Kafka系列2:深入理解Kafka消费者
Kafka系列2:深入理解Kafka消费者
上篇聊了Kafka概况,包含了Kafka的基本概念、设计原理,以及设计核心。本篇单独聊聊Kafka的生产者,包括如下内容:
- 生产者是如何生产消息
- 如何创建生产者
- 发送消息到Kafka
- 生产者配置
- 分区
生产者是如何生产消息的
首先来看一下Kafka生产者组件图
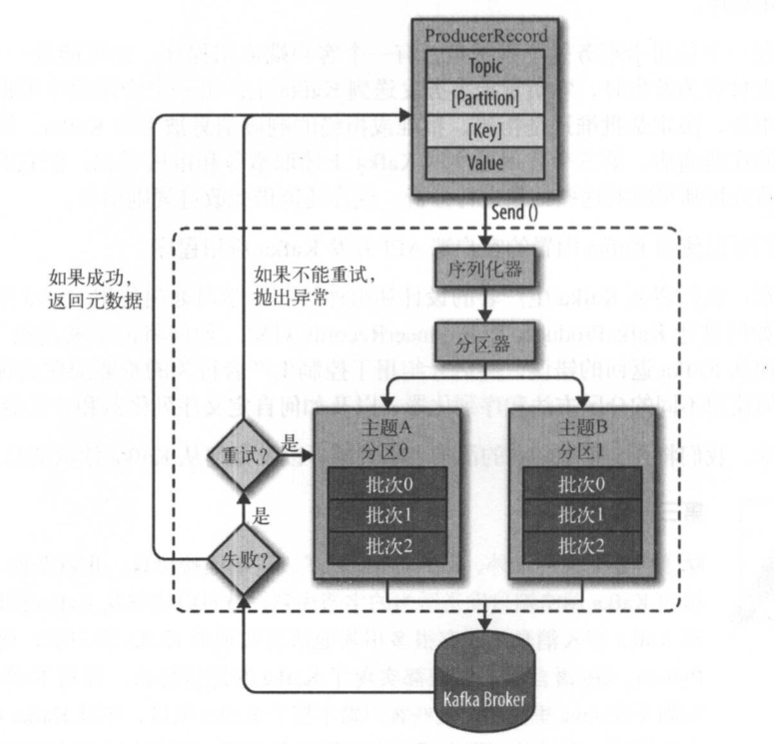
(生产者组件图。图片来源:《Kafka权威指南》)
第一步,Kafka 会将发送消息包装为 ProducerRecord 对象, ProducerRecord 对象包含了目标主题和要发送的内容,同时还可以指定键和分区。在发送 ProducerRecord 对象前,生产者会先把键和值对象序列化成字节数组,这样它们才能够在网络上传输。第二步,数据被传给分区器。如果之前已经在 ProducerRecord 对象里指定了分区,那么分区器就不会再做任何事情。如果没有指定分区 ,那么分区器会根据 ProducerRecord 对象的键来选择一个分区,紧接着,这条记录被添加到一个记录批次里,这个批次里的所有消息会被发送到相同的主题和分区上。有一个独立的线程负责把这些记录批次发送到相应的 broker 上。服务器在收到这些消息时会返回一个响应。如果消息成功写入 Kafka,就返回一个 RecordMetaData 对象,它包含了主题和分区信息,以及记录在分区里的偏移量。如果写入失败,则会返回一个错误。生产者在收到错误之后会尝试重新发送消息,如果达到指定的重试次数后还没有成功,则直接抛出异常,不再重试。
如何创建生产者
属性设置
在创建生产者对象的时候,要设置一些属性,有三个属性是必选的:
bootstrap.servers:指定Broker的地址清单,地址格式为host:port。清单里不需要包含所有的Broker地址,生产者会从给定的Broker里查找到其他Broker的信息;不过建议至少要提供两个Broker的信息保证容错。
key.serializer:指定键的序列化器。Broker希望接收到的消息的键和值都是字节数组。这个属性必须被设置为一个实现了org.apache.kafka.common.serialization.Serializer接口的类,生产者会使用这个类把键对象序列化成字节数组。Kafka客户端默认提供了ByteArraySerializer、StringSerializer和IntegerSerializer,因此一般不需要实现自定义的序列化器。需要注意的是,key.serializer属性是必须设置的,即使只发送值内容。
value.serializer:指定值的序列化器。如果键和值都是字符串,可以使用与key.serializer一样的序列化器,否则需要使用不同的序列化器。
项目依赖
以maven项目为例,要使用Kafka客户端,需要引入kafka-clients依赖:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.2.0</version>
</dependency>
样例
一个简单的创建Kafka生产者的代码样例如下:
Properties props = new Properties();
props.put("bootstrap.servers", "producer1:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
/*创建生产者*/
Producer<String, String> producer = new KafkaProducer<>(props); for (int i = 0; i < 10; i++) {
ProducerRecord<String, String> record = new ProducerRecord<>(topicName, "k" + i, "v" + i);
/* 发送消息*/
producer.send(record);
}
/*关闭生产者*/
producer.close();
这个样例中只配置了必须的这三个属性,其他都使用了默认的配置。
发送消息Kafka
实例化生产者对象后,接下来就可以开始发送消息了。发送消息主要有三种方式:
- 发送并忘记(fire-and-forget):把消息发送给服务器,但并不关心消息是否正常到达,也就是上面样例中的方式。大多数情况下,消息会正常到达,这可以由Kafka的高可用性和自动重发机制来保证。不过有时候也会丢失消息。
- 同步发送:使用send()方法发送消息,它会返回一个Future对象,调用get()方法进行等待,我们就可以知道消息是否发送成功。
- 异步发送:调用send()方法时,同时指定一个回调函数,服务器在返回响应时调用该函数。
发送并忘记
这是最简单的消息发送方式,只发送不管发送结果,代码样例如下:
ProducerRecord<String, String> record = new ProducerRecord<>("Topic", "k", "v"); // 1
try {
producer.send(record); // 2
} catch (Exception e) {
e.printStackTrace(); // 3
}
这段代码要注意几点:
- 生产者的send()方法将ProducerRecord对象作为参数,样例里用到的ProducerRecord构造函数需要目标主题的名字和要发送的键和值对象,它们都是字符串。键和值对象的类型都必须与序列化器和生产者对象相匹配。
- 使用生产者的send()方法发送ProducerRecord对象。消息会先被放进缓冲区,然后使用单独的线程发送到服务器端。send()方法会返回一个包含RecordMetadata的Future对象,不过此处不关注返回了什么。
- 发送消息时,生产者可能会出现一些执行异常,序列化消息失败异常、缓冲区超出异常、超时异常,或者发送线程被中断异常。
同步发送
在上一种发送方式中已经解释过同步发送和只发送的区别,以下是最简单的同步发送方式的代码样例,对比可以看到区别:
ProducerRecord<String, String> record = new ProducerRecord<>("Topic", "k", "v");
try {
producer.send(record).get;
} catch (Exception e) {
e.printStackTrace();
}
可以看到,二者的区别就在于是否接收发送结果。同步发送会接收send()方法的返回值,即一个Future对象,通过调用Future对象的get()方法来等待Kafka响应。如果服务器返回错误,则get()方法就会抛出异常。如果没有发生错误,我们会得到一个RecordMetadata对象,可以用它来获取消息的偏移量。
异步发送消息
对于吞吐量要求比较高的应用来说,又要同时保证服务的可靠性,发送并忘记方式可靠性较低,但同步发送方式又会降低吞吐量,这就需要异步发送消息的方式了。大多数时候,生产者并不需要等待响应,只需要在遇到消息发送失败时,抛出异常、记录错误日志,或者把消息写入“错误日志”文件便于以后分析。代码样例如下:
ProducerRecord<String, String> record = new ProducerRecord<>("Topic", "k", "v");
// 异步发送消息,并监听回调
producer.send(record, new Callback() { // 1
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) { // 2
if (exception != null) {
// 进行异常处理
} else {
System.out.printf("topic=%s, partition=%d, offset=%s \n", metadata.topic(), metadata.partition(), metadata.offset());
}
}
});
- 从上面代码可以看到,为了使用回调,只需要实现一个org.apache.kafka.clients.producer.Callback接口即可,这个接口只有一个onComplete方法。
- 如果Kafka返回错误,onComplete方法会抛出一个非空异常。在调用send()方法的时候会传入这个callback对象,根据发送的结果决定调用异常处理方法还是发送结果处理方法。
生产者配置
在创建生产者的时候,介绍了三个必须的属性,本节再一一介绍下其他的生产者属性:
acks
acks 参数指定了必须要有多少个分区副本收到消息,生产者才会认为消息写入是成功的:
- acks=0 : 消息发送出去就认为已经成功了,不会等待任何来自服务器的响应;
- acks=1 : 只要集群的首领节点收到消息,生产者就会收到一个来自服务器成功响应;
- acks=all :只有当所有参与复制的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应。
buffer.memory
该参数用来设置生产者内存缓冲区的大小生产者用它缓冲要发送到服务器的消息。如果程序发送消息的速度超过了发送到服务器的速度,会导致生产者缓冲区空间不足,这时候调用send()方法要么被阻塞,要么抛出异常。
compression.type
默认情况下,发送的消息不会被压缩。它指定了消息被发送给broker之前使用哪一种压缩算法进行压缩,可选值有 snappy(占用CPU少,关注性能和网络带宽时选用),gzip(占用CPU多,更高压缩比,网络带宽有限时选用),lz4。
retries
指定了生产者放消息发生错误后,消息重发的次数。如果达到设定值,生产者就会放弃重试并返回错误。
batch.size
当有多个消息需要被发送到同一个分区时,生产者会把它们放在同一个批次里。该参数指定了一个批次可以使用的内存大小,按照字节数计算。
linger.ms
该参数制定了生产者在发送批次之前等待更多消息加入批次的时间。KafkaProducer会在批次填满或linger.ms达到上限时把批次发送出去。
client.id
客户端 id,服务器用来识别消息的来源。
max.in.flight.requests.per.connection
指定了生产者在收到服务器响应之前可以发送多少个消息。它的值越高,就会占用越多的内存,不过也会提升吞吐量,把它设置为 1 可以保证消息是按照发送的顺序写入服务器,即使发生了重试。
timeout.ms、request.timeout.ms和metadata.fetch.timeout.ms
- timeout.ms 指定了 borker 等待同步副本返回消息的确认时间;
- request.timeout.ms 指定了生产者在发送数据时等待服务器返回响应的时间;
- metadata.fetch.timeout.ms 指定了生产者在获取元数据(比如分区首领是谁)时等待服务器返回响应的时间。
max.block.ms
该参数指定了在调用send()方法或使用partitionsFor()方法获取元数据时生产者的阻塞时间。当生产者的发送缓冲区已满,或者没有可用的元数据时,这些方法会阻塞。在阻塞时间达到 max.block.ms 时,生产者会抛出超时异常。
max.request.size
该参数用于控制生产者发送的请求大小。它可以指发送的单个消息的最大值,也可以指单个请求里所有消息总的大小。例如,假设这个值为 1000K ,那么可以发送的单个最大消息为 1000K ,或者生产者可以在单个请求里发送一个批次,该批次包含了 1000 个消息,每个消息大小为 1K。
receive.buffer.bytes和send.buffer.byte
这两个参数分别指定 TCP socket 接收和发送数据包缓冲区的大小,-1 代表使用操作系统的默认值。
分区
分区器
上面在说明生产者发送消息方式的时候有如下一行代码:
ProducerRecord<String, String> record = new ProducerRecord<>("Topic", "k", "v");
这里指定了Kafka消息的目标主题、键和值。ProducerRecord对象包含了主题、键和值。键的作用是:
- 作为消息的附加信息;
- 用来决定消息被写到主题的哪个分区,拥有相同键的消息将被写到同一个分区。
键可以设置为默认的null,是不是null的区别在于:
- 如果键为null,那么分区器使用轮询算法将消息均衡地分布到各个分区上;
- 如果键不为null,那么 分区器 会使用内置的散列算法对键进行散列,然后分布到各个分区上。
要注意的是,只有在不改变分区主题分区数量的情况下,键与分区之间的映射才能保持不变。
顺序保证
Kafka可以保证同一个分区里的消息是有序的。考虑一种情况,如果retries为非零整数,同时max.in.flight.requests.per.connection为比1大的数如果某些场景要求消息是有序的,也即生产者在收到服务器响应之前可以发送多个消息,且失败会重试。那么如果第一个批次消息写入失败,而第二个成功,Broker会重试写入第一个批次,如果此时第一个批次写入成功,那么两个批次的顺序就反过来了。也即,要保证消息是有序的,消息是否写入成功也是很关键的。那么如何做呢?在对消息的顺序要严格要求的情况下,可以将retries设置为大于0,max.in.flight.requests.per.connection设为1,这样在生产者尝试发送第一批消息时,就不会有其他的消息发送给Broker。当然这回严重影响生产者的吞吐量。
关注我的公众号,获取更多关于面试、技术的文章及福利资源。

【参考资料】《Kafka 权威指南》
Kafka系列2:深入理解Kafka消费者的更多相关文章
- Kafka 系列(四)—— Kafka 消费者详解
一.消费者和消费者群组 在 Kafka 中,消费者通常是消费者群组的一部分,多个消费者群组共同读取同一个主题时,彼此之间互不影响.Kafka 之所以要引入消费者群组这个概念是因为 Kafka 消费者经 ...
- Kafka 系列(三)—— Kafka 生产者详解
一.生产者发送消息的过程 首先介绍一下 Kafka 生产者发送消息的过程: Kafka 会将发送消息包装为 ProducerRecord 对象, ProducerRecord 对象包含了目标主题和要发 ...
- Kafka 系列(一)—— Kafka 简介
一.简介 ApacheKafka 是一个分布式的流处理平台.它具有以下特点: 支持消息的发布和订阅,类似于 RabbtMQ.ActiveMQ 等消息队列: 支持数据实时处理: 能保证消息的可靠性投递: ...
- Kafka系列3:深入理解Kafka消费者
上面两篇聊了Kafka概况和Kafka生产者,包含了Kafka的基本概念.设计原理.设计核心以及生产者的核心原理.本篇单独聊聊Kafka的消费者,包括如下内容: 消费者和消费者组 如何创建消费者 如何 ...
- 深入理解Kafka核心设计及原理(三):消费者
转载请注明出处:https://www.cnblogs.com/zjdxr-up/p/16114877.html 深入理解Kafka核心设计及原理(一):初识Kafka 深入理解Kafka核心设计及原 ...
- 《吃透MQ系列》之扒开Kafka的神秘面纱
大家好,这是<吃透 MQ 系列>的第二弹,有些珊珊来迟,后台被好几个读者催更了,实属抱歉! 这篇文章拖更了好几周,起初的想法是:围绕每一个具体的消息中间件,不仅要写透,而且要控制好篇幅,写 ...
- 【转】快速理解Kafka分布式消息队列框架
from:http://blog.csdn.net/colorant/article/details/12081909 快速理解Kafka分布式消息队列框架 标签: kafkamessage que ...
- kafka系列之(3)——Coordinator与offset管理和Consumer Rebalance
from:http://www.jianshu.com/p/5aa8776868bb kafka系列之(3)——Coordinator与offset管理和Consumer Rebalance 时之结绳 ...
- Kafka系列一之架构介绍和安装
Kafka架构介绍和安装 写在前面 还是那句话,当你学习一个新的东西之前,你总得知道这个东西是什么?这个东西可以用来做什么?然后你才会去学习它,使用它.简单来说,kafka既是一个消息队列,如今,它也 ...
随机推荐
- Exceptionless运用结果
一.后台页面功能 列表菜单 SubmitLog - 记录一般日志 log Messages SubmitException - 记录一次日志 Exceptions SubmitNotFound - 4 ...
- C#实现文件Move操作和文件的Copy操作
文件移动(Move)操作和文件的复制(Copy)是C#程式开发经常遇到的方法,根据传入的源文件地址和目标文件地址参数,实现对文件的操作.实现代码如下: Move操作代码: public static ...
- Spring Boot2 系列教程 (十五) | 服务端参数校验之一
估计很多朋友都认为参数校验是客户端的职责,不关服务端的事.其实这是错误的,学过 Web 安全的都知道,客户端的验证只是第一道关卡.它的参数验证并不是安全的,一旦被有心人抓到可乘之机,他就可以有各种方法 ...
- 【Linux】---Linux系统下各种常用命令总结
在Linux系统下,“万物皆文件”,之所以强调在强调这个概念,是因为很多人已经习惯了win系统下找找点点得那种方式和思维,因此总是会觉得linux系统下很多指令既复杂又难记.其实都是一样得东西,只是w ...
- 最短路变形题目 HDU多校7
Mr.Quin love fishes so much and Mr.Quin’s city has a nautical system,consisiting of N ports and M sh ...
- Eclipse常用快捷键【转】
Eclipse的编辑功能非常强大,掌握了Eclipse快捷键功能,能够大大提高开发效率.Eclipse中有如下一些和编辑相关的快捷键.1. [ALT+/]此快捷键为用户编辑的好帮手,能为用户提供内容的 ...
- java架构之路(多线程)JUC并发编程之Semaphore信号量、CountDownLatch、CyclicBarrier栅栏、Executors线程池
上期回顾: 上次博客我们主要说了我们juc并发包下面的ReetrantLock的一些简单使用和底层的原理,是如何实现公平锁.非公平锁的.内部的双向链表到底是什么意思,prev和next到底是什么,为什 ...
- RabbitMQ入门(二)工作队列
在文章RabbitMQ入门(一)之Hello World,我们编写程序通过指定的队列来发送和接受消息.在本文中,我们将会创建工作队列(Work Queue),通过多个workers来分配耗时任务. ...
- Java入门 - 语言基础 - 22.异常处理
原文地址:http://www.work100.net/training/java-exception.html 更多教程:光束云 - 免费课程 异常处理 序号 文内章节 视频 1 概述 2 Exce ...
- 【新书推荐】《ASP.NET Core微服务实战:在云环境中开发、测试和部署跨平台服务》 带你走近微服务开发
<ASP.NET Core 微服务实战>译者序:https://blog.jijiechen.com/post/aspnetcore-microservices-preface-by-tr ...