Ceph 存储集群5-数据归置
一、数据归置概览
Ceph 通过 RADOS 集群动态地存储、复制和重新均衡数据对象。很多不同用户因不同目的把对象存储在不同的存储池里,而它们都坐落于无数的 OSD 之上,所以 Ceph 的运营需要些数据归置计划。 Ceph 的数据归置计划概念主要有:
存储池( Pool ): Ceph 在存储池内存储数据,它是对象存储的逻辑组;存储池管理着归置组数量、副本数量、和存储池规则集。 要往存储池里存数据,用户必须通过认证、且权限合适,存储池可做快照。详情参见存储池。 归置组( Placement Group ): Ceph 把对象映射到归置组( PG ),归置组是一逻辑对象池的片段,这些对象组团后再存入到 OSD 。 归置组减少了各对象存入对应 OSD 时的元数据数量,更多的归置组(如每 OSD 个)使得均衡更好。详情见归置组。 CRUSH 图( CRUSH Map ): CRUSH 是重要组件,它使 Ceph 能伸缩自如而没有性能瓶颈、没有扩展限制、没有单点故障,它为 CRUSH 算法提供集群的物理拓扑, 以此确定一个对象的数据及它的副本应该在哪里、怎样跨故障域存储,以提升数据安全。详情见 CRUSH 图
二、存储池
如果你开始部署集群时没有创建存储池, Ceph 会用默认存储池存数据。存储池提供的功能:
自恢复力: 你可以设置在不丢数据的前提下允许多少 OSD 失效,对多副本存储池来说,此值是一对象应达到的副本数。 典型配置存储一个对象和它的一个副本(即 size = ),但你可以更改副本数;对纠删编码的存储池来说,此值是编码块数(即纠删码配置里的 m= )。
归置组: 你可以设置一个存储池的归置组数量。典型配置给每个 OSD 分配大约 个归置组,这样,不用过多计算资源就能得到较优的均衡。 配置了多个存储池时,要考虑到这些存储池和整个集群的归置组数量要合理。
CRUSH 规则: 当你在存储池里存数据的时候,与此存储池相关联的 CRUSH 规则集可控制 CRUSH 算法, 并以此操纵集群内对象及其副本的复制(或纠删码编码的存储池里的数据块)。你可以自定义存储池的 CRUSH 规则。
快照: 用 ceph osd pool mksnap 创建快照的时候,实际上创建了某一特定存储池的快照。
设置所有者: 你可以设置一个用户 ID 为一个存储池的所有者。
要把数据组织到存储池里,你可以列出、创建、删除存储池,也可以查看每个存储池的利用率。
列出存储池
要列出集群的存储池,命令如下:
ceph osd lspools
在新安装好的集群上,只有一个 rbd 存储池。
创建存储池
创建存储池前先看看存储池、归置组和 CRUSH 配置参考。你最好在配置文件里重置默认归置组数量,因为默认值并不理想。关于归置组数量请参考设置归置组数量。
例如:
osd pool osd pool
要创建一个存储池,执行:
ceph osd pool create {pool-name} {pg-num} [{pgp-num}] [replicated] \
[crush-ruleset-name] [expected-num-objects]
ceph osd pool create {pool-name} {pg-num} {pgp-num} erasure \
[erasure-code-profile] [crush-ruleset-name] [expected_num_objects]
参数含义如下:
{pool-name}
描述: 存储池名称,必须唯一。
类型: String
是否必需: 必需。
{pg-num}
描述: 存储池拥有的归置组总数。关于如何计算合适的数值,请参见归置组。默认值 对大多数系统都不合适。
类型: 整数
是否必需: Yes
默认值:
{pgp-num}
描述: 用于归置的归置组总数。此值应该等于归置组总数,归置组分割的情况下除外。
类型: 整数
是否必需: 没指定的话读取默认值、或 Ceph 配置文件里的值。
默认值:
{replicated|erasure}
描述: 存储池类型,可以是副本(保存多份对象副本,以便从丢失的 OSD 恢复)或纠删(获得类似 RAID5 的功能)。多副本存储池需更多原始存储空间,但已实现所有 Ceph 操作;纠删存储池所需原始存储空间较少,但目前仅实现了部分 Ceph 操作。
类型: String
是否必需: No.
默认值: replicated
[crush-ruleset-name]
描述: 此存储池所用的 CRUSH 规则集名字。指定的规则集必须存在。
类型: String
是否必需: No.
默认值: 对于多副本( replicated )存储池来说,其默认规则集由 osd pool default crush replicated ruleset 配置决定,此规则集必须存在。 对于用 erasure-code 编码的纠删码( erasure )存储池来说,不同的 {pool-name} 所使用的默认( default )纠删码配置是不同的,如果它不存在的话,会显式地创建它。
[erasure-code-profile=profile]
描述: 仅用于纠删存储池。指定纠删码配置框架,此配置必须已由 osd erasure-code-profile set 定义。
类型: String
是否必需: No.
创建存储池时,要设置一个合理的归置组数量(如 )。也要考虑到每 OSD 的归置组总数,因为归置组很耗计算资源,所以很多存储池和很多归置组(如 个存储池,各包含 归置组)会导致性能下降。收益递减点取决于 OSD 主机的强大。
如何为存储池计算合适的归置组数量请参见归置组。
[expected-num-objects]
描述: 为这个存储池预估的对象数。设置此值(要同时把 filestore merge threshold 设置为负数)后,在创建存储池时就会拆分 PG 文件夹,以免运行时拆分文件夹导致延时增大。
类型: Integer
是否必需: No.
默认值: ,创建存储池时不拆分目录。
设置存储池配额
存储池配额可设置最大字节数、和/或每存储池最大对象数。
ceph osd pool set-quota {pool-name} [max_objects {obj-count}] [max_bytes {bytes}]
例如:
ceph osd pool
要取消配额,设置为 0 。
删除存储池
要删除一存储池,执行:
ceph osd pool delete {pool-name} [{pool-name} --yes-i-really-really-mean-it]
如果你给自建的存储池创建了定制的规则集,你不需要存储池时最好删除它。如果你曾严格地创建了用户及其权限给一个存储池,但存储池已不存在,最好也删除那些用户。
重命名存储池
要重命名一个存储池,执行:
ceph osd pool rename {current-pool-name} {new-pool-name}
如果重命名了一个存储池,且认证用户有每存储池能力,那你必须用新存储池名字更新用户的能力(即 caps )。
查看存储池统计信息
要查看某存储池的使用统计信息,执行命令:
rados df
拍下存储池快照
要拍下某存储池的快照,执行命令:
ceph osd pool mksnap {pool-name} {snap-name}
删除存储池快照
要删除某存储池的一个快照,执行命令:
ceph osd pool rmsnap {pool-name} {snap-name}
调整存储池选项值
要设置一个存储池的选项值,执行命令:
ceph osd pool set {pool-name} {key} {value}
你可以设置下列键的值:
size 描述: 设置存储池中的对象副本数,详情参见设置对象副本数。仅适用于副本存储池。 类型: 整数 min_size 描述: 设置 I/O 需要的最小副本数,详情参见设置对象副本数。仅适用于副本存储池。 类型: 整数 适用版本: 0.54 及以上。 crash_replay_interval 描述: 允许客户端重放确认而未提交请求的秒数。 类型: 整数 pgp_num 描述: 计算数据归置时使用的有效归置组数量。 类型: 整数 有效范围: 等于或小于 pg_num 。 crush_ruleset 描述: 集群内映射对象归置时使用的规则集。 类型: 整数 hashpspool 描述: 给指定存储池设置/取消 HASHPSPOOL 标志。 类型: 整数 有效范围: 开启, 取消 适用版本: 0.48 及以上。 nodelete 描述: 给指定存储池设置/取消 NODELETE 标志。 类型: 整数 有效范围: 开启, 取消 适用版本: Version FIXME nopgchange 描述: 给指定存储池设置/取消 NOPGCHANGE 标志。 类型: 整数 有效范围: 开启, 取消 适用版本: Version FIXME nosizechange 描述: 给指定存储池设置/取消 NOSIZECHANGE 标志。 类型: 整数 有效范围: 开启, 取消 适用版本: Version FIXME write_fadvise_dontneed 描述: 设置或取消指定存储池的 WRITE_FADVISE_DONTNEED 标志。 类型: Integer 有效范围: 开启, 取消 noscrub 描述: 设置或取消指定存储池的 NOSCRUB 标志。 类型: Integer 有效范围: 设置, 取消 nodeep-scrub 描述: 设置或取消指定存储池的 NODEEP_SCRUB 标志。 类型: Integer 有效范围: 开启, 取消 hit_set_type 描述: 启用缓存存储池的命中集跟踪,详情见 Bloom 过滤器。 类型: String 有效值: bloom, explicit_hash, explicit_object 默认值: bloom ,其它是用于测试的。 hit_set_count 描述: 为缓存存储池保留的命中集数量。此值越高, ceph-osd 守护进程消耗的内存越多。 类型: 整数 有效范围: . Agent doesn’t handle > yet. hit_set_period 描述: 为缓存存储池保留的命中集有效期。此值越高, ceph-osd 消耗的内存越多。 类型: 整数 实例: 1hr hit_set_fpp 描述: bloom 命中集类型的假阳性概率。详情见 Bloom 过滤器。 类型: Double 有效范围: 0.0 - 1.0 默认值: 0.05 cache_target_dirty_ratio 描述: 缓存存储池包含的脏对象达到多少比例时就把它们回写到后端的存储池。 类型: Double 默认值: . cache_target_dirty_high_ratio 描述: 缓存存储池内包含的已修改(脏的)对象达到此比例时,缓存层代理就会更快地把脏对象刷回到后端存储池。 类型: Double 默认值: . cache_target_full_ratio 描述: 缓存存储池包含的干净对象达到多少比例时,缓存代理就把它们赶出缓存存储池。 类型: Double 默认值: . target_max_bytes 描述: 达到 max_bytes 阀值时 Ceph 就回写或赶出对象。 类型: 整数 实例: #-TB target_max_objects 描述: 达到 max_objects 阀值时 Ceph 就回写或赶出对象。 类型: 整数 实例: #1M objects hit_set_grade_decay_rate 描述: 在两个连续 hit_sets 间的热度衰退速率。 类型: Integer 有效范围: - 默认值: hit_set_grade_search_last_n 描述: 计算热度时,在 hit_sets 里最多计数 N 次。 类型: Integer 有效范围: - hit_set_count 默认值: cache_min_flush_age 描述: 达到此时间(单位为秒)时,缓存代理就把某些对象从缓存存储池刷回到存储池。 类型: 整数 实例: 10min cache_min_evict_age 描述: 达到此时间(单位为秒)时,缓存代理就把某些对象从缓存存储池赶出。 类型: 整数 实例: 30min fast_read 描述: 在纠删码存储池上,如果打开了这个标志,读请求会向所有分片发送子操作读,然后等着,直到收到的分片足以解码给客户端。对 jerasure 和 isa 纠删码插件来说,只要前 K 个请求返回,就能立即解码、并先把这些数据发给客户端。这样有助于资源折衷,以提升性能。当前,这些标志还只能用于纠删码存储池。 类型: Boolean 默认值: scrub_min_interval 描述: 在负载低时,洗刷存储池的最大间隔秒数。如果是 ,就按照配置文件里的 osd_scrub_min_interval 。 类型: Double 默认值: scrub_max_interval 描述: 不管集群负载如何,都要洗刷存储池的最大间隔秒数。如果是 ,就按照配置文件里的 osd_scrub_max_interval 。 类型: Double 默认值: deep_scrub_interval 描述: “深度”洗刷存储池的间隔秒数。如果是 ,就按照配置文件里的 osd_deep_scrub_interval 。 类型: Double 默认值:
获取存储池选项值
要获取一个存储池的选项值,执行命令:
ceph osd pool get {pool-name} {key}
你可以获取到下列选项的值:
size 描述: 见 size 类型: 整数 min_size 描述: 见 min_size 类型: 整数 适用版本: 0.54 及以上 crash_replay_interval 描述: 见 crash_replay_interval 类型: 整数 pgp_num 描述: 见 pgp_num 类型: 整数 有效范围: 小于等于 pg_num 。 crush_ruleset 描述: 见 crush_ruleset 类型: 整数 hit_set_type 描述: 见 hit_set_type 类型: String 有效选项: bloom 、 explicit_hash 、 explicit_object hit_set_count 描述: 见 hit_set_count 类型: 整数 hit_set_period 描述: 见 hit_set_period 类型: 整数 hit_set_fpp 描述: 见 hit_set_fpp 类型: Double cache_target_dirty_ratio 描述: 见 cache_target_dirty_ratio 类型: Double cache_target_dirty_high_ratio 描述: 见 cache_target_dirty_high_ratio 类型: Double cache_target_full_ratio 描述: 见 cache_target_full_ratio 类型: Double target_max_bytes 描述: 见 target_max_bytes 类型: 整数 target_max_objects 描述: 见 target_max_objects 类型: 整数 cache_min_flush_age 描述: 见 cache_min_flush_age 类型: 整数 cache_min_evict_age 描述: 见 cache_min_evict_age 类型: 整数 fast_read 描述: 见 fast_read 类型: Boolean scrub_min_interval 描述: 见 scrub_min_interval 类型: Double scrub_max_interval 描述: 见 scrub_max_interval 类型: Double deep_scrub_interval 描述: 见 deep_scrub_interval 类型: Double
设置对象副本数
要设置多副本存储池的对象副本数,执行命令:
ceph osd pool set {poolname} size {num-replicas}
注意:{num-replicas} 包括对象自身,如果你想要对象自身及其两份拷贝共计三份,指定 3。
例如:
ceph osd pool
你可以在每个存储池上执行这个命令。注意,一个处于降级模式的对象其副本数小于规定值 pool size ,但仍可接受 I/O 请求。为保证 I/O 正常,可用 min_size 选项为其设置个最低副本数。例如:
ceph osd pool
这确保数据存储池里任何副本数小于 min_size 的对象都不会收到 I/O 了。
获取对象副本数
要获取对象副本数,执行命令:
ceph osd dump | grep 'replicated size'
Ceph 会列出存储池,且高亮 replicated size 属性。默认情况下, Ceph 会创建一对象的两个副本(一共三个副本,或 size 值为 3 )
三、分级缓存
分级缓存可提升后端存储内某些(热点)数据的 I/O 性能。分级缓存需创建一个由高速而昂贵存储设备(如 SSD )组成的存储池、作为缓存层,以及一个相对低速/廉价设备组成的后端存储池(或纠删码编码的)、作为经济存储层。 Ceph 的对象处理器决定往哪里存储对象,分级代理决定何时把缓存内的对象刷回后端存储层;所以缓存层和后端存储层对 Ceph 客户端来说是完全透明的
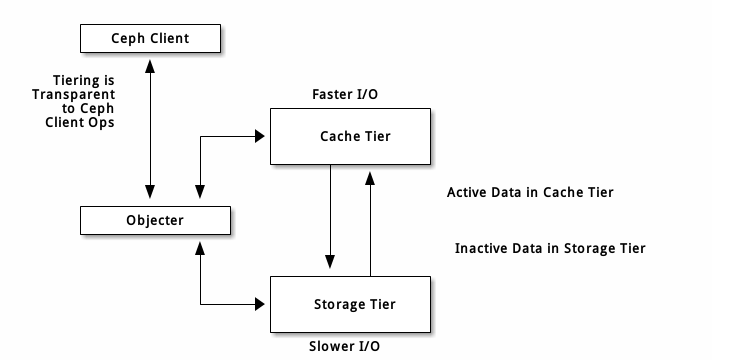
缓存层代理自动处理缓存层和后端存储之间的数据迁移。然而,管理员仍可干预此迁移规则,主要有两种场景:
回写模式: 管理员把缓存层配置为 writeback 模式时, Ceph 客户端们会把数据写入缓存层、并收到缓存层发来的 ACK ; 写入缓存层的数据会被迁移到存储层、然后从缓存层刷掉。直观地看,缓存层位于后端存储层的“前面”,当 Ceph 客户端要读取的数据位于存储层时, 缓存层代理会把这些数据迁移到缓存层,然后再发往 Ceph 客户端。从此, Ceph 客户端将与缓存层进行 I/O 操作,直到数据不再被读写。 此模式对于易变数据来说较理想(如照片/视频编辑、事务数据等)。 只读模式: 管理员把缓存层配置为 readonly 模式时, Ceph 直接把数据写入后端。读取时, Ceph 把相应对象从后端复制到缓存层, 根据已定义策略、脏对象会被缓存层踢出。此模式适合不变数据(如社交网络上展示的图片/视频、 DNA 数据、 X-Ray 照片等), 因为从缓存层读出的数据可能包含过期数据,即一致性较差。对易变数据不要用 readonly 模式。
正因为所有 Ceph 客户端都能用缓存层,所以才有提升块设备、 Ceph 对象存储、 Ceph 文件系统和原生绑定的 I/O 性能的潜力。
配置存储池
要设置缓存层,你必须有两个存储池。一个作为后端存储、另一个作为缓存。
配置后端存储池
设置后端存储池通常会遇到两种场景:
标准存储: 此时,Ceph存储集群内的存储池保存了一对象的多个副本; 纠删存储池: 此时,存储池用纠删码高效地存储数据,性能稍有损失。
在标准存储场景中,你可以用 CRUSH 规则集来标识失败域(如 osd 、主机、机箱、机架、排等)。
当规则集所涉及的所有驱动器规格、速度(转速和吞吐量)和类型相同时, OSD 守护进程运行得最优。
创建规则集的详情见 CRUSH 图。创建好规则集后,再创建后端存储池。
在纠删码编码情景中,创建存储池时指定好参数就会自动生成合适的规则集,详情见创建存储池。
在后续例子中,我们把 cold-storage 当作后端存储池。
配置缓存池
缓存存储池的设置步骤大致与标准存储情景相同,但仍有不同:缓存层所用的驱动器通常都是高性能的、且安装在专用服务器上、有自己的规则集。制定规则集时,要考虑到装有高性能驱动器的主机、并忽略没有的主机。详情见给存储池指定 OSD 。
在后续例子中, hot-storage 作为缓存存储池、 cold-storage 作为后端存储池。
关于缓存层的配置及其默认值的详细解释请参考存储池——调整存储池。
创建缓存层
设置一缓存层需把缓存存储池挂接到后端存储池上:
ceph osd tier add {storagepool} {cachepool}
例如:
ceph osd tier add cold-storage hot-storage
用下列命令设置缓存模式:
ceph osd tier cache-mode {cachepool} {cache-mode}
例如:
ceph osd tier cache-mode hot-storage writeback
缓存层盖在后端存储层之上,所以要多一步:必须把所有客户端流量从存储池迁移到缓存存储池。用此命令把客户端流量指向缓存存储池:
ceph osd tier set-overlay {storagepool} {cachepool}
例如:
ceph osd tier set-overlay cold-storage hot-storage
配置缓存层
缓存层支持几个配置选项,可按下列语法配置:
ceph osd pool set {cachepool} {key} {value}
目标尺寸和类型
生产环境下,缓存层的 hit_set_type 还只能用 Bloom 过滤器:
ceph osd pool set {cachepool} hit_set_type bloom
例如:
ceph osd pool set hot-storage hit_set_type bloom
hit_set_count 和 hit_set_period 选项分别定义了 HitSet 覆盖的时间区间、以及保留多少个这样的 HitSet 。
ceph osd pool ceph osd pool ceph osd pool
保留一段时间以来的访问记录,这样 Ceph 就能判断一客户端在一段时间内访问了某对象一次、还是多次(存活期与热度)。
min_read_recency_for_promote 定义了在处理一个对象的读操作时检查多少个 HitSet ,检查结果将用于决定是否异步地提升对象。
它的取值应该在 0 和 hit_set_count 之间,如果设置为 0 ,对象会一直被提升;
如果设置为 1 ,就只检查当前 HitSet ,如果此对象在当前 HitSet 里就提升它,否则就不提升;
设置为其它值时,就要挨个检查此数量的历史 HitSet ,如果此对象出现在 min_read_recency_for_promote 个 HitSet 里的任意一个,那就提升它。
还有一个相似的参数用于配置写操作,它是 min_write_recency_for_promote 。
ceph osd pool ceph osd pool
注意:统计时间越长、 min_read_recency_for_promote 或 min_write_recency_for_promote 取值越高, ceph-osd 进程消耗的内存就越多,特别是代理正忙着刷回或赶出对象时,此时所有 hit_set_count 个 HitSet 都要载入内存。
缓存空间消长
缓存分层代理有两个主要功能:
刷回: 代理找出修改过(或脏)的对象、并把它们转发给存储池做长期存储。 赶出: 代理找出未修改(或干净)的对象、并把最近未用过的赶出缓存。
相对空间消长
缓存分层代理可根据缓存存储池相对大小刷回或赶出对象。当缓存池包含的已修改(或脏)对象达到一定比例时,缓存分层代理就把它们刷回到存储池。用下列命令设置 cache_target_dirty_ratio :
ceph osd pool set {cachepool} cache_target_dirty_ratio {0.0..1.0}
例如,设置为 0.4 时,脏对象达到缓存池容量的 40% 就开始刷回:
ceph osd pool set hot-storage cache_target_dirty_ratio 0.4
当脏对象达到其容量的一定比例时,要更快地刷回脏对象。用下列命令设置 cache_target_dirty_high_ratio:
ceph osd pool set {cachepool} cache_target_dirty_high_ratio {0.0..1.0}
例如,设置为 0.6 表示:脏对象达到缓存存储池容量的 60% 时,将开始更激进地刷回脏对象。显然,其值最好在 dirty_ratio 和 full_ratio 之间:
ceph osd pool set hot-storage cache_target_dirty_high_ratio 0.6
当缓存池利用率达到总容量的一定比例时,缓存分层代理会赶出部分对象以维持空闲空间。执行此命令设置 cache_target_full_ratio :
ceph osd pool set {cachepool} cache_target_full_ratio {0.0..1.0}
例如,设置为 0.8 时,干净对象占到总容量的 80% 就开始赶出缓存池:
ceph osd pool set hot-storage cache_target_full_ratio 0.8
绝对空间消长
缓存分层代理可根据总字节数或对象数量来刷回或赶出对象,用下列命令可指定最大字节数:
ceph osd pool set {cachepool} target_max_bytes {#bytes}
例如,用下列命令配置在达到 1TB 时刷回或赶出:
ceph osd pool
用下列命令指定缓存对象的最大数量:
ceph osd pool set {cachepool} target_max_objects {#objects}
例如,用下列命令配置对象数量达到 1M 时开始刷回或赶出:
ceph osd pool
注意:如果两个都配置了,缓存分层代理会按先到的阀值执行刷回或赶出。
缓存时长
你可以规定缓存层代理必须延迟多久才能把某个已修改(脏)对象刷回后端存储池:
ceph osd pool set {cachepool} cache_min_flush_age {#seconds}
例如,让已修改(或脏)对象需至少延迟 10 分钟才能刷回,执行此命令:
ceph osd pool
你可以指定某对象在缓存层至少放置多长时间才能被赶出:
ceph osd pool {cache-tier} cache_min_evict_age {#seconds}
例如,要规定 30 分钟后才赶出对象,执行此命令:
ceph osd pool
拆除缓存层
回写缓存和只读缓存的去除过程不太一样。
拆除只读缓存
只读缓存不含变更数据,所以禁用它不会导致任何近期更改的数据丢失。
1.把缓存模式改为 none 即可禁用。
ceph osd tier cache-mode {cachepool} none
例如:
ceph osd tier cache-mode hot-storage none
2.去除后端存储池的缓存池。
ceph osd tier remove {storagepool} {cachepool}
例如:
ceph osd tier remove cold-storage hot-storage
拆除回写缓存
回写缓存可能含有更改过的数据,所以在禁用并去除前,必须采取些手段以免丢失缓存内近期更改的对象。
1.把缓存模式改为 forward ,这样新的和更改过的对象将直接刷回到后端存储池。
ceph osd tier cache-mode {cachepool} forward
例如:
ceph osd tier cache-mode hot-storage forward
2.确保缓存池已刷回,可能要等数分钟:
rados -p {cachepool} ls
如果缓存池还有对象,你可以手动刷回,例如:
rados -p {cachepool} cache-flush-evict-all
3. 去除此盖子,这样客户端就不会被指到缓存了。
ceph osd tier remove-overlay {storagetier}
例如:
ceph osd tier remove-overlay cold-storage
4.最后,从后端存储池剥离缓存层存储池。
ceph osd tier remove {storagepool} {cachepool}
例如:
ceph osd tier remove cold-storage hot-storage
四、归置组
预定义 pg_num
用此命令创建存储池时:
ceph osd pool create {pool-name} pg_num
确定 pg_num 取值是强制性的,因为不能自动计算。下面是几个常用的值:
1.少于 个 OSD 时可把 pg_num 设置为 2.OSD 数量在 到 个时,可把 pg_num 设置为 3.OSD 数量在 到 个时,可把 pg_num 设置为 4.OSD 数量大于 时,你得理解权衡方法、以及如何自己计算 pg_num 取值 5.自己计算 pg_num 取值时可借助 pgcalc 工具
随着 OSD 数量的增加,正确的 pg_num 取值变得更加重要,因为它显著地影响着集群的行为、以及出错时的数据持久性(即灾难性事件导致数据丢失的概率)。
归置组是如何使用的
存储池内的归置组( PG )把对象汇聚在一起,因为跟踪每一个对象的位置及其元数据需要大量计算——即一个拥有数百万对象的系统,不可能在对象这一级追踪位置。
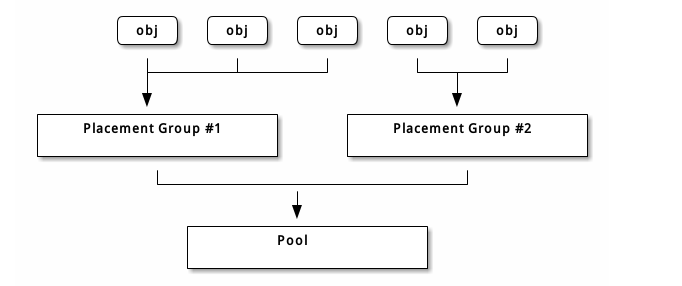
Ceph 客户端会计算某一对象应该位于哪个归置组里,它是这样实现的,先给对象 ID 做哈希操作,然后再根据指定存储池里的 PG 数量、存储池 ID 做一个运算。
详情见 PG 映射到 OSD。

注释:
1.如果 osd #2 失败, 另一个将被分配到放置组 #1 并将在 osd #1 中填充所有对象的副本。
2.如果将池大小从两个更改为三, 将为放置组分配一个额外的 OSD, 并将接收放置组中所有对象的副本。
3.放置组不拥有 OSD, 它们与来自同一池甚至其他池的其他放置组共享它。如果 osd #2 失败, 则放置组 #2 还必须使用 osd #3 还原对象的副本。
4.当放置组的数量增加时, 新的放置组将被分配操作系统。粉碎功能的结果也会改变, 一些来自前置组的物体将被复制到新的放置组中, 并从旧的位置上移除。
放置组权衡
数据的耐用性, 甚至在所有OSD的分布调用更多的放置组, 但他们的数量应该减少到最低, 以节省 CPU 和内存。
数据耐久性
在 OSD 失败后, 数据丢失的风险会增加, 直到它所包含的数据完全恢复。让我们设想一个在单个放置组中导致永久数据丢失的方案:
1.OSD 失败, 它所包含的对象的所有副本都将丢失。对于放置组中的所有对象, 复制突然的数量从三下降到2。2.Ceph 通过选取新的 OSD 来重新创建所有对象的第三个副本, 从而开始恢复此放置组3.在同一位置组中的另一个 osd 在新 osd 完全填充第三个副本之前失败。有些对象只会有一个幸存的副本。4.Ceph 选择另一个 OSD, 并不断复制对象, 以恢复所需的副本数。5.在相同的放置组中, 第三个 OSD 在恢复完成之前失败。如果此 OSD 包含对象的唯一剩余副本, 则它将永久丢失。
在群集中,三副本池中包含 10 OSD 和512放置组,CRUSH将给每个放置组三个 OSD。最后, 每个 OSD 将最后出于托管 (512 * 3)/10 = 〜150放置组。当第一个 OSD 失败时, 上述方案将同时启动所有150位置组的恢复。
150个放置组很可能是均匀地传播在9剩余的 OSD被恢复。因此, 每个剩余的 OSD 都可能将对象的副本发送给所有其他osd, 并且还会接收一些新的对象来存储, 因为它们成为新的放置组的一部分。
完成此恢复所需的时间完全取决于 Ceph 群集的体系结构。让我们说, 每个 osd 由一个1TB 固态硬盘托管在一台机器上, 所有这些都连接到一个 10 gb/s 交换机和恢复为一个单一的 osd 完成在 M 分钟内。如果每台机器有两个操作系统, 并且没有 SSD 日志和 1 gb/s 开关, 那么它至少会有一个数量级的慢速。
在这种规模的集群中, 放置组的数量对数据的耐久性几乎没有影响。它可能是128或 8192, 恢复不会慢或快。
但是, 将相同的 Ceph 群集增加到 20 osd 而不是 10 osd, 可能会加速恢复, 从而显著提高数据的耐久性。每个 osd 现在只参与 ~ 75 放置组, 而不是〜 150, 当只有 10 osd, 它仍然需要所有19剩余的操作系统执行相同数量的对象副本, 以恢复。但是, 10 OSD 必须复制大约100GB 每个, 他们现在必须复制 50GB, 而不是。如果网络是瓶颈, 恢复的速度将会加倍。换言之, 当操作系统的数量增加时, 恢复速度会更快。
如果这个集群增长到 40 OSD, 他们中的每个将只托管〜35的位置组。如果 OSD 死了, 恢复将保持更快, 除非它被另一个瓶颈阻止。但是, 如果这个集群增长到 200 OSD, 他们中的每一个只会托管〜7的位置组。如果 osd 死亡, 恢复将在这些位置组中的 21 (7 * 3) osd 之间发生: 恢复的时间比 40 osd 时要长, 这意味着应增加放置组的数量。
不论恢复时间有多短,在此期间都可能有第二个 OSD 失败。在前述的有 10 个 OSD 的集群中,不管哪个失败了,都有大约 17 个归置组(即需恢复的大约 150 / 9 个归置组)将只有一份可用副本;并且假设剩余的 8 个 OSD 中任意一个失败,两个归置组中最后的对象都有可能丢失(即正在恢复的、大约 17 / 8 个仅剩一个副本的归置组)。
当集群大小变为 20 个 OSD 时, 3 个 OSD 丢失导致的归置组损坏会降低。第二个 OSD 丢失会降级大约 4 个(即需恢复的归置组约为 75 / 19 )而不是约 17 个归置组,并且只有当第三个 OSD 恰好是包含可用副本的四分之一个 OSD 时、才会丢失数据。换句话说,假设在恢复期间丢失一个 OSD 的概率是 0.0001% ,那么,在包含 10 个 OSD 的集群中丢失 OSD 的概率是 17 * 10 * 0.0001% ,而在 20 个 OSD 的集群中将是 4 * 20 * 0.0001% 。
简而言之, 更多的 OSD 意味着更快的恢复和较低的连锁失败风险导致了一个位置组的永久性损失。在数据耐久性方面, 有512或4096的放置组大致相当于一个少于 50 OSD 的群集中。简而言之, 更多的 OSD 意味着更快的恢复和较低的连锁失败风险导致了一个位置组的永久性损失。在数据耐久性方面, 有512或4096的放置组大致相当于一个少于 50 OSD 的群集中。
注意: 添加到群集中的新 OSD 可能需要很长时间才能填充分配给它的放置组。但是, 没有任何对象的退化, 它对集群中所包含的数据的耐久性没有影响。
池中的对象分布
理论上对象在每个放置组中均匀分布。由于CRUSH计算每个对象的放置组, 但实际上并不知道在这个放置组中每个 osd 中存储了多少数据, 因此, 放置组数与 osd 数之间的比率可能会影响数据的分布显著.
例如, 如果在三复制池中有一个十 osd 的单个放置组, 则只有3个osd会被使用, 因为粉碎将没有其他选择。当有更多的放置组可用时, 对象更有可能均匀地分布在其中。CRUSH还尽一切努力均匀地传播 OSD 在所有现有的放置组。
只要放置组比 OSD多一个或两个数量级或更多, 分配应该是均匀的。
不均匀的数据分布可能是由 OSD 和放置组之间的比率以外的因素造成的。由于CRUSH没有考虑到物体的大小, 一些非常大的物体可能造成不平衡。100万4K 对象共计4GB 均匀地分布在1000安置小组在 10 OSD。他们将使用 4GB/10 = 400MB 在每个 OSD。如果将一个400MB 对象添加到池中, 则支持在其中放置对象的位置组的三 OSD 将用 400MB + 400MB = 800MB 填充, 而其余七个则只保留400MB。
内存、处理器和网络使用情况
各个归置组、 OSD 和监视器都一直需要内存、网络、处理器,在恢复期间需求更大。为消除过载而把对象聚集成簇是归置组存在的主要原因。
最小化归置组数量可节省不少资源。
确定归置组数量
如果你有超过50的 osd, 我们建议每 osd 约50-100 放置组, 以平衡资源的使用, 数据的耐久性和分布。如果你有少于50的 OSD, 在预选中进行拣选是最好的。对于单个对象池, 可以使用以下公式获取基线:
(OSDs * )
Total PGs = ------------
pool size
其中, 池大小是复制池的副本数, 也可以是用于擦除编码池的 K + M 总和 (由 ceph osd 擦除码配置文件返回)。
然后, 您应该检查该结果是否与您设计的 Ceph 群集的方式有意义, 以最大限度地提高数据的耐久性、对象分布和最大限度地减少资源使用。
其结果汇总后应该接近 2 的幂。汇总并非强制的,如果你想确保所有归置组内的对象数大致相等,最好检查下。
比如,一个配置了 200 个 OSD 且副本数为 3 的集群,你可以这样估算归置组数量:
( * )
----------- = . Nearest power of :
当用了多个数据存储池来存储数据时,你得确保均衡每个存储池的归置组数量、且归置组数量分摊到每个 OSD ,这样才能达到较合理的归置组总量,并因此使得每个 OSD 无需耗费过多系统资源或拖慢连接进程就能实现较小变迁。
例如, 在一个有10个池的集群中,10个 osd 组有512个放置组, 总共有5120个放置组。它不会使用太多的资源。但是, 如果创建了1000池, 每组有512个放置小组, 则 OSD 将处理5万个放置组, 并且需要大量的资源和时间来进行对等操作。
设置归置组数量
要设置某存储池的归置组数量,你必须在创建它时就指定好,详情见创建存储池。一存储池的归置组数量设置好之后,还可以增加(但不可以减少),下列命令可增加归置组数量:
ceph osd pool set {pool-name} pg_num {pg_num}
你增加归置组数量后、还必须增加用于归置的归置组( pgp_num )数量,这样才会开始重均衡。 pgp_num 数值才是 CRUSH 算法采用的用于归置的归置组数量。虽然 pg_num 的增加引起了归置组的分割,但是只有当用于归置的归置组(即 pgp_num )增加以后,数据才会被迁移到新归置组里。 pgp_num 的数值应等于 pg_num 。可用下列命令增加用于归置的归置组数量:
ceph osd pool set {pool-name} pgp_num {pgp_num}
获取归置组数量
要获取一个存储池的归置组数量,执行命令:
ceph osd pool get {pool-name} pg_num
获取归置组统计信息
要获取集群里归置组的统计信息,执行命令:
ceph pg dump [--format {format}]
可用格式有纯文本 plain (默认)和 json 。
获取卡住的归置组统计信息
要获取所有卡在某状态的归置组统计信息,执行命令:
ceph pg dump_stuck inactive|unclean|stale|undersized|degraded [--format <format>] [-t|--threshold <seconds>]
Inactive (不活跃)归置组不能处理读写,因为它们在等待一个有最新数据的 OSD 复活且进入集群。
Unclean (不干净)归置组含有复制数未达到期望数量的对象,它们应该在恢复中。
Stale (不新鲜)归置组处于未知状态:存储它们的 OSD 有段时间没向监视器报告了(由 mon_osd_report_timeout 配置)。
可用格式有 plain (默认)和 json 。阀值定义的是,归置组被认为卡住前等待的最小时间(默认 300 秒)。
获取一归置组运行图
要获取一个具体归置组的归置组图,执行命令:
ceph pg map {pg-id}
例如:
ceph pg map .6c
Ceph 将返回归置组图、归置组、和 OSD 状态:
osdmap e13 pg .6c (.6c) -> up [,] acting [,]
获取一 PG 的统计信息
要查看一个具体归置组的统计信息,执行命令:
ceph pg {pg-id} query
洗刷归置组
要洗刷一个归置组,执行命令:
ceph pg scrub {pg-id}
Ceph 检查原始的和任何复制节点,生成归置组里所有对象的目录,然后再对比,确保没有对象丢失或不匹配,并且它们的内容一致。
恢复丢失的
如果集群丢了一或多个对象,而且必须放弃搜索这些数据,你就要把未找到的对象标记为丢失( lost )。
如果所有可能的位置都查询过了,而仍找不到这些对象,你也许得放弃它们了。这可能是罕见的失败组合导致的,集群在写入完成前,未能得知写入是否已执行。
当前只支持 revert 选项,它使得回滚到对象的前一个版本(如果它是新对象)或完全忽略它。要把 unfound 对象标记为 lost ,执行命令:
ceph pg {pg-id} mark_unfound_lost revert|delete
注意:要谨慎使用,它可能迷惑那些期望对象存在的应用程序。
归置组状态
检查集群状态时(如运行 ceph -s 或 ceph -w ), Ceph 会报告归置组状态。一个归置组有一到多种状态,其最优状态为 active+clean 。
Creating:Ceph 仍在创建归置组。 Active:Ceph 可处理到归置组的请求。 Clean:Ceph 把归置组内的对象复制了规定次数。 Down:包含必备数据的副本挂了,所以归置组离线。 Replay:某 OSD 崩溃后,归置组在等待客户端重放操作。 Splitting:Ceph 正在把一归置组分割为多个。(实现了?) Scrubbing:Ceph 正在检查归置组的一致性。 Degraded:归置组内的对象还没复制到规定次数。 Inconsistent:Ceph 检测到了归置组内一或多个副本间不一致(如各对象大小不一、恢复后对象还没复制到副本那里、等等)。 Peering:归置组正在互联。 Repair:Ceph 正在检查归置组、并试图修复发现的不一致(如果可能的话)。 Recovering:Ceph 正在迁移/同步对象及其副本。 Backfill :Ceph 正在扫描并同步整个归置组的内容,而不是根据日志推算哪些最新操作需要同步。 Backfill 是恢复的一种特殊情况。 Wait-backfill:归置组正在排队,等候回填。 Backfill-toofull:回填操作在等待,因为目标 OSD 使用率超过了占满率。 Incomplete:Ceph 探测到某一归置组可能丢失了写入信息,或者没有健康的副本。如果你看到了这个状态,试着启动一下有可能包含所需信息的失败 OSD 、或者临时调整一下 min_size 以完成恢复。 Stale:归置组处于一种未知状态——从归置组运行图变更起就没再收到它的更新。 Remapped:归置组被临时映射到了另外一组 OSD ,它们不是 CRUSH 算法指定的。 Undersized:此归置组的副本数小于配置的存储池副本水平。 Peered:此归置组已互联,但是不能向客户端提供服务,因为其副本数没达到本存储池的配置值( min_size 参数)。在此状态下可以进行恢复,所以此归置组最终能达到 min_size 。
归置组术语解释
当你执行诸如 ceph -w 、 ceph osd dump 、及其他和归置组相关的命令时, Ceph 会返回下列术语及其值:
Peering:(建立互联) 是一种过程,它使得存储着同一归置组的所有 OSD 对归置组内的所有对象及其元数据统一意见。需要注意的是,达成一致不意味着它们都有最新内容。
Acting Set:(在任集合) 一列有序 OSD ,它们为某一特定归置组(或其中一些元版本)负责。
Up Set:The ordered list of OSDs responsible for a particular placement group for a particular epoch according to CRUSH. Normally this is the same as the Acting Set, except when the Acting Set has been explicitly overridden via pg_temp in the OSD Map.
[译者:此处原文没看懂……瞎译如下] (当选集合) 一列有序 OSD ,它们依据 CRUSH 算法为某一归置组的特定元版本负责。它通常和 Acting Set 相同, 除非 Acting Set 被 OSD 运行图里的 pg_temp 显式地覆盖掉了。
Current Interval 或 Past Interval: 某一特定归置组所在 Acting Set 和 Up Set 未更改时的一系列 OSD 运行图元版本。
Primary: (主 OSD ) Acting Set 的成员(按惯例第一个),它负责协调互联,并且是归置组内惟一接受客户端初始写入的 OSD 。
Replica:(副本 OSD ) 一归置组的 Acting Set 内不是主 OSD 的其它 OSD ,它们被同等对待、并由主 OSD 激活。
Stray:(彷徨 OSD ) 某一 OSD ,它不再是当前 Acting Set 的成员,但还没被告知它可以删除那个归置组副本。
Recovery:(恢复) 确保 Acting Set 内、一归置组中的所有对象的副本都存在于所有 OSD 上。一旦互联完成,主 OSD 就以接受写操作,且恢复进程可在后台进行。
PG Info:Basic metadata about the placement group’s creation epoch, the version for the most recent write to the placement group, last epoch started, last epoch clean, and the beginning of the current interval. Any inter-OSD communication about placement groups includes the PG Info, such that any OSD that knows a placement group exists (or once existed) also has a lower bound on last epoch clean or last epoch started.
(归置组信息) [译者:此处原文没看透……瞎译如下] 基本元数据, 关于归置组创建元版本、向归置组的最新写版本、最近的开始元版本( last epoch started )、最近的干净元版本( last epoch clean )、 和当前间隔( current interval )的起点。 OSD 间关于归置组的任何通讯都包含 PG Info , 这样任何知道一归置组存在(或曾经存在)的 OSD 也必定有 last epoch clean 或 last epoch started 的下限。
PG Log:(归置组日志) 一归置组内对象的一系列最近更新。注意,这些日志在 Acting Set 内的所有 OSD 确认更新到某点后可以删除。
Missing Set:(缺失集合) 各 OSD 都记录更新日志,而且如果它们包含对象内容的更新,会把那个对象加入一个待更新列表, 这个列表叫做那个 <OSD,PG> 的 Missing Set 。
Authoritative History:(权威历史) 一个完整、完全有序的操作集合,如果再次执行,可把一 OSD 上的归置组副本还原到最新。
Epoch:(元版本) 单递增 OSD 运行图版本号。
Last Epoch Start:(最新起始元版本) 一最新元版本,在这点上,一归置组所对应 Acting Set 内的所有节点都对权威历史达成了一致、并且互联被认为成功了。
up_thru:(领导拍板) 主 OSD 要想成功完成互联,它必须通过当前 OSD 图元版本通知一个监视器,让此监视器在 osd 图中设置其 up_thru 。这会使互联进程忽略之前的 Acting Set ,因为它经历特定顺序的失败后一直不能互联,比如像下面的第二周期:
acting set = [A,B]
acting set = [A]
acting set = [] 之后很短时间(例如同时失败、但探测是交叉的)
acting set = [B] ( B 重启了、但 A 没有)
Last Epoch Clean:(最新干净元版本) 最近的 Epoch ,这时某一特定归置组所在 Acting Set 内的所有节点都全部更新了(包括归置组日志和对象内容)。在这点上,恢复被认为已完成。
五、CRUSH 图
CRUSH 算法通过计算数据存储位置来确定如何存储和检索。 CRUSH 授权 Ceph 客户端直接连接 OSD ,而非通过一个中央服务器或经纪人。数据存储、检索算法的使用,使 Ceph 避免了单点故障、性能瓶颈、和伸缩的物理限制。
CRUSH 需要一张集群的地图,且使用 CRUSH 把数据伪随机地存储、检索于整个集群的 OSD 里。 CRUSH 的讨论详情参见 CRUSH - 可控、可伸缩、分布式地归置多副本数据 。
CRUSH 图包含 OSD 列表、把设备汇聚为物理位置的“桶”列表、和指示 CRUSH 如何复制存储池里的数据的规则列表。由于对所安装底层物理组织的表达, CRUSH 能模型化、并因此定位到潜在的相关失败设备源头,典型的源头有物理距离、共享电源、和共享网络,把这些信息编码到集群运行图里, CRUSH 归置策略可把对象副本分离到不同的失败域,却仍能保持期望的分布。例如,要定位同时失败的可能性,可能希望保证数据复制到的设备位于不同机架、不同托盘、不同电源、不同控制器、甚至不同物理位置。
当你写好配置文件,用 ceph-deploy 部署 Ceph 后,它生成了一个默认的 CRUSH 图,对于你的沙盒环境来说它很好。然而,部署一个大规模数据集群的时候,应该好好设计自己的 CRUSH 图,因为它帮你管理 Ceph 集群、提升性能、和保证数据安全性。
例如,如果一个 OSD 挂了, CRUSH 图可帮你定位此事件中 OSD 所在主机的物理数据中心、房间、行和机架,据此你可以请求在线支持或替换硬件。
类似地, CRUSH 可帮你更快地找出问题。例如,如果一个机架上的所有 OSD 同时挂了,问题可能在于机架的交换机或电源,而非 OSD 本身。
定制的 CRUSH 图也能在归置组降级时,帮你找出冗余副本所在主机的物理位置。
CRUSH 位置
用 CRUSH 图层次结构所表示的 OSD 位置被称为“ crush 位置”,它用键/值对列表来表示。例如,一 OSD 位于某特定行、机柜、机架、和主机,且是 CRUSH 图里名为 default 树的一部分,那么其 crush 位置可表示如下:
root=default row=a rack=a2 chassis=a2a host=a2a1
注:
1.注意键(关键词)与顺序无关; 2.键名( = 左边)必须是 CRUSH 内的合法 type ,默认情况下, 它包含 root 、 datacenter 、 room 、 row 、 pod 、 pdu 、 rack 、 chassis 、和 host ,但这些类型可修改 CRUSH 图任意定义。 3.并非所有键都需指定,例如,默认情况下 Ceph 会自动把 ceph-osd 守护进程的位置设置为 root=default host=HOSTNAME (即是 hostname -s )。
ceph-crush-location 挂钩
ceph-crush-location 工具可为某守护进程生成默认 CRUSH 位置字符串,此位置依次基于:
ceph.conf 里的 TYPE crush location ,例如这是 OSD 守护进程的: osd crush location ; ceph.conf 里的 crush location ; 默认的 root=default host=HOSTNAME ,其中主机名由 hostname -s 获取
典型部署场景下,部署软件(或系统管理员)会在此主机的 ceph.conf 配置文件里设置 crush location 域来描述此机器在数据中心或集群内的位置。这样 Ceph 守护进程和客户端就能提供基于位置的服务。
完全手动管理 CRUSH 图也是可能的,在配置中把挂钩关掉即可:
osd crush update on start = false
定制位置挂钩
定制化位置挂钩可代替通用挂钩,用于控制 OSD 在分级结构中的位置(启动时,各 OSD 都确认它们的位置正确无误):
osd crush location hook = /path/to/script
此挂钩应该接受几个参数(下述)并向标准输出打印一行 CRUSH 位置描述:
$ ceph-crush-location --cluster CLUSTER --id ID --type TYPE
其中,集群名通常是 ceph , id 是守护进程标识符( OSD 号),守护进程类型通常是 osd 。
编辑 CRUSH 图
要编辑现有的 CRUSH 图:
获取 CRUSH 图; 反编译 CRUSH 图; 至少编辑一个设备、桶、规则; 重编译 CRUSH 图; 注入 CRUSH 图
要激活 CRUSH 图里某存储池的规则,找到通用规则集编号,然后把它指定到那个规则集。详情参见调整存储池。
获取 CRUSH 图
要获取集群的 CRUSH 图,执行命令:
ceph osd getcrushmap -o {compiled-crushmap-filename}
Ceph 将把 CRUSH 输出( -o )到你指定的文件,由于 CRUSH 图是已编译的,所以编辑前必须先反编译。
反编译 CRUSH 图
要反编译 CRUSH 图,执行命令:
crushtool -d {compiled-crushmap-filename} -o {decompiled-crushmap-filename}
Ceph 将反编译( -d )二进制 CRUSH 图,且输出( -o )到你指定的文件。
编译 CRUSH 图
要编译 CRUSH 图,执行命令:
crushtool -c {decompiled-crush-map-filename} -o {compiled-crush-map-filename}
Ceph 将把已编译的 CRUSH 图保存到你指定的文件。
注入 CRUSH 图
要把 CRUSH 图应用到集群,执行命令:
ceph osd setcrushmap -i {compiled-crushmap-filename}
Ceph 将把你指定的已编译 CRUSH 图输入到集群。
CRUSH 图参数
CRUSH 图主要有 4 个主要段落。
1.设备: 由任意对象存储设备组成,即对应一个 ceph-osd 进程的存储器。 Ceph 配置文件里的每个 OSD 都应该有一个设备。 2.桶类型: 定义了 CRUSH 分级结构里要用的桶类型( types ),桶由逐级汇聚的存储位置(如行、机柜、机箱、主机等等)及其权重组成。 3.桶例程: 定义了桶类型后,还必须声明主机的桶类型、以及规划的其它故障域。 4.规则: 由选择桶的方法组成。
如果你用我们的某个“入门手册”配起了 Ceph ,应该注意到了,你并不需要创建 CRUSH 图。 Ceph 部署工具生成了默认 CRUSH 运行图,它列出了你定义在 Ceph 配置文件中的 OSD 设备、并把配置文件 [osd] 段下定义的各 OSD 主机声明为桶。为保证数据安全和可用,你应该创建自己的 CRUSH 图,以反映出自己集群的故障域。
注意:生成的 CRUSH 图没考虑大粒度故障域,所以你修改 CRUSH 图时要考虑上,像机柜、行、数据中心
CRUSH 图之设备
为把归置组映射到 OSD , CRUSH 图需要 OSD 列表(即配置文件所定义的 OSD 守护进程名称),所以它们首先出现在 CRUSH 图里。要在 CRUSH 图里声明一个设备,在设备列表后面新建一行,输入 device 、之后是唯一的数字 ID 、之后是相应的 ceph-osd 守护进程例程名字。
#devices
device {num} {osd.name}
例如:
#devices device osd. device osd. device osd. device osd.
一般来说,一个 OSD 映射到一个单独的硬盘或 RAID 。
CRUSH 图之桶类型
CRUSH 图里的第二个列表定义了 bucket (桶)类型,桶简化了节点和叶子层次。节点(或非叶子)桶在分级结构里一般表示物理位置,节点汇聚了其它节点或叶子,叶桶表示 ceph-osd 守护进程及其对应的存储媒体。
注意:CRUSH 中用到的 bucket 意思是分级结构中的一个节点,也就是一个位置或一部分硬件。但是在 RADOS 网关接口的术语中,它又是不同的概念
要往 CRUSH 图中增加一种 bucket 类型,在现有桶类型列表下方新增一行,输入 type 、之后是惟一数字 ID 和一个桶名。按惯例,会有一个叶子桶为 type 0 ,然而你可以指定任何名字(如 osd 、 disk 、 drive 、 storage 等等):
#types
type {num} {bucket-name}
例如:
# types type osd type host type chassis type rack type row type pdu type pod type room type datacenter type region type root
CRUSH 图之桶层次
CRUSH 算法根据各设备的权重、大致统一的概率把数据对象分布到存储设备中。 CRUSH 根据你定义的集群运行图分布对象及其副本, CRUSH 图表达了可用存储设备以及包含它们的逻辑单元。
要把归置组映射到跨故障域的 OSD ,一个 CRUSH 图需定义一系列分级桶类型(即现有 CRUSH 图的 #type 下)。创建桶分级结构的目的是按故障域隔离叶节点,像主机、机箱、机柜、电力分配单元、机群、行、房间、和数据中心。除了表示叶节点的 OSD ,其它分级结构都是任意的,你可以按需定义。
我们建议 CRUSH 图内的命名符合贵公司的硬件命名规则,并且采用反映物理硬件的例程名。良好的命名可简化集群管理和故障排除,当 OSD 和/或其它硬件出问题时,管理员可轻易找到对应物理硬件。
在下例中,桶分级结构有一个名为 osd 的分支、和两个节点分别名为 host 和 rack 。

注意:编号较高的 rack 桶类型汇聚编号较低的 host 桶类型
位于 CRUSH 图起始部分、 #devices 列表内是表示叶节点的存储设备,没必要声明为桶例程。位于分级结构第二低层的桶一般用于汇聚设备(即它通常是包含存储媒体的计算机,你可以用自己喜欢的名字描述,如节点、计算机、服务器、主机、机器等等)。在高密度环境下,经常出现一机框内安装多个主机/节点的情况,因此还要考虑机框故障——比如,某一节点故障后需要拉出机框维修,这会影响多个主机/节点和其内的 OSD 。
声明一个桶例程时,你必须指定其类型、惟一名称(字符串)、惟一负整数 ID (可选)、指定和各条目总容量/能力相关的权重、指定桶算法(通常是 straw )、和哈希(通常为 0 ,表示哈希算法 rjenkins1 )。一个桶可以包含一到多条,这些条目可以由节点桶或叶子组成,它们可以有个权重用来反映条目的相对权重。
你可以按下列语法声明一个节点桶:
[bucket-type] [bucket-name] {
id [a unique negative numeric ID]
weight [the relative capacity/capability of the item(s)]
alg [the bucket type: uniform | list | tree | straw ]
hash [the hash type: by default]
item [item-name] weight [weight]
}
例如,用上面的图表,我们可以定义两个主机桶和一个机柜桶, OSD 被声明为主机桶内的条目:
host node1 {
id -
alg straw
hash
item osd. weight 1.00
item osd. weight 1.00
}
host node2 {
id -
alg straw
hash
item osd. weight 1.00
item osd. weight 1.00
}
rack rack1 {
id -
alg straw
hash
item node1 weight 2.00
item node2 weight 2.00
}
注意:在前述示例中,机柜桶不包含任何 OSD ,它只包含低一级的主机桶、以及其内条目的权重之和。
桶类型 Ceph 支持四种桶,每种都是性能和组织简易间的折衷。如果你不确定用哪种桶,我们建议 straw ,关于桶类型的详细讨论见 CRUSH - 可控、可伸缩、分布式地归置多副本数据,特别是 Section 3.4 。支持的桶类型有: Uniform: 这种桶用完全相同的权重汇聚设备。例如,公司采购或淘汰硬件时,一般都有相同的物理配置(如批发)。 当存储设备权重都相同时,你可以用 uniform 桶类型,它允许 CRUSH 按常数把副本映射到 uniform 桶。权重不统一时,你应该采用其它算法。 List: 这种桶把它们的内容汇聚为链表。它基于 RUSH P 算法,一个列表就是一个自然、直观的扩张集群: 对象会按一定概率被重定位到最新的设备、或者像从前一样仍保留在较老的设备上。结果是优化了新条目加入桶时的数据迁移。 然而,如果从链表的中间或末尾删除了一些条目,将会导致大量没必要的挪动。所以这种桶适合永不或极少缩减的场景。 Tree: 它用一种二进制搜索树,在桶包含大量条目时比 list 桶更高效。它基于 RUSH R 算法, tree 桶把归置时间减少到了 O(log n) , 这使得它们更适合管理更大规模的设备或嵌套桶。 Straw: list 和 tree 桶用分而治之策略,给特定条目一定优先级(如位于链表开头的条目)、或避开对整个子树上所有条目的考虑。 这样提升了副本归置进程的性能,但是也导致了重新组织时的次优结果,如增加、拆除、或重设某条目的权重。 straw 桶类型允许所有条目模拟拉稻草的过程公平地相互“竞争”副本归置。
Hash
各个桶都用了一种哈希算法,当前 Ceph 仅支持 rjenkins1 ,输入 表示哈希算法设置为 rjenkins1 。
调整桶的权重
Ceph 用双整形表示桶权重。权重和设备容量不同,我们建议用 1.00 作为 1TB 存储设备的相对权重,这样 0.5 的权重大概代表 500GB 、 3.00 大概代表 3TB 。较高级桶的权重是所有枝叶桶的权重之和。 一个桶的权重是一维的,你也可以计算条目权重来反映存储设备性能。例如,如果你有很多 1TB 的硬盘,其中一些数据传输速率相对低、其他的数据传输率相对高,即使它们容量相同,也应该设置不同的权重(如给吞吐量较低的硬盘设置权重 0.8 ,较高的设置 1.20 )。
CRUSH 图之规则
CRUSH 图支持“ CRUSH 规则”概念,用以确定一个存储池里数据的归置。对大型集群来说,你可能创建很多存储池,且每个存储池都有它自己的 CRUSH 规则集和规则。默认的 CRUSH 图里,每个存储池有一条规则、一个规则集被分配到每个默认存储池。
注意:大多数情况下,你都不需要修改默认规则。新创建存储池的默认规则集是 0
CRUSH 规则定义了归置和复制策略、或分布策略,用它可以规定 CRUSH 如何放置对象副本。例如,你也许想创建一条规则用以选择一对目的地做双路复制;另一条规则用以选择位于两个数据中心的三个目的地做三路镜像;又一条规则用 6 个设备做纠删编码。关于 CRUSH 规则的详细研究见 CRUSH - 可控、可伸缩、分布式地归置多副本数据,主要是 Section 3.2。
规则格式如下:
rule <rulename> {
ruleset <ruleset>
type [ replicated | erasure ]
min_size <min-size>
max_size <max-size>
step take <bucket-type>
step [choose|chooseleaf] [firstn|indep] <N> <bucket-type>
step emit
}
ruleset
描述: 区分一条规则属于某个规则集的手段。给存储池设置规则集后激活。
目的: 规则掩码的一个组件。
类型: Integer
是否必需: Yes
默认值:
type
描述: 为硬盘(复制的)或 RAID 写一条规则。
目的: 规则掩码的一个组件。
类型: String
是否必需: Yes
默认值: replicated
合法取值: 当前仅支持 replicated 和 erasure
min_size
描述: 如果一个归置组副本数小于此数, CRUSH 将不应用此规则。
类型: Integer
目的: 规则掩码的一个组件。
是否必需: Yes
默认值:
max_size
描述: 如果一个归置组副本数大于此数, CRUSH 将不应用此规则。
类型: Integer
目的: 规则掩码的一个组件。
是否必需: Yes
默认值:
step take <bucket-name>
描述: 选取桶名并迭代到树底。
目的: 规则掩码的一个组件。
是否必需: Yes
实例: step take data
step choose firstn {num} type {bucket-type}
描述:
选取指定类型桶的数量,这个数字通常是存储池的副本数(即 pool size )。
如果 {num} == 选择 pool-num-replicas 个桶(所有可用的);
如果 {num} > && < pool-num-replicas 就选择那么多的桶;
如果 {num} < 它意为 pool-num-replicas - {num} 。
目的:
规则掩码的一个组件。
先决条件:
跟在 step take 或 step choose 之后。
实例:
step choose firstn type row
step chooseleaf firstn {num} type {bucket-type}
描述:
选择 {bucket-type} 类型的一堆桶,并从各桶的子树里选择一个叶子节点。集合内桶的数量通常是存储池的副本数(即 pool size )。
如果 {num} == 选择 pool-num-replicas 个桶(所有可用的);
如果 {num} > && < pool-num-replicas 就选择那么多的桶;
如果 {num} < 它意为 pool-num-replicas - {num} 。
目的:
规则掩码的一个组件。 它的使用避免了通过两步来选择一设备。
先决条件:
Follows step take or step choose.
实例:
step chooseleaf firstn type row
step emit
描述: 输出当前值并清空堆栈。通常用于规则末尾,也适用于相同规则应用到不同树的情况。
目的: 规则掩码的一个组件。
先决条件: Follows step choose.
实例: step emit
注意:把规则集编号设置到存储池,才能用一个通用规则集编号激活一或多条规则
主亲和性
一 Ceph 客户端读写数据时,总是连接 acting set 里的主 OSD (如 [2, 3, 4] 中, osd.2 是主的)。有时候某个 OSD 与其它的相比并不适合做主 OSD (比如其硬盘慢、或控制器慢),最大化硬件利用率时为防止性能瓶颈(特别是读操作),你可以调整 OSD 的主亲和性,这样 CRUSH 就尽量不把它用作 acting set 里的主 OSD 了。
ceph osd primary-affinity <osd-id> <weight>
主亲和性默认为 1 (就是说此 OSD 可作为主 OSD )。此值合法范围为 0-1 ,其中 0 意为此 OSD 不能用作主的, 1 意为 OSD 可用作主的;此权重小于 1 时, CRUSH 选择主 OSD 时选中它的可能性低。
给存储池指定 OSD
假设你想让大多数存储池坐落到使用大硬盘的 OSD 上,但是其中一些存储池映射到使用高速 SSD 的 OSD 上。在同一个 CRUSH 图内有多个独立的 CRUSH 树是可能的,定义两棵树、分别有自己的根节点——一个用于硬盘(如 root platter )、一个用于 SSD (如 root ssd ),如:
device osd.
device osd.
device osd.
device osd.
device osd.
device osd.
device osd.
device osd.
host ceph-osd-ssd-server- {
id -
alg straw
hash
item osd. weight 1.00
item osd. weight 1.00
}
host ceph-osd-ssd-server- {
id -
alg straw
hash
item osd. weight 1.00
item osd. weight 1.00
}
host ceph-osd-platter-server- {
id -
alg straw
hash
item osd. weight 1.00
item osd. weight 1.00
}
host ceph-osd-platter-server- {
id -
alg straw
hash
item osd. weight 1.00
item osd. weight 1.00
}
root platter {
id -
alg straw
hash
item ceph-osd-platter-server- weight 2.00
item ceph-osd-platter-server- weight 2.00
}
root ssd {
id -
alg straw
hash
item ceph-osd-ssd-server- weight 2.00
item ceph-osd-ssd-server- weight 2.00
}
rule data {
ruleset
type replicated
min_size
max_size
step take platter
step chooseleaf firstn type host
step emit
}
rule metadata {
ruleset
type replicated
min_size
max_size
step take platter
step chooseleaf firstn type host
step emit
}
rule rbd {
ruleset
type replicated
min_size
max_size
step take platter
step chooseleaf firstn type host
step emit
}
rule platter {
ruleset
type replicated
min_size
max_size
step take platter
step chooseleaf firstn type host
step emit
}
rule ssd {
ruleset
type replicated
min_size
max_size
step take ssd
step chooseleaf firstn type host
step emit
}
rule ssd-primary {
ruleset
type replicated
min_size
max_size
step take ssd
step chooseleaf firstn type host
step emit
step take platter
step chooseleaf firstn - type host
step emit
}
然后你可以设置一个存储池,让它使用 SSD 规则:
ceph osd pool
同样,用 ssd-primary 规则将使存储池内的各归置组用 SSD 作主 OSD ,普通硬盘作副本。
增加/移动 OSD
要增加或删除在线集群里 OSD 所对应的 CRUSH 图条目,执行 ceph osd crush set 命令。对于 v0.48 版,执行下列:
ceph osd crush set {id} {name} {weight} pool={pool-name} [{bucket-type}={bucket-name} ...]
Bobtail (v0.56) 可执行下列:
ceph osd crush set {id-or-name} {weight} root={pool-name} [{bucket-type}={bucket-name} ...]
其中:
id 描述: OSD 的数字标识符。 类型: Integer 是否必需: Yes 实例: name 描述: OSD 的全名。 类型: String 是否必需: Yes 实例: osd. weight 描述: OSD 的 CRUSH 权重。 类型: Double 是否必需: Yes 实例: 2.0 root 描述: OSD 所在树的根。 类型: Key/value pair. 是否必需: Yes 实例: root=default bucket-type 描述: 定义 OSD 在 CRUSH 分级结构中的位置。 类型: Key/value pairs. 是否必需: No 实例: datacenter=dc1 room=room1 row=foo rack=bar host=foo-bar-
下例把 osd.0 添加到分级结构里、或者说从前一个位置挪动一下。
ceph osd crush
调整一 OSD 的 CRUSH 权重
要调整在线集群中一 OSD 的 CRUSH 权重,执行命令:
ceph osd crush reweight {name} {weight}
其中:
name 描述: OSD 的全名。 类型: String 是否必需: Yes 实例: osd. weight 描述: OSD 的 CRUSH权重。 类型: Double 是否必需: Yes 实例: 2.0
删除 OSD
要从在线集群里把一 OSD 踢出 CRUSH 图,执行命令:
ceph osd crush remove {name}
其中:
name 描述: OSD 全名。 类型: String 是否必需: Yes 实例: osd.
增加桶
要在运行集群的 CRUSH 图中新建一个桶,用 ceph osd crush add-bucket 命令:
ceph osd crush add-bucket {bucket-name} {bucket-type}
其中:
bucket-name 描述: 桶的全名。 类型: String 是否必需: Yes 实例: rack12 bucket-type 描述: 桶的类型,它必须已存在于分级结构中。 类型: String 是否必需: Yes 实例: rack
下例把 rack12 桶加入了分级结构:
ceph osd crush add-bucket rack12 rack
移动桶
要把一个桶挪动到 CRUSH 图里的不同位置,执行命令:
ceph osd crush move {bucket-name} {bucket-type}={bucket-name}, [...]
其中:
bucket-name 描述: 要移动或复位的桶名。 类型: String 是否必需: Yes 实例: foo-bar- bucket-type 描述: 你可以指定桶在 CRUSH 分级结构里的位置。 类型: Key/value pairs. 是否必需: No 实例: datacenter=dc1 room=room1 row=foo rack=bar host=foo-bar-
删除桶
要把一个桶从 CRUSH 图的分级结构中删除,可用此命令:
ceph osd crush remove {bucket-name}
注意:从 CRUSH 分级结构里删除时必须是空桶。
其中:
bucket-name 描述: 将要删除的桶的名字。 类型: String 是否必需: Yes 实例: rack12
下例从分级结构里删除了 rack12 。
ceph osd crush remove rack12
可调选项
在 CRUSH 最初实现时加入的几个幻数,现在看来已成问题。作为过渡方法,较新版的 CRUSH (从 0.48 起)允许调整这些值。
最近发布的 Ceph 允许在 CRUSH 图里使用可调值,然而老客户端和守护进程不会正确地和调整过的 CRUSH 图交互,为应对这种情况,现在多了个功能位 CRUSH_TUNABLES (值 0x40000 )和 CRUSH_TUNABLES2 来反映支持可调值。
如果 ceph-mon 或 ceph-osd 进程现在用的 OSDMap 有非遗留值,它将要求连接它的客户端和守护进程有 CRUSH_TUNABLES 或 CRUSH_TUNABLES2 功能位。
将来,新建集群的可调值其默认值会更好。这要等到此功能进入内核客户端的时间足够长,对大多数用户来说已是无痛的过渡。
过时值的影响
遗留值导致几个不当行为:
1.如果分级结构的支部只有少量设备,一些 PG 的副本数小于期望值,这通常出现在一些子结构里, host 节点下少数 OSD 嵌套到了其他 OSD 里。 2.大型集群里,小部分 PG 映射到的 OSD 数目小于期望值,有多层结构(如:机架行、机架、主机、 OSD )时这种情况更普遍。 3.当一些 OSD 标记为 out 时,数据倾向于重分布到附近 OSD 而非整个分级结构。
CRUSH_TUNABLES
choose_local_tries: 本地重试次数。以前是 ,最优值是 。 choose_local_fallback_tries: 以前 ,现在是 。 choose_total_tries: 选择一个条目的最大尝试次数。以前 ,后来的测试表明,对典型的集群来说 更合适。最相当大的集群来说,更大的值也许必要。
CRUSH_TUNABLES2
chooseleaf_descend_once: 是否重递归叶子选择,或只试一次、并允许最初归置组重试。以前默认 ,最优为 。
CRUSH_TUNABLES3
chooseleaf_vary_r: 根据父节点已做过多少尝试,递归选叶是否应该以非零值 r 开始。原先的默认值是 ,但是用此值的话 CRUSH 有时候会找不到映射关系; 较优的值(计算代价和正确性合理)是 。然而,较老的集群里面已经有大量数据,从 改为 会导致大量的数据迁移; 时 CRUSH 也能正确找到映射,而且数据迁移少的多。
支持 CRUSH_TUNABLES 的客户端版本
argonaut 系列, v0.48.1 或更高版 v0. 或更高版 Linux 内核版本大于 v3. (对文件系统和 RBD 客户端都一样)
支持 CRUSH_TUNABLES2 的客户端版本
v0. 或更高版,包括 bobtail 系列 (v0..x) Linux 内核版本大于 v3. (对文件系统和 RBD 客户端都一样)
支持 CRUSH_TUNABLES3 的客户端版本
v0. (firefly) 或更高版 Linux 内核版本大于 v3. (对文件系统和 RBD 客户端都一样)
可调选项非最优时发出警告
从 v0.74 起,如果 CRUSH 可调选项不是最优值( v0.73 版里的默认值) Ceph 就会发出健康告警,有两种方法可消除这些告警:
1.调整现有集群上的可调选项。注意,这可能会导致一些数据迁移(可能有 10% 之多)。这是推荐的办法,但是在生产集群上要注意此调整对性能带来的影响。此命令可启用较优可调选项:
ceph osd crush tunables optimal
如果切换得不太顺利(如负载太高)且切换才不久,或者有客户端兼容问题(较老的 cephfs 内核驱动或 rbd 客户端、或早于 bobtail 的 librados 客户端),你可以这样切回:
ceph osd crush tunables legacy
2.不对 CRUSH 做任何更改也能消除报警,把下列配置加入 ceph.conf 的 [mon] 段下:
mon warn on legacy crush tunables = false
为使变更生效需重启所有监视器,或者执行下列命令:
ceph tell mon.\* injectargs --no-mon-warn-on-legacy-crush-tunables
一些要点
1.调整这些值将使一些 PG 在存储节点间移位,如果 Ceph 集群已经存储了大量数据,做好移动一部分数据的准备。
2.一旦更新运行图, ceph-osd 和 ceph-mon 就会开始向新建连接要求功能位,然而,之前已经连接的客户端如果不支持新功能将行为失常。
3.如果 CRUSH 可调值更改过、然后又改回了默认值, ceph-osd 守护进程将不要求支持此功能,然而, OSD 连接建立进程要能检查和理解旧地图。
因此,集群如果用过非默认 CRUSH 值就不应该再运行版本小于 0.48.1 的 ceph-osd ,即使最新版地图已经回滚到了遗留默认值。
调整 CRUSH
更改 crush 可调值的最简方法就是改到一个已知配置,它们有:
legacy: 采用 argonaut 及更低版本的行为; argonaut: 采用 argonaut 版最初的配置; bobtail: 采用 bobtail 版的配置; firefly: 采用 firefly 版的配置; optimal: 采用当前最佳配置; default: 新建集群可采用当前默认值
你可以在运行着的集群上选择一个配置:
ceph osd crush tunables {PROFILE}
要注意,这可能产生一些数据迁移。
调整 CRUSH ——强硬方法
如果你能保证所有客户端都运行最新代码,你可以这样调整可调值:从集群抽取 CRUSH 图、修改值、重注入。
1.提抽取最新 CRUSH 图:
ceph osd getcrushmap -o /tmp/crush
2.调整可调参数。这些值在我们测试过的大、小型集群上都有最佳表现。在极端情况下,你需要给 crushtool 额外指定 --enable-unsafe-tunables 参数才行:
crushtool -i /tmp/crush -- -- -- -o /tmp/crush.new
3.重注入修改的图
ceph osd setcrushmap -i /tmp/crush.new
遗留值
CRUSH 可调参数的遗留值可以用下面命令设置:
crushtool -i /tmp/crush -- -- -- -- -- -o /tmp/crush.legacy
再次申明, --enable-unsafe-tunables 是必需的,而且前面也提到了,回退到遗留值后慎用旧版 ceph-osd 进程,因为此功能位不是完全强制的。
Ceph 存储集群5-数据归置的更多相关文章
- Ceph 存储集群2-配置:心跳选项、OSD选项、存储池、归置组和 CRUSH 选项
一.心跳选项 完成基本配置后就可以部署.运行 Ceph 了.执行 ceph health 或 ceph -s 命令时,监视器会报告 Ceph 存储集群的当前状态.监视器通过让各 OSD 自己报告.并接 ...
- Ceph 存储集群4-高级运维:
一.高级运维 高级集群操作主要包括用 ceph 服务管理脚本启动.停止.重启集群,和集群健康状态检查.监控和操作集群. 操纵集群 运行 Ceph 每次用命令启动.重启.停止Ceph 守护进程(或整个集 ...
- Ceph 存储集群1-配置:硬盘和文件系统、配置 Ceph、网络选项、认证选项和监控器选项
所有 Ceph 部署都始于 Ceph 存储集群.基于 RADOS 的 Ceph 对象存储集群包括两类守护进程: 1.对象存储守护进程( OSD )把存储节点上的数据存储为对象: 2.Ceph 监视器( ...
- Ceph 存储集群第一部分:配置和部署
内容来源于官方,经过个人实践操作整理,官方地址:http://docs.ceph.org.cn/rados/ 所有 Ceph 部署都始于 Ceph 存储集群. 基于 RADOS 的 Ceph 对象存储 ...
- Ceph 存储集群
Ceph 存储集群 Ceph 作为软件定义存储的代表之一,最近几年其发展势头很猛,也出现了不少公司在测试和生产系统中使用 Ceph 的案例,尽管与此同时许多人对它的抱怨也一直存在.本文试着整理作者了解 ...
- 002.RHCS-配置Ceph存储集群
一 前期准备 [kiosk@foundation0 ~]$ ssh ceph@serverc #登录Ceph集群节点 [ceph@serverc ~]$ ceph health #确保集群状态正常 H ...
- Ceph 存储集群搭建
前言 Ceph 分布式存储系统,在企业中应用面较广 初步了解并学会使用很有必要 一.简介 Ceph 是一个开源的分布式存储系统,包括对象存储.块设备.文件系统.它具有高可靠性.安装方便.管理简便.能够 ...
- ceph存储集群的应用
1.ceph存储集群的访问接口 1.1ceph块设备接口(RBD) ceph块设备,也称为RADOS块设备(简称RBD),是一种基于RADOS存储系统支持超配(thin-provisioned). ...
- 初试 Centos7 上 Ceph 存储集群搭建
转载自:https://cloud.tencent.com/developer/article/1010539 1.Ceph 介绍 Ceph 是一个开源的分布式存储系统,包括对象存储.块设备.文件系统 ...
随机推荐
- $POJ$2976 $Dropping\ tests$ 01分数规划+贪心
正解:01分数规划 解题报告: 传送门! 板子题鸭,,, 显然考虑变成$a[i]-mid\cdot b[i]$,显然无脑贪心下得选出最大的$k$个然后判断是否大于0就好(,,,这么弱智真的算贪心嘛$T ...
- $HDU$ 4336 $Card\ Collector$ 概率$dp$/$Min-Max$容斥
正解:期望 解题报告: 传送门! 先放下题意,,,已知有总共有$n$张卡片,每次有$p_i$的概率抽到第$i$张卡,求买所有卡的期望次数 $umm$看到期望自然而然想$dp$? 再一看,哇,$n\le ...
- $BZOJ1799\ Luogu4127$ 月之谜 数位统计$DP$
AcWing Description Sol 看了很久也没有完全理解直接$DP$的做法,然后发现了记搜的做法,觉得好棒! 这里是超棒的数位$DP$的记搜做法总结 看完仿佛就觉得自己入门了,但是就像 ...
- DecoratorPattern(装饰器模式)-----Java/.Net
装饰器模式(Decorator Pattern)允许向一个现有的对象添加新的功能,同时又不改变其结构.这种类型的设计模式属于结构型模式,它是作为现有的类的一个包装
- 大数据学习之路-Centos6安装python3.5
Centos 6.8安装python3.5.2 因为学习所需,需要用到python3.x的环境,目前Linux系统默认的版本都是python2.x的,还有一些自带的工具需要用到python2.6版本, ...
- 「学习笔记」ST表
问题引入 先让我们看一个简单的问题,有N个元素,Q次操作,每次操作需要求出一段区间内的最大/小值. 这就是著名的RMQ问题. RMQ问题的解法有很多,如线段树.单调队列(某些情况下).ST表等.这里主 ...
- (一)Django项目架构介绍
项目的架构为: 1.虚拟环境virtualenv 安装Django==2.1.3 安装pymysql 安装mysqlclient 安装其他等 2.项目结构为: 应用APP: blog -- 管理博客 ...
- 2019年最值得关注的AI领域技术突破及未来展望
选自venturebeat 翻译:魔王.一鸣 前言 AI 领域最杰出的头脑如何总结 2019 年技术进展,又如何预测 2020 年发展趋势呢?本文介绍了 Soumith Chintala.Celest ...
- Flask 作者 Armin Ronacher:我不觉得有异步压力
英文 | I'm not feeling the async pressure[1] 原作 | Armin Ronacher,2020.01.01 译者 | 豌豆花下猫@Python猫 声明 :本翻译 ...
- GeneXus DevOps 自动化构建和部署流程
以下视频详细介绍了GeneXus DevOps自动化构建和部署流程,包括通过MS Bulid来管理自动化流程,自动化的架构,以及在GeneXus Server上使用Jenkins做为自动化引擎. 视频 ...