python并发编程-进程池线程池-协程-I/O模型-04
进程池线程池的使用*****
无论是开线程还是开进程都会消耗资源,即使开线程消耗的资远比开进程的少
而物理设备的性能是有限的,虽然可以加设备来提升上限,但如果像淘宝双十一那样,只有很少的时刻需要大量的资源,为了满足这个去买一大堆服务器显然是不划算的
(计算机中)池的目的:在保证计算机硬件安全的情况下最大限度的利用计算机硬件,池其实是降低了程序的运行效率,但是保证了计算机硬件的安全(硬件的发展跟不上软件的速度)
进程池线程池的目的:为了限制开设的进程数和线程数,从而保证计算机硬件的安全
进程池/线程池的创建和提交回调
import random
import time
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
def task(i):
time.sleep(random.random())
print(f"{i} is over...")
return f"{i}² = {i * i}"
if __name__ == '__main__': # 进程池的时候一定要放在这里面
'''不放报错 concurrent.futures.process.BrokenProcessPool: A process in the process pool was terminated abruptly while the future was running or pending.'''
# -------------------------------------------------
# 1.实例化进程池/线程池对象,并限制进程池/线程池中进程/线程数量
# -------------------------------------------------
# pool = ThreadPoolExecutor(3, 'MyThread-') # 不指定参数的情况下,默认是当前 CPU个数*5 , 也可以指定线程个数
pool = ProcessPoolExecutor(3) # 不指定参数的情况下,默认是当前 CPU个数 , 也可以指定进程个数(创进程不能传第二个参数)
# for i in range(5):
# # -------------------------------------------------
# # 2.线程池对象.submit() 异步提交任务
# # 提交任务的两种方式
# # 同步:提交完任务之后,在原地等待任务的返回结果,再继续执行下一步代码
# # 异步:提交任务之后,不等待任务的返回结果(这个结果怎么拿?),直接进行下一步操作
# # -------------------------------------------------
# pool.submit(task, i)
# print("主")
#
# # 0 is running...
# # 1 is running...
# # 2 is running...
# # 主
# # 1 is over...
# # 3 is running...
# # 0 is over...
# # 4 is running...
# # 4 is over...
# # 3 is over...
# # 2 is over...
# for i in range(5):
# future = pool.submit(task, i)
# # print(future) # <Future at 0x21a130dbb00 state=running> <Future at 0x21a1321ec50 state=pending>
# # -------------------------------------------------
# # future = pool.submit(task, i)
# # future.result() 接收返回值并获取回调值
# # -------------------------------------------------
# print(future.result())
# print("主")
# # 0 is running...
# # 0 is over...
# # 0² = 0
# # 1 is running...
# # 1 is over...
# # 1² = 1
# # 2 is running...
# # 2 is over...
# # 2² = 4
# # 3 is running...
# # 3 is over...
# # 3² = 9
# # 4 is running...
# # 4 is over...
# # 4² = 16
# # 主
# future_list = []
# for i in range(5):
# future = pool.submit(task, i)
# future_list.append(future)
#
# for future in future_list:
# print(f">>:{future.result()}") # 依次等每个 future的结果,所以是绝对有序的
# print("主")
# # 0 is running...
# # 1 is running...
# # 2 is running...
# # 0 is over...
# # 3 is running...
# # >>:0² = 0
# # 1 is over...
# # 4 is running...
# # >>:1² = 1
# # 4 is over...
# # 2 is over...
# # >>:2² = 4
# # 3 is over...
# # >>:3² = 9
# # >>:4² = 16
# # 主
future_list = []
for i in range(5):
future = pool.submit(task, i)
future_list.append(future)
pool.shutdown() # 关闭池子且等待池子中所有的任务运行完毕
for future in future_list:
print(f">>:{future.result()}") # 依次等每个 future的结果,所以是绝对有序的
print("主")
# 0 is running...
# 1 is running...
# 2 is running...
# 2 is over...
# 3 is running...
# 0 is over...
# 4 is running...
# 4 is over...
# 1 is over...
# 3 is over...
# >>:0² = 0
# >>:1² = 1
# >>:2² = 4
# >>:3² = 9
# >>:4² = 16
# 主
验证复用池子里的线程或进程
池子中创建的进程或线程创建一次就不会再创建了,至始至终用的都是最初的那几个,这样的话就可以节省反复开辟进程或线程的资源了
不是动态创建动态销毁的(如果是好几百个,可想而知)
import random
import time
import os
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
from threading import current_thread
def task(i):
time.sleep(random.random())
# print(f"{os.getpid()} {i} is over...")
print(f"{os.getpid()} {current_thread().name} {i} is over...")
return f"{i}² = {i * i}"
if __name__ == '__main__': # 进程池的时候一定要放在这里面
# pool = ProcessPoolExecutor(3)
pool = ThreadPoolExecutor(3, 'MyThreading')
future_list = []
for i in range(5):
future = pool.submit(task, i)
future_list.append(future)
pool.shutdown() # 关闭池子且等待池子中所有的任务运行完毕
for future in future_list:
print(f">>:{future.result()}") # 依次等每个 future的结果,所以是绝对有序的
print("主")
# 11000 0 is over... # 复用了进程号(即没有去开辟新的内存空间)
# 8024 2 is over...
# 10100 1 is over...
# 11000 3 is over...
# 8024 4 is over...
# >>:0² = 0
# >>:1² = 1
# >>:2² = 4
# >>:3² = 9
# >>:4² = 16
# 主
# 使用线程池的打印结果
# 13024 MyThreading_1 1 is over... # 1.复用了线程
# 13024 MyThreading_1 3 is over... # 2.复用了线程
# 13024 MyThreading_2 2 is over...
# 13024 MyThreading_0 0 is over...
# 13024 MyThreading_1 4 is over...
# >>:0² = 0
# >>:1² = 1
# >>:2² = 4
# >>:3² = 9
# >>:4² = 16
# 主
异步回调机制
这(
.add_done_callback())其实是.submit() 返回结果对象的方法
异步回调机制:当异步提交的任务有返回结果之后,会自动触发回调函数的执行
import random
import time
import os
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
from threading import current_thread
def callback(future):
print(f"我拿到了回调结果:{future.result()}")
def task(i):
time.sleep(random.random())
# print(f"{os.getpid()} {i} is over...")
print(f"{os.getpid()} {current_thread().name} {i} is over...")
return f"{i}² = {i * i}"
if __name__ == '__main__': # 进程池的时候一定要放在这里面
# pool = ProcessPoolExecutor(3)
pool = ThreadPoolExecutor(3, 'MyThreading')
future_list = []
for i in range(5):
# -----------------------------------------------------
# .submit().add_done_callback() 自动调用回调函数
# 会自动将 .submit()的返回结果作为参数传给.add_done_callback() 中传入的函数去调用执行
# .add_done_callback() 其实是 .submit()返回对象自身的方法
# -----------------------------------------------------
future = pool.submit(task, i).add_done_callback(callback)
future_list.append(future)
pool.shutdown() # 关闭池子且等待池子中所有的任务运行完毕
print("主")
# 11348 MyThreading_0 0 is over...
# 我拿到了回调结果:0² = 0
# 11348 MyThreading_2 2 is over...
# 我拿到了回调结果:2² = 4
# 11348 MyThreading_0 3 is over...
# 我拿到了回调结果:3² = 9
# 11348 MyThreading_1 1 is over...
# 我拿到了回调结果:1² = 1
# 11348 MyThreading_2 4 is over...
# 我拿到了回调结果:4² = 16
# 主
通过闭包给回调函数添加额外参数(扩展)
# 省略导模块等
# 线程池/进程池对象.submit() 会返回一个 future对象,该对象有.add_done_callback()方法(是一个对象绑定函数),参数是一个函数名(除了对象自身默认传入,无法为该函数传参)
# 这里利用闭包函数返回内部函数名的特点 直接调用这个闭包函数,达到传参的效果,可为回调函数添加更多的扩展性
def outter(*args, **kwargs):
def callback(res):
# 可以拿到 *args, **kwargs 参数做一些事情
print(res.result())
return callback
pool_list = []
for i in range(15):
pool_list.append(pool.submit(task, i).add_done_callback(outter(1, 2, 3, a=1, c=3))) # 朝线程池中提交任务(异步)
协程***
后期项目支持高并发可能才会用到
概念回顾(协程这里再理一下)
进程:资源单位(车间)
线程:操作系统的最小执行单位(流水线)
协程:单线程下实现并发的效果(完全是技术人员编造出来的名词)
并发:看起来像同时执行(多道技术核心:切换+保存状态)
协程:通过代码层面自己监测程序中的I/O行为,自己实现切换,让操作系统误认为这个线程没有I/O,从而保证程序在运行态和就绪态来回切换(不进入阻塞态),更大限度地利用CPU,最大程度上提高线程的执行效率
切换+保存状态就一定能够提升效率吗?
切换+保存状态 不一定能提升程序的效率
- 当任务是计算密集型,反而会降低效率
- 如果是IO密集型,会提升效率
如何实现协程
生成器的yield 可以实现保存状态(行不通)
但,效率更低了
# # 串行执行
# import time
#
#
# def func1():
# for i in range(10000000):
# i + 1
#
#
# def func2():
# for i in range(10000000):
# i + 1
#
#
# start = time.time()
# func1()
# func2()
# stop = time.time()
# print(stop - start)
# # 1.2481744289398193
# 基于yield并发执行
import time
def func1():
while True:
10000000 + 1
yield
def func2():
g = func1()
for i in range(10000000):
i + 1
next(g)
start = time.time()
func2()
stop = time.time()
print(stop - start)
# 1.9084477424621582
gevent模块实现
模块安装下载
搜索并下载(这里是因为我配了两个镜像源,所以出来了两个选项,随便选一个)
gevent基本介绍
from gevent import spawn, monkey
monkey.patch_all() # 一般这个要写在很前面(例如导socket模块之前)
# 两行亦可写成一行 from gevent import monkey;monkey.patch_all()
g1 = spawn(eat, 1, 2, 3, x=4, y=5)
# 创建一个协程对象g1,spawn括号内第一个参数是函数名,如eat,后面是该函数(eat)所需要的参数
g2 = spawn(func2)
g1.join() # 等待协程g1结束
g2.join() # 等待协程g2结束
# 上述两步亦可合作一步:joinall([g1,g2])
g1.value # 拿到eat函数执行的返回值
通过gevent实现遇到 IO自动切换状态(单线程下并发)
import time
from gevent import spawn
# gevent 本身识别不了time.sleep() 等不属于该模块内的I/O操作
# 使用下面的操作来支持
from gevent import monkey
monkey.patch_all() # 监测代码中所有 I/O 行为
def heng(name):
print(f"{name} 哼")
time.sleep(2)
print(f"{name} 哼 ...")
def ha(name):
print(f"{name} 哈")
time.sleep(3)
print(f"{name} 哈 ...")
# start_time = time.time()
# heng('egon')
# ha('jason')
# print(f"主 {time.time() - start_time}")
# # 主 5.005069732666016
start_time = time.time()
s1 = spawn(heng, 'egon')
s2 = spawn(ha, 'jason')
s1.join()
s2.join()
print(f"主 {time.time() - start_time}")
# 主 3.0046989917755127
在计算密集型任务中使用
from gevent import spawn, monkey
monkey.patch_all()
import time
def func1():
for i in range(10000000):
i + 1
def func2():
for i in range(10000000):
i + 1
start = time.time()
g = spawn(func1)
g2 = spawn(func2)
g.join()
g2.join()
stop = time.time()
print(stop - start)
# 1.1324069499969482
# 与前面普通的串行执行时间 1.2481744289398193 相近
利用gevent在单线程下实现并发(协程)
服务端
import socket
from gevent import spawn
from gevent import monkey # 让 gevent 能够识别python的 IO
monkey.patch_all()
server = socket.socket()
server.bind(('127.0.0.1', 8080))
server.listen(5)
def talk(conn):
while True:
try:
data = conn.recv(1024)
if len(data) == 0: break
print(data.decode('utf-8'))
conn.send(data.upper())
except ConnectionResetError as e:
print(e)
break
conn.close()
def wait_client_connect():
while True:
conn, addr = server.accept()
spawn(talk, conn)
if __name__ == '__main__':
g1 = spawn(wait_client_connect)
g1.join() # 别忘了加上
客户端
import socket
from threading import Thread, current_thread
def create_client():
client = socket.socket()
client.connect(('127.0.0.1', 8080))
n = 0
while True:
data = '%s %s' % (current_thread().name, n)
client.send(data.encode('utf-8'))
res = client.recv(1024)
print(res.decode('utf-8'))
n += 1
for i in range(400): # 手动开400个线程连接客户端(测试的是服务端单线程实现并发)
t = Thread(target=create_client)
t.start()
最大程度下提高代码的执行效率(实现高并发)
- 多进程下使用多线程
- 多线程下使用多协程
大前提
IO密集型任务
I/O 模型(只放了几张图)
此部分内容摘抄自博客: Python从入门到精通之IO模型
程序间数据交互,本质上数据都是从内存中取的(包括socket的recv等)
阻塞I/O模型

当用户进程调用了recvfrom这个系统调用,kernel就开始了IO的第一个阶段:准备数据。对于network io来说,很多时候数据在一开始还没有到达(比如,还没有收到一个完整的UDP包),这个时候kernel就要等待足够的数据到来。
而在用户进程这边,整个进程会被阻塞。当kernel一直等到数据准备好了,它就会将数据从kernel中拷贝到用户内存,然后kernel返回结果,用户进程才解除block的状态,重新运行起来。
非阻塞I/O模型
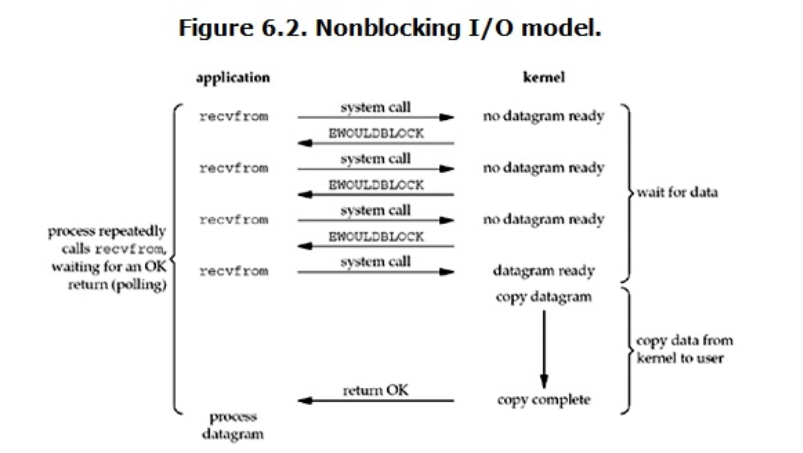
从图中可以看出,当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个error。从用户进程角度讲 ,它发起一个read操作后,并不需要等待,而是马上就得到了一个结果。用户进程判断结果是一个error时,它就知道数据还没有准备好,于是用户就可以在本次到下次再发起read询问的时间间隔内做其他事情,或者直接再次发送read操作。一旦kernel中的数据准备好了,并且又再次收到了用户进程的system call,那么它马上就将数据拷贝到了用户内存(这一阶段仍然是阻塞的),然后返回。
也就是说非阻塞的recvform系统调用调用之后,进程并没有被阻塞,内核马上返回给进程,如果数据还没准备好,此时会返回一个error。进程在返回之后,可以干点别的事情,然后再发起recvform系统调用。重复上面的过程,循环往复的进行recvform系统调用。这个过程通常被称之为轮询。轮询检查内核数据,直到数据准备好,再拷贝数据到进程,进行数据处理。需要注意,拷贝数据整个过程,进程仍然是属于阻塞的状态。
多路复用I/O模型
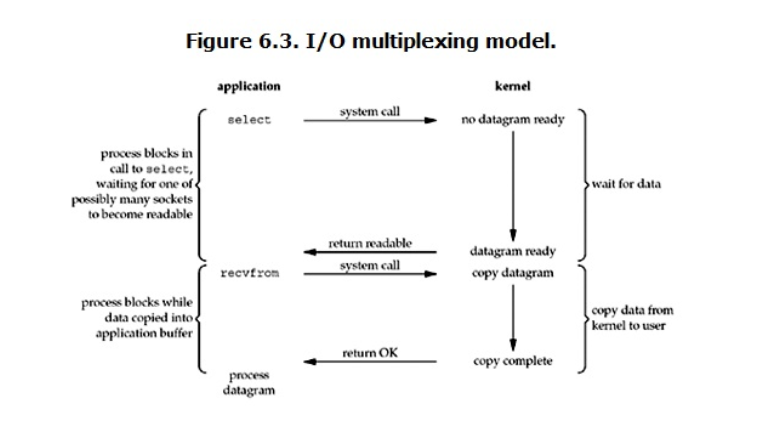
当用户进程调用了select,那么整个进程会被block,而同时,kernel会“监视”所有select负责的socket,当任何一个socket中的数据准备好了,select就会返回。这个时候用户进程再调用read操作,将数据从kernel拷贝到用户进程。
这个图和blocking IO的图其实并没有太大的不同,事实上还更差一些。因为这里需要使用两个系统调用(select和recvfrom),而blocking IO只调用了一个系统调用(recvfrom)。但是,用select的优势在于它可以同时处理多个connection。
信号驱动I/O模型
涉及太少,暂不做了解
异步I/O模型
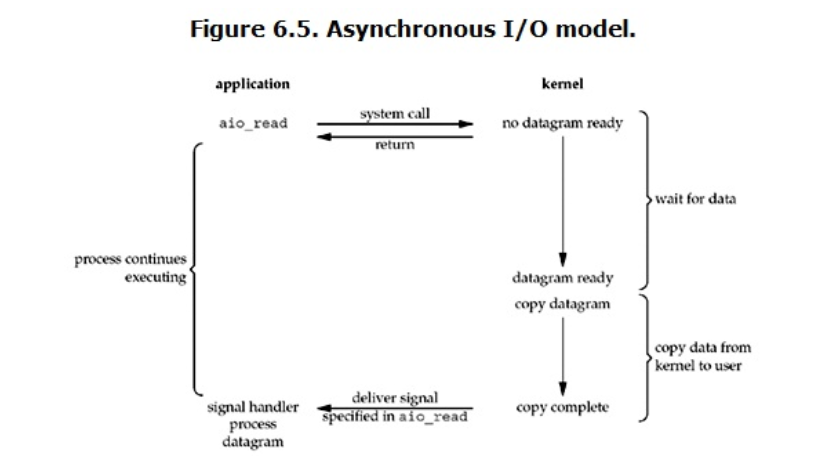
用户进程发起read操作之后,立刻就可以开始去做其它的事。而另一方面,从kernel的角度,当它受到一个asynchronous read之后,首先它会立刻返回,所以不会对用户进程产生任何block。然后,kernel会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,kernel会给用户进程发送一个signal,告诉它read操作完成了。
python并发编程-进程池线程池-协程-I/O模型-04的更多相关文章
- Python并发编程二(多线程、协程、IO模型)
1.python并发编程之多线程(理论) 1.1线程概念 在传统操作系统中,每个进程有一个地址空间,而且默认就有一个控制线程 线程顾名思义,就是一条流水线工作的过程(流水线的工作需要电源,电源就相当于 ...
- 图解Python 【第八篇】:网络编程-进程、线程和协程
本节内容一览图: 本章内容: 同步和异步 线程(线程锁.threading.Event.queue 队列.生产者消费者模型.自定义线程池) 进程(数据共享.进程池) 协程 一.同步和异步 你叫我去吃饭 ...
- python基础之进程、线程、协程篇
一.多任务(多线程) 多线程特点:(1)线程的并发是利用cpu上下文的切换(是并发,不是并行)(2)多线程执行的顺序是无序的(3)多线程共享全局变量(4)线程是继承在进程里的,没有进程就没有线程(5) ...
- Python自动化开发 -进程、线程和协程(二)
本节内容 一.线程进程介绍 二. 线程 1.线程基本使用 (Threading) 2.线程锁(Lock.RLock) 3.信号量(Semaphore) 4.事件(event) 5.条件(Conditi ...
- python(40)- 进程、线程、协程及IO模型
一.操作系统概念 操作系统位于底层硬件与应用软件之间的一层.工作方式:向下管理硬件,向上提供接口. 操作系统进行进程切换:1.出现IO操作:2.固定时间. 固定时间很短,人感受不到.每一个应用层运行起 ...
- Cpython解释器下实现并发编程——多进程、多线程、协程、IO模型
一.背景知识 进程即正在执行的一个过程.进程是对正在运行的程序的一个抽象. 进程的概念起源于操作系统,是操作系统最核心的概念,也是操作系统提供的最古老也是最重要的抽象概念之一.操作系统的其他所有内容都 ...
- Python之路【第十六篇】:Python并发编程|进程、线程
一.进程和线程 进程 假如有两个程序A和B,程序A在执行到一半的过程中,需要读取大量的数据输入(I/O操作), 而此时CPU只能静静地等待任务A读取完数据才能继续执行,这样就白白浪费了CPU资源. 是 ...
- Python 中的进程、线程、协程、同步、异步、回调
进程和线程究竟是什么东西?传统网络服务模型是如何工作的?协程和线程的关系和区别有哪些?IO过程在什么时间发生? 一.上下文切换技术 简述 在进一步之前,让我们先回顾一下各种上下文切换技术. 不过首先说 ...
- Python之路,进程、线程、协程篇
本节内容 进程.与线程区别 cpu运行原理 python GIL全局解释器锁 线程 语法 join 线程锁之Lock\Rlock\信号量 将线程变为守护进程 Event事件 queue队列 生产者 ...
- python并发编程之进程、线程、协程的调度原理(六)
进程.线程和协程的调度和运行原理总结. 系列文章 python并发编程之threading线程(一) python并发编程之multiprocessing进程(二) python并发编程之asynci ...
随机推荐
- JavaWeb_(Hibernate框架)Hibernate中事务
Hibernate中事务 事务的性质 事物的隔离级别 配置事务的隔离级别 事务的性质 原子性:原子,不可再分,一个操作不能分为更小的操作,要么全都执行,要么全不执行. 一致性:事务在完成时,必须使得所 ...
- JavaWeb_(Struts2框架)Action中struts-default下result的各种转发类型
此系列博文基于同一个项目已上传至github 传送门 JavaWeb_(Struts2框架)Struts创建Action的三种方式 传送门 JavaWeb_(Struts2框架)struts.xml核 ...
- LeetCode 21. 合并两个有序链表(Merge Two Sorted Lists)
题目描述 将两个有序链表合并为一个新的有序链表并返回.新链表是通过拼接给定的两个链表的所有节点组成的. 示例: 输入:1->2->4, 1->3->4 输出:1->1-& ...
- 小程序web-view利用url给内嵌的网页传值
这个方法跟网页上的一样,直接通过截取url中传过来的参数来取值 <web-view src="https://www.baidu.com/test.html?url=http://ww ...
- 石川es6课程---7、数组
石川es6课程---7.数组 一.总结 一句话总结: ^ 主要就map(映射:一个对一个),reduce(汇总:一堆出来一个),filter 过滤器,forEach 循环(迭代) 四个方法 ^ 使用 ...
- koa 基础(二十五)数据库 与 art-template 模板 联动 --- 新增数据
1.视图层 根目录/views/index.html <!DOCTYPE html> <html lang="en"> <head> <m ...
- Selenium2Library测试web
Selenium 定位元素 ▲ Locator 可以id或name来用定位界面元素 也可以使用XPath或Dom,但是,必须用XPath=或Dom=来开头 ▲ 最好使用id来定位,强烈建议强制要求开发 ...
- 生成ip地址表的不同姿势--脚本生成和echo命令生成
前段时间参加了几个线下的靶机攻防比赛,几十个队伍,如果攻击的时候一个个攻击就非常麻烦,浪费时间.所以需要批量攻击.批量攻击就需要一个完整的ip地址表.在这里总结一下... 有不足的地方欢迎评论 一.脚 ...
- Thread 源码阅读
Thread 属性说明 /** * 程序中的执行线程 * @since 1.0 */ public class Thread implements Runnable { /* Make sure re ...
- CSS操作表格的边框和表格的属性示例代码
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...