Kafka无法消费?!我的分布式消息服务Kafka却稳如泰山!
在一个月黑风高的夜晚,突然收到现网生产环境Kafka消息积压的告警,梦中惊醒啊,马上起来排查日志。
问题现象:消费请求卡死在查找Coordinator
Coordinator为何物?Coordinator用于管理Consumer Group中各个成员,负责消费offset位移管理和Consumer Rebalance。Consumer在消费时必须先确认Consumer Group对应的Coordinator,随后才能join Group,获取对应的topic partition进行消费。
那如何确定Consumer Group的Coordinator呢?分两步走:
1、一个Consumer Group对应一个__consumers_offsets的分区,首先先计算Consumer Group对应的__consumers_offsets的分区,计算公式如下:
__consumers_offsets partition# = Math.abs(groupId.hashCode() % groupMetadataTopicPartitionCount,其中groupMetadataTopicPartitionCount由offsets.topic.num.partitions指定。
2、1中计算的该partition的leader所在的broker就是被选定的Coordinator。
定位过程
Coordinator节点找到了,现在看看Coordinator是否有问题:

不出所料,Coordinator对应分区Leader为-1,消费端程序会一直等待,直到Leader选出来为止,这就直接导致了消费卡死。
为啥Leader无法选举?Leader选举是由Controller负责的。Controller节点负责管理整个集群中分区和副本的状态,比如partition的Leader选举,topic创建,副本分配,partition和replica扩容等。现在我们看看Controller的日志:
1. 6月10日15:48:30,006 秒Broker 1成为controller

此时感知的节点为1和2,节点3 在zk读不出来:

31秒847的时候把__consumer_offsets的分区3的Leader选为1,ISR为[1,2],leader_epoch为14:

再过1秒后才感知到Controller发生变化,自身清退

2. Broker 2在其后几百毫秒后(15:48:30,936)也成为Controller

但是Broker2 是感知到Broker 3节点是活的,日志如下:

注意这个时间点,Broker1还没在zk把__consumer_offsets的分区3 的Leader从节点3改为1,这样Broker 2还认为Broker 3是Leader,并且Broker 3在它认为是活的,所以不需要重新选举Leader。这样一直保持了相当长的时间,即使Broker 1已经把这个分区的Leader切换了,它也不感知。
3. Broker 2在12号的21:43:19又感知Broker 1网络中断,并处理节点失败事件:

因为Broker 2内存中认为__consumer_offsets分区3的Leader是broker 3,所以不会触发分区3的Leader切换。
Broker 2但是在处理失败的节点Broker 1时,会把副本从ISR列表中去掉,去掉前会读一次zk,代码如下:
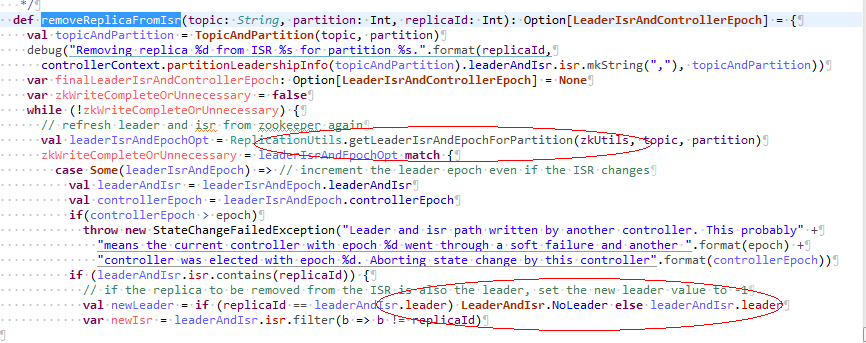
但是发现zk中分区3的Leader已经变为1,ISR列表为[1,2],当要去掉的节点1就是Leader的时候,Leader就会变为-1, ISR只有[2],从日志也可以看到:

这样分区3 的Leader一直为-1,直到有新的事件触发节点2重新选举才能恢复(例如重启某个节点)。
根因总结
出现网络异常后,由于新老controller之间感知的可用节点不同,导致新controller对某个分区的Leader在内存中的信息与zk记录元数据的信息不一致,导致controller选举流程出现错误,选不出Leader。 需要有新的选举事件才能触发Leader选出来,例如重启。
问题总结
这是一个典型的由于网络异常导致脑裂,进而出现了多个Controller,菊厂分布式消息服务Kafka经过电信级的可靠性验证,已经完美解决了这些问题 。
Kafka无法消费?!我的分布式消息服务Kafka却稳如泰山!的更多相关文章
- 分布式消息服务DMS如何实现死信消息的消费
本文部分内容节选自华为云帮助中心的分布式消息服务(DMS)服务的产品介绍 死信消息是什么 死信消息是指无法被正常消费的消息.分布式消息服务DMS支持对消息进行异常处理.当消息进行多次重复消费仍然失败后 ...
- 分布式消息服务DMS与开源Kafka对比
分布式消息服务(简称DMS)是一项基于高可用分布式集群技术的消息中间件服务,提供了可靠且可扩展的托管消息队列,用于收发消息和存储消息.那么,比起自建开源的Kafka,分布式消息服务DMS有哪些好处呢? ...
- 搞懂分布式技术21:浅谈分布式消息技术 Kafka
搞懂分布式技术21:浅谈分布式消息技术 Kafka 浅谈分布式消息技术 Kafka 本文主要介绍了这几部分内容: 1基本介绍和架构概览 2kafka事务传输的特点 3kafka的消息存储格式:topi ...
- 分布式消息队列 Kafka
分布式消息队列 Kafka 2016-02-25 杜亦舒 Kafka是一个高吞吐量的.分布式的消息系统,由Linkedin开发,开发语言为scala具有高吞吐.可扩展.分布式等特点 适用场景 活动数据 ...
- 分布式消息系统kafka
kafka:一个分布式消息系统 1.背景 最近因为工作需要,调研了追求高吞吐的轻量级消息系统Kafka,打算替换掉线上运行的ActiveMQ,主要是因为明年的预算日流量有十亿,而ActiveMQ的分布 ...
- 浅谈分布式消息技术 Kafka(转)
一只神秘的程序猿. Kafka的基本介绍 Kafka是最初由Linkedin公司开发,是一个分布式.分区的.多副本的.多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可 ...
- 浅谈分布式消息技术 Kafka
Kafka的基本介绍Kafka是最初由Linkedin公司开发,是一个分布式.分区的.多副本的.多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/ngin ...
- 高并发面试必问:分布式消息系统Kafka简介
转载:https://blog.csdn.net/caisini_vc/article/details/48007297 Kafka是分布式发布-订阅消息系统.它最初由LinkedIn公司开发,之后成 ...
- 分布式消息系统Kafka初步
终于可以写kafka的文章了,Mina的相关文章我已经做了索引,在我的博客中置顶了,大家可以方便的找到.从这一篇开始分布式消息系统的入门. 在我们大量使用分布式数据库.分布式计算集群的时候,是否会遇到 ...
随机推荐
- JAVA基础知识|继承的几个问题
1.子类从父类继承了什么? 子类拥有父类非private的属性,方法. 2.子类可以操作父类的非private属性吗? 子类不能继承父类的私有属性,但是如果父类中的非private方法影响到了私有属性 ...
- 6.linux 用户和权限的建立
一.用户和权限的建立 su 用户名 切换用户,如果是root用户切换其他用户,不需要输入密码. exit 可以切换回上一个用户 linux 操作系统用户 ...
- Alpha项目冲刺! Day3-产出
各个成员今日完成的任务 林恩:任务分工,博客撰写,完善设置等模块 杨长元:安卓本地数据库基本建立 李震:完成注册页面 胡彤:完善服务端 寇永明:画图,学习 王浩:画图,学习 李杰:画图,学习 各个成员 ...
- 解决跨操作系统平台JSON中文乱码问题
解决跨操作系统平台JSON中文乱码问题 LINUX统一使用utf-8编码,WINDOWS却不是. LINUX中间件,传输JSON给WINDOWS程序,会乱码. 解决办法: 对JSON字段是字符串类型的 ...
- 通过phpMyAdmin优化mysql 数据库可能存在的问题
通过phpMyAdmin优化mysql 数据库可能存在的问题 文章来源:外星人来地球 欢迎关注,有问题一起学习欢迎留言.评论
- 反向代理Nginx
引用:https://baijiahao.baidu.com/s?id=1600687025749463237&wfr=spider&for=pc 参考下图,正向代理用途:Client ...
- requests与urllib.request
requests很明显,在写法上与urllib.request不同,前者多一个 S.导入包时:import requestsimport urllib.requesturllib.request请求模 ...
- 一百四十三:CMS系统之评论布局和功能一
模型 class CommentModel(db.Model): """ 评论 """ __tablename__ = 'comment' ...
- MapReduce本地运行模式wordcount实例(附:MapReduce原理简析)
1. 环境配置 a) 配置系统环境变量HADOOP_HOME b) 把hadoop.dll文件放到c:/windows/System32目录下 c) ...
- python 类型注解
函数定义的弊端 python 是动态语言,变量随时可以被赋值,且能赋值为不同类型 python 不是静态编译型语言,变量类型是在运行器决定的 动态语言很灵活,但是这种特性也是弊端 def add(x, ...