大事务造成的延迟(从binlog入手分析)
log_event.cc
入口:
int Query_log_event::do_apply_event(Relay_log_info const *rli,
const char *query_arg, size_t q_len_arg)
包括: sql_mode , 客户端字符集,自增环境设置,登陆的db,结果执行时间,ddl和dml执行时间
dml: 数据被写盘后的时间 thd->set_time(&(common_header->when)); , 一个事务对应一个Query_Event
ddl: 实际语句执行时间 thd->set_time(&(common_header->when)); 整个语句执行后才写入执行时间
show slave status 入口:
rpl_slave.cc:
bool show_slave_status_send_data(THD *thd, Master_info *mi,
char* io_gtid_set_buffer,
char* sql_gtid_set_buffer)
if ((mi->get_master_log_pos() == mi->rli->get_group_master_log_pos()) &&
(!strcmp(mi->get_master_log_name(), mi->rli->get_group_master_log_name())))
检查SQL线程是否在中继日志的末尾
检查应使用两个条件进行
condition1:比较日志位置和
condition2:比较文件名
获得 seconds_behind_master 时间
long time_diff= ((long)(time(0) - mi->rli->last_master_timestamp) - mi->clock_diff_with_master);
系统时间 (long)(time(0)
主从之间系统时间差值 mi->clock_diff_with_master
1. 重点:
主从服务器的操作系统时间要一致,因为这两个是可变不稳定因素
dml语句和ddl语句的执行时间 mi->rli->last_master_timestamp
log_event.cc
Query_log_event::Query_log_event(const char* buf, uint event_len,
const Format_description_event
*description_event,
Log_event_type event_type)
dml(从begin开始) 和 ddl 执行时间
exec_time= end_time.tv_sec - thd_arg->start_time.tv_sec;
rpl_slave.cc
等于各个Event header 的 timestamp , 事务都是 GTID_EVENT 和 XID_EVENT 提交时间
rli->last_master_timestamp= ev->common_header->when.tv_sec + (time_t) ev->exec_time;
主库
从库
GTID_EVENT
T1+Commit时间
延迟 T2-(T1+Commit时间)
QUERY_EVENT
T1
延迟 T2-T1
MAP_EVENT
T1
延迟 T2-T1
DELETE_EVENT
T1
延迟 T2-T1
XID_EVENT
T1+Commit时间
延迟 T2-(T1+Commit时间)
binlog_event.h
class Log_event_header
·timeval:固定4字节,是新纪元时间(1970年1月1日0时0分0秒)以来的秒数。这个时
间是命令发起的时间。如何定义命令发起呢?它是执行计划生成后开始实际执行语句的
时候。源码可以是在dispatch一command函数的开头设置的(thd->set-time())。言外
之意对于语法意义、权限橙查、优化器生成执行计划的时间都包括在里面。其次要注意
了这个时间在从库计算Seconds一Behind一Master的时候是一个重要的依据,这一点我们
将在第27节详细讨论。
·type_code:固定1字节,event事件的编码。每TEvent有自己的编码。
·unmasked_server_id:固定4字节。就是生成这个Event服务端的serverid。即便从库端开启了
log-slave-updates%,从库将主库的Event写到BinaryLog,这个serverid也是主库
的serveride如果这个Event再冫欠传到主库,那么需要跳过。源码可以在
Log-event::do-shalLskip函数中找到跳过逻辑如下“
·event Len:固定4字节,整个Event的长度。
·end_log_p:固定4字节,下一个Event的开始位置。
.flags:固定2字节,某些Event包含这个标示,比如Format-descriptionlog_event中
LOG_EVENT_BINLOG_IN_USE_F 标示当前Binary log是当前写入文件。
class Log_event_footer
·Event footer中的crc:固定4字节,这部分就是整个Event的一个crc校验码,用于标示Event的完整性
因为能力和篇幅有限,不可能介绍所有的Event,本系列值介绍一些常用的Evnet,下面是本系 列将会介绍到了 Event:
• QUERY_EVENT=2 :在语句模式下记录实际的语句,在行模式下不记录任何语句相关 的倍息,
但是DDL始终是记录的语句,本系列值考虑行模式。因此即便是行模式下的 DDL也会记录为语句。
• FORMAT_DESCRIPTION_EVENT= 15:说明Binary log的版本信息。总包含在每一个 Binary log的开头。
• XID_EVENT=16:当事务提交的时候记录这个Event其中携带了XID信息。
• TABLE_MAP_EVENT = 19: 包含了tablejd和具体表名的映射。
• WRITE_ROWS_EVENT = 30: INSERT语句生成的Event,包含插入的实际数据。是行 模式才有的。
• UPDATE_ROWS_EVENT = 31: UPDATE语句生成的Event,包含数据的前后印象数 据。是行模式才有的
• DELETE_ROWS_EVENT = 32: DELETE语句生成的Event,包含实际需要删除的数 据。是行模式才有的。
• GTID_LOG_EVENT = 33: 如果开启GTID模式的时候生成关于GTID的倍息,并且携带 last commit和seq number作为MTS并行回放的依据。
• ANONYMOUS_GTIDJ_OG_EVENT=34:在关闭GTID模式的时候生成,并且携带last commit和seq number作为MTS并行回放的依据#。
• PREVIOUS_GIlDS_LOG_EVENT二35:说明前面所有的Binary log包含的GIlD SET, relay log则代表10线程收到的GTID SET。
参考Log_event_type
一、FORMAT DESCRIPTION EVENT
1、FORMAT_DESCRIPTION_EVENT的作用
携带的数据都是固定的,
包含了binary log的版本信息、MySQL的版本信息、Event_header的长度、
以及每个Event type的固定部分的长度。
下面倌患将会保存在从库的内存中:
• 在从库的内存中保存主库的倍息,这个变星是Master_info.mi_description_event。
queue_event函数中case binary_log::FORMAT_DESCRIPTION_EVENT部分。
• 将从库的relay log的FORMAT_DESCRIPTION_EVENT记录为和主库相同,
即更新 RelayJogInfo.rlLdescription_event
log_event.cc:
int Format_description_log_event::do_apply_event(Relay_log_info const *rli) 函数中如下片段:
如果从站未请求该事件,即Master发送了当从站要求位置> 4时,
该事件将使rli-> group_master_log_pos前进。
说Slave要位置1000,Format_desc事件的结尾是96。
然后在复制rli-> group_master_log_pos的开始将是0,
然后是96,然后跳到第一个真正询问的事件(即> 96)
/* Save the information describing this binlog */
const_cast<Relay_log_info *>(rli)->set_rli_description_event(this);
至少下面几个地方都会读取其中的倍息:
1. 每次SQL线程应用Event的时候会获取Event_header的长度和相应Even個定部分的长度。
2. I0线程启动的时候检测版本,參考函数 get_master_version_and_clock 。
3. 将倌患写入到 relay log 的开头的FORMAT_DESCR丨PTION_EVENT中。
4. 位置必须在#4
rpl_slave.cc:
static int get_master_version_and_clock(MYSQL* mysql, Master_info* mi)
从库针对不同版本不同处理 , mysql>=5.0 都能复制
switch (version_number)
{
case 0:
case 1:
case 2:
errmsg = "Master reported unrecognized MySQL version";
err_code= ER_SLAVE_FATAL_ERROR;
sprintf(err_buff, ER(err_code), errmsg);
break;
case 3:
mi->set_mi_description_event(new
Format_description_log_event(1, mysql->server_version));
break;
case 4:
mi->set_mi_description_event(new
Format_description_log_event(3, mysql->server_version));
break;
default:
/*
Master is MySQL >=5.0. Give a default Format_desc event, so that we can
take the early steps (like tests for "is this a 3.23 master") which we
have to take before we receive the real master's Format_desc which will
override this one. Note that the Format_desc we create below is garbage
(it has the format of the *slave*); it's only good to help know if the
master is 3.23, 4.0, etc.
*/
mi->set_mi_description_event(new
Format_description_log_event(4, mysql->server_version));
break;
}
}
将binlog event 写入 binlog cache
bool Format_description_log_event::write(IO_CACHE* file)
if (post_header_len_size == Binary_log_event::LOG_EVENT_TYPES)
相同版本主从服务器复制
else if (post_header_len_size > Binary_log_event::LOG_EVENT_TYPES)
在新的Master和旧的Slave之间复制。但不会从内存复制,所以任何内存不足的读取。
else
在旧的主服务器和新的从服务器之间复制。
在这种情况下,它可能导致 Master 和 Slave 上发生不同的number_of_events。 当循环relay log时,来自Master的FDE用于在Slave上创建FDE事件,该事件将在此处写入。 在这种情况下,我们可能最终会读取更多字节,如post_header_len.size()<Binary_log_event :: LOG_EVENT_TYPES;。 引起内存问题。
binlog_version
server_version
create_timestamp
headerjength
array of post-header
•固定部分,这部分是大小不变的。
1. binlog_version: 2字节 binary log的版本当前为‘4’。
2. server_version: 50字节,MySQL的版本,为字符串形式#
3. create_timestamp: 4字节,MySQL每次启动的时候的第一^^binary log的 FORMAT_DESCRIPTION_EVENT会记录,其他情况为0,源码有如下解释:
4. headerjength: 1 字节,Event header的长度。当前为‘19’。
5. array of post-header:当前版本为39字节#这是一个数组用于保存每个Event类型的固 定部分的大小9
生成时机
这个Event作为binary log的第一个Event, _般都是在binary log切换的时候发生比如:
• flush binary 丨ogs命令。
• binary log自动切换。
• 重启MySQL实例
最后注意下在本Event的Event header中flags如果为 LOG_EVENT_BINLOGJN_USE_F标示 说明当前binary log没有关闭(比如本binary log为当前写入文件或者异常关闭MySQL实 例)^如果异常关闭MySQL实例会检测这个值决定是否做binary log recovery。
二、PREVIOUS GTIDS LOG EVENT
1、PREVIOUS_GTIDS_LDG_EVENT的作用
这个Event只包含可变部分。通常作为binary log的第二个Event,用于描述前面所有的binary log包含的GTID SET (包括已经删除的)。前面我们说过初始化GTID模块的时候也会扫描 binary log中的这个Event*在relay log同样包含这个Event,主要用于描述I/O线程接收过哪些 GTID,我们后面能看到MySQL实例初始化的时候可能会扫描relay log中的这个Event来确认 Retrieved_Gtid_Set 。
3、 主体格式
整个写入过程集中在Gtid_set::encode函数中,因为GTID SET中可能出现多个server_uuid并 且可能出现'gap',因此是可变的。在Gtid_set::encode函数中我们也可以清晰的看到它在循环 GTID SET中的每个server_uuid和每一个GTID SET Interval,如下:
• 可变部分,这部分大小可变
• number of sids: 8字节# 小端显示,本GITD SET有多少个server_uuid
• server_uuid: 16字节。GTID SET中的server_uuid
• n_intervals: 8字节。本server_uuid下GTID SET Interval的个数
• inter_start: 8字节。每个GTID SET Interval起始的gno
• inter_next: 8字节。每个GTID SET Interval结尾的下一个gno
注意:甶于一个GTIDSET可以包含多个server_uuid,因此第2到第5部分可能包含多个。
如果 还包含多个GTID SET Interval则第4和第5部分也可能多个。(参考图6-2)
4、 实例解析
下面是一个PREVIOUS_GTIDS_LOG_EVENT (mysqlbinlog —hexdump 输出>,这种情况 是我手动删除了 auto.cnf手动构造出来的:
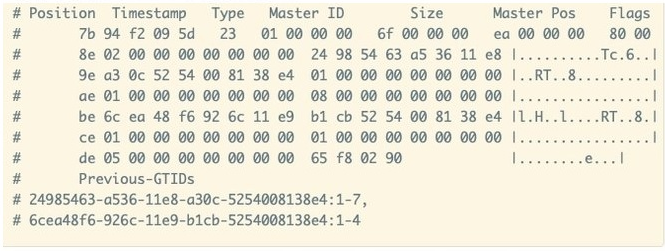 (cnblog格式能否优美一下)
(cnblog格式能否优美一下)
• 02 00 00 00 00 00 00 00:包含2个server_uuid U小端显示就是2个。
• 24 98 54 63 a5 36 11 e8 a3 0c 52 54 00 81 38 e4:第一个server_uuid。
• 01 00 00 ◦0 00 00 00 00: njntervals表示本GTID SET Interval的个数。小端显示就 是1个
• 01 00 00 00 00 00 00 00: inter_start,第一个GTID SET Interva丨的起始的gno为1
• 08 00 00 00 00 00 00 00: inter_next,第一个GTID SET Interval结尾的下一个gno为8.
• 6c ea 48 f6 92 6c 11 e9 b1 cb 52 54 00 81 38 e4:第二个server_uuid
• 01 00 00 00 00 00 00 00: njntervals表示本GT丨D SET Interval的个数。小端显示就 是1个
• 01 00 00 00 00 00 00 00: inter_start,第一个GTID SET Interva丨的起始的gno为 1
• 05 00 00 00 00 00 00 00: inter_next,第一个GTID SET Interval结尾的下一个gno位
我们看到解析出来的:
• 24985463-a536-11e8-a30c-5254008138e4:1-7
• 6cea48f6-926c-11e9-b1cb-5254008138e4:1-4
可以看到它们是一致的,只是inter_next应该减去了 1,因为Event中记录的是GTID SET Interval结尾的下一个gno*
5、生成时机
生成时机一般也是进行binary log切换的时候作为第二个Event写入binary log
7、重点 EventGTIDJ_LOG_EVENT
注意:本文分为正文和附件两部分,都是图片格式,如果正文有图片不清晰可以将附件的图片 保存到本地查看。
本节比较简单因为GTID_LOG_EVENT和ANONYMOUS_GTID_LOG_EVENT格式一致,只是 携带的数据不一样而已,我们只解释GTID_LOG_EVENT即可
一、GTID LOG EVENT
(1) GTID_LOG_EVENT的作用
GTID的作用我们前面已经说过了,后面还会提及。这里我们只需要知道GTID_LOG_EVENT 这个Event主要记录的部分有下面三个:
• GTID的详细倌息。
• 逻辑时钟详细倍息,即last commit和seq number
• 是否为行模式,比如DDL语句就不是行模式的
我们需要注意显示开启事务的情况下GTID_LOG_EVENT和XID_EVENT Event header的 timestamp都是commit命令发起的时间,当然如果没有显示开启事务那么timestamp还是命 令发起的时间。

固定部分
• flags: 1字节。主要用于表示是否是行模式的,如果是则为0X00。不是则为0X01,注意 DDL都不是行模式的,而是语句模式^
• server_uuid: 16字节。server_uuid參数去掉中间的16进制表示。
• gno: 8字节。小端显示。表示GTID的序号。
• ts type: 1字节•固定为02。
• last commit: 8字节。小端显示。
• seq number: 8字节。小端显示。
关于last commit和seq number的生成方式会在后面第15节和第16节进行详细描述。
(4)简单解析
下面是一个的GTID_LOG_EVEN丁(mysqlbinlog—hexdump 输出):
#191218 21:08:49 server id 1 end_log_pos 417 CRC32 0xac5430b1
# Position Timestamp Type Master ID Size Master Pos Flags
# 160 e1 24 fa 5d 21 01 00 00 00 41 00 00 00 a1 01 00 00 00 00
# 173 00 12 cf ee 78 e5 80 11 e6 a7 90 00 ff 05 93 af |....x...........|
# 183 ce 02 00 00 00 00 00 00 00 02 01 00 00 00 00 00 |................|
# 193 00 00 02 00 00 00 00 00 00 00 b1 30 54 ac |...........0T.|
# GTID last_committed=1 sequence_number=2 rbr_only=yes
/*!50718 SET TRANSACTION ISOLATION LEVEL READ COMMITTED*//*!*/;
mysql> show variables like '%uuid%';
+---------------+--------------------------------------+
| Variable_name | Value |
+---------------+--------------------------------------+
| server_uuid | 12cfee78-e580-11e6-a790-00ff0593afce |
+---------------+--------------------------------------+
1 row in set (0.00 sec)
• 02 00 00 00 00 00 00 00:这就是GTID的序号,小端显示就是0X02, 10进制的2
• 02: ts type
• 01 00 00 00 00 00 00 00:即last_committed=1 , 小端显示就是0X01
• 02 00 00 00 00 00 00 00:即sequence_nunnber=2 ,小端显示就是0X02
• 40 00 00 00 00 00 00 00:这就是GTID的序号,小端显示就是0X40, 10进制的64
• 02: ts type
• 01 00 00 00 00 00 00 00:即last_committed=1,小端显示就是0X01
• 02 00 00 00 00 00 00 00:即sequence_nunnber=2 ,小端显示就是0X02
(5) 生成时机
关于生成时机来讲GTID_LOG_EVENT的生成和写入binary log文件都是order commit的flush 阶段,这里就不过多解释了
(6) ANONYMOUS_GTID_LOG_EVENT
这是匿名GTID Event, 5.7如果不开启GTID则使用这种格式。它除了不生成GTID相关倍患外 和GTID_LOG_EVENT保持一致,即如下部分全部为0:
• server_uuid
• gno
就不单独解析了,有兴趣的朋友可以自行解析一下,比较简单
(7) GTID三种模式
•自动生成GTID:主库一般是这种情况(AUTOMATIC_GROUP)
•指定GTID:从库或者使用GTID_NEXT—般就是这种情况(GTID_GROUP>
•匿名GTID:当然也就是不开启GTID了时候了(ANONYMOUS_GROUP)
源码的注释
rpl_gtid.h
/**
Specifies that the GTID has not been generated yet; it will be
generated on commit. It will depend on the GTID_MODE: if
GTID_MODE<=OFF_PERMISSIVE, then the transaction will be anonymous;
if GTID_MODE>=ON_PERMISSIVE, then the transaction will be assigned
a new GTID.
This is the default value: thd->variables.gtid_next has this state
when GTID_NEXT="AUTOMATIC".
It is important that AUTOMATIC_GROUP==0 so that the default value
for thd->variables->gtid_next.type is AUTOMATIC_GROUP.
*/
AUTOMATIC_GROUP= 0,
/**
Specifies that the transaction has been assigned a GTID (UUID:NUMBER).
thd->variables.gtid_next has this state when GTID_NEXT="UUID:NUMBER".
This is the state of GTID-transactions replicated to the slave.
*/
GTID_GROUP,
/**
Specifies that the transaction is anonymous, i.e., it does not
have a GTID and will never be assigned one.
thd->variables.gtid_next has this state when GTID_NEXT="ANONYMOUS".
This is the state of any transaction generated on a pre-GTID
server, or on a server with GTID_MODE==OFF.
*/
ANONYMOUS_GROUP,
/**
GTID_NEXT is set to this state after a transaction with
GTID_NEXT=='UUID:NUMBER' is committed.
This is used to protect against a special case of unsafe
non-transactional updates.
Background: Non-transactional updates are allowed as long as they
are sane. Non-transactional updates must be single-statement
transactions; they must not be mixed with transactional updates in
the same statement or in the same transaction. Since
non-transactional updates must be logged separately from
transactional updates, a single mixed statement would generate two
different transactions.
Problematic case: Consider a transaction, Tx1, that updates two
transactional tables on the master, t1 and t2. Then slave (s1) later
replays Tx1. However, t2 is a non-transactional table at s1. As such, s1
will report an error because it cannot split Tx1 into two different
transactions. Had no error been reported, then Tx1 would be split into Tx1
and Tx2, potentially causing severe harm in case some form of fail-over
procedure is later engaged by s1.
To detect this case on the slave and generate an appropriate error
message rather than causing an inconsistency in the GTID state, we
do as follows. When committing a transaction that has
GTID_NEXT==UUID:NUMBER, we set GTID_NEXT to UNDEFINED_GROUP. When
the next part of the transaction is being processed, an error is
generated, because it is not allowed to execute a transaction when
GTID_NEXT==UNDEFINED. In the normal case, the error is not
generated, because there will always be a Gtid_log_event after the
next transaction.
*/
UNDEFINED_GROUP,
/*
GTID_NEXT is set to this state by the slave applier thread when it
reads a Format_description_log_event that does not originate from
this server.
Background: when the slave applier thread reads a relay log that
comes from a pre-GTID master, it must preserve the transactions as
anonymous transactions, even if GTID_MODE>=ON_PERMISSIVE. This
may happen, e.g., if the relay log was received when master and
slave had GTID_MODE=OFF or when master and slave were old, and the
relay log is applied when slave has GTID_MODE>=ON_PERMISSIVE.
So the slave thread should set GTID_NEXT=ANONYMOUS for the next
transaction when it starts to process an old binary log. However,
there is no way for the slave to tell if the binary log is old,
until it sees the first transaction. If the first transaction
begins with a Gtid_log_event, we have the GTID there; if it begins
with query_log_event, row events, etc, then this is an old binary
log. So at the time the binary log begins, we just set
GTID_NEXT=NOT_YET_DETERMINED_GROUP. If it remains
NOT_YET_DETERMINED when the next transaction begins,
gtid_pre_statement_checks will automatically turn it into an
anonymous transaction. If a Gtid_log_event comes across before
the next transaction starts, then the Gtid_log_event will just set
GTID_NEXT='UUID:NUMBER' accordingly.
*/
NOT_YET_DETERMINED_GROUP
};
待续!
大事务造成的延迟(从binlog入手分析)的更多相关文章
- MySQL大事务导致的Insert慢的案例分析
[问题] 有台MySQL服务器不定时的会出现并发线程的告警,从记录信息来看,有大量insert的慢查询,执行几十秒,等待flushing log,状态query end [初步分析] 从等待资源来看, ...
- MySQL线上执行大事务或锁表操作
前提 在线执行一些大事务或锁表操作(给某个核心级表加一列或者执行修改操作),此时不但主库从库要长时间锁表,主从延迟也会变大.未避免大事务sql对整个集群产生影响,,我们希望一条SQL语句只在Maste ...
- mysql 案例 ~ 分析执行完的大事务
一 简介:今天咱们来聊聊如何定位以及执行完的大事务 二 目的:通过分析binlog脚本来定位执行的大事务 三 分析脚本 mysqlbinlog --base64-output=decode-rows ...
- Spring大事务到底如何优化?
所谓的大事务就是耗时比较长的事务. Spring有两种方式实现事务,分别是编程式和声明式两种. 不手动开启事务,mysql 默认自动提交事务,一条语句执行完自动提交. 一.大事务产生的原因 操作的数据 ...
- REQUIRES_NEW 如果不在一个事务那么自己创建一个事务 如果在一个事务中 自己在这个大事务里面在创建一个子事务 相当于嵌套事务 双层循环那种
REQUIRES_NEW 如果不在一个事务那么自己创建一个事务 如果在一个事务中 自己在这个大事务里面在创建一个子事务 相当于嵌套事务 双层循环那种 不管是否存在事务,业务方法总会自己开启一个事 ...
- SqlServer 复制中将大事务分成小事务分发
原文:SqlServer 复制中将大事务分成小事务分发 在sql server 复制中,当在发布数据库执行1个大事务时,如一次性操作 十万或百万以上的数据.当操作数据在发布数据库执行完成后 ,日志读取 ...
- 生产环境下,MySQL大事务操作导致的回滚解决方案
如果mysql中有正在执行的大事务DML语句,此时不能直接将该进程kill,否则会引发回滚,非常消耗数据库资源和性能,生产环境下会导致重大生产事故. 如果事务操作的语句非常之多,并且没有办法等待那么久 ...
- 基于binlog来分析mysql的行记录修改情况(python脚本分析)
最近写完mysql flashback,突然发现还有有这种使用场景:有些情况下,可能会统计在某个时间段内,MySQL修改了多少数据量?发生了多少事务?主要是哪些表格发生变动?变动的数量是怎 ...
- 基于binlog来分析mysql的行记录修改情况
https://www.cnblogs.com/xinysu/archive/2017/05/26/6908722.html import pymysqlfrom pymysql.cursors im ...
随机推荐
- CachedRowSet 接口
Sun Microsystems 提供的 CachedRowSet 接口的参考实现是一个标准实现.开发人员可以按原样使用此实现.可以扩展它,也可以选择自己编写此接口的实现. CachedRowSet ...
- CentOS6.5升级NTP
二.安装依赖包 yum -y install gcc libcap libcap-devel glibc-devel 三.升级Ntp 1.tar zxf /tmp/ntp-4.2.8p10.tar.g ...
- Perl中神奇的@EXPORT
@EXPORT Perl通过继承,可以使子类可以像使用本地方法一样使用其基类的方法. 一个类如果想把自己的方法(变量)暴露给别人使用(比如一些公共基础类的的通用方法或变量),还可将直接将方法(变量)添 ...
- 17.python文件处理
原文:https://www.cnblogs.com/linhaifeng/articles/5984922.html 文件处理流程: 1. 打开文件,得到文件句柄并赋值给一个变量2. 通过句柄对文件 ...
- 14.python类型总结,集合,字符串格式化
借鉴:https://www.cnblogs.com/linhaifeng/articles/5935801.html https://www.cnblogs.com/wupeiqi/article ...
- pyspider 安装使用过程的一些坑
1.没有正确安装对应版本的pycurl 原因分析: PyCurl 安装错误,需要安装 PyCurl 库(PyCurl 是一个Python接口,是多协议文件传输库的 libcurl.类似于urllib ...
- Redis 都有哪些数据类型?分别在哪些场景下使用比较合适?
redis 主要有以下几种数据类型: string hash list set sorted set string 这是最简单的类型,就是普通的 set 和 get,做简单的 KV 缓存. set c ...
- 【python小随笔】celery异步任务与调用返回值
s1.py(配置任务文件) from celery import Celery import time my_task = Celery("tasks", broker=" ...
- 【转载】JavaScript术语:shim 和 polyfill
在学习和使用 JavaScript 的时候,我们会经常碰到两个术语:shim 和 polyfill.它们有许多定义和解释,意思相近又有差异. Shim Shim 指的是在一个旧的环境中模拟出一个新 A ...
- 洛谷$P2523\ [HAOI2011]\ Problem\ c$ $dp$
正解:$dp$ 解题报告: 传送门$QwQ$ 首先港下不合法的情况.设$sum_i$表示$q\geq i$的人数,当且仅当$sum_i>n-i+1$时无解. 欧克然后考虑这题咋做$QwQ$. 一 ...