360搜索引擎取真实地址-python代码
还是个比较简单的,不像百度有加密算法
分析
http://www.so.com/link?url=http%3A%2F%2Fedu.sd.chinamobile.com%2Findex%2Fnews.do%3Faction%3DnoticeDetail%26id%3D22452&q=inurl%3Anews.do&ts=1488978912&t=89c5361a44fe3f52931d25c6de262bb&src=haosou
网址是上面这个样子,没加密直接取就好了,去掉头http://www.so.com/link?url=和尾&q=一直到末尾的部分,剩下的就可以吃了
那么规则我们就可以写出来了
a['href'][a['href'].index('?url='):a['href'].index('&q=')][5:]
a['href']是待处理网址,a['href'].index('?url='):a['href'].index('&q=')的部分为?url=http%3A%2F%2Fedu.sd.chinamobile.com%2Findex%2Fnews.do%3Faction%3DnoticeDetail%26id%3D22452
最后还需要用unquote解码
- 在python3中是
urllib.parse.unquote - 在python2中是
urllib.unquote
code
import requests
from bs4 import BeautifulSoup
from urllib.parse import unquote
headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0"
}
#爬取360搜索引擎真实链接,第一个参数关键词str,第二个参数爬取页数int
def parse360(keyword, pagenum):
keywordsBaseURL = 'https://www.so.com/s?q=' + str(keyword) + '&pn='
pnum = 1
while pnum <= int(pagenum):
baseURL = keywordsBaseURL + str(pnum)
try:
request = requests.get(baseURL, headers=headers)
soup = BeautifulSoup(request.text, "html.parser")
urls = [unquote(a['href'][a['href'].index('?url='):a['href'].index('&q=')][5:]) for a in soup.select('li.res-list > h3 > a')]
for url in urls:
yield url
except:
yield None
finally:
pnum += 1
用法示例:
def main():
for url in parse360("keyword",10):
if url:
print url
else:
continue
if __name__ == '__main__':
main()
最后上一张测试图
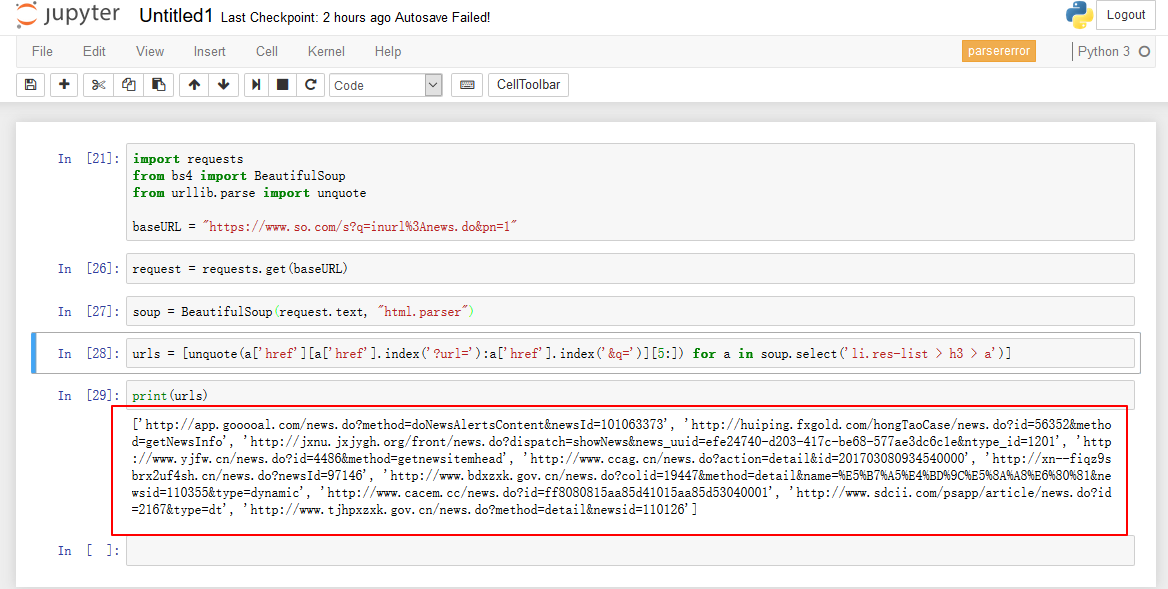
转载请注明出处
360搜索引擎取真实地址-python代码的更多相关文章
- 百度搜索引擎取真实地址-python代码
代码 def parseBaidu(keyword, pagenum): keywordsBaseURL = 'https://www.baidu.com/s?wd=' + str(quote(key ...
- 抓取oschina上面的代码分享python块区下的 标题和对应URL
# -*- coding=utf-8 -*- import requests,re from lxml import etree import sys reload(sys) sys.setdefau ...
- C#取真实IP地址及分析
说一哈,我也是转来的,不是想骗PV,方便自己查而已! 目前网上流行的所谓"取真实IP地址"的方法,都有bug,没有考虑到多层透明代理的情况. 多数代码类似: string IpAd ...
- JSP 获取真实IP地址的代码
[转载]JSP 获取真实IP地址的代码 JSP 获取真实IP地址的代码 在JSP里,获取客户端的IP地址的方法是:request.getRemoteAddr(),这种方法在大部分情况下都是有效的. ...
- 【转载】JSP 获取真实IP地址的代码
JSP 获取真实IP地址的代码 在JSP里,获取客户端的IP地址的方法是:request.getRemoteAddr(),这种方法在大部分情况下都是有效的. 但是在通过了 Apache,Squid ...
- 20行Python代码爬取王者荣耀全英雄皮肤
引言王者荣耀大家都玩过吧,没玩过的也应该听说过,作为时下最火的手机MOBA游戏,咳咳,好像跑题了.我们今天的重点是爬取王者荣耀所有英雄的所有皮肤,而且仅仅使用20行Python代码即可完成. 准备工作 ...
- python爬取网页的通用代码框架
python爬取网页的通用代码框架: def getHTMLText(url):#参数code缺省值为‘utf-8’(编码方式) try: r=requests.get(url,timeout=30) ...
- Python动态网页爬虫-----动态网页真实地址破解原理
参考链接:Python动态网页爬虫-----动态网页真实地址破解原理
- python爬虫构建代理ip池抓取数据库的示例代码
爬虫的小伙伴,肯定经常遇到ip被封的情况,而现在网络上的代理ip免费的已经很难找了,那么现在就用python的requests库从爬取代理ip,创建一个ip代理池,以备使用. 本代码包括ip的爬取,检 ...
随机推荐
- python之mysqldb模块安装
之所以会写下这篇日志,是因为安装的过程有点虐心.目前这篇文章是针对windows操作系统上的mysqldb的安装.安装python的mysqldb模块,首先当然是找一些官方的网站去下载:https:/ ...
- Core Java Fundation
http://www.cnblogs.com/cmfwm/p/7671188.html http://blog.csdn.net/fuckluy/article/details/50614983 ht ...
- sql server2000中使用convert来取得datetime数据类型样式(转)
日期数据格式的处理,两个示例: CONVERT(varchar(16), 时间一, 20) 结果:2007-02-01 08:02/*时间一般为getdate()函数或数据表里的字段*/ CONVER ...
- 【Linux学习三】VI/VIM全屏文本编辑器
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 一.打开关闭文件打开文件:vim /path/to/somefilev ...
- 【转】Tomcat 快速入门
本文转载自:https://www.cnblogs.com/jingmoxukong/p/8258837.html?utm_source=gold_browser_extension 目录 Tomca ...
- java springboot activemq 邮件短信微服务,解决国际化服务的国内外兼容性问题,含各服务商调研情况
java springboot activemq 邮件短信微服务,解决国际化服务的国内外兼容性问题,含各服务商调研情况 邮件短信微服务 spring boot 微服务 接收json格式参数 验证参数合 ...
- ptrace线程
在ptrace时使用waitpid(-1, &status, 0);无法正常trace 修改为waitpid(-1, &status, __WALL);即可 原因是:
- 51Nod 1072 威佐夫游戏
题目链接:https://www.51nod.com/onlineJudge/questionCode.html#!problemId=1072 有2堆石子.A B两个人轮流拿,A先拿.每次可以从一堆 ...
- bzoj1180 tree
题目链接 link cut tree 模板题 link cut tree不都是模板题嘛?(雾 #include<algorithm> #include<iostream> #i ...
- linux OS与SQL修改时区,系统时间
linux修改系统时间和linux查看时区.修改时区的方法 一.查看和修改Linux的时区 1. 查看当前时区命令 : "date -R" 2. 修改设置Linux服务器时区方法 ...