spark的task调度器(FAIR公平调度算法)
FAIR 调度策略的树结构如下图所示:
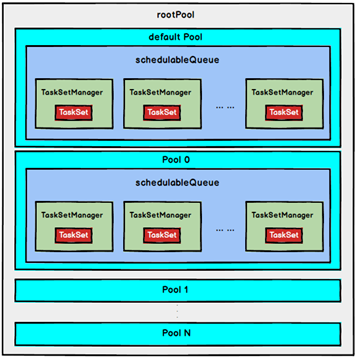
FAIR 调度策略内存结构
FAIR 模式中有一个 rootPool 和多个子 Pool, 各个子 Pool 中存储着所有待分配的 TaskSetMagager 。
在 FAIR 模 式 中 , 需 要 先 对 子 Pool 进 行 排 序 , 再 对 子 Pool 里 面 的
TaskSetMagager 进行排序,因为 Pool 和 TaskSetMagager 都继承了 Schedulable 特质, 因此使用相同的排序算法。
排序过程的比较是基于 Fair-share 来比较的,每个要排序的对象包含三个属性:
runningTasks 值( 正在运行的 Task 数)、minShare 值、weight 值,比较时会综合考量 runningTasks 值, minShare 值以及 weight 值。
注意,minShare、weight 的值均在公平调度配置文件 fairscheduler.xml 中被指定,调度池在构建阶段会读取此文件的相关配置。
1) 如果 A 对象的 runningTasks 大于它的 minShare, B 对象的 runningTasks 小于它的 minShare,那么 B 排在 A 前面; ( runningTasks比 minShare小的先执行)
2) 如果 A 、B 对象的 runningTasks 都小于它们的 minShare ,那么就比较runningTasks 与 minShare 的比值( minShare 使用率),谁小谁排前面;( minShare使用率低的先执行)
3) 如果 A 、B 对象的 runningTasks 都大于它们的 minShare ,那么就比较runningTasks 与 weight 的比值( 权重使用率),谁小谁排前面。(权重使用率低的先执行)
4) 如果上述比较均相等,则比较名字。
整体上来说就是通过 minShare 和 weight 这两个参数控制比较过程, 可以做到让 minShare 使用率和权重使用率少( 实际运行 task 比例较少) 的先运行。
private[spark] class FairSchedulingAlgorithm extends SchedulingAlgorithm {
override def comparator(s1: Schedulable, s2: Schedulable): Boolean = {
val minShare1 = s1.minShare
val minShare2 = s2.minShare
默认为0,除非通过fair的配置文件进行了配置指定
val runningTasks1 = s1.runningTasks
val runningTasks2 = s2.runningTasks
如果是TaskSetManager时,就是taskSet中运行的task的个数,
如果是Pool实例是表示是所有使用这个poolName的所有的TaskSetManager正在运行的task的个数.
val s1Needy = runningTasks1 < minShare1
val s2Needy = runningTasks2 < minShare2
只有在minShare在fair的配置文件中显示配置,同时大于正在运行的task的个数时,才会为true
val minShareRatio1 = runningTasks1.toDouble / math.max(minShare1, 1.0).toDouble
val minShareRatio2 = runningTasks2.toDouble / math.max(minShare2, 1.0).toDouble
运行的task的个数针对于minShare的比重
val taskToWeightRatio1 = runningTasks1.toDouble / s1.weight.toDouble
val taskToWeightRatio2 = runningTasks2.toDouble / s2.weight.toDouble
得到正在运行的task个数针对于pool的weight的比重
var compare: Int = 0
这里首先根据正在运行的task的个数是否已经达到调度队列中最小的分片的个数来进行排序,
如果s1中运行运行的个数小于s1的pool的配置的minShare,返回true,表示s1排序在前面.
如果s2中运行的task的个数小于s2的pool中配置的minShare(最小分片数)的值,表示s1小于s2,这时s2排序应该靠前.
if (s1Needy && !s2Needy) {
return true
} else if (!s1Needy && s2Needy) {
return false
} else if (s1Needy && s2Needy) {
这种情况表示s1与s2两个队列中,正在运行的task的个数都已经大于(不小于)了两个子调度器中配置的minShare的个数时,根据两个子调度器队列中正在运行的task的个数对应此调度器中最小分片的值所占的比重最小的一个排序更靠前
compare = minShareRatio1.compareTo(minShareRatio2)
} else {
这种情况表示s1与s2两个子调度器的队列中,正在运行的task的个数都还没有达到配置的最小分片的个数的情况,比较两个队列中正在运行的task的个数对应调度器队列的weigth的占比,最小的一个排序更靠前
compare = taskToWeightRatio1.compareTo(taskToWeightRatio2)
}
if (compare < 0) {
true
} else if (compare > 0) {
false
} else {
如果两个根据上面的计算,排序值都相同,就看看这两个调度器的名称,按名称的字节序来排序了.
s1.name < s2.name
}
}
}
spark的task调度器(FAIR公平调度算法)的更多相关文章
- 调度器&负载均衡调度算法整理
一.Linux 调度器 Linux中进程调度器已经经过很多次改进了,目前核心调度器是在CFS(Completely Fair Scheduler),从2.6.23开始被作为默认调度器.用作者Ing ...
- Volcano成Spark默认batch调度器
摘要:对于Spark用户而言,借助Volcano提供的批量调度.细粒度资源管理等功能,可以更便捷的从Hadoop迁移到Kubernetes,同时大幅提升大规模数据分析业务的性能. 2022年6月16日 ...
- Yarn 公平调度器案例
目录 公平调度器案例 需求 配置多队列的公平调度器 1 修改yarn-site.xml文件,加入以下从参数 2 配置fair-scheduler.xml 3 分发配置文件重启yarn 4 测试提交任务 ...
- YARN调度器(Scheduler)详解
理想情况下,我们应用对Yarn资源的请求应该立刻得到满足,但现实情况资源往往是有限的,特别是在一个很繁忙的集群,一个应用资源的请求经常需要等待一段时间才能的到相应的资源.在Yarn中,负责给应用分配资 ...
- Linux IO Scheduler(Linux IO 调度器)
每个块设备或者块设备的分区,都对应有自身的请求队列(request_queue),而每个请求队列都可以选择一个I/O调度器来协调所递交的request.I/O调度器的基本目的是将请求按照它们对应在块设 ...
- Hadoop的调度器总结
Hadoop的调度器总结 随着MapReduce的流行,其开源实现Hadoop也变得越来越受推崇.在Hadoop系统中,有一个组件非常重要,那就是调度器,它的作用是将系统中空闲的资源按一定策略分配给作 ...
- Linux IO 调度器
Linux IO Scheduler(Linux IO 调度器) 每个块设备或者块设备的分区,都对应有自身的请求队列(request_queue),而每个请求队列都可以选择一个I/O调度器来协调所递交 ...
- Linux IO Scheduler(Linux IO 调度器)【转】
每个块设备或者块设备的分区,都对应有自身的请求队列(request_queue),而每个请求队列都可以选择一个I/O调度器来协调所递交的request.I/O调度器的基本目的是将请求按照它们对应在块设 ...
- Linux I/O 调度器
每个块设备或者块设备的分区,都对应有自身的请求队列, 而每个请求队列都可以选择一个I/O调度器来协调所递交的.I/O调度器的基本目的是将请求按照它们对应在块设备上的扇区号进行排列,以减少磁头的移动, ...
随机推荐
- jQuery基础知识1
jquery的概念 js query jquery库 封装了大量js,封装js的入口函数.兼容性问题.DOM操作.事件.ajax 使用jquery 下载包 引用 <script src=&quo ...
- MySQL之三张表关联
创建三张表 1.学生表 mysql> create table students( sid int primary key auto_increment, sname ) not null, a ...
- django安装tinymce
1. pip install django-tinymce 2. 运行:python manage.py collectstatic 3. 编辑 settings.py 4. TINYMCE_JS_U ...
- 使用JSP/Servalet技术开发新闻发布系统------JSP数据交互一
什么是内置对象 JSP内置对象是 Web 容器创建的一组对象,不用通过手动new就可以使用 JSP中的九大内存对象 request 请求对象 response 响应对象 out 输出对象 ...
- 异常:ORA-01013: 用户请求取消当前的操作
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/bnmnba/article/detail ...
- Neo4j 快速清除数据库数据
在开发过程中,很多时候需要快(简)速(单)清(粗)除(暴)Neo4j中存在的海量数据节点和关系数据.在这种情况下,delete和detach从性能上都已力不从心.Neo4j官方推荐清库方法,即删除gr ...
- VS下字符串与数组互相装换
1.分割字符串IdStr为int数组Ids int[] Ids = Array.ConvertAll<string, int>(IdStr.Trim().Split(','), deleg ...
- dumpe/dumpe2fs/e2fsck
xt2/3/4文件系统备份工具 导出ext2/ext3/ext4文件系统信息 dumpe2fs e2fsck 强制检查文件系统 检查文件系统
- qml 3d 纪念那些曾经爬过的坑
1.使用多position画图时,图形不受控制的问题? 在变量属性设置时Attribute中的attributeBaseType 数据类型一定要和 Buffer中data 数据类型一定要相同. 例如 ...
- Kalman实际应用总结
目录 Kalman理论介绍 一. 简单理论介绍理论 二. 升华理论介绍 Kalman基本应用 一. Kalman跟踪/滤波 二. Kalman预测/融合(单传感器) 三. Kalman多传感器融合A ...