利用Python进行数据分析_Pandas_处理缺失数据
申明:本系列文章是自己在学习《利用Python进行数据分析》这本书的过程中,为了方便后期自己巩固知识而整理。
1 读取excel数据
import pandas as pd
import numpy as np
file = 'D:\example.xls'
df = pd.DataFrame(pd.read_excel(file))
df

2 检测缺失值
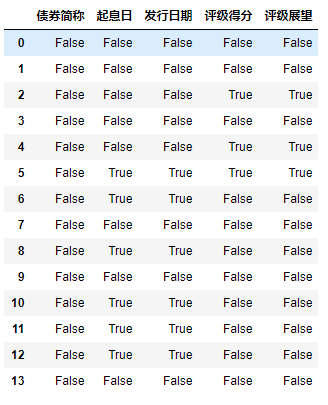
2.1 isnull返回一个含有布尔值的对象
import pandas as pd
import numpy as np
file = 'D:\example.xls'
df = pd.DataFrame(pd.read_excel(file))
df = df.isnull()
df
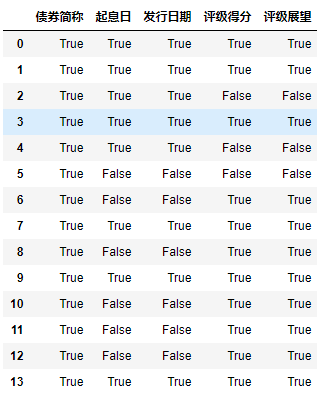
2.2 notnull 是isnull 的否定式
import pandas as pd
import numpy as np
file = 'D:\example.xls'
df = pd.DataFrame(pd.read_excel(file))
df = df.notnull()
df
3 滤除缺失数据
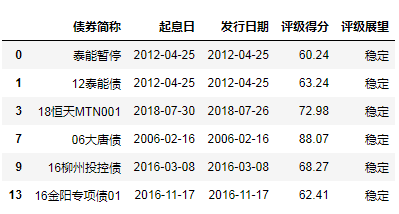
3.1 滤除所有包含缺失值的行
df.dropna()
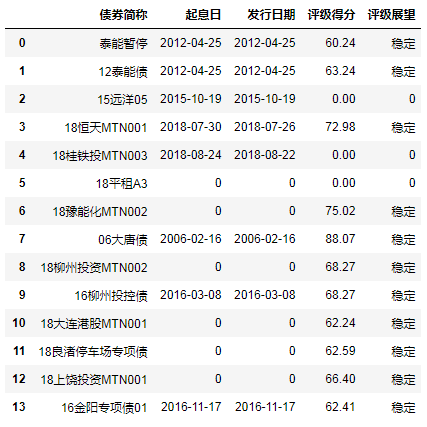
3.2 查看不含缺失值的所有行、列
df.dropna(thresh=4)

4 填充缺失数据
DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None, **kwargs)
4.1 统一填充某一个值value
df.fillna(0)或df.fillna(value=0)
4.2 用前面的值填充缺失部分
df.fillna(method='ffill')
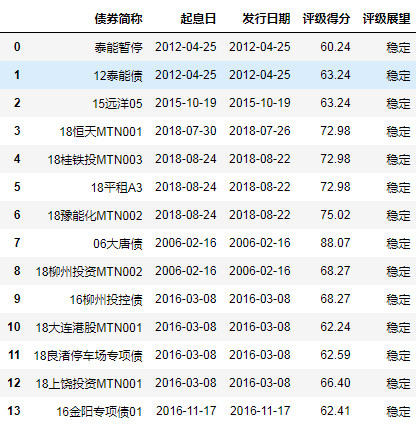
4.3 用后面的值填充缺失部分
df.fillna(method='bfill')
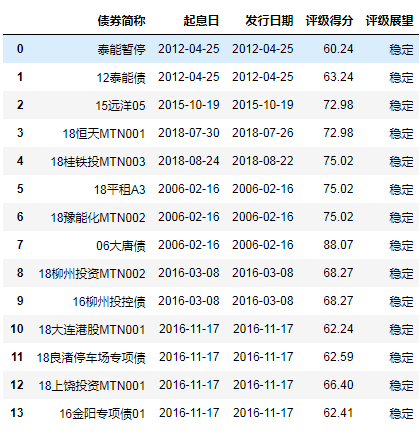
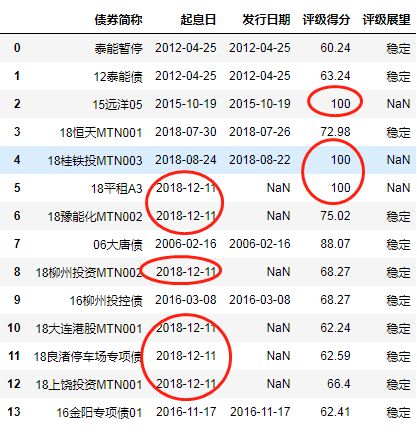
4.3 某N列用特定的值填充缺失部分
df.fillna({'起息日':'2018-12-11','评级得分':''})
4.4 指定一整个轴的值填充缺失部分
df.fillna(method='ffill',axis=1)

利用Python进行数据分析_Pandas_处理缺失数据的更多相关文章
- 利用Python进行数据分析(12) pandas基础: 数据合并
pandas 提供了三种主要方法可以对数据进行合并: pandas.merge()方法:数据库风格的合并: pandas.concat()方法:轴向连接,即沿着一条轴将多个对象堆叠到一起: 实例方法c ...
- 利用Python进行数据分析_Pandas_数据加载、存储与文件格式
申明:本系列文章是自己在学习<利用Python进行数据分析>这本书的过程中,为了方便后期自己巩固知识而整理. 1 pandas读取文件的解析函数 read_csv 读取带分隔符的数据,默认 ...
- 利用Python进行数据分析_Pandas_基本功能
申明:本系列文章是自己在学习<利用Python进行数据分析>这本书的过程中,为了方便后期自己巩固知识而整理. 第一 重新索引 Series的reindex方法 In [15]: obj = ...
- 利用Python进行数据分析_Pandas_数据结构
申明:本系列文章是自己在学习<利用Python进行数据分析>这本书的过程中,为了方便后期自己巩固知识而整理. 首先,需要导入pandas库的Series和DataFrame In [21] ...
- 利用Python进行数据分析_Pandas_层次化索引
申明:本系列文章是自己在学习<利用Python进行数据分析>这本书的过程中,为了方便后期自己巩固知识而整理. 层次化索引主要解决低纬度形式处理高纬度数据的问题 import pandas ...
- 利用Python进行数据分析_Pandas_汇总和计算描述统计
申明:本系列文章是自己在学习<利用Python进行数据分析>这本书的过程中,为了方便后期自己巩固知识而整理. In [1]: import numpy as np In [2]: impo ...
- 利用Python进行数据分析_Pandas_数据清理、转换、合并、重塑
1 合并数据集 pandas.merge pandas.merge(left, right, how='inner', on=None, left_on=None, right_on=None, le ...
- 利用Python进行数据分析 第6章 数据加载、存储与文件格式(2)
6.2 二进制数据格式 实现数据的高效二进制格式存储最简单的办法之一,是使用Python内置的pickle序列化. pandas对象都有一个用于将数据以pickle格式保存到磁盘上的to_pickle ...
- 利用Python进行数据分析 第8章 数据规整:聚合、合并和重塑.md
学习时间:2019/11/03 周日晚上23点半开始,计划1110学完 学习目标:Page218-249,共32页:目标6天学完(按每页20min.每天1小时/每天3页,需10天) 实际反馈:实际XX ...
随机推荐
- tomcat设置gzip
使用tomcat发布3dtiles或terrain数据遇到的gzip问题 问题一 对大于1KB的json请求进行gzip压缩,json为原文件 1.创建原始文件 2.设置 在apache-tomcat ...
- 在 Arch 上Yaourt 使用这些替代品
1. aurman aurman 是最好的 AUR 助手之一,也能胜任 Yaourt 替代品的地位.它有非常类似于 pacman 的语法,可以支持所有的 pacman 操作.你可以搜索 AUR.解决包 ...
- Why use swap when there is more than enough RAM.
Swappiness is a property of the Linux kernel that changes the balance between swapping out runtime m ...
- 【spark 算子案例】
package spark_example01; import java.io.File; import java.io.FileWriter; import java.io.IOException; ...
- Java项目开发
项目开发整体构建: MVC+DAO设计模式 用面向对象的方式理解和使用数据库,一个数据库对应一个java项目 数据库--项目 表--类 字段--属性 表中的一条数据--类的一个对象 M:模型层 Jav ...
- jQuery Ajax calls and the Html.AntiForgeryToken()
jQuery Ajax calls and the Html.AntiForgeryToken() https://stackoverflow.com/a/4074289/3782855 I use ...
- Maven多镜像配置
Maven阿里云镜像相信国内用得是很爽的,但有时候,一些版本的包明明可以在http://mvnrepository.com上搜索到.但你确实下载不来... 废话不多,settings.xml多镜像配置 ...
- Django之数据库对象关系映射
Django ORM基本配置 到目前为止,当我们的程序涉及到数据库相关操作时,我们一般都会这么搞: 创建数据库,设计表结构和字段 使用 MySQLdb 来连接数据库,并编写数据访问层代码 业务逻辑层去 ...
- MauiMETA工具的使用(一)
MauiMETA工具的使用(一) 摘自:https://www.jianshu.com/p/a377119947f8 tianxiaoMCU 关注 2018.12.21 14:15 字数 267 ...
- CentOS7下配置Tomcat以APR模式+Tomcat Native运行
在慢速网络上Tomcat线程数开到300以上的水平,不配APR,基本上300个线程狠快就会用满,以后的请求就只好等待.但是配上APR之后,Tomcat将以JNI的形式调用Apache HTTP服务器的 ...