Apache版hadoop编译
前言
做为大数据入门的基础,hadoop是每个大数据开发人员几乎不可避免的基础,目前hadoop已经发展到3.x.x版本,但当前企业使用的主流还是2.x.x版本,hadoop官网提供了编译后的hadoop,但这个是32位的,并且未供带C程序访问的接口,我们在使用本地库(可以用来做压缩,以及支持C程序等等)的时候就会出问题,所以需要自己再编译,之前自己编译过一次,但没有做总结,这次重新编译,做个总结记录一下。
一、环境准备
我是用的是 hadoop-2.8.5-src.tar.gz 版本,解压后找到BUILDING.txt
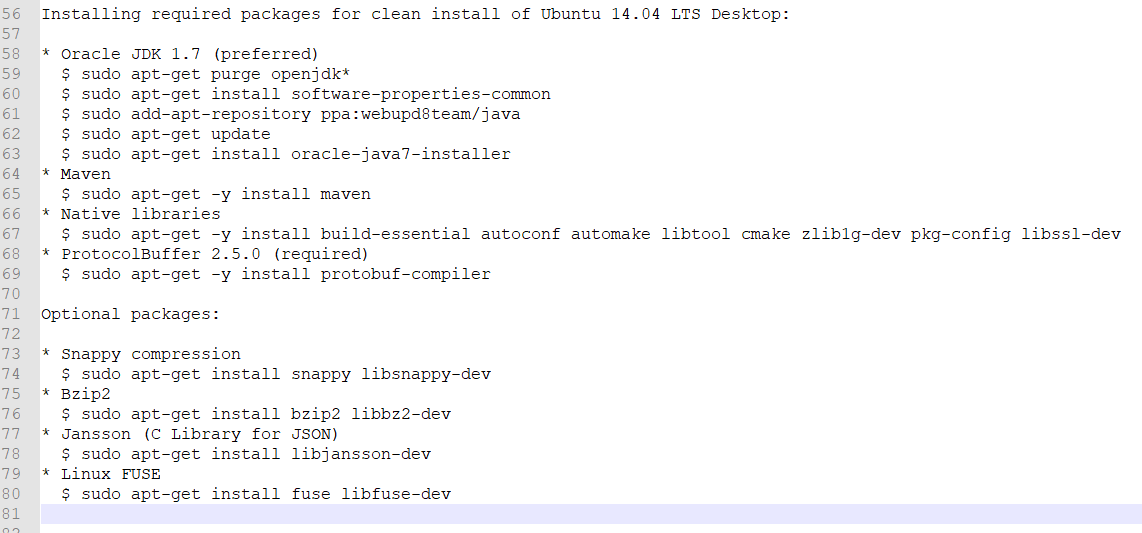
此文件列出了我们需要使用的一些环境,官方给的是在Ubuntu上进行编译,这里我使用的是CentOS7 minimal,部分软件下载 Ubuntu和CentOS不同,这里给大家总结了出来,执行以下命令即可
yum install -y gcc
yum install -y gcc-c++
yum install -y cmake
yum install -y snappy
yum install -y snappy-devel
yum install -y openssl
yum install -y autoconf
yum install -y libtool
yum install -y zlib-devel
yum install -y pkgconfig
yum install -y openssl-devel
yum install -y bzip2
yum install -y bzip2-devel
yum install -y bzip2-libs
上面是直接使用yum即可安装的,下面是需要我们自己下载相关文件编译安装,这里就不写这些软件的安装方式了,其中protobuf必须使用 2.5.0版本(注:谷歌将protobuf buffers放到github上后,已经找不到2.5.0官方版本了,这里提供一个从别人那里Fork到的提供给大家,protobuf-2.5.0)
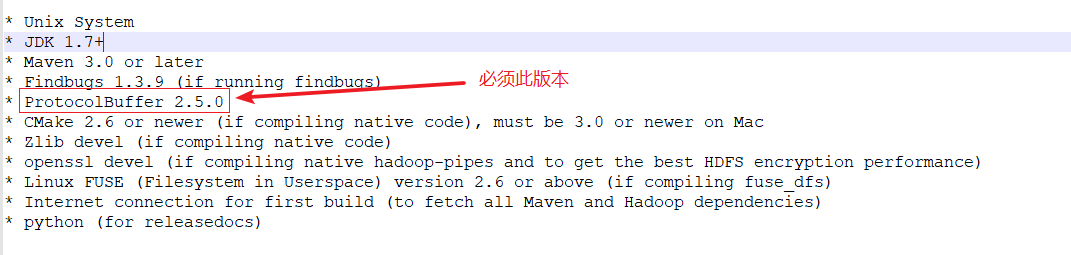
- 系统:CentOS Linux release 7.4.1708(minimal)
- JDK: java version "1.8.0_202"
- MAVEN: apache-maven-3.6.0
- ant: apache-ant-1.10.5
- protobuf: protobuf-2.5.0 (必须)
二、执行安装
进入解压后的hadoop-2.8.5-src,执行 (这里maven可以将仓库挂载到宿主机的maven仓库,减少网络压力,挂载方法可以参考这里)
mvn package -Pdist,native -Drequire.snappy -DskipTests -Dtar
要确保网络的通常,此过程比较耗时,中间可能会出现有关jar包下载失败导致编译失败,再次编译即可
编译完成后,hadoop-2.8.5-src/hadoop-dist/target 目录下即可找到我们编译后的文件

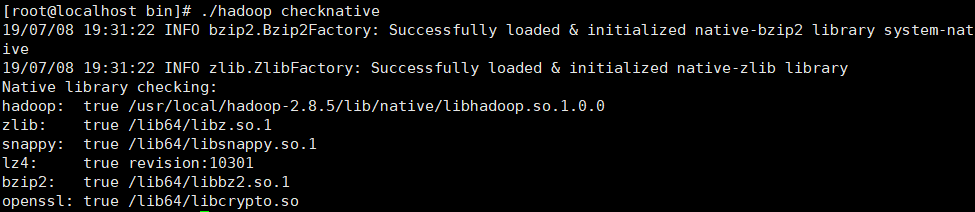
解压 hadoop-2.8.5-src/hadoop-dist/target/hadoop-2.8.5.tar.gz , bin文件夹下执行 ./hadoop checknative,即可查看是否成功将本地相关库编译成功
最后啰嗦一下:
java -version #java查看版本
mvn -v #maven查看版本
ant -version #ant查看版本
protoc --version #protocol查看版本
Apache版hadoop编译的更多相关文章
- Hadoop介绍及最新稳定版Hadoop 2.4.1下载地址及单节点安装
Hadoop介绍 Hadoop是一个能对大量数据进行分布式处理的软件框架.其基本的组成包括hdfs分布式文件系统和可以运行在hdfs文件系统上的MapReduce编程模型,以及基于hdfs和MapR ...
- Windows Azure HDInsight 支持预览版 Hadoop 2.2 群集
Windows Azure HDInsight 支持预览版 Hadoop 2.2 群集 继去年 10 月推出 Windows Azure HDInsight 之后,我们宣布 Windows Az ...
- Hadoop编译打包记录
Hadoop编译打包,基于2.7.2版本的源码. # 打包过程中需要使用到的工具 java -version mvn -version ant -version type protoc type cm ...
- APUE学习--第三版apue编译
第三版apue编译: 1. 首先在 http://www.apuebook.com/ 下载源码解压: tar zxvf src.3e.tar.gz 看完Readme可知,直接执 ...
- discuz论坛apache日志hadoop大数据分析项目:清洗数据核心功能解说及代码实现
discuz论坛apache日志hadoop大数据分析项目:清洗数据核心功能解说及代码实现http://www.aboutyun.com/thread-8637-1-1.html(出处: about云 ...
- Golang版protobuf编译
官方网址: https://developers.google.com/protocol-buffers/ (需要FQ) 代码仓库: https://github.com/google/protobu ...
- exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
1.虽然,不是大错,还说要贴一下,由于我运行run-example streaming.NetworkWordCount localhost 9999的测试案例,出现的错误,第一感觉就是Spark没有 ...
- Linux - Unix环境高级编程(第三版) 代码编译
Unix环境高级编程(第三版) 代码编译 本文地址:http://blog.csdn.net/caroline_wendy 时间:2014.10.2 1. 下载代码:http://www.apuebo ...
- Hadoop编译源码
Hadoop编译源码 克隆一个虚拟机 然后一步一步安装就行 安装所需:链接: https://pan.baidu.com/s/1jIZlQmi 密码: gggv 5.1 前期准备工作 1)CentOS ...
随机推荐
- Java并发编程教程
Java是一种多线程编程语言,我们可以使用Java来开发多线程程序. 多线程程序包含两个或多个可同时运行的部分,每个部分可以同时处理不同的任务,从而能更好地利用可用资源,特别是当您的计算机有多个CPU ...
- Http,Socket,TCP/IP 协议简述
Http,Socket,TCP/IP 协议简述:https://blog.csdn.net/gordohu/article/details/54097841 TCP/IP协议,HTTP协议与webSo ...
- jsp 内置对象HTTP协议
有些对象不用声明就能够在JSP页面的脚本部分使用,这就是JSP的内置对象. JSP的内置对象有:request .response.session.application.out. 下面我们将一一介绍 ...
- 【目录】mysql 进阶篇系列
随笔分类 - mysql 进阶篇系列 mysql 开发进阶篇系列 55 权限与安全(安全事项 ) 摘要: 一. 操作系统层面安全 对于数据库来说,安全很重要,本章将从操作系统和数据库两个层面对mysq ...
- 函数高阶(函数,改变函数this指向,高阶函数,闭包,递归)
一.函数的定义方式 1.函数声明方式 function 关键字(命名函数) 2.函数表达式(匿名函数) 3.new Function( ) var fn = new Function(‘参数1 ...
- MyBatis操作数据库(基本增删改查)
一.准备所需工具(jar包和数据库驱动) 网上搜索下载就可以 二.新建一个Java project 1.将下载好的包导入项目中,build path 2.编写MyBatis配置文件:主要填写prope ...
- java全栈商业小程序开发
此次开发只为学习和巩固,第一次学习开发 一.开发前需要了解: 开发框架MVVM.痛点.开源工具.VUE前端框架.微信支付模块.uni-app前端框架.小程序申请.开发工具下载.编写测试小程序.小程序结 ...
- 前端学习(十二)js数据类型(笔记)
选项卡: for循环 for(初始值,条件,自增){} for(var i=0; i<9;i++){} 几个按钮对应相同个内容!!! -------------------- ...
- Python 直接赋值、浅拷贝和深度拷贝区别
Python 直接赋值.浅拷贝和深度拷贝区别 转自https://www.runoob.com/w3cnote/python-understanding-dict-copy-shallow-or-de ...
- 【NOIP2019模拟2019.9.4】B(期望的线性性)
题目描述: \(1<=n,ai<=5*10^5\) 题解: 我是弱智我不会期望线性. 设\(E(a[i])\)表示第i个期望被减的个数. \(E(a[1])=a[1]\) 不难发现\(E( ...