Hive Shell 命令详解
Hive服务介绍
Hive默认提供的cli(shell)服务,如果需要启动其他服务,那么需要service参数来启动其他服务,比如thrift服务、metastore服务等。可以通过命令hive --service help查看hive支持的命令。
Hive Shell命令介绍
Hive的shell命令是通过${HIVE_HOME}/bin/hive文件进行控制的,通过该文件我们可以进行hive当前会话的环境管理、也进行进行hive的表管理等操作。hive命令需要使用';'进行结束标示。通过hive -H查看帮助信息:另外从hive0.11版本开始支持--database <databasename>.
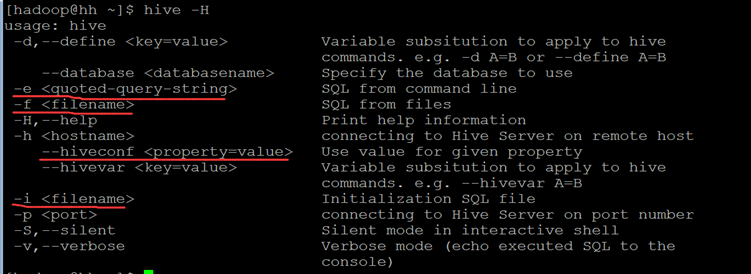
Hive Shell常用基本命令
Hive的Shell基本常用命令主要包含退出客户端、添加文件、修改/查看环境变量、执行linux命令、执行dfs命令等。命令包括:
quit、exit、set、add JAR[S] <filepath> <filepath>*、list JAR[S]、delete JAR[S] <filepath>*、! <linux-command>、dfs <dfs command>等。
除了Hive的基本命令外,其他的命令主要是DDL和DML等操作数据表的命令。
HiveQL介绍
HiveQL简称HQL,是一种类似sql的查询语言,绝大多数语法和sql类似。HQL支持基本类型和复杂类型两大类数据类型。
基本类型包括TINYINT(1byte), SMALLINT(2byte), INT(4byte), BIGINT(8byte), FLOAT(4byte), DOUBLE(8byte), BOOLEAN(-), STRING(2G)。
复杂类型包括ARRAY(一组有序数组,类型必须一致), MAP(无序键值对,键值内部字段类型必须相同,而且要求key的类型为基本数据类型), STRUCT(一组字段,类型任意)。
show、describe、explain命令介绍
show命令的主要作用是查看database、table、function等组件的名称信息,也就是通过show命令我们可以知道我们的hive中有那些database;当前database中有那些table。等等。和mysql的show命令类型。
describe命令的主要作用是获取database、table、partition的具体描述信息,包括存储位置、字段类型等信息。
explain命令的主要作用是获取hql语句的执行计划,我们可以通过分析这些执行计划来优化hql语句。

Database介绍
hive提供database的定义,database的主要作用是提供数据分割的作用,方便数据管理。命令如下:
创建: create (DATABASE|SCHEMA) [IF NOT EXISTS] database_name [COMMENT database_comment] [LOCATION hdfs_path] [WITH DBPROPERTIES (property_name=value,name=value....)]。
显示描述信息:describe DATABASE|SCHEMA [extended] database_name。
删除:DROP DATABASE|SCHEMA [IF EXISTS] database_name [RESTRICT|CASCADE]
使用: use database_name。
Hive表介绍
Hive中的表可以分为内部表(托管表)和外部表,区别在于:外部表的数据不是有hive进行管理的,也就是说当删除外部表的时候,外部表的数据不会从hdfs中删除。而内部表是又hive进行管理的,在删除表的时候,数据也会删除。一般情况下,我们在创建外部表的时候会将表数据的存储路径定义在hive的数据仓库路径之外。
Hive创建表主要有三种方式,第一种直接使用create table命令,第二种使用create table .... AS select ....(会产生数据)。第三种使用create table tablename like exist_tablename.命令。
create table命令介绍

案例1:
先将data2.txt文件上传到hdfs的/customers文件夹中。
hdfs dfs -mkdir /customers
hdfs dfs -put data2.txt /customers
案例2:
先将data3.txt文件上传到hdfs的/complex_table_test文件夹中。
hdfs dfs -mkdir /complex_table_test
hdfs dfs -put data2.txt /complex_table_test
案例3:
hive和hbase关联
create external table hive_users
(key string,
id int,
name string,
phone string)
row format serde 'org.apache.hadoop.hive.hbase.HBaseSerDe'
stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
with serdeproperties('hbase.columns.mapping'=':key,f:id,f:name,f:phone')
tblproperties('hbase.table.name'='users');
Hive shell 命令深入使用
前置条件:
hive启动
root用户登录 密码123456
启动mysql:service mysqld restart
使用hadoop用户登录,启动metastore:hive --service metastore &
数据文件准备
将文档文件夹中的classes.txt和students.txt移动到linux机器和hdfs文件系统上。
命令:hdfs dfs -put ./13 /kai/
创建hive相关表准备:
create database kai13;
create table students(studentId int comment 'this is student id, is not null', classId int comment 'this is class id, can set to null', studentName string comment 'this is student name') row format delimited fields terminated by ',';
create table classes(classId int comment 'this is class id, is not null', className string comment 'this is class name') row format delimited fields terminated by ',';
一、导入数据
1. 分别导入local和hdfs的数据
a. 分别从linux机器上导入数据
load data local inpath '/home/hadoop/datas/13/classes.txt' into table classes;
load data local inpath '/home/hadoop/datas/13/students.txt' into table students;
load data local inpath '/home/hadoop/datas/13/classes.txt' overwrite into table classes;
b. 从hdfs上导入数据
load data inpath '/kai/13/students.txt' into table students;
dfs -put /home/hadoop/datas/13/students.txt /kai/13/
load data inpath '/kai/13/students.txt' overwrite into table students;
2. 导入其他表的数据(多表插入)
将学生表的学生id和classid分别导出到不同表中,
create table test1(id int);
create table test2(id int);
from students insert into table test1 select studentid insert overwrite table test2 select distinct classid where classid is not null;
二、select语法介绍
from语法
1. 正常from:
select * from students;
2. from语句提前:
from students select *;
cte语法:
1. 获取班级号为1的学生信息:
with tmp as (select studentid as sid,classid as cid,studentname as name from students where classid=1) from tmp select *;
2. 获取总学生数、已经分配班级的学生数、未分配班级的学生数(作业1)。
分析;
总学生数:studentid的总数
分配班级的学生数:classid不为空的学生总数
未分配的学生数: classid为空的学生数
结果: 12 7 5
where & group by语法实例:
group语句只能返回对于的group列&进行聚合的value。
1. 获取学生数大于3的班级id
from students select classid where classid is not null group by classid having count(studentid) > 3;
排序语法:
1. 使用order by根据学生id倒序。
select * from students order by studentid desc;
2. 设置hive.mapred.mode为strict,然后在进行order by操作。
set hive.mapred.mode=strict;
select * from students order by studentid desc; 会出现异常
select * from students order by studentid desc limit 5;
3. 使用sort by根据学生id排序。
select * from students sort by studentid desc;
4. 设置mapreduce.job.reduces个数为两个,然后再使用sort by进行排序。
set mapreduce.job.reduces=2;
select * from students sort by studentid desc;
三、join语法
内连接语法
1. 获取学生和班级之间完全匹配的数据。
select students.*,classes.* from classes join students on classes.classid=students.classid;
select students.*,classes.* from classes cross join students on classes.classid=students.classid;
外链接语法:
1. 获取全部学生的班级信息,如果该学生没有分配班级,那么班级信息显示为null。
select students.*, classes.* from students left join classes on students.classid = classes.classid;
2. 获取全部班级的学生信息,如果某个班级没有学生,那么学生信息显示为null。(作业2)
3. 获取全部信息,如果没有匹配数据的显示null。(作业3)
半连接:
1. 获取学生表中班级id在班级表中的所有学生信息。
sql: select students.* from students where classid in (select distinct classid from classes);
原hql: select students.* from students join classes on students.classid = classes.classid;
新hql: select students.* from students left semi join classes on students.classid=classes.classid;
mapjoin:
select /*+ mapjoin(classes) */ * from students join classes on students.classid=classes.classid;
四、子查询
1. 获取学生数最多的班级,学生的个数。
第一步:获取每个班级的学生总数
第二步:选择学生数最多的班级学生数
from (select count(studentid) as sc from students where classid is not null group by classid) as tmp select max(sc);
2. 获取学生数最多的班级信息。(作业4)
第一步:获取每个班级的学生总数
第二步:选择学生数最多的班级学生数
第三步:根据最多的学生数和第一步获取的表数据进行比较,获取班级信息。
五、导出数据
1. 导出表关联后的班级名称和学生名称(loca&hdfs)。(导出全部不为空的信息)
班级1,学生1
from (select classes.classname as col1, students.studentname as col2 from classes join students on classes.classid = students.classid) as tmp insert overwrite local directory '/home/hadoop/result/13/01' select col1,col2 insert overwrite directory '/kai/result/13/01/' select col1,col2 ;
格式化:
from (select classes.classname as col1, students.studentname as col2 from classes join students on classes.classid = students.classid) as tmp insert overwrite local directory '/home/hadoop/result/13/01' row format delimited fields terminated by ',' select col1,col2 ;
2. 同时分别将已经分配班级的学生和未分配班级的学生导出到不同的文件夹中。
六、其他命令
1. 在students和classes表上创建一个视图,视图包含两列分别是:班级名称,学生名称
create view viewname as select classes.classname as cname, students.studentname as sname from classes join students on classes.classid = students.classid
2. 在linux系统中通过命令hive -f/-e将所有学生信息保存到一个文件中。
新建一个文件,文件内容为:
select * from students
执行:hive --database kai13 -f test.sql >> result.txt
Hive Shell 命令详解的更多相关文章
- adb shell 命令详解,android
http://www.miui.com/article-275-1.html http://noobjava.iteye.com/blog/1914348 adb shell 命令详解,android ...
- 【Devops】【docker】【CI/CD】关于jenkins构建成功后一步,执行的shell命令详解+jenkins容器运行宿主机shell命令的实现方法
1.展示这段shell命令 +详解 #================================================================================= ...
- Linux主要shell命令详解(上)
[摘自网络] kill -9 -1即实现用kill命令退出系统 Linux主要shell命令详解 [上篇] shell是用户和Linux操作系统之间的接口.Linux中有多种shell,其中缺省使用的 ...
- adb shell 命令详解,android, adb logcat
http://www.miui.com/article-275-1.html http://noobjava.iteye.com/blog/1914348 adb shell 命令详解,android ...
- hadoop Shell命令详解
调用文件系统(FS)Shell命令应使用bin/hadoop fs <args>的形式.所有的的FS shell命令使用URI路径作为参数.URI路径详解点击这里. 1.cat说明:将路径 ...
- adb shell 命令详解(转)
adb介绍 SDK的Tools文件夹下包含着Android模拟器操作的重要命令adb,adb的全称为(Android Debug Bridge就是调试桥的作用.通过adb我们可以在Eclipse中方面 ...
- adb shell 命令详解
adb介绍 SDK的Tools文件夹下包含着Android模拟器操作的重要命令adb,adb的全称为(Android Debug Bridge就是调试桥的作用.通过adb我们可以在Eclipse中方面 ...
- Linux主要shell命令详解(中)
shell中的特殊字符 shell中除使用普通字符外,还可以使用一些具有特殊含义和功能的特殊字符.在使用它们时应注意其特殊的含义和作用范围.下面分别对这些特殊字符加以介绍. 1. 通配符 通配符用于模 ...
- Linux主要shell命令详解(下)
命令行编辑操作 功能 Ctrl+b或左箭头键 左移一个字符(移至前一个字符) Ctrl+f或右箭头键 右移一个字符(移至后一个字符) Ctrl+a 移至行首 Ctrl+e 移至行尾 Esc b 左移一 ...
随机推荐
- 2019-03-11-day009-函数定义
什么是函数 函数就是将许多冗余的代码进行整合统一调用的内存地址 函数怎么定义 def make(): print('掏出手机') print('打开微信') print('摇一摇') print('聊 ...
- m3u8编码视频webgl、threejs渲染视频纹理demo
<!DOCTYPE html> <html> <head> <meta charset=utf-8 /> <title>fz-live< ...
- 在PHP5.4上使用Google翻译的API报错
/********************************************************************** * 在PHP5.4上使用Google翻译的API报错 * ...
- git get submodule after clone
/********************************************************************************* * git get submodu ...
- $interpolateProvider
angular.module('emailParser', []) .config(['$interpolateProvider', function($interpolateProvider) { ...
- Unity 3D调用Windows打开、保存窗口、文件浏览器
Unity调用Window窗口 本文提供全流程,中文翻译. Chinar 坚持将简单的生活方式,带给世人!(拥有更好的阅读体验 -- 高分辨率用户请根据需求调整网页缩放比例) Chinar -- 心分 ...
- Gym 101889:2017Latin American Regional Programming Contest(寒假自训第14场)
昨天00.35的CF,4点才上床,今天打的昏沉沉的,WA了无数发. 题目还是满漂亮的. 尚有几题待补. C .Complete Naebbirac's sequence 题意:给定N个数,他们在1到K ...
- 矩阵快速幂(以HDU1757为例)
对于数据量大的求余运算,在有递推式的情况下,可以构造矩阵求解. A - A Simple Math Problem Lele now is thinking about a simple functi ...
- next_permutation函数和per_permiutation函数
next_permutation用于求有序数组里面的下一个排序,形式为next_permutation(数组名,数组名+n)
- PTA——天平找小球
PTA 7-22 用天平找小球 #include<stdio.h> int main() { int a,b,c; scanf("%d%d%d",&a,& ...