吴裕雄 python 机器学习——集成学习AdaBoost算法分类模型
import numpy as np
import matplotlib.pyplot as plt from sklearn import datasets,ensemble
from sklearn.model_selection import train_test_split def load_data_classification():
'''
加载用于分类问题的数据集
'''
# 使用 scikit-learn 自带的 digits 数据集
digits=datasets.load_digits()
# 分层采样拆分成训练集和测试集,测试集大小为原始数据集大小的 1/4
return train_test_split(digits.data,digits.target,test_size=0.25,random_state=0,stratify=digits.target) #集成学习AdaBoost算法分类模型
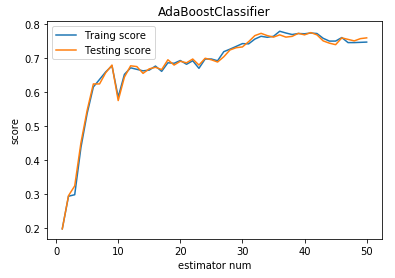
def test_AdaBoostClassifier(*data):
'''
测试 AdaBoostClassifier 的用法,绘制 AdaBoostClassifier 的预测性能随基础分类器数量的影响
'''
X_train,X_test,y_train,y_test=data
clf=ensemble.AdaBoostClassifier(learning_rate=0.1)
clf.fit(X_train,y_train)
## 绘图
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
estimators_num=len(clf.estimators_)
X=range(1,estimators_num+1)
ax.plot(list(X),list(clf.staged_score(X_train,y_train)),label="Traing score")
ax.plot(list(X),list(clf.staged_score(X_test,y_test)),label="Testing score")
ax.set_xlabel("estimator num")
ax.set_ylabel("score")
ax.legend(loc="best")
ax.set_title("AdaBoostClassifier")
plt.show() # 获取分类数据
X_train,X_test,y_train,y_test=load_data_classification()
# 调用 test_AdaBoostClassifier
test_AdaBoostClassifier(X_train,X_test,y_train,y_test)
def test_AdaBoostClassifier_base_classifier(*data):
'''
测试 AdaBoostClassifier 的预测性能随基础分类器数量和基础分类器的类型的影响
'''
from sklearn.naive_bayes import GaussianNB X_train,X_test,y_train,y_test=data
fig=plt.figure()
ax=fig.add_subplot(2,1,1)
########### 默认的个体分类器 #############
clf=ensemble.AdaBoostClassifier(learning_rate=0.1)
clf.fit(X_train,y_train)
## 绘图
estimators_num=len(clf.estimators_)
X=range(1,estimators_num+1)
ax.plot(list(X),list(clf.staged_score(X_train,y_train)),label="Traing score")
ax.plot(list(X),list(clf.staged_score(X_test,y_test)),label="Testing score")
ax.set_xlabel("estimator num")
ax.set_ylabel("score")
ax.legend(loc="lower right")
ax.set_ylim(0,1)
ax.set_title("AdaBoostClassifier with Decision Tree")
####### Gaussian Naive Bayes 个体分类器 ########
ax=fig.add_subplot(2,1,2)
clf=ensemble.AdaBoostClassifier(learning_rate=0.1,base_estimator=GaussianNB())
clf.fit(X_train,y_train)
## 绘图
estimators_num=len(clf.estimators_)
X=range(1,estimators_num+1)
ax.plot(list(X),list(clf.staged_score(X_train,y_train)),label="Traing score")
ax.plot(list(X),list(clf.staged_score(X_test,y_test)),label="Testing score")
ax.set_xlabel("estimator num")
ax.set_ylabel("score")
ax.legend(loc="lower right")
ax.set_ylim(0,1)
ax.set_title("AdaBoostClassifier with Gaussian Naive Bayes")
plt.show() # 调用 test_AdaBoostClassifier_base_classifier
test_AdaBoostClassifier_base_classifier(X_train,X_test,y_train,y_test)

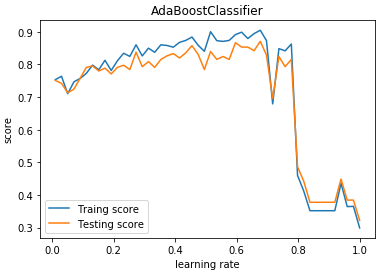
def test_AdaBoostClassifier_learning_rate(*data):
'''
测试 AdaBoostClassifier 的预测性能随学习率的影响
'''
X_train,X_test,y_train,y_test=data
learning_rates=np.linspace(0.01,1)
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
traing_scores=[]
testing_scores=[]
for learning_rate in learning_rates:
clf=ensemble.AdaBoostClassifier(learning_rate=learning_rate,n_estimators=500)
clf.fit(X_train,y_train)
traing_scores.append(clf.score(X_train,y_train))
testing_scores.append(clf.score(X_test,y_test))
ax.plot(learning_rates,traing_scores,label="Traing score")
ax.plot(learning_rates,testing_scores,label="Testing score")
ax.set_xlabel("learning rate")
ax.set_ylabel("score")
ax.legend(loc="best")
ax.set_title("AdaBoostClassifier")
plt.show() # 调用 test_AdaBoostClassifier_learning_rate
test_AdaBoostClassifier_learning_rate(X_train,X_test,y_train,y_test)
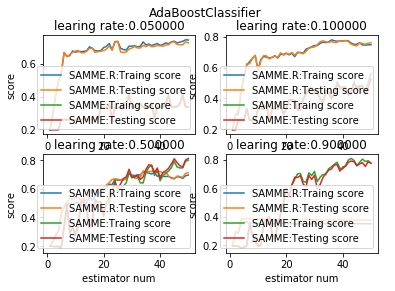
def test_AdaBoostClassifier_algorithm(*data):
'''
测试 AdaBoostClassifier 的预测性能随学习率和 algorithm 参数的影响
'''
X_train,X_test,y_train,y_test=data
algorithms=['SAMME.R','SAMME']
fig=plt.figure()
learning_rates=[0.05,0.1,0.5,0.9]
for i,learning_rate in enumerate(learning_rates):
ax=fig.add_subplot(2,2,i+1)
for i ,algorithm in enumerate(algorithms):
clf=ensemble.AdaBoostClassifier(learning_rate=learning_rate,algorithm=algorithm)
clf.fit(X_train,y_train)
## 绘图
estimators_num=len(clf.estimators_)
X=range(1,estimators_num+1)
ax.plot(list(X),list(clf.staged_score(X_train,y_train)),label="%s:Traing score"%algorithms[i])
ax.plot(list(X),list(clf.staged_score(X_test,y_test)),label="%s:Testing score"%algorithms[i])
ax.set_xlabel("estimator num")
ax.set_ylabel("score")
ax.legend(loc="lower right")
ax.set_title("learing rate:%f"%learning_rate)
fig.suptitle("AdaBoostClassifier")
plt.show() # 调用 test_AdaBoostClassifier_algorithm
test_AdaBoostClassifier_algorithm(X_train,X_test,y_train,y_test)
吴裕雄 python 机器学习——集成学习AdaBoost算法分类模型的更多相关文章
- 吴裕雄 python 机器学习——集成学习AdaBoost算法回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习随机森林RandomForestRegressor回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习随机森林RandomForestClassifier分类模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习梯度提升决策树GradientBoostingRegressor回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——人工神经网络与原始感知机模型
import numpy as np from matplotlib import pyplot as plt from mpl_toolkits.mplot3d import Axes3D from ...
- 吴裕雄 python 机器学习——等度量映射Isomap降维模型
# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt from sklearn import datas ...
- 吴裕雄 python 机器学习——多维缩放降维MDS模型
# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt from sklearn import datas ...
- 吴裕雄 python 机器学习——多项式贝叶斯分类器MultinomialNB模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,naive_bayes from skl ...
- 吴裕雄 python 机器学习——数据预处理二元化OneHotEncoder模型
from sklearn.preprocessing import OneHotEncoder #数据预处理二元化OneHotEncoder模型 def test_OneHotEncoder(): X ...
随机推荐
- 洛谷P3381 MCMF【网络流】
题目描述 如题,给出一个网络图,以及其源点和汇点,每条边已知其最大流量和单位流量费用,求出其网络最大流和在最大流情况下的最小费用. 输入格式 第一行包含四个正整数N.M.S.T,分别表示点的个数.有向 ...
- Python实现人工神经网络逼近股票价格
1.基本数据绘制成图 数据有15天股票的开盘价格和收盘价格,可以通过比较当天开盘价格和收盘价格的大小来判断当天股票价格的涨跌情况,红色表示涨,绿色表示跌,测试代码如下: # encoding:utf- ...
- 《NVM-Express-1_4-2019.06.10-Ratified》学习笔记(4.12-加-6.2-加-7.2.5.2)Fused_Operations
4.12 Fused Operations 融合操作 融合操作通过“fusing”把两个简单的命令融合一起来支持一个更复杂的命令.协议规定这个特性是可选的:如果支持此特性,需要在Figure 247 ...
- shell登录 脚本 expect
作用 工作中,我们运行命令.脚本或程序时,这些命令.脚本或程序都需要从终端输入某些继续运行的指令,而这些输入都需要人为的手工进行. 利用expect,则可以根据程序的提示,模拟标准输入提供给程序,从而 ...
- 2个月,我从编程小白成为了Python研发工程师
从编程小白,到Python研发工程师,需要多久呢? 答案就是:91门课,450个小时. 听起来似乎难以实现,但其实如果每天抽出八小时学习,两个月的时间,就能由编程小白转变成为Python工程师,听起来 ...
- vba工程密码清除
EXCEL vba工程密码破解 方法一:这种方法实际是避开VBA工程密码验证,即骗vba编辑器,该密码输入成功,请求放行.不管他是破解还是欺骗 能达到我们的目的角开就行________________ ...
- IIS学习笔记
IIS传输笔记 1.作用 IIS 将网站开发代码传输到服务器上,就是为了网站的发布 2.下载安装 我是使用的云服务器,windows sever 2012 2.1打开"服务器管理器" ...
- AcWing 12. 背包问题求具体方案
//f[i][j]=max(f[i-1][j],f[i-1][j-v[i]]+w[i]) #include <iostream> using namespace std; ; int n, ...
- 【填坑】python3 manage.py migrate:?: (mysql.W002) MySQL Strict Mode is not set for database connection 'default'
问题: WARNINGS:?: (mysql.W002) MySQL Strict Mode is not set for database connection 'default' H ...
- 手机大厂必备测试技能-GMS 认证
GMS认证背景 在之前的一篇文章有给各位小伙伴们科普过关于GMS的作用,http://www.lemfix.com/topics/266 "墙"内的小伙伴可能很少会用到这样的服务, ...