑白图像]
题目链接:http://cogs.pro:8081/cogs/problem/problem.php?pid=vxSmxkeqa [题目描述] 输入一个n×n的黑白图像(1表示黑色,0表示白色),任务 ...
- JQ scrollTop 无效的场景
先要设置DOM为显示,然后在设置scrollTop,先后顺序不能调换.