Lucene简单了解和使用
一,Lucene简介
1 、 Lucene 是什么?
Lucene 是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎。说到底它是一个信息检索程序库,而不是应用产品。因此它并不像百度或者 google 那样,拿来就能用,它只是提供了一种工具让你能实现这些产品。
2 、Lucene 能做什么?
要回答这个问题,先要了解 lucene 的本质。实际上 lucene 的功能很单一,说到底,就是我们给它若干个字符串,然后它为我们提供一个全文搜索服务,最后告诉我们要搜索的关键词出现在哪里。知道了这个本质,我们就可以发挥想象做任何符合这个条件的事情了。比如我们可以把站内新闻都索引了,做个资料库;也可以把一个数据库表的若干个字段索引起来,那就不用再担心因为“%like%”而锁表了;学完 lucene,你也可以写个自己的搜索引擎了……
3,Lucene 速度测试
下面给出一些测试数据,如果你觉得可以接受,那么可以选择。测试一:250 万记录,300M 左右文本,生成索引 380M 左右,800 线程下平均处理时间 300ms。
测试二:37000 记录,索引数据库中的两个 varchar 字段,索引文件2.6M,800 线程下平均处理时间 1.5ms。
二,深入lucene
1 、 为什么 lucene 这么快
1、倒排索引
2、压缩算法
3、二元搜索
2 、倒排序索引它是根据属性的值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(invertedindex)。
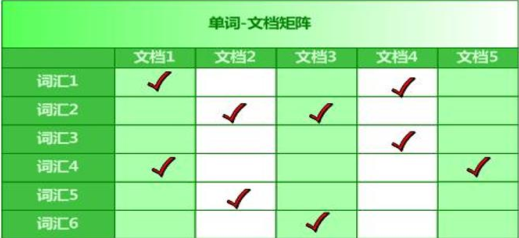
3 、 工作方式
Lucene 提供的服务实际包含两部分:一入一出。所谓入是写入,即将你提供的源(本质是字符串)写入索引或者将其从索引中删除;所谓出是读出,即向用户提供全文搜索服务,让用户可以通过关键词定位源。
4 、写入流程
1、源字符串首先经过 analyzer 处理,包括:分词,分成一个个单词;去除 stopword(可选)。
2、将源中需要的信息加入 Document 的各个 Field(信息域)中,并把需要索引的 Field 索引起来,把需要存储的 Field 存储起来。
3、将索引写入磁盘。
5 、读出流程
1、用户提供搜索关键词,经过 analyzer 处理。
2、对处理后的关键词搜索它的索引,找出对应的 Document。
3、用户根据需要从找到的 Document 中提取需要的 Field。
6 、Docement
用户提供的源是一条条记录,它们可以是文本文件、字符串或者数据库表的一条记录等等。一条记录经过索引之后,就是以一个Document 的形式存储在索引文件中的。用户进行搜索,也是以Document 列表的形式返回。
7 、Field
一个 Document 可以包含多个信息域,例如一篇文章可以包含“标题”、“正文”、“最后修改时间”等信息域,这些信息域就是通过 Field在 Document 中存储的。Field 有两个属性可选:存储和索引。通过存储属性你可以控制是否对这个 Field 进行存储;通过索引属性你可以控制是否对该Field 进行索引。这看起来似乎有些废话,事实上对这两个属性的正
确组合很重要。
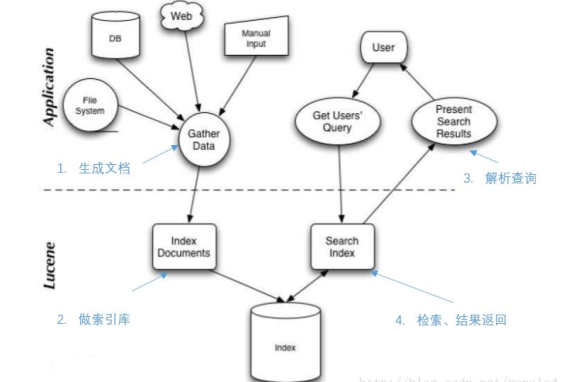
8 、 实现原理

Lucene 整体使用如图所示:
9 、环境配置
下载 lucene jar
官网:https://lucene.apache.org/
导入 jar 到项目中
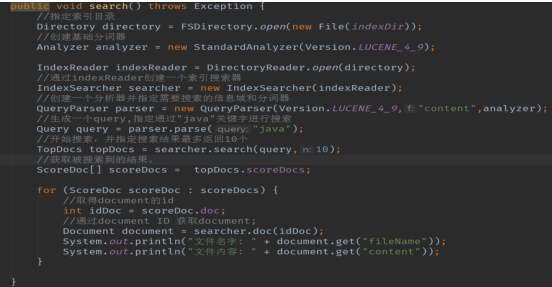
10 、创建索引

11 、查询索引
12 、其他功能
12.1 分词器
Lucene 自带的 StandardAnalyzer 分词器,只能对英语进行分词。在对中文进行分词的时候采用了一元分词,即每一个中文作为一个词,如“我是中国人”,则分词结果为“我”,“是”,“中”,“国”,“人”,可以看出分词效果很差。在这里推荐一个比较好用的中文分词器IKAnalyzer。
12.2 停用词
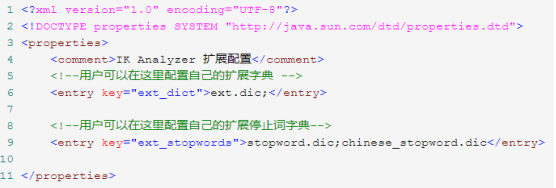
停用词是指在信息检索中,为节省存储空间和提高搜索效率,在处理自然语言数据(或文本)之前或之后会自动过滤掉某些字或词,这些字或词即被称为 Stop Words(停用词)。比如中文中“了”, “么”,“呢”,“的”等意义不大且在一篇文章中出现频率又很高的词,又比
如英文中的”for”,”in”,”it”,”a”,”or”等词。在使用 IKAnalyzer 分词器的时候,可以在 IKAnalyzer.cfg.xml里配置相关信息,如下图:
12.3 高亮-Highlighter

13,Field
一.Field 属性
Field 是文档中的域,包括 Field 名和 Field 值两部分,一个文档可以包括多个 Field,Document 只是 Field 的一个承载体,Field
值即为要索引的内容,也是要搜索的内容。
是否分词(tokenized)
是:作分词处理,即将 Field 值进行分词,分词的目的是为了索引。
比如:商品名称、商品简介等,这些内容用户要输入关键字搜索,由于搜索的内容格式大、内容多需要分词后将语汇单元索引。
否:不作分词处理
比如:商品 id、订单号、身份证号等
是否索引(indexed)
是:进行索引。将 Field 分词后的词或整个 Field 值进行索引,索引的目的是为了搜索。
比如:商品名称、商品简介分词后进行索引,订单号、身份证号不用分词但也要索引,这些将来都要作为查询条件。
否:不索引。该域的内容无法搜索到
比如:商品 id、文件路径、图片路径等,不用作为查询条件的不用索引。
是否存储(stored)
是:将 Field 值存储在文档中,存储在文档中的 Field 才可以从Document 中获取。
比如:商品名称、订单号,凡是将来要从 Document 中获取的 Field都要存储。
否:不存储 Field 值,不存储的 Field 无法通过 Document 获取
比如:商品简介,内容较大不用存储。如果要向用户展示商品简介可以从系统的关系数据库中获取商品简介。如果需要商品描述,则根据搜索出的商品 ID 去数据库中查询,然后
显示出商品描述信息即可。
二.Field 常用类型
开发中常用 的 Filed 类型,注意 Field 的属性,根据需求选择:
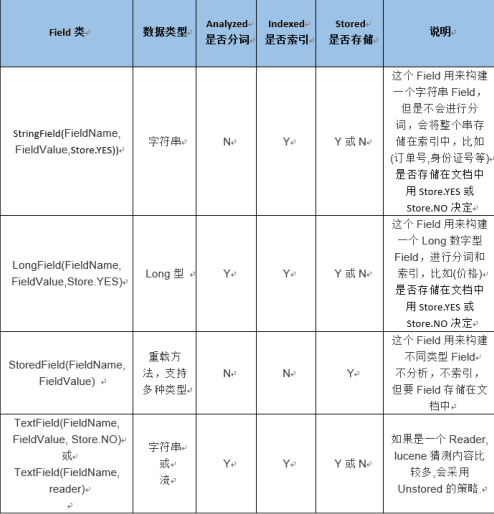
三. 例子
图书 id:
是否分词:不用分词,因为不会根据商品 id 来搜索商品
是否索引:不索引,因为不需要根据图书 ID 进行搜索
是否存储:要存储,因为查询结果页面需要使用 id 这个值
图书名称:
是否分词:要分词,因为要将图书的名称内容分词索引,根据关
键搜索图书名称抽取的词。
是否索引:要索引。
是否存储:要存储
图书价格:
是否分词:要分词,lucene 对数字型的值只要有搜索需求的都要
分词和索引,因为 lucene 对数字型的内容要特殊分词处理,本例
子可能要根据价格范 围搜索,需要分词和索引。
是否索引:要索引
是否存储:要存储
图书图片地址:
是否分词:不分词
是否索引:不索引
是否存储:要存储
图书描述:
是否分词:要分词
是否索引:要索引
是否存储:因为图书描述内容量大,不在查询结果页面直接显示,
不存储。 不存储是来不在 lucene 的索引文件中记录,节省 lucene
的索引文件空间, 如果要在详情页面显示描述,思路: 从 lucene
中取出图书的 id,根据图书的 id 查询关系数据库中 book 表 得
到描述信息。
Lucene简单了解和使用的更多相关文章
- Lucene 简单API使用
本demo 简单模拟实现一个图书搜索功能. 模拟向数据库添加数据的时候,添加书籍索引. 提供搜索接口,支持按照书名,作者,内容进行搜索. 按默认规则排序返回搜索结果. Jar依赖: <prope ...
- Lucene 简单手记http://www.cnblogs.com/hoojo/archive/2012/09/05/2671678.html
什么是全文检索与全文检索系统? 全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查 ...
- Lucene简单介绍
[2016.6.11]以前写的笔记,拿出来放到博客里面~ 相关软件: Solr, IK Analyzer, Luke, Nutch;Tomcat; 1.是什么: Lucene是apache软件基金会j ...
- lucene简单搜索demo
方法类 package com.wxf.Test; import com.wxf.pojo.Goods; import org.apache.lucene.analysis.standard.Stan ...
- Lucene简单总结
Lucene API Document Document:文档对象,是一条原始数据 文档编号 文档内容 1 谷歌地图之父跳槽FaceBook 2 谷歌地图之父加盟FaceBook 3 谷歌地图创始人拉 ...
- lucene简单使用demo
测试结构目录: 1.索引库.分词器 Configuration.java package com.test.www.web.lucene; import java.io.File; import or ...
- lucene简单使用
lucene7以上最低要求jdk1.8 lucene下载地址: http://archive.apache.org/dist/lucene/java/ <dependency> <g ...
- lucene 简单搜索步骤
1.创建IndexReader实例: Directory dir = FSDirectory.open(new File(indexDir)); IndexReader reader = Direct ...
- Lucene入门的基本知识(四)
刚才在写创建索引和搜索类的时候发现非常多类的概念还不是非常清楚,这里我总结了一下. 1 lucene简单介绍 1.1 什么是lucene Lucene是一个全文搜索框架,而不是应用产品.因此它并不 ...
随机推荐
- 【VS开发】Wix 安装教程
original link : http://www.cnblogs.com/stoneniqiu/p/3355086.html 因为项目需要,最近在研究Wix打包部署,园子里也有一些关于wix ...
- MySQL 事务一览
MySQL 中的事务? 对 MySQL 来说,事务通常是一组包含对数据库操作的集合.在执行时,只有在该组内的事务都执行成功,这个事务才算执行成功,否则就算失败.MySQL 中,事务支持是在引擎层实现的 ...
- CNN-1: LeNet-5 卷积神经网络模型
1.LeNet-5模型简介 LeNet-5 模型是 Yann LeCun 教授于 1998 年在论文 Gradient-based learning applied to document ...
- Jmeter CSV操作
统计行号列号 import java.io.BufferedReader; import java.io.FileReader; import java.io.File; print("== ...
- VC++操作注册表(创建,读取,更改,删除)
#include "stdafx.h" #include <Windows.h> #include <iostream> using namespace s ...
- 华为S5700系列交换机配置文件导出、导入
一.导出 配置用户名密码,使能ftp ftp server enable aaa local-user putty password cipher putty123 local-user putty ...
- Python——类和对象(一)
一.定义类 在面向对象的程序设计中有两种重要概念: 类:可以理解为一个种类,一个模型,是一种抽象的东西. 实例.对象:可以理解为一种具体制作或者存在的东西. 定义类的语法格式如下: class 类名: ...
- PAT(B) 1017 A除以B(Java)
题目链接:1017 A除以B 分析 读取输入的A和B后,保存为字符串.模拟除法运算过程. 不要用BigInteger,因为会超时. 另外字符串经常要扩展(例如:append())的话,不要用Strin ...
- Gossip协议
Gossip数据传播协议: Fabric通过将工作负载划分到事务执行(背书和提交)对等节点和事务排序节点,优化了区块链网络性能.安全性和可伸缩性.这种网络操作的解耦需要一个安全.可靠和可伸缩的数据传播 ...
- QLineEdit的信号函数
QLineEdit一共有6个信号函数,并不多,很好理解. ·void cursorPositionChanged( intold, intnew ) 当鼠标移动时发出此信号,old为先前的位置,new ...