AB实验人群定向HTE模型5 - Meta Learner
Meta Learner和之前介绍的Casual Tree直接估计模型不同,属于间接估计模型的一种。它并不直接对treatment effect进行建模,而是通过对response effect(target)进行建模,用treatment带来的target变化作为HTE的估计。主要方法有3种:T-Learner, S-Learner, X-Learner,思路相对比较传统的是在监督模型的基础上去近似因果关系。
Meta-Learner的优点很明显,可以使用任意ML监督模型进行拟合不需要构建新的estimator。所以如果有必需要基于DNN/LGB的需求不妨用Meta-Learner作为Benchamrk
核心论文
Künzel, S. R., Sekhon, J. S., Bickel, P. J., & Yu, B. (2019). Metalearners for estimating heterogeneous treatment effects using machine learning. Proceedings of the National Academy of Sciences, 116(10), 4156–4165.
模型
T-Learner
T是two的缩写,是比较传统的ML模型用于因果推理的方式。对照组和实验组进行分别建模得到两个模型,对每个样本计算两个模型的预测值之差作为HTE的估计
\[
\begin{align}
\mu_0(x) = E[Y (0)|X = x]\\
\mu_1(x) = E[Y (1)|X = x]\\
\hat{\tau}(x) = \hat{\mu}_1 (x) - \hat{\mu}_0(x)
\end{align}
\]
T-Learner有3个很明显的问题
- 对照组的模型无法学到实验组的pattern,实验组的模型也无法用到对照组的数据。两个模型完全隔离,也就导致两个模型可能各自有各自的偏差,从而导致的预测产生较大的误差。
- T-Learner限制了Treatment只能是离散值
- 大多数情况下treatment effect和response相比都是很小的,因此在response上的估计偏差会对treatment有很大影响
S-Learner
S是Single的缩写,把对照组和实验组放在一起建模,把实验分组作为特征加入训练特征。然后用Imputation的方法计算如果该样本进入实验组vs对照组模型预测的差异作为对实验影响的估计。
\[
\begin{align}
μ(x, w) &= E[Y|X = x, W = w]\\
\hat{\tau}(x) &= \hat{\mu} (x,1) - \hat{\mu}(x,0)
\end{align}
\]
S-Learner的问题同样在于本质是对response进行拟合。如果使用树作为Base-learner,最终的HTE可以简单理解为样本落在不同的叶节点,叶节点的样本差异。但因为树本身是对outcome进行建模而非对treatment effect进行建模,很有可能有效的人群划分方式在这种情况下并学习不到。
S-Learner的思想很常见,和可解释机器学习中的Individual Conditional Expectation(ICE)本质是一样的, 在全样本上求平均也就是大家熟悉的Partial Dependence。
X-Learner
X-Learner是针对上述提到的问题对T-Learner和S-Learner进行了融合。步骤如下
- 分别对对照组和实验组进行建模得到模型\(M_1\),\(M_2\)和T-Learner一样
- 把对照组放进实验组模型预测,再把实验组放进对照组模型预测,预测值和实际值的差作为HTE的近似。这里和S-Learner的思路近似是imputation的做法。
- 实验组和对照组分别对上述target建模得到\(M_3\),\(M_4\),每个样本得到两个预测值然后加权,权重一般可选propensity score,随机实验中可以直接用进组用户数,流量相同的随机实验直接用0.5感觉也没啥问题
\[
\begin{align}
\hat{\mu_0}(x) &= M_1(Y^0 \sim X^0)\\
\hat{\mu_1}(x) &= M_2(Y^1 \sim X^1)\\
\hat{D_1}(x) &= Y_1 - \hat{\mu}_0(x)\\
\hat{D_0}(x) &= \hat{\mu}_1(x) - Y_0 \\
\hat{\tau_0} &= M_3(\hat{D_0}(x) \sim X_0)\\
\hat{\tau_1} &= M_4(\hat{D_1}(x) \sim X_1)\\
\hat{\tau} &= g(x) *\hat{\tau_0} + (1-g(x)) *\hat{\tau_1}\\
\end{align}
\]
方法比较
在作者分别给出几种可能类型的simulation,并评估S,X,T的表现。以下分别是:Treatment unbalanced, CATE complex linear, CATE complex non-linear, HTE=0 global linear, HTE=0 local linear。
简而言之,实验影响较大时X-Learner表现最好,实验影响微小时S-Learner和X-Learner表现差不多。
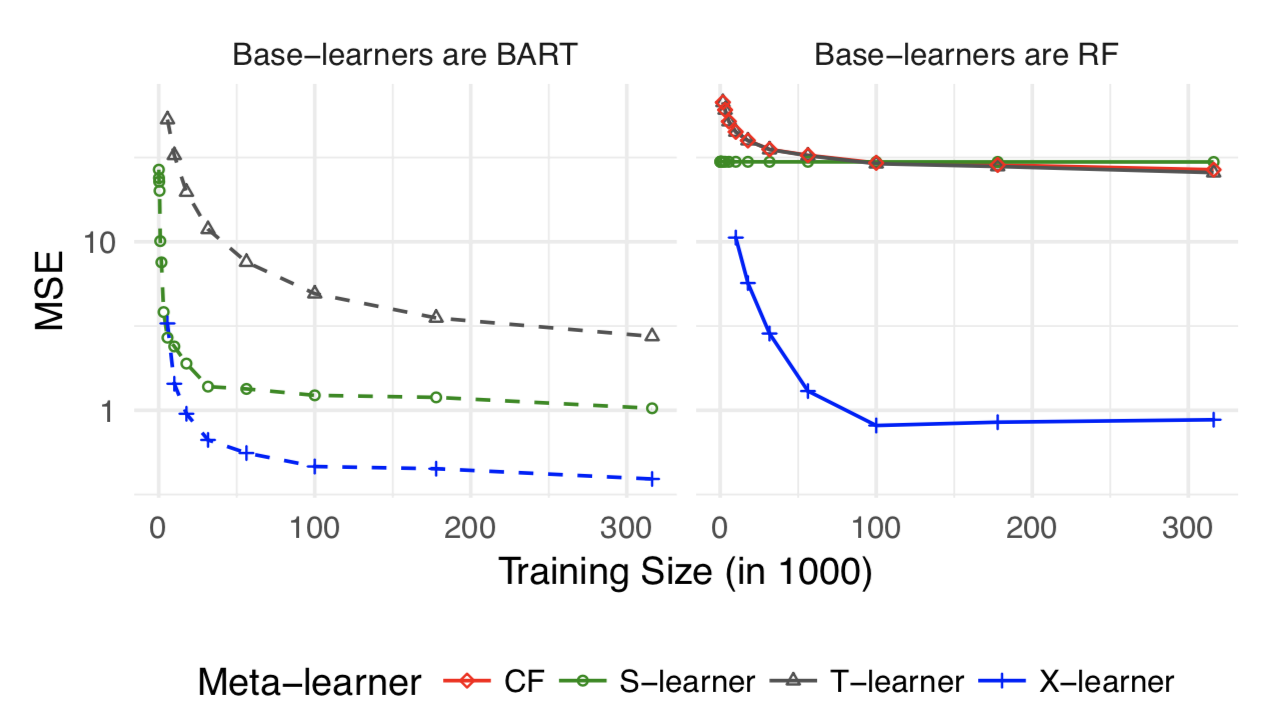
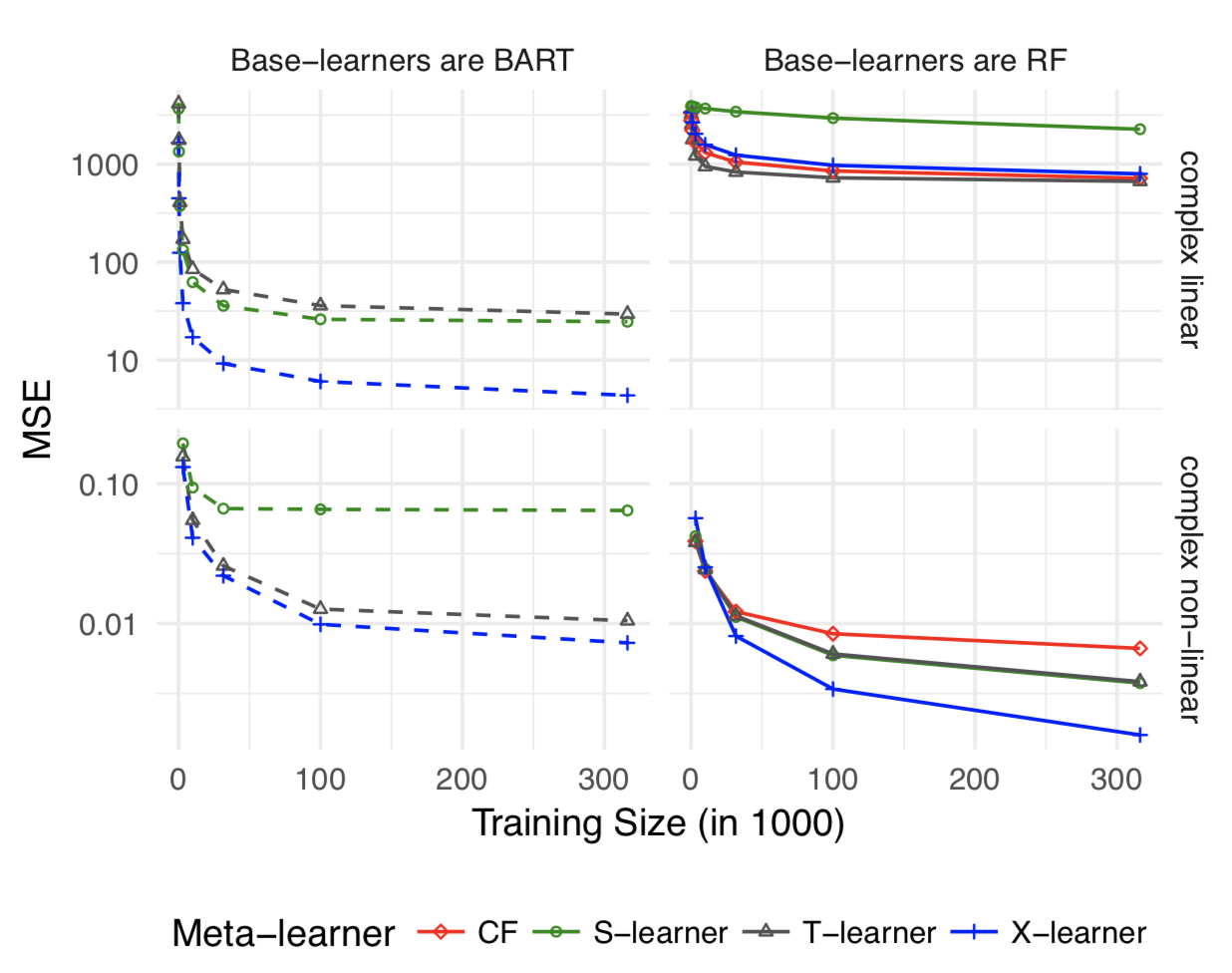
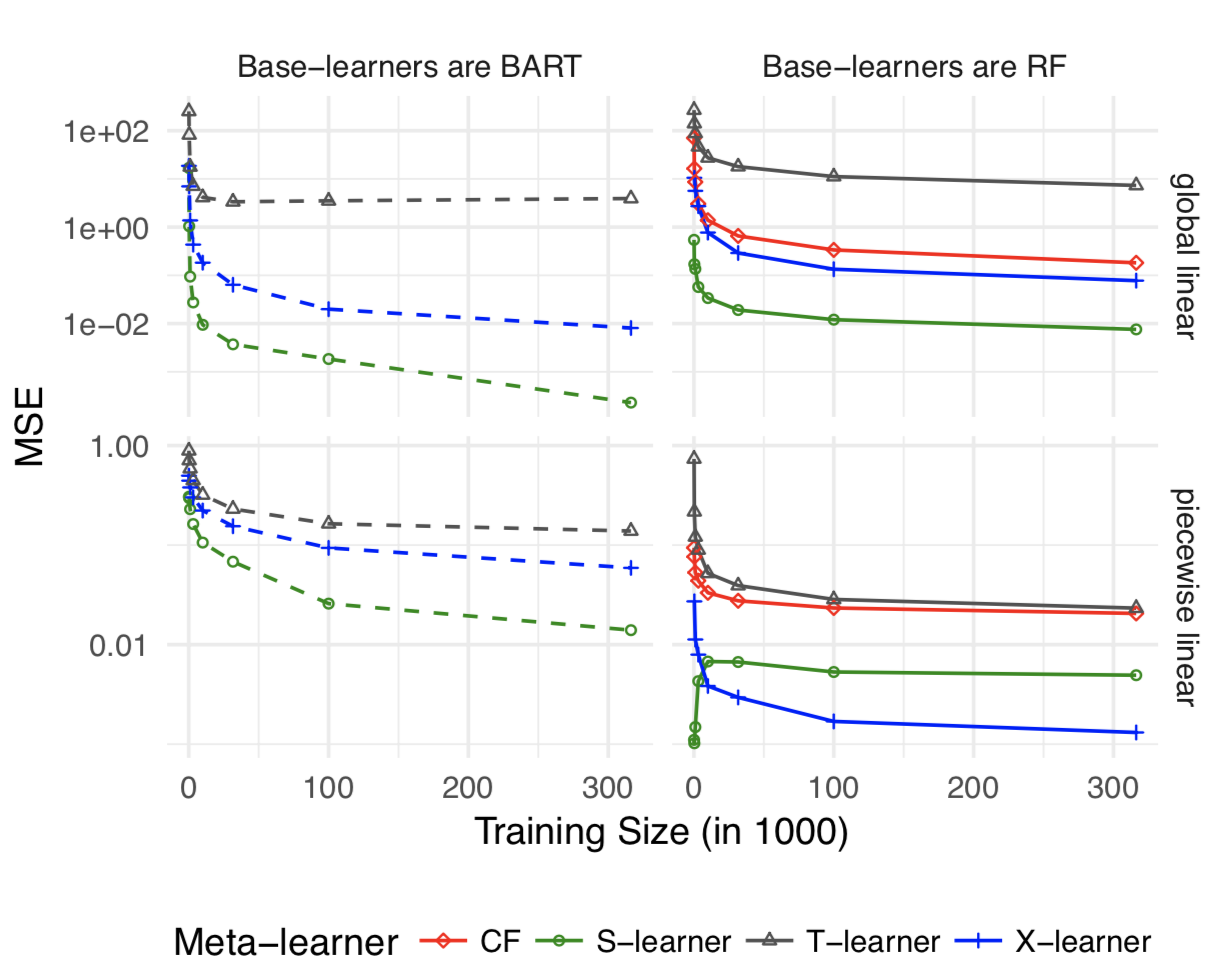
对其他HTE模型感兴趣的
AB实验人群定向HTE模型5 - Meta Learner的更多相关文章
- Paper慢慢读 - AB实验人群定向 Double Machine Learning
Hetergeneous Treatment Effect旨在量化实验对不同人群的差异影响,进而通过人群定向/数值策略的方式进行差异化实验,或者对实验进行调整.Double Machine Learn ...
- Paper慢慢读 - AB实验人群定向 Recursive Partitioning for Heterogeneous Casual Effects
这篇是treatment effect估计相关的论文系列第一篇所以会啰嗦一点多给出点背景. 论文 Athey, S., and Imbens, G. 2016. Recursive partition ...
- Paper慢慢读 - AB实验人群定向 Learning Triggers for Heterogeneous Treatment Effects
这篇论文是在 Recursive Partitioning for Heterogeneous Casual Effects 的基础上加入了两个新元素: Trigger:对不同群体的treatment ...
- 滴滴数据驱动利器:AB实验之分组提效
桔妹导读:在各大互联网公司都提倡数据驱动的今天,AB实验是我们进行决策分析的一个重要利器.一次实验过程会包含多个环节,今天主要给大家分享滴滴实验平台在分组环节推出的一种提升分组均匀性的新方法.本文首先 ...
- AB实验的高端玩法系列3 - AB组不随机?观测试验?Propensity Score
背景 都说随机是AB实验的核心,为什么随机这么重要呢?有人说因为随机所以AB组整体不存在差异,这样才能准确估计实验效果(ATE) \[ ATE = E(Y_t(1) - Y_c(0)) \] 那究竟随 ...
- AB实验的高端玩法系列4- 实验渗透低?用户未被触达?CACE/LATE
CACE全称Compiler Average Casual Effect或者Local Average Treatment Effect.在观测数据中的应用需要和Instrument Variable ...
- django模型之meta使用
模型元数据Meta是“任何不是字段的数据”,比如排序选项(ordering),数据库表名(db_table)或者人类可读的单复数名称(verbose_name 和verbose_name_plural ...
- AB实验的高端玩法系列2 - 更敏感的AB实验, CUPED!
背景 AB实验可谓是互联网公司进行产品迭代增加用户粘性的大杀器.但人们对AB实验的应用往往只停留在开实验算P值,然后let it go...let it go ... 让我们把AB实验的结果简单的拆解 ...
- 为什么在数据驱动的路上,AB 实验值得信赖?
在线AB实验成为当今互联网公司中必不可少的数据驱动的工具,很多公司把自己的应用来做一次AB实验作为数据驱动的试金石. 文 | 松宝 来自 字节跳动数据平台团队增长平台 在线AB实验成为当今互联网公司中 ...
随机推荐
- 深入理解Java虚拟机:JVM高级特性与最佳实践
第一部分走近Java第1章走近Java21.1概述21.2Java技术体系31.3Java发展史51.4Java虚拟机发展史91.4.1SunClassicExactVM91.4.2SunHotSpo ...
- 英语学习app——Alpha发布2
英语学习app--Alpha发布1 这个作业属这个作业属于哪个课程 https://edu.cnblogs.com/campus/xnsy/GeographicInformationScience/ ...
- 机器学习-浅谈神经网络和Keras的应用
概述 神经网络是深度学习的基础,它在人工智能中有着非常广泛的应用,它既可以应用于咱们前面的章节所说的Linear Regression, classification等问题,它还广泛的应用于image ...
- Python 类中方法的内部变量,命名加'self.'变成 self.xxx 和不加直接 xxx 的区别
先看两个类的方法: >>> class nc(): def __init__(self): self.name ='tester' #name变量加self >>> ...
- RabbitMq 深入了解
积少成多 ---- 仅以此致敬和我一样在慢慢前进的人儿 问题一:什么是RabbitMq 下面就是些个人的感受, rabbitmq 就是一个遵循AMQP协议(这个是啥不清楚) 的消息队列的实现,用于服 ...
- js中函数this的指向
this 在面试中,js指向也常常被问到,在开发过程中也是一个需要注意的问题,严格模式下的this指向undefined,这里就不讨论. 普通函数 记住一句话哪个对象调用函数,该函数的this就指向该 ...
- WPF另类实现摄像头录像
WPF中使用第三方控件来直接进行录像的控件没有找到(aforgenet好像不维护了?WPFMediaKit好像只能实现摄像头拍照.收费的控件没有使用,不做评论.) 通过百度(感谢:https://ww ...
- 五、spring源码阅读之ClassPathXmlApplicationContext加载beanFactory
ApplicationContext applicationContext = new ClassPathXmlApplicationContext("spring-config.xml&q ...
- C指针右左法则
摘录的别人的: C语言所有复杂的指针声明,都是由各种声明嵌套构成的.如何解读复杂指针声明呢?右左法则是一个既著名又常用的方法.不过,右左法则其实并不是C标准里面的内容,它是从C标准的声明规定中归纳出 ...
- Asp.net core下利用EF core实现从数据实现多租户(1)
前言 随着互联网的的高速发展,大多数的公司由于一开始使用的传统的硬件/软件架构,导致在业务不断发展的同时,系统也逐渐地逼近传统结构的极限. 于是,系统也急需进行结构上的升级换代. 在服务端,系统的I/ ...