Ambari HDP 下 SPARK2 与 Phoenix 整合
1、环境说明
| 操作系统 | CentOS Linux release 7.4.1708 (Core) |
|---|---|
| Ambari | 2.6.x |
| HDP | 2.6.3.0 |
| Spark | 2.x |
| Phoenix | 4.10.0-HBase-1.2 |
2、条件
HBase 安装完成
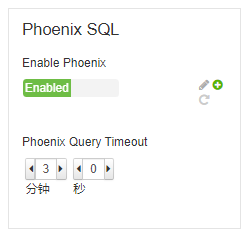
Phoenix 已经启用,Ambari界面如下所示:
Spark 2安装完成
3、Spark2 与 Phoenix整合
Phoenix 官网整合教程: http://phoenix.apache.org/phoenix_spark.html
步骤:
进入 Ambari Spark2 配置界面
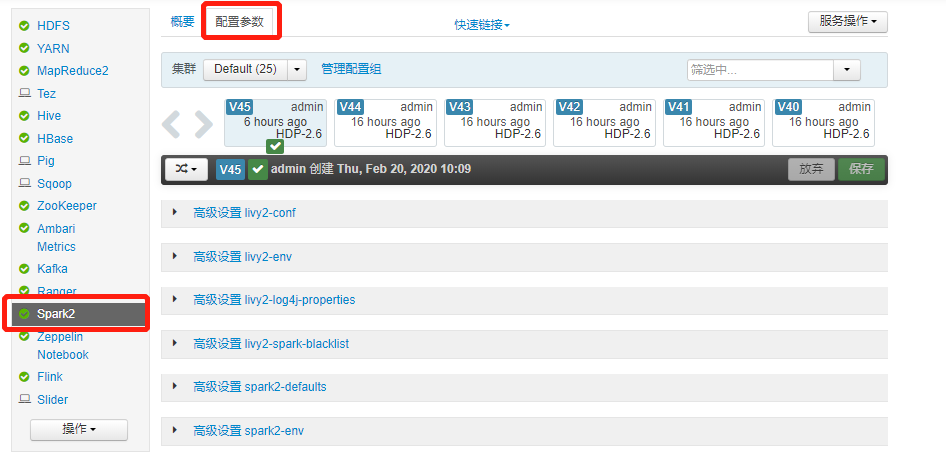
找到
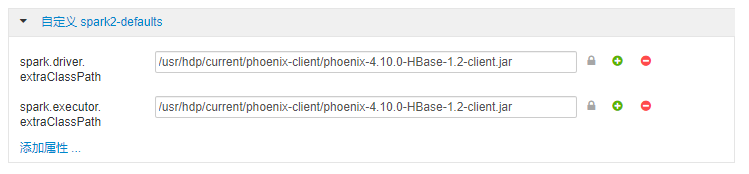
自定义 spark2-defaults并添加如下配置项:spark.driver.extraClassPath=/usr/hdp/current/phoenix-client/phoenix-4.10.0-HBase-1.2-client.jar
spark.executor.extraClassPath=/usr/hdp/current/phoenix-client/phoenix-4.10.0-HBase-1.2-client.jar
4、Yarn HA 问题
如果配置了Yarn HA, 则需要修改 Yarn HA 配置,否则spark-submit提交任务会报如下错误:
Exception in thread "main" java.lang.IllegalAccessError: tried to access method org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider.getProxyInternal()Ljava/lang/Object; from class org.apache.hadoop.yarn.client.RequestHedgingRMFailoverProxyProvider
at org.apache.hadoop.yarn.client.RequestHedgingRMFailoverProxyProvider.init(RequestHedgingRMFailoverProxyProvider.java:75)
at org.apache.hadoop.yarn.client.RMProxy.createRMFailoverProxyProvider(RMProxy.java:163)
at org.apache.hadoop.yarn.client.RMProxy.createRMProxy(RMProxy.java:94)
at org.apache.hadoop.yarn.client.ClientRMProxy.createRMProxy(ClientRMProxy.java:72)
at org.apache.hadoop.yarn.client.api.impl.YarnClientImpl.serviceStart(YarnClientImpl.java:187)
at org.apache.hadoop.service.AbstractService.start(AbstractService.java:193)
at org.apache.spark.deploy.yarn.Client.submitApplication(Client.scala:153)
at org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend.start(YarnClientSchedulerBackend.scala:56)
at org.apache.spark.scheduler.TaskSchedulerImpl.start(TaskSchedulerImpl.scala:173)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:509)
at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2516)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$7.apply(SparkSession.scala:922)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$7.apply(SparkSession.scala:914)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:914)
at cn.spark.sxt.SparkOnPhoenix$.main(SparkOnPhoenix.scala:13)
at cn.spark.sxt.SparkOnPhoenix.main(SparkOnPhoenix.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.i
修改Yarn HA配置:
将原来的配置:
yarn.client.failover-proxy-provider=org.apache.hadoop.yarn.client.RequestHedgingRMFailoverProxyProvider
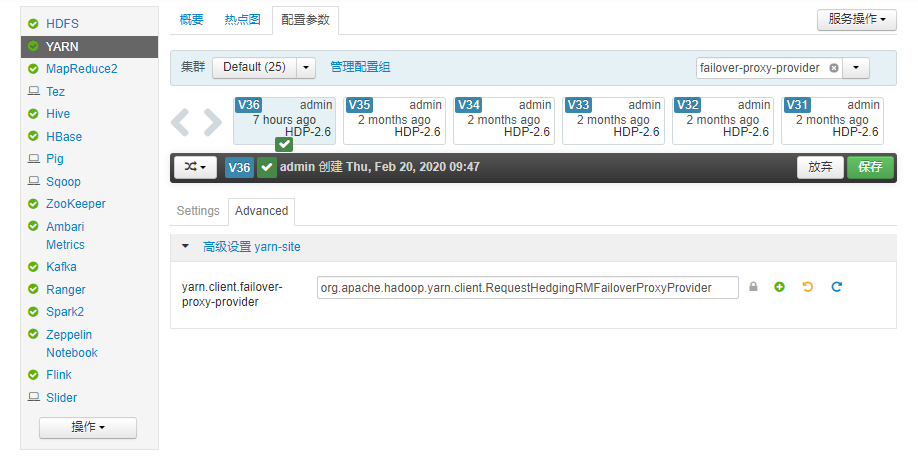
改为现在的配置:
yarn.client.failover-proxy-provider=org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider

如果没有配置 Yarn HA, 则不需要进行此步配置

Ambari HDP 下 SPARK2 与 Phoenix 整合的更多相关文章
- linux下apache和tomcat整合
一 Apache与Tomcat比较联系 apache支持静态页,tomcat支持动态的,比如servlet等. 一般使用apache+tomcat的话,apache只是作为一个转发,对jsp的处理是由 ...
- Hadoop记录-安装ambari hdp集群
#!/bin/sh #配置用户sudo权限(参考/etc/sudoers文件,在/etc/sudoers.d/新建一个用户配置文件,注意要注销) #需要在/etc/sudoers末尾追加:sfapp ...
- cent os 6.5+ambari+HDP集群安装
1. 搭建一个测试集群,集群有4台机器,配置集群中每一台机器的/etc/hosts文件: [root@nn .ssh]# cat /etc/hosts 127.0.0.1 localhost loca ...
- Ambari HDP集群搭建全攻略
世界上最快的捷径,就是脚踏实地,本文已收录[架构技术专栏]关注这个喜欢分享的地方. 最近因为工作上需要重新用Ambari搭了一套Hadoop集群,就把搭建的过程记录了下来,也希望给有同样需求的小伙伴们 ...
- HBase+Phoenix整合入门--集群搭建
环境:CentOS 6.6 64位 hbase 1.1.15 phoenix-4.7.0-HBase-1.1 一.前置环境: 已经安装配置好Hadoop 2.6和jdk 1.7 二.安装hba ...
- 【Java EE 学习 82 下】【MAVEN整合Eclipse】【MAVEN的一些高级概念】
一.MAVEN整合Eclipse MAVEN是非常优秀,但是总是要开命令行敲命令是比较不爽的,我们已经习惯了使用IDE,所以还有一种将MAVEN整合到Eclipse的方法. 详情查看:http://w ...
- ambari hdp 集成 impala
1.下载ambari-impala-service VERSION=`hdp-select status hadoop-client | sed 's/hadoop-client - \([0-9]\ ...
- Ambari HDP集群搭建文档
一.配置主机和节点机器之间SSH无密登录 多台外网服务器配置时,需要在/etc/hosts中把本机的IP地址设置为内网IP地址 http://2d67df38.wiz02.com/share/s/0J ...
- [WebServer] Linux下Apache与Tomcat整合的简单方法
Apache与Tomcat比较联系 apache支持静态页,tomcat支持动态的,比如servlet等. 一般使用apache+tomcat的话,apache只是作为一个转发,对jsp的处理是由to ...
随机推荐
- python的list()函数
list()函数将其它序列转换为 列表 (就是js的数组). 该函数不会改变 其它序列 效果图一: 代码一: # 定义一个元组序列 tuple_one = (123,','abc') print( ...
- 【C_Language】---队列和栈的C程序实现
这几天总结了C语言的队列,栈的实现方法,在此总结一下:一.栈 首先从栈开始,诚然,相信学习过数据结构的你,肯定应该知道栈是什么东西了,如果不知道也没事每一句话我就可以帮你总结--数据只在栈顶进行插入和 ...
- 蒙蔽的FormBody
作为一个不算新人的新人,今天看到 了FormBody这个绿色字体,之前没有怎么注意过, 好了 ,发现了一篇文章,记录下. 这篇文章总结下来就是: 在前端穿过的数据是Json格式(当我们设置Conten ...
- java反序列化php序列化的对象
最近工作中遇到一个需要解析php序列化后存入DB的array, a:4:{i:0;a:2:{s:11:"province";s:8:"0016";s:7:&qu ...
- 你在使用什么 Redis 客户端工具?
今天发现一个不错的 Redis 客户端工具:AnotherRedisDesktopManager. 兼容 Windows Mac Linux,号称又快又稳定,加载大量 keys 时也不会崩溃. Git ...
- Go的http包中默认路由匹配规则
# 一.执行流程 首先我们构建一个简单http server: ```go package main import ( "log" "net/http" ) f ...
- [bzoj2115] [洛谷P4151] [Wc2011] Xor
Description Input 第一行包含两个整数N和 M, 表示该无向图中点的数目与边的数目. 接下来M 行描述 M 条边,每行三个整数Si,Ti ,Di,表示 Si 与Ti之间存在 一条权值为 ...
- 7、python基本数据类型之散列类型
前言:python的基本数据类型可以分为三类:数值类型.序列类型.散列类型,本文主要介绍散列类型. 一.散列类型 内部元素无序,不能通过下标取值 1)字典(dict):用 {} 花括号表示,每一个元素 ...
- java中常用的锁机制
基础知识 基础知识之一:锁的类型 锁就那么几个,只是根据特性,分为不同的类型 锁的概念 在计算机科学中,锁(lock)或互斥(mutex)是一种同步机制,用于在有许多执行线程的环境中强制对资源的访问限 ...
- linux DHCP 服务器
配置 1:/etc/dhcp.conf 配置文件 2:dhcp.leases 启动 dhcp 服务器 linux dhcp客户端 windows dhcp 客户端