图解kubernetes调度器ScheduleAlgorithm核心实现学习框架设计
ScheduleAlgorithm是一个接口负责为pod选择一个合适的node节点,本节主要解析如何实现一个可扩展、可配置的通用算法框架来实现通用调度,如何进行算法的统一注册和构建,如何进行metadata和调度流程上下文数据的传递
1. 设计思考
1.1 调度设计
1.1.1 调度与抢占

当接收到pod需要被调度后,默认首先调用schedule来进行正常的业务调度尝试从当前集群中选择一个合适的node
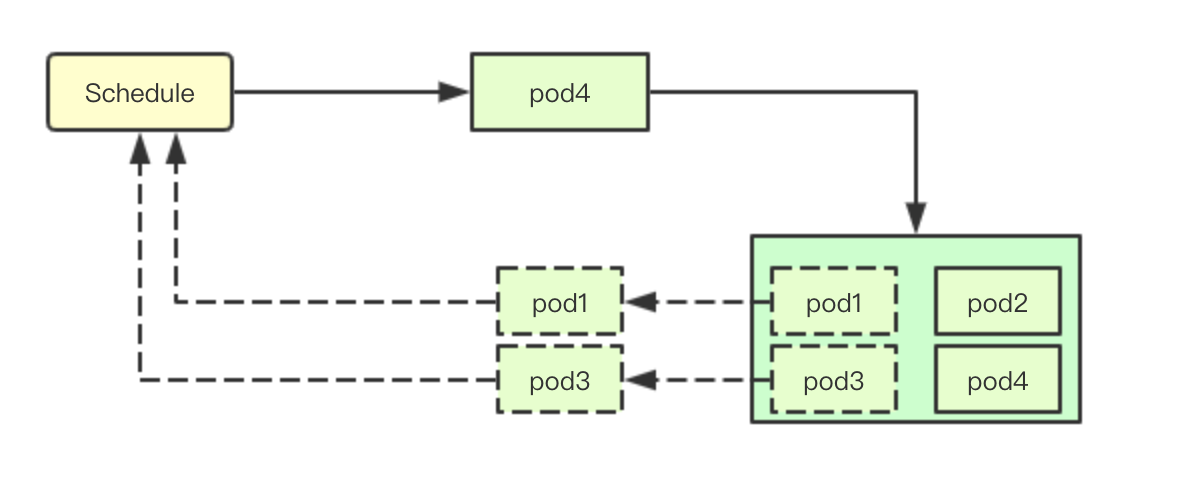
如果调度失败则尝试抢占调度,根据优先级抢占低优先级的pod运行高优先级pod
1.1.2 调度阶段
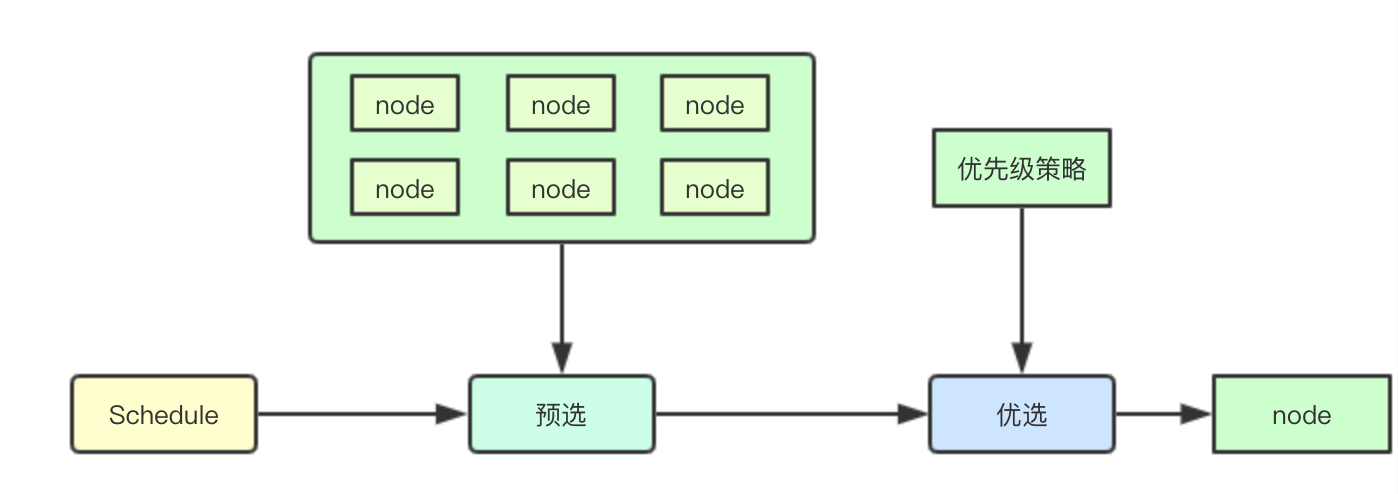
在k8s的调度算法运行流程中,主要分为两个阶段:预选和优选,即从当前集群中选择符合要求的node,再从这些node中选择最合适的节点
1.1.3 节点选择
随着集群的增加集群中的node数量越来越多,k8s并不是遍历所有集群资源,而是只选取部分节点,同时借助之前说的 schedulerCache来实现pod节点的分散
1.2 框架设计
1.2.1 注册表与算法工厂
针对不同的算法,声明不同的注册表,负责集群中当前所有算法的注册,从而提供给调度配置决策加载那些插件,实现算法的可扩展性
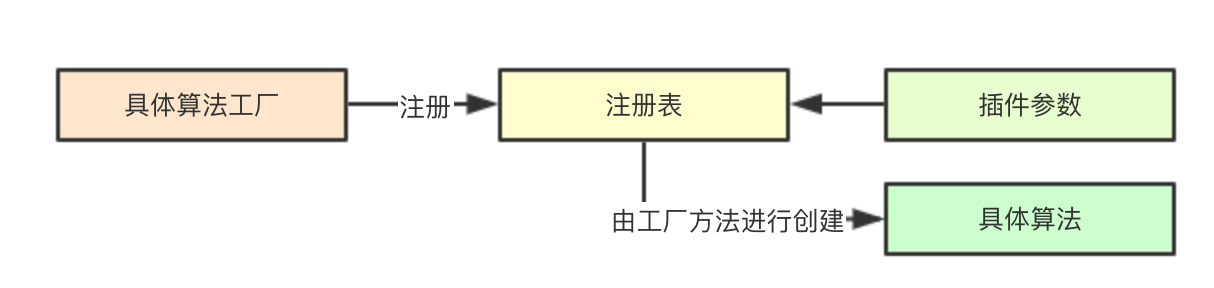
并通过工厂模式来进行统一管理,解耦算法的注册与具体调度流程中的使用,由每个算法的工厂方法来接受参数进行具体算法的创建
1.2.3 metadata与PluginContext
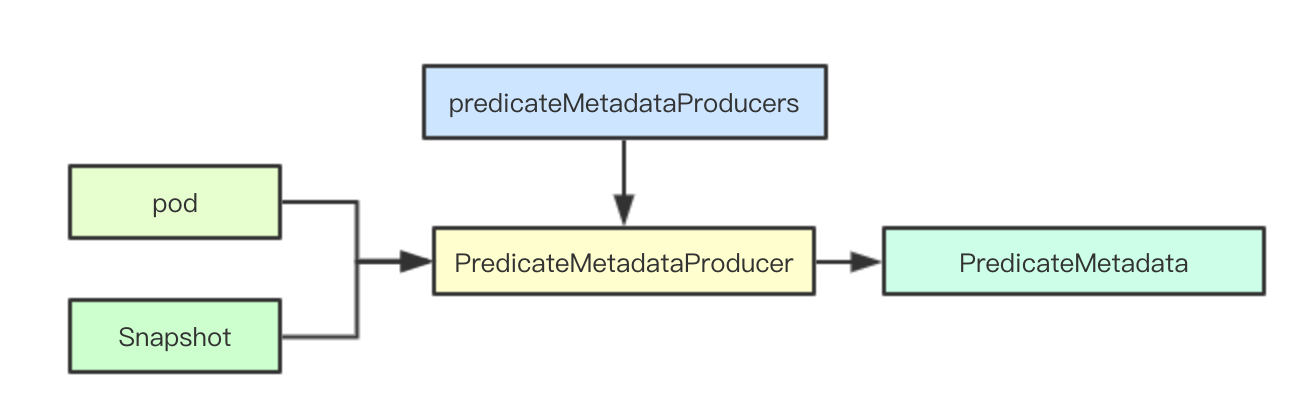
在调度实际运行的过程中,需要集合当前集群中的元数据信息(node和pod)来进行具体算法的决策,scheduler采用PredicateMetadataProducer和PriorityMetadataProducer来进行元数据的构建, 其次针对一些可能被多个算法都使用的数据,也会在这里完成构建,比如亲和性的pod、拓扑等
并通过PluginContext进行本次调度上下文数据的存储,用于在多个调度算法之间存储数据进行交互
1.2.4 Provider
Provider主要是封装一组具体的预选和优选算法,并通过注册来实现统一管理, 其中系统内置了DefaultProvider
1.2.5 framework
framework是一种内部的扩展机制,通过定制给定的阶段函数,进行调度流程的影响,本节先不介绍
1.2.6 extender
一种外部的扩展机制,可以根据需要进行动态的配置,其实就是外部的一个service,但是相比framework可以使用自己独立的数据存储,实现对调度器的扩展
2. 源码分析
2.1 数据结构
type genericScheduler struct {
cache internalcache.Cache
schedulingQueue internalqueue.SchedulingQueue
predicates map[string]predicates.FitPredicate
priorityMetaProducer priorities.PriorityMetadataProducer
predicateMetaProducer predicates.PredicateMetadataProducer
prioritizers []priorities.PriorityConfig
framework framework.Framework
extenders []algorithm.SchedulerExtender
alwaysCheckAllPredicates bool
nodeInfoSnapshot *schedulernodeinfo.Snapshot
volumeBinder *volumebinder.VolumeBinder
pvcLister corelisters.PersistentVolumeClaimLister
pdbLister algorithm.PDBLister
disablePreemption bool
percentageOfNodesToScore int32
enableNonPreempting bool
}
2.1.1 集群数据
集群元数据主要分为三部分:
Cache: 存储从apiserver获取的数据
SchedulingQueue: 存储当前队列中等待调度和经过调度但是未真正运行的pod
cache internalcache.Cache
schedulingQueue internalqueue.SchedulingQueue
nodeInfoSnapshot *schedulernodeinfo.Snapshot
2.1.1 预选算法相关
预选算法主要包含两部分:当前使用的预选调度算法结合和元数据构建器
predicates map[string]predicates.FitPredicate
predicateMetaProducer predicates.PredicateMetadataProducer
2.1.3 优先级算法相关
优选算法与预选算法不太相同,在后续文章中会进行介绍
priorityMetaProducer priorities.PriorityMetadataProducer
prioritizers []priorities.PriorityConfig
2.1.4 扩展相关
framework framework.Framework
extenders []algorithm.SchedulerExtender
2.2 调度算法注册表
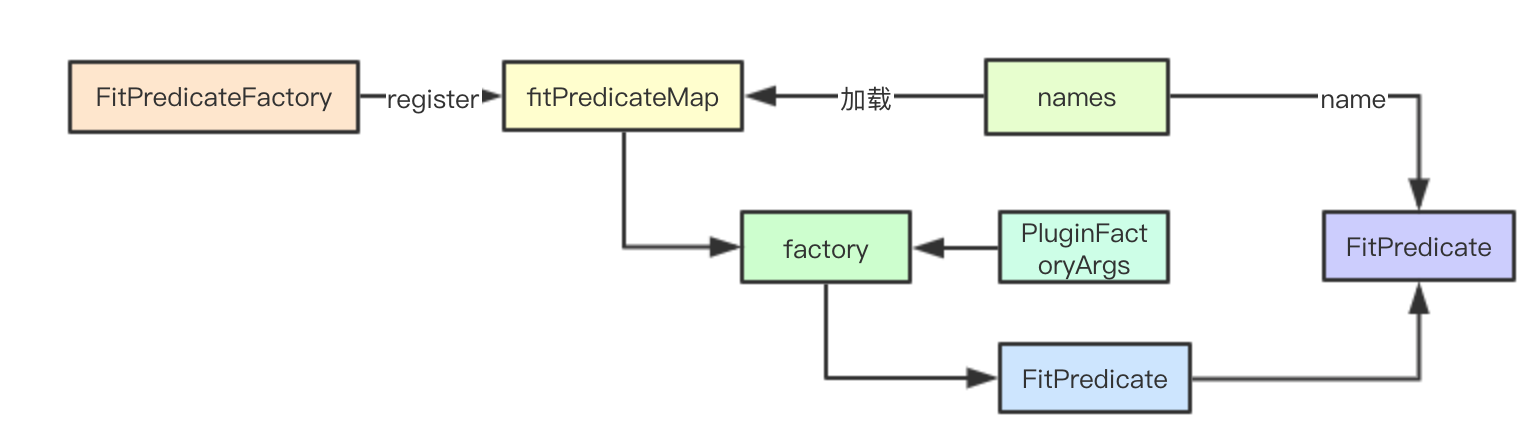
Priority会复杂一点,这里就不介绍了,其核心设计都是一样的
2.2.1 工厂注册表
fitPredicateMap = make(map[string]FitPredicateFactory)
2.2.2 注册表注册
注册主要分两类:如果后续算法不会使用当前Args里面的数据,只需要使用metadata里面的,就直接返回注册算法,下面的函数就是返回一个工厂方法,但是不会使用Args参数
func RegisterFitPredicate(name string, predicate predicates.FitPredicate) string {
return RegisterFitPredicateFactory(name, func(PluginFactoryArgs) predicates.FitPredicate { return predicate })
}
最终注册都是通过下面的工厂注册函数实现,通过mutex和map实现
func RegisterFitPredicateFactory(name string, predicateFactory FitPredicateFactory) string {
schedulerFactoryMutex.Lock()
defer schedulerFactoryMutex.Unlock()
validateAlgorithmNameOrDie(name)
fitPredicateMap[name] = predicateFactory
return name
}
2.2.3 生成预选算法
通过插件工厂参数影响和Factory构建具体的预选算法,上面构建的工厂方法,下面则给定参数,通过工厂方法利用闭包的方式来进行真正算法的生成
func getFitPredicateFunctions(names sets.String, args PluginFactoryArgs) (map[string]predicates.FitPredicate, error) {
schedulerFactoryMutex.RLock()
defer schedulerFactoryMutex.RUnlock()
fitPredicates := map[string]predicates.FitPredicate{}
for _, name := range names.List() {
factory, ok := fitPredicateMap[name]
if !ok {
return nil, fmt.Errorf("invalid predicate name %q specified - no corresponding function found", name)
}
fitPredicates[name] = factory(args)
}
// k8s中默认包含一些强制性的策略,不允许用户自己进行删除,这里是加载这些参数
for name := range mandatoryFitPredicates {
if factory, found := fitPredicateMap[name]; found {
fitPredicates[name] = factory(args)
}
}
return fitPredicates, nil
}
2.2.4 根据当前feature进行算法删除
当我们在系统演进的时候,也可以借鉴这种思想,来避免用户使用那些当前或者未来版本中可能逐渐被放弃的设计
if utilfeature.DefaultFeatureGate.Enabled(features.TaintNodesByCondition) {
// Remove "CheckNodeCondition", "CheckNodeMemoryPressure", "CheckNodePIDPressure"
// and "CheckNodeDiskPressure" predicates
factory.RemoveFitPredicate(predicates.CheckNodeConditionPred)
factory.RemoveFitPredicate(predicates.CheckNodeMemoryPressurePred)
}
2.3 predicateMetadataProducer
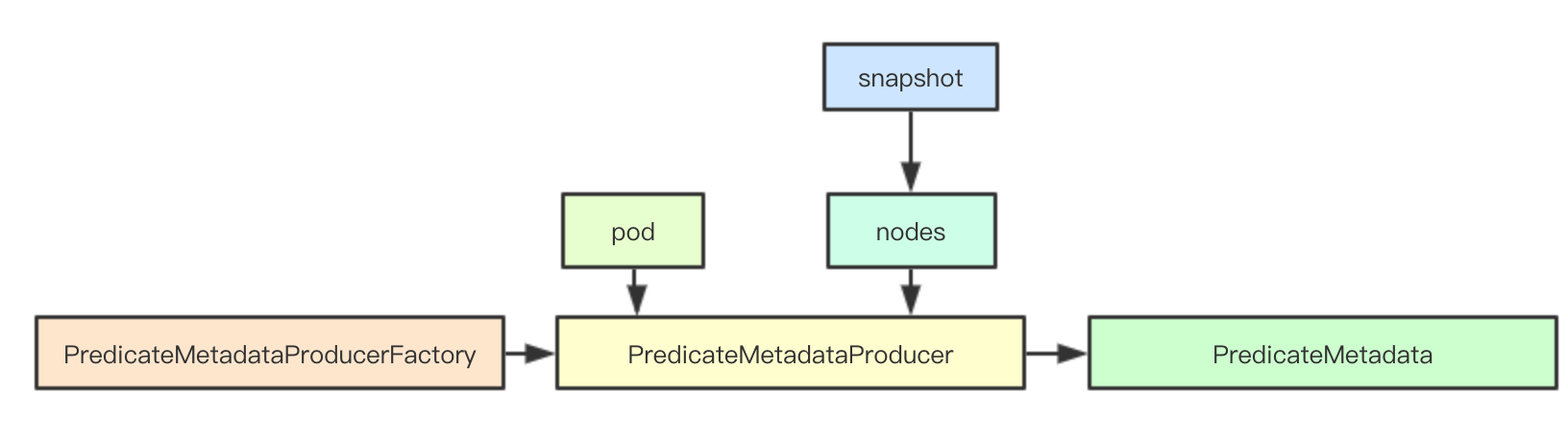
2.3.1 PredicateMetadata
// PredicateMetadata interface represents anything that can access a predicate metadata.
type PredicateMetadata interface {
ShallowCopy() PredicateMetadata
AddPod(addedPod *v1.Pod, nodeInfo *schedulernodeinfo.NodeInfo) error
RemovePod(deletedPod *v1.Pod, node *v1.Node) error
}
2.3.2 声明
predicateMetadataProducer PredicateMetadataProducerFactory
工厂函数
// PredicateMetadataProducerFactory produces PredicateMetadataProducer from the given args.
type PredicateMetadataProducerFactory func(PluginFactoryArgs) predicates.PredicateMetadataProducer
PredicateMetadataProducer通过上面的工厂函数创建而来,其接受当前需要调度的pod和snapshot里面的node信息,从而构建当前的PredicateMetadata
// PredicateMetadataProducer is a function that computes predicate metadata for a given pod.
type PredicateMetadataProducer func(pod *v1.Pod, nodeNameToInfo map[string]*schedulernodeinfo.NodeInfo) PredicateMetadata
2.3.2 注册
// RegisterPredicateMetadataProducerFactory registers a PredicateMetadataProducerFactory.
func RegisterPredicateMetadataProducerFactory(factory PredicateMetadataProducerFactory) {
schedulerFactoryMutex.Lock()
defer schedulerFactoryMutex.Unlock()
predicateMetadataProducer = factory
}
2.3.4 意义
PredicateMetadata其本质上就是当前系统中的元数据,其设计的主要目标是为了当前的调度流程中后续多个调度算法中都可能需要计算的数据,进行统一的计算,比如节点的亲和性、反亲和、拓扑分布等,都在此进行统一的控制, 当前版本的实现时PredicateMetadataFactory,这里不进行展开
2.4 Provider
2.4.1 AlgorithmProviderConfig
// AlgorithmProviderConfig is used to store the configuration of algorithm providers.
type AlgorithmProviderConfig struct {
FitPredicateKeys sets.String
PriorityFunctionKeys sets.String
}
2.4.2 注册中心
algorithmProviderMap = make(map[string]AlgorithmProviderConfig)
2.4.3 注册
func RegisterAlgorithmProvider(name string, predicateKeys, priorityKeys sets.String) string {
schedulerFactoryMutex.Lock()
defer schedulerFactoryMutex.Unlock()
validateAlgorithmNameOrDie(name)
algorithmProviderMap[name] = AlgorithmProviderConfig{
FitPredicateKeys: predicateKeys,
PriorityFunctionKeys: priorityKeys,
}
return name
}
2.4.4 默认Provider注册
func init() {
// 注册算法DefaulrProvider 的算法provider
registerAlgorithmProvider(defaultPredicates(), defaultPriorities())
}
2.5 核心调度流程
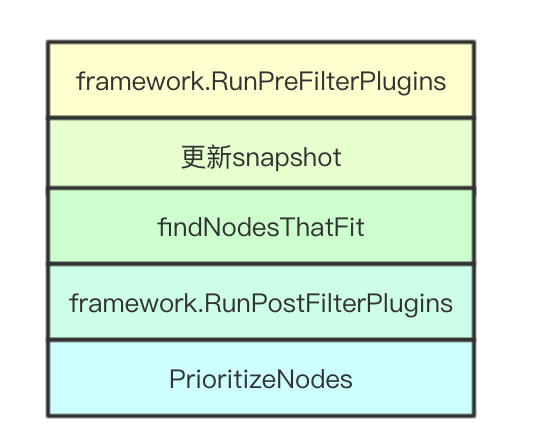
核心调度流程,这里面只介绍主线的流程,至于怎么预选和优选则在下一篇文章进行更新,因为稍微有点复杂,而framework和extender则在后续介绍完这两部分在进行介绍, 其中extender的调用则是在PrioritizeNodes进行优先级算中进行调用
// Schedule tries to schedule the given pod to one of the nodes in the node list.
// If it succeeds, it will return the name of the node.
// If it fails, it will return a FitError error with reasons.
func (g *genericScheduler) Schedule(pod *v1.Pod, pluginContext *framework.PluginContext) (result ScheduleResult, err error) {
// 省略非核心代码
// 调用framework的RunPreFilterPlugins
preFilterStatus := g.framework.RunPreFilterPlugins(pluginContext, pod)
if !preFilterStatus.IsSuccess() {
return result, preFilterStatus.AsError()
}
// 获取当前的node数量
numNodes := g.cache.NodeTree().NumNodes()
if numNodes == 0 {
return result, ErrNoNodesAvailable
}
// 更新snapshot
if err := g.snapshot(); err != nil {
return result, err
}
// 预选阶段
filteredNodes, failedPredicateMap, filteredNodesStatuses, err := g.findNodesThatFit(pluginContext, pod)
if err != nil {
return result, err
}
// 将预选结果调用framework的postfilter
postfilterStatus := g.framework.RunPostFilterPlugins(pluginContext, pod, filteredNodes, filteredNodesStatuses)
if !postfilterStatus.IsSuccess() {
return result, postfilterStatus.AsError()
}
if len(filteredNodes) == 0 {
return result, &FitError{
Pod: pod,
NumAllNodes: numNodes,e
FailedPredicates: failedPredicateMap,
FilteredNodesStatuses: filteredNodesStatuses,
}
}
startPriorityEvalTime := time.Now()
// 如果只有一个节点则直接返回
if len(filteredNodes) == 1 {
return ScheduleResult{
SuggestedHost: filteredNodes[0].Name,
EvaluatedNodes: 1 + len(failedPredicateMap),
FeasibleNodes: 1,
}, nil
}
// 获取所有的调度策略
metaPrioritiesInterface := g.priorityMetaProducer(pod, g.nodeInfoSnapshot.NodeInfoMap)
// 获取所有node的优先级,此处会将extenders进行传入,实现扩展接口的调用
priorityList, err := PrioritizeNodes(pod, g.nodeInfoSnapshot.NodeInfoMap, metaPrioritiesInterface, g.prioritizers, filteredNodes, g.extenders, g.framework, pluginContext)
if err != nil {
return result, err
}
// 从优先级中选择出合适的node
host, err := g.selectHost(priorityList)
trace.Step("Selecting host done")
return ScheduleResult{
SuggestedHost: host,
EvaluatedNodes: len(filteredNodes) + len(failedPredicateMap),
FeasibleNodes: len(filteredNodes),
}, err
}
3. 设计总结
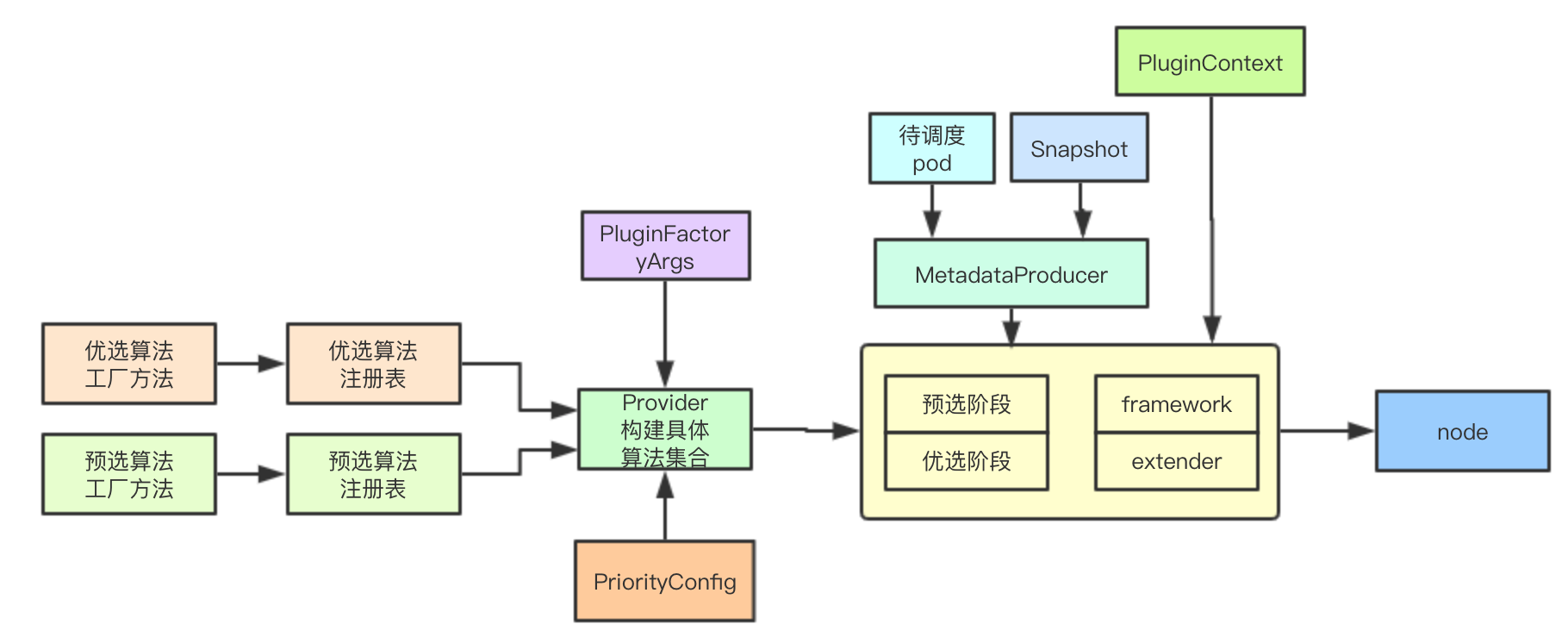
在调度算法框架中大量使用了工厂方法来进行算法、元数据等的构建,并通过封装MetadataProducer来进行公共业务逻辑接口的封装,通过PluginContext进行调度流程中上下文数据的传递,并且用户可以通过定制Provider来进行具体调度算法的选择
本文只介绍了大的框架设计,诸如具体的算法注册和构建其大多都是在构建scheduler命令行参数处通过加载对应的包和init函数来实现,本文没有介绍一些具体的细节连抢占也没有介绍,后续文章里面会进行一一展开,感兴趣的同学,欢迎一起学习交流
微信号:baxiaoshi2020
关注公告号阅读更多源码分析文章
更多文章关注 www.sreguide.com
本文由博客一文多发平台 OpenWrite 发布


图解kubernetes调度器ScheduleAlgorithm核心实现学习框架设计的更多相关文章
- 图解kubernetes调度器预选设计实现学习
Scheduler中在进行node选举的时候会首先进行一轮预选流程,即从当前集群中选择一批node节点,本文主要分析k8s在预选流程上一些优秀的筛选设计思想,欢迎大佬们指正 1. 基础设计 1.1 预 ...
- 图解kubernetes调度器SchedulingQueue核心源码实现
SchedulingQueue是kubernetes scheduler中负责进行等待调度pod存储的对,Scheduler通过SchedulingQueue来获取当前系统中等待调度的Pod,本文主要 ...
- 图解kubernetes调度器抢占流程与算法设计
抢占调度是分布式调度中一种常见的设计,其核心目标是当不能为高优先级的任务分配资源的时候,会通过抢占低优先级的任务来进行高优先级的调度,本文主要学习k8s的抢占调度以及里面的一些有趣的算法 1. 抢占调 ...
- 图解kubernetes调度器SchedulerExtender扩展
在kubernetes的scheduler调度器的设计中为用户预留了两种扩展机制SchdulerExtender与Framework,本文主要浅谈一下SchdulerExtender的实现, 因为还有 ...
- 图解kubernetes调度器SchedulerCache核心源码实现
SchedulerCache是kubernetes scheduler中负责本地数据缓存的核心数据结构, 其实现了Cache接口,负责存储从apiserver获取的数据,提供给Scheduler调度器 ...
- Kubernetes 调度器实现初探
Kubernetes 调度器 Kubernetes 是一个基于容器的分布式调度器,实现了自己的调度模块.在Kubernetes集群中,调度器作为一个独立模块通过pod运行.从几个方面介绍Kuberne ...
- kubernetes 调度器
调度器 kube-scheduler 是 kubernetes 的核心组件之一,主要负责整个集群资源的调度功能,根据特定的调度算法和策略,将 Pod 调度到最优的工作节点上面去,从而更加合理.更加充分 ...
- 第十五章 Kubernetes调度器
一.简介 Scheduler 是 kubernetes 的调度器,主要的任务是把定义的 pod 分配到集群的节点上.听起来非常简单,但有很多要考虑的问题: ① 公平:如何保证每个节点都能被分配资源 ② ...
- 巧用Prometheus来扩展kubernetes调度器
Overview 本文将深入讲解 如何扩展 Kubernetes scheduler 中各个扩展点如何使用,与扩展scheduler的原理,这些是作为扩展 scheduler 的所需的知识点.最后会完 ...
随机推荐
- window10+python3.7安装tensorflow--gpu tensorflow 安装
能安装GPU的前提是:1.显卡支持CUDA (1)右击我的电脑–属性 (2)打开设备管理器 (3)显示适配器 我的电脑是支持CUDA的 2.pip 版本 >= 8.1查看pip版本 :pip ...
- PHP 面试题 一
1.用PHP打印出前一天的时间格式是2017-5-10 22:21:21(2分) 月,日没有前导零:2017-5-1 22:21:21echo date("Y-n-j H:i:s" ...
- java IO的概述和File方法
IO流用来处理设备之间的数据传输 Java对数据的操作是通过流的方式 Java用于操作流的对象都在IO包中 File类在整个IO包中与文件本身有关的操作类,所有的与文件本身 ...
- java Class中得到构造方法Constructor、方法Method、字段Field
常用方法: Constructor类用于描述类中的构造方法: Constructor<T> getConstructor(Class<?>... parameterTypes) ...
- linux scull 的设计
编写驱动的第一步是定义驱动将要提供给用户程序的能力(机制).因为我们的"设备"是计算 机内存的一部分, 我们可自由做我们想做的事情. 它可以是一个顺序的或者随机存取的设 备, 一个 ...
- P1038 间谍入侵
题目描述 爱丽丝魔法王国成立10周年,于是决定矩形国庆大阅兵. 在国庆大阅兵期间,为了防止暗黑王国的间谍乔装成平民混入,需要对每一个进城的人做检测. 因为暗黑王国的人长得和爱丽丝魔法王国的人长得很像, ...
- WPF 使用 SharpDx 异步渲染
本文告诉大家如何通过 SharpDx 进行异步渲染,但是因为在 WPF 是需要使用 D3DImage 画出来,所以渲染只是画出图片,最后的显示还是需要 WPF 在他自己的主线程渲染 本文是一个系列,希 ...
- linux 后备缓存
一个设备驱动常常以反复分配许多相同大小的对象而结束. 如果内核已经维护了一套相同 大小对象的内存池, 为什么不增加一些特殊的内存池给这些高容量的对象? 实际上, 内核 确实实现了一个设施来创建这类内存 ...
- linux 存取 I/O 内存
在一些平台上, 你可能逃过作为一个指针使用 ioremap 的返回值的惩罚. 这样的使用不 是可移植的, 并且, 更加地, 内核开发者已经努力来消除任何这样的使用. 使用 I/O 内 存的正确方式是通 ...
- CF1151FSonya and Informatics
CF1151FSonya and Informatics 给一个长度为 n$ (n\leq 100)$的 \(0/1\) 串,进行 k\((k \leq 10^9)\)次操作,每次操作选择两个位置 \ ...