十一、FHS基础原理
文件系统: http://note.youdao.com/noteshare?id=298f02714da5b9483429a40dda667f35&sub=6120396419BA477EBF7F15F1799E4DC4
更详细可参考 :骏马金龙的博客,
一、一些常见的文件系统
- Linux的文件系统: ext2(无日志功能), ext3, ext4, xfs, reiserfs, btrfs
- 光盘:iso9660
- 交换文件系统:swap (虚拟内存)
- 网络文件系统:nfs, cifs
- 集群文件系统:gfs2, ocfs2
- 内核级分布式文件系统:ceph
- windows的文件系统:vfat, ntfs
- 伪文件系统:proc, sysfs, tmpfs, hugepagefs
- Unix的文件系统:UFS, FFS, JFS
- 用户空间的分布式文件系统:mogilefs, moosefs, glusterfs
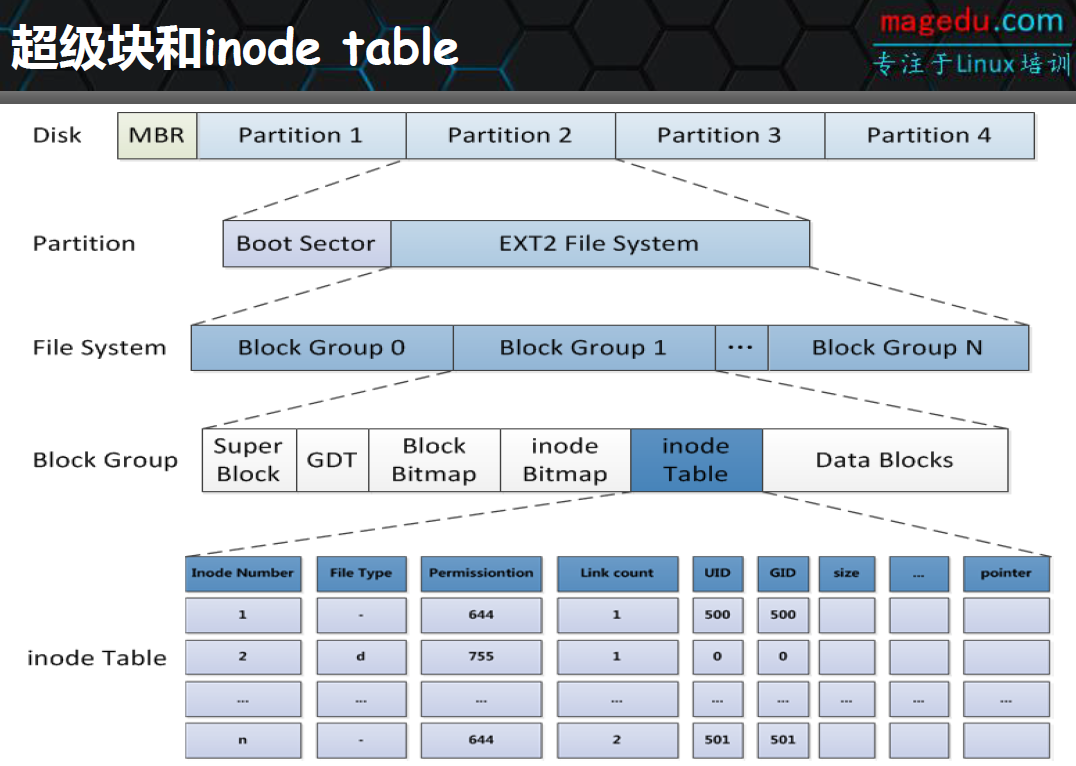
二、文件系统的组成
1. block:块
Linux文件系统中使用“block”块为读写单元,块的大小一般为1024bytes(1k)或2048bytes(2k)或4096bytes(4k)。比如需要读一个或多个块时,文件系统的IO管理器通知磁盘控制器要读取哪些块的数据,硬盘控制器将这些块按扇区读取出来,再通过硬盘控制器将这些扇区数据重组返回给计算机。但是其缺点就是会照成空间浪费,比如一个只有96字节的文件也要完整的占有一个块,那么剩余的空间就会造成浪费。
2. inode(index node,索引节点)、inode表
inode的作用主要是高效、有序的查找文件,而文件存储于数量不一的block中。
inode中存储了inode号、文件类型、权限、文件所有者、大小、时间戳等元数据信息,还存储了指向属于该文件block的指针,这样读取inode就可以找到属于该文件的block,进而读取这些block并获得该文件的数据。可以将inode同类理解为目录。
(a)inode 记录的文件数据:inode唯独不包含文件名(文件名在目录上)。
根目录是自引用的,目录是一个映射表不是容器
、该文件的存取模式
、该文件的属主和属组
、该文件的大小
、该文件建立或状态改变的时间(ctime)
、最近一次的读取时间(mtime)
、最近修改的时间
地址指针:
- 直接指针
- 间接指针
- 三级指针
使用stat /FILE命令可以查看文件的元数据:
[root@CentOS7 ~]#stat /etc/passwd
File: ‘/etc/passwd’
Size: Blocks: IO Block: regular file
Device: 802h/2050d Inode: Links:
Access: (/-rw-r--r--) Uid: ( / root) Gid: ( / root)
Context: system_u:object_r:passwd_file_t:s0
Access: -- ::31.449000177 +
Modify: -- ::20.214867983 +
Change: -- ::20.215867983 +
Birth: -
这里再提出一个概念:inode表。
假如每个inode128字节,一个4K的block就可以存放32个inode,再将这些存放inode的块组合起来就行成了inode table(inode表)。
举个例子,每一个家庭都要向派出所登记户口信息,通过户口本可以知道家庭住址,而每个镇或街道的派出所将本镇或本街道的所有户口整合在一起,要查找某一户地址时,在派出所就能快速查找到。inode table就是这里的派出所。
3. bmap(bitmap index)、imap(inode map)位图索引
3.1 bmap
在向硬盘存储数据时,文件系统需要知道哪些块是空闲的,哪些块是已经占用了的,bmap的作用就是总览硬盘中哪些block被占用,哪些是空闲的,这样可以高效写入数据。
位图只使用0和1标识对应block是空闲还是被占用,0和1在位图中的位置和block的位置一一对应,第一位标识第一个块,第二个位标识第二个块,依次下去直到标记完所有的block。比如:对于一个block大小为1KB、容量为1G的文件系统而言,block数量有1024*1024个,所以在bmap位图中使用10241024个位共1024*1024/8=131072字节=128K,即1G的文件只需要128个block做位图就能完成一一对应。通过扫描这100多个block就能知道哪些block是空闲的,速度提高了非常多。
注意:bmap优化针对的是写入优化,对读取优化使用的是inode。
3.2 imap
imap的作用同理bmap,也是为了让系统迅速了解哪些inode在使用,哪些处于空闲状态
4.块组
为解决bmap、inode table和imap太大的问题,比如100G文件就需要128k*100=12.5M的bmap空间,系统扫描这个空间也是蛮费时间,因此我们将占用的block分成block groups(块组)。
注意:在物理层面上的划分是将磁盘按柱面划分为多个分区,即多个文件系统;在逻辑层面上的划分是将文件系统划分成块组。每个文件系统包含多个块组,每个块组包含多个元数据区和数据区:元数据区就是存储bmap、inode table、imap等的数据;数据区就是存储文件数据的区域。注意块组是逻辑层面的概念,所以并不会真的在磁盘上按柱面、按扇区、按磁道等概念进行划分。
下面介绍如何划分块组:
它只需确定一个数据——每个block的大小,再根据bmap至多只能占用一个完整的block的标准就能计算出块组如何划分。如果文件系统非常小,所有的bmap总共都不能占用完一个block,那么也只能空闲bmap的block了。
(注意:每个block的大小在创建文件系统时可以人为指定,不指定也有默认值。)
假如现在block的大小是1KB,一个bmap完整占用一个block能标识1024*8= 8192个block(当然这8192个block是数据区和元数据区共8192个,因为元数据区分配的block也需要通过bmap来标识)。每个block是1K,每个块组是8192K即8M,创建1G的文件系统需要划分1024/8=128个块组,如果是1.1G的文件系统呢?128+12.8=128+13=141个块组。
可以使用dumpe2fs /dev/sda1 查看相关信息:
ext4文件系统的信息:
[root@CentOS6 ~]#dumpe2fs /dev/sda1
dumpe2fs 1.41. (-May-)
Filesystem volume name: <none>
Last mounted on: /boot # 挂载点
Filesystem UUID: db5da648-a6e9-41e2-b9bb-1ec771e61499
Filesystem magic number: 0xEF53
Filesystem revision #: (dynamic)
Filesystem features: has_journal ext_attr resize_inode dir_index filetype needs_recovery extent flex_bg sparse_super large_file huge_file uninit_bg dir_nlink extra_isize
Filesystem flags: signed_directory_hash
Default mount options: user_xattr acl # 开通acl功能
Filesystem state: clean
Errors behavior: Continue #错误时继续进行
Filesystem OS type: Linux
Inode count: # inode号数量
Block count: # block数量
Reserved block count: # 保存的block数量
Free blocks: # 空闲的block数量
Free inodes: # 空闲的inode数量
First block: # 第一个block号
Block size: # block大小4k
Fragment size:
Reserved GDT blocks: # 保留的GDT block数量
Blocks per group: # 每个块组的block数量
Fragments per group:
Inodes per group: # 每个块组的inode数量
Inode blocks per group: # 每个块组inode占用的块数量,即inode表大小,*4k
Flex block group size: #
Filesystem created: Tue Oct ::
Last mount time: Fri Nov ::
Last write time: Fri Nov ::
Mount count:
Maximum mount count: -
Last checked: Tue Oct ::
Check interval: (<none>)
Lifetime writes: MB
Reserved blocks uid: (user root)
Reserved blocks gid: (group root)
First inode:
Inode size: # inode大小
Required extra isize:
Desired extra isize:
Journal inode: # 日志文件的inode数
Default directory hash: half_md4
Directory Hash Seed: 50ef58d8-3fa1-473a-84d0-2e0a5156c604
Journal backup: inode blocks
Journal features: (none)
Journal size: 32M
Journal length:
Journal sequence: 0x0000002b
Journal start:
可见:该分区中共有262144个block,每个块大小4k,所以该分区容量为1G,每个块组包含32768个块,一个分了8个块组。
5.块组里的其他block
5.1 Boot Block 引导块
Boot Block也称为boot sector。它位于分区上的第一个块,占用1024字节,并非所有分区都有这个boot sector,只有装了操作系统的主分区和装了操作系统的逻辑分区才有。里面存放的也是boot loader,这段boot loader称为VBR(主分区装操作系统时)或EBR(扩展分区装操作系统时),这里的Boot loader和mbr上的boot loader是存在交错关系的。开机启动的时候,首先加载mbr中的bootloader,然后定位到操作系统所在分区的boot serctor上加载此处的boot loader。
5.2 Superblock(超级块)
超级块(superblock)用于存储文件系统本身的属性信息:如各种时间戳、block总数量和空闲数量、inode总数量和空闲数量、当前文件系统是否正常、什么时候需要自检等等。
超级块占用1024字节,也需要一个block,所以这个块称为superblock,他的块号可能为0,也可能为1。如果block大小为1K,则引导块正好占用一个block,这个block号为0,所以superblock的号为1;如果block大小大于1K,则引导块和超级块同置在一个block中,这个block号为0。总之superblock的起止位置是第二个1024(1024-2047)字节。df 命令读取的就是每个文件系统的超级块内的信息,所以其速度非常快。相反,用du命令查看一个较大目录的已用空间就非常慢,因为不可避免地要遍历整个目录的所有文件。
[root@CentOS6 ~]#df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/sda2 % /
tmpfs % /dev/shm
/dev/sda1 % /boot
/dev/sda3 % /data
/dev/sr0 % /media/CentOS_6.9_Final
superblock对于文件系统而言是至关重要的,超级块丢失或损坏必将导致文件系统的损坏,所以超级块的信息会在块组上有备份。
dumpe2fs -h /dev/sda1获取超级块信息(dumpe2fs /dev/sda1 略同)
[root@CentOS6 ~]#dumpe2fs -h /dev/sda1 dumpe2fs 1.41. (-May-)
Filesystem volume name: <none>
Last mounted on: /boot
Filesystem UUID: db5da648-a6e9-41e2-b9bb-1ec771e61499
Filesystem magic number: 0xEF53
Filesystem revision #: (dynamic)
Filesystem features: has_journal ext_attr resize_inode dir_index filetype needs_recovery extent flex_bg sparse_super large_file huge_file uninit_bg dir_nlink extra_isize
Filesystem flags: signed_directory_hash
Default mount options: user_xattr acl
Filesystem state: clean
Errors behavior: Continue
Filesystem OS type: Linux
Inode count:
Block count:
Reserved block count:
Free blocks:
Free inodes:
First block:
Block size:
Fragment size:
Reserved GDT blocks:
Blocks per group:
Fragments per group:
Inodes per group:
Inode blocks per group:
Flex block group size:
Filesystem created: Tue Oct ::
Last mount time: Fri Nov ::
Last write time: Fri Nov ::
Mount count:
Maximum mount count: -
Last checked: Tue Oct ::
Check interval: (<none>)
Lifetime writes: MB
Reserved blocks uid: (user root)
Reserved blocks gid: (group root)
First inode:
Inode size:
Required extra isize:
Desired extra isize:
Journal inode:
Default directory hash: half_md4
Directory Hash Seed: 50ef58d8-3fa1-473a-84d0-2e0a5156c604
Journal backup: inode blocks
Journal features: (none)
Journal size: 32M
Journal length:
Journal sequence: 0x0000002b
Journal start:
5.3 GDT(块组描述符表)
记录每个块组的信息和属性等元数据,大小为32个字节。
虽然每个块组都需要块组描述符来记录块组的信息和属性元数据,但是不是每个块组中都存放了块组描述符。ext文件系统的存储方式是:将它们组成一个GDT,并将该GDT存放于某些块组中,存放GDT的块组和存放superblock和备份superblock的块相同,也就是说它们是同时出现在某一个块组中的。读取时也总是读取Group0中的块组描述符表信息。
假如block大小为4KB的文件系统划分了143个块组,每个块组描述符32字节,那么GDT就需要143*32=4576字节即两个block来存放。这两个GDT block中记录了所有块组的块组信息,且存放GDT的块组中的GDT都是完全相同的。dumpe2fs /dev/sda1命令后面的显示信息就是GDT
5.4 Reserved GDT(保留GDT)
保留GDT用于以后扩容文件系统使用,防止扩容后块组太多,使得块组描述符超出当前存储GDT的blocks。保留GDT和GDT总是同时出现,当然也就和superblock同时出现了。
完整的文件系统结构图

6.Data block
数据所占用的block由文件对应inode记录中的block指针找到,不同的文件类型,数据block中存储的内容是不一样的。以下是Linux中不同类型文件的存储方式:
- 对于常规文件,文件的数据正常存储在数据块中。
- 对于目录,该目录下的所有文件和一级子目录的目录名存储在数据块中。
- 文件名不是存储在其自身的inode中,而是存储在其所在目录的data block中。
- 对于符号链接,如果目标路径名较短则直接保存在inode中以便更快地查找,如果目标路径名较长则分配一个数据块来保存。
- 设备文件、FIFO和socket等特殊文件没有数据块,设备文件的主设备号和次设备号保存在inode中。
6.1 目录文件
对于目录文件,其inode记录中存储的是目录的inode号、目录的属性元数据和目录文件的block指针,这里面没有存储目录自身文件名的信息。
目录的data block中并没有直接存储目录中文件的inode号,它存储的是指向inode table中对应文件inode号的指针。
* block指针:每个inode号指向的block
* inode指针:目录文件其inode指向inode表
比如:对于没有执行权限的目录文件,我们ll /FILE/TO/并不能读取到该目录下的文件信息,只能读到目录本身的信息。
所以,目录文件的读权限(r)和写权限(w),都是针对目录文件的数据块本身。由于目录文件内只有文件名、文件类型和inode指针,所以如果只有读权限,只能获取文件名和文件类型信息,无法获取其他信息,尽管目录的data block中也记录着文件的inode指针,但定位指针是需要x权限的,因为其它信息都储存在文件自身对应的inode中,而要读取文件inode信息需要有目录文件的执行权限通过inode指针定位到文件对应的inode记录上。
补充:硬链接与软链接的区别:
- 硬链接:指向同一个inode的多个文件路径,但需在同一个分区中
- 目录不支持硬链接;
- 硬链接不能跨文件系统(跨分区);
- 创建硬链接即为为inode创建新的引用路径,会增加inode引用计数
- 修改符号链接文件的权限,变动的是源文件的权限
- 无论修改硬链接中的哪个文件,全部的文件都会跟着改动权限
ln file1 file2
- 符号链接与文件是两人个各自独立的文件,各有自己的inode;对原文件创建符号链接不会增加或减少目标文件inode的引用计数;
- 支持对目录创建符号链接,可以跨文件系统;
- 删除符号链接文件不影响原文件;但删除原文件,符号指定的路径即不存在,此时会变成无效链接;
- 符号链接文件的大小是其指向文件的路径字符串的长度(字节数)
ln -s file1 file2
软链接:指向一个文件路径的另一个文件的路径
三、示例解读:cat /var/log/messages
- 找到根文件系统的块组描述符表所在的blocks,读取GDT(已在内存中)找到inode table的block号。
- 在inode table的block中定位到根"/"的inode,找出"/"指向的data block。
- 在"/"的datablock中记录了var目录名和指向var目录文件inode的指针,并找到该inode记录,inode记录中存储了指向var的block指针,所以也就找到了var目录文件的data block。
- 在var的data block中记录了log目录名和其inode指针,通过该指针定位到该inode所在的块组及所在的inode table,并根据该inode记录找到log的data block。
- 在log目录文件的data block中记录了messages文件名和对应的inode指针,通过该指针定位到该inode所在的块组及所在的inode table,并根据该inode记录找到messages的data block。
- 最后读取messages对应的datablock。
简言之:找到GDT-->找到"/"的inode-->找到/的数据块读取var的inode-->找到var的数据块读取log的inode-->找到log的数据块读取messages的inode-->找到messages的数据块并读取它们。
十一、FHS基础原理的更多相关文章
- Hadoop基础原理
Hadoop基础原理 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 业内有这么一句话说:云计算可能改变了整个传统IT产业的基础架构,而大数据处理,尤其像Hadoop组件这样的技术出 ...
- I2C 基础原理详解
今天来学习下I2C通信~ I2C(Inter-Intergrated Circuit)指的是 IC(Intergrated Circuit)之间的(Inter) 通信方式.如上图所以有很多的周边设备都 ...
- C#基础原理拾遗——引用类型的值传递和引用传递
C#基础原理拾遗——引用类型的值传递和引用传递 以前写博客不深动,只搭个架子,像做笔记,没有自己的思考,也没什么人来看.这个毛病得改,就从这一篇开始… 最近准备面试,深感基础之重要,奈何我不是计算机科 ...
- OpenStack的基础原理
OpenStack的基础原理 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. OpenStack既是一个社区,也是一个项目和一个开源软件,它提供了一个部署云的操作平台或工具集.其 ...
- 二十一. Python基础(21)--Python基础(21)
二十一. Python基础(21)--Python基础(21) 1 ● 类的命名空间 #对于类的静态属性: #类.属性: 调用的就是类中的属性 #对象.属性: 先从自己的内存空间里找名 ...
- DNS服务基础原理介绍
FQDN 全称域名 localhost(主机名或者是别名).localdomain(域名) FQDN=主机名.域名 根域 . 顶级域名 .com .n ...
- Sql注入基础原理介绍
说明:文章所有内容均截选自实验楼教程[Sql注入基础原理介绍]~ 实验原理 Sql 注入攻击是通过将恶意的 Sql 查询或添加语句插入到应用的输入参数中,再在后台 Sql 服务器上解析执行进行的攻击, ...
- 十一. Python基础(11)—补充: 作用域 & 装饰器
十一. Python基础(11)-补充: 作用域 & 装饰器 1 ● Python的作用域补遗 在C/C++等语言中, if语句等控制结构(control structure)会产生新的作用域 ...
- Macaca 基础原理浅析
导语 前面几篇文章介绍了在Macaca实践中的一些实用技巧与解决方案,今天简单分析一下Macaca的基础原理.这篇文章将以前面所分享的UI自动化Macaca-Java版实践心得中的demo为基础,进行 ...
随机推荐
- [Vue]避免 v-if 和 v-for 用在同一个元素上
一般我们在两种常见的情况下会倾向于这样做: 情形1:为了过滤一个列表中的项目 (比如 v-for="user in users" v-if="user.isActive& ...
- (十一)SpringBoot之文件上传以及
一.案例 1.1 配置application.properties #主配置文件,配置了这个会优先读取里面的属性覆盖主配置文件的属性 spring.profiles.active=dev server ...
- 【原创】大叔经验分享(87)marathon重启应用过程服务不可用
marathon提供多种健康检查方式 常用的有TCP和HTTP, TCP检查端口是否存在,存在则认为实例健康: HTTP检查指定URL的HTTP返回码,返回码正常(2xx.3xx)则认为实例健康: 这 ...
- requests Use body.encode('utf-8') if you want to send it encoded in UTF-8
基本环境 使用 requests 模块发送 post 请求,请求体包含中文报错 系统环境:centos7.3 python版本:python3.6.8 请求代码: // 得到中文 param_json ...
- 建表时表空间的一些参数pctfree initrans maxtrans storage的含义
转自:https://a475334705.iteye.com/blog/2291441 create table X_SMALL_AREA ( idx_id NUMBER ...
- Axure流程图
什么是流程图 一个流程图可用于展示各种各样的处理流程,包括用例流程.商业流程.页面流程等.在Axure中,流程图常用于提供一个高保真的.能通过所设计的页面来完成的任务视图.一张简明的流程图,能促进和其 ...
- MFC编程——Where is WinMain?
源码 #include<afxwin.h> class MyApp :public CWinApp { public: virtual BOOL InitInstance(); }; My ...
- 主板(motherboard)
若转载请于明显处标明出处:http://www.cnblogs.com/kelamoyujuzhen/p/8979262.html 整台PC都是围绕主板(motherboard)构建的,它是PC中最重 ...
- 2018/7/31 -zznu-oj -问题 C: 磨刀- 【扩展欧几里得算法的基本应用】
问题 C: 磨刀 时间限制: 1 Sec 内存限制: 128 MB提交: 190 解决: 39[提交] [状态] [讨论版] [命题人:admin] 题目描述 磨刀是一个讲究的工作,只能在n℃下进 ...
- 前端与SQL
转载自:http://developer.51cto.com/art/201706/542163.htm