【Spark机器学习速成宝典】推荐引擎——协同过滤
目录
推荐模型的分类
ALS交替最小二乘算法:显式矩阵分解
Spark Python代码:显式矩阵分解
ALS交替最小二乘算法:隐式矩阵分解
Spark Python代码:隐式矩阵分解
|
推荐模型的分类 |
最为流行的两种方法是基于内容的过滤、协同过滤。
基于内容的过滤:
比如用户A买了商品A,商品B与商品A相似(这个相似是基于商品内部的属性,比如“非常好的协同过滤入门文章”和“通俗易懂的协同过滤入门教程”比较相似),那么就能将商品B推荐给用户。
协同过滤:
利用的是训练数据是大量用户对商品的评分,即(userID,productID,score)。称得上最经典最常用的推荐算法。协同过滤又可细分为:基于用户的推荐、基于物品的推荐。
基于用户的推荐:
简单解释就是“志趣相投”
以商品为维度,寻找相似用户。就能给用户A推送他的相似用户买过的商品。

基于物品的推荐:
简单解释就是“物以类聚”
以用户为维度,寻找相似商品。比如用户A买了个商品A,那就能推荐与商品A相似的商品。

|
ALS交替最小二乘算法:显式矩阵分解 |
ALS(Alternating Least squares)算法是用来求解协同过滤模型的重要算法。在训练集中我们有用户对商品打分的矩阵:

问题:用户u5给商品v4的打分大概是多少呢?这就是协同过滤算法要做的事情,即求出每一个格子里的值,这个值就是某用户对某商品的评分。那如何做呢?答:矩阵分解。
首先,将用户评分矩阵Am×n拆成用户特征矩阵Um×k乘以商品特征矩阵Vk×n的形式:
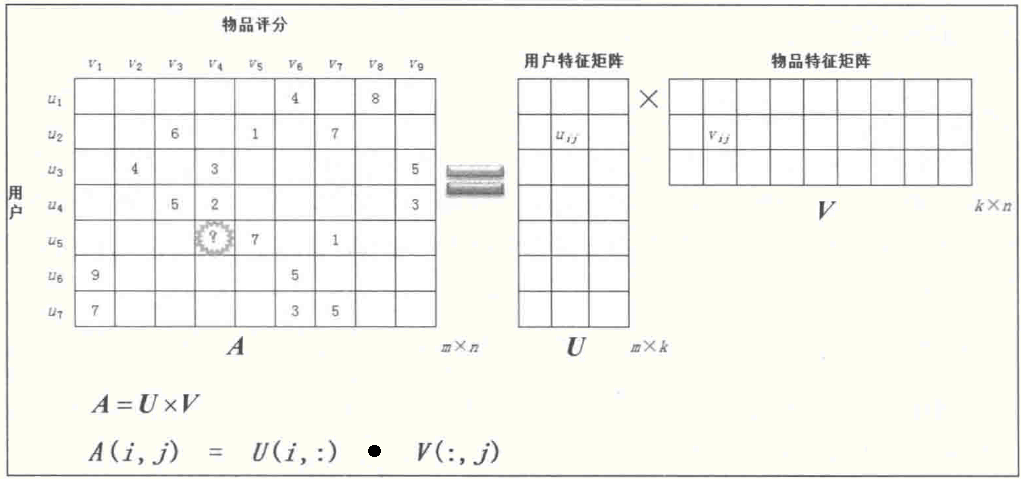
其中A=U×V,如果得到了U和V,那么用户评分矩阵中的A(i,j),可由向量U(i,:)点乘向量V(:,j)计算得到。
用两个小矩阵 Um×k 和 Vn×k 的乘积近似等价Am×n。这样,整个系统的自由度从o(mn)降到o((m+n)k)。代价函数可以设置为:矩阵A中每个元素与重构矩阵U×V之间的每个元素的误差平方和,即:
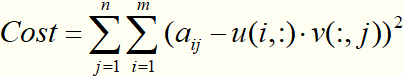
为防止过拟合,一般加入L2正则化项:

但是这个损失函数不是凸的,而且变量互相耦合在一起,不宜求解。那怎么办? 答:使用ALS算法。
ALS算法的思想是:将 U 或 V 固定其一,这个最优化问题立刻变成一个凸的可拆分的问题,求解过程就是基于最小二乘法的最优化问题。
ALS算法完整求解过程:先随机生成 U(0),然后固定 U(0)求解 V(0),再固定 V(0)求解 U(1)这样交替进行下去,由于总体问题的非凸性,ALS并不保证收敛到全局最优解,但在实际应用中迭代10次,便能训练出较好的模型。
最终我们可以得到这三个矩阵:

通过这些矩阵便可以做以下事情:
1.为用户推荐潜在感兴趣的TopK个商品
2.为商品寻找潜在的TopK个用户
3.寻找相似用户
4.寻找相似商品
模型训练中涉及到的参数调节的准则:
rank:对应ALS模型中的因子个数,也就是在低阶近似矩阵中的隐含特征个数。因子个数一般越多越好。但它也会直接影响模型训练和保存时所需的内存开销,尤其是在用户和物品很多的时候。因此实践中该参数常作为训练效果与系统开销之间的调节参数。通常,其合理取值为10到200。
iterations:对应运行时的迭代次数。ALS能确保每次迭代都能降低评级矩阵的重建误差,但一般经少数次迭代后ALS模型便已能收敛为一个比较合理的好模型。这样,大部分情况下都没必要迭代太多次(10次左右一般就挺好)。
lambda:该参数控制模型的正则化过程,从而控制模型的过拟合情况。其值越高,正则化越严厉。该参数的赋值与实际数据的大小、特征和稀疏程度有关。和其他的机器学习模型一样,正则参数应该通过用非样本的测试数据进行交叉验证来调整。
|
Spark Python代码:显式矩阵分解 |
# -*-coding=utf-8 -*-
from pyspark import SparkConf, SparkContext
from pyspark.mllib.recommendation import ALS, MatrixFactorizationModel, Rating
sc = SparkContext("local") # 加载和解析数据
data = sc.textFile("test.data")
ratings = data.map(lambda l: l.split(',')).map(lambda l: Rating(int(l[0]), int(l[1]), float(l[2]))) # 使用交替最小二乘算法训练推荐模型
rank = 3
numIterations = 10
model = ALS.train(ratings, rank, numIterations) # 打印用户特征矩阵
print "用户特征矩阵:"
a = model.userFeatures().collect()
for i in a:
print str(i[1][0])[:5] + "," + str(i[1][1])[:5] + "," + str(i[1][2])[:5] # 打印物品特征矩阵
print "物品特征矩阵:"
b = model.productFeatures().collect()
for i in b:
print str(i[1][0])[:5] + "," + str(i[1][1])[:5] + "," + str(i[1][2])[:5] # 打印用户评分矩阵
print "用户评分矩阵:"
res = model.recommendProductsForUsers(9) #为每一个用户推荐num个商品
def a(userdata):
lst = []
userid = int(userdata[0])
lst.append(userid)
for i in userdata[1]:
product = str(i.product) + ":" + str(i.rating)[:5]
lst.append(product)
return lst
res = res.map(a).collect()
res.sort(key=lambda x:x[0])
for line in res:
line = line[1:]
# print line
j = [i.split(":") for i in line]
j.sort(key=lambda x:x[0])
l=""
for k in j:
l += k[1] + ","
print l a = model.predict(user=1, product=2)
print "预测user1与product2的兴趣度:"
print a a = model.recommendUsers(product=2, num=2)
print "为商品2寻找潜在的TopK个用户:"
print a a = model.recommendProducts(user=1, num=3)
print "为user1推荐潜在感兴趣的TopK个商品:"
print a a = model.recommendProductsForUsers(num=3).collect()
print "为所有用户推荐潜在感兴趣的TopK个商品:"
for i in a:
print i a = model.recommendUsersForProducts(num=3).collect()
print "为所有商品寻找潜在的TopK个用户:"
for i in a:
print i '''res
17/12/23 14:50:00 WARN BLAS: Failed to load implementation from: com.github.fommil.netlib.NativeSystemBLAS
17/12/23 14:50:00 WARN BLAS: Failed to load implementation from: com.github.fommil.netlib.NativeRefBLAS
17/12/23 14:50:01 WARN LAPACK: Failed to load implementation from: com.github.fommil.netlib.NativeSystemLAPACK
17/12/23 14:50:01 WARN LAPACK: Failed to load implementation from: com.github.fommil.netlib.NativeRefLAPACK
17/12/23 14:50:01 WARN Executor: 1 block locks were not released by TID = 29:
[rdd_210_0]
17/12/23 14:50:01 WARN Executor: 1 block locks were not released by TID = 30:
[rdd_211_0]
17/12/23 14:50:01 WARN Executor: 1 block locks were not released by TID = 31:
[rdd_210_0]
17/12/23 14:50:01 WARN Executor: 1 block locks were not released by TID = 32:
[rdd_211_0]
用户特征矩阵:
0.575,-0.52,-0.76
0.165,1.110,-0.51
0.597,0.941,-0.07
0.516,0.430,-0.52
-0.28,0.113,1.037
0.385,-0.34,-1.07
0.236,0.805,-0.66
物品特征矩阵:
2.467,1.397,-7.93
1.896,3.044,-0.17
3.575,3.367,-3.25
1.584,2.145,-0.48
-1.53,3.854,5.902
1.358,-0.08,-4.12
0.121,6.417,0.299
3.823,-3.44,-5.18
2.387,3.749,-0.29
用户评分矩阵:
6.801,-0.36,2.801,0.163,-7.44,4.000,-3.52,7.996,-0.36,
6.028,3.787,6.000,2.895,1.003,2.241,6.992,-0.53,4.712,
3.357,4.013,5.539,3.002,2.295,1.025,6.095,-0.58,4.979,
6.020,2.383,4.995,1.996,-2.21,2.815,2.670,3.197,3.002,
-8.78,-0.38,-4.02,-0.71,6.996,-4.67,1.001,-6.86,-0.56,
9.004,-0.13,3.707,0.386,-8.28,4.986,-2.51,8.252,-0.06,
6.998,3.020,5.727,2.427,-1.19,2.997,4.996,1.587,3.783,
预测user与product的兴趣度:
-0.364804845726
为商品2寻找潜在的TopK个用户:
[Rating(user=3, product=2, rating=4.013395373544592), Rating(user=2, product=2, rating=3.7876436839883194)]
为user1推荐潜在感兴趣的TopK个商品:
[Rating(user=1, product=8, rating=7.996952478409568), Rating(user=1, product=1, rating=6.801415502963593), Rating(user=1, product=6, rating=4.000096674124945)]
为所有用户推荐潜在感兴趣的TopK个商品:
(4, (Rating(user=4, product=1, rating=6.020880222950041), Rating(user=4, product=3, rating=4.995487526087871), Rating(user=4, product=8, rating=3.1971086869642846)))
(1, (Rating(user=1, product=8, rating=7.996952478409568), Rating(user=1, product=1, rating=6.801415502963593), Rating(user=1, product=6, rating=4.000096674124945)))
(6, (Rating(user=6, product=1, rating=9.004180651398052), Rating(user=6, product=8, rating=8.25221831618579), Rating(user=6, product=6, rating=4.986725295866833)))
(3, (Rating(user=3, product=7, rating=6.095926975521101), Rating(user=3, product=3, rating=5.5399318710354155), Rating(user=3, product=9, rating=4.979915488571464)))
(7, (Rating(user=7, product=1, rating=6.998396543388047), Rating(user=7, product=3, rating=5.72731910674824), Rating(user=7, product=7, rating=4.9965585464819355)))
(5, (Rating(user=5, product=5, rating=6.996394158606613), Rating(user=5, product=7, rating=1.0018132801060546), Rating(user=5, product=2, rating=-0.386246390781805)))
(2, (Rating(user=2, product=7, rating=6.9928960101812), Rating(user=2, product=1, rating=6.02809652321465), Rating(user=2, product=3, rating=6.000155003043972)))
为所有商品寻找潜在的TopK个用户:
(4, (Rating(user=3, product=4, rating=3.0029246134929766), Rating(user=2, product=4, rating=2.8953672065005556), Rating(user=7, product=4, rating=2.427766056801616)))
(1, (Rating(user=6, product=1, rating=9.004180651398052), Rating(user=7, product=1, rating=6.998396543388047), Rating(user=1, product=1, rating=6.801415502963593)))
(6, (Rating(user=6, product=6, rating=4.986725295866833), Rating(user=1, product=6, rating=4.000096674124945), Rating(user=7, product=6, rating=2.997989324292092)))
(3, (Rating(user=2, product=3, rating=6.000155003043972), Rating(user=7, product=3, rating=5.72731910674824), Rating(user=3, product=3, rating=5.5399318710354155)))
(7, (Rating(user=2, product=7, rating=6.9928960101812), Rating(user=3, product=7, rating=6.095926975521101), Rating(user=7, product=7, rating=4.9965585464819355)))
(9, (Rating(user=3, product=9, rating=4.979915488571464), Rating(user=2, product=9, rating=4.712732268716017), Rating(user=7, product=9, rating=3.7833941032831433)))
(8, (Rating(user=6, product=8, rating=8.25221831618579), Rating(user=1, product=8, rating=7.996952478409568), Rating(user=4, product=8, rating=3.1971086869642846)))
(5, (Rating(user=5, product=5, rating=6.996394158606613), Rating(user=3, product=5, rating=2.295168542063017), Rating(user=2, product=5, rating=1.0030496463981144)))
(2, (Rating(user=3, product=2, rating=4.013395373544592), Rating(user=2, product=2, rating=3.7876436839883194), Rating(user=7, product=2, rating=3.0206127312499014)))
�ɹ�: ����ֹ PID 59904 (���� PID 59620 �ӽ���)�Ľ��̡�
�ɹ�: ����ֹ PID 59620 (���� PID 59484 �ӽ���)�Ľ��̡�
�ɹ�: ����ֹ PID 59484 (���� PID 46708 �ӽ���)�Ľ��̡� '''
test.data数据:
1,6,4.0
1,8,8.0
2,3,6.0
2,5,1.0
2,7,7.0
3,2,4.0
3,4,3.0
3,9,5.0
4,3,5.0
4,4,2.0
4,9,3.0
5,5,7.0
5,7,1.0
6,1,9.0
6,6,5.0
7,1,7.0
7,6,3.0
7,7,5.0
|
ALS交替最小二乘算法:隐式矩阵分解 |
在显式矩阵分解的训练集中,我们有用户对商品的评级,用户评分的高低决定了用户对商品的感兴趣的程度,假设有10个等级,那么评1级就是意味着讨厌,评10级意味着非常喜欢。
但是,有些时候我们没有用户显式的打分数据,而是有用户的行为数据。
比如:用户对某一个电影观看多次,可以说这个用户喜欢这个电影,而且置信度很高;如果用户对某个电影观看了一次,我们也可以说用户喜欢这个电影,只是置信度低。
下面介绍:隐式矩阵分解。
首先我们有数据集:
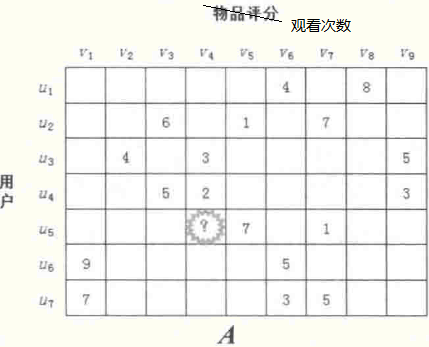
先将数据集依照公式:
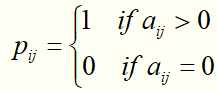 ,
, 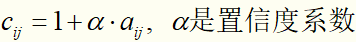
拆成2个矩阵:二元偏好矩阵P、信心权重矩阵C(这里取α=0.1,α也是一个正则化参数)

代价函数是:

求解的方法和显式矩阵分解一样。
|
Spark Python代码:隐式矩阵分解 |
# -*-coding=utf-8 -*-
from pyspark import SparkConf, SparkContext
from pyspark.mllib.recommendation import ALS, MatrixFactorizationModel, Rating
sc = SparkContext("local") # 加载和解析数据
data = sc.textFile("test.data")
ratings = data.map(lambda l: l.split(',')).map(lambda l: Rating(int(l[0]), int(l[1]), float(l[2]))) # 使用交替最小二乘算法训练推荐模型
rank = 3
numIterations = 10
model = ALS.train(ratings, rank, numIterations)
# 打印用户评分矩阵
def a(userdata):
lst = []
userid = int(userdata[0])
lst.append(userid)
for i in userdata[1]:
product = str(i.product) + ":" + str(i.rating)[:5]
lst.append(product)
return lst model = ALS.trainImplicit(ratings, rank, numIterations, alpha=0.1) res = model.recommendProductsForUsers(9) #为每一个用户推荐num个商品
res = res.map(a).collect()
res.sort(key=lambda x:x[0])
for line in res:
line = line[1:]
# print line
j = [i.split(":") for i in line]
j.sort(key=lambda x:x[0])
l=""
for k in j:
l += k[1] + ","
print l '''
0.674,0.072,-0.15,0.054,-0.23,0.891,0.089,0.432,0.054,
0.091,-0.03,0.771,0.125,0.999,-0.04,1.085,-0.18,0.126,
-0.01,0.601,0.501,0.989,-0.17,0.055,-0.19,0.089,0.991,
-0.04,0.547,0.725,0.962,0.171,-0.04,0.144,-0.01,0.964,
0.128,-0.14,0.493,-0.10,0.814,0.019,0.913,-0.13,-0.10,
0.778,0.031,-0.09,0.005,-0.09,0.997,0.284,0.454,0.005,
0.887,-0.05,0.158,-0.05,0.330,1.058,0.787,0.404,-0.05,
'''
【Spark机器学习速成宝典】推荐引擎——协同过滤的更多相关文章
- spark机器学习从0到1协同过滤算法 (九)
一.概念 协同过滤算法主要分为基于用户的协同过滤算法和基于项目的协同过滤算法. 基于用户的协同过滤算法和基于项目的协同过滤算法 1.1.以用户为基础(User-based)的协同过滤 用相似统 ...
- 【Spark机器学习速成宝典】基础篇02RDD常见的操作(Python版)
目录 引例入门:textFile.collect.filter.first.persist.count 创建RDD的方式:parallelize.textFile 转化操作:map.filter.fl ...
- 【Spark机器学习速成宝典】基础篇01Windows下spark开发环境搭建+sbt+idea(Scala版)
注意: spark用2.1.1 scala用2.11.11 材料准备 spark安装包 JDK 8 IDEA开发工具 scala 2.11.8 (注:spark2.1.0环境于scala2.11环境开 ...
- 【Spark机器学习速成宝典】模型篇08保序回归【Isotonic Regression】(Python版)
目录 保序回归原理 保序回归代码(Spark Python) 保序回归原理 待续... 返回目录 保序回归代码(Spark Python) 代码里数据:https://pan.baidu.com/s/ ...
- 【Spark机器学习速成宝典】模型篇07梯度提升树【Gradient-Boosted Trees】(Python版)
目录 梯度提升树原理 梯度提升树代码(Spark Python) 梯度提升树原理 待续... 返回目录 梯度提升树代码(Spark Python) 代码里数据:https://pan.baidu.co ...
- 【Spark机器学习速成宝典】模型篇06随机森林【Random Forests】(Python版)
目录 随机森林原理 随机森林代码(Spark Python) 随机森林原理 参考:http://www.cnblogs.com/itmorn/p/8269334.html 返回目录 随机森林代码(Sp ...
- 【Spark机器学习速成宝典】模型篇05决策树【Decision Tree】(Python版)
目录 决策树原理 决策树代码(Spark Python) 决策树原理 详见博文:http://www.cnblogs.com/itmorn/p/7918797.html 返回目录 决策树代码(Spar ...
- 【Spark机器学习速成宝典】模型篇04朴素贝叶斯【Naive Bayes】(Python版)
目录 朴素贝叶斯原理 朴素贝叶斯代码(Spark Python) 朴素贝叶斯原理 详见博文:http://www.cnblogs.com/itmorn/p/7905975.html 返回目录 朴素贝叶 ...
- 【Spark机器学习速成宝典】模型篇03线性回归【LR】(Python版)
目录 线性回归原理 线性回归代码(Spark Python) 线性回归原理 详见博文:http://www.cnblogs.com/itmorn/p/7873083.html 返回目录 线性回归代码( ...
随机推荐
- ASR测试方法---字错率(WER)、句错率(SER)统计
一.基础概念 1.1.语音识别(ASR) 语音识别(speech recognition)技术,也被称为自动语音识别(英语:Automatic Speech Recognition, ASR), 狭隘 ...
- 嵌入式安装telnet
busybox配置 Defined at networking/Config.in:784 Depends on: TELNET Location: -> Networking Utilitie ...
- Computer Vision_1_Active Appearance Models :Active Appearance Models——1998
此为计算机视觉部分,主要侧重在底层特征提取,视频分析,跟踪,目标检测和识别方面等方面. 1. Active Appearance Models 活动表观模型和活动轮廓模型基本思想来源 Snake,现在 ...
- Linux--磁盘检查简单介绍
系统莫名其妙的掉电或磁盘发生问题非常可能导致文件系统的错乱,文件系统若发生错乱,可以使用fsck(file system check)命令进行检查. 使用权限:root用户 选项和参数: -a:检测到 ...
- web开发:jquery初级
一.JQ入门 二.引入JQ 三.页面加载 四.分析JQ源码流程 五.JQ操作 六.c菜单栏案例 一.JQ入门 what is jQuery ???1.jQuery是对原生JavaScript二次封装的 ...
- 字符串搜索(strStr)--- C++版
上篇中是用JAVA实现的字符串搜索算法, 这次改用C++来实现,当然在C++就没有像JAVA那样方便的API可以很简便的实现了,其思想跟上篇类似,直接上具体实现代码: 编译运行: 下面分析下流程: 还 ...
- Java 扫描微信公众号二维码,关注并自动登录网站
https://blog.csdn.net/qq_42851002/article/details/81327770 场景:用户扫描微信公众号的二维码,关注后自动登录网站,若已关注则直接登录. 逻辑: ...
- Linux权限操作(用户和组)
useradd 添加用户useradd -u uid user 创建指定uid的用户-o 配合-u 不检查uid的唯一性-d 指定家目录-s 指定shell-r 创建系统用户-m 强制创建家目录-M ...
- 03—Code First
Code First模式我们称之为“代码优先”模式,使用Code First模式进行EF开发时开发人员只需要编写对应的数据类(其实就是领域模型的实现过程),然后自动生成数据库.这样设计的 ...
- 【换根dp】9.22小偷
换根都不会了 题目大意 给定一棵$n$个点的树和树上一撮关键点,求到所有$m$个关键点距离的最大值$dis_{max}\le LIM$的点的个数. $n,m\le 30000,LIM\le 30000 ...