RoBERTa模型总结
RoBERTa模型总结
前言
RoBERTa是在论文《RoBERTa: A Robustly Optimized BERT Pretraining Approach》中被提出的。此方法属于BERT的强化版本,也是BERT模型更为精细的调优版本。RoBERTa主要在三方面对之前提出的BERT做了该进,其一是模型的具体细节层面,改进了优化函数;其二是训练策略层面,改用了动态掩码的方式训练模型,证明了NSP(Next Sentence Prediction)训练策略的不足,采用了更大的batch size;其三是数据层面,一方面使用了更大的数据集,另一方面是使用BPE(Byte-Pair Encoding )来处理文本数据。
1. RoBERTa对一般BERT的模型细节进行了优化
Optimization
原始BERT优化函数采用的是Adam默认的参数,其中\(\beta_1=0.9, \beta_2 = 0.999\),在RoBERTa模型中考虑采用了更大的batches,所以将\(\beta_2\)改为了0.98。
2. RoBARTa对一般BERT的训练策略进行了优化
(1)动态掩码与静态掩码
原始静态mask:
BERT中是准备训练数据时,每个样本只会进行一次随机mask(因此每个epoch都是重复),后续的每个训练步都采用相同的mask,这是原始静态mask,即单个静态mask,这是原始 BERT 的做法。
修改版静态mask:
在预处理的时候将数据集拷贝 10 次,每次拷贝采用不同的 mask(总共40 epochs,所以每一个mask对应的数据被训练4个epoch)。这等价于原始的数据集采用10种静态 mask 来训练 40个 epoch。
动态mask:
并没有在预处理的时候执行 mask,而是在每次向模型提供输入时动态生成 mask,所以是时刻变化的。
不同模式的实验效果如下表所示。其中 reference 为BERT 用到的原始静态 mask,static 为修改版的静态mask。

(2)对NSP训练策略的探索
为了探索NSP训练策略对模型结果的影响,将一下4种训练方式及进行对比:
SEGMENT-PAIR + NSP:
这是原始 BERT 的做法。输入包含两部分,每个部分是来自同一文档或者不同文档的 segment (segment 是连续的多个句子),这两个segment 的token总数少于 512 。预训练包含 MLM 任务和 NSP 任务。
SENTENCE-PAIR + NSP:
输入也是包含两部分,每个部分是来自同一个文档或者不同文档的单个句子,这两个句子的token 总数少于 512。由于这些输入明显少于512 个tokens,因此增加batch size的大小,以使 tokens 总数保持与SEGMENT-PAIR + NSP 相似。预训练包含 MLM 任务和 NSP 任务。
FULL-SENTENCES:
输入只有一部分(而不是两部分),来自同一个文档或者不同文档的连续多个句子,token 总数不超过 512 。输入可能跨越文档边界,如果跨文档,则在上一个文档末尾添加文档边界token 。预训练不包含 NSP 任务。
DOC-SENTENCES:
输入只有一部分(而不是两部分),输入的构造类似于FULL-SENTENCES,只是不需要跨越文档边界,其输入来自同一个文档的连续句子,token 总数不超过 512 。在文档末尾附近采样的输入可以短于 512个tokens, 因此在这些情况下动态增加batch size大小以达到与 FULL-SENTENCES 相同的tokens总数。预训练不包含 NSP 任务。
以下是论文中4种方法的实验结果:
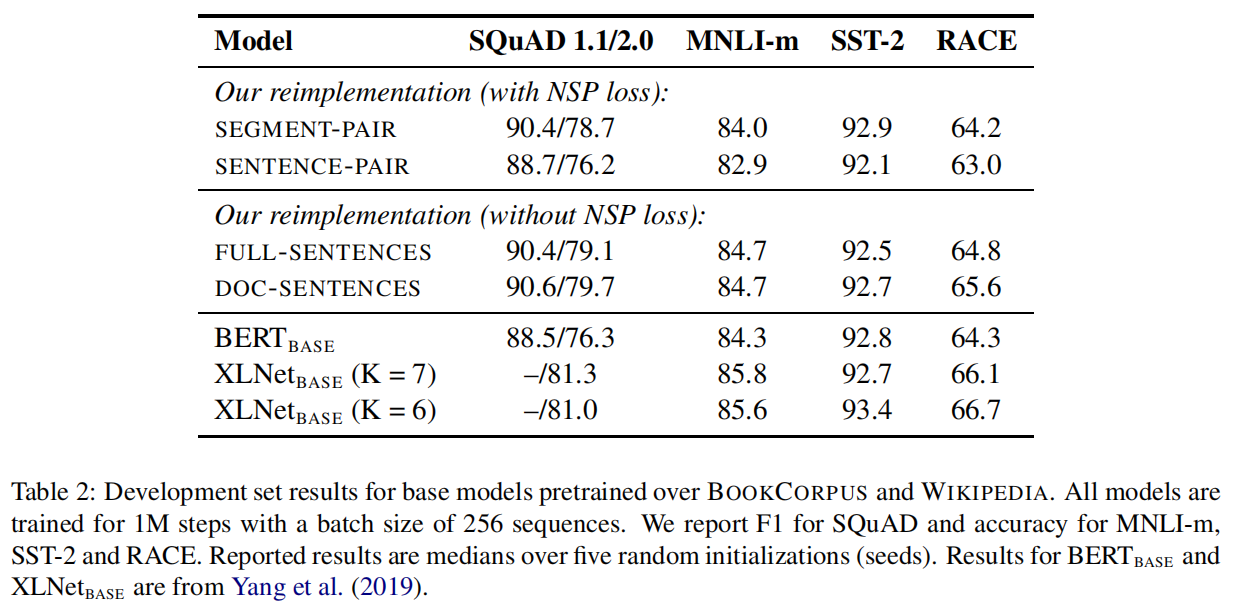
从实验结果来看,如果在采用NSP loss的情况下,将SEGMENT-PAIR与SENTENCE-PAIR 进行对比,结果显示前者优于后者。发现单个句子会损害下游任务的性能,可能是如此模型无法学习远程依赖。接下来把重点放在没有NSP loss的FULL-SENTENCES上,发现其在四种方法中结果最好。可能的原因:原始 BERT 实现采用仅仅是去掉NSP的损失项,但是仍然保持 SEGMENT-PARI的输入形式。最后,实验还发现将序列限制为来自单个文档(doc-sentence)的性能略好于序列来自多个文档(FULL-SENTENCES)。但是 DOC-SENTENCES 策略中,位于文档末尾的样本可能小于 512 个 token。为了保证每个 batch 的 token 总数维持在一个较高水平,需要动态调整 batch-size。出于处理方便,后面采用DOC-SENTENCES输入格式。
(3)Training with large batches
虽然在以往的经验中,当学习速率适当提高时,采用非常 大mini-batches的训练既可以提高优化速度,又可以提高最终任务性能。但是论文中通过实验,证明了更大的batches可以得到更好的结果,实验结果下表所示。
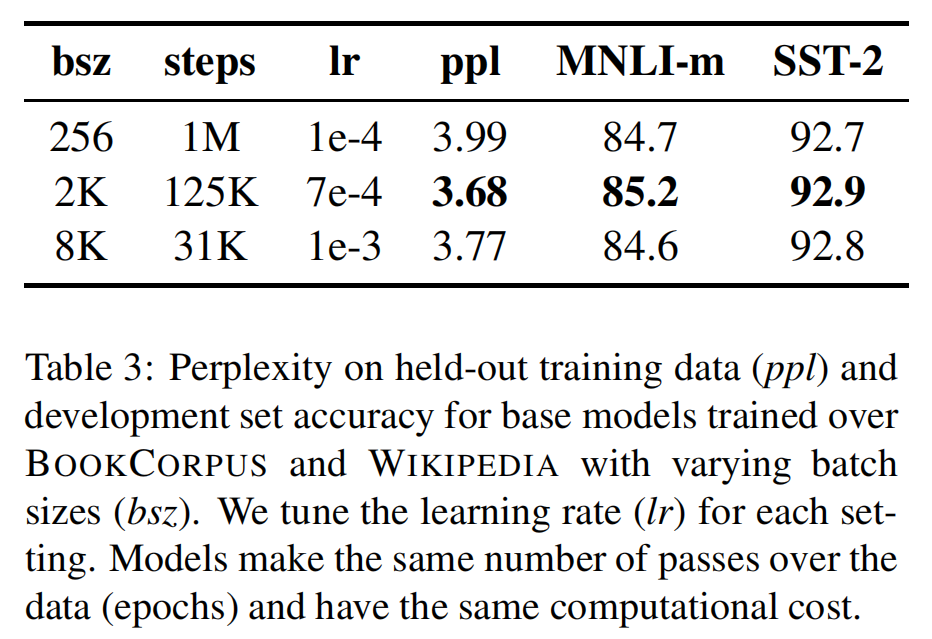
论文考虑了并行计算等因素,在后续的实验中使用batch size=8k进行训练。
3. RoBARTa在数据层面对模型进行了优化
(1)使用了更大的训练数据集
将16G的数据集提升到160G数据集,并改变多个steps,寻找最佳的超参数。
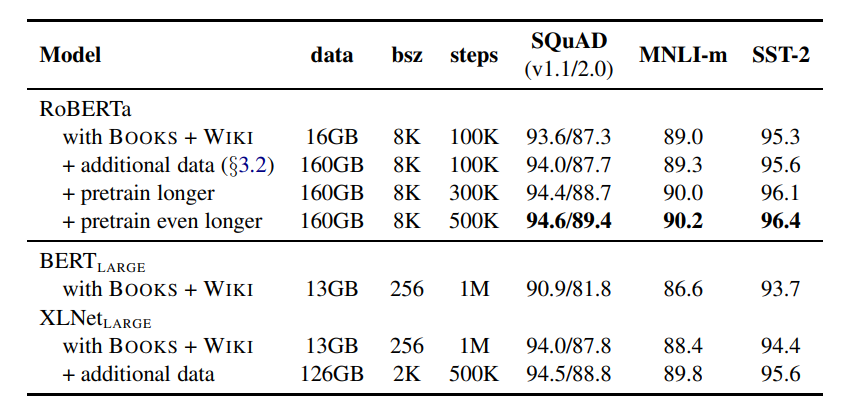
(2)Text Encoding
字节对编码(BPE)(Sennrich et al.,2016)是字符级和单词级表示的混合,该编码方案可以处理自然语言语料库中常见的大量词汇。BPE不依赖于完整的单词,而是依赖于子词(sub-word)单元,这些子词单元是通过对训练语料库进行统计分析而提取的,其词表大小通常在 1万到 10万之间。当对海量多样语料建模时,unicode characters占据了该词表的大部分。Radford et al.(2019)的工作中介绍了一个简单但高效的BPE, 该BPE使用字节对而非unicode characters作为子词单元。
总结下两种BPE实现方式:
基于 char-level :原始 BERT 的方式,它通过对输入文本进行启发式的词干化之后处理得到。
基于 bytes-level:与 char-level 的区别在于bytes-level 使用 bytes 而不是 unicode 字符作为 sub-word 的基本单位,因此可以编码任何输入文本而不会引入 UNKOWN 标记。
当采用 bytes-level 的 BPE 之后,词表大小从3万(原始 BERT 的 char-level )增加到5万。这分别为 BERT-base和 BERT-large增加了1500万和2000万额外的参数。之前有研究表明,这样的做法在有些下游任务上会导致轻微的性能下降。但是本文作者相信:这种统一编码的优势会超过性能的轻微下降。且作者在未来工作中将进一步对比不同的encoding方案。
RoBERTa模型总结的更多相关文章
- Improving Commonsense Question Answering by Graph-based Iterative Retrieval over Multiple Knowledge Sources —— 基于多知识库迭代检索的常识问答系统
基于多知识库迭代检索的问答系统 论文地址 背景 常识问答任务需要引入外部知识来帮助模型更好地理解自然语言问题,现有的解决方案大都采用两阶段框架: 第一阶段 -- 从广泛的知识来源中找到与给定问题相关的 ...
- CoLAKE: 如何实现非结构性语言和结构性知识表征的同步训练
原创作者 | 疯狂的Max 论文CoLAKE: Contextualized Language and Knowledge Embedding 解读 01 背景与动机 随着预训练模型在NLP领域各大任 ...
- Qt 学习之路:模型-视图高级技术
PathView PathView是 QtQuick 中最强大的视图,同时也是最复杂的.PathView允许创建一种更灵活的视图.在这种视图中,数据项并不是方方正正,而是可以沿着任意路径布局.沿着同一 ...
- BERT-wwm、BERT-wwm-ext、RoBERTa、SpanBERT、ERNIE2
一.BERT-wwm wwm是Whole Word Masking(对全词进行Mask),它相比于Bert的改进是用Mask标签替换一个完整的词而不是子词,中文和英文不同,英文中最小的Token就是一 ...
- NLP中的预训练语言模型(二)—— Facebook的SpanBERT和RoBERTa
本篇带来Facebook的提出的两个预训练模型——SpanBERT和RoBERTa. 一,SpanBERT 论文:SpanBERT: Improving Pre-training by Represe ...
- RoBERTa
2019-10-19 21:46:18 问题描述:谈谈对RoBERTa的理解. 问题求解: 在XLNet全面超越Bert后没多久,Facebook提出了RoBERTa(a Robustly Optim ...
- RoBERTa:一个调到最优参的BERT
RoBERTa: A Robustly Optimized BERT Pretraining Approach. Yinhan Liu, Myle Ott, Naman Goyal, et al. 2 ...
- NLP与深度学习(六)BERT模型的使用
1. 预训练的BERT模型 从头开始训练一个BERT模型是一个成本非常高的工作,所以现在一般是直接去下载已经预训练好的BERT模型.结合迁移学习,实现所要完成的NLP任务.谷歌在github上已经开放 ...
- NLP论文解读:无需模板且高效的语言微调模型(下)
原创作者 | 苏菲 论文题目: Prompt-free and Efficient Language Model Fine-Tuning 论文作者: Rabeeh Karimi Mahabadi 论文 ...
随机推荐
- 对EntityViewInfo的理解
1,EntityViewInfo常常用作bos中接口参数,来做查询用,其中包含了FilterInfo(过滤).Selector(指定属性)以及Sorter(排序) SelectorItemColl ...
- C# event 事件
事件第二篇:https://www.cnblogs.com/FavoriteMango/p/11731485.html 曾经面试碰到一道设计题: 现有一个人,一群鸟,人有一把手枪,当人开枪时,所有的鸟 ...
- linux大盘格式化分区
Linux 实例的磁盘管理 对于 Linux 系统上的大磁盘,也要采用 GPT 分区格式, 也可以不分区, 把磁盘当成一个整体设备使用. 在 Linux 上一般采用 XFS 或者 EXT4 来做大盘的 ...
- Python3 pip换源
pip安装源 介绍 """ 1.采用国内源,加速下载模块的速度 2.常用pip源: -- 豆瓣:https://pypi.douban.com/simple -- 阿里: ...
- JVM探秘:内存分配与回收策略
本系列笔记主要基于<深入理解Java虚拟机:JVM高级特性与最佳实践 第2版>,是这本书的读书笔记. 内存分配一般关注的是对象在堆上分配的情况,对象主要分配在新生代的Eden区中,如果启用 ...
- 01_垂直居中body中的应用
1: 应用场景 在body中书写一个代码块, 使其相对于body垂直居中 <!DOCTYPE html> <html lang="en"> <head ...
- Collection 的子类 List
List集合的一些使用方法: 一. 声明集合: List<String> list = new ArrayList<String>(); 二.往集合里面添加元素 list.ad ...
- React-router路由4.0版本用法
第一步:引包两个 命令:cnpm i -S react-router react-router-dom 第二步:用路由管理APP页面 1.创建主路由管理页面,在这里使用了路由嵌套 import Rea ...
- CI框架获取post和get参数_CodeIgniter使用心得
请参考:CI文档的输入类部分: $this->input->post()$this->input->get() -------------------------------- ...
- Inception V1、V2、V3和V4
Inception模块分为V1.V2.V3和V4. V1(GoogLeNet)的介绍 论文:Going deeper with convolutions 论文链接:https://arxiv.org/ ...