Weka里如何将arff文件或csv文件批量导入MySQL数据库(六)
这里不多说,直接上干货!
前提博客是
Weka中数据挖掘与机器学习系列之数据格式ARFF和CSV文件格式之间的转换(四)
1、将arff文件批量导入MySQL数据库
我在这里,arff文件以Weka安装目录下data文件夹中的iris.arff文件为例。

这个很简单,直接open file,不多说。
2、将csv文件批量导入MySQL数据库
首选,需要先删除csv文件中第一行对属性名的描述,如下图。

得到
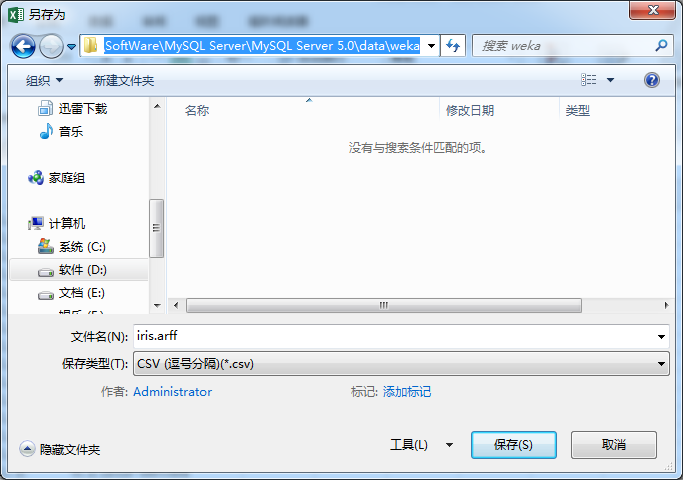
然后,我这里保存到,D:\SoftWare\MySQL Server\MySQL Server 5.0\data\weka


然后,再这里,要先在weka数据库里,先建立表 不然它怎么知道往哪里导数据呢?

科普一下,float 和 real 数据类型被称为近似的数据类型。

或者,直接使用命令行界面,多么的爽 (建议,用命令行界面来操作!!!)
create table iris(sepallength REAL,sepalwidth REAL,petallength REAL,petalwidth REAL,class VARCHAR());


养成习惯,立马去查看数据库的属性


并在命令行下执行以上批处理语句:
load data infile '\iris.csv'
into table iris
fields terminated by ',' optionally enclosed by '"' escaped by '"'
lines terminated by '\r\n';
因为,这会直接,去加载(默认),

直接把命令,复制进去



是一模一样的!
当然,大家,不仅可以这样,通过MySQL命令行来加载导入MySQL数据库。大家也可以通过如下的java代码来导入哈!
新建java工程,导入驱动包和weka包。进行代码编写和设计。
package sdust.lab207.data; import java.io.File; import weka.core.Instance;
import weka.core.Instances;
import weka.core.converters.ArffLoader;
import weka.core.converters.DatabaseLoader;
import weka.core.converters.ConverterUtils.DataSource;
import weka.experiment.InstanceQuery; /**
* @author LbZhang
* @version 创建时间:2016年6月10日 上午10:16:23
* @description 数据加载 weka.core.Instances;
1.Weka处理的数据表格中,一个横行称为一个实例(Instance),竖行代表一个属性(Arrtibute),数据表格称为一个数据集,在weka看来,呈现了属性之间的一种关系(Relation)
2.Weka存储数据的格式是ARFF(Attribute-RelationFile Format)文件,这是一种ASCII文本文件。
3.Weka的ARFF文件可以分为两部分。第一部分给出了头信息(Head information),包括了对关系的声明和对属性的声明。第二部分给出了数据信息(Data information),即数据集中给出的数据。从@Data标记开始,后面的就是数据信息了。
4.Weka作为数据挖掘,面临的第一个问题往往是我们的数据不是ARFF格式的。幸好,WEKA还提供了对CSV文件的支持,而这种格式是被许多其他软件所支持的。此外,WEKA还提供了通过JDBC访问数据库的功能。
*/
public class DataLoad { /**
* Open Declaration weka.core.converters.ConverterUtils.DataSource
* DataSource(数据源)类是weka.core.converters.ConverterUtils的内部类,用于从有适当文件扩展名的文件中读取数据。
*
*
*/ public static void main(String[] args) { //DataLoad.testFileload();
DataLoad.testDBload(); } private static void testDBload() {
try {
//InstanceQuery使用
InstanceQuery iq = new InstanceQuery();
iq.setDatabaseURL("jdbc:mysql://127.0.0.1:3306/jdtaobao");
iq.setUsername("root");
iq.setPassword("root");
iq.setQuery("SELECT * FROM tb_timestat");
//iq.setSparseData(true);
Instances ist = iq.retrieveInstances(); System.out.println(ist.checkForStringAttributes()); System.out.println(ist.get());
System.out.println(ist.attributeStats());
// System.out.println(ist.get(2)); DatabaseLoader dloader = new DatabaseLoader();
String jdurl="jdbc:mysql://127.0.0.1:3306/jdtaobao";
String user = "root";
String pass = "root";
dloader.setSource(jdurl,user,pass);
dloader.setQuery("SELECT * FROM tb_timestat");
//批量检索
Instances data = dloader.getDataSet();
// System.out.println(data.classIndex());
// System.out.println(data.size());
// System.out.println(data.get(0));
System.out.println(data.get(data.size()-));
System.out.println(data);
System.out.println(); //增量检索
DatabaseLoader diloader = new DatabaseLoader();
diloader.setSource(jdurl,user,pass);
diloader.setQuery("SELECT * FROM tb_user"); Instances structure = diloader.getStructure(); Instances insts = new Instances(structure);
Instance inst ;
while((inst=diloader.getNextInstance(structure))!=null){
System.out.println(inst);
insts.add(inst);
}
System.out.println(insts); } catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
} } private static void testFileload() {
try { // 读取数据代码片段
Instances data1 = DataSource.read("data\\cpu.arff");
Instances data2 = DataSource.read("data\\cpu.arff");
// 当要加载的文件的与加载器通常关联的文件扩展名不同时,用户只能直接指定加载器。
// 加载arrf文件代码片段
ArffLoader loader = new ArffLoader();
loader.setSource(new File("data\\cpu.arff"));
Instances data = loader.getDataSet();// 获取数据集合 System.out.println(data.classIndex()); // 如果没有设置类别属性
if (data.classIndex() == -)
data.setClassIndex();
// 使用第一个属性作为类别属性
if (data.classIndex() == -)
data.setClassIndex(data.numAttributes()-); if (data.classIndex() == -) {//如果没有设置类别属性列
System.out.println(data1.get());
}
//System.out.println(data.attribute(0)); } catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
} } }
我们这里使用的是mysql数据库,所以我们将DatabaseUtils.props.mysql取代DatabaseUtils.props,并且修改文件的内容。
主要是将内容修改为:
第一步:配置相关的数据库驱动和链接信息
# Database settings for MySQL 3.23.x, .x
#
# General information on database access can be found here:
# http://weka.wikispaces.com/Databases
#
# url: http://www.mysql.com/
# jdbc: http://www.mysql.com/products/connector/j/
# author: Fracpete (fracpete at waikato dot ac dot nz)
# version: $Revision: $ # JDBC driver (comma-separated list)
#jdbcDriver=org.gjt.mm.mysql.Driver
jdbcDriver=com.mysql.jdbc.Driver # database URL
#jdbcURL=jdbc:mysql://server_name:3306/database_name
jdbcURL=jdbc:mysql://localhost:3306/weka
第二步: 类型去掉注释
# specific data types
string, getString() = ; --> nominal
boolean, getBoolean() = ; --> nominal
double, getDouble() = ; --> numeric
byte, getByte() = ; --> numeric
short, getByte()= ; --> numeric
int, getInteger() = ; --> numeric
long, getLong() = ; --> numeric
float, getFloat() = ; --> numeric
date, getDate() = ; --> date
text, getString() = ; --> string
time, getTime() = ; --> date
timestamp, getTime() = ; --> date
第三步:添加字符转换方式
#mysql-conversion
#Text
CHAR=
TINYTEXT=
TEXT=
VARCHAR=
LONGVARCHAR=
BINARY=
VARBINARY=
LONGVARBINARY=
BLOB=
MEDIUMTEXT=
MEDIUMBLOB=
LONGTEXT=
LONGBLOB= #Number types
BIT=
NUMERIC=
DECIMAL=
FLOAT=
DOUBLE=
TINYINT=
SMALLINT=
#SHORT=
SHORT=
INTEGER=
INT=
MEDIUMINT=
BIGINT=
LONG=
INT_UNSIGNED= #Data Types
REAL=
DATE=
TIME=
TIMESTAMP=
DATETIME= # other options
CREATE_DOUBLE=DOUBLE
CREATE_STRING=TEXT
CREATE_INT=INT
CREATE_DATE=DATETIME
DateFormat=yyyy-MM-dd HH:mm:ss
checkUpperCaseNames=false
checkLowerCaseNames=false
checkForTable=true
第三步:添加字符转换方式
#mysql-conversion
#Text
CHAR=
TINYTEXT=
TEXT=
VARCHAR=
LONGVARCHAR=
BINARY=
VARBINARY=
LONGVARBINARY=
BLOB=
MEDIUMTEXT=
MEDIUMBLOB=
LONGTEXT=
LONGBLOB= #Number types
BIT=
NUMERIC=
DECIMAL=
FLOAT=
DOUBLE=
TINYINT=
SMALLINT=
#SHORT=
SHORT=
INTEGER=
INT=
MEDIUMINT=
BIGINT=
LONG=
INT_UNSIGNED= #Data Types
REAL=
DATE=
TIME=
TIMESTAMP=
DATETIME=
可能大家会出现如下的问题:
couldn’t read from database unknown data type: INT, Add Entry in weka/experiment/DatabaseUtils.props.
错误处理
问题解决:
主要是因为数据库数据类型 java 数据类型还有weka 数据类型的匹配导致的。
因此第三步是十分重要的!
INT_UNSIGNED=6
VARCHAR=0
等一定要注意INT_UNSIGNED的连接下划线。
Weka里如何将arff文件或csv文件批量导入MySQL数据库(六)的更多相关文章
- SpringMVC文件上传 Excle文件 Poi解析 验证 去重 并批量导入 MYSQL数据库
SpringMVC文件上传 Excle文件 Poi解析并批量导入 MYSQL数据库 /** * 业务需求说明: * 1 批量导入成员 并且 自主创建账号 * 2 校验数据格式 且 重复导入提示 已被 ...
- sql文件批量导入mysql数据库
有一百多个sql文件肿么破?一行一行地导入数据库肯定是极其愚蠢的做法,但是我差点就这么做了... 网上首先找到的方法是:写一个xxx.sql文件,里边每一行都是source *.sql ...,之后再 ...
- SQLite新建数据库及txt文件(CSV文件)导入
1.安装准备: Windows系统环境: 安装:SQLiteExpert 及 官网的SQLite tool 我们要用到其中的SQLite.exe 地址:https://www.sqli ...
- js操作一般文件和csv文件
js操作一般文件和csv文件 将文本文件读成字符串 <input type="file" id="upload"> document.getElem ...
- 将Excel文件转为csv文件的python脚本
#!/usr/bin/env python __author__ = "lrtao2010" ''' Excel文件转csv文件脚本 需要将该脚本直接放到要转换的Excel文件同级 ...
- Python之xlsx文件与csv文件相互转换
1 xlsx文件转csv文件 import xlrd import csv def xlsx_to_csv(): workbook = xlrd.open_workbook('1.xlsx') tab ...
- 【Github】如何下载csv文件/win10如何修改txt文件为csv文件
csv文件:逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号) 右键点击raw按钮,选择目标另存为,下载的是txt文件 win10如何 ...
- 将csv的数据导入mysql
手头有一份8MB的CSV文件需要分析,对于程序员来说,还有比在数据库里分析更愉快的事情吗? 所以让我们把CSV导入MYSQL吧. 一.首先按照文件列数创建相应的SQL表 例如: DROP TABLE ...
- MySQL中load data infile将文件中的数据批量导入数据库
有时候我们需要将文件中的数据直接导入到数据库中,那么我们就可以使用load data infile,下面具体介绍使用方法. dao中的方法 @Autowired private JdbcTemplat ...
随机推荐
- 堆+建堆、插入、删除、排序+java实现
package testpackage; import java.util.Arrays; public class Heap { //建立大顶堆 public static void buildMa ...
- Android SDK开发
目前我们的应用内使用了 ArcFace 的人脸检测功能,其他的我们并不了解,所以这里就和大家分享一下我们的集成过程和一些使用心得 集成 ArcFace FD 的集成过程非常简单 在 ArcFace F ...
- Golang websocket
环境:Win10 + Go1.9.2 1.先下载并引用golang的websocket库 ①golang的官方库都在https://github.com/golang下,而websocket库在/ne ...
- 牛客OI周赛4-提高组 B 最后的晚餐(dinner)
最后的晚餐(dinner) 思路: 容斥 求 ∑(-1)^i * C(n, i) * 2^i * (2n-i-1)! 这道题卡常数 #pragma GCC optimize(2) #pragma GC ...
- Integer与int区别
Integer与int的区别:估计大多数人只会说道两点,一开始我也不太清楚,Ingeter是int的包装类,int的初值为0,Ingeter的初值为null.但是如果面试官再问一下Integer i ...
- JavaWeb知识点总结
>一: 创建Web项目项目说明:1.java Resources:java源文件2.WebContent:网页内容html.css.js.jsp.资源.配置文件等 HTML:Hyper Text ...
- python - selenium 2 升级到最新版本
python - selenium 2 升级到最新版本 之前一直用的是selenium 2.48 .firefox36 而实际用户的浏览器可能都有自动更新功能,所以版本基本上是最新的.所以这次专门做了 ...
- Navicat Premium 12如何激活
Navicat Premium 12如何激活 一.总结 一句话总结:激活过程中一定要断开网络连接,点电脑的飞行模式没有用,断开网络连接之后才有手动激活的选项 需要断网 点电脑的飞行模式无用 二.Nav ...
- php oracle数据库NCOLB字段ORA-01704
php oracle数据库NCOLB字段ORA-01704 对clob更新 ORA-01704: 字符串文字太长 解决办法:把字符赋值给一个变量,然后赋值update语句 declarev_clob ...
- hihocoder-1407 后缀数组二·重复旋律2 不重合 最少重复K次
后缀数组不能直接通过Height得出不重合的公共串.我们可以二分k值,这样连续的Height只要都大于等于k,那他们互相间的k值都大于等于k.每个这样的连续区间查找SA的最大最小值,做差判断是否重合( ...