go语言入门(6)复合类型
1,分类

2,指针
指针是一个代表着某个内存地址的值。这个内存地址往往是在内存中存储的另一个变量的值的起始位置。
1)基本操作
Go语言虽然保留了指针,但与其它编程语言不同的是:
- 默认值 nil,没有 NULL 常量
- 操作符 "&" 取变量地址, "*" 通过指针访问目标对象
- 不支持指针运算,不支持 "->" 运算符,直接⽤ "." 访问目标成员
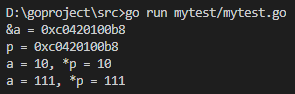
func main() {
var a int = //声明一个变量,同时初始化
fmt.Printf("&a = %p\n", &a) //操作符 "&" 取变量地址
var p *int = nil //声明一个变量p, 类型为 *int, 指针类型
p = &a
fmt.Printf("p = %p\n", p)
fmt.Printf("a = %d, *p = %d\n", a, *p)
*p = //*p操作指针所指向的内存,即为a
fmt.Printf("a = %d, *p = %d\n", a, *p)
}
2)new函数
表达式new(T)将创建一个T类型的匿名变量,所做的是为T类型的新值分配并清零一块内存空间,然后将这块内存空间的地址作为结果返回,而这个结果就是指向这个新的T类型值的指针值,返回的指针类型为*T。
func main() {
var p1 *int
p1 = new(int) //p1为*int 类型, 指向匿名的int变量
fmt.Println("*p1 = ", *p1) //*p1 = 0
p2 := new(int) //p2为*int 类型, 指向匿名的int变量
*p2 =
fmt.Println("*p2 = ", *p2) //*p1 = 111
}

我们只需使用new()函数,无需担心其内存的生命周期或怎样将其删除,因为Go语言的内存管理系统会帮我们打理一切。
3)指针做函数参数
func swap01(a, b int) {
a, b = b, a
fmt.Printf("swap01 a = %d, b = %d\n", a, b)
}
func swap02(x, y *int) {
*x, *y = *y, *x
}
func main() {
a :=
b :=
//swap01(a, b) //值传递
swap02(&a, &b) //变量地址传递
fmt.Printf("a = %d, b = %d\n", a, b)
}
3,数组
1)概述
数组是指一系列同一类型数据的集合。数组中包含的每个数据被称为数组元素(element),一个数组包含的元素个数被称为数组的长度。
数组长度必须是常量,且是类型的组成部分。 [2]int 和 [3]int 是不同类型。
var n int =
var a [n]int //err, non-constant array bound n
var b []int //ok
2)操作数组
数组的每个元素可以通过索引下标来访问,索引下标的范围是从0开始到数组长度减1的位置。
var a []int
for i := ; i < ; i++ {
a[i] = i +
fmt.Printf("a[%d] = %d\n", i, a[i])
} //range具有两个返回值,第一个返回值是元素的数组下标,第二个返回值是元素的值
for i, v := range a {
fmt.Println("a[", i, "]=", v)
}
内置函数 len(长度) 和 cap(容量) 都返回数组长度 (元素数量):
a := []int{}
fmt.Println(len(a), cap(a))//10 10
初始化:
a := []int{, } // 未初始化元素值为 0
b := [...]int{, , } // 通过初始化值确定数组长度
c := []int{: , : } // 通过索引号初始化元素,未初始化元素值为 0
fmt.Println(a, b, c) //[1 2 0] [1 2 3] [0 0 100 0 200]
//支持多维数组
d := [][]int{{, }, {, }, {, }, {, }}
e := [...][]int{{, }, {, }, {, }, {, }} //第二维不能写"..."
f := [][]int{: {, }, : {, }}
g := [][]int{: {: }, : {: }}
fmt.Println(d, e, f, g)
相同类型的数组之间可以使用 == 或 != 进行比较,但不可以使用 < 或 >,也可以相互赋值:
3)函数间传递数组
根据内存和性能来看,在函数间传递数组是一个开销很大的操作。在函数之间传递变量时,总是以值的方式传递的。如果这个变量是一个数组,意味着整个数组,不管有多长,都会完整复制,并传递给函数。
func modify(array []int) {
array[] = // 试图修改数组的第一个元素
//In modify(), array values: [10 2 3 4 5]
fmt.Println("In modify(), array values:", array)
}
func main() {
array := []int{, , , , } // 定义并初始化一个数组
modify(array) // 传递给一个函数,并试图在函数体内修改这个数组内容
//In main(), array values: [1 2 3 4 5]
fmt.Println("In main(), array values:", array)
}
数组指针做函数参数:
func modify(array *[]int) {
(*array)[] =
//In modify(), array values: [10 2 3 4 5]
fmt.Println("In modify(), array values:", *array)
}
func main() {
array := []int{, , , , } // 定义并初始化一个数组
modify(&array) // 数组指针
//In main(), array values: [10 2 3 4 5]
fmt.Println("In main(), array values:", array)
}
4,slice
1)概述
数组的长度在定义之后无法再次修改;数组是值类型,每次传递都将产生一份副本。显然这种数据结构无法完全满足开发者的真实需求。Go语言提供了数组切片(slice)来弥补数组的不足。
切片并不是数组或数组指针,它通过内部指针和相关属性引用数组片段。
slice 并不是真正意义上的动态数组,而是一个引用类型。slice总是指向一个底层array,slice的声明也可以像array一样,只是不需要长度。
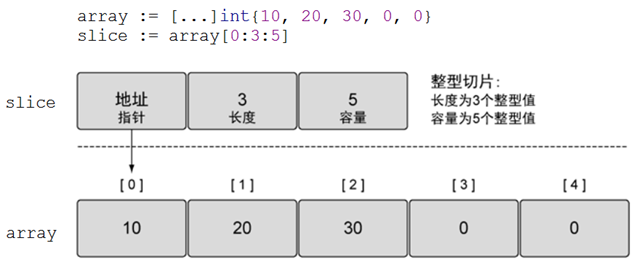
2)切片的创建和初始化
slice和数组的区别:声明数组时,方括号内写明了数组的长度或使用...自动计算长度,而声明slice时,方括号内没有任何字符。
var s1 []int //声明切片和声明array一样,只是少了长度,此为空(nil)切片
s2 := []int{} //make([]T, length, capacity) //capacity省略,则和length的值相同
var s3 []int = make([]int, )
s4 := make([]int, , ) s5 := []int{, , } //创建切片并初始化
注意:make只能创建slice、map和channel,并且返回一个有初始值(非零)。
3)切片的操作
3.1)切片截取

示例说明:
array := []int{, , , , , , , , , }

3.2)切片和底层数组的关系
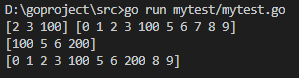
s := []int{, , , , , , , , , }
s1 := s[:] //[2 3 4]
s1[] = //修改切片某个元素改变底层数组
fmt.Println(s1, s) //[2 3 100] [0 1 2 3 100 5 6 7 8 9]
s2 := s1[:] // 新切片依旧指向原底层数组 [100 5 6 7]
s2[] =
fmt.Println(s2) //[100 5 6 200]
fmt.Println(s) //[0 1 2 3 100 5 6 200 8 9]
3.3)内建函数
append
append函数向 slice 尾部添加数据,返回新的 slice 对象:
var s1 []int //创建nil切换
//s1 := make([]int, 0)
s1 = append(s1, ) //追加1个元素
s1 = append(s1, , ) //追加2个元素
s1 = append(s1, , , ) //追加3个元素
fmt.Println(s1) //[1 2 3 4 5 6] s2 := make([]int, )
s2 = append(s2, )
fmt.Println(s2) //[0 0 0 0 0 6] s3 := []int{, , }
s3 = append(s3, , )
fmt.Println(s3)//[1 2 3 4 5]
append函数会智能地底层数组的容量增长,一旦超过原底层数组容量,通常以2倍容量重新分配底层数组,并复制原来的数据:
func main() {
s := make([]int, , )
c := cap(s)
for i := ; i < ; i++ {
s = append(s, i)
if n := cap(s); n > c {
fmt.Printf("cap: %d -> %d\n", c, n)
c = n
}
}
}

copy
函数 copy 在两个 slice 间复制数据,复制长度以 len 小的为准,两个 slice 可指向同一底层数组。
data := [...]int{, , , , , , , , , }
s1 := data[:] //{8, 9}
s2 := data[:] //{0, 1, 2, 3, 4}
copy(s2, s1) // dst:s2, src:s1
fmt.Println(s2) //[8 9 2 3 4]
fmt.Println(data) //[8 9 2 3 4 5 6 7 8 9]
4)切片做函数参数
func test(s []int) { //切片做函数参数
s[] = -
fmt.Println("test : ")
for i, v := range s {
fmt.Printf("s[%d]=%d, ", i, v)
//s[0]=-1, s[1]=1, s[2]=2, s[3]=3, s[4]=4, s[5]=5, s[6]=6, s[7]=7, s[8]=8, s[9]=9,
}
fmt.Println("\n")
}
func main() {
slice := []int{, , , , , , , , , }
test(slice)
fmt.Println("main : ")
for i, v := range slice {
fmt.Printf("slice[%d]=%d, ", i, v)
//slice[0]=-1, slice[1]=1, slice[2]=2, slice[3]=3, slice[4]=4, slice[5]=5, slice[6]=6, slice[7]=7, slice[8]=8, slice[9]=9,
}
fmt.Println("\n")
}
5,map
1)概述
Go语言中的map(映射、字典)是一种内置的数据结构,它是一个无序的key—value对的集合,比如以身份证号作为唯一键来标识一个人的信息。
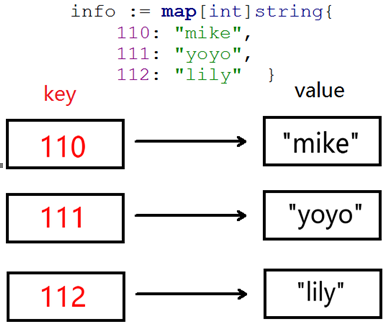
map格式为:
map[keyType]valueType
在一个map里所有的键都是唯一的,而且必须是支持==和!=操作符的类型,切片、函数以及包含切片的结构类型这些类型由于具有引用语义,不能作为映射的键,使用这些类型会造成编译错误:
dict := map[ []string ]int{} //err, invalid map key type []string
map值可以是任意类型,没有限制。map里所有键的数据类型必须是相同的,值也必须相同类型,但键和值的数据类型可以不相同。
2)创建和初始化
2.1) map的创建
var m1 map[int]string //只是声明一个map,没有初始化, 此为空(nil)map
fmt.Println(m1 == nil) //true
//m1[1] = "mike" //err, panic: assignment to entry in nil map //m2, m3的创建方法是等价的
m2 := map[int]string{}
m3 := make(map[int]string)
fmt.Println(m2, m3) //map[] map[] m4 := make(map[int]string, ) //第2个参数指定容量
fmt.Println(m4) //map[]
2.2) map的初始化
//1、定义同时初始化
var m1 map[int]string = map[int]string{: "mike", : "yoyo"}
fmt.Println(m1) //map[1:mike 2:yoyo] //2、自动推导类型 :=
m2 := map[int]string{: "mike", : "yoyo"}
fmt.Println(m2)
3)常用操作
3.1)赋值
m1 := map[int]string{: "mike", : "yoyo"}
m1[] = "xxx" //修改
m1[] = "lily" //追加, go底层会自动为map分配空间
fmt.Println(m1) //map[1:xxx 2:yoyo 3:lily]
m2 := make(map[int]string, ) //创建map
m2[] = "aaa"
m2[] = "bbb"
fmt.Println(m2) //map[0:aaa 1:bbb]
fmt.Println(m2[], m2[]) //aaa bbb
3.2)遍历
m1 := map[int]string{: "mike", : "yoyo"}
//迭代遍历1,第一个返回值是key,第二个返回值是value
for k, v := range m1 {
fmt.Printf("%d ----> %s\n", k, v)
//1 ----> mike
//2 ----> yoyo
}
//迭代遍历2,第一个返回值是key,第二个返回值是value(可省略)
for k := range m1 {
fmt.Printf("%d ----> %s\n", k, m1[k])
//1 ----> mike
//2 ----> yoyo
}
//判断某个key所对应的value是否存在, 第一个返回值是value(如果存在的话)
value, ok := m1[]
fmt.Println("value = ", value, ", ok = ", ok) //value = mike , ok = true
value2, ok2 := m1[]
fmt.Println("value2 = ", value2, ", ok2 = ", ok2) //value2 = , ok2 = false
3.3)删除
m1 := map[int]string{: "mike", : "yoyo", : "lily"}
//迭代遍历1,第一个返回值是key,第二个返回值是value
for k, v := range m1 {
fmt.Printf("%d ----> %s\n", k, v)
//1 ----> mike
//2 ----> yoyo
//3 ----> lily
}
delete(m1, ) //删除key值为3的map
for k, v := range m1 {
fmt.Printf("%d ----> %s\n", k, v)
//1 ----> mike
//3 ----> lily
}
4,map做函数参数
在函数间传递映射并不会制造出该映射的一个副本,不是值传递,而是引用传递:
func DeleteMap(m map[int]string, key int) {
delete(m, key) //删除key值为3的map
for k, v := range m {
fmt.Printf("len(m)=%d, %d ----> %s\n", len(m), k, v)
//len(m)=2, 1 ----> mike
//len(m)=2, 3 ----> lily
}
}
func main() {
m := map[int]string{: "mike", : "yoyo", : "lily"}
DeleteMap(m, ) //删除key值为3的map
for k, v := range m {
fmt.Printf("len(m)=%d, %d ----> %s\n", len(m), k, v)
//len(m)=2, 1 ----> mike
//len(m)=2, 3 ----> lily
}
}
6,结构体
1)结构体类型
有时我们需要将不同类型的数据组合成一个有机的整体,如:一个学生有学号/姓名/性别/年龄/地址等属性。显然单独定义以上变量比较繁琐,数据不便于管理。
结构体是一种聚合的数据类型,它是由一系列具有相同类型或不同类型的数据构成的数据集合。每个数据称为结构体的成员。
2)结构体初始化
2.1)普通变量
type Student struct {
id int
name string
sex byte
age int
addr string
}
func main() {
//1、顺序初始化,必须每个成员都初始化
var s1 Student = Student{, "mike", 'm', , "sz"}
s2 := Student{, "yoyo", 'f', , "sz"}
//s3 := Student{2, "tom", 'm', 20} //err, too few values in struct initializer
//2、指定初始化某个成员,没有初始化的成员为零值
s4 := Student{id: , name: "lily"}
}
2.2)指针变量
type Student struct {
id int
name string
sex byte
age int
addr string
}
func main() {
var s5 *Student = &Student{, "xiaoming", 'm', , "bj"}
s6 := &Student{, "rocco", 'm', , "sh"}
}
3)结构体成员的使用
3.1)普通变量
//===============结构体变量为普通变量
//1、打印成员
var s1 Student = Student{, "mike", 'm', , "sz"}
//结果:id = 1, name = mike, sex = m, age = 18, addr = sz
fmt.Printf("id = %d, name = %s, sex = %c, age = %d, addr = %s\n", s1.id, s1.name, s1.sex, s1.age, s1.addr) //2、成员变量赋值
var s2 Student
s2.id =
s2.name = "yoyo"
s2.sex = 'f'
s2.age =
s2.addr = "guangzhou"
fmt.Println(s2) //{2 yoyo 102 16 guangzhou}
3.2)指针变量
//===============结构体变量为指针变量
//3、先分配空间,再赋值
s3 := new(Student)
s3.id =
s3.name = "xxx"
fmt.Println(s3) //&{3 xxx 0 0 } //4、普通变量和指针变量类型打印
var s4 Student = Student{, "yyy", 'm', , "sz"}
fmt.Printf("s4 = %v, &s4 = %v\n", s4, &s4) //s4 = {4 yyy 109 18 sz}, &s4 = &{4 yyy 109 18 sz} var p *Student = &s4
//p.成员 和(*p).成员 操作是等价的
p.id =
(*p).name = "zzz"
fmt.Println(p, *p, s4) //&{5 zzz 109 18 sz} {5 zzz 109 18 sz} {5 zzz 109 18 sz}
4)结构体比较
如果结构体的全部成员都是可以比较的,那么结构体也是可以比较的,那样的话两个结构体将可以使用 == 或 != 运算符进行比较,但不支持 > 或 < 。
func main() {
s1 := Student{, "mike", 'm', , "sz"}
s2 := Student{, "mike", 'm', , "sz"}
fmt.Println("s1 == s2", s1 == s2) //s1 == s2 true
fmt.Println("s1 != s2", s1 != s2) //s1 != s2 false
}
5)结构体作为函数参数
5.1)值传递
func printStudentValue(tmp Student) {
tmp.id =
//printStudentValue tmp = {250 mike 109 18 sz}
fmt.Println("printStudentValue tmp = ", tmp)
}
func main() {
var s Student = Student{, "mike", 'm', , "sz"}
printStudentValue(s) //值传递,形参的修改不会影响到实参
fmt.Println("main s = ", s) //main s = {1 mike 109 18 sz}
}
5.2)引用传递
func printStudentPointer(p *Student) {
p.id =
//printStudentPointer p = &{250 mike 109 18 sz}
fmt.Println("printStudentPointer p = ", p)
}
func main() {
var s Student = Student{, "mike", 'm', , "sz"}
printStudentPointer(&s) //引用(地址)传递,形参的修改会影响到实参
fmt.Println("main s = ", s) //main s = {250 mike 109 18 sz}
}
6)可见性
Go语言对关键字的增加非常吝啬,其中没有private、 protected、 public这样的关键字。
要使某个符号对其他包(package)可见(即可以访问),需要将该符号定义为以大写字母开头。

test.go示例代码如下:
//test.go
package test //student01只能在本文件件引用,因为首字母小写
type student01 struct {
Id int
Name string
} //Student02可以在任意文件引用,因为首字母大写
type Student02 struct {
Id int
name string
}
main.go示例代码如下:
// main.go
package main import (
"fmt"
"test" //导入test包
) func main() {
//s1 := test.student01{1, "mike"} //err, cannot refer to unexported name test.student01 //err, implicit assignment of unexported field 'name' in test.Student02 literal
//s2 := test.Student02{2, "yoyo"}
//fmt.Println(s2) var s3 test.Student02 //声明变量
s3.Id = //ok
//s3.name = "mike" //err, s3.name undefined (cannot refer to unexported field or method name)
fmt.Println(s3)
}
go语言入门(6)复合类型的更多相关文章
- C语言中的复合类型
复合类型 一.掌握的类型 1. 指针数组 int * arr[10]; //arr是一个数组,有10个元素,每个元素都是一个指针,即arr是一个指针数组 int a,b,c,d; arr[0] = & ...
- go语言基础之复合类型
1.分类 类型 名称 长度 默认值 说明 pointer 指针 nil array 数组 0 slice 切片 nil 引⽤类型 map 字典 nil 引⽤类型 struct 结构体 2.指针 指针是 ...
- Go语言入门篇-复合数据类型
复合数据类型 主要讨论四种类型——数组.slice.map和结构体 数组和结构体聚合类型 --数组和结构体都是有固定内存大小的数据结构 --数组:由同构的元素组成——每个数组元素都是完全相同的类型 ...
- C++学习(八)入门篇——复合类型
数组(需要声明以下三点): (1)存储在每个元素中值的类型 (2)数组名 (3)数组中的元素数 声明数组的通用格式如下: typeName arrayName[arraySize];arraySize ...
- Go语言入门篇-基本类型排序和 slice 排序
参见博客:https://blog.csdn.net/u010983881/article/details/52460998 package main import ( "sort" ...
- go语言 类型:基础类型和复合类型
Go 语言中包括以下内置基础类型:布尔型:bool整型:int int64 int32 int16 int8 uint8(byte) uint16 uint32 uint64 uint浮点型:floa ...
- 带你学够浪:Go语言基础系列 - 8分钟学复合类型
★ 文章每周持续更新,原创不易,「三连」让更多人看到是对我最大的肯定.可以微信搜索公众号「 后端技术学堂 」第一时间阅读(一般比博客早更新一到两篇) " 对于一般的语言使用者来说 ,20% ...
- Java入门 - 语言基础 - 06.变量类型
原文地址:http://www.work100.net/training/java-variable-type.html 更多教程:光束云 - 免费课程 变量类型 序号 文内章节 视频 1 概述 2 ...
- 《C语言入门1.2.3—一个老鸟的C语言学习心得》—清华大学出版社炮制的又一本劣书及伪书
<C语言入门1.2.3—一个老鸟的C语言学习心得>—清华大学出版社炮制的又一本劣书及伪书 [薛非评] 区区15页,有80多个错误. 最严重的有: 通篇完全是C++代码,根本不是C语言代码. ...
- c语言入门这一篇就够了-学习笔记(一万字)
内容来自慕课网,个人学习笔记.加上了mtianyan标签标记知识点. C语言入门 -> Linux C语言编程基本原理与实践 -> Linux C语言指针与内存 -> Linux C ...
随机推荐
- C++ STL swap_range
#include <iostream>#include <vector>#include <deque>#include <algorithm> usi ...
- Anaconda3详细安装使用教程及问题总结
1.Anaconda是什么? 简单来说,Anaconda是Python的包管理器和环境管理器. 先来解决一个初学者都会问的问题:我已经安装了Python,那么为什么还需要Anaconda呢?原因有以下 ...
- js 高级程序设计 第三章学习笔记——Number数据类型需要注意的事项
1.浮点数值 虽然小数点前面可以没有整数,但是并不推荐这种写法. 由于保存浮点数值需要的内存空间是保存整数值的两倍,因此ECMAScript会不失时机地将浮点数值转化为整数数值.显然,如果小数点后面没 ...
- Sprint Retrospective - 回顾的重要性
在Scrum中,每个Sprint结束的时候会有两个会议(Sprint Review/Demo和Sprint Retrospective回顾).这两个会议是对过去的一个Sprint的一个总结,其中Rev ...
- 【ARM-Linux开发】ARM7 ARM9 ARM Cortex M3 M4 有什么区别
ARM7 ARM9 ARM Cortex M3 M4 区别 arm7 arm9 可以类比386和奔腾, 不同代,arm9相比arm7指令集和性能都有所增强,arm7和arm9都有带mmu和无mmu的版 ...
- 【并行计算-CUDA开发】 NVIDIA Jetson TX1
概述 NVIDIA Jetson TX1是计算机视觉系统的SoM(system-on-module)解决方案.它组合了最新的NVIDIAMaxwell GPU架构,其具有ARM Cortex-A57 ...
- Java编程思想(三)控制程序流程
3.1.10逗号运算符 我们可以使用一系列由逗号分隔的语句,而且哪些语句均会独立执行. 3.1.15复习计算顺序
- kubernetes--资源清单
⒈资源含义 k8s中所有的内容都被抽象为资源,资源实例化之后,叫做对象. ⒉资源分类 名称空间级别 仅在此名称空间下生效,k8s的系统组件是默认放在kube-system名称空间下的,而kubectl ...
- S02_CH07_ ZYNQ PL中断请求
S02_CH07_ ZYNQ PL中断请求 7.1 ZYNQ 中断介绍 7.1.1 ZYNQ中断框图 可以看到本例子中PL到PS部分的中断经过ICD控制器分发器后同时进入CPU1 和CPU0.从下面的 ...
- oracle学习笔记03
一:表空间 /* 创建表空间:逻辑单位,通常我们新建一个项目,就会去创建表空间,在表空间中创建用户,用户去创建表. 语法:create tablespace 表空间名字 datafile '文件的路径 ...