《SQL基础教程》
Product表
CREATE TABLE Product
(product_id CHAR(4) NOT NULL,
product_name VARCHAR(100) NOT NULL,
product_type VARCHAR(32) NOT NULL,
sale_price INTEGER ,
purchase_price INTEGER ,
regist_date DATE ,
PRIMARY KEY (product_id));
插入数据
-- DML:插 入 数 据
BEGIN TRANSACTION;
INSERT INTO Product VALUES ('0001', 'T恤衫', '衣服', 1000, 500, '2009-09-20');
INSERT INTO Product VALUES ('0002', '打孔器', '办公用品', 500, 320, '2009-09-11');
INSERT INTO Product VALUES ('0003', '运动T恤', '衣服', 4000, 2800, NULL);
INSERT INTO Product VALUES ('0004', '菜刀', '厨房用具', 3000, 2800, '2009-09-20');
INSERT INTO Product VALUES ('0005', '高压锅', '厨房用具', 6800, 5000, '2009-01-15');
INSERT INTO Product VALUES ('0006', '叉子', '厨房用具', 500, NULL, '2009-09-20');
INSERT INTO Product VALUES ('0007', '擦菜板', '厨房用具', 880, 790, '2008-04-28');
INSERT INTO Product VALUES ('0008', '圆珠笔', '办公用品', 100, NULL,'2009-11-11');
COMMIT;
第一章 数据库与SQL
表定义的更新(ALTER TABLE语句)
ALTER TABLE <表名> ADD COLUMN <列的定义>;
添加一列可以存储100位的可变长字符串的product_name_pinyin列
-- Oracle和SQLServer中不用写`COLUMN`。
--Oracle
ALTER TABLE Product ADD (product_name_pinyin VARCHAR2(100));
--SQL Server
ALTER TABLE Product ADD product_name_pinyin VARCHAR(100);
删除列的ALTER TABLE语句
ALTER TABLE <表名> DROP COLUMN <列名>;
删除product_name_pinyin列
ALTER TABLE Product DROP COLUMN product_name_pinyin;
变更表名:
--Oracle PostgreSQL
ALTER TABLE Poduct RENAME TO Product;
--DB2
RENAME TABLE Poduct TO Product;
--SQL Server
sp_rename 'Poduct', 'Product';
--MySQL
RENAME TABLE Poduct to Product;
第三章 聚合与排序
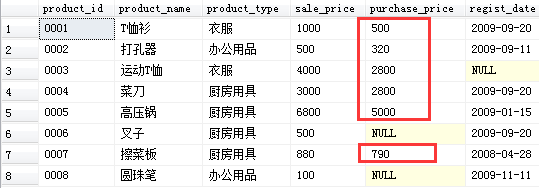
3-1 对表进行聚合查询
计算表中数据的行数
SELECT COUNT(*)
FROM Product;
------
8
计算NULL之外的数据的行数
如果想得到purchase_price列(进货单价)中非空行数的话,
SELECT COUNT(purchase_price)
FROM Product;
------
6
第四章 数据的更新
4-1 数据的插入
从其他表复制数据
已存在表的情况下:
-- 用来插入数据的商品复制表
CREATE TABLE ProductCopy
(product_id CHAR(4) NOT NULL,
product_name VARCHAR(100) NOT NULL,
product_type VARCHAR(32) NOT NULL,
sale_price INTEGER ,
purchase_price INTEGER ,
regist_date DATE ,
PRIMARY KEY (product_id));
-- 将商品表中的数据复制到商品复制表中
---- 简单写法
INSERT INTO ProductCopy
SELECT *
FROM Product;
---- 正常方法
INSERT INTO ProductCopy (product_id, product_name, product_type,
sale_price, purchase_price, regist_date)
SELECT product_id, product_name, product_type, sale_price,
purchase_price, regist_date
FROM Product;
不存在表的情况下(备份表操作):
但是不保留主外键
SELECT * INTO ProductCopy20180502 FROM ProductCopy

第五章 复杂查询
5-2 子查询
标量子查询
标量就是单一的意思,在数据库之外的领域也经常使用
而标量子查询则有一个特殊的限制,那就是必须而且只能返回1行1列的结果。
标量子查询就是返回单一值的子查询。
例子:
-- 在WHERE子句中不能使用聚合函数
SELECT product_id, product_name, sale_price
FROM Product
WHERE sale_price > AVG(sale_price); --!报错:WHERE子句中不能使用聚合函数
WHERE子句中不能使用聚合函数,因此这样的SELECT语句是错误的。
下面是正确方式:
-- “查询出销售单价高于平均销售单价的商品。”
SELECT product_id, product_name, sale_price
FROM Product
WHERE sale_price > (SELECT AVG(sale_price)
FROM Product);
5-3 关联子查询
选取出各
条件:商品种类中高于该商品种类的平均销售单价的商品
1.按照商品种类计算平均价格
SELECT AVG(sale_price)
FROM Product
GROUP BY product_type;
返回结果是多行结果,所以不能使用标量子查询。
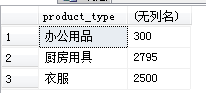
这个时候改使用关联子查询。
SELECT product_type, product_name, sale_price
FROM Product AS P1
WHERE sale_price > (SELECT AVG(sale_price)
FROM Product AS P2
WHERE P1.product_type = P2.product_type --该条件是关键
GROUP BY product_type);

该条件的意思就是,在同一商品种类中对各商品的销售单价和平均单价进行比较。
在对表中某一部分记录的集合进行比较时,就可以使用关联子查询。
在细分的组内进行比较时,需要使用关联子查询。
大家还记得我们用来说明GROUP BY子句的图

使用关联子查询进行切分的图示也基本相同

我们首先需要计算各个商品种类中商品的平均销售单价,由于该单价会用来和商品表中的各条记录进行比较,因此关联子查询实际只能返回1行结果。这也是关联子查询不出错的关键。
关联子查询执行时DBMS内部的执行情况
练习题:
5.1 创建出满足下述三个条件的视图(视图名称为ViewPractice5_1)。 使用Product(商品)表作为参照表,假设表中包含初始状态的 8行数据。
条件 1: 销售单价大于等于1000日元。
条件 2: 登记日期是2009年 9月 20日。
条件 3: 包含商品名称、销售单价和登记日期三列。
对该视图执行SELECT语句的结果如下所示。
SELECT * FROM ViewPractice5_1;
执行结果
| product_name | sale_price | regist_date |
|---|---|---|
| T恤衫 | 1000 | 2009-09-20 |
| 菜刀 | 3000 | 2009-09-20 |
5.2 向习题 5.1 中创建的视图 ViewPractice5_1中插入如下数据,会得到什么样的结果呢?
INSERT INTO ViewPractice5_1 VALUES ('刀子', 300, '2009-11-02');
5.3 请根据如下结果编写 SELECT语句,其中 sale_price_all列为全部商品的平均销售单价。
| product_id | product_name | product_type | sale_price | sale_price_all |
|---|---|---|---|---|
| 0001 | T恤衫 | 衣服 | 1000 | 2097.5000000000000000 |
| 0002 | 打孔器 | 办公用品 | 500 | 2097.5000000000000000 |
| 0003 | 运动T恤 | 衣服 | 4000 | 2097.5000000000000000 |
| 0004 | 菜刀 | 厨房用具 | 3000 | 2097.5000000000000000 |
| 0005 | 高压锅 | 厨房用具 | 6800 | 2097.5000000000000000 |
| 0006 | 叉子 | 厨房用具 | 500 | 2097.5000000000000000 |
| 0007 | 擦菜板 | 厨房用具 | 880 | 2097.5000000000000000 |
| 0008 | 圆珠笔 | 办公用品 | 100 | 2097.5000000000000000 |
5.4 请根据习题5.1中的条件编写一条SQL语句,创建一幅包含如下数据的视图(名称为 AvgPriceByType)。
执行结果
| product_id | product_name | product_type | sale_price | avg_sale_price |
|---|---|---|---|---|
| 0001 | T恤衫 | 衣服 | 1000 | 2500.0000000000000000 |
| 0002 | 打孔器 | 办公用品 | 500 | 300.0000000000000000 |
| 0003 | 运动T恤 | 衣服 | 4000 | 2500.0000000000000000 |
| 0004 | 菜刀 | 厨房用具 | 3000 | 2795.0000000000000000 |
| 0005 | 高压锅 | 厨房用具 | 6800 | 2795.0000000000000000 |
| 0006 | 叉子 | 厨房用具 | 500 | 2795.0000000000000000 |
| 0007 | 擦菜板 | 厨房用具 | 880 | 2795.0000000000000000 |
| 0008 | 圆珠笔 | 办公用品 | 100 | 300.0000000000000000 |
提示 :其 中 的 关 键 是avg_sale_price列。与习题5.3不同,这里需要计算出的是各商品种类的平均销售单价。这与5-3节中使用关联子查询所得到的结果相同。
也就是说,该列可以使用关联子查询进行创建。问题就是应该在什么地方使用这个关联子查询。
答案:
5.1
CREATE VIEW ViewPractice5_1
AS (SELECT product_name, sale_price, regist_date
FROM dbo.Product
WHERE sale_price >= 1000
AND regist_date = '2009-09-20'
)
5.2
对视图的更新归根结底是对视图所对应的表进行更新。因此,该INSERT语句实质上和下面的INSERT语句相同。
INSERT INTO Product (product_id, product_name, product_type, sale_price, purchase_price, regist_date)
VALUES (NULL, '刀子', NULL, 300, NULL, '2009-11-02');
5.3
SELECT product_id, product_name, product_type, sale_price,
( SELECT AVG(sale_price) FROM Product ) AS 'sale_Price_all'
FROM dbo.Product;
5.4
方案一:
SELECT product_id,product_name, product_type, sale_price,
(
SELECT AVG(sale_price) FROM Product P2
WHERE P1.product_type = P2.product_type --关键
GROUP BY P2.product_type
) AS avg_sale_price
FROM Product P1;
方案二:
SELECT p1.product_id, p1.product_name, p1.product_type, p1.sale_price,p2.avg_sale_price
FROM dbo.Product p1
LEFT JOIN
(SELECT product_type,AVG(sale_price) AS avg_sale_price FROM dbo.Product
GROUP BY product_type) p2
ON p1.product_type = p2.product_type
第六章 函数、谓词、CASE表达式
6-1 各种函数
字符串函数
创建表
-- DDL:创 建 表
CREATE TABLE SampleStr
(str1 VARCHAR(40),
str2 VARCHAR(40),
str3 VARCHAR(40))
-- DML:插 入 数 据
BEGIN TRANSACTION;
INSERT INTO SampleStr (str1, str2, str3) VALUES ('opx' ,'rt',NULL);
INSERT INTO SampleStr (str1, str2, str3) VALUES ('abc' ,'def' ,NULL);
INSERT INTO SampleStr (str1, str2, str3) VALUES ('山田' ,'太郎' ,'是我');
INSERT INTO SampleStr (str1, str2, str3) VALUES ('aaa' ,NULL ,NULL);
INSERT INTO SampleStr (str1, str2, str3) VALUES (NULL ,'xyz',NULL);
INSERT INTO SampleStr (str1, str2, str3) VALUES ('@!#$%' ,NULL ,NULL);
INSERT INTO SampleStr (str1, str2, str3) VALUES ('ABC' ,NULL ,NULL);
INSERT INTO SampleStr (str1, str2, str3) VALUES ('aBC' ,NULL ,NULL);
INSERT INTO SampleStr (str1, str2, str3) VALUES ('abc太郎' ,'abc' ,'ABC');
INSERT INTO SampleStr (str1, str2, str3) VALUES ('abcdefabc' ,'abc' ,'ABC');
INSERT INTO SampleStr (str1, str2, str3) VALUES ('micmic' ,'i' ,'I');
COMMIT;
- 拼接
+或者|| LENGTH——字符串长度LOWER——小写转换REPLACE——字符串的替换
REPLACE(对象字符串,替换前的字符串,替换后的字符串)
SELECT str1, str2, str3,
REPLACE(str1, str2, str3) AS rep_str
FROM SampleStr;

SUBSTRING——字符串的截取
--(PostgreSQL/MySQL专用语法)
SUBSTRING(对象字符串 FROM 截取的起始位置 FOR 截取的字符数)
-- sqlserver专用
SUBSTRING(对象字符串,截取的起始位置,截取的字符数)
SELECT str1,
SUBSTRING(str1, 3, 2) AS sub_str
FROM SampleStr;

UPPER——大写转换
日期函数
- 获取当前日期和时间
--SQL Server,PostgreSQL,MySQL
SELECT CURRENT_TIMESTAMP
--2018-05-03 17:21:07.763
- 获取当前日期
--PostgreSQL MySQL
SELECT CURRENT_DATE;
--2018-05-03
--SqlServer
SELECT CAST(CURRENT_TIMESTAMP AS DATE) AS CUR_DATE;
--2018-05-03
- 取得当前时间
--PostgreSQL MySQL
SELECT CURRENT_TIME;
--17:21:07.995+09
--SqlServer 使用CAST函数将CURRENT_TIMESTAMP转换为时间类型
SELECT CAST(CURRENT_TIMESTAMP AS TIME) AS CUR_TIME;
--17:21:07.7630000
- EXTRACT——截取日期元素
EXTRACT(日期元素 FROM 日期)
-- PostgreSQL MySQL
SELECT CURRENT_TIMESTAMP,
EXTRACT(YEAR FROM CURRENT_TIMESTAMP) AS year,
EXTRACT(MONTH FROM CURRENT_TIMESTAMP) AS month,
EXTRACT(DAY FROM CURRENT_TIMESTAMP) AS day,
EXTRACT(HOUR FROM CURRENT_TIMESTAMP) AS hour,
EXTRACT(MINUTE FROM CURRENT_TIMESTAMP) AS minute,
EXTRACT(SECOND FROM CURRENT_TIMESTAMP) AS second;
--SQL Server (使用如下的DATEPART函数)
SELECT CURRENT_TIMESTAMP,
DATEPART(YEAR , CURRENT_TIMESTAMP) AS year,
DATEPART(MONTH , CURRENT_TIMESTAMP) AS month,
DATEPART(DAY , CURRENT_TIMESTAMP) AS day,
DATEPART(HOUR , CURRENT_TIMESTAMP) AS hour,
DATEPART(MINUTE , CURRENT_TIMESTAMP) AS minute,
DATEPART(SECOND , CURRENT_TIMESTAMP) AS second;

6-2 谓词
EXIST谓词
“判断是否存在满足某种条件的记录”,如果存在这样的记录就返回真(TRUE),如果不存在就返回假(FALSE)。
EXIST(存在)谓词的主语是“记录”。
① EXIST的使用方法与之前的都不相同。
② 语法理解起来比较困难。
③ 实际上即使不使用EXIST,基本上也都可以使用IN(或者NOT IN)来代替。
例子:使用EXIST选取出“大阪店在售商品的销售单价”
--exists谓词
SELECT p.product_name, p.sale_price
FROM dbo.Product p
WHERE exists (
SELECT product_id FROM dbo.ShopProduct sp WHERE shop_id = '000C'
AND p.product_id = sp.product_id
)
-- IN谓词
SELECT product_name, sale_price
FROM Product
WHERE product_id IN (SELECT product_id
FROM ShopProduct
WHERE shop_id = '000C');
| product_name | sale_price |
|---|---|
| 叉子 | 500 |
| 运动T恤 | 4000 |
| 菜刀 | 3000 |
| 擦菜板 | 880 |
- EXIST的参数
之前我们学过的谓词,基本上都是像“列 LIKE 字符串”或者“列 BETWEEN 值1 AND 值2”这样需要指定2个以上的参数,而EXIST的左侧并没有任何参数。很奇妙吧?这是因为EXIST是只有1个参数的谓词。EXIST只需要在右侧书写1个参数,该参数通常都会是一个子查询。
(
SELECT product_id FROM dbo.ShopProduct sp WHERE shop_id = '000C'
AND p.product_id = sp.product_id
)
上面这样的子查询就是唯一的参数。确切地说,由于通过条件SP.product_id = P.product_id将Product表和ShopProduct表进行了联接,因此作为参数的是关联子查询。EXIST通常都会使用关联子查询作为参数
6-3 Case表达式
CASE表达式的语法分为简单CASE表达式和搜索CASE表达式两种。
--简单 CASE 语法
CASE <表达式>
WHEN <表达式> THEN <表达式>
WHEN <表达式> THEN <表达式>
WHEN <表达式> THEN <表达式>
. . .
ELSE <表达式>
END
--搜索 CASE 语法
CASE WHEN <求值表达式> THEN <表达式>
WHEN <求值表达式> THEN <表达式>
WHEN <求值表达式> THEN <表达式>
. . .
ELSE <表达式>
END
WHEN子句中的“<求值表达式>”就是类似“列 = 值”这样,我们也可以将其看作使用=、!=或者LIKE、BETWEEN等谓词编写出来的表达式。
例子:要得到如下结果
A:衣 服
B:办 公 用 品
C:厨 房 用 具
因为表中的记录并不包含“A: ”或者“B: ”这样的字符串,所以需要在SQL中进行添加。
SELECT CASE WHEN product_type = '衣服' THEN 'A:' + product_type
WHEN product_type = '办公用品' THEN 'B:' + product_type
WHEN product_type = '厨房用具' THEN 'C:' + product_type
ELSE NULL
END
FROM dbo.Product;
--简单CASE
SELECT CASE product_type WHEN '衣服' THEN 'A:' + product_type
WHEN '办公用品' THEN 'B:' + product_type
WHEN '厨房用具' THEN 'C:' + product_type
ELSE NULL
END
FROM dbo.Product;

CASE表达式的书写位置
CASE表达式的便利之处就在于它是一个表达式。之所以这么说,是因为表达式可以书写在任意位置,也就是像“1 + 1”这样写在什么位置都可以的意思。例如,我们可以利用CASE表达式将下述SELECT语句结果中的行和列进行互换。
要实现下面的结果:
| sum_price_clothes | sum_price_kitchen | sum_price_office |
|---|---|---|
| 5000 | 11180 | 600 |
上述结果是根据商品种类计算出的销售单价的合计值,通常我们将商品种类列作为GROUP BY子句的聚合键来使用,但是这样得到的结果会以“行”的形式输出,而无法以列的形式进行排列。
SELECT product_type,
SUM(sale_price) AS sum_price
FROM Product
GROUP BY product_type;
但是结果是:
| product_type | sum_price |
|---|---|
| 衣服 | 5000 |
| 办公用品 | 600 |
| 厨房用具 | 11180 |
我们可以像代码清单6-43那样在SUM函数中使用CASE表达式来获得一个3列的结果。
-- 对按照商品种类计算出的销售单价合计值进行 行列转换
SELECT SUM(CASE WHEN product_type = '衣服'
THEN sale_price ELSE 0 END) AS sum_price_clothes,
SUM(CASE WHEN product_type = '厨房用具'
THEN sale_price ELSE 0 END) AS sum_price_kitchen,
SUM(CASE WHEN product_type = '办公用品'
THEN sale_price ELSE 0 END) AS sum_price_office
FROM Product;
练习题:
按照销售单价(sale_price)对练习 6.1中的 Product (商品)表中的商品进行如下分类。
● 低档商品:销售单价在1000日元以下(T恤衫、办公用品、叉子、擦菜板、圆珠笔)
● 中档商品:销售单价在1001日元以上3000日元以下(菜刀)
● 高档商品:销售单价在3001日元以上(运动T恤、高压锅)
请编写出统计上述商品种类中所包含的商品数量的 SELECT语句,结果如下所示。
| low_price | mid_price | high_price |
|---|---|---|
| 5 | 1 | 2 |
答案:
SELECT
COUNT(CASE when sale_price<=1000 THEN sale_price END) AS low_price,
COUNT(CASE when sale_price>1001 AND sale_price<=3000 THEN sale_price END) AS mid_price,
COUNT(CASE when sale_price>3001 THEN sale_price END) AS high_price
FROM dbo.Product
第八章 SQL高级处理
8-1 窗口函数(OLAP函数 或 分析函数)
窗口语法
<窗口函数> OVER ([PARTITION BY <列清单>]
ORDER BY <排序用列清单>)
其中重要的关键字是PARTITION BY和ORDER BY,理解这两个关键字的作用是帮助我们理解窗口函数的关键。
① 能够作为窗口函数的聚合函数(SUM、AVG、COUNT、MAX、MIN)
②RANK、DENSE_RANK、ROW_NUMBER等专用窗口函数
例子:根据不同的商品种类,按照销售单价从低到高的顺序创建排序表
| product_name | product_type | sale_price | ranking |
|---|---|---|---|
| 叉子 | 厨房用具 | 500 | 1 |
| 擦菜板 | 厨房用具 | 880 | 2 |
| 菜刀 | 厨房用具 | 3000 | 3 |
| 高压锅 | 厨房用具 | 6800 | 4 |
| T恤衫 | 衣服 | 1000 | 1 |
| 运动T恤 | 衣服 | 4000 | 2 |
| 圆珠笔 | 办公用品 | 100 | 1 |
| 打孔器 | 办公用品 | 500 | 2 |
SELECT product_name, product_type, sale_price,
RANK () OVER (PARTITION BY product_type
ORDER BY sale_price) AS ranking
FROM Product;
PARTITION BY能够设定排序的对象范围。本例中,为了按照商品种类进行排序,我们指定了product_type。
ORDER BY能够指定按照哪一列、何种顺序进行排序。为了按照销售单价的升序进行排列,我们指定了sale_price。此外,窗口函数中的ORDER BY与SELECT语句末尾的ORDER BY一样,可以通过关键字ASC/DESC来指定升序和降序。

窗口函数兼具分组和排序两种功能。
通过 PARTITION BY分组后的记录集合称为窗口。此处的窗口并非“窗户”的意思,而是代表范围。这也是“窗口函数”名称的由来。
无需指定PARTITION BY
SELECT product_name, product_type, sale_price,
RANK () OVER (ORDER BY sale_price) AS ranking
FROM Product;
| product_name | product_type | sale_price | ranking |
|---|---|---|---|
| 圆珠笔 | 办公用品 | 100 | 1 |
| 叉子 | 厨房用具 | 500 | 2 |
| 打孔器 | 办公用品 | 500 | 2 |
| 擦菜板 | 厨房用具 | 880 | 4 |
| T恤衫 | 衣服 | 1000 | 5 |
| 菜刀 | 厨房用具 | 3000 | 6 |
| 运动T恤 | 衣服 | 4000 | 7 |
| 高压锅 | 厨房用具 | 6800 | 8 |
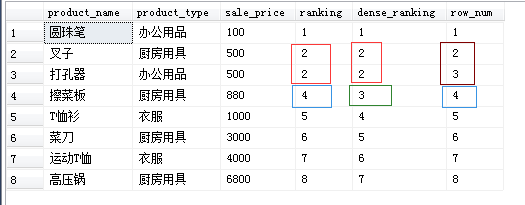
专用窗口函数的种类
- RANK函数
计算排序时,如果存在相同位次的记录,则会跳过之后的位次。
例)有 3条记录排在第 1位时:1位、1位、1位、4位…… - DENSE_RANK函数
同样是计算排序,即使存在相同位次的记录,也不会跳过之后的位次。
例)有 3条记录排在第 1位时:1位、1位、1位、2位…… - ROW_NUMBER函数
赋予唯一的连续位次。
例)有 3条记录排在第 1位时:1位、2位、3位、4位……
SELECT product_name, product_type, sale_price,
RANK () OVER (ORDER BY sale_price) AS ranking,
DENSE_RANK () OVER (ORDER BY sale_price) AS dense_ranking,
ROW_NUMBER () OVER (ORDER BY sale_price) AS row_num
FROM Product;
作为窗口函数使用的聚合函数
- 将SUM函数作为窗口函数使用
SELECT product_id, product_name, sale_price,
SUM(sale_price) OVER (ORDER BY product_id) AS current_sum
FROM Product;

计算该合计值的逻辑就像金字塔堆积那样,一行一行逐渐添加计算对象。在按照时间序列的顺序,计算各个时间的销售额总额等的时候,通常都会使用这种称为累计的统计方法。
- 将AVG函数作为窗口函数使用
SELECT product_id, product_name, sale_price,
AVG (sale_price) OVER (ORDER BY product_id) AS current_avg
FROM Product;
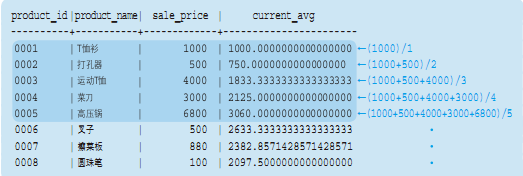
计算移动平均
窗口函数就是将表以窗口为单位进行分割,并在其中进行排序的函数。其实其中还包含在窗口中指定更加详细的汇总范围的备选功能,该备选功能中的汇总范围称为框架。
需要在ORDER BY子句之后使用指定范围的关键字。
--指定“最靠近的3行”作为汇总对象
SELECT product_id, product_name, sale_price,
AVG (sale_price) OVER (ORDER BY product_id
ROWS 2 PRECEDING) AS moving_avg
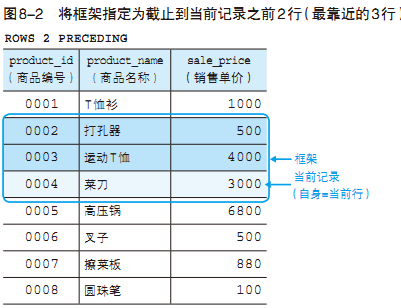
FROM Product;
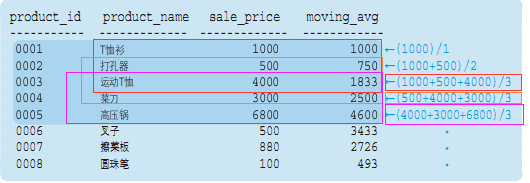
这里我们使用了ROWS(“行”)和PRECEDING(“之前”)两个关键字,将框架指定为“截止到之前~行 ”, 因 此 “ROWS 2 PRECEDING”就是将框架指定为“截止到之前2行”,也就是将作为汇总对象的记录限定为如下的“最靠近的3行 ”
这样的统计方法称为移动平均(moving average)。由于这种方法在希望实时把握“最近状态”时非常方便,因此常常会应用在对股市趋势的实时跟踪当中。
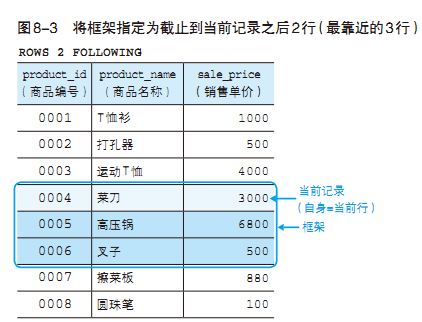
使用关键字FOLLOWING(“ 之 后 ”) 替 换PRECEDING,就可以指定“截止到之后~行”作为框架了(图8-3)。
8-2 GROUPING运算符
同时得到合计行

使用GROUP BY无法得到合计行
SELECT product_type, SUM(sale_price)
FROM Product
GROUP BY product_type;
| product_type | sum |
|---|---|
| 衣服 | 5000 |
| 办公用品 | 600 |
| 厨房用具 | 11180 |
如果想要获得那样的结果,通常的做法是分别计算出合计行和按照商品种类进行汇总的结果,然后通过 UNION ALL 连接在一起(代码清单8-11)。
SELECT '合计' AS product_type, SUM(sale_price)
FROM Product
UNION ALL
SELECT product_type, SUM(sale_price)
FROM Product
GROUP BY product_type;
| product_type | sum |
|---|---|
| 合计 | 16780 |
| 衣服 | 5000 |
| 办公用品 | 600 |
| 厨房用具 | 11180 |
这样一来,为了得到想要的结果,需要执行两次几乎相同的SELECT语句,再将其结果进行连接,不但看上去十分繁琐,而且DBMS内部的处理成本也非常高,难道没有更合适的实现方法了吗?
ROLLUP——同时得出合计和小计
ROLLUP的中文翻译是
汇总,卷曲,比如卷起百叶窗、窗帘卷,等等。其名称也形象地说明了该操作能够得到像从小计到合计这样,从最小的聚合级开始,聚合单位逐渐扩大的结果。
GROUPING运算符包含以下3种
ROLLUPCUBEGROUPING SETS
该运算符的作用,一言以蔽之,就是“一次计算出不同聚合键组合的结果”
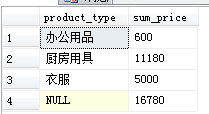
SELECT product_type, SUM(sale_price) AS sum_price
FROM Product
GROUP BY ROLLUP(product_type);
■将“登记日期”添加到聚合键当中
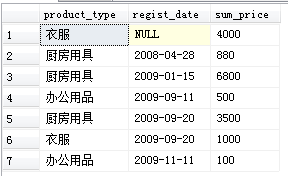
在GROUP BY中添加“登记日期”(不使用ROLLUP)
SELECT product_type, regist_date, SUM(sale_price) AS sum_price
FROM Product
GROUP BY product_type, regist_date;
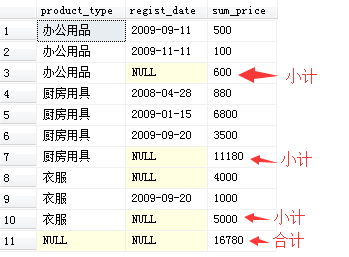
在GROUP BY中添加“登记日期”(使用ROLLUP)
SELECT product_type, regist_date, SUM(sale_price) AS sum_price
FROM Product
GROUP BY ROLLUP(product_type, regist_date);
GROUPING函数——让NULL更加容易分辨
之前使用ROLLUP所得到的结果有些蹊跷,问题就出在“衣服”的分组之中,有两条记录的regist_date列为NULL,但其原因却并不相同。

为了避免混淆,SQL提供了一个用来判断超级分组记录(合计行记录)的NULL的特定函数—— GROUPING函数。
该函数在其参数列的值为超级分组记录所产生的NULL时返回1,其他情况返回0。
SELECT GROUPING(product_type) AS product_type,
GROUPING(regist_date) AS regist_date, SUM(sale_price) AS sum_price
FROM Product
GROUP BY ROLLUP(product_type, regist_date);

这样就能分辨超级分组记录中的NULL和原始数据本身的NULL了。
在超级分组记录的键值中插入恰当的字符串
SELECT CASE WHEN GROUPING(product_type) = 1 THEN '商品种类 合计'
ELSE product_type
END AS product_type,
CASE WHEN GROUPING(regist_date) = 1 THEN '登记日期 合计'
ELSE CAST(regist_date AS NVARCHAR(16))
END AS regist_date, SUM(sale_price) AS sum_price
FROM Product
GROUP BY ROLLUP(product_type, regist_date);

CUBE——用数据来搭积木
CUBE是“立方体”的意思,这个名字和ROLLUP一样,都能形象地说明函数的动作。
SELECT CASE WHEN GROUPING(product_type) = 1 THEN '商品种类 合计'
ELSE product_type
END AS product_type,
CASE WHEN GROUPING(regist_date) = 1 THEN '登记日期 合计'
ELSE CAST(regist_date AS NVARCHAR(16))
END AS regist_date, SUM(sale_price) AS sum_price
FROM Product
GROUP BY cube(product_type, regist_date)
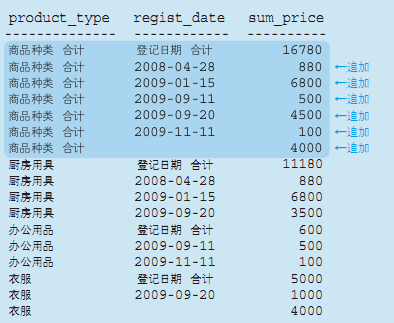
在ROLLUP的基础上多出几条,多出来的记录就是只把regist_date作为聚合键所得到的汇总结果。
CUBE与ROLLUP的区别

等价于
SELECT CASE WHEN GROUPING(product_type) = 1 THEN '商品种类 合计'
ELSE product_type
END AS product_type,
CASE WHEN GROUPING(regist_date) = 1 THEN '登记日期 合计'
ELSE CAST(regist_date AS NVARCHAR(16))
END AS regist_date, SUM(sale_price) AS sum_price
FROM Product
GROUP BY ROLLUP(product_type, regist_date)
UNION
SELECT '商品种类 合计',CAST(regist_date AS VARCHAR(16)),SUM(sale_price) FROM Product
GROUP BY regist_date
所谓CUBE,就是将GROUP BY子句中聚合键的“所有可能的组合”的汇总结果集中到一个结果中。因此,组合的个数就是2n(n是聚合键的个数)。本例中聚合键有2个,所以22 = 4。如果再添加1个变为3个聚合键的话,就是23 = 8

GROUPING SETS——取得期望的积木
如果希望从中选取出将“商品种类”和“登记日期”各自作为聚合键的结果,或者不想得到“合计记录和使用2个聚合键的记录”时,可以使用GROUPING SETS
SELECT CASE WHEN GROUPING(product_type) = 1
THEN '商品种类 合计'
ELSE product_type END AS product_type,
CASE WHEN GROUPING(regist_date) = 1
THEN '登记日期 合计'
ELSE CAST(regist_date AS VARCHAR(16)) END AS regist_date,
SUM(sale_price) AS sum_price
FROM Product
GROUP BY GROUPING SETS (product_type, regist_date);

上述结果中也没有全体的合计行(16780日 元 )。 与ROLLUP或者CUBE能够得到规定的结果相对,GROUPING SETS用于从中取出个别条件对应的不固定的结果。
《SQL基础教程》的更多相关文章
- 简单物联网:外网访问内网路由器下树莓派Flask服务器
最近做一个小东西,大概过程就是想在教室,宿舍控制实验室的一些设备. 已经在树莓上搭了一个轻量的flask服务器,在实验室的路由器下,任何设备都是可以访问的:但是有一些限制条件,比如我想在宿舍控制我种花 ...
- 利用ssh反向代理以及autossh实现从外网连接内网服务器
前言 最近遇到这样一个问题,我在实验室架设了一台服务器,给师弟或者小伙伴练习Linux用,然后平时在实验室这边直接连接是没有问题的,都是内网嘛.但是回到宿舍问题出来了,使用校园网的童鞋还是能连接上,使 ...
- 外网访问内网Docker容器
外网访问内网Docker容器 本地安装了Docker容器,只能在局域网内访问,怎样从外网也能访问本地Docker容器? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动Docker容器 ...
- 外网访问内网SpringBoot
外网访问内网SpringBoot 本地安装了SpringBoot,只能在局域网内访问,怎样从外网也能访问本地SpringBoot? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装Java 1 ...
- 外网访问内网Elasticsearch WEB
外网访问内网Elasticsearch WEB 本地安装了Elasticsearch,只能在局域网内访问其WEB,怎样从外网也能访问本地Elasticsearch? 本文将介绍具体的实现步骤. 1. ...
- 怎样从外网访问内网Rails
外网访问内网Rails 本地安装了Rails,只能在局域网内访问,怎样从外网也能访问本地Rails? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动Rails 默认安装的Rails端口 ...
- 怎样从外网访问内网Memcached数据库
外网访问内网Memcached数据库 本地安装了Memcached数据库,只能在局域网内访问,怎样从外网也能访问本地Memcached数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装 ...
- 怎样从外网访问内网CouchDB数据库
外网访问内网CouchDB数据库 本地安装了CouchDB数据库,只能在局域网内访问,怎样从外网也能访问本地CouchDB数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动Cou ...
- 怎样从外网访问内网DB2数据库
外网访问内网DB2数据库 本地安装了DB2数据库,只能在局域网内访问,怎样从外网也能访问本地DB2数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动DB2数据库 默认安装的DB2 ...
- 怎样从外网访问内网OpenLDAP数据库
外网访问内网OpenLDAP数据库 本地安装了OpenLDAP数据库,只能在局域网内访问,怎样从外网也能访问本地OpenLDAP数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动 ...
随机推荐
- Linux记录-重启后磁盘丢失问题解决方案
1.df -TH 查看挂载情况 2.fdisk -l 查看磁盘情况 3.blkid 查看磁盘文件系统 4.vim /etc/fstab 加入 /dev/xvdf ext4 defaults 0 ...
- JAVA-大白话探索JVM-类加载过程(二)
首先我们知道JVM是什么以及类加载器的作用 不清楚的可以看看JAVA-大白话探索JVM-类加载器(一) 现在我们来摸索下类的加载过程 首先,我们将类加载过程分为三步走 装载 链接 初始化 其中 链接 ...
- synchronized实现原理
线程安全是并发编程中的重要关注点,应该注意到的是,造成线程安全问题的主要诱因有两点,一是存在共享数据(也称临界资源),二是存在多条线程共同操作共享数据.因此为了解决这个问题,我们可能需要这样一个方案, ...
- 5W2H分析法
- 10 SpringBoot全面接管SpringMVC
Spring Boot官方文档描述 If you want to keep Spring Boot MVC features and you want to add additional MVC co ...
- KillerBee
KillerBee介绍 KillerBee----是攻击zigbee和IEEE 802.15.4网络的框架和工具.使用killerBee工具和一个兼容的IEEE 802.15.4无线接口,你就能窃取z ...
- BZOJ 4614[Wf2016]Oil
权限题鸭qwq 首先可以知道最优答案选出来的直线一定可以经过某条线段左端点,如果这条直线没有过左端点,可以通过平移和旋转等操作达到.所以可以枚举这条直线过了哪条线段的左端点,那么对于其他线段,能对答案 ...
- django学习~第四篇
django表单 1 今天继续来学学django的表单 首先介绍下http的方法,这是最基本的 GET 方法 GET一般用于获取/查询 资源信息,以?分割URL和传输数据 ...
- java 多线程面试
一.多线程的创建 1.多线程的创建 (1).继承Thread类 (2).实现Runnable接口 2.两种启动线程方法的区别 1.共同点 必须调用Thread 产生线程,然后调用start()方法 开 ...
- 使用neo4j-import工具导入数据
从Neo4j2.2版本开始,系统就自带了一个大数据量的导入工具:neo4j-import,可支持并行.可扩展的大规模csv数据导入(本例版本为:3.4.7版本) 1.前提条件 关闭neo4j 无法在原 ...